当前位置:网站首页>Basic knowledge of database (interview)
Basic knowledge of database (interview)
2022-07-05 23:02:00 【Chelizi】
One 、 Basic knowledge of
1、Char and Varchar difference ?
(1)Char It's fixed length , and Varchar Yes, it can grow .
Char Space will be allocated according to the declared string length , The right side of the string will be filled with spaces .
(2) In terms of storage mode ,Char Occupation of English characters 1 byte , Use... For a Chinese character 2 byte . and Varchar Use... For each character 2 byte .
2、 What are the three paradigms of database ?
(1) First normal form : Any table should have Primary key , And the atomicity of each field can no longer be divided .

(2) Second normal form : Based on the First normal form Based on , All non primary key fields depend entirely on the primary key , Can't generate partial dependence .

(3) Third normal form : Based on the second paradigm , All non primary key fields directly depend on the primary key , Cannot generate delivery dependency .

Many to many ? Use three tables , Relation table two Foreign keys .
One to many ? Two tables , Add more watches Foreign keys .
Two 、 Indexes
1、 Classification of indexes
Single index : Add an index to a single field
Composite index : Add an index to the union of multiple fields
primary key : An index is automatically added to the primary key
unique index : Yes unique Indexes are automatically added to the constrained fields
2、 Advantages and disadvantages of index
An index is equivalent to a list of books , Through the directory, you can quickly find the corresponding resources .
In terms of databases , There are two retrieval methods when querying a table : Full table scan 、 Index search ( It's very efficient ).
Although index can improve retrieval efficiency , But you can't add indexes at will , Because the index is also an object in the database , It also requires continuous database maintenance . such as , The data in the table is often modified , This is not suitable for adding indexes , Because once the data is modified , The index needs to be reordered , For maintenance .
3、 The design principle of index ( When to consider adding an index to a field )
The amount of data is huge ( According to the needs of customers , According to the online environment )
This field is rarely used DML operation ( Because the field cannot be modified , Indexes also need to be maintained )
This field often appears in where clause ( Which field do you often query based on )
- Choose a unique index ;
- Index fields that are often used as query criteria ;
- Order for frequent need 、 Index fields for grouping and combining operations ;
- Limit the number of indexes ;
- Watch 不 Suggest index ( For example, the magnitude is within one million );
- all 量 Using data 量 Fewer indexes ;
- Delete indexes that are no longer or rarely used .
4、 The data structure of the index
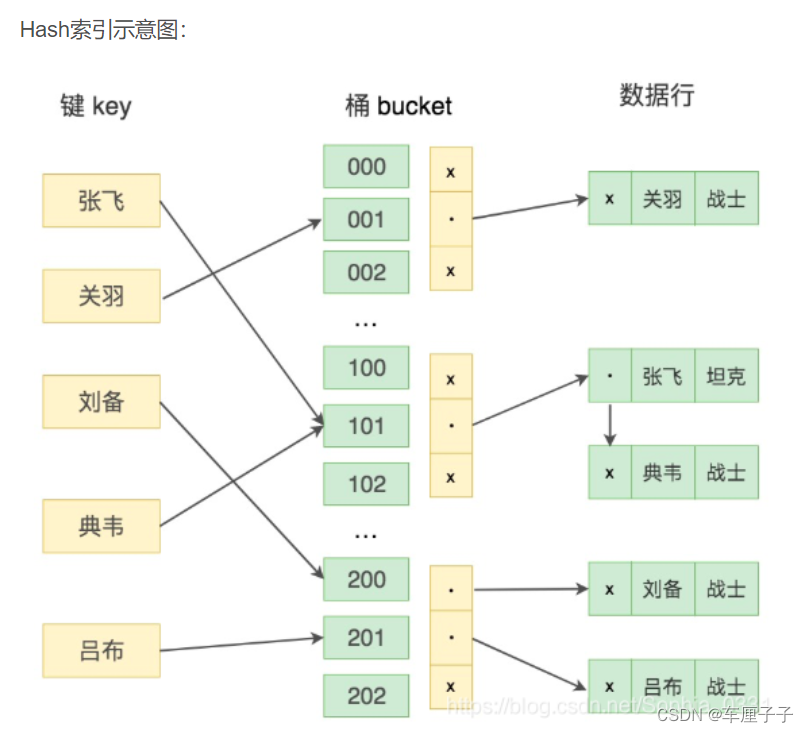
The data structure of index is related to the implementation of specific storage engine ,MySQL What is commonly used in Hash and B+ Trees Indexes .
