当前位置:网站首页>ISPRS2021/遥感影像云检测:一种地理信息驱动的方法和一种新的大规模遥感云/雪检测数据集
ISPRS2021/遥感影像云检测:一种地理信息驱动的方法和一种新的大规模遥感云/雪检测数据集
2022-07-07 10:46:00 【HheeFish】
ISPRS2021/云检测:A geographic information-driven method and a new large scale dataset for remote sensing cloud/snow detection一种地理信息驱动的方法和一种新的大规模遥感云/雪检测数据集
0.摘要
地理信息如海拔、纬度和经度是遥感图像产品中常见但基本的元记录。本文表明,这一组记录为遥感图像的云和雪检测提供了重要的先验。直觉来源于一些常见的地理知识,其中很多都很重要,但常常被忽视。例如,众所周知,低纬度或低空地区不太可能有雪,不同地理位置的云可能有不同的视觉外观。以前的云和雪检测方法简单地忽略了这些信息的使用,而仅仅基于图像数据(波段反射率)进行检测。由于忽略了这些先验,这些方法在复杂场景下(如云-雪共存)难以获得满意的性能。本文提出了一种用于云和雪检测的新型神经网络——地理信息驱动网络(GeoInfoNet)。除了使用图像数据外,该模型还集成了训练和检测阶段的地理信息。专门设计了“地理信息编码器”,将图像的海拔、纬度和经度编码为一组辅助地图,然后将其输入检测网络。该网络可以通过密集鲁棒特征提取和融合进行端到端训练。建立了用于云雪检测的新数据集“Levir_CS”,该数据集包含4168幅高分一号卫星图像和相应的地理记录,比该领域其他数据集大20多倍。在“Levir_CS”上的实验表明,该方法与云并集相交率为90.74%,与雪并集相交率为78.26%。它比其他先进的云和雪检测方法有很大的优势。特征可视化还表明,该方法学习了一些接近常识的重要先验信息。
1.概述
在过去的几十年里,遥感技术的快速发展帮助人们更好地了解地球。光学遥感技术作为遥感家族中的一个重要分支,在目标检测等领域有着重要的应用意义(邹和石,2016;林等,2017a,b;邹和石,2017),场景分类(石等,2018)等。然而,遥感图像的成像过程经常受到云和雪的干扰。以往的文献表明,云平均每天覆盖地球表面的一半以上(Zhang and Xiao, 2014;安和石,2015;谢等人,2017;吴,石,2018)。在一些高纬度地区,地面也可能终年被冰雪覆盖。一方面,上述两个因素都将极大地影响遥感图像的处理和分析,其中云可以是遮挡的一种形式(Li et al., 2014, 2019b),雪可能会急剧增加反射率。另一方面,环境研究如气候研究(Bi等,2019)和生态变化分析(Campbell等,2005;Wang et al., 2018)需要云/雪掩膜,但手动标记图像通常耗时且昂贵(Zhan et al., 2017)。自动云和雪检测提供了一种产生像素级云/雪掩模的有效方法,从而形成了许多遥感应用的基础。
