当前位置:网站首页>[course notes] Compilation Principle
[course notes] Compilation Principle
2022-07-06 05:55:00 【starbuling~】
thank Bilibili University Of To love , In the grammar analysis part, her explanation video provided great help
- The introduction
- Introduction to formal language
- Lexical analysis
- Syntax analysis
- Semantic analysis and intermediate code generation
- Code optimization
- The symbol table
The introduction
The concept of compiler
Program : A series of instructions or statements , It is used to describe a series of tasks that a computer should perform in turn . In essence, it describes the processing process of certain data
The hierarchy of the program :
structure : Basic symbols ( Letter , Array , Symbols etc. )、 word 、 expression 、 sentence 、 Subprogram 、 Program
Programming language : All programs in this language
- grammar 、 semantics 、 pragmatics
- grammar : It indicates the Combination law
It describes the structure of the program , According to it, the correct program can be generated ( Lexical Rules , Rule of grammar ).
Grammar rules and lexical rules define the formal structure of a program , Defining the meaning of grammatical units is a semantic problem .- Lexical Rules : The formation rules of word symbols ( Word symbol is the most basic structure with independent meaning in language )
- Include : constant 、 identifier 、 Basic words 、 operator 、 Boundary symbol ( comma 、 A semicolon 、 Brackets 、 blank )
- Describe the tool : Finite automaton
- Rule of grammar : The formation rules of grammatical units
- Include : expression 、 sentence 、 Subprogram 、 The process 、 function 、 Program
- Describe the tool : Context-free grammar
- Lexical Rules : The formation rules of word symbols ( Word symbol is the most basic structure with independent meaning in language )
- semantics : Represents the specific of each token represented by various representation methods meaning
Is the meaning of language components , It is explained by the effect of program execution . The relationship between each token and the object represented by the token . - pragmatics : Indicates in the behavior of each mark , Their source 、 Use and impact
compiler : Translate the program into assembly language program or machine language program ( Target program ), Then execute the translation program
The build process
The main process :
Grammatical analysis produces grammatical units ; Before the object code is quaternion
Lexical analysis : Read the source program of character stream from left to right , Recognize words and express them into machine expressions
Syntax analysis : According to the grammar rules of the source program, the sequence of words of the source program is formed into grammatical phrases
Semantic analysis : Analyze the semantics of grammatical units given by the parser
Intermediate code generation : Internal representation of the source program ( Ternary form 、 Quaternion 、 Reverse Polish notation )
Code optimization : Equivalent transformation of code to improve execution efficiency [ Running speed 、 Save storage space ]( Machine related 、 Machine independent )
Target code generation
Symbol table management : Every step involves
front end : morphology 、 grammar 、 semantics 、 Intermediate code generation , Machine independent code optimization
Back end : Machine related code optimization 、 Target code generation
It's easy to transplant programs
All over
Scan the source program or the middle representation of the source program from beginning to end
- A passage can consist of several paragraphs
- A stage can also be completed several times
Formal linguistic automata
formal language : Language only in the grammatical sense
alphabet ∑ \sum ∑: A nonempty finite set of elements
Symbol : Elements in the alphabet
Grammar : Formal rules or grammatical rules that describe the grammatical structure of a language
effect : Use finite sets to express infinite sentences
Grammatical quadruple : G ( V N , V T , P , S ) G(V_N,V_T,P,S) G(VN,VT,P,S), Short for G [ S ] G[S] G[S]
V => W: V Directly deduce W,W The direct specification is V
Sentence pattern = { x ∣ S ⇒ ∗ x , And x ∈ V ∗ } \{x|S \stackrel{*}{\Rightarrow} x ,\ And \ x\in V^* \} { x∣S⇒∗x, And x∈V∗}, Identification symbols S It's also a sentence pattern
The sentence = x , ( S ⇒ + x , And x ∈ V T ∗ ) x, (S \stackrel{+}{\Rightarrow} x ,\ And \ x\in V_T^* ) x,(S⇒+x, And x∈VT∗), x x x Composed of terminal symbols only , Sentences are also sentence patterns
Language L ( G ) = { x ∣ S ⇒ + x , And x ∈ V T ∗ } L(G) = \{x|S \stackrel{+}{\Rightarrow} x ,\ And \ x\in V_T^* \} L(G)={ x∣S⇒+x, And x∈VT∗}, Grammar G A collection of all sentences
Grammatical equivalence : L ( G 1 ) = L ( G 2 ) L(G_1) = L(G_2) L(G1)=L(G2)
Types of grammar : For any production α → β \alpha \rightarrow \beta α→β,
- 0 Type grammar : α ∈ ( V N ∪ V T ) + , β ∈ ( V N ∪ V T ) ∗ \alpha \in (V_N \cup V_T)^+,\ \ \beta \in (V_N \cup V_T)^* α∈(VN∪VT)+, β∈(VN∪VT)∗
- 1 Type grammar ( Context sensitive ): ∣ β ∣ ≥ ∣ α ∣ , S → ϵ except Outside |\beta| \ge |\alpha|, \ \ S \rightarrow \epsilon With the exception of ∣β∣≥∣α∣, S→ϵ except Outside
- 2 Type grammar ( Context free ): α ∈ V N , β ∈ ( V N ∪ V T ) ∗ \alpha \in V_N,\ \ \beta \in (V_N \cup V_T)^* α∈VN, β∈(VN∪VT)∗
- 3 Type grammar ( Regular ): The forms are A → a B or A → a , A ∈ V N , B ∈ V N , a ∈ V T A \rightarrow aB or \ A \rightarrow a,\ A \in V_N, B\in V_N, a\in V_T A→aB or A→a, A∈VN,B∈VN,a∈VT
Context sensitive : α 1 A α 2 → α 1 β α 2 \alpha_1A\alpha_2 \rightarrow \alpha_1\beta\alpha_2 α1Aα2→α1βα2, A ∈ V N , Its He yes V ∗ , β ≠ ϵ A\in V_N, The others are V^*, \beta \ne \epsilon A∈VN, Its He yes V∗,β=ϵ
Context free : A → β A \rightarrow \beta A→β, A ∈ V N , β ∈ V ∗ A \in V_N, \beta \in V^* A∈VN,β∈V∗
Grammar tree
Leftmost inference : Any step α ⇒ β \alpha \Rightarrow \beta α⇒β All right. α \alpha α The most Left Substitution of nonterminal
Rightmost derivation : Any step α ⇒ β \alpha \Rightarrow \beta α⇒β All right. α \alpha α The most Right Substitution of nonterminal
Pushing to the right is called canonical derivation . The sentence patterns derived from norms are called normative sentence patterns
Grammatical ambiguity : A grammar has a sentence corresponding to two different grammar trees ( The grammar books derived from the leftmost and rightmost are different )
The phrase : Leaf nodes of internal nodes
Direct phrase : Directly growing leaf nodes
The prime phrase : In the phrase (1) Contains at least one Terminator (2) There are no other smaller prime phrases
