当前位置:网站首页>Interpretation of Flink source code (III): Interpretation of executiongraph source code
Interpretation of Flink source code (III): Interpretation of executiongraph source code
2022-07-06 17:11:00 【Stray_ Lambs】
Catalog
ExectionGraph Execution diagram
ExecutionGraph Core objects of
ExecutionGraph Specific generation process
1、Flink Client submit JobGraph to JobManager
2、 structure ExecutionGraph object
ExectionGraph Execution diagram
stay Flink in ExecutionGraph Execution diagram is the central data structure that coordinates the distributed execution of data flow , It preserves each parallel task 、 Each intermediate flow and the communication between them .StreamGraph and JobGraph The transformation of Chengdu is in Flink client , and Final Flink The core execution diagram of job runtime scheduling layer ExecutionGraph It's on the server JobManager Generated in the .
ExecutionGraph In the actual processing conversion, it is only changed GobGraph Each node of , The whole topology has not been changed . The following changes have taken place :
- The concept of parallelism is added , Become a truly schedulable graph structure ;
- Generated and JobVertex Corresponding ExecutionJobVertex and ExecutionVertex, as well as IntermediateDataSet Corresponding IntermediateResult and IntermediateResultPartition etc. , Parallelism will be achieved through these classes .

ExecutionGraph Core objects of
1、ExecutionJobVertex
ExecutionJobVertex and JobGraph Medium JobVertex One-to-one correspondence .ExecutionJobVertex Indicates that the execution process is from JobGraph A vertex of , It saves the aggregated state of all parallel subtasks . Every ExecutionJobVertex There are as many as parallelism ExecutionVertex.
2、ExecutionVertex
ExecutionVertex Express ExecutionVertex One of the concurrent subtasks of , Input is ExecutionEdge, The output is IntermediateResultPartition.ExecutionVertex from ExecutionJobVertex And the index identification of parallel subtasks .
3、IntermediateResult
IntermediateResult and JobGraph Medium IntermediateDataSet One-to-one correspondence . One IntermediateResult Contains multiple IntermediateResultPartition, Its number is equal to the parallelism of the operator .
4、IntermediateResultPartition
IntermediateResultPartition Express ExecutionVertex An output partition of ( In the middle ), The producer is ExecutionVertex, There are several consumers ExecutionEdge.
5、ExecutionEdge
ExecutionEdge Express ExecutionVertex The input of , The input source is IntermediateResultPartition, The destination is ExecutionVertex. There can only be one source and one destination .
6、Execution
ExecutionVertex Can be executed multiple times ( Used to recover 、 Recalculate 、 Reconfiguration ),Execution Be responsible for tracking the status information of an execution of this vertex and resource .
To prevent failure , Or when some data needs to be recalculated ,ExecutionVertex There may be multiple executions . Because in future operation requests , It is no longer available . Execution by ExecutionAttemptID identification .JobMananger and TaskManager All messages about task deployment and task status update between are using ExecutionAttemptID To locate the message recipient .
ExecutionGraph Specific generation process
ExecutionGraph Is a description of parallelization JobGraph Execution diagram , Generate and maintain CheckpointCordinator,TaskTracker,ExecutionVertex,ExecutionEdge,IntermediateResult And other components . and ExecutionGraph It's just Flink Part of the core data structure , stay JM Of SchedulerNG Generate ExecutionGraph Before ,Flink Will perform a series of in RM The distribution of Container The operation , Follow Yarn Cluster interaction , be based on Akka Of RpcServer(Flink Packaged actor) Communication mode registration , be based on ZK High availability election of , The core management and scheduling components involved include ResourceManager,Dispatcher,JobManager,Scheduler etc. .
There are many frameworks designed in this chapter , In the structure ExecutionGraph In the process, it will be parsed in turn Flink Follow Yarn Interaction , be based on Akka Communication mode and based on ZK Of HA Etc .
The last chapter talked about JobGraph The establishment of the ,JobGraph After creation ,Flink Will create YarnJobClusterExecutor Submit task to cluster . stay StreamExecutionEnvironment Class , call public JobExecutionResult execute(StreamGraph streamGraph) throws Exception Medium final JobClient jobClient = executeAsync(streamGraph) Method .
public JobClient executeAsync(StreamGraph streamGraph) throws Exception {
checkNotNull(streamGraph, "StreamGraph cannot be null.");
checkNotNull(configuration.get(DeploymentOptions.TARGET), "No execution.target specified in your configuration file.");
final PipelineExecutorFactory executorFactory =
executorServiceLoader.getExecutorFactory(configuration);
checkNotNull(
executorFactory,
"Cannot find compatible factory for specified execution.target (=%s)",
configuration.get(DeploymentOptions.TARGET));
// Call... From here execute Method to start creating ExecutionGraph
CompletableFuture<JobClient> jobClientFuture = executorFactory
.getExecutor(configuration)
.execute(streamGraph, configuration, userClassloader);
try {
JobClient jobClient = jobClientFuture.get();
jobListeners.forEach(jobListener -> jobListener.onJobSubmitted(jobClient, null));
return jobClient;
} catch (ExecutionException executionException) {
final Throwable strippedException = ExceptionUtils.stripExecutionException(executionException);
jobListeners.forEach(jobListener -> jobListener.onJobSubmitted(null, strippedException));
throw new FlinkException(
String.format("Failed to execute job '%s'.", streamGraph.getJobName()),
strippedException);
}
}Call in AbstractJobClusterExecutor Class execute Method .
public CompletableFuture<JobClient> execute(@Nonnull final Pipeline pipeline, @Nonnull final Configuration configuration, @Nonnull final ClassLoader userCodeClassloader) throws Exception {
// Generate JobGraph
final JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration);
try (final ClusterDescriptor<ClusterID> clusterDescriptor = clusterClientFactory.createClusterDescriptor(configuration)) {
final ExecutionConfigAccessor configAccessor = ExecutionConfigAccessor.fromConfiguration(configuration);
final ClusterSpecification clusterSpecification = clusterClientFactory.getClusterSpecification(configuration);
// Start publishing deployment tasks to the cluster
final ClusterClientProvider<ClusterID> clusterClientProvider = clusterDescriptor
.deployJobCluster(clusterSpecification, jobGraph, configAccessor.getDetachedMode());
LOG.info("Job has been submitted with JobID " + jobGraph.getJobID());
return CompletableFuture.completedFuture(
new ClusterClientJobClientAdapter<>(clusterClientProvider, jobGraph.getJobID(), userCodeClassloader));
}
}The general steps are to create YarnClient,check Environmental Science , For example, inspection. Yarn Whether the queue exists , Register the required memory ,CPU And so on , initialization Jar Wait for the file storage environment (hdfs),kerberos Identity authentication, etc . All application resources and execution actions will put Into the Yarn Of ApplicationSubmissionContext In the context of , Finally through yarnClient.submitApplication(appContext) towards Yarn Cluster commit task .
private ApplicationReport startAppMaster(
Configuration configuration,
String applicationName,
String yarnClusterEntrypoint,
JobGraph jobGraph,
YarnClient yarnClient,
YarnClientApplication yarnApplication,
ClusterSpecification clusterSpecification) throws Exception {
// ------------------ Initialize the file systems -------------------------
...