海拔、经度、纬度等地理信息是遥感影像产品中重要的元记录。这样一组记录为图像处理和分析任务提供了辅助的甚至是至关重要的信息。在云和雪的检测中,它也提供了重要的先验。例如,众所周知,低纬度或低空地区不太可能有雪,不同地理位置的云可能有不同的视觉外观。图1显示了一些云和雪的样本图像。每张图片覆盖了大约4万平方公里的区域,并且在地球上不同的位置有不同的代表。近年来,许多深度学习的云检测和雪检测方法被提出。尽管在这一领域已经做出了很大的努力和改进,但以往的方法,即使是最先进的方法,仍然有局限性。这种方法最严重的缺陷之一是在进行检测时忽略了地理信息的使用。也就是说,这些深度学习方法的设计完全基于对图像数据(波段反射率)的使用,而忽略了其他必要的先验,如高度和位置。在云和雪同时出现的复杂场景中,这些方法通常难以生成准确的云和雪掩模。
本文提出了一种新的基于深度学习的云和雪检测方法。这种方法被称为地理信息驱动神经网络(GeoInfoNet)。不同于以往只注重使用图像数据(波段反射率)而忽略地理信息的方法,该方法设计了一个“地理信息编码器”,将一幅图像的高度、纬度和经度编码为一组二维地图。然后,这些地图被明智地集成到检测网络,然后以端到端方式训练整个检测模型。可以看出,随着辅助信息的整合,云和雪的检测精度不断提高。该方法在很大程度上优于其他先进的云和雪检测方法。除了新的检测框架外,还建立了一个用于云和雪检测的大数据集,该数据集由4168幅高分一号卫星图像组成,是该领域其他数据集的20多倍。更重要的是,数据集包含相应的地理信息,包括经度、纬度和每个图像的高分辨率海拔地图。本文的贡献总结如下:
1)不同于以往基于波段反射率构建的云和雪检测方法,直接忽略图像的地理信息,提出了一种新的深度学习框架“GeoInfoNet”,将地理信息集成到检测流程中,自动学习先验检测。编码器将辅助信息如海拔、经度和纬度编码为一组2D地图,检测网络可以以端到端方式有效地学习像素。
2) 对特征可视化的广泛研究显示了框架学习了什么先验知识,以及不同部分对检测结果的贡献有多大。
3)建立了一个新的数据集用于云和雪检测,该数据集比之前的数据集大20倍。更重要的是,每个图像的地理信息都记录在数据集中,而这些信息不包括在以前的数据集中。
