当前位置:网站首页>Event parse tree Drain3 usage and explanation
Event parse tree Drain3 usage and explanation
2022-08-05 03:43:00 【less shopkeeper selling sesame oil】
Event parse treeDrain
开源代码链接:https://github.com/IBM/Drain3
开源代码:IBM/Drain3
Originally a paper published by the Chinese University of Hong Kong,Purpose of invention for parsing log templates,Initiate research and open source,后由IBMTeam of engineers excavating,进行了python3.x的迭代,重构了代码,method is exactly the same method,Drain升级为Drain3.
Here is the original paper addresses:
http://jiemingzhu.github.io/pub/pjhe_icws2017.pdf
Drain3Introduction to the principle
The following article part are introducedIBMThe team is based on the team work of the Chinese University of Hong Kong,further improvement work,和Drain3的能力介绍.
Use open source Drain3 log-template mining project to monitor for network outages使用开源的Drain3Log template mining project to monitor network outages
Log-template mining is a method for extracting useful information from unstructured log files. This blog post explains how you can use log-template mining to monitor for network outages and introduces you to Drain3, an open source streaming log template miner.Log template mining is a method to extract useful information from unstructured log files.This blog post explains how to use log template mining to monitor network outages,and introduced to youDrain3,This is an open source flow log template mining tool.
Our main goal in this use case is the early identification of incidents in the networking infrastructure of data centers that are part of the IBM Cloud. The IBM Cloud is based on many data centers in different regions and continents. At each data center (DC), thousands of network devices produce a high volume of syslog events. Using that information to quickly identify and troubleshoot outages and performance issues in the networking infrastructure helps reduce downtime and improve customer satisfaction.
在这个用例中,Our main goal is to identify earlyIBM Cloudof events in the network infrastructure of the data center.IBM CloudBased on many data centers located in different regions and continents.在每个数据中心(DC),Thousands of network devices generate a large amount ofsyslog事件.Use this information to quickly identify and troubleshoot outages and performance issues in your network infrastructure,Helps reduce downtime and improve customer satisfaction.
Logs usually exist as raw text files, although they can also be in other formats like csv, json, etc. A log contains a series of events that occurred in the system/component that wrote them. Each event usually carries a timestamp field and a free text field that describes the nature of the event (generated from a template written in a free language). Usually, each log event includes additional information, which might cover event severity level, thread ID, ID of the software component that wrote the event, host name, etc.
Logs usually exist as raw text files,Although they can also be in other formats,如csv、json等.The log is included in the system that wrote the log/A sequence of events that occur in a component.Each event usually has a timestamp field and a free text field describing the nature of the event(Generated from a template written in a free language).通常,Each log event contains additional information,Include the severity level of the incident、线程ID、Write software components of the eventID、主机名等.
This log event contains the following information parts (headers): timestamp, hostname, priority, and message body.
The log event contains the following information sections(头):时间戳、主机名、Priority and message body.
Each data center contains devices covering many vendors, types and versions. And these devices output log messages in many formats. Our first step was to extract the headers specified above. This can be done deterministically with some regular-expression based rules.Each data center contains many vendors、Type and version of device.These devices output log messages in various formats.Our first step is to extract the header files specified above.This can be done deterministically with some regex based rules.
Logs vs metrics日志和指标
When we want to troubleshoot or debug a complex software component, logs are usually among our best friends. Often we can also use metrics that cover periodic measurements of the system’s performance. These may include: CPU usage, memory usage, number of requests per second, etc. There are multiple mature and useful techniques and algorithms to analyze metrics, but significantly fewer to analyze logs. Therefore, we decided to build our own.When we want to troubleshoot or debug a complex software component,Logs are often our best friend.通常,We can also use metrics that contain periodic measures of system performance.这些可能包括:CPU使用情况、内存使用情况、requests per second, etc.There are various mature and useful techniques and algorithms for analyzing indicators,But there are far fewer techniques and algorithms for analyzing logs.因此,We decided to build our own.
While metrics are easier to deal with because they represent a more structured type of information, they don’t always have the information we’re looking for. From a developer perspective, the effort required to add a new type of metric is greater than what is needed to add a new log event. Also, we usually want to keep the number of metrics we collect reasonably small to avoid bloating storage space and I/O.While metrics are easier to work with,because they represent a more structured type of information,But they don't always contain the information we're looking for.从开发人员的角度来看,Adding new types of metrics requires more work than adding new log events.此外,We generally want to keep the number of metrics collected fairly small,to avoid increasing storage space andI/O.
We tend to add metric types post-mortem (after some kind of error occurred) in an effort to detect that same kind of error in the future. Software with a good set of metrics is usually mature and has been deployed in production for a long period. Logging, on the other hand, is easier to write and more expressive. This naturally results in log files containing more information that is useful for debugging than what is found in metric streams. This is especially true in less-mature systems. As a result, logs are better for troubleshooting errors and performance problems that were not anticipated when the software was written.We tend to be after the fact(after some type of error)Add a metric type,so that the same type of error can be detected in the future.Software with good metrics is usually mature,and has been deployed in production for a long time.另一方面,Logging is easier to write,也更有表现力.This naturally results in log files containing more useful debugging information than in the metric stream.This is especially true in less mature systems.因此,Logs can better troubleshoot errors and performance issues that were not anticipated when the software was written.