Handle : The symbol string corresponding to the leftmost and smallest tree . The leftmost direct phrase
1
2
Lexical analysis
Basic concepts
Types of word symbols : Basic words 、 identifier 、 constant 、 Operator 、 Boundary symbol ( comma 、 A semicolon 、 Brackets 、 blank )
Normal form and normal set :
A normal set can be expressed as a normal expression ( Normal form ) Express
A normal expression is a way to represent a normal set
A set of words is a normal set if and only if it can be expressed in a normal form
ϵ \epsilon ϵ and ϕ \phi ϕ All are ∑ \sum ∑ Normal form on , The normal set they represent is { ϵ } \{\epsilon\} { ϵ} and ϕ \phi ϕ
The normal set is the word set of the program
The normal form is lexical rules
Determine finite automata (DFA)
automata Pentagram M = ( S , ∑ , f , S 0 , F ) M = (S, \sum, f, S_0, F) M=(S,∑,f,S0,F)
S S S: Finite state set
∑ \sum ∑: Enter the alphabet
f f f: State transition functions ( Single valued mapping )
S 0 S_0 S0: Unique initial state
F F F: The final set ( Can be empty )
Uncertain finite automata (NFA) Pentagram , The difference is that :
f f f: State transition functions ( Non single value )
S 0 S_0 S0: Initial state set
- There are multiple initial states
- The mark on the arc can be a word or even a normal form
- The same word may appear on multiple arcs emitted in the same state
Conclusion : There is an algorithm to determine the equivalence of two automata
NFA Convert to equivalent DFA( Determinate )
- Introduce new initial state nodes X And end state nodes Y, from X Introduce a line to any node in the initial state set ϵ \epsilon ϵ arc , Introduce one from each node in the final state set ϵ \epsilon ϵ arc
- Change the state transition diagram to mark each arc as ∑ \sum ∑ A character on or ϵ \epsilon ϵ
- Construction table
DFA The basic idea of minimization :
hold M The state set of is divided into some unwanted ones , Make the state of any two different subsets distinguishable ( Not equivalent ), And any two states of the same subset are equivalent
Syntax analysis —— Top down analysis
Left recursion & to flash back
key problem :
- Eliminate left recursion
- Eliminate backtracking
First & Follow
Definition
G = ( V T , V N , S , P ) G = (V_T,V_N,S,P) G=(VT,VN,S,P) It's context free grammar
F i r s t ( α ) = { a ∣ α ⇒ ∗ a β , a ∈ V T , α , β ∈ V ∗ } First(\alpha) = \{a | \alpha \stackrel{*}{\Rightarrow} a\beta, a\in V_T, \alpha,\beta \in V^* \} First(α)={ a∣α⇒∗aβ,a∈VT,α,β∈V∗}, if α ⇒ ∗ ϵ \alpha \stackrel{*}{\Rightarrow} \epsilon α⇒∗ϵ, It stipulates that ϵ ∈ F i r s t ( α ) \epsilon \in First(\alpha) ϵ∈First(α)
- The first terminator
F o l l o w = a ∣ S ⇒ ∗ μ A β , a ∈ F i r s t ( β ) , μ ∈ V ∗ , β ∈ V + Follow = {a | S \stackrel{*}{\Rightarrow} \mu A\beta, a \in First(\beta), \mu \in V^*, \beta \in V^+ } Follow=a∣S⇒∗μAβ,a∈First(β),μ∈V∗,β∈V+
- β \beta β The first terminator of the string
- meaning : A set of terminators that may be followed by grammatical symbols , It doesn't contain ϵ \epsilon ϵ
- Purpose : If launched ϵ \epsilon ϵ, What string is followed
How to find
First Set to the left of production ,Follow Set to see the right part of production
First:
- If the first one on the right is a terminator , Then join the set
- If the first one on the right is a non terminator , It is First Set join set
Follow:( in the light of B)
- Grammar starter , There must be #
- Situation 1 ( There's nothing in the back ):A -> α B \alpha B αB FOLLOW(B) B Empty after , Will FOLLOW(A) Add to FOLLOW(B) in
- Situation two ( There's something in the back ):A -> α B β \alpha B\beta αBβ
- β \beta β It's the terminator , Write it down directly
- β \beta β Yes no terminator ,first( β \beta β) remove ϵ \epsilon ϵ Add to follow(B)
- If β → ϵ \beta \rightarrow \epsilon β→ϵ , Then turn back to case 1
1:
Example 2:
LL(1)
meaning :
- first L: Top down analysis is Scan from left to right Input string
- the second L: Used during analysis Leftmost inference
- 1: just Look right at a symbol Then you can decide how to deduce ( Choose which production formula to deduce )
similar LL(K), Look ahead K Symbols
Select
Analysis conditions ( Judge a grammar as LL(1) Grammar ):
- Grammar does not contain left recursion
- For every non terminator in grammar A A A Any two productions of α i \alpha_i αi and α j \alpha_j αj, That's the case : A → α i ∣ α j A \rightarrow \alpha_i | \alpha_j A→αi∣αj
- If the candidate prefix set does not contain ϵ \epsilon ϵ : F i r s t ( α i ) ∩ F i r s t ( α j ) = ϕ First(\alpha_i) \cap First(\alpha_j) = \phi First(αi)∩First(αj)=ϕ
- If it has a candidate header set, it contains ϵ \epsilon ϵ, be F i r s t ( A ) ∩ F o l l o w ( A ) = ϕ First(A) \cap Follow(A) = \phi First(A)∩Follow(A)=ϕ
extraction Select Set : A → α , A ∈ V N , α ∈ V ∗ A \rightarrow \alpha, A\in V_N, \alpha \in V^* A→α,A∈VN,α∈V∗
- α ⇒ ∗ ϵ \alpha \stackrel{*}\Rightarrow \epsilon α⇒∗ϵ : S e l e c t ( A → α ) = ( F i r s t ( α ) − ϵ ) ∪ F o l l o w ( A ) Select(A\rightarrow \alpha) = (First(\alpha)-\epsilon) \cup Follow(A) Select(A→α)=(First(α)−ϵ)∪Follow(A)
- α ⇏ ∗ ϵ \alpha \stackrel{*}\nRightarrow \epsilon α⇏∗ϵ : S e l e c t ( A → α ) = F i r s t ( α ) Select(A\rightarrow \alpha) = First(\alpha) Select(A→α)=First(α)
therefore LL(1) The condition of grammar is :
For each non Terminator A Any two productions of , All satisfied with S e l e c t ( A → α ) ∪ S e l e c t ( A → β ) = ϕ Select(A\rightarrow \alpha) \cup Select(A\rightarrow \beta) = \phi Select(A→α)∪Select(A→β)=ϕ

Forecast analysis table M M M Construction method of
- To grammar G G G Every production of A → α A \rightarrow \alpha A→α perform 2,3 【 According to the production structure analysis table 】
- For each Terminator a ∈ F i r s t ( α ) a \in First(\alpha) a∈First(α), hold A → α A \rightarrow \alpha A→α Add to M [ A , a ] M[A,a] M[A,a]
- if ϵ ∈ F i r s t ( α ) \epsilon \in First(\alpha) ϵ∈First(α), That is, you can launch an empty string , For anything b ∈ F o l l o w ( A ) b\in Follow(A) b∈Follow(A) hold A → α A \rightarrow \alpha A→α Add to M [ A , b ] M[A,b] M[A,b]
- Put all the undefined M [ A , a ] M[A,a] M[A,a] Mark “ Error flag ”
Example :
When constructing , see First Set , Find the corresponding production and write it in the corresponding position ; If there is \epsilon, Then look at Follow Set , Write the production in the corresponding position 
Syntax analysis —— Bottom up analysis
The basic idea : Start with the input string , Step by step “ Statute ”, Until the beginning of grammar . That is, from the end of the tree , Construct syntax tree .