本文的以下内容组织如下。第二节介绍了该方法的相关工作。第3节详细介绍了所提出的方法。在第4节中,给出了数据集Levir_CS的详细信息。在第5节中,对该方法进行了广泛的实验,并在第6节中提出了讨论。最后,第七部分对本文进行总结。
2.方法
本节详细描述了检测方法,以及地理信息如何编码并集成到网络中
2.1.GeoInfoNet概述
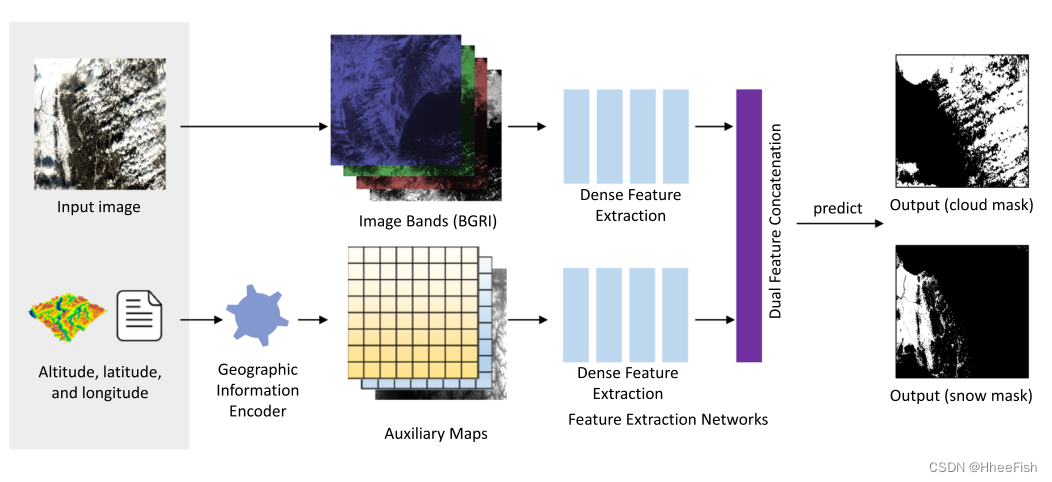
图2。拟议方法概述。提出了一种称为GeoInfoNet的新网络,该网络利用图像数据和辅助地理信息进行云雪检测。地理信息编码器旨在将这一信息编码为一组辅助地图。这两个网络分支的特征都是通过“特征提取网络”提取的,其中包括“密集特征提取”模块和“双特征拼接”模块。前一个模块可以提取每个分支的代表性特征,而后一个模块用于生成精细的特征表示,进一步用于生成云和雪遮罩
图2显示了该方法的概述。拟议的地理信息网是一个端到端网络,利用输入图像和一组辅助地图。辅助地图由地理信息编码器生成,将在第2.2节中介绍。在GeoInfoNet中,遵循DenseNet(Huang等人,2017)中的网络结构作为主干网络,分别从输入图像和辅助地图中提取多尺度密集特征。然后,从这两个分支中提取的这些特征将被合并并用于生成最终的云和雪遮罩。该方法中的两个基本模块,即构成“特征提取网络”的“密集特征提取”和“双特征串联”,将在第2.3.1节和第2.3.2节中详细描述。
2.2.地理信息编码器Geographic information encoder
地理信息编码器设计用于将三种类型的元记录(即经度、纬度和海拔)以及图像编码到一组辅助地图中。该模块可以被视为拟议地理信息网GeoInfoNet的预处理模块。生成的这些映射与输入图像具有相同的空间大小,但可能具有不同数量的通道。图3显示了地理信息编码器的处理管道。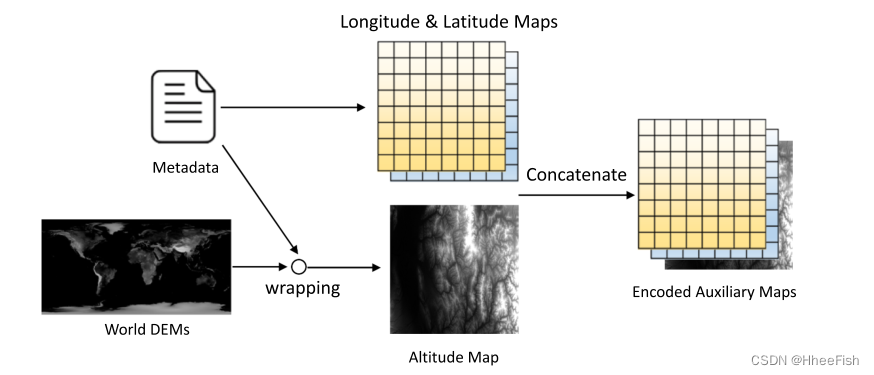
图3。地理信息编码器的处理管道。对于输入图像,基于等式(1)从元数据生成经度图和纬度图ALat。输入图像的高度图AAlt也是通过将世界DEM以像素方式包装到图像投影坐标来生成的。最后,将这三个映射连接起来以生成最终编码的。辅助地图。
给定一幅h×w大小的遥感图像,首先在其左上角和右下角记录经纬度。然后,通过仿射变换模型生成经度图和纬度图ALat(Warmerdam,2008;Zhao等人,2010)。对于y行中的某个像素(0⩽y<h)和x列(0⩽x<w),沿ALong(y,x)的相应经度和纬度ALat(y,x)可计算如下: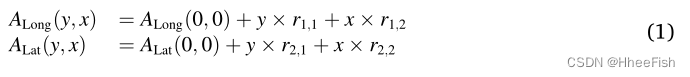
