当前位置:网站首页>Spark accumulator
Spark accumulator
2022-07-06 02:04:00 【Diligent ls】
One 、 System accumulator
accumulator : Distributed sharing writes only variables .(Executor and Executor Data cannot be read between )
An accumulator is used to put Executor End variable information is aggregated to Driver End . stay Driver A variable defined in , stay Executor Each end task Will get a new copy of this variable , Every task After updating the values of these copies , Send back Driver Perform consolidation calculation at the end .
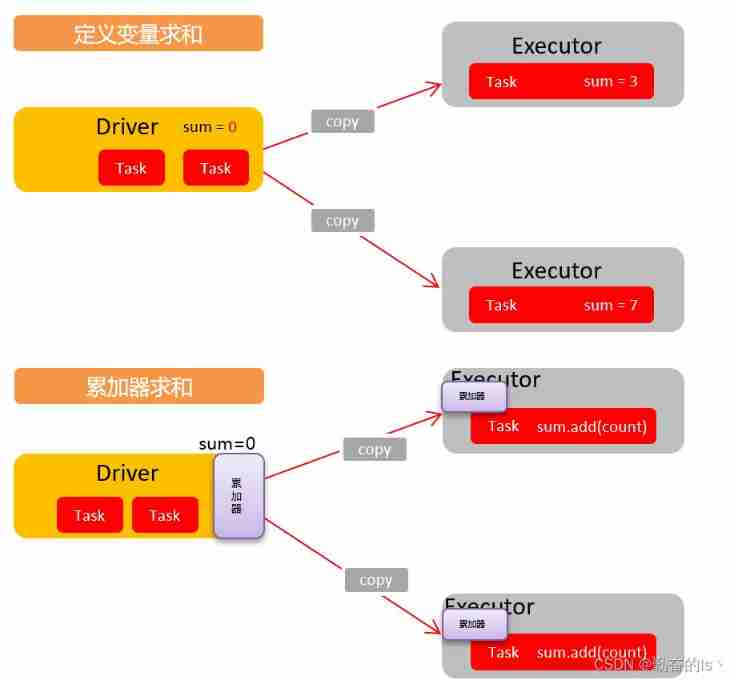
Definition :SparkContext.accumulator(initialValue) Method
object accumulator01_system {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("WC")
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
val dataRDD: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)))
val sum: LongAccumulator = sc.longAccumulator("sum")
dataRDD.foreach{
case (word,count) => {
sum.add(count)
}
}
println(("a",sum.value))
sc.stop()
}
}Be careful :
Executor The task at the end cannot read the value of the accumulator ( for example : stay Executor End calls sum.value, The value obtained is not the final value of the accumulator ). So we say , The accumulator is a distributed shared write only variable .
The accumulator should be placed in the action operator , Because the number of times the conversion operator is executed depends on job The number of , If one spark The application has multiple action operators , The accumulator in the conversion operator may be updated more than once , Lead to wrong result . therefore , If you want an accumulator that is absolutely reliable both in failure and in repeated calculations , We have to put it in foreach() In such an action operator .
For accumulators used in action operators ,Spark Just put everyone Job The modification of each accumulator is applied once .
Two 、 Custom accumulator
Custom accumulator steps
(1) Inherit AccumulatorV2, Set input 、 Output generics
(2) rewrite 6 Abstract methods
(3) To use a custom accumulator, you need to register :sc.register( accumulator ," Accumulator name ")
object accumulator03_define {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("WC")
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[String] = sc.makeRDD(List("Hello", "Hello", "Hello", "Hello", "Spark", "Spark","Hive","Hive"), 2)
// Create accumulators
val acc: myaccumulator = new myaccumulator()
// Register accumulator
sc.register(acc,"wordcount")
// Use accumulator
rdd.foreach{
word => {
acc.add(word)
}
}
// Get the accumulation result of the accumulator
println(acc.value)
sc.stop()
}
}
class myaccumulator extends AccumulatorV2[String,mutable.Map[String,Long]]{
// Define the output data set , A variable Map
var map: mutable.Map[String, Long] = mutable.Map[String,Long]()
// Whether it is in initialization state , If the set data is empty , This is the initialization state
override def isZero: Boolean = map.isEmpty
// Copy accumulator
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = new myaccumulator()
// Reset accumulator
override def reset(): Unit = map.clear()
// Add data
override def add(v: String): Unit = {
if(v.startsWith("H")){
map(v) = map.getOrElse(v,0L) + 1
}
}
// Merge accumulator
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map2: mutable.Map[String, Long] = other.value
map2.foreach{
case (word,count) =>{
map(word) = map.getOrElse(word,0L) + count
}
}
}
// The value of the accumulator
override def value: mutable.Map[String, Long] = map
}边栏推荐
- Cadre du Paddle: aperçu du paddlelnp [bibliothèque de développement pour le traitement du langage naturel des rames volantes]
- Genius storage uses documents, a browser caching tool
- Unity learning notes -- 2D one-way platform production method
- Force buckle 1020 Number of enclaves
- Online reservation system of sports venues based on PHP
- Comments on flowable source code (XXXV) timer activation process definition processor, process instance migration job processor
- How to set an alias inside a bash shell script so that is it visible from the outside?
- 【Flask】获取请求信息、重定向、错误处理
- [technology development -28]: overview of information and communication network, new technology forms, high-quality development of information and communication industry
- Gbase 8C database upgrade error
猜你喜欢
Kubernetes stateless application expansion and contraction capacity

Basic operations of database and table ----- set the fields of the table to be automatically added
Blue Bridge Cup embedded_ STM32 learning_ Key_ Explain in detail
A basic lintcode MySQL database problem

Leetcode skimming questions_ Verify palindrome string II

How to improve the level of pinduoduo store? Dianyingtong came to tell you
![[depth first search] Ji Suan Ke: Betsy's trip](/img/b5/f24eb28cf5fa4dcfe9af14e7187a88.jpg)
[depth first search] Ji Suan Ke: Betsy's trip
Redis如何实现多可用区?
![[Jiudu OJ 09] two points to find student information](/img/35/25aac51fa3e08558b1f6e2541762b6.jpg)
[Jiudu OJ 09] two points to find student information
How does redis implement multiple zones?
随机推荐
[flask] obtain request information, redirect and error handling
Online reservation system of sports venues based on PHP
This time, thoroughly understand the deep copy
Redis-字符串类型
LeetCode 322. Change exchange (dynamic planning)
ClickOnce does not support request execution level 'requireAdministrator'
[solution] add multiple directories in different parts of the same word document
Leetcode sum of two numbers
Basic operations of databases and tables ----- non empty constraints
Folio. Ink is a free, fast and easy-to-use image sharing tool
Install redis
Leetcode skimming questions_ Sum of squares
D22:indeterminate equation (indefinite equation, translation + problem solution)
Using SA token to solve websocket handshake authentication
C web page open WinForm exe
selenium 等待方式
NLP fourth paradigm: overview of prompt [pre train, prompt, predict] [Liu Pengfei]
Computer graduation design PHP campus restaurant online ordering system
Basic operations of databases and tables ----- primary key constraints
Grabbing and sorting out external articles -- status bar [4]