LOG.info("Submitting application master " + appId);
yarnClient.submitApplication(appContext);
...
}When Yarn The cluster received Client After applying, it will do a series of resource verification actions , Including whether there is free memory ,CPU It can give users (flink) Resources requested , User authority verification , Are there any free Container, Is there a specified Yarn Line up, etc , If the above conditions are met, start to notify RM Allocate one Container To the idle NM Used as startup Flink Of AM, stay Container After the assignment, I will go hdfs( Default ) Load user uploaded Jar package , Call after reflection loading deployInternal Of the specified entry class Main Method . Except for the last step Flink Internal code of , The rest are in Yarn Complete within the cluster .
What we specify here is Per-Job Pattern :
/**
* The class to start the application master with. This class runs the main
* method in case of the job cluster.
*/
protected String getYarnJobClusterEntrypoint() {
return YarnJobClusterEntrypoint.class.getName();
}
// When flink client The task submitted to ResourceManager After completion
//ResourceManager Will do resource verification and find free resources in the cluster NodeManager Allocate one container As flink Of AppMaster Then call the following main function
public static void main(String[] args) {
// startup checks and logging
....
try {
YarnEntrypointUtils.logYarnEnvironmentInformation(env, LOG);
} catch (IOException e) {
LOG.warn("Could not log YARN environment information.", e);
}
Configuration configuration = YarnEntrypointUtils.loadConfiguration(workingDirectory, env);
YarnJobClusterEntrypoint yarnJobClusterEntrypoint = new YarnJobClusterEntrypoint(configuration);
// Ready to start Flink colony
ClusterEntrypoint.runClusterEntrypoint(yarnJobClusterEntrypoint);
}ClusterEntrypoint yes FlinkOnYarn stay AM Main entry class of , It does two main things ,
First of all , Start some external dependent services , Columns such as :RpcService(Akka),HAService,BlobService etc.
second , Start your own RM and Dispatcher, here RM yes Flink Resource controller maintained internally , such as Flink Of Slot It is a two-stage Application ( It will be parsed later ),Dispatcher It's mainly about generating JobManager,
and RM and Dispatcher Are configurable HA Of (LeaderContender)
private void runCluster(Configuration configuration, PluginManager pluginManager) throws Exception {
synchronized (lock) {
// establish RPCService( Packaged Akka Of ActorSystem, Used for creation and maintenance later flink Of each service actors)
// Follow spark equally ,flink The message communication of is based on Akka Of actor Asynchronous event communication mode , Data interaction is based on being good at high concurrency and asynchrony IO frame Netty
// start-up HaService(HA Mode will use zk As the main backup master Synchronization save point of metadata ), Responsible for large file transfer service blobServer etc.
// Use connections zk Client's Curator In the framework of zk establish flink Directory and start the thread that monitors the data changes of the directory
// image Dispatcher,JobManager Based on zk Of HA Mode is also called Curator Of LeaderLatch And their core logic entry is also in the code block of successful master selection
initializeServices(configuration, pluginManager);
// write host information into configuration
configuration.setString(JobManagerOptions.ADDRESS, commonRpcService.getAddress());
configuration.setInteger(JobManagerOptions.PORT, commonRpcService.getPort());
// establish DefaultDispatcherResourceManagerComponentFactory
final DispatcherResourceManagerComponentFactory dispatcherResourceManagerComponentFactory = createDispatcherResourceManagerComponentFactory(configuration);
clusterComponent = dispatcherResourceManagerComponentFactory.create(
configuration,
ioExecutor,
commonRpcService,
haServices,
blobServer,
heartbeatServices,
metricRegistry,
archivedExecutionGraphStore,
new RpcMetricQueryServiceRetriever(metricRegistry.getMetricQueryServiceRpcService()),
this);
....
}Here we mainly mention RpcService(Akka),HAService Two services
Follow Spark similar ,Flink It is a master-slave cluster architecture , Therefore, there will be a lot of message communication and data transmission between different roles of each node , there For data transmission Netty( It will be parsed later ), and For communication between roles Akka,Flink be based on Akka It mainly encapsulates two interfaces ,1:RpcServer,2:RpcEndpoint, They are respectively encapsulated AkkaSystem and AkkaActor.Akka All roles are through AkkaSystem This top-level parent class is created , The attributes of each role will not be exposed, but through ActorRef Reference send message , therefore Flink At the beginning of the creation RpcServer And those mentioned later include things like RM,JobManager,TaskExecutor All inherited and encapsulated AkkaActor Of RpcEndpoint( In the constructor by RpcServer establish )
// initialization RpcEndpoint when , Will create AkkaActor
protected RpcEndpoint(final RpcService rpcService, final String endpointId) {
this.rpcService = checkNotNull(rpcService, "rpcService");
this.endpointId = checkNotNull(endpointId, "endpointId");
// Unified by FLinkClusterEntrypoint Of ActorSystem The child created actor, It's packed with ActorRef
this.rpcServer = rpcService.startServer(this);
this.mainThreadExecutor = new MainThreadExecutor(rpcServer, this::validateRunsInMainThread);
}
public <C extends RpcEndpoint & RpcGateway> RpcServer startServer(C rpcEndpoint) {
checkNotNull(rpcEndpoint, "rpc endpoint");
// register Actor And get the ActorRef
final SupervisorActor.ActorRegistration actorRegistration = registerAkkaRpcActor(rpcEndpoint);
final ActorRef actorRef = actorRegistration.getActorRef();
..
}RpcEndpoint It has its own lifecycle interface , Different role implementations may be different , Of course it's different RpcEndpoint Roles also encapsulate different message classes , such as TaskExecutor Yes offerSlotsToJobManager The news of ,JobManager Yes startScheduling The news of , All through ActorRef Call message tell Interface .