Hash Indexes The bottom is Hash surface , When querying, call Hash Function gets the corresponding key value ( Corresponding address ), Then go back to the table and query to obtain the actual data .
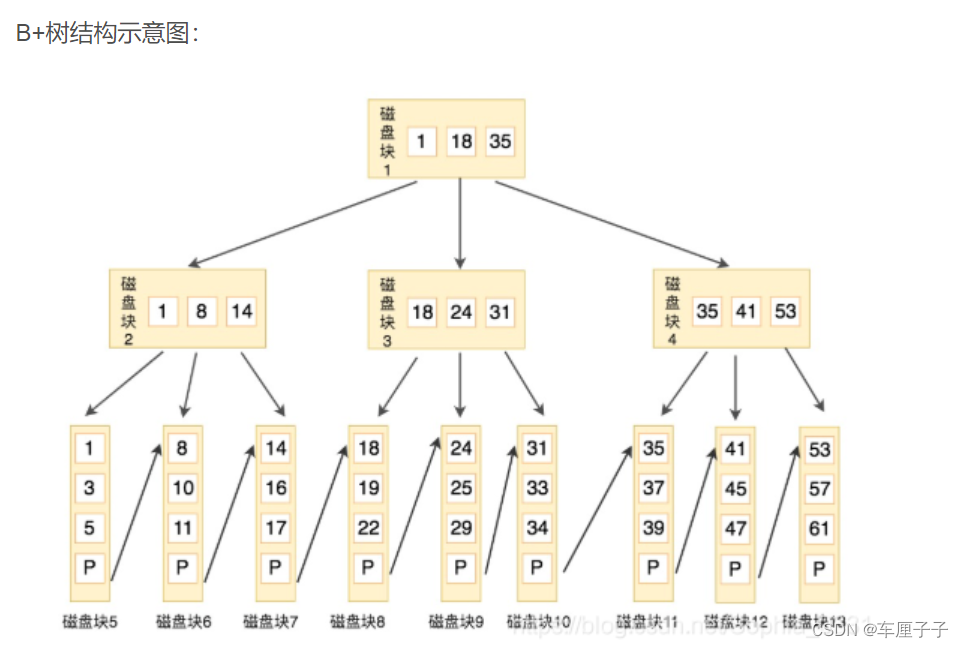
B+ Tree index The underlying implementation principle is multi-channel balanced lookup tree , Every query starts from the root node , Query the leaf node to get the key value , Finally, query to determine whether it is necessary to query back to the table .
(1)Hash and B+ The difference between tree indexes
Hash
1)Hash Faster equivalent query , But you can't do a range query . Because after Hash After the function is indexed , The order of indexes cannot be consistent with the original order , Therefore, range query cannot be supported . Empathy , Nor does it support sorting by index .
2)Hash Fuzzy query and leftmost prefix matching of multi column index are not supported , because Hash The value of the function is unpredictable , Such as AA and AB There is no correlation between the calculated values of .
3)Hash You can't avoid querying data back to the table at any time .
4) Although the query efficiency is high in equivalence , But the performance is unstable , Because when there are a lot of duplicates in a key value , produce Hash Collision , At this time, the query efficiency may be reduced .
B+ Tree
1)B+ The essence of a tree is a search tree , Natural support range query and sorting .
2) When certain conditions are met ( Cluster index 、 Overwrite index, etc ) When you can complete the query only through the index , There is no need to return the form .
3) The query efficiency is relatively stable , Because every query is from the root node to the leaf node , And is the height of the tree .
