当前位置:网站首页>Interpretation of Flink source code (I): Interpretation of streamgraph source code
Interpretation of Flink source code (I): Interpretation of streamgraph source code
2022-07-06 17:28:00 【Stray_ Lambs】
Catalog
Flink Basic concepts of flow graph
StreamNode and StreamEdge The relationship between
Flink Basic concepts of flow graph
Here is a brief introduction Flink Some basic concepts and processes of flow graph , Details can be found in Flink Basic concepts . According to the generation order of different graphs , Mainly divided into 4 layer :StreamGraph-->JobGraph-->ExecutionGraph--> Physical execution diagram . The specific steps are as follows :
- Client Generate the application code of the job StreamGraph( What is generated in batch mode is OptimizedPlan).StreamGraph Is a data structure that represents the topology of a stream handler , Describe the logical topological relationship between operators , It encapsulates the generation job graph (JobGraph) The necessary information .
- take StreamGraph Convert to JobGraph.JobGraph Express JobManager Acceptable low level Flink Data flow program . All from higher levels API All programs are converted into JobGraph.JobGraph Is a graph of vertices and intermediate results , These vertices are connected with the intermediate result to form a DAG.JobGraph Configuration information that defines the scope of work , and Each vertex and intermediate result defines the characteristics of specific operations and intermediate data .
- take JobGraph Submit to Dispatcher.Dispatcher The component is responsible for receiving job submissions 、 Resume work in case of failure 、 monitor Flink The status of the session cluster .
- Dispatcher according to JobGraph Create the corresponding JobManager And run .
- JobManager take JobGraph Convert to ExecutionGraph.ExecutionGraph It is the central data structure to coordinate the distributed execution of data flow , It preserves each parallel task 、 Each intermediate flow and the communication information between them .
- JobManager take ExecutionGraph Convert to physical execution diagram .
StreamGraph Source code
StreamGraph As Flink The logic encapsulation of the top layer can be understood as user API The logic layer of transformation , It is mainly written by users Transformation convert to StreamNode And generate upstream and downstream StreamEdge And load into StreamGraph. Next, we will focus on Yarn Pattern as an example .
StreamGraph Core objects of
StreamNode and StreamEdge yes StreamGraph Core data structure object .
StreamNode
StreamNode yes StreamGraph The nodes in the , That is to say Operators in stream programs . One StreamNode Represents an operator , even Source and Sink Also with StreamNode Express , Just because it means input and output, it has a specific name .StreamNode Encapsulates other key attributes of the operator , For example, its parallelism 、 Zone information 、 Serializers of input and output types, etc .
and StreamNode It is divided into entity and virtual . because StreamNode It is transformed , But not all conversion operations have practical physical meaning ( That is, physically corresponding to specific operators ), such as Partition (Partition)、 Division / choice (Select) And merge (Union) Not in StreamGraph Create actual nodes in , Instead, create virtual nodes , This node contains specific attributes . fictitious StreamNode The information of the node will not be StreamGraph It shows that , Instead, it is stored in the corresponding conversion edge (StreamEdge) On .
StreamEdge
StreamEdge Used to connect two StreamNode, One StreamNode There can be multiple entry edges 、 Out of the way .StreamEdge The partition is stored in 、 Bypass output and other information .
StreamNode and StreamEdge The relationship between
StreamEdge contain Source StreamNode( Use sourceVertex Attribute representation ) And purpose StreamNode( Use targetVertex Attribute representation ).StreamNode The in edge set and out edge set connected to it are stored in , use inEdges and outEdges Express .
StreamNode Source code :
/**
* Class representing the operators in the streaming programs, with all their properties.
*/
@Internal
public class StreamNode {
private final int id;
private int parallelism;
/**
* Maximum parallelism for this stream node. The maximum parallelism is the upper limit for
* dynamic scaling and the number of key groups used for partitioned state.