Dealing with the unstructured nature of logsHandling the unstructured nature of logs
One major difference between a log file and a book, for example, is that a log is produced from a finite number of immutable print statements. The log template in each print statement never changes, and the only dynamic part is the template variables. For example, the following Python print statement would generate the free-text (message-body) portion of the log event in the example above:例如,One of the main differences between log files and books is that,The log is generated by a limited number of immutable print statements.The log template in each print statement does not change,The only dynamic part is the template variable.例如,下面的Python printStatements will be generated in the example above log event free text(message-body)部分:
print (f’User {user_name} logged out successfully, session duration = {hours} hours, {seconds} seconds’)
It’s generally not a simple task to identify the templates used in a log file because the source code or parts of it are not always available. If we had a unique identifier per event type included in each log message, that would help a lot, but that kind of information is rarely included.Identifying templates used in log files is often not a simple task,because the source code or parts of it are not always available.If each event type contained in each log message has a unique identifier,那将非常有帮助,but rarely contains such information.
Fortunately, the de-templating problem has received some research attention in recent years. The LogPAI project at the Chinese University of Hong Kong performed extensive benchmarking on the accuracy of 13 template miners. We evaluated the leading performers on that benchmark for our use case and settled on Drain as the best template-miner for our needs. Drain uses a simple approach for de-templating that is both accurate and fast.幸运的是,The de-template problem has received some research attention in recent years.香港中文大学的LogPAI项目对13The accuracy of the template miners was extensively benchmarked.We evaluate leading performance on benchmarks for use cases,并确定Drainis the best template miner for our needs.DrainUse a simple method that is both accurate and fast to template.
Preparing Drain for production usageReady for production useDrain
Moving forward, our next step was to extend Drain for the production environment, giving birth to Drain3 (i.e., adjusted for Python 3). In our scenario, syslogs are collected from the IBM Cloud network devices and then streamed into an Apache Kafka topic. Although Drain was developed with a streaming use-case in mind, we had to solve some issues before we could use Drain in a production pipeline. We detail these issues below.继续前进,Our next step is to scale in productionDrain,产生Drain3(即,针对Python 3进行调整).在我们的场景中,syslog日志从IBMCloud network equipment collection,然后流到Apache Kafka主题中.尽管Drainis developed based on flow use cases,but in our production pipeline we can useDrain之前,We have to solve some problems.We will discuss these issues in detail below.
Refactoring - Drain was originally implemented in Python 2.7. We converted the code into a modern Python 3.6 codebase, while refactoring, improving the readability of the code, removing dependencies (e.g., pandas) and unused code, and fixing some bugs.重构——Drain最初是在Python 2.7中实现的.We convert the code to modernPython 3.6代码库,Refactoring at the same time,提高了代码的可读性,Removed dependencies(如pandas)and unused code,并修复了一些bug.
Streaming Support - Instead of using the original function that reads a static log file, we externalized the log-reading code, and added a feeding function add_log_message() to process the next log line and return the ID of the identified log cluster (template). The cluster ID format was changed from a hash code into a more human-readable sequential ID.流支持——We are not using the original function that reads static log files,Instead, externalize the log reading code,and added a complementary functionadd_log_message()To deal with the next log line,and returns the identified log cluster(模板)的ID.集群IDFormat changed from hash code to more readable orderID.
Resiliency - A production pipeline must be resilient. Drain is a stateful algorithm that maintains a parse tree that can change after each new log line begins being processed. To ensure resiliency, the template extractor must be able to restart using a saved state. In this way, after a failure, any knowledge already gathered will remain when the process recovers. Otherwise, we would have to stream all the logs from scratch to reach the same knowledge level. The state should be saved to a fault-tolerant, distributed medium and not a local file. A messaging system such as Apache Kafka is suitable for this, since it is distributed and persistent. Moreover, we were already using Kafka in our pipeline and did not want to add a dependency on another database/technology.弹性——Production pipelines must be resilient.Drainis a stateful algorithm,It maintains a parse tree,This parse tree can be changed after each new log line is processed.To ensure flexibility,The template extractor must be able to restart with the saved state.这样,在失败之后,when the process resumes,Any knowledge that has been gathered will be preserved.否则,We will have to stream all the logs from scratch,to achieve the same level of knowledge.State should be saved to a fault-tolerant distributed medium,instead of local files.像Apache KafkaSuch a messaging system is suitable for this,Because it is distributed and persistent.此外,We already use in our pipelineKafka,and don't want to add to another database/技术的依赖.
We had the Drain state serialized and published into a dedicated Kafka topic upon each change. Our assumption was that after an initial learning period, new or changed templates will occur rather infrequently, and that would not be a big performance hit. Another advantage of Kafka as a persistence medium is that, in addition to loading the latest state, we could also load prior versions, depending on the topic size, which is dependent on the topic retention policy we define.We serializedDrain状态,and publish it to a dedicatedKafka主题中.我们的假设是,after the initial learning phase,New or changed templates will rarely appear,This will not have big impact on performance.KafkaAnother advantage of being a persistent medium is that,Apart from loading the latest state,We can also load previous versions,It depends on the size of the theme,It depends on our defined topic retention policy.
We also made the persistence pluggable (i.e., injectable), so it would be easy to add additional persistence mediums or databases, and provide persistence to a local file for testing purposes.We also make persistence pluggable(即可注入),so it is easy to add additional persistent media or databases,and provide persistence to a local file for testing.