// start-up RpcEndpoint
public final void start() {
rpcServer.start();
}
// Trigger the start logic
protected void onStart() throws Exception {}
// stop it RpcEndpoint
protected final void stop() {
rpcServer.stop();
}
// Trigger stop logic
protected CompletableFuture<Void> onStop() {
return CompletableFuture.completedFuture(null);
}Let's talk about it here HAService This service component
public static HighAvailabilityServices createHighAvailabilityServices(
Configuration configuration,
Executor executor,
AddressResolution addressResolution) throws Exception {
HighAvailabilityMode highAvailabilityMode = HighAvailabilityMode.fromConfig(configuration);
switch (highAvailabilityMode) {
...
case ZOOKEEPER:
BlobStoreService blobStoreService = BlobUtils.createBlobStoreFromConfig(configuration);
// Use zk As the main backup master Synchronization save point of metadata
return new ZooKeeperHaServices(
ZooKeeperUtils.startCuratorFramework(configuration),
executor,
configuration,
blobStoreService);
...
}Flink With the help of Curator The interaction of Zookeeper, And start the thread that monitors the changes of the directory data , It's using leaderLatch Primary strategy , That is to say zk Create a temporary ordered node under the specified directory (LeaderContender), Node number Minimum The Settings for leader, If the node hangs, it will be re elected .
public static CuratorFramework startCuratorFramework(Configuration configuration) {
Preconditions.checkNotNull(configuration, "configuration");
....
CuratorFramework cf = CuratorFrameworkFactory.builder()
.connectString(zkQuorum)
.sessionTimeoutMs(sessionTimeout)
.connectionTimeoutMs(connectionTimeout)
.retryPolicy(new ExponentialBackoffRetry(retryWait, maxRetryAttempts))
// Curator prepends a '/' manually and throws an Exception if the
// namespace starts with a '/'.
.namespace(rootWithNamespace.startsWith("/") ? rootWithNamespace.substring(1) : rootWithNamespace)
.aclProvider(aclProvider)
.build();
cf.start();
return cf;
}Flink be based on Curator It mainly encapsulates several interfaces , Here we mainly talk about those who provide election Services ZooKeeperLeaderElectionService And competing LeaderContender
ZooKeeperLeaderElectionService: Mainly responsible for the monitoring function of election services and data changes
LeaderContender: Election participants need to inherit this interface , It will be recalled after winning the master grantLeadership Interface
public ZooKeeperLeaderElectionService(CuratorFramework client, String latchPath, String leaderPath) {
this.client = Preconditions.checkNotNull(client, "CuratorFramework client");
this.leaderPath = Preconditions.checkNotNull(leaderPath, "leaderPath");
//LeaderLatch Election strategy
leaderLatch = new LeaderLatch(client, latchPath);
// Monitored node Node transformation data
cache = new NodeCache(client, leaderPath);
issuedLeaderSessionID = null;
confirmedLeaderSessionID = null;
confirmedLeaderAddress = null;
leaderContender = null;
running = false;
}
public void start(LeaderContender contender) throws Exception {
Preconditions.checkNotNull(contender, "Contender must not be null.");
Preconditions.checkState(leaderContender == null, "Contender was already set.");
LOG.info("Starting ZooKeeperLeaderElectionService {}.", this);
synchronized (lock) {
client.getUnhandledErrorListenable().addListener(this);
leaderContender = contender;
// towards leaderLatch Add yourself , monitor leaderLatch The result of the election
leaderLatch.addListener(this);
// Start the election
leaderLatch.start();
// Monitor should node node
cache.getListenable().addListener(this);
cache.start();
client.getConnectionStateListenable().addListener(listener);
running = true;
}
}public interface LeaderContender {
/**
* Callback method which is called by the {@link LeaderElectionService} upon selecting this
* instance as the new leader. The method is called with the new leader session ID.
*
* @param leaderSessionID New leader session ID
*/
void grantLeadership(UUID leaderSessionID);
...
}OK, After initializing these core services, return to the initial code , Start to create RM and Dispatcher as well as Web Monitoring and other services
RM:Flink Self maintained resource management components , Mainly responsible for internal maintenance slot Distributed SlotManager,
Dispatcher: Mainly to create JobManager,JobManager Will create the responsible generation ExecutionGraph and CheckpointCoordinator Of SchedulerNG And responsible for management TM Of Slot Life cycle of SlotPool.
public DispatcherResourceManagerComponent create(
Configuration configuration,
Executor ioExecutor,
RpcService rpcService,
HighAvailabilityServices highAvailabilityServices,
BlobServer blobServer,
HeartbeatServices heartbeatServices,
MetricRegistry metricRegistry,
ArchivedExecutionGraphStore archivedExecutionGraphStore,
MetricQueryServiceRetriever metricQueryServiceRetriever,
FatalErrorHandler fatalErrorHandler) throws Exception {
LeaderRetrievalService dispatcherLeaderRetrievalService = null;
LeaderRetrievalService resourceManagerRetrievalService = null;
WebMonitorEndpoint<?> webMonitorEndpoint = null;
ResourceManager<?> resourceManager = null;
DispatcherRunner dispatcherRunner = null;
try {
//onyarn mode zk Of LeaderRetriever, monitor zk/dispatcher_lock The data changes and is cached to NodeCache in .
dispatcherLeaderRetrievalService = highAvailabilityServices.getDispatcherLeaderRetriever();
// The same as above is just zk The directory path is resource_manager_lock
resourceManagerRetrievalService = highAvailabilityServices.getResourceManagerLeaderRetriever();
.......