*/
private int maxParallelism;
private ResourceSpec minResources = ResourceSpec.DEFAULT;
private ResourceSpec preferredResources = ResourceSpec.DEFAULT;
private final Map<ManagedMemoryUseCase, Integer> managedMemoryOperatorScopeUseCaseWeights = new HashMap<>();
private final Set<ManagedMemoryUseCase> managedMemorySlotScopeUseCases = new HashSet<>();
private long bufferTimeout;
private final String operatorName;
private @Nullable String slotSharingGroup;
private @Nullable String coLocationGroup;
private KeySelector<?, ?>[] statePartitioners = new KeySelector[0];
private TypeSerializer<?> stateKeySerializer;
private StreamOperatorFactory<?> operatorFactory;
private TypeSerializer<?>[] typeSerializersIn = new TypeSerializer[0];
private TypeSerializer<?> typeSerializerOut;
// In edge set and out edge set
private List<StreamEdge> inEdges = new ArrayList<StreamEdge>();
private List<StreamEdge> outEdges = new ArrayList<StreamEdge>();
private final Class<? extends AbstractInvokable> jobVertexClass;
private InputFormat<?, ?> inputFormat;
private OutputFormat<?> outputFormat;
private String transformationUID;
private String userHash;
private boolean sortedInputs = false;
.....
// to StreamNode Add in and out edges , That is to say, set directly on the in side and out side add
public void addInEdge(StreamEdge inEdge) {
if (inEdge.getTargetId() != getId()) {
throw new IllegalArgumentException("Destination id doesn't match the StreamNode id");
} else {
inEdges.add(inEdge);
}
}
public void addOutEdge(StreamEdge outEdge) {
if (outEdge.getSourceId() != getId()) {
throw new IllegalArgumentException("Source id doesn't match the StreamNode id");
} else {
outEdges.add(outEdge);
}
}
....
}StreamEdge Source code :
/**
* An edge in the streaming topology. One edge like this does not necessarily
* gets converted to a connection between two job vertices (due to
* chaining/optimization).
*/
@Internal
public class StreamEdge implements Serializable {
private static final long serialVersionUID = 1L;
private static final long ALWAYS_FLUSH_BUFFER_TIMEOUT = 0L;
private final String edgeId;
// Source and destination nodes
private final int sourceId;
private final int targetId;
/**
* The type number of the input for co-tasks.
*/
private final int typeNumber;
/**
* The side-output tag (if any) of this {@link StreamEdge}.
*/
// Side output stream label
private final OutputTag outputTag;
/**
* The {@link StreamPartitioner} on this {@link StreamEdge}.
*/
// Comparator
private StreamPartitioner<?> outputPartitioner;
/**
* The name of the operator in the source vertex.
*/
private final String sourceOperatorName;
/**
* The name of the operator in the target vertex.
*/
private final String targetOperatorName;
// shuffle Patterns define how data is exchanged between operators
private final ShuffleMode shuffleMode;
private long bufferTimeout;
public StreamEdge(
StreamNode sourceVertex,
StreamNode targetVertex,
int typeNumber,
long bufferTimeout,
StreamPartitioner<?> outputPartitioner,
OutputTag outputTag,
ShuffleMode shuffleMode) {
this.sourceId = sourceVertex.getId();
this.targetId = targetVertex.getId();
this.typeNumber = typeNumber;
this.bufferTimeout = bufferTimeout;
this.outputPartitioner = outputPartitioner;
this.outputTag = outputTag;
this.sourceOperatorName = sourceVertex.getOperatorName();
this.targetOperatorName = targetVertex.getOperatorName();
this.shuffleMode = checkNotNull(shuffleMode);
this.edgeId = sourceVertex + "_" + targetVertex + "_" + typeNumber + "_" + outputPartitioner;
}
}Upload jar package
When the client submit Script upload jar After the package , from Flink Get the jar package , And invoke the user's... Through reflection main function .