Masking - We also improved the template mining accuracy by adding support for masking. Masking of a log message is the process of identifying constructs such as decimal numbers, hex numbers, IPs, email addresses, and so on, and replacing those with wildcards. In Drain3, masking is performed prior to processing of the log de-templating algorithm to help improve its accuracy. For example, the message ‘request 0xefef23 from 127.0.0.1 handled in 23ms‘ could be masked to ‘request from handled in ms’. Usually, just a few regular expression rules are sufficient for masking.屏蔽——We also improved the accuracy of template mining by adding support for masking.Masking log messages is to identify things such as decimal numbers、十六进制数、ip、Structures such as email addresses,and use wildcards to replace the process of these structs.在Drain3中,Mask before processing log anti-template algorithm,to help improve its accuracy.例如,消息’ request 0xefef23 from 127.0.0.1 handled in 23ms ‘Can be masked as ’ request from handled in ms '.通常,Just a few regex rules are enough to mask.
Packaging - The improved Drain3 code-base, including state persistence support and the enhancements, is available as an open source software under the MIT license in GitHub: https://github.com/IBM/Drain3. It is also consumable with pip as a PyPI package. Contributions are welcome.打包—经过改进的Drain3代码库,Includes state persistence support and enhancements,可以在GitHubas open source software onMIT许可下使用:https://github.com/IBM/Drain3.它还可以作为PyPI包与pip一起使用.Contributions are welcome.
Using log templates for analyticsAnalysis using log templates
Now that we could identify the template for each log message, how would we use that information to identify outages? Our model detects sudden changes in the frequencies of message types over time, and those may indicate networking issues. Take for example, a network device that normally outputs 10 log message of type L1 every 5 minutes. If that rate drops to 0, it might mean the device is down. Similarly, if the rate increased significantly, it may indicate another issue, e.g. a DDoS attack. Generally, rare types of messages, or message types we have never seen before, are also highly correlated with issues. This is keeping in mind that errors in a production data center are rare.Now that we can determine the template for each log message,So how do you use that information to determine outages??Our model detects sudden changes in message type frequency over time,These changes may indicate network problems.例如,each of a network device5minutes are output normally10条L1Type of log information.If the rate drops to0,This could mean that the equipment failure.类似地,If the rate increases significantly,may mean another problem,例如DDoS攻击.通常,Rare message types or ones we have never seen are also highly relevant to the problem.这要记住,Errors are rare in production data centers.
It is also possible to analyze the values of parameters in the log messages, just as we would for metrics. An anomaly in a parameter value could indicate of an issue. For example, we could look at a log message that prints the time it took to perform some operation:You can also analyze parameter values in log messages,As we analysis measures.Anomalies in parameter values may indicate a problem.例如,We can look at a log message,It prints the time it took to do something:
fine tuning completed (took <NUM> ms)
Or a new categorical (string) parameter we never encountered before, e.g., a new task name that did not load:or a new category we've never encountered before(字符串)参数,例如,A new task name that is not loaded:
Task Did Not Load: <*>
Let’s take the following synthetic log snippet and see how we turn it into a time series on which we can do anomaly detection:Let's take the following synthetic log snippet as an example,See how we can convert this into a time series,for anomaly detection:
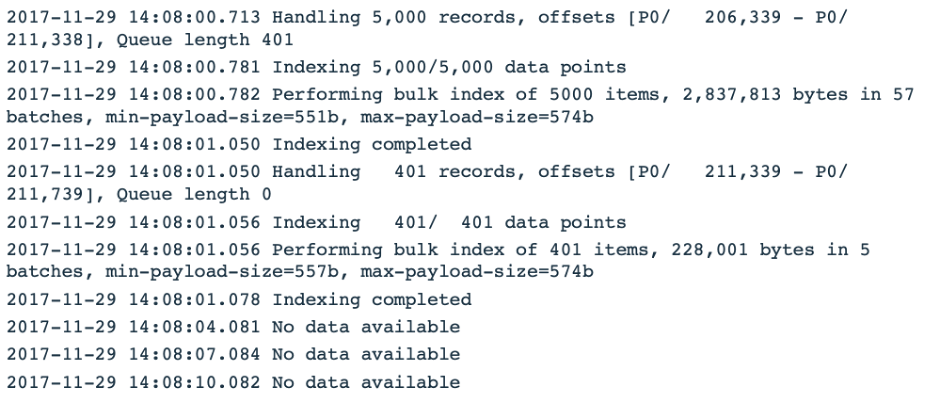
We cluster the messages using the color codes for message types, as follows:We cluster messages using color coding of message types,如下所示:

Now we count the occurrences of each message type in each time window, and also calculate an average value for each parameter:Now we count the number of occurrences of each message type in each time window,and calculate the mean of each parameter:
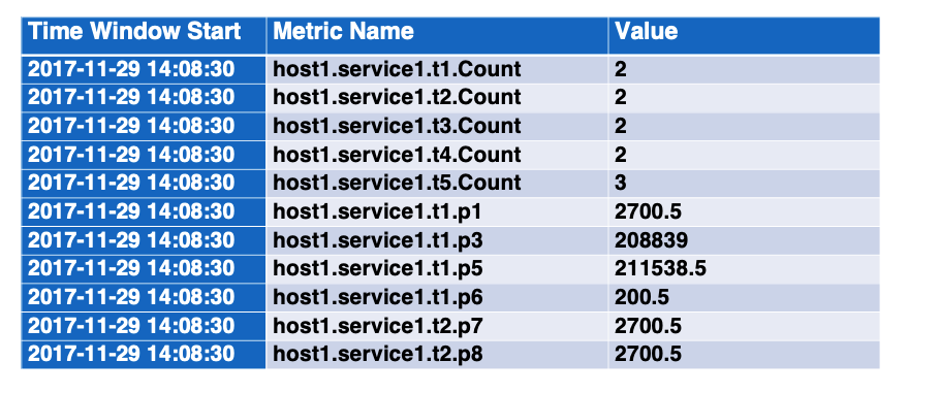
The outcome is multiple time-series, which can be used for anomaly detection.The result is multiple time series,可用于异常检测.