(2) Why use B+ Trees Instead of Binary tree and B Trees Do the index
Binary tree
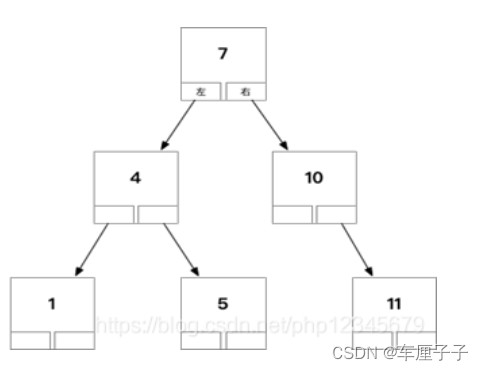
a. If there is a lot of index data , The level of the tree will be very high ( Only the left and right child nodes ), When the amount of data is large, the query will still be slow , The search efficiency is O(logn).
b. A binary tree stores only one record per node , When a query is found in the tree, it takes disk IO More times . When the file system needs to read data from disk , Generally read on a page basis , Suppose there is too little data in a page , Then the operating system needs to read more pages , Involving random disks I/O More visits . Reading data from disk into memory involves random I/O The interview of , It is one of the most expensive operations in the database .
B Trees
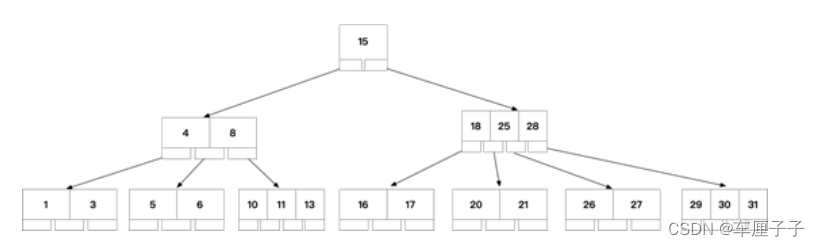
a. It's not a binary search anymore , It is N Cross search , The height of the tree will decrease , Quick query
b. Leaf node , Nonleaf node , Can store data , And can store multiple data
c. Traverse through the middle order , You can access all nodes in the tree
B+ Trees
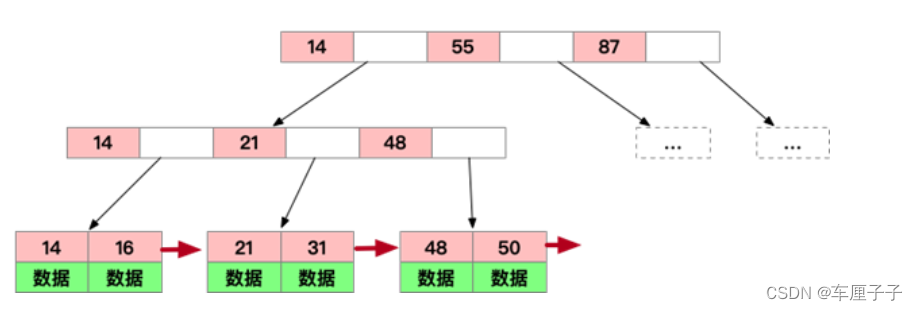
B Both non leaf nodes and leaf nodes store data , So when querying data , The best time complexity is O(1), The worst is O(log n). and B+ Trees store data only at leaf nodes , Non leaf nodes store keywords , And the keywords of different non leaf nodes may be repeated , So when querying data , The time complexity is fixed to O(log n).
B+ The leaf nodes of trees are connected with each other by linked list , Therefore, only scanning the linked list of leaf nodes can complete a traversal operation ,B Trees can only be traversed through the middle order .
Why? B+ Tree ratio B Trees are more suitable for database indexes ?
B+ There are fewer trees IO frequency .
Because the index file is very large, the index file is stored on disk ,B+ The non leaf nodes of the tree only store keywords, not data , As a result, a single page can store more keywords , That is to say, the more keywords need to be searched when reading into memory at one time , Random disk I/O The number of reads is relatively reduced . and B Both non leaf nodes and leaf nodes store data .
B+ Tree query efficiency is more stable
Because the data only exists on the leaf node , So the search efficiency is fixed to O(log n), therefore B+ The query efficiency of tree is compared with B Trees are more stable .
