当前位置:网站首页>Flink learning notes (10) Flink fault tolerance mechanism
Flink learning notes (10) Flink fault tolerance mechanism
2022-07-03 09:34:00 【Did Xiao Hu get stronger today】
List of articles
10. Flink Fault tolerance mechanism
In a distributed architecture , When a node fails , Other nodes are basically unaffected . At this time, you only need to restart the application , Restore the state at a certain point in time and continue processing . It all seems simple , But in real-time stream processing , We It is not only necessary to ensure that it can restart and continue to run after a fault , Also ensure the correctness of the results 、 Speed of fault recovery 、 To processability The impact of energy , This requires more sophisticated design in Architecture .
stay Flink in , There is a complete set of fault tolerance mechanism (fault tolerance) To ensure recovery after failure , One of the most important What we need is checkpoints (checkpoint).
10.1 checkpoint (Checkpoint)
In streaming , Save all the previous states at a certain time point , This “ The archive ” It's called “ checkpoint ” (checkpoint).
10.1.1 Save checkpoints
- Periodic trigger save
stay Flink in , check The saving of enumeration is triggered periodically , The interval time can be set . When the checkpoint save operation is triggered every other period of time , Copy the current status of each task , Put them together according to a certain logical structure and persist them , That makes up. checkpoint .
- The point in time of saving
When all tasks have just finished processing the same input data , Put their Save the State . First , This avoids the storage of additional information other than status , Improve the efficiency of checkpoint saving . secondly , A data is either completely processed by all tasks , The state is saved ; Or it's not finished , shape All States are not saved : This is equivalent to building a “ Business ”(transaction). If there is a fault , We recover to Status saved before , All data being processed at the time of failure needs to be reprocessed ; So we just need to make the source (source) The task resubmits the offset to the data source 、 Just request replay data .
The specific process of saving
Save checkpoints , The key is to wait until all tasks will “ The same data ” Finished processing .
When we need to save checkpoints (checkpoint) when , After all tasks have processed the same piece of data , Take a snapshot of the state and save it . As for the specific storage location , This is the configuration of the state backend term “ check check spot save Store ”( CheckpointStorage ) To decide , You can have the heap memory of the job manager (JobManagerCheckpointStorage) And file system (FileSystemCheckpointStorage) Two options . In general , Checkpoints are written to persistent distributed file systems .
10.1.2 Restore state from checkpoint
When running the stream handler ,Flink Checkpoints are saved periodically . When there is a breakdown , You need to find the latest Successfully saved checkpoints to restore the state .
(1) restart app
(2) Read checkpoints , Reset state
(3) Replay data
(4) Continue to process data
10.1.3 Checkpoint algorithm
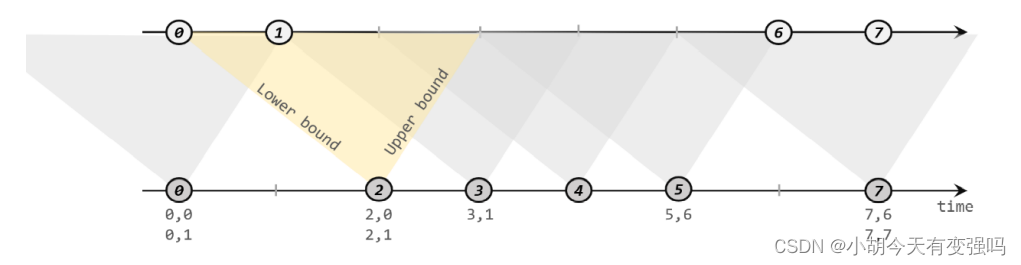
Flink The point in time when the checkpoint was saved , When all tasks have processed the same input data . But the type and value of the data will change after the task processing , How do different tasks know what to deal with “ The same ” Data? ? A simple idea is , When received JobManager After the instruction to save checkpoints is issued ,Source Operator task Pause and wait after processing the current data , No more reading new data . So it's better to , Without suspending the overall stream processing , Save status backups to checkpoints . stay Flink in , Based on Chandy-Lamport Distributed snapshot of the algorithm .
(1)JobManager Send instructions , Trigger the save of checkpoints ;Source Task save status , Insert boundary line
JobManager Periodically to every TaskManager Send a message with a new checkpoint ID The news of , Through this There are three ways to start checkpoints . Upon receipt of instructions ,TaskManger Will be in all Source Insert a dividing line in the task (barrier), And save the offset to the remote persistent storage .
(2) State snapshot save complete , The dividing line passes downstream
After the state is stored in persistent storage , Will return a notification to Source Mission ;Source The task will be to JobManager Confirm that the checkpoint is complete , Then put... Like data barrier Pass... To downstream tasks .
(3) Broadcast boundaries to multiple parallel subtasks downstream , Perform boundary line alignment
(4) After the boundary line is aligned , Save state to persistent storage
After the boundaries of each zone are aligned , You can take a snapshot of the current state , Saved to persistent storage . Storage complete after , Same will barrier Continue to transmit to the downstream , And notify JobManager Save completed .
(5) First process the cached data , Then continue processing normally .
10.1.4 Checkpoint configuration
- Enable checkpoints
By default ,Flink The program disables checkpoints . If you want to Flink The application turns on the function of automatically saving snapshots , You need to explicitly call the execution environment in your code .enableCheckpointing() Method :
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// every other 1 Start checkpoint save once per second
env.enableCheckpointing(1000);
- Checkpoint storage (Checkpoint Storage)
Checkpoint specific persistent storage location , Depending on “ Checkpoint storage ”(CheckpointStorage) Set up . Silent In case of recognition , Checkpoints are stored in JobManager A pile of (heap) In the memory . For the persistence of large states ,Flink It also provides an interface for saving in other storage locations , This is it. CheckpointStorage.
// Configure storage checkpoints to JobManager Heap memory
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());
// Configure storage checkpoints to the file system
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://namenode:40010/flink/checkpoints"));
- Other advanced configurations
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Enable checkpoints , Time interval between 1 second
env.enableCheckpointing(1000);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
// Set precise once mode
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// Minimum interval time 500 millisecond
checkpointConfig.setMinPauseBetweenCheckpoints(500);
// Timeout time 1 minute
checkpointConfig.setCheckpointTimeout(60000);
// There can only be one checkpoint at a time
checkpointConfig.setMaxConcurrentCheckpoints(1);
// Open external persistent save of checkpoints , The job is still retained after cancellation
checkpointConfig.enableExternalizedCheckpoints(
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// Enable misaligned checkpoint save
checkpointConfig.enableUnalignedCheckpoints();
// Set checkpoint storage , You can pass in a String, Specify the path of the file system
checkpointConfig.setCheckpointStorage("hdfs://my/checkpoint/dir")
10.1.5 Save it (Savepoint)
Except for checkpoints (checkpoint) Outside ,Flink It also provides another very unique image saving function —— Save it (Savepoint). Its principle and algorithm are exactly the same as that of checkpoint , Just more Some additional metadata . in fact , A savepoint is a consistency mirror that creates the state of a streaming job through a checkpoint mechanism image (consistent image) Of .
- Purpose of savepoint
The biggest difference between savepoints and checkpoints , It's the time to trigger . Checkpoints are made by Flink Automatically managed , Create... On a regular basis , Automatic reading for recovery after failure , This is a “ Auto save ” The function of ; Savepoints are not automatically created , have to The save operation must be explicitly triggered manually by the user , So is “ Manual save ”. Therefore, although the principles of the two are consistent , But use There is a difference : Checkpoints are mainly used for fault recovery , Is the core of fault tolerance mechanism ; Savepoints are more flexible , It can be used To do planned manual backup and recovery .
(1) Version management and archive storage
(2) to update Flink edition
(3) Update the application
(4) Adjust parallelism
(5) Suspend the application
- Use savepoints
(1) Create a savepoint
bin/flink savepoint :jobId [:targetDirectory]
jobId You need to fill in the jobs to save the image ID, The target path targetDirectory Optional , Indicates the save point Storage path .
Default path for savepoints , Configuration files are available flink-conf.yaml Medium state.savepoints.dir Item to set set :
state.savepoints.dir: hdfs:///flink/savepoints
(2) Restart the application from the savepoint
bin/flink run -s :savepointPath [:runArgs]
10.2 State consistency
simply , In fact, consistency is the result of correctness . For distributed systems , It emphasizes the phase in different nodes Copies of the same data should always “ coincident ”, That is, when reading from different nodes, you can always get the same value .
边栏推荐
- Logstash+jdbc data synchronization +head display problems
- LeetCode每日一题(2232. Minimize Result by Adding Parentheses to Expression)
- [set theory] order relation (chain | anti chain | chain and anti chain example | chain and anti chain theorem | chain and anti chain inference | good order relation)
- Hudi learning notes (III) analysis of core concepts
- Basic knowledge of database design
- 【Kotlin学习】类、对象和接口——定义类继承结构
- ERROR: certificate common name “*.” doesn’t match requested ho
- Django operates Excel files through openpyxl to import data into the database in batches.
- Beego learning - Tencent cloud upload pictures
- PIP configuring domestic sources
猜你喜欢