//Flink To follow Yarn Interactive components , Mainly responsible for Yarn Of RM Application and release Flink Of JM,TM resources
// establish RMPRCEndpoint, establish slotManager( be responsible for slot Application and release of ,RM After selecting the master, it is mainly to start SlotManager,
//SlotManager It will start itself taskManager Of 2 Cycle detection thread includes detection TM Connection timeout for , Idle and slot Timeout of application .
resourceManager = resourceManagerFactory.createResourceManager(
configuration,
ResourceID.generate(),
rpcService,
highAvailabilityServices,
heartbeatServices,
fatalErrorHandler,
new ClusterInformation(hostname, blobServer.getPort()),
webMonitorEndpoint.getRestBaseUrl(),
metricRegistry,
hostname,
ioExecutor);
final HistoryServerArchivist historyServerArchivist = HistoryServerArchivist.createHistoryServerArchivist(configuration, webMonitorEndpoint, ioExecutor);
final PartialDispatcherServices partialDispatcherServices = new PartialDispatcherServices(
configuration,
highAvailabilityServices,
resourceManagerGatewayRetriever,
blobServer,
heartbeatServices,
() -> MetricUtils.instantiateJobManagerMetricGroup(metricRegistry, hostname),
archivedExecutionGraphStore,
fatalErrorHandler,
historyServerArchivist,
metricRegistry.getMetricQueryServiceGatewayRpcAddress(),
ioExecutor);
log.debug("Starting Dispatcher.");
// establish DefaultDispatcherRunner(LeaderContender), Start the election leader
// Mainly responsible for creating JM
dispatcherRunner = dispatcherRunnerFactory.createDispatcherRunner(
highAvailabilityServices.getDispatcherLeaderElectionService(),
fatalErrorHandler,
new HaServicesJobGraphStoreFactory(highAvailabilityServices),
ioExecutor,
rpcService,
partialDispatcherServices);
log.debug("Starting ResourceManager.");
// towards RMRpcEndpoint(ActorRef) Send start command
//RM Start notification of (onStart) Create after receiving Yarn Of RMClient And register yourself to establish a heartbeat according to the user's Yarn Configuration information creation RM,NM client
// Finally, select the master and start SlotManager
resourceManager.start();
resourceManagerRetrievalService.start(resourceManagerGatewayRetriever);
dispatcherLeaderRetrievalService.start(dispatcherGatewayRetriever);
......
}Start Dispatcher The election , Create after winning the master MiniDispatcher Start creating JM
Here we can see that it is the call we analyzed before ZooKeeperLeaderElectionService Service to start Dispatcher(LeaderContender) The election
public static DispatcherRunner create(
LeaderElectionService leaderElectionService,
FatalErrorHandler fatalErrorHandler,
DispatcherLeaderProcessFactory dispatcherLeaderProcessFactory) throws Exception {
final DefaultDispatcherRunner dispatcherRunner = new DefaultDispatcherRunner(
leaderElectionService,
fatalErrorHandler,
dispatcherLeaderProcessFactory);
// Start DefaultDispatcherRunner The election of
return DispatcherRunnerLeaderElectionLifecycleManager.createFor(dispatcherRunner, leaderElectionService);
}
private DispatcherRunnerLeaderElectionLifecycleManager(T dispatcherRunner, LeaderElectionService leaderElectionService) throws Exception {
this.dispatcherRunner = dispatcherRunner;
this.leaderElectionService = leaderElectionService;
// Start the election
leaderElectionService.start(dispatcherRunner);
}Recall what we said before grantLeadership Interface
This will create MiniDispatcher, It also inherited RpcEndpoint Features and is responsible for generating JM, And start the MiniDispatcherActor
//Dispatcher Success in seizing the master
@Override
public void grantLeadership(UUID leaderSessionID) {
runActionIfRunning(() -> startNewDispatcherLeaderProcess(leaderSessionID));
}
public AbstractDispatcherLeaderProcess.DispatcherGatewayService create(
DispatcherId fencingToken,
Collection<JobGraph> recoveredJobs,
JobGraphWriter jobGraphWriter) {
final Dispatcher dispatcher;
try {
// establish MiniDispatcherRpcEndpoint(Actor)
dispatcher = dispatcherFactory.createDispatcher(
rpcService,
fencingToken,
recoveredJobs,
(dispatcherGateway, scheduledExecutor, errorHandler) -> new NoOpDispatcherBootstrap(),
PartialDispatcherServicesWithJobGraphStore.from(partialDispatcherServices, jobGraphWriter));
} catch (Exception e) {
throw new FlinkRuntimeException("Could not create the Dispatcher rpc endpoint.", e);
}
// start-up dispatcherRpcEndpoint
dispatcher.start();
return DefaultDispatcherGatewayService.from(dispatcher);
}I've said everything before RpcEndpoint Have achieved a set of life cycle
Here start the RpcEndpoint ,Start->OnStart
//------------------------------------------------------
// Lifecycle methods
//------------------------------------------------------
@Override
public void onStart() throws Exception {
try {
startDispatcherServices();
} catch (Throwable t) {
final DispatcherException exception = new DispatcherException(String.format("Could not start the Dispatcher %s", getAddress()), t);
onFatalError(exception);
throw exception;
}
// Ready to start creating JobManager
startRecoveredJobs();
this.dispatcherBootstrap = this.dispatcherBootstrapFactory.create(
getSelfGateway(DispatcherGateway.class),
this.getRpcService().getScheduledExecutor() ,
this::onFatalError);
}establish JM,JM yes Flink Is one of the core components ,JM Maintain the internal Slot Resource scheduling SlotPool And responsible for maintenance CheckpointCoordinator And production ExecutionGraph Of SchedulerNG etc. .
CompletableFuture<JobManagerRunner> createJobManagerRunner(JobGraph jobGraph, long initializationTimestamp) {
// obtain clusterEntrypoint Of actorSystem Used to create JobManagerRunnerRpcpoint
final RpcService rpcService = getRpcService();
// establish JM-> Generate SchedulerNG-> Generate ExecutionGraph-> Generate ExecutionJobVertex
//-> Generate ExecutionVertex,IntermediateResult/partiton-> Generate CheckpointCoordinator
//->JM Elector -> start-up SchedulerNG Distribute tasks and ck
return CompletableFuture.supplyAsync(
() -> {
try {
JobManagerRunner runner = jobManagerRunnerFactory.createJobManagerRunner(
jobGraph,
configuration,
rpcService,
highAvailabilityServices,
heartbeatServices,
jobManagerSharedServices,
new DefaultJobManagerJobMetricGroupFactory(jobManagerMetricGroup),
fatalErrorHandler,
initializationTimestamp);
// Start the election JMLeader
runner.start();
return runner;
} catch (Exception e) {
throw new CompletionException(new JobInitializationException(jobGraph.getJobID(), "Could not instantiate JobManager.", e));
}
},
ioExecutor); // do not use main thread executor. Otherwise, Dispatcher is blocked on JobManager creation
}
public JobMaster(
RpcService rpcService,
JobMasterConfiguration jobMasterConfiguration,
ResourceID resourceId,
JobGraph jobGraph,
HighAvailabilityServices highAvailabilityService,
SlotPoolFactory slotPoolFactory,
JobManagerSharedServices jobManagerSharedServices,
HeartbeatServices heartbeatServices,
JobManagerJobMetricGroupFactory jobMetricGroupFactory,
OnCompletionActions jobCompletionActions,
FatalErrorHandler fatalErrorHandler,
ClassLoader userCodeLoader,
SchedulerNGFactory schedulerNGFactory,
ShuffleMaster<?> shuffleMaster,
PartitionTrackerFactory partitionTrackerFactory,
ExecutionDeploymentTracker executionDeploymentTracker,
ExecutionDeploymentReconciler.Factory executionDeploymentReconcilerFactory,
long initializationTimestamp) throws Exception {
super(rpcService, AkkaRpcServiceUtils.createRandomName(JOB_MANAGER_NAME), null);
.....