Statute : According to the production rules of grammar , Replace the right part of the production with the left symbol .“ Move in - Statute ” thought
key problem : Precise definition “ A string of rules ” This intuitive concept
- Operator first analysis —— The leftmost prime phrase
- Rules and regulations —— Handle
Rules and regulations
G G G It's grammar , S S S Is the beginning sign , α β δ \alpha \beta \delta αβδ It is a sentence pattern of grammar ,
If there is :$ S \stackrel{*}{\Rightarrow} \alpha A \delta$ , A ⇒ + β A \stackrel{+}{\Rightarrow} \beta A⇒+β, be β \beta β It's sentence pattern α β δ \alpha \beta \delta αβδ Relative to the nonterminal A Of The phrase
Especially if there is : A ⇒ β A \Rightarrow \beta A⇒β, be β \beta β It's sentence pattern α β δ \alpha \beta \delta αβδ Relative to the rules A → β A \rightarrow \beta A→β The direct phrase of
The leftmost direct phrase of a sentence pattern is called the Handle ( Uniqueness ). For standard sentence patterns , Only terminators can appear after the handle .
Use handle as “ A string of rules ” The specification process is the standard specification , Also known as the leftmost Protocol , Because the rightmost derivation in formal language is often called canonical derivation , If grammar is unambiguous , Then the inverse process of specification derivation must be specification
In the grammar tree corresponding to a sentence pattern :
- Rooted in a non terminator All end nodes of subtrees of more than two generations are arranged from left to right Is a relative to the non terminator The phrase
- If The subtree has only two generations , Then the phrase is Direct phrase
The prime phrase : A grammar G The prime phrase of the sentence pattern of means that it contains at least one terminator , And it doesn't contain any smaller prime phrases except itself
The leftmost prime phrase : The prime phrase on the far left of the sentence pattern
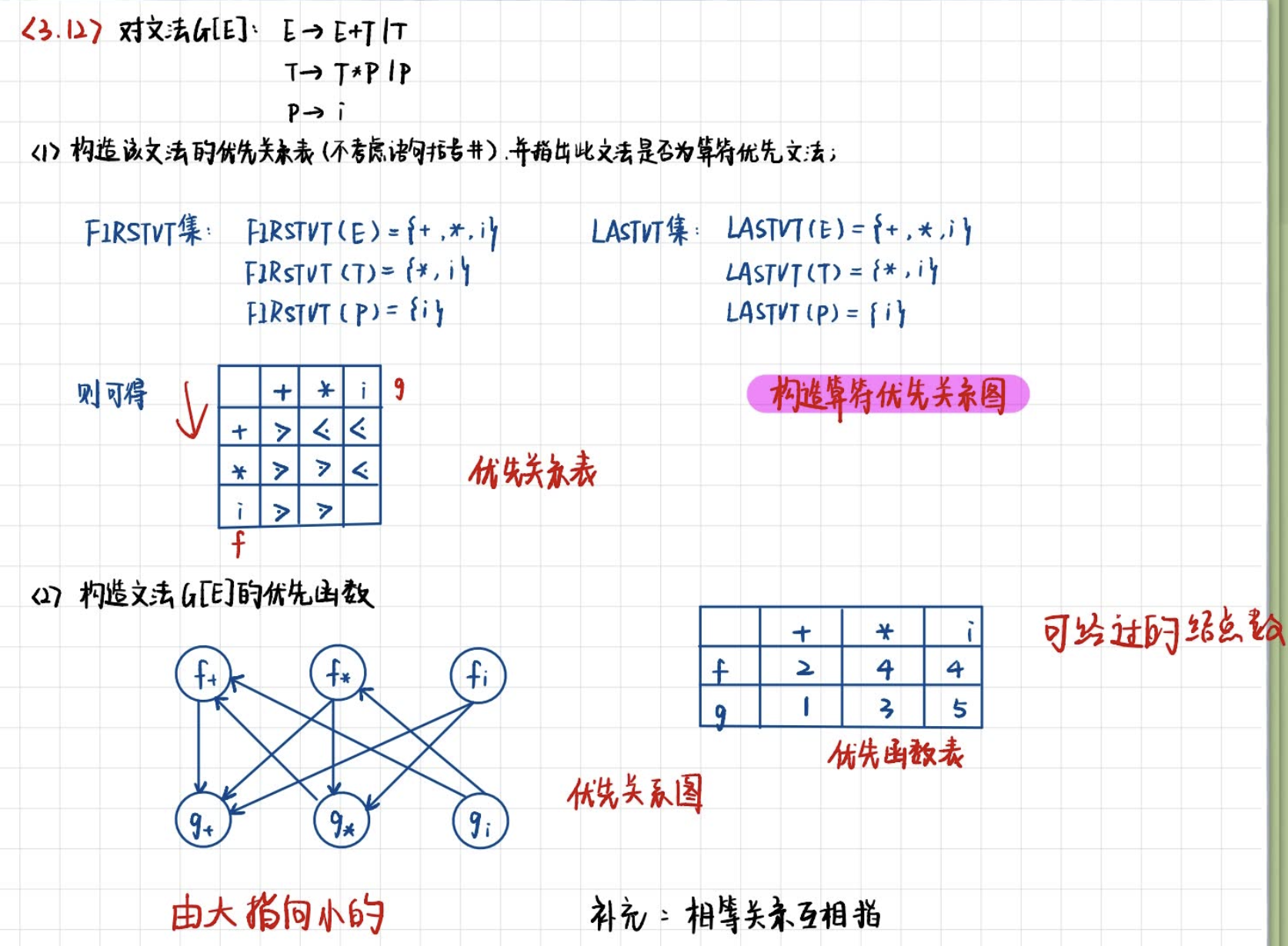
: Grammar G(E):
(1) E -> E+T | T
(2) T -> T*F | F
(3) F -> P ↑ \uparrow ↑F | F
(4) P -> (E) | i
For sentence patterns : T+F*P+i
The phrase :T, F, P, i, F*P, T+F*P, T+F*P+i ( Leaf nodes of subtrees of more than two generations )
Direct phrase :T, F, P, i ( Leaf nodes of two generations of subtrees )
Handle :T ( The leftmost direct phrase )
The prime phrase :F*P, i ( The deepest phrase )
The leftmost prime phrase :F*P
Simple priority analysis
Priority relation table
- a ≐ b a \doteq b a≐b: To form such as P -> …ab… or P -> …aQb… Generative formula
- a ⋖ b a \lessdot b a⋖b: To form such as P -> …aP…, Yes b ∈ F i r s t v t ( P ) b \in Firstvt(P) b∈Firstvt(P)
- a ⋗ b a \gtrdot b a⋗b: To form such as P -> …Pa…, Yes a ∈ L a s t v t ( P ) a \in Lastvt(P) a∈Lastvt(P)
FirstVT: The first terminator
LastVT: The last terminator
Basic concepts
Operator priority analysis is not a normative method
Operator grammar : If the right part of any production does not contain two successive ( Juxtaposition ) The nonterminal of , That is, it does not contain the form such as …QR… Production right of form