// There are many processes , I try to write in detail ……
// Mainly submission function ,CliFrontend It is the entry of program submission , The key method is cli.parseAndRun(args)
public static void main(final String[] args) {
EnvironmentInformation.logEnvironmentInfo(LOG, "Command Line Client", args);
// 1. find the configuration directory
// 1. Get configuration conf Catalog : /opt/tools/flink-1.12.2/conf
final String configurationDirectory = getConfigurationDirectoryFromEnv();
// 2. load the global configuration
// 2. Load global conf To configure :
// "taskmanager.memory.process.size" -> "1728m"
// "parallelism.default" -> "1"
// "jobmanager.execution.failover-strategy" -> "region"
// "jobmanager.rpc.address" -> "localhost"
// "taskmanager.numberOfTaskSlots" -> "1"
// "jobmanager.memory.process.size" -> "1600m"
// "jobmanager.rpc.port" -> "6123"
final Configuration configuration =
GlobalConfiguration.loadConfiguration(configurationDirectory);
// 3. load the custom command lines
// 3. Load custom parameters
final List<CustomCommandLine> customCommandLines =
loadCustomCommandLines(configuration, configurationDirectory);
try {
// structure CliFrontend : GenericCLI > flinkYarnSessionCLI > DefaultCLI
final CliFrontend cli = new CliFrontend(configuration, customCommandLines);
SecurityUtils.install(new SecurityConfiguration(cli.configuration));
// Use parseAndRun Submit instructions
int retCode = SecurityUtils.getInstalledContext().runSecured(() -> cli.parseAndRun(args));
System.exit(retCode);
} catch (Throwable t) {
final Throwable strippedThrowable =
ExceptionUtils.stripException(t, UndeclaredThrowableException.class);
LOG.error("Fatal error while running command line interface.", strippedThrowable);
strippedThrowable.printStackTrace();
System.exit(31);
}
}
// After the parseAndRun(args) This function , Different methods will be called according to different commands requested , for example run,stop wait
// Supported commands
/**
*
* // actions
* private static final String ACTION_RUN = "run";
* private static final String ACTION_RUN_APPLICATION = "run-application";
* private static final String ACTION_INFO = "info";
* private static final String ACTION_LIST = "list";
* private static final String ACTION_CANCEL = "cancel";
* private static final String ACTION_STOP = "stop";
* private static final String ACTION_SAVEPOINT = "savepoint";
*/
// Because we are submitting job, So the call is CliFrontend.run function
// In this function, it is mainly to determine the execution Flink Methods / Environmental Science / Program and other information ,
// adopt CliFrontend.executeProgram(effectiveConfiguration, program)
// And then leave it to ClientUtils Tool class submits task
protected void executeProgram(final Configuration configuration, final PackagedProgram program)
throws ProgramInvocationException {
ClientUtils.executeProgram(
new DefaultExecutorServiceLoader(), configuration, program, false, false);
}
// from ClientUtils.executeProgram( The name of the previous method is the same , It's just different ), Build the execution environment of the program / Class loader , Start preparing to execute ...
// Execute program code
public static void executeProgram(
PipelineExecutorServiceLoader executorServiceLoader,
Configuration configuration,
PackagedProgram program,
boolean enforceSingleJobExecution,
boolean suppressSysout)
throws ProgramInvocationException {
checkNotNull(executorServiceLoader);
// Get the loader of the user . : [email protected]
final ClassLoader userCodeClassLoader = program.getUserCodeClassLoader();
// Cache the current class loader ...
final ClassLoader contextClassLoader = Thread.currentThread().getContextClassLoader();
try {
// Set the class loader to the class loader specified by the user ..
Thread.currentThread().setContextClassLoader(userCodeClassLoader);
//log info : Starting program (detached: false)
LOG.info(
"Starting program (detached: {})",
!configuration.getBoolean(DeploymentOptions.ATTACHED));
// Get the environment in the user code ....
// getExecutionEnvironment
ContextEnvironment.setAsContext(
executorServiceLoader,
configuration,
userCodeClassLoader,
enforceSingleJobExecution,
suppressSysout);
StreamContextEnvironment.setAsContext(
executorServiceLoader,
configuration,
userCodeClassLoader,
enforceSingleJobExecution,
suppressSysout);
try {
// By way of reflection , Call the... Of the user program mian Method ...
program.invokeInteractiveModeForExecution();
} finally {
ContextEnvironment.unsetAsContext();
StreamContextEnvironment.unsetAsContext();
}
} finally {
Thread.currentThread().setContextClassLoader(contextClassLoader);
}
}
// Last, last , adopt PackagedProgram.invokeInteractiveModeForExecution
// Here is by calling the underlying callMainMethod Method , Call through reflection main Method .