// establish slotPool, Mainly responsible for RM Application and release slot
this.slotPool = checkNotNull(slotPoolFactory).createSlotPool(jobGraph.getJobID());
// Store the later created TM Of Map
this.registeredTaskManagers = new HashMap<>(4);
//JM Accept each TM Information feedback
this.partitionTracker = checkNotNull(partitionTrackerFactory)
.create(resourceID -> {
Tuple2<TaskManagerLocation, TaskExecutorGateway> taskManagerInfo = registeredTaskManagers.get(resourceID);
if (taskManagerInfo == null) {
return Optional.empty();
}
return Optional.of(taskManagerInfo.f1);
});
// Track each TM Whether the task is pending, The feedback attribute instance is PendingBackPressureRequest
this.backPressureStatsTracker = checkNotNull(jobManagerSharedServices.getBackPressureStatsTracker());
//NettyShuffleMaster, Responsible for creating Producer Of InetSocketAddress Connection information
this.shuffleMaster = checkNotNull(shuffleMaster);
// Monitoring indicator group
this.jobManagerJobMetricGroup = jobMetricGroupFactory.create(jobGraph);
//scheduler Will create ExecutionGraph
this.schedulerNG = createScheduler(executionDeploymentTracker, jobManagerJobMetricGroup);
//Job State monitor , Start up Scheduler Created on
this.jobStatusListener = null;
// establish RM Connect
this.resourceManagerConnection = null;
this.establishedResourceManagerConnection = null;
// establish TM and RM heartbeat
this.accumulators = new HashMap<>();
this.taskManagerHeartbeatManager = NoOpHeartbeatManager.getInstance();
this.resourceManagerHeartbeatManager = NoOpHeartbeatManager.getInstance();
}This is mainly about Scheduler
Scheduler yes JM One of the core components , It will generate ExecutionGraph And in JM Trigger after selecting the master ExecutionGraph Of Checkpoint Dispatch and Slot Application and deployment of TM.
public SchedulerBase(
final Logger log,
final JobGraph jobGraph,
final BackPressureStatsTracker backPressureStatsTracker,
final Executor ioExecutor,
final Configuration jobMasterConfiguration,
final SlotProvider slotProvider,
final ScheduledExecutorService futureExecutor,
final ClassLoader userCodeLoader,
final CheckpointRecoveryFactory checkpointRecoveryFactory,
final Time rpcTimeout,
final RestartStrategyFactory restartStrategyFactory,
final BlobWriter blobWriter,
final JobManagerJobMetricGroup jobManagerJobMetricGroup,
final Time slotRequestTimeout,
final ShuffleMaster<?> shuffleMaster,
final JobMasterPartitionTracker partitionTracker,
final ExecutionVertexVersioner executionVertexVersioner,
final ExecutionDeploymentTracker executionDeploymentTracker,
final boolean legacyScheduling,
long initializationTimestamp) throws Exception {
this.log = checkNotNull(log);
this.jobGraph = checkNotNull(jobGraph);
this.backPressureStatsTracker = checkNotNull(backPressureStatsTracker);
this.ioExecutor = checkNotNull(ioExecutor);
this.jobMasterConfiguration = checkNotNull(jobMasterConfiguration);
this.slotProvider = checkNotNull(slotProvider);
this.futureExecutor = checkNotNull(futureExecutor);
this.userCodeLoader = checkNotNull(userCodeLoader);
this.checkpointRecoveryFactory = checkNotNull(checkpointRecoveryFactory);
this.rpcTimeout = checkNotNull(rpcTimeout);
final RestartStrategies.RestartStrategyConfiguration restartStrategyConfiguration =
jobGraph.getSerializedExecutionConfig()
.deserializeValue(userCodeLoader)
.getRestartStrategy();
// Retry mechanism , Yes FixedDelayRestartStrategy,FailureRateRestartStrategy Equal strategy
this.restartStrategy = RestartStrategyResolving.resolve(restartStrategyConfiguration,
restartStrategyFactory,
jobGraph.isCheckpointingEnabled());
if (legacyScheduling) {
log.info("Using restart strategy {} for {} ({}).", this.restartStrategy, jobGraph.getName(), jobGraph.getJobID());
}
// A large file BlobWriter service
this.blobWriter = checkNotNull(blobWriter);
//JM Detection index group
this.jobManagerJobMetricGroup = checkNotNull(jobManagerJobMetricGroup);
// apply Slot Timeout time , start-up Scheduler I will apply for it later Slot
this.slotRequestTimeout = checkNotNull(slotRequestTimeout);
// Both deployment and cancellation will modify this executionVertexVersioner
this.executionVertexVersioner = checkNotNull(executionVertexVersioner);
// Whether to delay scheduling
this.legacyScheduling = legacyScheduling;
// establish executionGraph
this.executionGraph = createAndRestoreExecutionGraph(jobManagerJobMetricGroup, checkNotNull(shuffleMaster), checkNotNull(partitionTracker), checkNotNull(executionDeploymentTracker), initializationTimestamp);
....
}Mainly created ExecutionGraph,StateBackend,CheckpointCoordinator etc.
public static ExecutionGraph buildGraph(
@Nullable ExecutionGraph prior,
JobGraph jobGraph,
Configuration jobManagerConfig,
ScheduledExecutorService futureExecutor,
Executor ioExecutor,
SlotProvider slotProvider,
ClassLoader classLoader,
CheckpointRecoveryFactory recoveryFactory,
Time rpcTimeout,
RestartStrategy restartStrategy,
MetricGroup metrics,
BlobWriter blobWriter,
Time allocationTimeout,
Logger log,
ShuffleMaster<?> shuffleMaster,
JobMasterPartitionTracker partitionTracker,
FailoverStrategy.Factory failoverStrategyFactory,
ExecutionDeploymentListener executionDeploymentListener,
ExecutionStateUpdateListener executionStateUpdateListener,
long initializationTimestamp) throws JobExecutionException, JobException {
.....