Algorithm for constructing priority relation table
According to the expression :
- Find out everything first a ≐ b a\doteq b a≐b The terminator pair of .
- structure Fitstvt and Lastvt aggregate
- If there is a production P -> a… or P -> Qa…, be a ∈ F i r s t v t ( P ) a \in Firstvt(P) a∈Firstvt(P)
- if a ∈ F i r s t v t ( Q ) a \in Firstvt(Q) a∈Firstvt(Q), And there's production P -> Q… be a ∈ F i r s t v t ( P ) a \in Firstvt(P) a∈Firstvt(P)
- If there is a production p -> …a or P -> …aQ, be a ∈ L a s t v t ( P ) a \in Lastvt(P) a∈Lastvt(P)
- if a ∈ L a s t v t ( Q ) a \in Lastvt(Q) a∈Lastvt(Q), And there's production P -> …Q be a ∈ L a s t v t ( P ) a \in Lastvt(P) a∈Lastvt(P)
- Check the candidate relationship of each production to ensure that ⋖ \lessdot ⋖ and ⋗ \gtrdot ⋗ All terminator pairs of ( The known is always smaller than the unknown )
Example 
Operator first analysis (OPG)
Operator precedence grammar sentence pattern : N 1 a 1 N 2 a 2 . . . N n a n N n + 1 N_1a_1N_2a_2...N_na_nN_{n+1} N1a1N2a2...NnanNn+1, Each of them a i a_i ai Are terminators , N i N_i Ni Is a dispensable non terminator
An operator precedence grammar G The leftmost prime phrase of any sentence pattern of is the leftmost substring that meets the following conditions :
N j a j N j + 1 a j + 1 . . . N i a i N i + 1 , Its in a j − 1 ⋖ a j , a j ≐ a j + 1 , . . . , a i − 1 ≐ a i , a i ⋗ a i + 1 N_j a_j N_{j+1} a_{j+1}...N_i a_i N_{i+1},\ among a_{j-1} \lessdot a_j,\ a_j \doteq a_{j+1},...,\ a_{i-1} \doteq a_i,\ a_i \gtrdot a_{i+1} NjajNj+1aj+1...NiaiNi+1, Its in aj−1⋖aj, aj≐aj+1,..., ai−1≐ai, ai⋗ai+1
Operator first analysis algorithm :
Maintain a monotonous stack of operator selection Relations , If the first terminator at the top of the stack ⋗ \gtrdot ⋗ Currently facing input string characters , Then a paragraph with ≐ \doteq ≐ A string in the stack of relationships . Use a production formula to regulate , The right part of this production corresponds to the pop-up string from bottom to top from left to right , Terminator to terminator , Non terminator to non terminator ( Only the corresponding terminator is required to be the same )
When the algorithm finishes its work , Symbol stack S Should present #N#,N It's a nonterminal , But it is not necessarily the starting symbol
Operator first analysis is much faster than specification , Because we skipped all the simple non production ( Form like P->Q)
The key problem of operator priority analysis is —— Looking for leftmost prime phrases
LR analysis
Definition : It is a bottom-up grammatical analysis method of normative specification
The essence : It is a memory with first in and last out ( Stack ) Deterministic finite state automata
L: Scan the input string from left to right
R: Construct an inverse process of the rightmost derivation
Four operation actions : Move in 、 Statute 、 Accept 、 Report errors
hold “ history ” and “ expectation ” The abstraction becomes state , Combined with the current input symbol reality Information , Can finish LR analysis
LR Grammar :