其中,沿ALong(0,0)和ALat(0,0)是图像左上角的经度和纬度值。r1,1、r1,2、r2,1和r2,2是x和y方向上的经度/纬度分辨率单位,可以从图像产品的图元文件中获得,也可以从四个图像角点和中心点的坐标中估计。
除了经度和纬度之外,图像的高度也被编码到另一个辅助地图AAlt中。给定一幅图像及其相应的经度/纬度信息,可以通过像素坐标将全球数字高程模型(DEM)包装到此图像的投影坐标来生成海拔图AAlt。对于大多数光学遥感图像产品,图像高度信息不包括在图元文件中。在本文中,使用的DEM是基于2000年航天飞机雷达地形任务(SRTM)收集的数据创建的,分辨率为3弧秒(空间分辨率:90米)。
每个输入图像的最终编码辅助映射A可以表示为上述三个映射在通道维度中的串联,如下所示,
其中,A的维数为(h,w,3)。
2.3.特征提取网络
2.3.1.密集特征提取
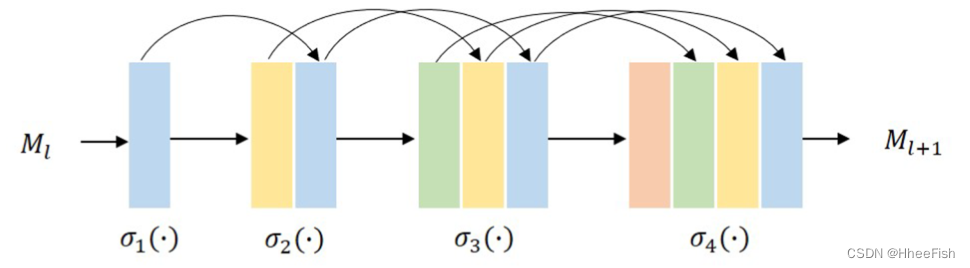
图4。4层致密块体的图示。每个卷积层将所有前面的特征映射作为输入。
在基于深度学习的云雪检测方法中,学习鲁棒特征表示对于检测任务至关重要。由于改进网络主干不是本文的重点,因此简单地使用了一种称为“DenseNet”(Huang等人,2017)的著名主干,它可以在各种任务中实现最先进的结果,作为从输入数据阵列中提取高质量特征的主干网络。
DenseNet由多个致密块体组成。在每个块中,来自所有先前卷积层的特征被连接在一起。形式上,第(l+1)层的特征映射Ml+1可以计算如下,
其中σ(⋅) 表示特征上的非线性变换。图4显示了Ml+1的计算过程。
根据等式3,在计算Ml+1的过程中保留特征映射M1、M2、…、Ml。考虑到特征映射的串联需要占用空间,与标准卷积网络中的滤波器数量相比,每个卷积层的滤波器数量u设置为一个较小的数字,例如,u=32,例如VGG(Simonyan和Zisserman,2015)和ResNets(He等人,2016)。在这种情况下,(l+1)层中输入特征图的数量将为u1+32×l,其中u1是第一层中的特征图的数量,32是每个层中的滤波器,也可以认为是增长率。一个小的增长率不仅调节了特征的数量,这使得特征提取网络变得相对深入,而且还均衡了每层中添加的特征数量,因为新添加的信息应被视为同等重要。