// create a new execution graph, if none exists so far
// Generate ExecutionGraph, Mainly responsible for the maintenance of ExecutionJobVertex And responsible for checkpoint Of coordinator
final ExecutionGraph executionGraph;
try {
executionGraph = (prior != null) ? prior :
new ExecutionGraph(
jobInformation,
futureExecutor,
ioExecutor,
rpcTimeout,
restartStrategy,
maxPriorAttemptsHistoryLength,
failoverStrategyFactory,
slotProvider,
classLoader,
blobWriter,
allocationTimeout,
partitionReleaseStrategyFactory,
shuffleMaster,
partitionTracker,
jobGraph.getScheduleMode(),
executionDeploymentListener,
executionStateUpdateListener,
initializationTimestamp);
} catch (IOException e) {
throw new JobException("Could not create the ExecutionGraph.", e);
}
.....
// establish ExecutionJobVertex, establish ExecutionGraph The core method of
executionGraph.attachJobGraph(sortedTopology);
.....
final StateBackend rootBackend;
try {
// establish StateBackend, Generate according to user configuration
// Including based on Flink Oneself JVM heap Of MemoryStateBackend
// External state storage RocksDBStateBackend, Support hdfs Waiting FsStateBackend
rootBackend = StateBackendLoader.fromApplicationOrConfigOrDefault(
applicationConfiguredBackend, jobManagerConfig, classLoader, log);
}
catch (IllegalConfigurationException | IOException | DynamicCodeLoadingException e) {
throw new JobExecutionException(jobId, "Could not instantiate configured state backend", e);
}
....
// If true, Generate CheckpointCoordinator
// But it will not really be implemented at present , But wait for the later JM Of SchedulerNG Notify when initializing coordinator The state changes to running Only after
executionGraph.enableCheckpointing(
chkConfig,
triggerVertices,
ackVertices,
confirmVertices,
hooks,
checkpointIdCounter,
completedCheckpoints,
rootBackend,
checkpointStatsTracker);
}
// create all the metrics for the Execution Graph
// Register test indicators
metrics.gauge(RestartTimeGauge.METRIC_NAME, new RestartTimeGauge(executionGraph));
metrics.gauge(DownTimeGauge.METRIC_NAME, new DownTimeGauge(executionGraph));
metrics.gauge(UpTimeGauge.METRIC_NAME, new UpTimeGauge(executionGraph));
executionGraph.getFailoverStrategy().registerMetrics(metrics);
return executionGraph;
}
public void enableCheckpointing(
CheckpointCoordinatorConfiguration chkConfig,
List<ExecutionJobVertex> verticesToTrigger,
List<ExecutionJobVertex> verticesToWaitFor,
List<ExecutionJobVertex> verticesToCommitTo,
List<MasterTriggerRestoreHook<?>> masterHooks,
CheckpointIDCounter checkpointIDCounter,
CompletedCheckpointStore checkpointStore,
StateBackend checkpointStateBackend,
CheckpointStatsTracker statsTracker) {
....
// call checkpoint Of ExecutorService Single pass pool , Used as a ExecutionGraph Periodically trigger checkpoint
checkpointCoordinatorTimer = Executors.newSingleThreadScheduledExecutor(
new DispatcherThreadFactory(
Thread.currentThread().getThreadGroup(), "Checkpoint Timer"));
// establish CheckpointCoordinator
checkpointCoordinator = new CheckpointCoordinator(
jobInformation.getJobId(),
chkConfig,
tasksToTrigger,
tasksToWaitFor,
tasksToCommitTo,
operatorCoordinators,
checkpointIDCounter,
checkpointStore,
checkpointStateBackend,
ioExecutor,
new CheckpointsCleaner(),
new ScheduledExecutorServiceAdapter(checkpointCoordinatorTimer),
SharedStateRegistry.DEFAULT_FACTORY,
failureManager);
...
if (chkConfig.getCheckpointInterval() != Long.MAX_VALUE) {
// the periodic checkpoint scheduler is activated and deactivated as a result of
// job status changes (running -> on, all other states -> off)
// register Job State monitor , stay SchedulerNG When initializing Will inform coordinator Change for running And really trigger checkpoint
registerJobStatusListener(checkpointCoordinator.createActivatorDeactivator());
}
this.stateBackendName = checkpointStateBackend.getClass().getSimpleName();
}Here we focus on building ExecutionGraph The process :
1: It mainly generates the following upstream Producer(JobVertex) The number corresponds to ExecutionJobVertex
2:( The core )ExecutionJobVertex Start building to partition fine-grained ExecutionVertex(Flink The build contains JobVertex Before, it was Operator Coarse grained execution diagram , The next chapter will analyze the smallest unit SubResultPartition Equal granularity data structure )
public void attachJobGraph(List<JobVertex> topologiallySorted) throws JobException {
....
// Traverse JobVertex, Loop creation ExecutionJobVertex
for (JobVertex jobVertex : topologiallySorted) {
// If JobVertex Need incoming data JobEdge The set is empty and should JobVertex Cannot stop
if (jobVertex.isInputVertex() && !jobVertex.isStoppable()) {
// Whether all sources Task Can be stopped
this.isStoppable = false;
}
// create the execution job vertex and attach it to the graph
// Create a number corresponding JobVertex Of ExecutionVertex, And attach it to the figure
ExecutionJobVertex ejv = new ExecutionJobVertex(
this,
jobVertex,
1,
maxPriorAttemptsHistoryLength,
rpcTimeout,
globalModVersion,
createTimestamp);
// Will create the ExecutionJobVertex And the prepositional IntermediateResult Connect
ejv.connectToPredecessors(this.intermediateResults);
// structure Map<JobVertexID,ExecutionJobVertex> object
ExecutionJobVertex previousTask = this.tasks.putIfAbsent(jobVertex.getID(), ejv);
if (previousTask != null) {
throw new JobException(String.format("Encountered two job vertices with ID %s : previous=[%s] / new=[%s]",
jobVertex.getID(), ejv, previousTask));
}
// obtain ExecutionJobVertex Produced IntermediateResult aggregate , And loop the set
for (IntermediateResult res : ejv.getProducedDataSets()) {
// All intermediate results are part of the graph , structure Map<IntermediateDataSetID, IntermediateResult> Type object
IntermediateResult previousDataSet = this.intermediateResults.putIfAbsent(res.getId(), res);
if (previousDataSet != null) {
throw new JobException(String.format("Encountered two intermediate data set with ID %s : previous=[%s] / new=[%s]",
res.getId(), res, previousDataSet));
}
}
// Save in order executionJobVertex It is used to add in sequence checkpoint Of OperatorCoordinators In line
this.verticesInCreationOrder.add(ejv);
// Record ExecutionVertex An overview of , be equal to ExecutionJobVertex Total parallelism
this.numVerticesTotal += ejv.getParallelism();
newExecJobVertices.add(ejv);
}
...