LR Grammar : Be able to construct an analysis table , Each of its entrances is uniquely identified
LR(K) Grammar : You can check forward at most with one step K Number of input symbols LR Analyzer for analysisNot all context free grammars are LR Grammar
LR Grammar is not ambiguous , Ambiguous grammar is definitely not LR Of
Prefix of words : The first part of the word , Including empty strings ϵ \epsilon ϵ
Live prefix : A prefix to a normal sentence pattern , This prefix does not contain any symbols after the handle ( These symbols must be terminator strings )
In the process of specification , Ensure that there is always a live prefix in the analysis stack , Explain the move in taken by the analysis / The conventional action is correct
project :G Grammar G Add a dot to the right of each production of called G Of LR(0) Project
A → ϵ A \rightarrow \epsilon A→ϵ Only one item :$A \rightarrow \ \cdotp $
Grammatical LR(0) Project specification family : Constituting the recognition of a grammatical prefix DFA All of the project set
Protocol project ( ⋅ \cdotp ⋅ In the end ): A → α ⋅ A \rightarrow \alpha \cdotp A→α⋅
Accept the project ( Start grammar corresponding to ): S ′ → α ⋅ S' \rightarrow \alpha \cdotp S′→α⋅
Move into the project ( ⋅ \cdotp ⋅ Followed by the Terminator ): A → α ⋅ a β , ( a ∈ V T ) A \rightarrow \alpha \cdotp a\beta, (a \in V_T) A→α⋅aβ,(a∈VT)
Projects to be contracted ( ⋅ \cdotp ⋅ Followed by a non Terminator ): A → α ⋅ B β , ( B ∈ V N ) A \rightarrow \alpha \cdotp B\beta, (B \in V_N) A→α⋅Bβ,(B∈VN)
Effective projects : anytime , Analyze the live prefix in the stack x 1 x 2 . . . x m x_1 x_2 ... x_m x1x2...xm The most effective item set is the top of the stack state S m S_m Sm The set represented by
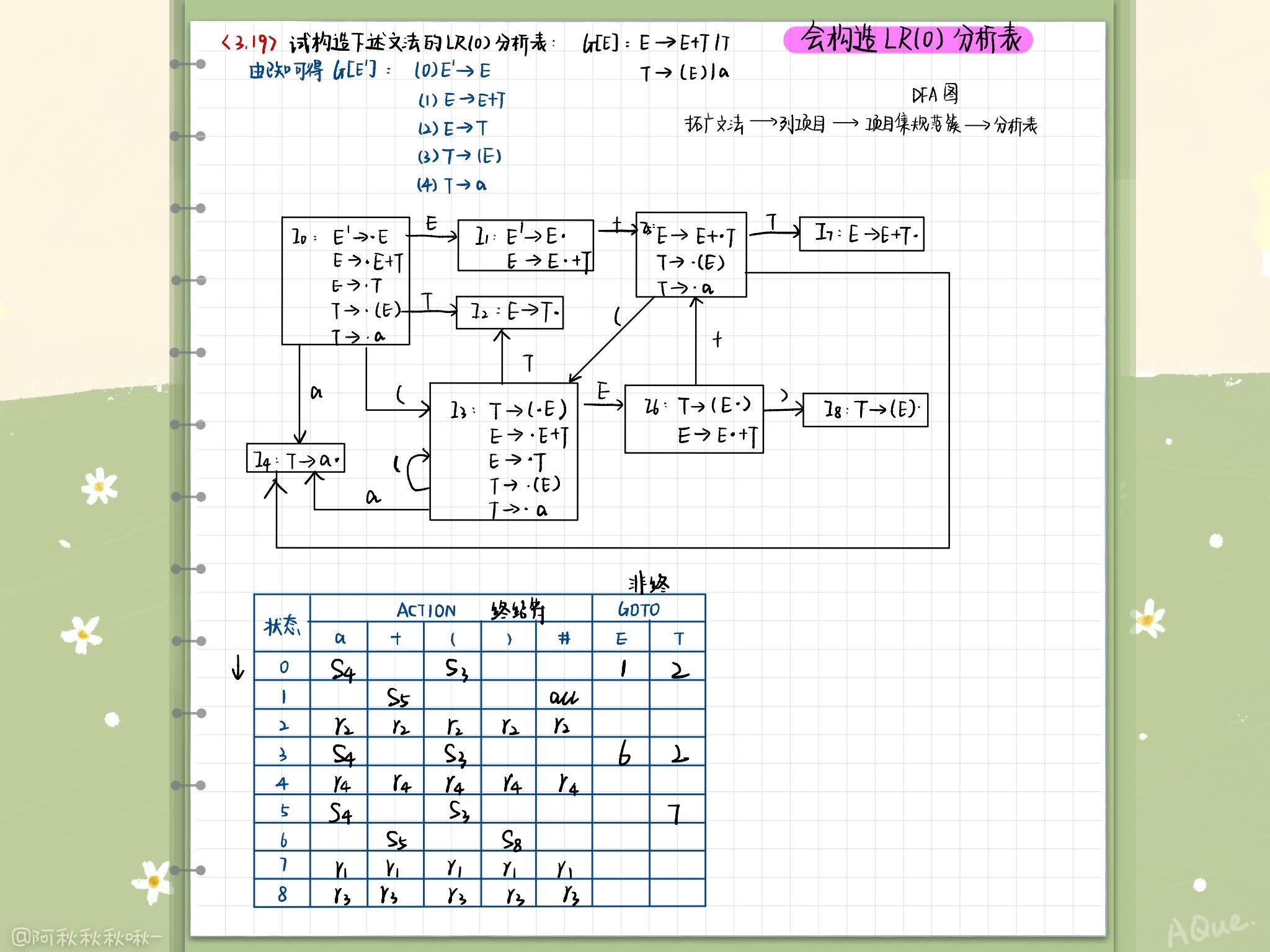
LR(0) Project set specification family construction
Transforming grammar , Introduce unique “ Receiving state ” Generative formula S’ -> S
Calculation Closure(I) and Go(I,X)
Go(I,x) = Closure(J), among J = { Any shape A-> α x ⋅ β \alpha x\cdotp \beta αx⋅β | A-> α ⋅ x β \alpha \cdotp x\beta α⋅xβ Belong to I}
Intuitively , if I It's a live prefix γ \gamma γ Valid item set , that Go(I,x) That's right γ x \gamma x γx A valid project set
With {Closure({S’->S})} For state 0, utilize Go Function connects the item set into one DFA Conversion chart
Construct according to the following rules Action Sub tables and Goto Sub table
- If the project A A A-> α ⋅ β \alpha \cdotp \beta α⋅β Belong to I k I_k Ik And G o ( I k , a ) = I j Go(I_k,a)=I_j Go(Ik,a)=Ij, a a a For the Terminator , be A c t i o n [ k , a ] = S j Action[k,a]=S_j Action[k,a]=Sj
- If the project A → α ⋅ A \rightarrow \alpha \cdotp A→α⋅ Belong to I k I_k Ik , So for any terminator a a a( Or terminator #), A c t i o n [ k , a ] = γ j Action[k,a] = \gamma_j Action[k,a]=γj
- If the project S ’ → S ⋅ S’ \rightarrow S\cdotp S’→S⋅ Belong to I k I_k Ik, A c t i o n [ k , # ] = a c c Action[k,\#] = acc Action[k,#]=acc
- if Go(I_k,A) = I_j, A It's a nonterminal , be Goto[k,A] = j
- The blank space is an error flag .