Idea uses the MVN command to package and report an error, which is not available
Learning C language from scratch -- installation and configuration of 01 MinGW
Spark cluster installation and deployment

Redis learning (I)
Hudi 快速体验使用(含操作详细步骤及截图)
Go language - JSON processing

Hudi学习笔记(三) 核心概念剖析
Flink学习笔记(八)多流转换

Construction of simple database learning environment

CATIA automation object architecture - detailed explanation of application objects (III) systemservice
随机推荐
Flask+supervisor installation realizes background process resident
Leetcode daily question (1856. maximum subarray min product)
WARNING: You are using pip ; however. Later, upgrade PIP failed, modulenotfounderror: no module named 'pip‘
Vscode Arduino installation Library
[kotlin learning] operator overloading and other conventions -- overloading the conventions of arithmetic operators, comparison operators, sets and intervals
Alibaba cloud notes for the first time
Using Hudi in idea
LeetCode每日一题(2232. Minimize Result by Adding Parentheses to Expression)
Spark overview
Crawler career from scratch (I): crawl the photos of my little sister ① (the website has been disabled)
LeetCode每日一题(2305. Fair Distribution of Cookies)
Spark 概述
Win10安装ELK
Global KYC service provider advance AI in vivo detection products have passed ISO international safety certification, and the product capability has reached a new level
数字身份验证服务商ADVANCE.AI顺利加入深跨协 推进跨境电商行业可持续性发展
Explanation of the answers to the three questions
Run flash demo on ECS
What do software test engineers do? Pass the technology to test whether there are loopholes in the software program
Idea uses the MVN command to package and report an error, which is not available
Derivation of Fourier transform