}ExecutionJobVertex Core component analysis :
-->ExecutionVertex: Corresponding to current ExecutionJobVertex Every section , Mainly responsible for creating IntermediateResultPartition,ExecutionEdge,Execution
--> IntermediateResultPartition: Mainly storage upstream ExecutionVertex And downstream List<List<ExecutionEdge>>
--> ExecutionEdge: Main maintenance Source and Target
--> Execution: Mainly responsible for Flink Fine grained physical execution at the partition level triggers , towards TM Submit the deployment task , Trigger TM The Execution Of Checkpoint
ExecutionJobVertex(
ExecutionGraph graph,
JobVertex jobVertex,
int defaultParallelism,
int maxPriorAttemptsHistoryLength,
Time timeout,
long initialGlobalModVersion,
long createTimestamp) throws JobException {
....
// At present Vertex Parallelism
this.parallelism = numTaskVertices;
this.resourceProfile = ResourceProfile.fromResourceSpec(jobVertex.getMinResources(), MemorySize.ZERO);
this.taskVertices = new ExecutionVertex[numTaskVertices];
this.inputs = new ArrayList<>(jobVertex.getInputs().size());
// take the sharing group
this.slotSharingGroup = checkNotNull(jobVertex.getSlotSharingGroup());
this.coLocationGroup = jobVertex.getCoLocationGroup();
// create the intermediate results
// Previously created on the client JobVertex Created when IntermediateDataSet( Every ChainableOperator(JobVertex) Generate a IntermediateDataSet)
this.producedDataSets = new IntermediateResult[jobVertex.getNumberOfProducedIntermediateDataSets()];
// There may be multiple upstream
for (int i = 0; i < jobVertex.getProducedDataSets().size(); i++) {
final IntermediateDataSet result = jobVertex.getProducedDataSets().get(i);
// Generate corresponding IntermediateDataSet(JobVertex) The number of IntermediateResult(ExecutionJobVertex)
this.producedDataSets[i] = new IntermediateResult(
result.getId(),
this,
numTaskVertices,
result.getResultType());
}
// create all task vertices
// Create according to parallelism ExecutionVertex
// Generate IntermediateResultPartition Sign up to producedDataSets
// Generate inputEdges and execution
for (int i = 0; i < numTaskVertices; i++) {
ExecutionVertex vertex = new ExecutionVertex(
this,
i,
producedDataSets,
timeout,
initialGlobalModVersion,
createTimestamp,
maxPriorAttemptsHistoryLength);
this.taskVertices[i] = vertex;
}
....
}
ExecutionVertex(
ExecutionJobVertex jobVertex,
int subTaskIndex,
IntermediateResult[] producedDataSets,
Time timeout,
long initialGlobalModVersion,
long createTimestamp,
int maxPriorExecutionHistoryLength) {
this.jobVertex = jobVertex;
this.subTaskIndex = subTaskIndex;
this.executionVertexId = new ExecutionVertexID(jobVertex.getJobVertexId(), subTaskIndex);
this.taskNameWithSubtask = String.format("%s (%d/%d)",
jobVertex.getJobVertex().getName(), subTaskIndex + 1, jobVertex.getParallelism());
this.resultPartitions = new LinkedHashMap<>(producedDataSets.length, 1);
// There may be multiple upstream ChainableOperator(ExecutionJobVertex), Generate IntermediateResultPartition Sign up to IntermediateResult in
for (IntermediateResult result : producedDataSets) {
IntermediateResultPartition irp = new IntermediateResultPartition(result, this, subTaskIndex);
result.setPartition(subTaskIndex, irp);
resultPartitions.put(irp.getPartitionId(), irp);
}
//ExecutionEdge Main maintenance Source and Target( There may be multiple upstream and downstream )
this.inputEdges = new ExecutionEdge[jobVertex.getJobVertex().getInputs().size()][];
this.priorExecutions = new EvictingBoundedList<>(maxPriorExecutionHistoryLength);
// Create a execution
// Mainly responsible for taskManager Deploy TaskDeploymentDescriptor, Trigger checkpoint, Exception handling
// Back JM After the election , Will pass through SchedulerNG call execution towards TaskManager Submit TaskDescriptor
this.currentExecution = new Execution(
getExecutionGraph().getFutureExecutor(),
this,
0,
initialGlobalModVersion,
createTimestamp,
timeout);
// create a co-location scheduling hint, if necessary
CoLocationGroup clg = jobVertex.getCoLocationGroup();
if (clg != null) {
this.locationConstraint = clg.getLocationConstraint(subTaskIndex);
}
else {
this.locationConstraint = null;
}
getExecutionGraph().registerExecution(currentExecution);
this.timeout = timeout;
this.inputSplits = new ArrayList<>();
}thus ,ExecutionGraph Build it , I can see Flink stay Client Submit the task to ExecutionGraph Generate , The whole construction process began to become complex , From local Flink From the construction of to the construction of clusters , Including the emergence of a variety of external dependency frameworks , Like applying AMContainer Time following Yarn Of RM Interaction , Different RpcEndpoin Roles are based on Akka Communication mechanism , And based on ZK Of HA The election .... Of course, it also generates JM Distributed Dispatcher, Physically scheduled Scheduler, Resource Management RM And other fine-grained scheduling and monitoring components ... But for now, it's still Flink It is still in a ready process to be deployed .
Summary
Let's summarize ExecutionGraph Conversion process of . After generation JobGraph after , Submitted Job after , stay JobManager Conduct ExecutionGraph Transformation .