//mainMethod.invoke(null, (Object) args) This is where the final implementation begins .
/**
* This method assumes that the context environment is prepared, or the execution will be a
* local execution by default.
*/
public void invokeInteractiveModeForExecution() throws ProgramInvocationException {
// mainClass: class org.apache.flink.streaming.examples.socket.SocketWindowWordCount
// args
// 0 = "--port"
// 1 = "9999"
callMainMethod(mainClass, args);
}
// class org.apache.flink.streaming.examples.socket.SocketWindowWordCount args : --port 9999
private static void callMainMethod(Class<?> entryClass, String[] args)
throws ProgramInvocationException {
Method mainMethod;
if (!Modifier.isPublic(entryClass.getModifiers())) {
throw new ProgramInvocationException(
"The class " + entryClass.getName() + " must be public.");
}
// public static void org.apache.flink.streaming.examples.socket.SocketWindowWordCount.main(java.lang.String[]) throws java.lang.Exception
try {
mainMethod = entryClass.getMethod("main", String[].class);
} catch (NoSuchMethodException e) {
throw new ProgramInvocationException(
"The class " + entryClass.getName() + " has no main(String[]) method.");
} catch (Throwable t) {
throw new ProgramInvocationException(
"Could not look up the main(String[]) method from the class "
+ entryClass.getName()
+ ": "
+ t.getMessage(),
t);
}
if (!Modifier.isStatic(mainMethod.getModifiers())) {
throw new ProgramInvocationException(
"The class " + entryClass.getName() + " declares a non-static main method.");
}
if (!Modifier.isPublic(mainMethod.getModifiers())) {
throw new ProgramInvocationException(
"The class " + entryClass.getName() + " declares a non-public main method.");
}
// Start execution !!!!!!!!!
try {
mainMethod.invoke(null, (Object) args);
} catch (IllegalArgumentException e) {
throw new ProgramInvocationException(
"Could not invoke the main method, arguments are not matching.", e);
} catch (IllegalAccessException e) {
throw new ProgramInvocationException(
"Access to the main method was denied: " + e.getMessage(), e);
} catch (InvocationTargetException e) {
Throwable exceptionInMethod = e.getTargetException();
if (exceptionInMethod instanceof Error) {
throw (Error) exceptionInMethod;
} else if (exceptionInMethod instanceof ProgramParametrizationException) {
throw (ProgramParametrizationException) exceptionInMethod;
} else if (exceptionInMethod instanceof ProgramInvocationException) {
throw (ProgramInvocationException) exceptionInMethod;
} else {
throw new ProgramInvocationException(
"The main method caused an error: " + exceptionInMethod.getMessage(),
exceptionInMethod);
}
} catch (Throwable t) {
throw new ProgramInvocationException(
"An error occurred while invoking the program's main method: " + t.getMessage(),
t);
}
}
When mainMethod.invoke At the beginning of execution , each operator I'm going to generate the corresponding Transformation And so on , Until it runs to StreamExecutionEnvironment.execute() after , Just started lazy execution . Be similar to Spark Medium action operator , Just start to really execute the code .
Generate StreamGraph
// call getStreamGraph function
public JobExecutionResult execute(String jobName) throws Exception {
Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");
// Generate StreamGraph
return execute(getStreamGraph(jobName));
}
// This is mainly to generate StreamGraph, It uses StreamGraphGenerator.generate function
/**
* Getter of the {@link org.apache.flink.streaming.api.graph.StreamGraph} of the streaming job. This call
* clears previously registered {@link Transformation transformations}.