What’s next?接下来是什么?
Of course, not every anomaly is an outage or an incident. In a big data center, it is almost guaranteed that you will get a few anomalies every hour. Weighting and correlating multiple anomalies is a must in order to estimate when an alert is justified.当然,Not every exception is an outage or an accident.在大型数据中心,It is almost guaranteed that some anomalies will occur every hour.Weighting and correlating multiple anomalies is a must,to estimate when an alert is reasonable.
Drain3Introduction to the use of open source code
The following article is about open sourceDrain3Introduction to the use of code,使用方式,和流程
Introduction介绍
Drain3 is an online log template miner that can extract templates (clusters) from a stream of log messages in a timely manner. It employs a parse tree with fixed depth to guide the log group search process, which effectively avoids constructing a very deep and unbalanced tree.
Drain3Is an online journal template mining tools,Templates can be extracted in time from the log message stream(集群).It USES a fixed depth of parse tree to guide the search process log group,Effectively avoids very large construction depths、Unbalanced tree.
Drain3 continuously learns on-the-fly and extracts log templates from raw log entries.
Drain3Continuous dynamic learning,and extract the log template from the raw log entry.
Example:例子
For the input:
connected to 10.0.0.1
connected to 192.168.0.1
Hex number 0xDEADBEAF
user davidoh logged in
user eranr logged in
Drain3 extracts the following templates:
Drain3The following templates were extracted:
ID=1 : size=2 : connected to <:IP:>
ID=2 : size=1 : Hex number <:HEX:>
ID=3 : size=2 : user <:*:> logged in
Full sample program output:
Complete example program output:
Starting Drain3 template miner
Checking for saved state
Saved state not found
Drain3 started with 'FILE' persistence
Starting training mode. Reading from std-in ('q' to finish)
> connected to 10.0.0.1
Saving state of 1 clusters with 1 messages, 528 bytes, reason: cluster_created (1)
{"change_type": "cluster_created", "cluster_id": 1, "cluster_size": 1, "template_mined": "connected to <:IP:>", "cluster_count": 1}
Parameters: [ExtractedParameter(value='10.0.0.1', mask_name='IP')]
> connected to 192.168.0.1
{"change_type": "none", "cluster_id": 1, "cluster_size": 2, "template_mined": "connected to <:IP:>", "cluster_count": 1}
Parameters: [ExtractedParameter(value='192.168.0.1', mask_name='IP')]
> Hex number 0xDEADBEAF
Saving state of 2 clusters with 3 messages, 584 bytes, reason: cluster_created (2)
{"change_type": "cluster_created", "cluster_id": 2, "cluster_size": 1, "template_mined": "Hex number <:HEX:>", "cluster_count": 2}
Parameters: [ExtractedParameter(value='0xDEADBEAF', mask_name='HEX')]
> user davidoh logged in
Saving state of 3 clusters with 4 messages, 648 bytes, reason: cluster_created (3)
{"change_type": "cluster_created", "cluster_id": 3, "cluster_size": 1, "template_mined": "user davidoh logged in", "cluster_count": 3}
Parameters: []
> user eranr logged in
Saving state of 3 clusters with 5 messages, 644 bytes, reason: cluster_template_changed (3)
{"change_type": "cluster_template_changed", "cluster_id": 3, "cluster_size": 2, "template_mined": "user <:*:> logged in", "cluster_count": 3}
Parameters: [ExtractedParameter(value='eranr', mask_name='*')]
> q
Training done. Mined clusters:
ID=1 : size=2 : connected to <:IP:>
ID=2 : size=1 : Hex number <:HEX:>
ID=3 : size=2 : user <:*:> logged in
This project is an upgrade of the original Drain project by LogPAI from Python 2.7 to Python 3.6 or later with additional features and bug-fixes.
Read more information about Drain from the following paper:
Pinjia He, Jieming Zhu, Zibin Zheng, and Michael R. Lyu. Drain: An Online Log Parsing Approach with Fixed Depth Tree, Proceedings of the 24th International Conference on Web Services (ICWS), 2017.
(2017Analytical Methods for Start-ups at The Chinese University of Hong Kong,Paper and the principle of form.git项目地址:https://github.com/logpai/logparser)
A Drain3 use case is presented in this blog post: Use open source Drain3 log-template mining project to monitor for network outages .
(近年IBM团队基于2017年的工作,Further refactoring of the code,And add the corresponding design inside,For details, see the blog.)
New features 新特性
- Persistence. Save and load Drain state into an Apache Kafka topic, Redis or a file.
- Streaming. Support feeding Drain with messages one-be-one.
- Masking. Replace some message parts (e.g numbers, IPs, emails) with wildcards. This improves the accuracy of template mining.
- Packaging. As a pip package.
- Configuration. Support for configuring Drain3 using an
.inifile or a configuration object. - Memory efficiency. Decrease the memory footprint of internal data structures and introduce cache to control max memory consumed (thanks to @StanislawSwierc)
- Inference mode. In case you want to separate training and inference phase, Drain3 provides a function for fast matching against already-learned clusters (templates) only, without the usage of regular expressions.