B+ The tree is more suitable for range lookup
B+ The leaf nodes of a tree are connected in order by a linked list , So to scan all the data, you only need to scan the leaf node once , Easy to scan database and range query ;B Trees also store data because they are not leaf nodes , Therefore, we can only scan in order by traversing the middle order . in other words , For range queries and ordered traversal ,B+ More efficient trees .
3、 ... and 、 Storage
1、 Storage engine (MyISAM and InnoDB)
(1)InnoDB Support transactions , and MyISAM I won't support it .
(2)InnoDB Support foreign keys , and MyISAM I won't support it . So you're going to have a with a foreign key InnoDB surface To MyISAM The table will fail .
(3)InnoDB and MyISAM support B+ Tree Index of data structure . but InnoDB yes Clustered index , and MyISAM Yes no clustered index .
(4)InnoDB Do not save the number of data rows in the table , perform select count(*) from table You need a full scan . and MyISAM Use a variable to record the number of rows in the whole table , Pretty fast ( Be careful not to have WHERE Clause ).
(5)InnoDB Support surface 、 That's ok ( Default ) Level lock , and MyISAM Support table level lock .
(6)InnoDB There has to be unique index ( Such as primary key ), If not specified , Will automatically find or produce a hidden column Row_id To act as the default primary key , and MyISAM There can be no primary key .
By default InnoDB,MyISAM It is applicable to the program dominated by insertion , Like the blog system 、 News portal .
2、 Storage structure
InnoDB Page of 、 District 、 paragraph ?
page (Page)
First ,InnoDB Divide the physical disk into pages (page), The default size of each page is 16 KB, Page is the smallest storage unit .
District (Extent)
If there is only one level of page , The number of pages is very large , The allocation and recycling of storage space will be troublesome , Because maintaining the state of so many pages is very troublesome . therefore ,InnoDB It also introduces the area (Extent) The concept of . A zone defaults to 64 Consisting of consecutive pages , That is to say 1MB. adopt Extent It is easier to allocate and recycle storage space .
paragraph (Segment)
B+ The leaf node of the tree stores our specific data , Non leaf nodes are index pages . therefore B+ The tree divides the data into two parts , Leaf node part and non leaf node part , That's the paragraph we're going to introduce Segment, in other words InnoBD Two are created for each index in Segment To store the corresponding two parts of data .
Four 、 Business
1、 What is a database transaction ?
A transaction is a complete business logic unit , Can not be further divided .

Two of the above DML Statements must both succeed , Or fail at the same time , A success message is not allowed , One failure .
To ensure the above two DML Statements succeed or fail at the same time , Then you need to use the database “ Transaction mechanism ”.
2、 What are the four characteristics of a transaction ?(ACID)
A: Atomicity : Transactions are the smallest unit of work , Can not be further divided .
C: Uniformity : Transactions must guarantee multiple DML Statements succeed or fail at the same time .
I: Isolation, : Business A And business B There is isolation between , The database between concurrent transactions is independent .
D: persistence : The final data must be persisted to the hard disk file , The transaction is a successful end .
3、 Concurrency of transactions ?
Dirty reading : One transaction reads uncommitted data from another transaction . Business A Read transactions B Updated data , then B Rollback operation , that A The data read is dirty .
Fantasy reading : The amount of data read twice in a transaction is inconsistent . System administrator A Change the scores of all students in the database from specific scores to ABCDE Grade , But the system administrator B At this time, a specific score record was inserted , When the system administrator A After the change, I found that there is another record that hasn't been changed , It's like an illusion , This is called Unreal reading .
It can't be read repeatedly : The contents of the data read twice in a transaction are inconsistent . Business A Read the same data multiple times , Business B In the transaction A During multiple reads , The data has been updated and submitted , Cause transaction A When reading the same data multiple times , result atypism .