*
* @param jobName Desired name of the job
* @return The streamgraph representing the transformations
*/
@Internal
public StreamGraph getStreamGraph(String jobName) {
return getStreamGraph(jobName, true);
}
/**
* Getter of the {@link org.apache.flink.streaming.api.graph.StreamGraph StreamGraph} of the streaming job
* with the option to clear previously registered {@link Transformation transformations}. Clearing the
* transformations allows, for example, to not re-execute the same operations when calling
* {@link #execute()} multiple times.
*
* @param jobName Desired name of the job
* @param clearTransformations Whether or not to clear previously registered transformations
* @return The streamgraph representing the transformations
*/
@Internal
public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) {
StreamGraph streamGraph = getStreamGraphGenerator().setJobName(jobName).generate();
if (clearTransformations) {
this.transformations.clear();
}
return streamGraph;
}
public StreamGraph generate() {
// Generate StreamGraph example
streamGraph = new StreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings);
// Determine the execution mode
shouldExecuteInBatchMode = shouldExecuteInBatchMode(runtimeExecutionMode);
// To configure StreamGraph
configureStreamGraph(streamGraph);
alreadyTransformed = new HashMap<>();
// Traverse all transformations
for (Transformation<?> transformation: transformations) {
// Generate streamNode and streamEdge
transform(transformation);
}
.........
}
// Finally, according to transform(transformtaion), Generate StreamGraph
// among transform The function will be called translateInternal Generate instances . In subsequent versions, it is in transformFeedback Function , call addEdge Function StreamEdges Link to
private Collection<Integer> translateInternal(
final OneInputTransformation<IN, OUT> transformation,
final Context context) {
checkNotNull(transformation);
checkNotNull(context);
final StreamGraph streamGraph = context.getStreamGraph();
final String slotSharingGroup = context.getSlotSharingGroup();
final int transformationId = transformation.getId();
final ExecutionConfig executionConfig = streamGraph.getExecutionConfig();
// Generate StreamNode, To add to StreamGraph Of streamNodesMap in
streamGraph.addOperator(
transformationId,
slotSharingGroup,
transformation.getCoLocationGroupKey(),
transformation.getOperatorFactory(),
transformation.getInputType(),
transformation.getOutputType(),
transformation.getName());
.......
for (Integer inputId: context.getStreamNodeIds(parentTransformations.get(0))) {
// Generate Edge And put the edge Add to your upstream and downstream streamNode in
streamGraph.addEdge(inputId, transformationId, 0);
}
}
Here's an explanation , It's generating StreamGraph When , Among them is transformation Parameters , This parameter is mainly in StreamGraphGenerator.generate(this, transformations) When it is delivered . It's through protected final List<StreamTransformation<?>> transformations = new ArrayList<>(); produce . every last operator Operators will correspond to one OutputStreamOperator, And then call it in the function. transform function , And carry out addOperator(resultTransform), Add operators to transformation Complete the assignment .
public <R> SingleOutputStreamOperator<R> transform(String operatorName, TypeInformation<R> outTypeInfo, OneInputStreamOperator<T, R> operator) {
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operator,
outTypeInfo,
environment.getParallelism());
...
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
Generate StreamNode
public <IN, OUT> void addOperator(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
StreamOperatorFactory<OUT> operatorFactory,
TypeInformation<IN> inTypeInfo,
TypeInformation<OUT> outTypeInfo,
String operatorName) {
// Later, production Task Time is through this Class To reflect calling the constructor with parameters to initialize Task
// such as Map Function corresponding OneInputStreamTask.class
Class<? extends AbstractInvokable> invokableClass =
operatorFactory.isStreamSource() ? SourceStreamTask.class : OneInputStreamTask.class;
addOperator(vertexID, slotSharingGroup, coLocationGroup, operatorFactory, inTypeInfo,
outTypeInfo, operatorName, invokableClass);
}
protected StreamNode addNode(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
Class<? extends AbstractInvokable> vertexClass,
StreamOperatorFactory<?> operatorFactory,
String operatorName) {
if (streamNodes.containsKey(vertexID)) {
throw new RuntimeException("Duplicate vertexID " + vertexID);
}
// Generate StreamNode Core Data :slotSharingGroup,operatorFactory( Commonly used user self-defined operators SimpleUdfStreamOperatorFactory etc. ,
// It encapsulates the user's userFunction)
StreamNode vertex = new StreamNode(
vertexID,
slotSharingGroup,
coLocationGroup,
operatorFactory,
operatorName,
vertexClass);
streamNodes.put(vertexID, vertex);
.....