- Parameter extraction. Accurate extraction of the variable parts from a log message as an ordered list, based on its mined template and the defined masking instructions (thanks to @Impelon).
略
Expected Input and Output expected input and output
Although Drain3 can be ingested with full raw log message, template mining accuracy can be improved if you feed it with only the unstructured free-text portion of log messages, by first removing structured parts like timestamp, hostname. severity, etc.
虽然Drain3Can absorb full raw log messages,But if only the unstructured free text portion of the log message is provided,It can improve the accuracy of template mining,First remove the structured part,如时间戳、主机名.severity, etc.
The output is a dictionary with the following fields:
输出是一个字典,包含以下字段:
change_type- indicates either if a new template was identified, an existing template was changed or message added to an existing cluster.Indicates if a new template is confirmed,An existing template was changed or a message was added to an existing cluster.cluster_id- Sequential ID of the cluster that the log belongs to.顺序的IDLogs belong to the cluster.cluster_size- The size (message count) of the cluster that the log belongs to.The size of the log by cluster(消息计数).cluster_count- Count clusters seen so far.cluster count.template_mined- the last template of above cluster_id.上面cluster_idthe last template.
Configuration配置
Drain3 is configured using configparser. By default, config filename is drain3.ini in working directory. It can also be configured passing a [TemplateMinerConfig] object to the [TemplateMiner]constructor.
使用[configparser]配置Drain3.默认情况下,工作目录下的config filename为’ drain3.ini '.It can also be done by adding a[TemplateMinerConfig]对象传递给[TemplateMiner]constructor to configure.
Primary configuration parameters:
主要配置参数:
[DRAIN]/sim_th- similarity threshold. if percentage of similar tokens for a log message is below this number, a new log cluster will be created (default 0.4)相似度阈值.If the percentage of similar tokens for log messages is below this number,will create a new log cluster(默认为0.4).[DRAIN]/depth- max depth levels of log clusters. Minimum is 2. (default 4)Maximum depth level for log clusters.最低是2.(默认4)[DRAIN]/max_children- max number of children of an internal node (default 100)The most architectural node number of internal nodes(默认100)[DRAIN]/max_clusters- max number of tracked clusters (unlimited by default). When this number is reached, model starts replacing old clusters with a new ones according to the LRU cache eviction policy.Maximum number of traceable clusters(默认无限制).当达到这个数量时,The model begins to be based onLRUCache eviction strategy replaces old clusters with new ones.[DRAIN]/extra_delimiters- delimiters to apply when splitting log message into words (in addition to whitespace) ( default none). Format is a Python list e.g.['_', ':'].Split log messages into words(除了空格)The delimiter to apply when (默认为无).Format是一个Python列表.['_', ':'].[MASKING]/masking- parameters masking - in json format (default “”) 参数屏蔽- json格式(默认"")[MASKING]/mask_prefix&[MASKING]/mask_suffix- the wrapping of identified parameters in templates. By default, it is<and>respectively. Wrap an identified parameter in a template.默认情况下,分别为’ < ‘和’ > '.[SNAPSHOT]/snapshot_interval_minutes- time interval for new snapshots (default 1) time interval for new snapshots (default 1)[SNAPSHOT]/compress_state- whether to compress the state before saving it. This can be useful when using Kafka persistence.Whether to compress the state before saving.这在使用KafkaVery useful for persistence.
Masking屏蔽(掩码)
This feature allows masking of specific variable parts in log message with keywords, prior to passing to Drain. A well-defined masking can improve template mining accuracy.This feature allows passing toDrain之前,Mask specific variable parts in log messages with keywords.Well-defined masks can improve the accuracy of template mining.
Template parameters that do not match any custom mask in the preliminary masking phase are replaced with <*> by Drain core.Template parameters that do not match any custom mask at the initial mask stage will beDrain core替换为’ <*> '.
Use a list of regular expressions in the configuration file with the format {'regex_pattern', 'mask_with'} to set custom masking.
For example, following masking instructions in drain3.ini will mask IP addresses and integers:
Use the format in the configuration file as’ {‘regex_pattern’, ‘mask_with’} 'A list of regular expressions to set custom masks.
[MASKING]
masking = [
{"regex_pattern":"((?<=[^A-Za-z0-9])|^)(\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3})((?=[^A-Za-z0-9])|$)", "mask_with": "IP"},
{"regex_pattern":"((?<=[^A-Za-z0-9])|^)([\\-\\+]?\\d+)((?=[^A-Za-z0-9])|$)", "mask_with": "NUM"},
]
]
Persistence持久化特性
The persistence feature saves and loads a snapshot of Drain3 state in a (compressed) json format. This feature adds restart resiliency to Drain allowing continuation of activity and maintain learned knowledge across restarts.Persistence features start with (压缩)jsonFormat save and loadDrain3状态的快照.该特性为DrainAdded restart resilience,Allow activity to continue,and maintain what has been learned across reboots.
Drain3 state includes the search tree and all the clusters that were identified up until snapshot time.Drain3Status includes search tree and all clusters identified before snapshot time.
The snapshot also persist number of log messages matched each cluster, and it’s cluster_id.The snapshot also saves the number of log messages matching each cluster,它是’ cluster_id '.