4、 The isolation level of the transaction
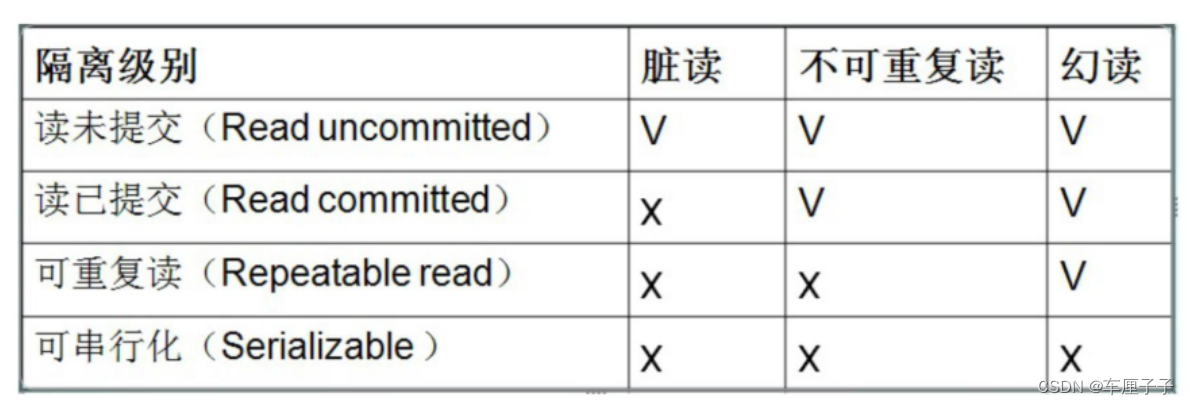
First level : Read uncommitted (Read uncommitted)
The other party's transaction has not been committed , Our current transaction can read uncommitted data from the other party .
Read uncommitted, dirty read exists (dirty read) The phenomenon : Indicates that dirty data has been read .
The second level : Read submitted (Read committed)
We can read the data after the other party's transaction is committed .
The problem with reading submitted is : It can't be read repeatedly .
The third level : Repeatable (Repeatable read)
This isolation level solves the problem of non repeatable reads .
The problem with this level of isolation is : The data read is an illusion 、
Level 4 : Serializable (Serializable)
All problems solved . Low efficiency , Transaction queuing is required .
oracle The default isolation level of the database is read committed ;mysql database The default isolation level is Repeatable .
5、 ... and 、 lock
1、 The function and classification of database lock
When there are concurrent transactions in the database , There may be data inconsistencies , At this time, we need some mechanisms to ensure the order of access , Lock mechanism is such a mechanism . That is, the function of lock is to solve the problem of concurrency .
From the granularity of lock , Locks can be divided into table locks 、 Row lock and page lock
Row-level locks : It is the lock with the smallest granularity , Indicates that only the row of the current operation is locked . Row level lock can greatly reduce the conflict of database operation . The lock granularity is the smallest , But locking costs the most .
The overhead of row level locking is large , Lock the slow , And there will be a deadlock . But the locking granularity is the smallest , The lowest probability of lock collisions , The highest degree of concurrency .
Table lock : It is a lock with the largest granularity , Indicates to lock the whole table of the current operation , It's easy to implement , Less resource consumption , By most MySQL Engine support .
Page level lock : It is a kind of lock with granularity between row level lock and table level lock . The watch lock is fast , But there are many conflicts , Less line level conflict , But the speed is slow. . So I took the middle page level , Lock an adjacent set of records at a time .
From the nature of use , Can be divided into shared locks 、 Exclusive lock and update lock
Shared lock :S lock , Also called read lock , For all read-only data operations .
S Locks are not exclusive , Allow multiple concurrent transactions to lock the same resource , But add S It is not allowed to add... While locking X lock , That is, resources cannot be modified .S The lock is usually released immediately after reading , No need to wait for the transaction to end .
Exclusive lock :X lock , Also known as write lock , Means to write data .
X Locks allow only one transaction to lock the same resource , And not released until the end of the transaction , Any other business has to wait until X The lock is released to access the page .
Update lock :U lock , Used to book the resources to be imposed X lock , Allow other transactions to read , But no more U Lock or X lock .
When the page being read is about to be updated , Upgrade to X lock ,U The lock cannot be released until the end of the transaction . so U Locks are used to avoid deadlocks caused by shared locks .