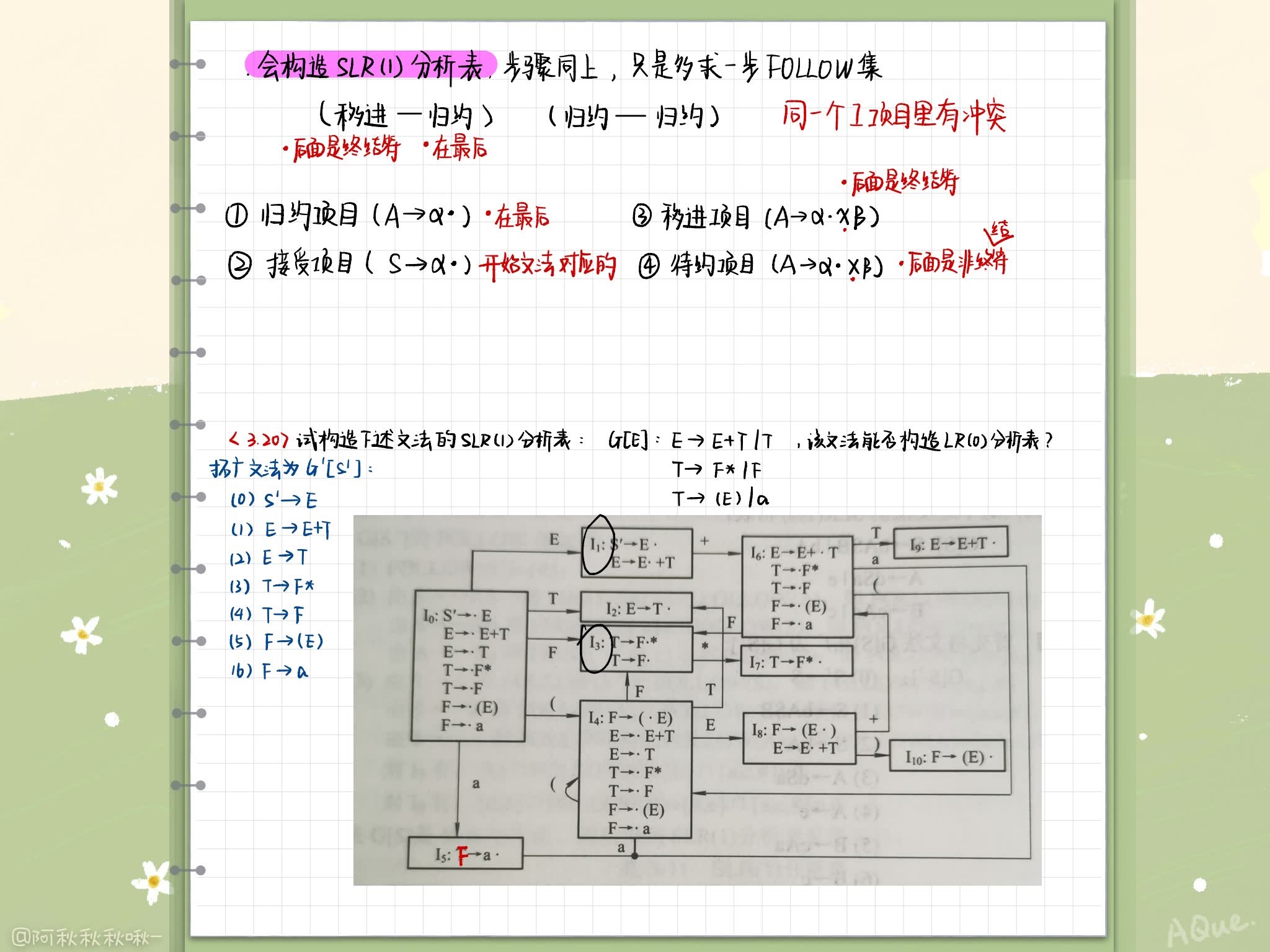
SLR The structure of the analysis table
Assume LR(0) A project set of specification families I contains m One entry project , It also contains n A protocol project , If the non terminator on the left of all the specification items Follow Sets do not intersect ( Including no two Follow The collection has #), And it does not match any terminator accepted by the move in project a The intersection , Is implied in I The action conflict in can be checked by checking the current input symbol a Belong to the above n+1 Which of the sets is solved
- if a ∈ { a 1 , a 2 , . . . , a m } a \in \{a_1, a_2, ..., a_m\} a∈{ a1,a2,...,am} Move in
- if a ∈ F o l l o w ( B i ) , i = 1 , 2 , . . . , n a \in Follow(B_i), i=1,2,...,n a∈Follow(Bi),i=1,2,...,n, Use the production type B i → α B_i \rightarrow \alpha Bi→α Make a protocol
- Besides , Report errors
SLR(1) terms of settlement : This solution to conflicting actions
Structure analysis table and structure LR(0) The analysis table is only in (2) Different steps , Will only belong to Follow(A) The terminator of is written γ j \gamma_j γj

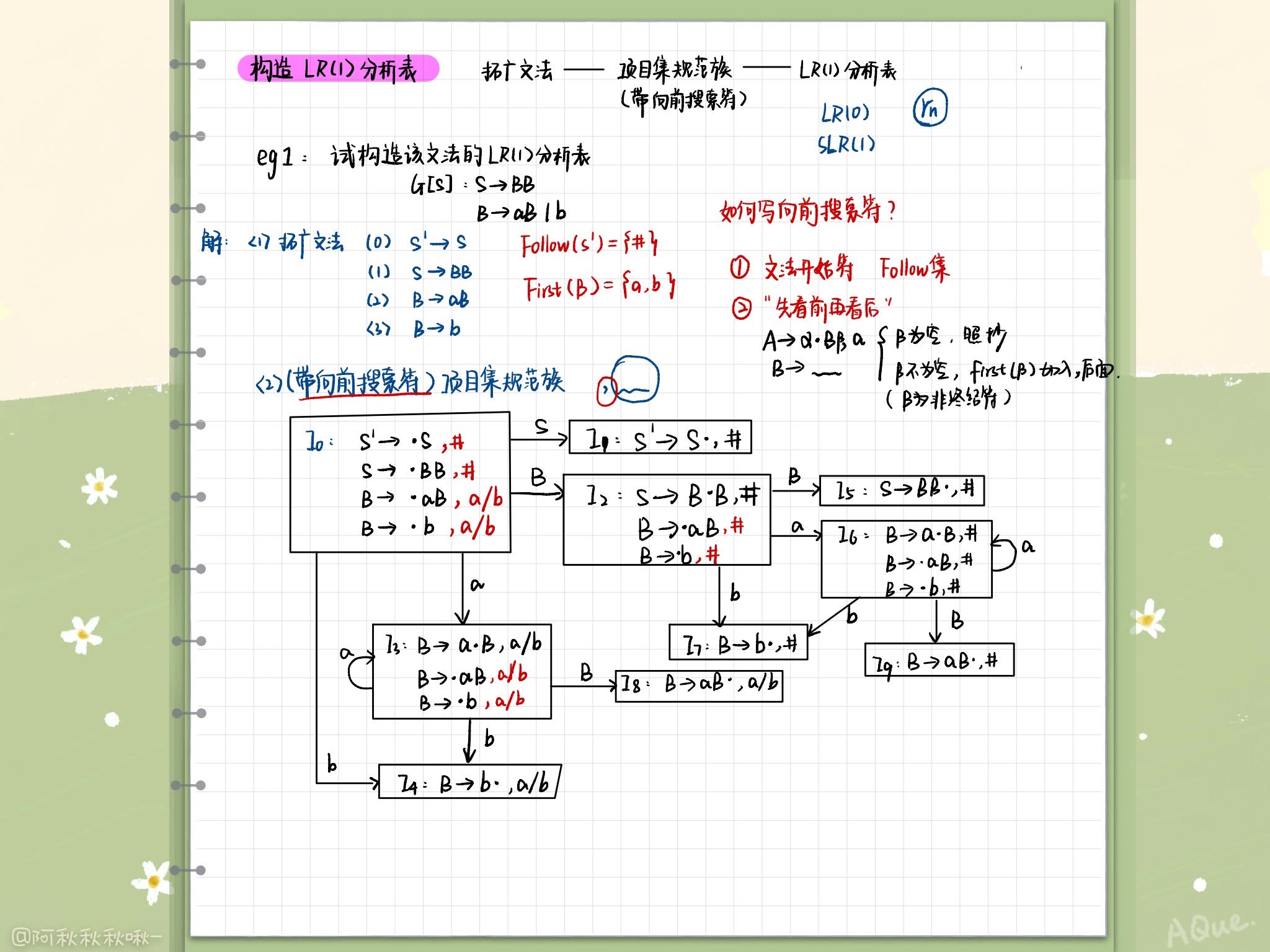
standard LR The structure of the analysis table
The general form of each project is [ A → α ⋅ β , a 1 a 2 . . . a k ] [A \rightarrow \alpha\cdotp \beta, a_1a_2...a_k] [A→α⋅β,a1a2...ak] Such a project is called a LR(K) project , In the project a1…ak It is called forward search string / Looking forward to
The forward search string is only meaningful for the specification item , That is, we need to split LR(0) Projects in China
LR(1) Of Closure Set and Go function
Closure(I):
- I Any project of belongs to Closure(I)
- If the project [ A → α ⋅ B β , a ] [A\rightarrow \alpha \cdotp B\beta,a] [A→α⋅Bβ,a] Belong to Closure(I), B → ϵ B \rightarrow \epsilon B→ϵ It's a generative , So for F i r s t ( β a ) First(\beta a) First(βa) Each terminator in b, If [ B → ⋅ ϵ , b ] [B\rightarrow \cdotp \epsilon, b] [B→⋅ϵ,b] It wasn't there Closure(I) in , I'm going to add it in
Conversion function Go:
Make I It's a project set ,X Is a grammatical symbol , function Go(I,x) Defined as : G o ( I , x ) = C l o s u r e ( J ) Go(I,x) = Closure(J) Go(I,x)=Closure(J)
among J = { ren What shape Such as [ A → α X ⋅ β , a ] Of term Objective ∣ [ A → α ⋅ X β , a ] ∈ I } J = \{ Any shape [A \rightarrow \alpha X\cdotp \beta, a] Project | [A \rightarrow \alpha \cdotp X \beta, a] \in I\} J={ ren What shape Such as [A→αX⋅β,a] Of term Objective ∣[A→α⋅Xβ,a]∈I}