An example of a snapshot:
快照示例:
{
"clusters": [
{
"cluster_id": 1,
"log_template_tokens": [
"aa",
"aa",
"<*>"
],
"py/object": "drain3_core.LogCluster",
"size": 2
},
{
"cluster_id": 2,
"log_template_tokens": [
"My",
"IP",
"is",
"<IP>"
],
"py/object": "drain3_core.LogCluster",
"size": 1
}
]
}
This example snapshot persist two clusters with the templates:This example snapshot uses a template to persist two clusters:
["aa", "aa", "<*>"] - occurs twice发生两次
["My", "IP", "is", "<IP>"] - occurs once发生一次
Snapshots are created in the following events:Snapshots are created in the following events:
cluster_created- in any new templatein any new templatecluster_template_changed- in any update of a templatein any update of the templateperiodic- after n minutes from the last snapshot. This is intended to save cluster sizes even if no new template was identified.距离上次快照n分钟后.This is to save the cluster size,Even if no new templates are found.
Drain3 currently supports the following persistence modes:目前,Drain3The following persistence modes are supported:
- Kafka - The snapshot is saved in a dedicated topic used only for snapshots - the last message in this topic is the last snapshot that will be loaded after restart. For Kafka persistence, you need to provide:
topic_name. You may also provide otherkwargsthat are supported bykafka.KafkaConsumerandkafka.Producere.gbootstrap_serversto change Kafka endpoint (default islocalhost:9092).Snapshots are kept in a dedicated topic just for snapshots-The last message in the thread is the last snapshot that will be loaded after reboot.对于Kafka持久性,你需要提供:’ topic_name ‘.You can also provide otherkafka支持的’ kwargs '.kafka.KafkaConsumer和kafka.Producer例如bootstrap_servers来改变Kafka端点(default islocalhost:9092). - Redis - The snapshot is saved to a key in Redis database (contributed by @matabares).Snapshots are saved toRedisa key in the database(由@matabares贡献).
- File - The snapshot is saved to a file.将快照保存到文件中.
- Memory - The snapshot is saved an in-memory object.Snapshots are kept in memory objects.
- None - No persistence.没有持久性.
Drain3 persistence modes can be easily extended to another medium / database by inheriting the [PersistenceHandler] class.通过继承“PersistenceHandler”类,可以很容易地将Drain3Persistence mode extends to another qualitative/数据库.
Training vs. Inference modes训练模式vs.推理模式
In some use-cases, it is required to separate training and inference phases.在某些用例中,Need to separate training and inference phases.
In training phase you should call template_miner.add_log_message(log_line). This will match log line against an existing cluster (if similarity is above threshold) or create a new cluster. It may also change the template of an existing cluster.在训练阶段,你应该调用’ template_miner.add_log_message(log_line) '.This will match log lines with existing clusters(If the similarity is above the threshold)or create a new cluster.It may also change the template of an existing cluster.
In inference mode you should call template_miner.match(log_line). This will match log line against previously learned clusters only. No new clusters are created and templates of existing clusters are not changed. Match to existing cluster has to be perfect, otherwise None is returned. You can use persistence option to load previously trained clusters before inference.在推断模式下,你应该调用’ template_miner.match(log_line) ‘.This will only match log lines with previously learned clusters.No new cluster will be created,also does not change the template of an existing cluster.The match with the existing cluster must be perfect,否则返回’ None '.Can use persistence options before that trained the cluster before loading.
Memory efficiency内存效率
This feature limits the max memory used by the model. It is particularly important for large and possibly unbounded log streams. This feature is controlled by the max_clusters parameter, which sets the max number of clusters/templates trarcked by the model. When the limit is reached, new templates start to replace the old ones according to the Least Recently Used (LRU) eviction policy. This makes the model adapt quickly to the most recent templates in the log stream.This feature limits the maximum memory used by the model.For large and possibly unbounded log streams,这一点尤为重要.这个特性是由“max_clusters”参数控制的,It sets the cluster that the model tracks/Maximum number of templates.当达到限制时,根据LRU (Least Recently Used)策略,The new template starts replacing the old one.This enables the model to quickly adapt to the latest templates in the log stream.
Parameter Extraction参数提取
Drain3 supports retrieving an ordered list of variables in a log message, after its template was mined. Each parameter is accompanied by the name of the mask that was matched, or * for the catch-all mask.After digging through the template for log messages,Drain3Support for retrieving an ordered list of variables in log messages.Each parameter is accompanied by the name of the matching mask,或“*”means capture all masks.
Parameter extraction is performed by generating a regular expression that matches the template and then applying it on the log message. When exact_matching is enabled (by default), the generated regex included the regular expression defined in relevant masking instructions. If there are multiple masking instructions with the same name, either match can satisfy the regex. It is possible to disable exact matching so that every variable is matched against a non-whitespace character sequence. This may improve performance on expanse of accuracy.The method of parameter extraction is to generate a regular expression that matches the template,and then applied to log messages.当启用’ exact_matching '时(默认情况下),The generated regular expression contains the regular expression defined in the relevant masking directive.If there are multiple masked directives with the same name,Any match can satisfy the regular expression.Exact match can be disabled,so that each variable is matched against sequences of non-whitespace characters.This may improve the performance of the accuracy extension.
Parameter extraction regexes generated per template are cached by default, to improve performance. You can control cache size with the MASKING/parameter_extraction_cache_capacity configuration parameter.默认情况下,The parameter extraction regular expressions generated by each template are cached,以提高性能.你可以通过“MASKING/parameter_extraction_cache_capacity”Configuration parameters to control cache size.