Subjectively divide , It can also be divided into optimistic lock and pessimistic lock
Optimism lock : Subjectively determine that resources will not be modified , So read data without locking , Only when updating, use the version number mechanism to confirm whether the resource has been modified .
Optimistic lock is suitable for multi read applications , The system throughput can be improved .
Pessimistic locking : With strong exclusivity and exclusivity , Every time the data is read, it is considered that it will be modified by other transactions , So every operation needs to be locked .
2、 Relationship between isolation level and lock ?
1) stay Read Uncommitted Below grade , Reading data does not require a shared lock , This will not conflict with the exclusive lock on the modified data ;
2) stay Read Committed Below grade , Read operations require shared locks , But release the shared lock after the statement is executed ;
3) stay Repeatable Read Below grade , Read operations require shared locks , But the shared lock is not released before the transaction is committed , In other words, the shared lock must be released after the transaction is completed ;
4) stay SERIALIZABLE Below grade , The most restrictive , Because this level locks the entire range of keys , And hold the lock all the time , Until the transaction is complete .
3、 Snapshot read and current read
Read the snapshot Is to read snapshot data , Simple without lock Select All belong to snapshot reading .
The current reading Is to read the latest data , Not historical data . The lock SELECT, Or add, delete and modify the data, which will be read currently .
4、 What is? MVCC And realize ?
MVCC Multi version concurrency control , You can read and write without blocking each other , It is mainly used to improve the concurrency efficiency when solving the problems of non repeatable reading and unreal reading .
Its principle is to realize the concurrency control of database through multiple version management of data rows , Simply put, it's saving historical versions of the data . You can determine whether the data is displayed by comparing the version numbers . When reading data, there is no need to lock to ensure the isolation effect of transactions .
6、 ... and 、SQL sentence
1、SQL Left connection of 、 The right connection 、 Internal connection
(1)Left join: That's left connection , It's based on the left table , according to ON The conditions of the two tables given later connect the two tables . The result will list all the query information in the left table , The right table only lists ON The latter condition is the same as the part satisfied by the left table . The full name of the left connection is the left outer connection , It is a kind of external connection .
(2)Right join: Right connection , Is based on the right table , according to ON The conditions of the two tables given later connect the two tables . The result will list all the query information in the right table , The left table only lists ON The latter condition is the same as the part satisfied by the right table . The full name of right connection is right outer connection , It is a kind of external connection .
(3)Inner join: Internal connection , At the same time, take the two tables as reference objects , according to ON The conditions of the two tables given later connect the two tables . The result is that both tables meet ON The following conditions will be listed .
The internal connection can only query the data that can be matched by two tables , Unmatched data cannot be found .
The external connection can unconditionally query all the data in the main table .
2、Where and Having The difference between ?
where Clause is used before grouping query results , Remove the unqualified lines , That is to say Filter data before grouping ,where A condition cannot contain a grouper function , Use where Conditions filter out specific lines .
having Clause is used to filter groups that meet the conditions , That is to say Filter data after grouping , Conditions often include groupings , Use having Conditions filter out specific groups , You can also use multiple grouping criteria for grouping .
边栏推荐
- The difference between MVVM and MVC
- 我对新中台模型的一些经验思考总结
- 两数之和、三数之和(排序+双指针)
- Selenium+Pytest自动化测试框架实战
- Tensor attribute statistics
- Fix the memory structure of JVM in one article
- Vcomp110.dll download -vcomp110 What if DLL is lost
- My experience and summary of the new Zhongtai model
- Function default parameters, function placeholder parameters, function overloading and precautions
- 一文搞定class的微观结构和指令
猜你喜欢
LeetCode145. Post order traversal of binary tree (three methods of recursion and iteration)
How can easycvr cluster deployment solve the massive video access and concurrency requirements in the project?
