当前位置:网站首页>SQL common optimization
SQL common optimization
2022-07-07 20:00:00 【Whiteye too white】
sql Optimize
1. Small tables drive large tables
First, query the table with less data , Then execute the query of the table with more data .
2. Index building , A table does not exceed 5 An index
Avoid large memory consumption .
3. Go to the index , Try to meet the leftmost match , Avoid index invalidation
Index failure :
(1)select *
(2)>、<、!=、between
(3) In front of % Of like Inquire about .
(4)where The field value type is inconsistent with the database , There is an automatic conversion .
(5)or Connect different fields .
(6)or Connect the same field , But there is >、<、!= Non indexed query .( Only when both left and right queries are indexes .)
(7) Function or operation causes index invalidation .
(8)IS NULL Don't walk index ,IS NOT NULL Go to the index ( Table design : When not necessary , The field should not be NULL, Set the default empty string or 0)
(9) When querying the range of composite cables , The following index is invalid .
(10)IN Can walk the index , But when IN When the value range of is large, the index will be invalid .
- ep_range_index_dive_limit This parameter affects in Use index or not ,MySQL 5.6 Default 10, MySQL.5.7 Default 200. But our code tends to be controlled in 50 Inside . A Table data is greater than B Table data , choice in Than exists High execution efficiency . contrary ,A Table data is less than B Table data , choice exists More efficient . in Execute subquery first ,exists First perform the appearance .
(11)not in Will invalidate the index , In either case not exists All ratio not in Efficient .
- Use left join or not exists To optimize not in operation .
4. Try to separate hot and cold data
Reduce the number of query table columns , Avoid cold data filtering .
5. Adjust the order of index columns
The uniqueness is better 、 Field is short 、 The frequently used column is placed on the far left of the union index
6. Override indexes are a priority for frequent queries
Query the data together when searching .
7. Avoid implicit conversions of data types
Avoid index invalidation .
8. No use SELECT * You have to use SELECT < Field list > Inquire about
There will be redundant fields , Consume more CPU And network bandwidth Will not be able to use overlay index .
9. Avoid subqueries , The subquery can be optimized to join operation
Subqueries will generate a large number of temporary tables without indexes .
10. Avoid using JOIN Too many tables associated
The more associated tables, the larger the associated cache .
11. Used when there is obviously no duplicate value UNION ALL instead of UNION
UNION ALL No de duplication operation , Speed up query .
12. Big SQL Split , More than one species SQL Batch processing
One SQL You can only use one cpu Calculate , After splitting, multiple cpu Parallel computing .
13. WHERE Functional transformations and calculations for columns are forbidden in clauses
Avoid index invalidation .
14. Use count(*) instead of count( Name )?
Comprehensive performance :count( Non primary key columns ) < count( Primary key ) < count(1) ≈ count()
count() yes SQL92 The syntax for defining the number of standard statistics lines , It's not about the database ,count(*) The statistical value is NULL The line of , and
count( Name ) This column is not counted NULL Row of values .
边栏推荐
- 开源OA开发平台:合同管理使用手册
- 浏览积分设置的目的
- R语言ggplot2可视化:使用ggpubr包的ggdensity函数可视化分组密度图、使用stat_overlay_normal_density函数为每个分组的密度图叠加正太分布曲线
- Kirin Xin'an joins Ningxia commercial cipher Association
- ASP. Net gymnasium integrated member management system source code, free sharing
- Specify the version of OpenCV non-standard installation
- 多个线程之间如何协同
- The strength index of specialized and new software development enterprises was released, and Kirin Xin'an was honored on the list
- vulnhub之Funfox2
- 剑指 Offer II 013. 二维子矩阵的和
猜你喜欢
Implement secondary index with Gaussian redis

九章云极DataCanvas公司获评36氪「最受投资人关注的硬核科技企业」
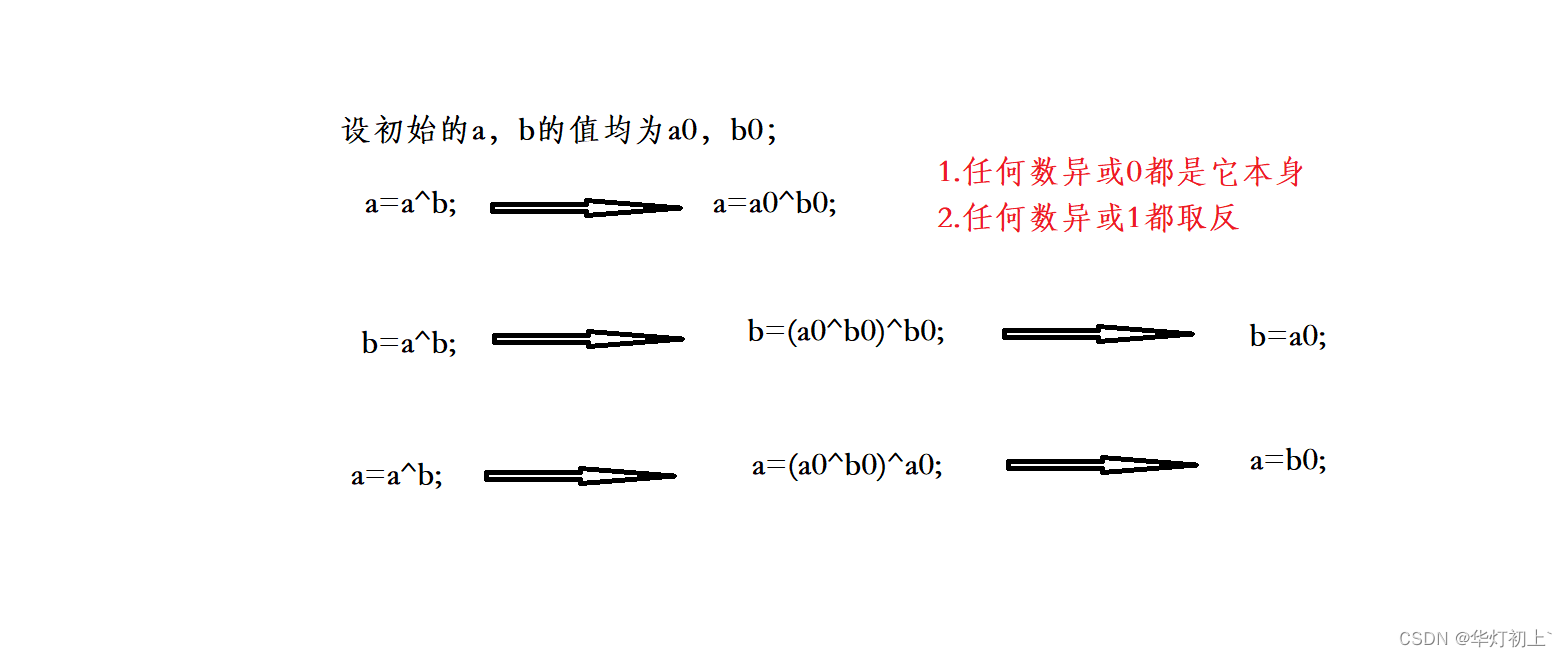
位运算介绍
关于ssh登录时卡顿30s左右的问题调试处理
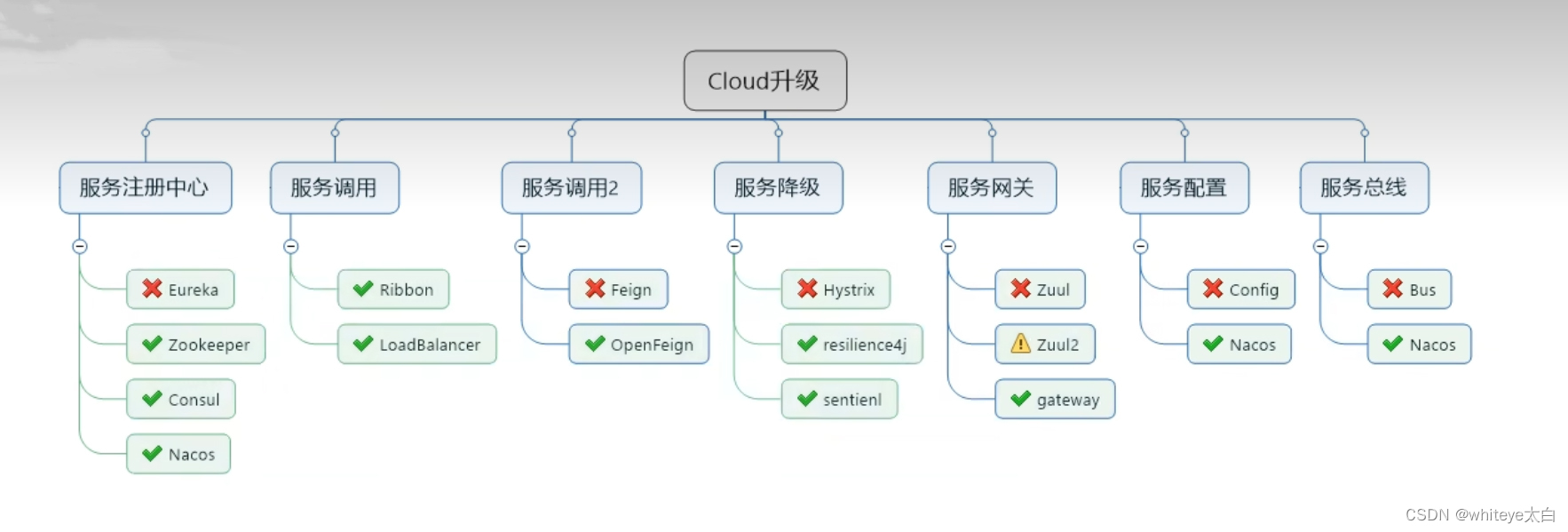
Cloud 组件发展升级

2022如何评估与选择低代码开发平台?
mock. JS returns an array from the optional data in the object array
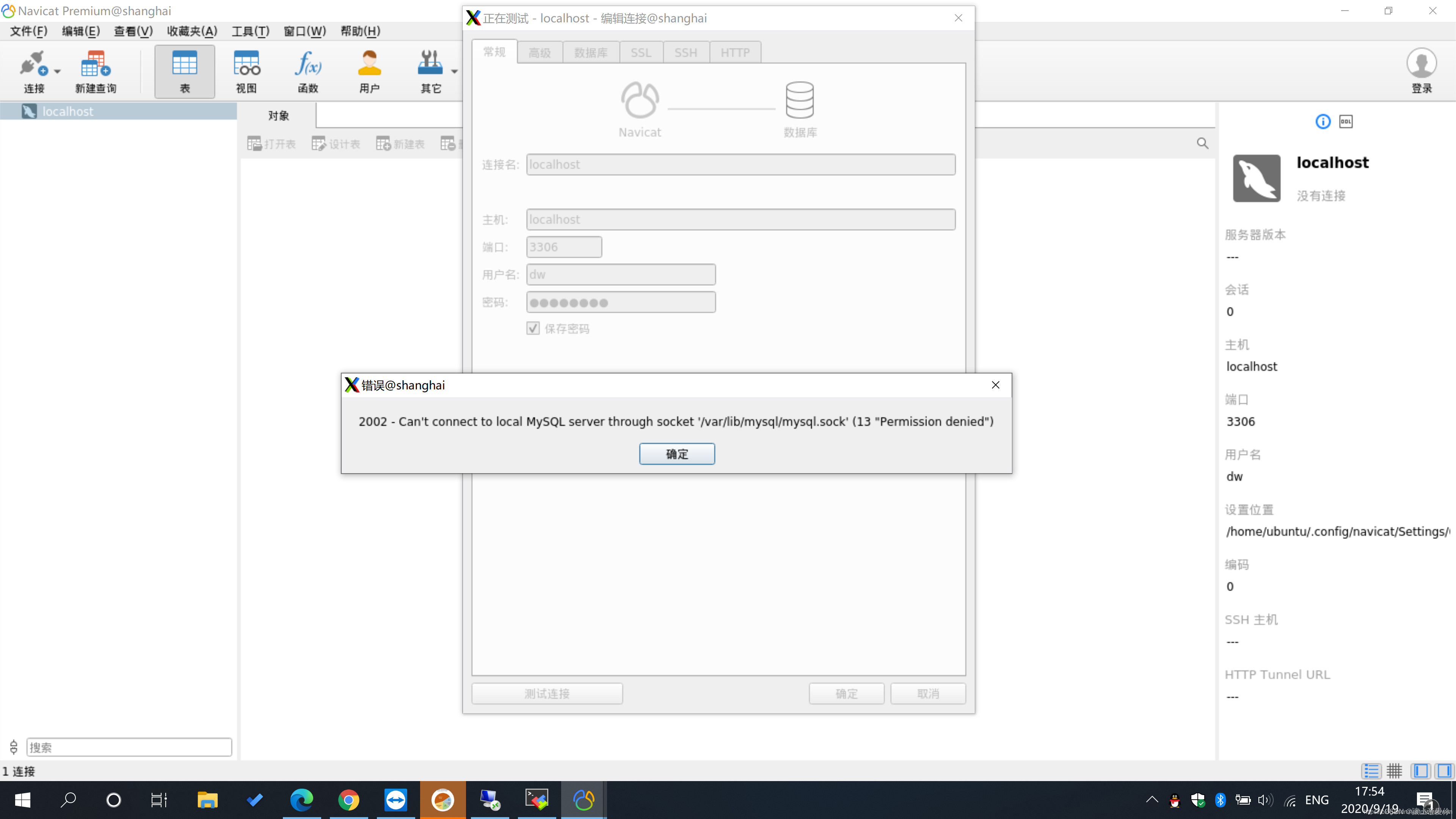
Navicat连接2002 - Can‘t connect to local MySQL server through socket ‘/var/lib/mysql/mysql.sock‘解决
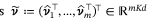
Automatic classification of defective photovoltaic module cells in electroluminescence images-論文閱讀筆記
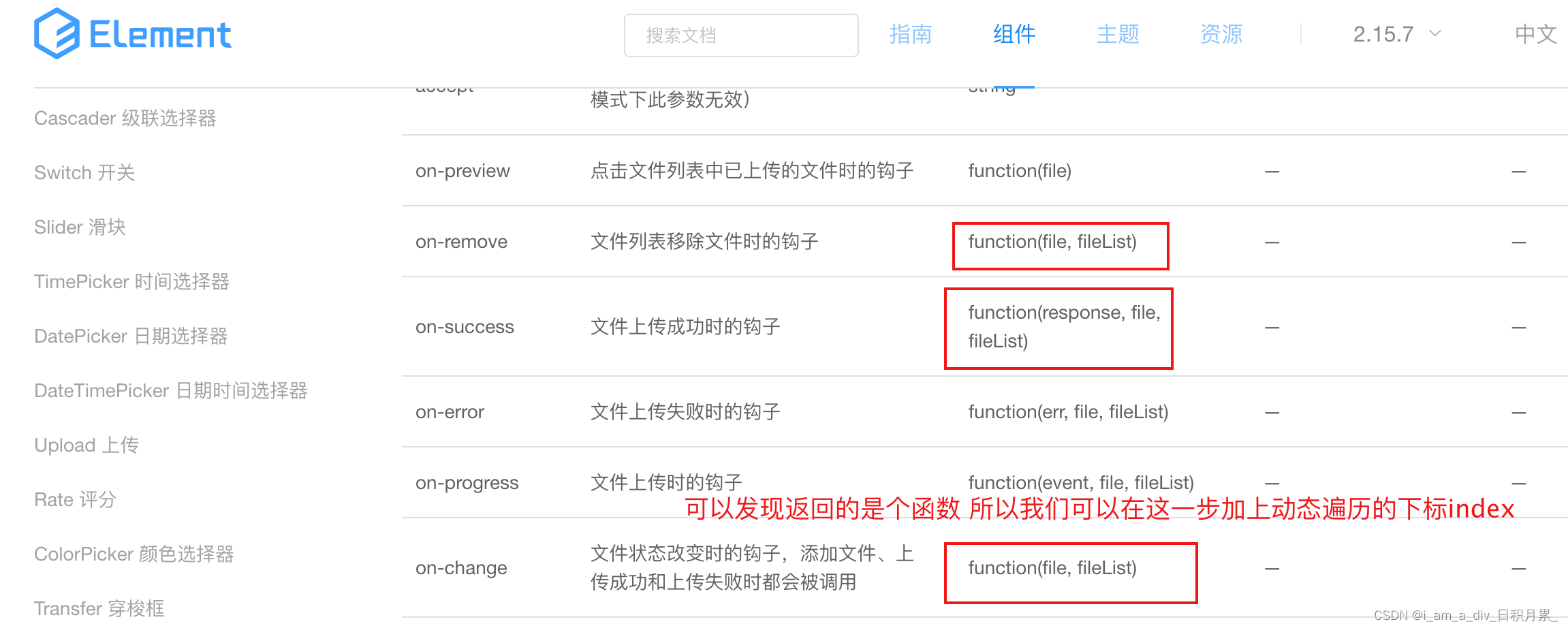
el-upload上传组件的动态添加;el-upload动态上传文件;el-upload区分文件是哪个组件上传的。
随机推荐
时间工具类
el-upload上传组件的动态添加;el-upload动态上传文件;el-upload区分文件是哪个组件上传的。
R语言使用ggplot2函数可视化需要构建泊松回归模型的计数目标变量的直方图分布并分析构建泊松回归模型的可行性
【STL】vector
R语言dplyr包select函数、group_by函数、filter函数和do函数获取dataframe中指定因子变量中指定水平中特定数值数据列的值第三大的值
Ways to improve the utilization of openeuler resources 01: Introduction
强化学习-学习笔记8 | Q-learning
Le PGR est - il utile au travail? Comment choisir une plate - forme fiable pour économiser le cœur et la main - d'œuvre lors de la préparation de l'examen!!!
毕业季|遗憾而又幸运的毕业季
【STL】vector
Kunpeng developer summit 2022 | Kirin Xin'an and Kunpeng jointly build a new ecosystem of computing industry
九章云极DataCanvas公司摘获「第五届数字金融创新大赛」最高荣誉!
吞吐量Throughout
Kirin Xin'an with heterogeneous integration cloud financial information and innovation solutions appeared at the 15th Hunan Financial Technology Exchange Conference
Boot 和 Cloud 的版本选型
R语言dplyr包mutate_at函数和min_rank函数计算dataframe中指定数据列的排序序号值、名次值、将最大值的rank值赋值为1
what‘s the meaning of inference
【剑指offer】剑指 Offer II 012. 左右两边子数组的和相等
8 CAS
项目经理『面试八问』,看了等于会了