}Generate Edge
private void addEdgeInternal(Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
List<String> outputNames,
OutputTag outputTag,
ShuffleMode shuffleMode) {
// If it is sideout Type of transformation, Use upstream transformationId Continue to call addEdgeInternal
if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0;
//outputTag Identify a sideout flow
if (outputTag == null) {
outputTag = virtualSideOutputNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, null, outputTag, shuffleMode);
//partition Type of transformation ditto
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
shuffleMode = virtualPartitionNodes.get(virtualId).f2;
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag, shuffleMode);
} else {
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
// If no partitioner was specified and the parallelism of upstream and downstream
// operator matches use forward partitioning, use rebalance otherwise.
// The partition is determined by whether the parallelism of upstream and downstream is consistent
// here ForwardPartitioner And RebalancePartitioner The difference between etc. is mainly reflected in selectChannel,
// The former directly returns to the current channel Of index 0 The latter is the current Channel The number is random +1 Right again Channel Take the remainder of the number ( Others partitioner Also realize different selectChannel)
if (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner<Object>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
if (partitioner instanceof ForwardPartitioner) {
if (upstreamNode.getParallelism() != downstreamNode.getParallelism()) {
throw new UnsupportedOperationException("Forward partitioning does not allow " +
"change of parallelism. Upstream operation: " + upstreamNode + " parallelism: " + upstreamNode.getParallelism() +
", downstream operation: " + downstreamNode + " parallelism: " + downstreamNode.getParallelism() +
" You must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");
}
}
// decision Operator Is it possible chain(!=batch) as well as ResultPartitionType The type of
// Usually transformation Of shuffleMode = UNDEFINED( Include partition Type of transformation)
// here ResultPartitionType The type of will be determined by GlobalDataExchangeMode decision ( Not batch In mode =ALL_EDGES_PIPELINED->ResultPartitionType=PIPELINED_BOUNDED)