Week 17 homework
Selenium+Pytest自动化测试框架实战
Leetcode weekly The 280 game of the week is still difficult for the special game of the week's beauty team ~ simple simulation + hash parity count + sorting simulation traversal
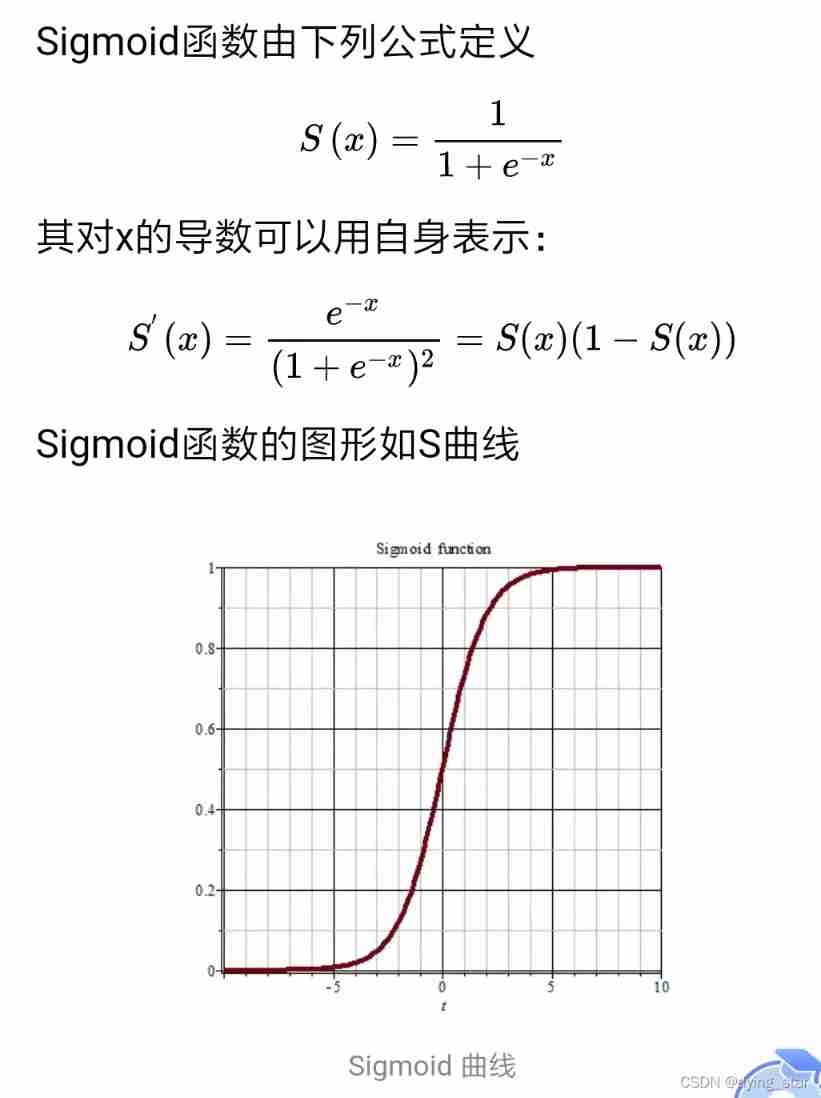
Activate function and its gradient
One article deals with the microstructure and instructions of class
Three. Js-01 getting started
![[untitled]](/img/98/aa874a72f33edf416f38cb6e92f654.png)
[untitled]
Matlab smooth curve connection scatter diagram
随机推荐
Media query: importing resources
使用rewrite规则实现将所有到a域名的访问rewrite到b域名
Vision Transformer (ViT)
如何快速理解复杂业务,系统思考问题?
Arduino measures AC current
Thinkphp5.1 cross domain problem solving
Finally understand what dynamic planning is
Tiktok__ ac_ signature
我对新中台模型的一些经验思考总结
并查集实践
【Note17】PECI(Platform Environment Control Interface)
Paddy serving v0.9.0 heavy release multi machine multi card distributed reasoning framework
openresty ngx_ Lua regular expression
Registration and skills of hoisting machinery command examination in 2022
东南亚电商指南,卖家如何布局东南亚市场?
Yiwen gets rid of the garbage collector
鏈錶之雙指針(快慢指針,先後指針,首尾指針)
C Primer Plus Chapter 9 question 9 POW function
派对的最大快乐值
[speech processing] speech signal denoising and denoising based on MATLAB low-pass filter [including Matlab source code 1709]