当前位置:网站首页>《ActBERT》百度&悉尼科技大学提出ActBERT,学习全局局部视频文本表示,在五个视频-文本任务中有效!...
《ActBERT》百度&悉尼科技大学提出ActBERT,学习全局局部视频文本表示,在五个视频-文本任务中有效!...
2022-07-03 20:20:00 【我爱计算机视觉】
关注公众号,发现CV技术之美
本文分享论文『ActBERT: Learning Global-Local Video-Text Representations』,百度&悉尼科技大学提出《ActBERT》,学习全局局部视频文本表示,在五个视频-文本任务中有效!
详细信息如下:

论文链接:https://arxiv.org/abs/2011.07231
01
摘要
在本文中,作者提出了ActBERT,用于从未标记数据中进行联合视频文本表示的自监督学习。首先,作者利用全局动作信息来分析语言文本和局部区域对象之间的相互作用。它从成对的视频序列和文本描述中揭示全局和局部视觉线索,以进行详细的视觉和文本关系建模。
然后,作者引入了一个TaNgled Transformer block(TNT)来编码三种信息源,即全局行为、局部区域对象和语言描述。全局-局部对应关系是通过从上下文信息中提取的线索来发现的。它强制执行联合视频文本表示,以了解细粒度对象以及全局人类意图。作者验证了ActBERT在下游视频和语言任务上的泛化能力,即文本视频片段检索、视频字幕、视频问答、动作分割和动作step定位。ActBERT的表现明显优于最先进的技术,表明其在视频文本表征学习方面的优势。
02
Motivation
尽管监督学习在各种计算机视觉任务中都取得了成功,但近年来,从未标记数据中进行的自监督表征学习越来越受到关注。在自监督学习中,模型首先在大量未标记数据上进行预训练,并带有代理损失。微调过程进一步帮助预训练的模型专门处理下游任务。最近,文本的自监督表征学习取得了快速的进展,其中来自Transformers的双向编码器表征(BERT)模型显著地推广到许多自然语言任务。
受BERT在自监督训练方面取得成功的启发,本文的目标是学习一种用于视频和文本联合建模的类似模型。作者利用了基于叙事教学视频的视频-文本关系,其中对齐的文本由现成的自动语音识别(ASR)模型检测。这些教学视频是视频-文本关系研究的自然来源。首先,它们在YouTube和其他平台上随处可见。其次,视觉帧与教学叙事保持一致。文本叙述不仅明确地覆盖了场景中的对象,还识别了视频片段中的显著动作。
为了将BERT推广到视频和语言任务,研究者们通过学习量化视频帧特征扩展了BERT模型。原始的BERT将离散元素作为输入,并预测相应的token作为输出。相比之下,视觉特征是具有真实值的分布式表示,而真实值特征不能直接分类为离散标签进行“视觉token”预测。因此,研究者通过聚类将视觉特征离散化为视觉单词。这些视觉token可以直接传递给原始的BERT模型。然而,在聚类过程中,可能会丢失详细的局部信息,例如交互对象、人类行为。它阻止模型揭示视频和文本之间的细粒度关系。在本文中,作者提出ActBERT学习一种联合视频文本表示方法,该方法从成对的视频序列和文本描述中发现全局和局部视觉线索。全局和局部视觉信号都与语义流相互作用。ActBERT利用深刻的上下文信息,利用细粒度关系进行视频-文本联合建模。
首先,ActBERT将全局动作、局部区域对象和文本描述整合到一个联合框架中。动作对于各种与视频相关的下游任务至关重要。人类行为的识别可以证明模型的运动理解能力和复杂的人类意图推理能力。在模型预训练期间,明确模拟人类行为可能是有益的。虽然动作线索很重要,但在之前的自监督视频文本训练中,它们在很大程度上被忽略了,在这种训练中,动作与对象的处理方式相同。为了模拟人类行为,作者首先从文本描述中提取动词,并从原始数据集中构建一个动作分类数据集。然后,训练一个3D卷积网络来预测动作标签。将优化后的网络特征作为动作嵌入。这样,将表示片段级别的动作,并插入相应的动作标签。除了全局运动信息,作者还结合了局部区域信息,以提供细粒度的视觉线索。对象区域提供有关整个场景的详细视觉线索,包括区域对象特征、对象位置。语言模型可以从区域信息中受益,从而实现更好的语言和视觉对齐。
其次,作者引入了一个TaNgled Transformer block(TNT)来编码来自三个来源的特征,即全局动作、局部区域对象和语言token。之前的研究在设计新的Transformer层时考虑了两种模态,即来自图像和自然语言的细粒度对象信息。然而,在本文的场景中,有三个输入源。两个来源,即局部区域特征和语言文本,提供了视频中发生事件的详细描述。另一个全局动作特征提供了时间序列中的人类意图,以及上下文推断的直接线索。作者设计了一个新的TaNgled Transformer block,用于从三个来源进行跨模态特征学习。为了增强两个视觉线索和语言特征之间的相互作用,作者使用一个单独的transformer块对每个模态进行编码。相互的跨模态交流后来通过两个额外的多头注意块得到加强。动作特征催化相互作用。在动作特征的引导下,作者将视觉信息注入到语言Transformer中,并将语言信息融入到视觉Transformer中tangled transformer动态地选择其上下文中的线索,以促进目标预测。
此外,作者还设计了四个代理任务来训练ActBERT,即带有全局和局部视觉线索的蒙面语言建模、蒙面动作分类、蒙面对象分类和跨模态匹配。预训练的ActBERT被转移到五个与视频相关的下游任务中,即视频字幕、动作分割、文本视频片段检索、动作步骤定位和视频问答。定量实验结果表明,ActBERT以明显的优势实现了最先进的性能。
03
方法
3.1. Preliminary
本节首先说明原始的BERT模型。BERT以无监督的方式在大型语料库上预训练语言模型。研究发现,预训练的模型灵活,有利于各种下游任务,例如问答。
在BERT中,输入实体由多层双向Transformer处理。每个输入的嵌入都通过堆叠的自注意层进行处理,以聚合上下文特征。注意力权重是自适应生成的。输出特征包含有关原始输入序列的上下文信息。在自注意中,生成的特征与输入序列顺序无关,并且使输出表示具有置换不变性。当输入序列shuffle时,输出表示不受影响。因此,位置嵌入通常应用于每个输入实体,以合并顺序线索。
在最初的BERT中,采用了两项预训练任务。在屏蔽语言建模(MLM)任务中,一部分输入单词被随机屏蔽。这些被屏蔽的单词被一个特殊的token “[MASK]”代替。该任务是根据上下文内容的观察结果预测屏蔽词。上下文内容是未屏蔽的元素,为预测屏蔽词提供有用的相关线索。
另一项任务,即Next Sentence Prediction(NSP),对两个句子之间的顺序信息进行建模。从一份文件中抽取两个句子,NSP旨在确定第二个句子与第一个句子的顺序是否正确。这两个句子通过“[SEP]”连接起来,这样模型就可以知道输入是分开的句子。根据第一个token“[CLS]”的输出特征进行预测。这是一个二分类问题,使用了一个简单的sigmoid分类器。预测为“1”表示句子是连续的,第二句正好在第一句之后。
3.2. ActBERT
3.2.1 Input Embeddings
ActBERT中有四种类型的输入元素。它们是动作、图像区域、语言描述和特殊token。特殊token用于区分不同的输入。
每个输入序列以一个特殊token “[CLS]”开始,以另一个token “[SEP]”结束。将动作特征表示为,区域特征表示为,顺序文本特征表示为。整个序列被表示为
402 Payment Required
。“[SEP]”也插入不同的句子之间。我们还可以在来自不同片段的区域之间插入“[SEP]”,这可以帮助模型识别片段边界。对于每个输入步骤,最终嵌入特征由四个不同的嵌入组成。嵌入包括位置嵌入、分段嵌入、token嵌入、视觉特征嵌入。作者添加了一些新token来区分动作特征和区域对象特征。引入视觉嵌入来提取视觉和动作信息。这些嵌入被添加为ActBERT的最终特征。
Position embedding
作者将一个可学习的位置嵌入序列中的每个输入。由于自注意不考虑顺序信息,所以位置编码提供了一种灵活的方式,在序列顺序重要时嵌入序列。对于不同片段中的动作,位置嵌入会随着视频片段的顺序而不同。对于从同一帧中提取的区域,作者使用相同的位置嵌入。为了区分同一帧中的区域,作者考虑了不同空间位置的空间位置嵌入。
Segment embedding
作者考虑使用多个视频片段进行长期视频上下文建模。每个视频片段或视频片段都有相应的片段嵌入。这些元素,即动作输入、区域对象输入、语言描述,在同一视频片段中嵌入了相同的片段。
Token embedding
每个单词都嵌入了3万个词汇量的词条嵌入。除了上面提到的特殊token(“[CLS]”、“[MASK]”、“[SEP]”),作者还引入“[ACT]”和“[REGION]”,分别表示从视频帧中提取的动作特征和区域特征。请注意,所有动作输入都具有相同的token嵌入,这揭示了输入的模态。
Visual (action) embedding
对于每个视频片段,作者从相应的描述中提取动词。为了简单起见,作者删除了没有任何动词的片段。然后,从所有提取的动词中构建词汇表。在动词词汇构建之后,每个视频片段都有一个或多个类别标签。作者在这个数据集上训练了一个三维卷积神经网络。3D网络的输入是一个包含额外时间维度的张量,然后利用卷积神经网络上的softmax分类器。对于具有多个标签的片段,作者使用'L1-norm'归一化one-hot标签。在对模型进行训练后,提取全局平均池化后的特征作为动作特征。此特征可以很好地表示视频片段中发生的动作。
为了获得区域目标特征,作者从预训练的目标检测网络中提取边界框和相应的视觉特征。图像区域特征为视觉和文本关系建模提供了详细的视觉信息。对于每个区域,视觉特征嵌入是预训练网络中输出层之前的特征向量。结合空间位置嵌入,用5-D向量表示区域位置。该向量由四个框坐标和区域面积的分数组成。具体来说,我们将向量表示为
402 Payment Required
,其中W是帧宽度,H是帧高度,(x 1,y 1)和(x 2,y 2)分别是左上和右下的坐标。然后嵌入该向量以匹配视觉特征的维度。最终的区域目标特征是空间位置嵌入和目标检测特征的总和。
3.2.2 Tangled Transformer
作者设计了一个Tangled Transformer(TNT)来更好地编码三种信息源,即动作特征、区域对象特征和语言特征。

与只使用一个同等对待视觉和文本特征的Transformer不同,本文的Tangled Transformer由三个Transformer组成。这三个Transformer分别具有三个特征源。为了增强视觉和语言特征之间的相互作用,作者将视觉信息注入语言Transformer,并将语言信息纳入视觉Transformer。通过跨模态交互作用,TNT可以动态地选择明智的线索进行目标预测。将Transformer块l的中间表示表示为
402 Payment Required
。为了简单起见,可以表示为 , , ,分别由w-transformer、a-transformer和r-transformer处理,如上图所示。除了来自同一模态的标准多头注意编码特征外,作者还利用其他两个多头注意块来增强transformer之间的相互作用。本文的TNT和co-attentional transformer在几个方面不同。首先,co-attentional transformer只是将键和值从一个模态传递到另一个模态的注意块,无需进一步的预处理。第二,co-attentional transformer对这两种模态一视同仁,而“TNT块”利用全局线索来指导从语言和视觉特征中选择局部提示。第三,在co-attentional transformer中,来自不同模态的键和值替换了原始键值,而TNT将键值与原始值堆叠在一起。这样,在Transformer编码过程中,语言和视觉特征都被结合起来。
3.2.3 ActBERT Training
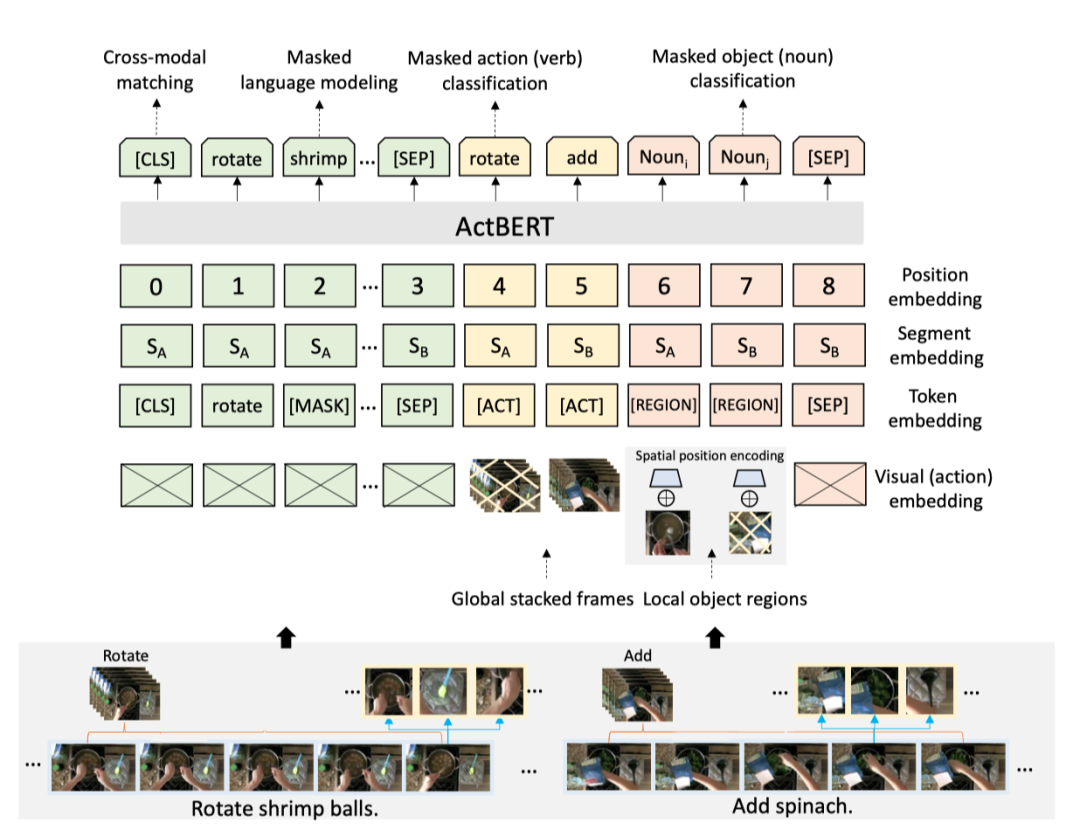
上图展示了本文方法的预训练任务。
Masked Language Modeling with Global and Local Visual Cues
作者将BERT中的蒙面语言建模(MLM)任务扩展到本文的设置中。作者利用来自局部区域对象和全局动作的视觉线索来揭示视觉和语言实体之间的关系。输入句子中的每个单词都以固定的概率随机屏蔽。该任务要求模型从上下文描述中学习,同时提取相关的视觉特征以便于预测。当一个动词词被屏蔽时,模型应该利用动作特征进行更准确的预测。当一个对象的描述被屏蔽时,局部区域特征可以提供更多的上下文信息。因此,强大的模型需要在局部和全局范围内协调视觉和语言输入。然后,输出特征会在整个语言词汇表上附加一个softmax分类器。
Masked Action Classification
同样,在屏蔽动作分类中,动作特征也被屏蔽。该任务是根据语言特征和对象特征预测蒙面动作标签。明确的行动预测在两个方面都是有益的。首先,动作顺序线索可以长期利用。例如,对于动作序列为“进入”、“旋转”、“添加”的视频,此任务可以更好地利用有关执行此教学任务的时序信息。其次,利用区域对象和语言文本进行更好的跨模态建模。请注意,在屏蔽动作分类中,目标是预测屏蔽动作特征的分类标签。该任务可以增强预训练模型的动作识别能力,可以进一步推广到许多下游任务,例如视频问答。
Masked Object Classification
在屏蔽对象分类中,区域对象特征被随机屏蔽。作者预测了隐藏图像区域在固定词汇表上的分布。随机区域的目标分布计算为softmax激活,该激活通过在特征提取阶段将该区域转发到相同的预训练检测模型来提取。两个分布之间的KL差异最小化。
Cross-modal matching
与NSP任务相似,作者在第一个token “[CLS]”的输出上应用一个线性层。然后是一个Sigmoid分类起,表示语言句子和视觉特征的相关性得分。如果分数很高,说明文本很好地描述了视频片段。该模型通过二元交叉熵损失进行优化。为了训练这种跨模态匹配任务,作者从未标记的数据集中抽取负视频文本对。
04
实验
Video captioning
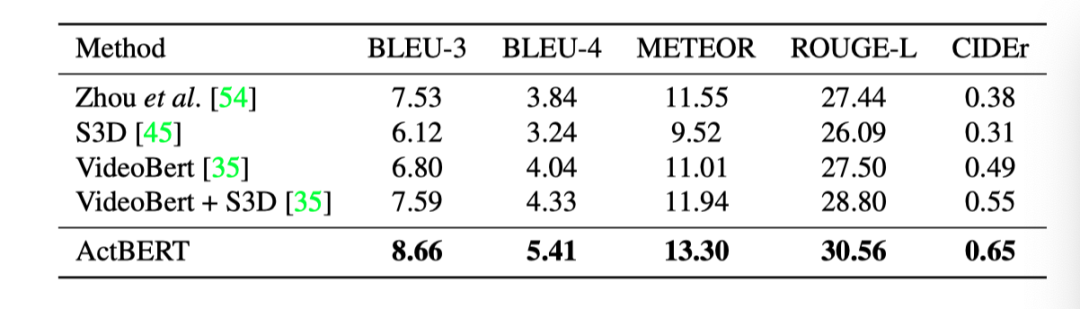
上表展示了本文方法在YouCook2数据集,Video Captioning任务上的实验结果,说明ActBERT可以很好的泛化到captioning任务上。
Action segmentation

上表展示了本文方法在COIN数据集,Action Segmentation任务上的实验结果,可以看出ActBERT比Baseline提升了20%左右。
Action step localization
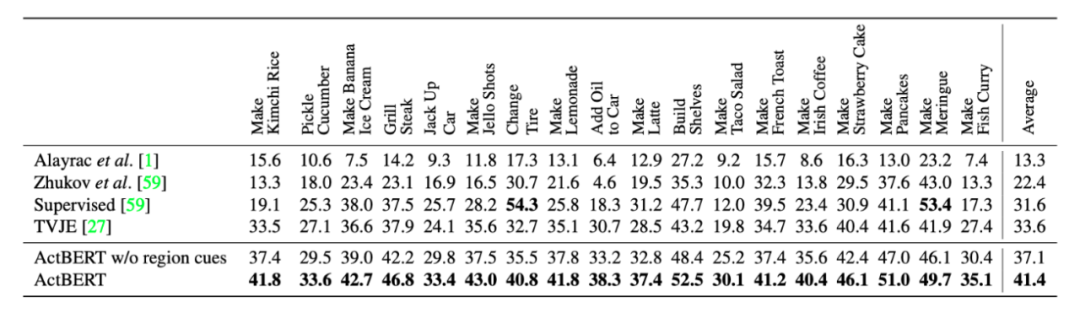
上表展示了本文方法在CrossTask数据集,Action step localization任务上的实验结果。
Text-video clip retrieval

上表展示了本文方法在YouCook2数据集,视频-文本检索任务上的实验结果。
Video question answering
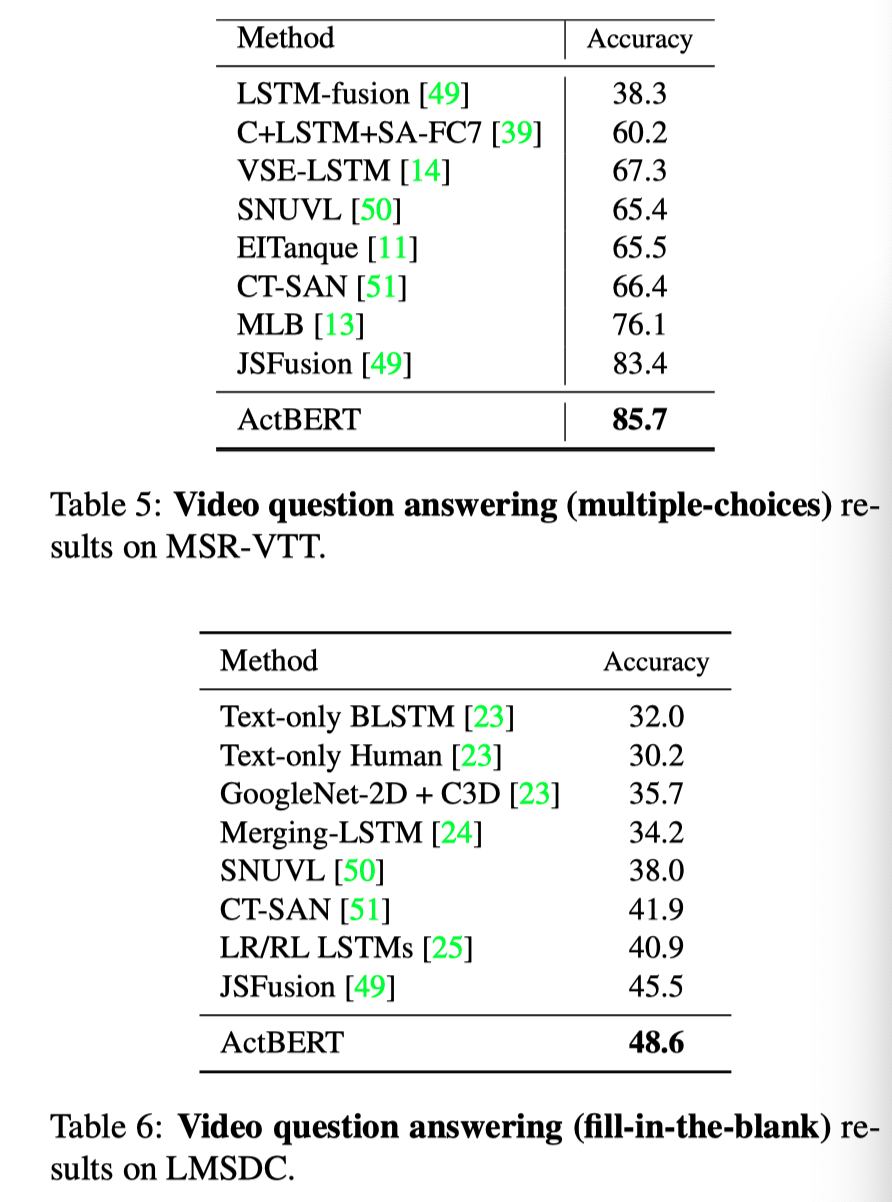
上表分别展示了文本方法在MSRVTT和LMSDC数据集上QA任务的实验结果,可以看出,本文的方法可明显由于其他的baseline方法。
05
总结
在这篇文章中,作者引入了ActBERT以一种自监督的方式进行联合视频文本建模。模型直接对全局和局部视觉线索进行建模,以实现细粒度视觉和语言关系学习。ActBERT以三种信息来源作为输入,即全局动作、局部区域对象和语言描述。TaNgled Transformer 进一步增强了三个来源之间的通信。五个视频文本基准测试的定量结果证明了ActBERT的有效性。
参考资料
[1]https://arxiv.org/abs/2011.07231

END
欢迎加入「视觉语言」交流群备注:VL

边栏推荐
- Promethus
- Research Report on the overall scale, major manufacturers, major regions, products and application segmentation of rotary tablet presses in the global market in 2022
- Global and Chinese markets of active matrix LCD 2022-2028: Research Report on technology, participants, trends, market size and share
- Sparse matrix (triple) creation, transpose, traversal, addition, subtraction, multiplication. C implementation
- Deep search DFS + wide search BFS + traversal of trees and graphs + topological sequence (template article acwing)
- MPLS configuration
- Machine learning support vector machine SVM
- Wireless network (preprocessing + concurrent search)
- Commands related to files and directories
- TLS environment construction and plaintext analysis
猜你喜欢
2.3 other data types
Vscode reports an error according to the go plug-in go get connectex: a connection attempt failed because the connected party did not pro
Basic knowledge of dictionaries and collections

JVM JNI and PVM pybind11 mass data transmission and optimization
Point cloud data denoising

Interval product of zhinai sauce (prefix product + inverse element)

Derivation of decision tree theory

2022 high voltage electrician examination and high voltage electrician reexamination examination

Test changes in Devops mode -- learning and thinking

String and+
随机推荐
Line segment tree blue book explanation + classic example acwing 1275 Maximum number
2.1 use of variables
FAQs for datawhale learning!
Upgrade PIP and install Libraries
AST (Abstract Syntax Tree)
Gym welcomes the first complete environmental document, which makes it easier to get started with intensive learning!
Global and Chinese markets of active matrix LCD 2022-2028: Research Report on technology, participants, trends, market size and share
MDM mass data synchronization test verification
Deep search DFS + wide search BFS + traversal of trees and graphs + topological sequence (template article acwing)
Use nodejs+express+mongodb to complete the data persistence project (with modified source code)
Promethus
Global and Chinese markets for medical temperature sensors 2022-2028: Research Report on technology, participants, trends, market size and share
Leetcode daily question solution: 540 A single element in an ordered array
Popularize the basics of IP routing
Viewing Chinese science and technology from the Winter Olympics (II): when snowmaking breakthrough is in progress
Global and Chinese market of cyanuric acid 2022-2028: Research Report on technology, participants, trends, market size and share
An old programmer gave it to college students
About callback function and hook function
App compliance
P5.js development - setting