if (shuffleMode == null) {
shuffleMode = ShuffleMode.UNDEFINED;
}
// Generate StreamEdge The core attributes are upstream and downstream nodes, partitions and shuffleMode
StreamEdge edge = new StreamEdge(upstreamNode, downstreamNode, typeNumber,
partitioner, outputTag, shuffleMode);
// Take this edge Add to your upstream and downstream streamNode in
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
}
}The core approach
addOperator: structure streamNodes aggregate
addEdge: Building edges
addEdgeInternal: Building edges , In this method , Determine the partition strategy , If no partition is specified, local distribution is determined according to whether the parallelism of upstream and downstream operators is the same , Or distribute evenly
getJobGraph: Generate JobGraph
getStreamingPlanAsJSON:StreamGraph String representation
Reference resources
Flink Explain the operation architecture in detail - Programmer base
边栏推荐
猜你喜欢
TCP's three handshakes and four waves

Introduction to spring trick of ByteDance: senior students, senior students, senior students, and the author "brocade bag"
EasyRE WriteUp
C# WinForm系列-Button简单使用
Instructions for Redux
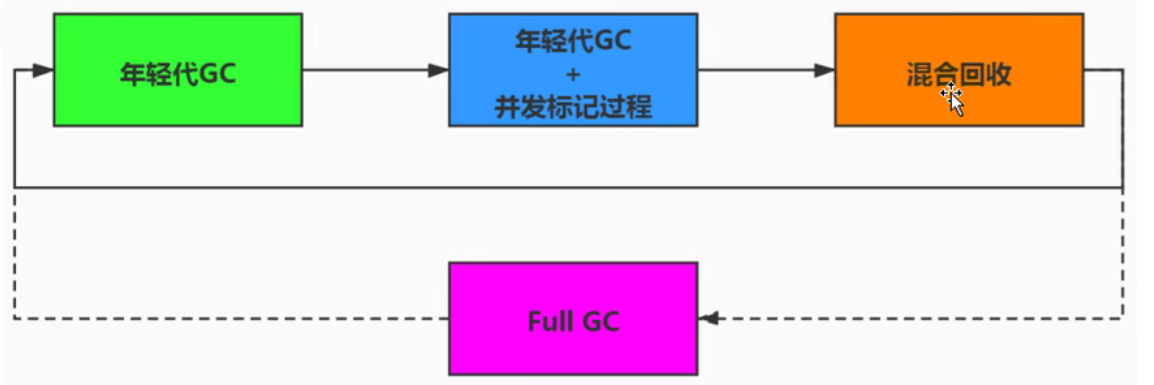
JVM garbage collector part 2

程序员定位解决问题方法论
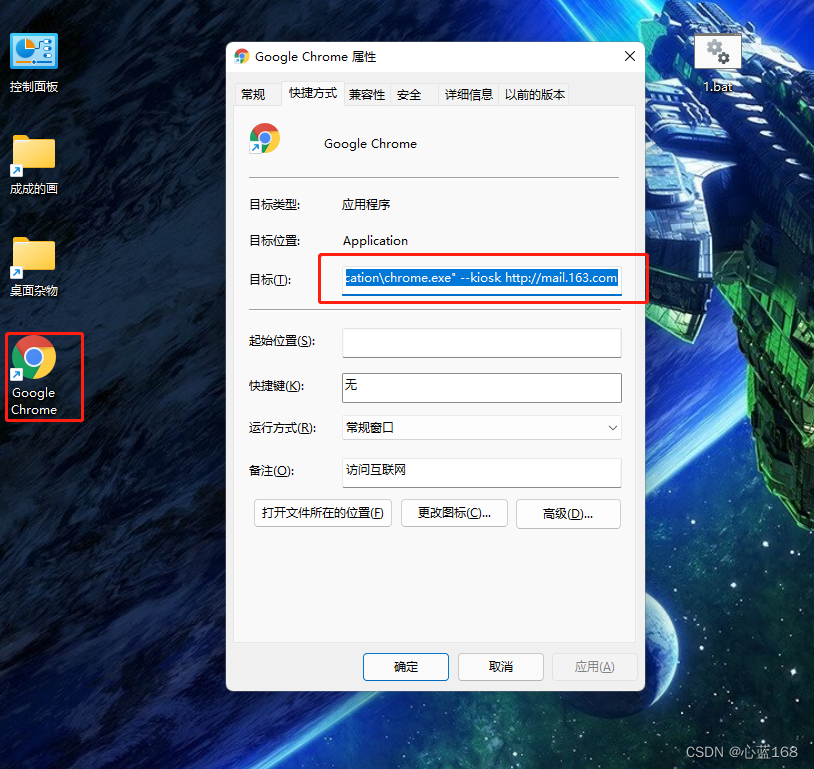
C#版Selenium操作Chrome全屏模式显示(F11)

Akamai talking about risk control principles and Solutions
03个人研发的产品及推广-计划服务配置器V3.0
随机推荐
Introduction to spring trick of ByteDance: senior students, senior students, senior students, and the author "brocade bag"
暑假刷题嗷嗷嗷嗷
Flink 解析(二):反压机制解析
Flink 解析(三):内存管理
Resume of a microservice architecture teacher with 10 years of work experience
03 products and promotion developed by individuals - plan service configurator v3.0
Redis installation on centos7
TCP's three handshakes and four waves
04个人研发的产品及推广-数据推送工具
mysql的合计/统计函数
Flexible report v1.0 (simple version)
JVM运行时数据区之程序计数器
02 personal developed products and promotion - SMS platform
05个人研发的产品及推广-数据同步工具
【逆向中级】跃跃欲试
Data transfer instruction
数据仓库建模使用的模型以及分层介绍
Selenium test of automatic answer runs directly in the browser, just like real users.
Idea breakpoint debugging skills, multiple dynamic diagram package teaching package meeting.
关于Selenium启动Chrome浏览器闪退问题