LR(1) The structure of the analysis table ( Itemset specification family with forward search )
Basic idea and structure LR(0) The analysis table is the same , Specifically :
- contain [S’ -> S, #] The set of is the initial state of the analyzer
- Remember the specification is to remember only the terminator column in the prospect string

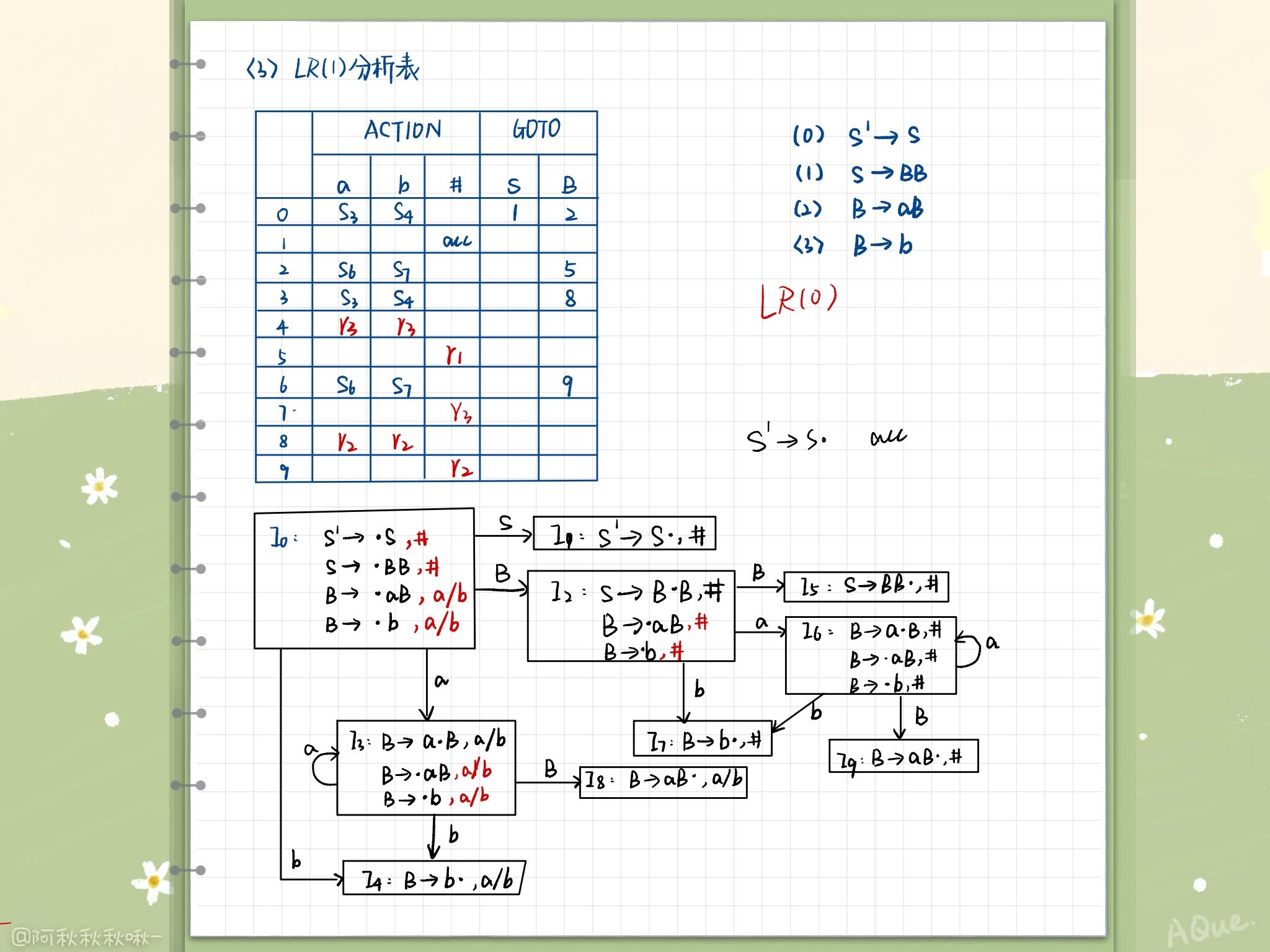
Three kinds of normative Relations :
LR(1) The state is better than SLR many
L R ( 0 ) ⊂ S L R ⊂ L R ( 1 ) ⊂ nothing Two The righteous writing Law LR(0) \subset SLR \subset LR(1) \subset Unambiguous grammar LR(0)⊂SLR⊂LR(1)⊂ nothing Two The righteous writing Law
Attribute grammar and grammar guided translation
Attributive grammar
Based on context free grammar , For each grammar symbol ( Terminator / non-terminal ) Equipped with a number of related “ value ”( Called attribute )
- Attributes represent information related to grammatical symbols , Such as type value 、 Code sequences 、 Contents of symbol table, etc
- Attributes can be evaluated or passed
- Semantic rules : For each production of grammar, it is equipped with a set of calculation rules of attributes
attribute
- Comprehensive attributes :“ Bottom up ” Transmit information
- Inheritance attribute :“ From top to bottom ” Transmit information
Terminators have only comprehensive properties , Provided by lexical analyzer
Non terminators can have both synthetic and inherited properties , All inherited attributes of the grammar start symbol are the initial values before the attribute calculation
A calculation rule must be provided for the inherited attribute appearing on the right side of the production and the comprehensive attribute appearing on the left side of the production .
Attribute calculation rules can only use the attributes of grammatical symbols in the corresponding production
The inherited attribute appearing on the left of the production and the comprehensive attribute appearing on the right of the production are not calculated by the given property calculation rules of the production , They are calculated by other production attribute rules or provided by the parameters of the attribute calculator
The work described by semantic rules can include : Attribute calculation 、 Static semantic check 、 Symbol table operation 、 Code generation, etc
In the syntax tree , The value of the comprehensive attribute of a node is determined by its child nodes and its own attribute values