Sample usage:示例使用
result = template_miner.add_log_message(log_line)
params = template_miner.extract_parameters(
result["template_mined"], log_line, exact_matching=True)
For the input "user johndoe logged in 11 minuts ago", the template would be:对于输入“user johndoe logged in 11 minutes ago”,Template will be:
"user <:*:> logged in <:NUM:> minuts ago"
… and the extracted parameters:and the extracted parameters:
[
ExtractedParameter(value='johndoe', mask_name='*'),
ExtractedParameter(value='11', mask_name='NUM')
]
Installation安装
Drain3 is available from PyPI. To install use pip:Drain3可以从PyPI获取.要安装使用’ pip ':
pip3 install drain3
Note: If you decide to use Kafka or Redis persistence, you should install relevant client library explicitly, since it is declared as an extra (optional) dependency, by either:注意:如果你决定使用Kafka或Redis持久化,You should explicitly install the relevant client library,because it is declared as an extra(可选的)依赖,通过:
pip3 install kafka-python
– or –
pip3 install redis
Examples例子
In order to run the examples directly from the repository, you need to install dependencies. You can do that using * pipenv* by executing the following command (assuming pipenv already installed):In order to run the example directly from the repository,you need to install dependencies.You can use it by executing the following command* pipenv*(假设pipenv已经安装):
(或者使用pip 安装requirements.txt中的包)
python3 -m pipenv sync
Example 1 - drain_stdin_demo示例1 - ’ drain_stdin_demo ’
Run [examples/drain_stdin_demo.py] from the root folder of the repository by:Execute in the root directory of the repositoryexamples/drain_stdin_demo.py命令:
python3 -m pipenv run python -m examples.drain_stdin_demo
This example uses Drain3 on input from stdin and persist to either Kafka / file / no persistence.This example usesstdin输入的Drain3,并持久化到Kafka / file /无持久化.
Change persistence_type variable in the example to change persistence mode.改变“persistence_type”Example of a variable in persistence mode.
Enter several log lines using the command line. Press q to end online learn-and-match mode.Enter a few log lines using the command line.按“q”end onlinelearn-and-match模式.
Next, demo goes to match (inference) only mode, in which no new clusters are trained and input is matched against previously trained clusters only. Press q again to finish execution.接下来,Demo entry matches only(推断)模式,Do not train new clusters in this mode,Input only matches previously trained clusters.再次按“q”完成执行.
Example 2 - drain_bigfile_demo例子2 -“drain_bigfile_demo”
Run [examples/drain_bigfile_demo] from the root folder of the repository by:运行drain_bigfile_demofrom the root folder of the repository:
python3 -m pipenv run python -m examples.drain_bigfile_demo
This example downloads a real-world log file (of an SSH server) and process all lines, then prints result clusters, prefix tree and performance statistics.This example downloads a real log file(SSH服务器的)and process all rows,then print the resulting cluster、Prefix trees and performance statistics.
Sample config file样例配置文件
An example drain3.ini file with masking instructions can be found in the [examples]folder as well.one with masking instructions’ Drain3 .ini 'File examples can be found atexamples文件夹中找到.
Contributing贡献
Our project welcomes external contributions. Please refer to [CONTRIBUTING.md] for further details.We welcome the external donations.请参阅[CONTRIBUTING.md]了解更多细节.
边栏推荐
- UE4 在游戏运行时更改变量 (通过鼠标滑轮来更改第一人称角色的最大行走速度)
- [Solved] Unity Coroutine coroutine is not executed effectively
- 十五. 实战——mysql建库建表 字符集 和 排序规则
- Increasing leetcode - a daily topic 1403. The order of the boy sequence (greed)
- The second council meeting of the Dragon Lizard Community was successfully held!Director general election, 4 special consultants joined
- ASP.NET应用程序--Hello World
- GC Gaode coordinate and Baidu coordinate conversion
- 从企业的视角来看,数据中台到底意味着什么?
- ffmpeg pixel format basics
- 调用阿里云oss和sms服务
猜你喜欢

如何在WordPress中添加特定类别的小工具
36-Jenkins-Job Migration

Index Mysql in order to optimize paper 02 】 【 10 kinds of circumstances and the principle of failure
YYGH-13-客服中心
【已解决】Unity Coroutinue 协程未有效执行的问题
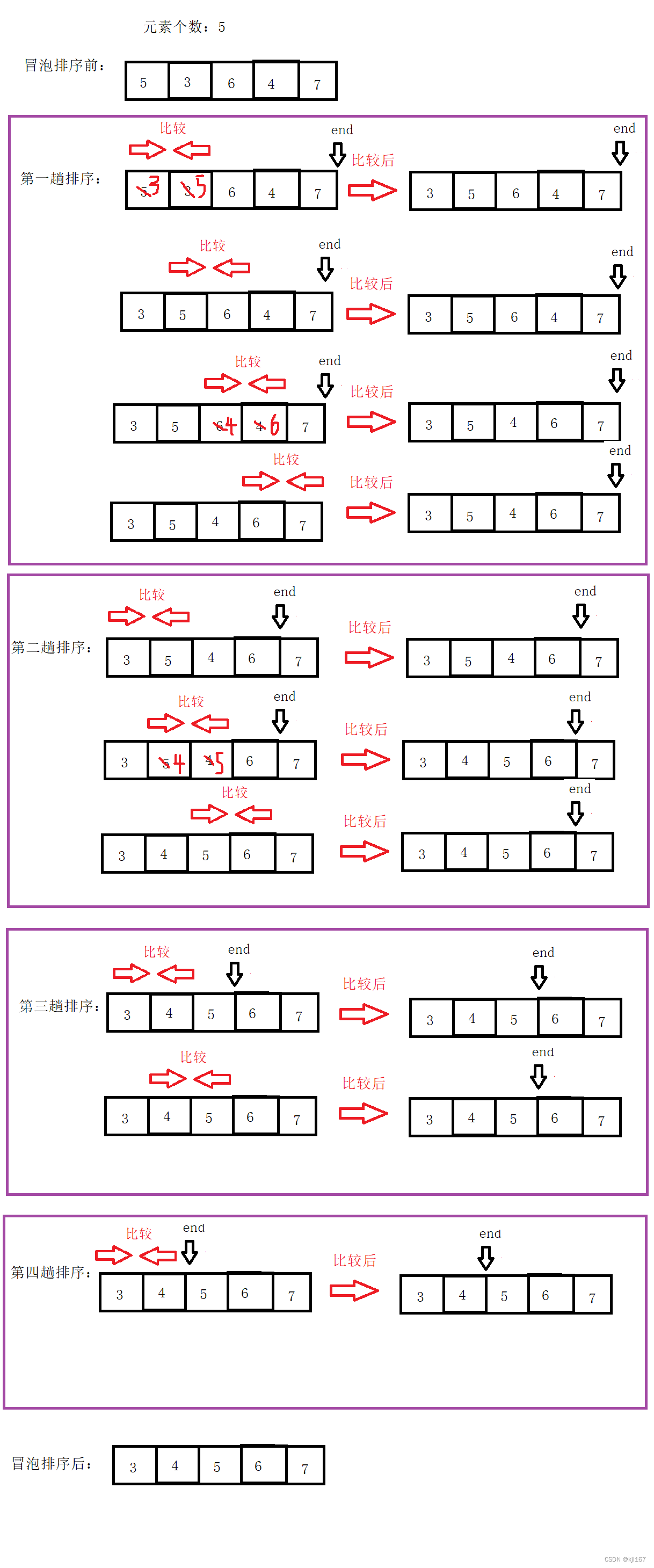
Bubble Sort and Quick Sort
UE4 opens doors with overlapping events
2022-08-04 The sixth group, hidden from spring, study notes
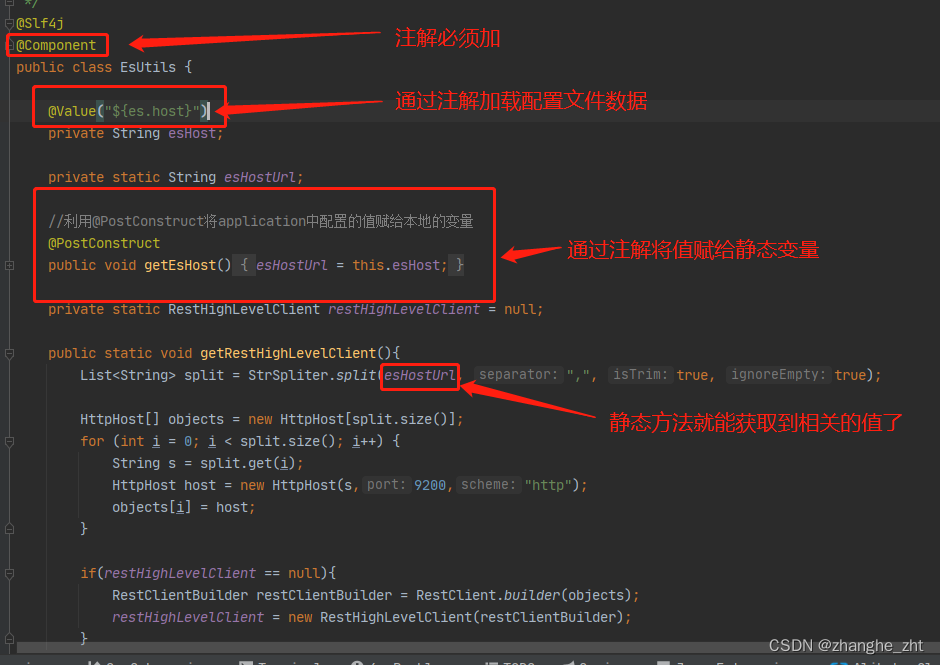
静态方法获取配置文件数据

MySql的索引学习和使用;(本人觉得足够详细)
随机推荐
用CH341A烧录外挂Flash (W25Q16JV)
IJCAI2022 | DictBert: Pre-trained Language Models with Contrastive Learning for Dictionary Description Knowledge Augmentation
token、jwt、oauth2、session解析
markdown如何换行——md文件
Ali's local life's single-quarter revenue is 10.6 billion, Da Wenyu's revenue is 7.2 billion, and Cainiao's revenue is 12.1 billion
高项 02 信息系统项目管理基础
leetcode-每日一题1403. 非递增顺序的最小子序列(贪心)
21 Days Learning Challenge (2) Use of Graphical Device Trees
GC Gaode coordinate and Baidu coordinate conversion
测试薪资这么高?刚毕业就20K
如何在WordPress中添加特定类别的小工具
High Item 02 Information System Project Management Fundamentals
.NET应用程序--Helloworld(C#)
cross domain solution
YYGH-13-Customer Service Center
Spark Basics [Introduction, Getting Started with WordCount Cases]
DEJA_VU3D - Cesium功能集 之 058-高德地图纠偏
调用阿里云oss和sms服务
Acid (ACID) Base (BASE) Principles for Database Design
presto启动成功后出现2022-08-04T17:50:58.296+0800 ERROR Announcer-3 io.airlift.discovery.client.Announcer