1、Flink Client submit JobGraph to JobManager
A procedural JobGraph Being really submitted begins with JobClient Of submitJobAndWait() Method call , and JobClient Of submitJobAndWait() Method Will trigger based on Akka Of Actor Message communication between .JobClient It plays a role in this “ The bridge ” The role of , It's connected Synchronous method calls and asynchronous message communication .
stay submitJobAndWait() In the method , The first thing to do is create a JobClientActor Of ActorRef, And send it a message containing JobGraph Example of SubmitJobAndWith news . The SubmitJobAndWait The message is JobClientActor After receiving , call trySubmitJob() Method triggers the real commit action , That is, through jobManager.tell() The way to JobManagerActor Send package JobGraph Of submitJob news . And then ,JobManagerActor Will receive from JobClientActor Of SubmitJob news , And then trigger submitJob() Method .
2、 structure ExecutionGraph object
Code new ExecutionJobVertex() Used to put one by one JobVertex Encapsulated into ExecutionJobVertex, And create ExecutionVertex、Execution、IntermediateResult、IntermediateResultPartition, As ExecutionGraph Core objects of .
stay ExecutionJobVertex In the constructor of , First, according to the corresponding JobVertex The concurrency of generates the corresponding number of ExecutionVertex. among , A kind of ExecutionVertex Represents a ExecutionJobVertex Concurrent subtasks . Then turn the original JobVertex The middle result of IntermediateResultDataSet Turn into ExecutionGraph Medium IntermediateResult.IntermediateResult.setPartition() establish IntermediateResult and IntermediateResultPartition The relationship between , Then generate Execution, And configure relevant resources .
The newly created ExecutionJobVertex Meeting call ejv.connectToPredecessor() Method , Connect upstream according to different distribution strategies , Its parameters are generated upstream IntermediateResult aggregate . among , according to JobEdge in Two kinds of Different DistributionPattern Property to call connectPoinWise() perhaps connectAllToAll() Method , establish ExecutionEdge, take ExecutionVertex And the upstream IntermediateResultPartition Connect .
in general ,ExecutionGraph The conversion process of is : take JobGraph After sorting by topology, we get a JobVertex aggregate , Traversing this JobVertex aggregate , From Source Start , take JobVertex Encapsulated into ExecutionJobVertex, And create ExecutionVertex、Execution、IntermediateResult、IntermediateResultPartition. And then through ejv.connectToPredecessor() Method creation ExecutionEdge, Establish the connection between the current node and its upstream node , I.e. connection ExecutionVertex and IntermediateResultPartition.
Build up ExecutionGraph after , The next step is based on ExecutionGraph Trigger job scheduling , apply Task Slot, Deploy tasks to TaskManager perform .
Reference resources
边栏推荐
- 關於Stream和Map的巧用
- Which is more important for programming, practice or theory [there are some things recently, I don't have time to write an article, so I'll post an article on hydrology, and I'll fill in later]
- Yum install XXX reports an error
- Activiti directory (III) deployment process and initiation process
- [graduation project] QT from introduction to practice: realize imitation of QQ communication, which is also the last blog post in school.
- Basic knowledge of assembly language
- Conception du système de thermomètre numérique DS18B20
- 暑假刷题嗷嗷嗷嗷
- Only learning C can live up to expectations Top1 environment configuration
- 登陆验证koa-passport中间件的简单使用
猜你喜欢

MySQL optimization notes
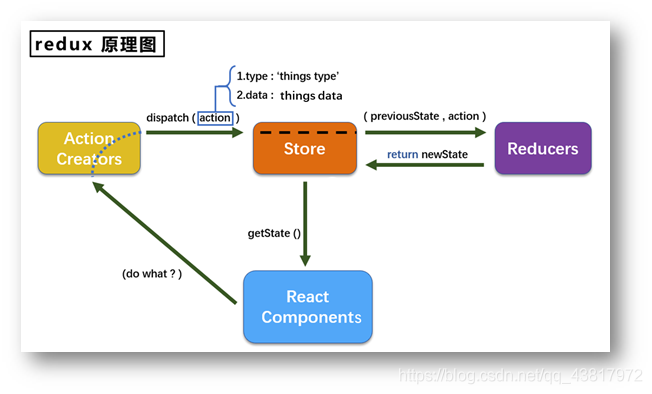
redux使用说明
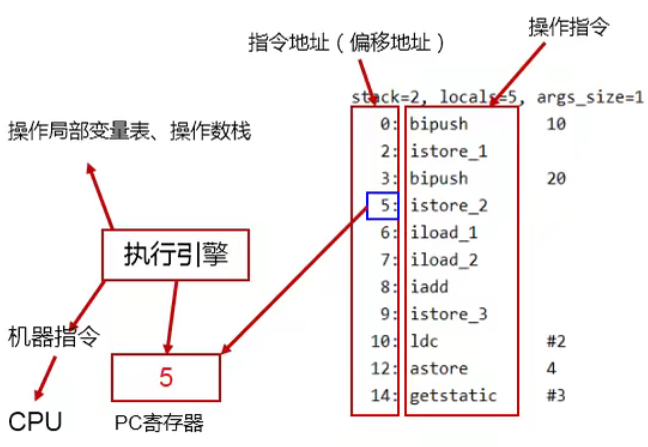
JVM运行时数据区之程序计数器
Assembly language segment definition
搭建flutter环境入坑集合
Erlang installation

When it comes to Google i/o, this is how ByteDance is applied to flutter
Fdog series (4): use the QT framework to imitate QQ to realize the login interface, interface chapter.

100张图训练1小时,照片风格随意变,文末有Demo试玩|SIGGRAPH 2021
![[graduation project] QT from introduction to practice: realize imitation of QQ communication, which is also the last blog post in school.](/img/ef/2072aac5f85c7daf39174784dec7ee.jpg)
[graduation project] QT from introduction to practice: realize imitation of QQ communication, which is also the last blog post in school.
随机推荐
關於Stream和Map的巧用
汇编语言基础知识
8086 内存
100张图训练1小时,照片风格随意变,文末有Demo试玩|SIGGRAPH 2021
[graduation project] QT from introduction to practice: realize imitation of QQ communication, which is also the last blog post in school.
关于Stream和Map的巧用
Programmer orientation problem solving methodology
Logical operation instruction
Conception du système de thermomètre numérique DS18B20
Eureka high availability
Activiti目录(五)驳回、重新发起、取消流程
The daemon thread starts redis and modifies the configuration file
JVM垃圾回收概述
Solr word segmentation analysis
~85 transition
Activiti directory (IV) inquiry agency / done, approved
MySQL日期函数
redux使用说明
原型链继承
Yao BanZhi and his team came together, and the competition experts gathered together. What fairy programming competition is this?