The inherited attribute of a node is the parent node of this node ( Or brother node ) And certain properties of itself
Processing method based on attribute grammar
Dependency graph :
Each semantic rule containing procedure calls introduces a virtual comprehensive attribute
If the attribute in the dependency graph b Depends on properties c, Then the subordinate attribute c The node of has a directed edge connected to the attribute b The node of
Well defined attribute grammar : If there is no circular dependency between attributes in an attribute grammar , The grammar is called well defined
边栏推荐
- 授予渔,从0开始搭建一个自己想要的网页
- 应用安全系列之三十七:日志注入
- Auto.js学习笔记17:基础监听事件和UI简单的点击事件操作
- Pytorch代码注意的细节,容易敲错的地方
- [string] palindrome string of codeup
- 如何在业务代码中使用 ThinkPHP5.1 封装的容器内反射方法
- Cannot build artifact 'test Web: War expanded' because it is included into a circular depend solution
- [email protected]树莓派
- ArcGIS应用基础4 专题图的制作
- B站刘二大人-反向传播
猜你喜欢

数字经济破浪而来 ,LTD是权益独立的Web3.0网站?
[SQL Server fast track] - authentication and establishment and management of user accounts
B站刘二大人-线性回归 Pytorch
LTE CSFB process

Report on the competition status and investment decision recommendations of Guangxi hospital industry in China from 2022 to 2028
H3C V7 switch configuration IRF
![[Tang Laoshi] C -- encapsulation: classes and objects](/img/4e/30d2d4652ea2d4cd5fa7cbbb795863.jpg)
[Tang Laoshi] C -- encapsulation: classes and objects

B站刘二大人-Softmx分类器及MNIST实现-Lecture 9
PDK工艺库安装-CSMC
Redis message queue
![[SQL Server fast track] - authentication and establishment and management of user accounts](/img/42/c1def031ec126a793195ebc881081e)
随机推荐
Dynamic programming -- knapsack problem
数字经济破浪而来 ,LTD是权益独立的Web3.0网站?
[imgui] unity MenuItem shortcut key
Redis message queue
清除浮动的方式
H3C S5820V2_ Upgrade method after stacking IRF2 of 5830v2 switch
Pytorch代码注意的细节,容易敲错的地方
华为BFD的配置规范
Station B, Master Liu Er - dataset and data loading
Raised a kitten
B站刘二大人-多元逻辑回归 Lecture 7
Yygh-11-timing statistics
Market development prospect and investment risk assessment report of China's humidity sensor industry from 2022 to 2028
c语言——冒泡排序
How to download GB files from Google cloud hard disk
[Jiudu OJ 08] simple search x
Rustdesk builds its own remote desktop relay server
Jushan database appears again in the gold fair to jointly build a new era of digital economy
Redistemplate common collection instructions opsforvalue (II)
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower