当前位置:网站首页>干货!通过软硬件协同设计加速稀疏神经网络
干货!通过软硬件协同设计加速稀疏神经网络
2022-07-06 01:25:00 【AITIME论道】
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

通过剪枝去除冗余权值是一种常见的压缩神经网络的方法。然而,由于剪枝所生成的稀疏模式较为随机,难以有效被硬件利用,之前方法实现的压缩比与硬件上实际时间的推理加速有较大的差距。而结构化剪枝方法又因为对剪枝过程加以限制,只能实现较为有限的压缩比。为了解决这一问题,本工作中,我们设计了一种硬件友好的压缩方法。通过分解原始权重矩阵,我们将原来的卷积分解为两个步骤,对输入特征的线性组合以及使用基卷积核的卷积操作。基于这一结构,我们相应设计了稀疏神经网络加速器来高效地跳过冗余操作,实现提升推理性能和能耗比的目的。
本期AI TIME PhD直播间,我们邀请到杜克大学电子与计算机工程系博士生——李石宇,为我们带来报告分享《通过软硬件协同设计加速稀疏神经网络》。

李石宇:
本科毕业于清华大学自动化系,目前是杜克大学电子与计算机工程系三年级博士生,师从李海和陈怡然老师。他的主要研究方向为计算机体系结构以及深度学习系统的软硬件协同设计。
The inflation of model size
在追求神经网络识别准确率的同时,我们发现新一代的神经网络模型无论是在计算量还是参数的数量上都在不断增大,同时也引入了许多复杂的操作。
这种复杂度也阻碍了模型在应用端的部署,因为这些设备如手机、IOT设备等都有着严格的功耗和算力限制。
这也引发了我们对设计更高效神经网络算法及相应硬件平台的需求。
Sparse CNN
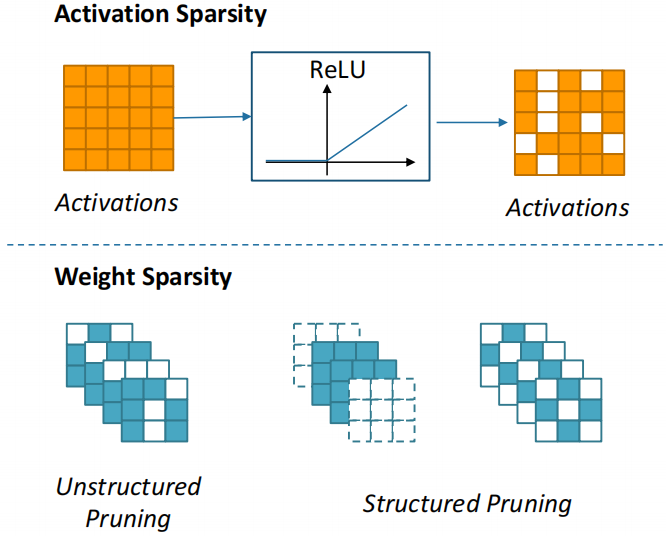
当下的卷积网络中有很多冗余的存在,也就是说存在一些权值或输入是不必要的。如果我们可以在训练阶段将这些冗余去掉,就可以推理所需要的算力和资源。人们在寻求稀疏神经网络的时候,往往把稀疏分为两类:
一类是激活值的稀疏,即输入的稀疏。这类稀疏往往是由激活函数带来的,我们会发现在经过类似ReLU的激活函数之后会有很多输入变成0。那么这些0在我们的计算中是可以被跳过的。
另一类是权值的稀疏。权值的稀疏往往是通过剪枝算法得到的。剪枝算法我们又有两种分类:
● 非结构化的剪枝Unstructured Pruning
我们根据每个权值的重要程度和阈值对比,如果权值较小就可以在计算中跳过。
● 结构化的剪枝Structured Pruning
我们在进行剪枝的时候限制去掉的是整个结构,或者是剪枝的时候根据某种预先定义的固定模式来进行。这样结构化剪枝能帮助我们在硬件推理的时候得到一个可预知的稀疏结构,更好的跳过不必要的运算。
Motivation
我们做这些研究的出发点是,我们看到在神经网络压缩的算法种,结构化的剪枝对硬件比较友好,我们可以很高效的利用这些压缩后的结构,而非结构化的剪枝能够为我们带来比较高的压缩比。同时,另一种低秩近似的方法可以比较好的得到一种容易控制的加速效果。因此我们想,我们是不是能够提出一种方法,把之前这些压缩方法的优点结合起来呢?
我们观察发现,这些卷积神经网络的卷积核通常有比较稀疏的表达。如果我们把卷积核当作一个向量,这些向量可以被投影进一个更低维的子空间。基于此,我们的第一项工作便是算法层面的优化。我们把卷积核投影进一个低维的子空间,并在这个子空间中找到一组基。我们用这组基的线性组合来进行原来卷积核的近似。这就是我们提的第一项算法上的框架——PENNI Framework。
PENNI Framework
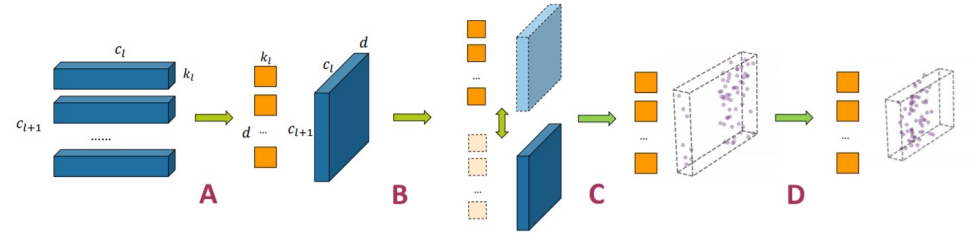
● A. Kernel Decomposition – Low-Rank Approximation
我们进行了卷积核的分解。
● B. Alternative Retraining – Sparsity Regularization
我们对分解之后的网络结构进行训练,来恢复原始的准确率,并在训练过程中应用一些正则化的方法得到稀疏的网络。
● C. Pruning – Unstructured Pruning
我们在训练之后对整个网络进行了剪枝。我们使用的是一种基于绝对值的剪枝方法。
● D. Model Shrinking – Structural Pruning
我们根据剪枝之后的网络去识别出一种冗余的结构,比如输入通道或者输出通道并直接去掉。
Kernel Decomposition
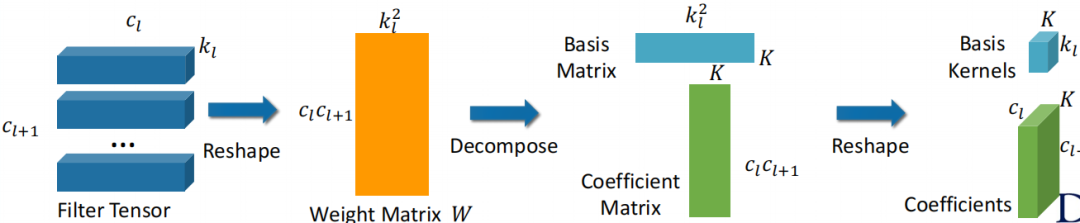
首先,我们来看如何进行卷积核的分解。通常的神经网络权值会表达出一种张量的形式。
我们的第一步就是把张量变形成一个矩阵。我们把输入和输出这两个通道合在一起,然后把卷积核的宽和高两个维度合在一起得到一个权值矩阵。
我们可以看到这个矩阵对应的每一行其实表征的是原来的卷积核,我们现在用一个向量而不是之前的二维形式去表示原来的卷积核。这一步之后,我们可以采用矩阵分解的方法,如奇异值分解。
我们再根据特征值排序来选择矩阵分解后的特征向量,也就是我们的新基向量。这样的过程也是把我们的原始矩阵投影到一个比较低维的空间。
在得到基的矩阵之后,我们同时可以得到一个投影矩阵,同时也可以把原始的卷积核投影到一个新的空间并得到一组系数矩阵。该矩阵的每一行代表如何用一组新的基的线性组合去得到一个原始的卷积核近似。
这样我们也就完成了矩阵分解的过程,达到了通过分解完成压缩的目的。
Retraining and Pruning
● 我们接下来对分解之后的网络进行训练,训练中会应用一个正则化的方法得到一个稀疏的稀疏矩阵。
● 第二步则是剪枝。根据训练之后的系数绝对值进行剪枝,并进行fine-tuning来恢复整个网络剪枝后识别的准确率。
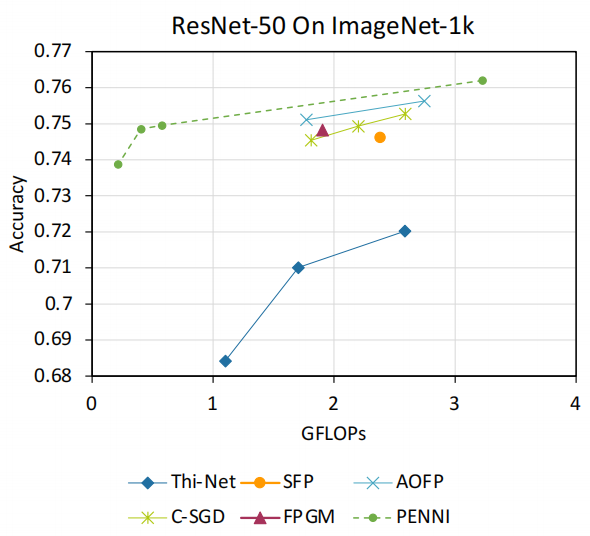
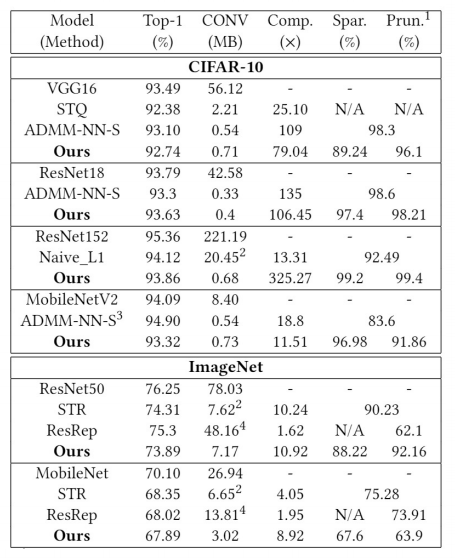
Experiments
我们把我们的框架和之前的一些结构化剪枝方法进行了对比,发现可以大幅图提高压缩比,并维持和之前方法相近的识别准确率。
● CIFAR-10:
■ VGG16: 93.26% FLOPs reduction with 0.4% accuracy loss
■ ResNet-56:79.4% FLOPs reduction with 0.2% accuracy loss
● ImageNet:
■ AlexNet:70.4% FLOPs reduction with 1% accuracy loss
■ ResNet-50:90.1% FLOPs reduction with ~1% accuracy loss
Computation Reorganization
说完了算法框架层面的,我们最终的目的是希望这样一种压缩分解的算法可以为我们加速器的设计提供一些指导,尤其是在之前压缩的部分会得到一个稀疏的系数。如何高效的利用这个稀疏系数,跳过所有冗余计算就是我们之后研究的目的。相关公式如下所示:
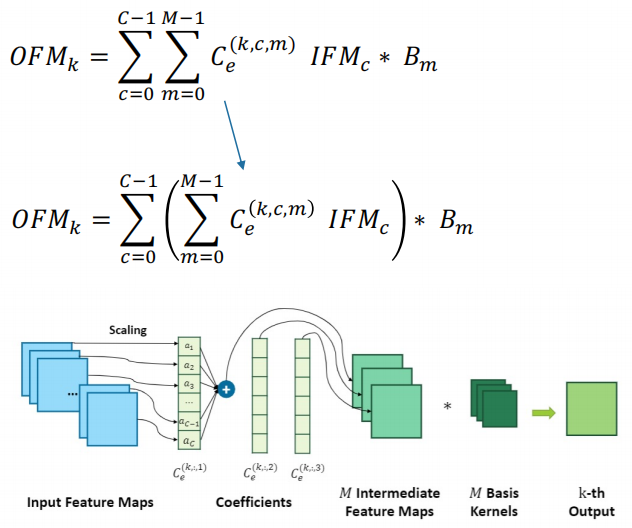
我们发现,卷积其实是一个线性操作。我们可以对这个运算顺序做出改变,先去计算输入特征图的线性组合,之后再对每个基的卷积核进行运算。虽然改变顺序的运算看起来非常简单,但是确实能为我们带来很多好处。
● 能够减少需要缓存的中间结果。
● 能够更好地重用输入特征图
Hybrid Quantization
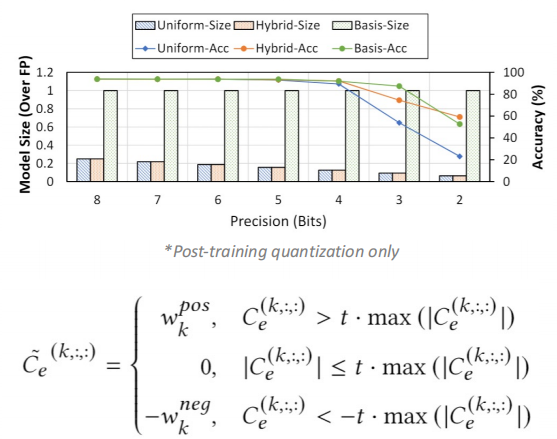
我们发现在分解之后,因为我们原始的权重分为两个部分——基的卷积核和系数。这两部分使用的频率也不同,基卷积核需要被所有的输入和输出通道所利用,而每个系数只会被一对输入和输出通道所利用。根据这个特点,我们可以给这两部分权重分别使用不同的精度——给基的权重使用高精度,给系数使用低精度。
这样做的好处是可以给我们的参数所需要的存储空间,低精度也有利于我们后续对硬件的稀疏处理。
我们最后的框架对这个基卷积核使用了8-bit进行量化,对系数使用了三值(2-bit)进行量化。
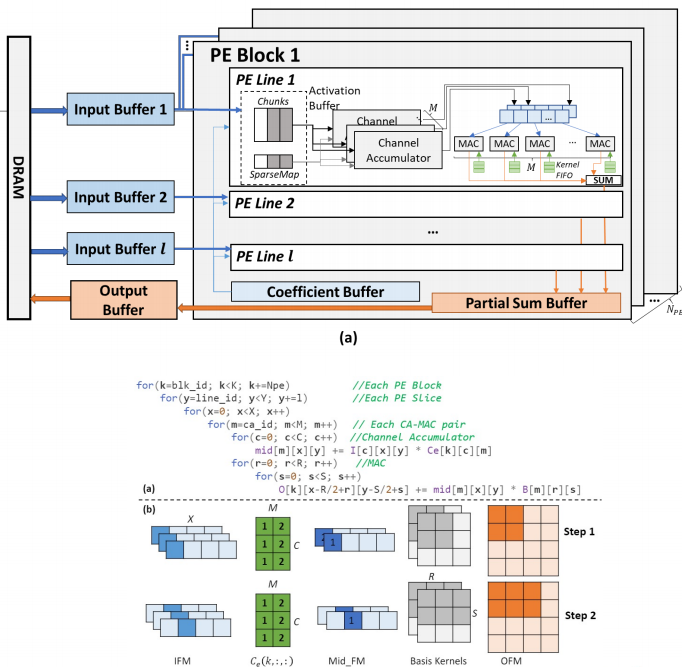
Architecture overview
在此前的基础上,我们提出了加速器的硬件设计。我们使用的也是一个层次化的设计,将所有的运算单元组合成块。每个块中又分成了行,每行中也分为两部分,一部分处理输入特征图的线性组合,另一部分处理卷积操作。
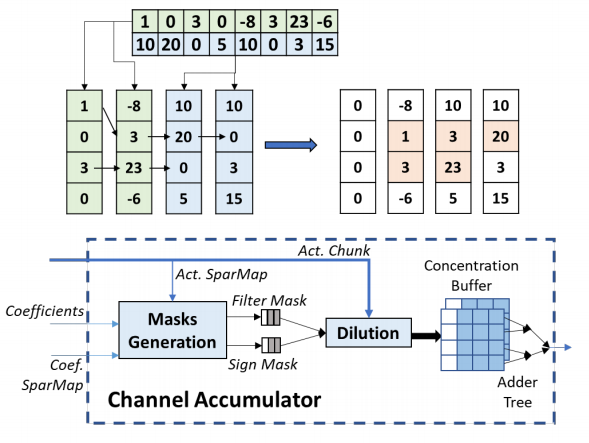
Dilution-Concentration
为了处理稀疏参数,我们提出了一个新的机制——Dilution-Concentration。这也是一个稀释和浓缩的过程,我们把稀疏特征的处理分为了两步:
● 稀释:我们匹配输入和权值中非0的值,并去掉其他的值.
● 浓缩:因为我们的权值只有正负,所有我们可以稀释之后的结果进行重新排序并将非0的值放在向量头部。
针对稀疏向量的编码,我们使用了一种SparseMap的编码形式。
我们也对每行分别进行编码,以保证运算单元的每一行可以同步的进行解码,从而提高整个运算的并行度。
整个的稀疏处理分为两步,第一步的稀释过程我们使用了Bit gather运算,该运算的目的就是把向量中的1收集在向量头部。这个操作可以使用蝴蝶网络来高效完成,在硬件设备上开销也是很低的。
该过程需要生成两个mask:
● Activation mask 当前输入元素中对应着非零特征值的元素
● Sign mask 在当前系数种选择对应着非0输入的稀疏,并用0和1来表征它的符号

第二步就是浓缩的过程。我们使用了look-ahead和look-aside这两种成熟的技巧在寄存器中寻找非0的值填进0值的位置,就可以得到一个稠密的向量。由于这两步是异步进行的,我们使用流水线的设计来提升整体的效率。
Input Buffer Design
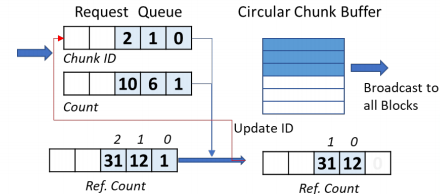
我们对输入的缓存进行设计,使用了一个环形的缓存结构来减少整个缓存的复杂度。因为所以运算单元的行是共享同一输入的,所以我们用缓存中保存计数器并对比的方法,判断当前数据是否已被所有运算单元读取。如果已经被读取,该空间就可以被用来读取新的数据。
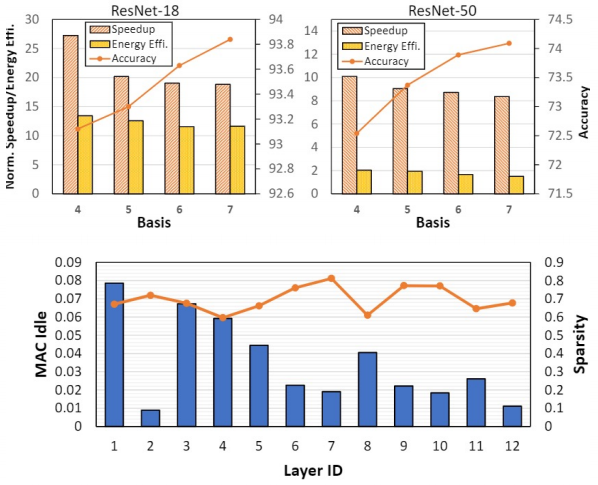
Algorithm Evaluation
之后的实验中,我们主要对比了我们的算法的压缩结果和非结构化剪枝的对比。我们能达到一个相同甚至更高的压缩比,当然会有一些准确度的损失,但相对较小。
Accelerator evaluation settings
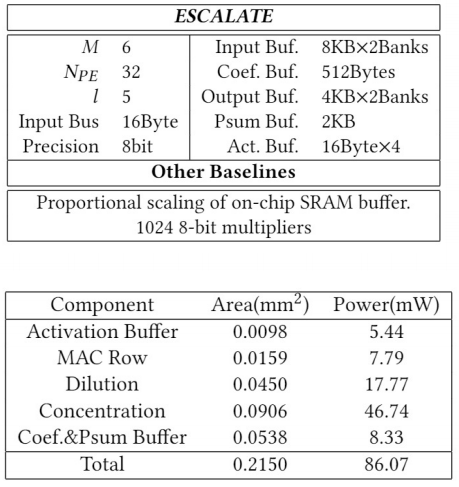
对于加速器的设计,我们将性能模型与之前加速器工作进行了对比。
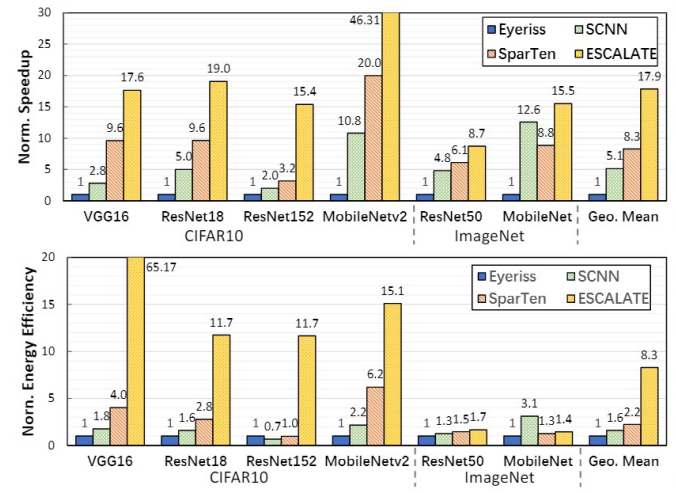
Speedup and Energy Efficiency
我们对比了加速和能效。
● 在CIFAR10 上,高稀疏度使得加速器能够及时生成中间特征映射。
● 在ImageNet上,CA需要更多的周期来输入特征图线性组合来产生一个中间元素,这导致MAC处于空闲状态,限制了加速。
● 总体上,我们和之前稀疏加速器和非结构化剪枝框架进行对比,平均可以达到一个2—3倍的加速效果。同时,我们的框架也可以通过调整压缩过程中的参数来确定是得到一个更高的识别准确率还是更高加速比。
提
醒
论文题目:
PENNI: Pruned Kernel Sharing for Efficient CNN Inference
ESCALATE: Boosting the Efficiency of Sparse CNN Accelerator with Kernel Decomposition
论文链接:
http://proceedings.mlr.press/v119/li20d.html
https://dl.acm.org/doi/abs/10.1145/3466752.3480043
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:李石宇
活动预告

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了700多位海内外讲者,举办了逾300场活动,超260万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!
边栏推荐
- ADS-NPU芯片架构设计的五大挑战
- IP storage and query in MySQL
- Test de vulnérabilité de téléchargement de fichiers basé sur dvwa
- SPIR-V初窺
- Format code_ What does formatting code mean
- VMware Tools安装报错:无法自动安装VSock驱动程序
- Development trend of Ali Taobao fine sorting model
- Leetcode1961. 检查字符串是否为数组前缀
- ThreeDPoseTracker项目解析
- [Yu Yue education] Liaoning Vocational College of Architecture Web server application development reference
猜你喜欢


随机推荐
Recommended areas - ways to explore users' future interests
GNSS terminology
SSH login is stuck and disconnected
Ubantu check cudnn and CUDA versions
What is weak reference? What are the weak reference data types in ES6? What are weak references in JS?
关于softmax函数的见解
[technology development -28]: overview of information and communication network, new technology forms, high-quality development of information and communication industry
ClickOnce 不支持请求执行级别“requireAdministrator”
[understanding of opportunity-39]: Guiguzi - Chapter 5 flying clamp - warning 2: there are six types of praise. Be careful to enjoy praise as fish enjoy bait.
Exciting, 2022 open atom global open source summit registration is hot
How to get the PHP version- How to get the PHP Version?
[day 30] given an integer n, find the sum of its factors
ADS-NPU芯片架构设计的五大挑战
Gartner released the prediction of eight major network security trends from 2022 to 2023. Zero trust is the starting point and regulations cover a wider range
【详细】快速实现对象映射的几种方式
Leetcode 208. Implement trie (prefix tree)
How does Huawei enable debug and how to make an image port
Unity | 实现面部驱动的两种方式
Leetcode skimming questions_ Verify palindrome string II
WordPress collection plug-in automatically collects fake original free plug-ins