非线性变换σ(⋅) 在网络中,包括两种类型的操作,归一化操作(批量归一化(Ioffe和Szegedy,2015))和非线性激活操作(校正线性单位函数(Glorot等人,2011))。需要注意的是,1×1卷积可以放在3×3卷积之前,这似乎是一个“瓶颈”,在何等人(2016)、黄等人(2017)中,这些设置能够提高计算效率。因此,遵循“瓶颈设计”的思想,σ(⋅) 以BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3)的形式设计,其中每个Conv(1×1)输出4u特征映射。
除了上述密集连接模块外,网络中还设计了一些下采样模块,以在空间上减小特征地图的大小并提高计算效率(Wu和Shi,2018)。这些模块按照BN-ReLU-Conv(1×1)-Pool(平均2×2)的配置设计为过渡块,并放置在密集块之间。这里的1×1卷积输出一半的输入特征映射。
黄等人(2017)提出了几种不同类型的DenseNet配置,包括DenseNet121、DenseNet169、DenseNet201和DenseNet264。“DenseNetX”中的数字“X”表示分类网络中使用的卷积层的数量。在密集特征提取模块中,考虑到计算效率和GPU内存成本的平衡,采用了DenseNet169的配置。该模块接收输入阵列,该阵列首先通过初始卷积层(“Conv_0”)和初始池层(“Pool_ 0”)进行处理,然后相应地通过四个密集块和三个过渡块。与Huang等人(2017)中的设置不同,“Conv_0”的步长设置为1,并删除了云和雪检测任务的最后一个分类层。密集特征提取模块的配置细节如表1所示。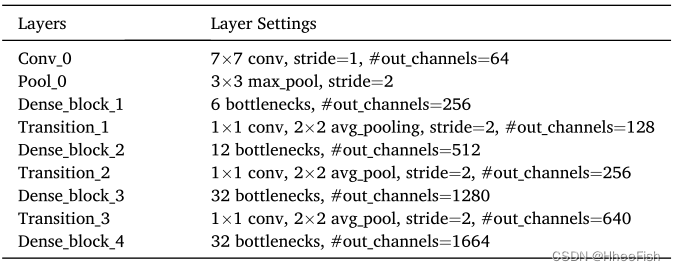
表1密集特征提取模块的配置。
2.3.2.双特征串联
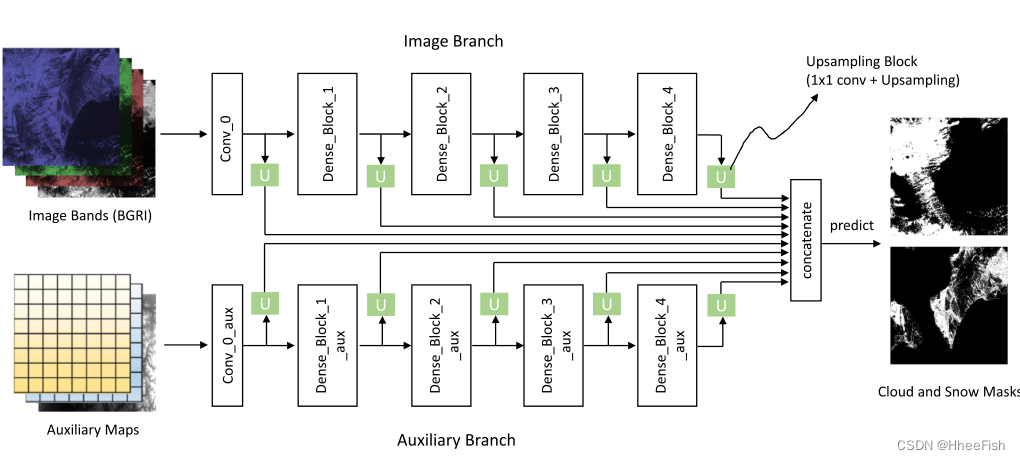
图5。密集特征提取模块的详细信息。该方法同时接收两种类型的输入,即输入遥感图像的原始RGBI波段和由地理信息编码器编码的辅助地图。在这两个分支中,密集特征均由“convo_0”层和以下四个密集块提取。将不同块的特征上采样到相同的大小,并通过1×1卷积调整其通道数,然后沿通道维度连接所有这些特征。最后,使用预测层生成云和雪的像素级分数图。
在上述特征提取过程中,随着层的加深,输出特征图的数量变得更大。与输入的空间分辨率相比,最终输出的空间分辨率降低到16×采样,如表1所示。为了生成高分辨率的云和雪遮罩,必须通过提取特征来提高特征分辨率。这可以通过合并不同块的特征并生成细粒度特征表示来实现。因此,密集特征级联模块就是根据这一目的设计的。在该模块中,使用了蓝绿红红外(BGRI)输入图像和编码辅助地图的初始特征。
如图5所示,对于网络(输入图像分支和辅助地图分支),首先使用双线性插值将每个特征块的空间特征上采样到输入图像的大小。然后,沿通道维度将上采样特征连接在一起。在级联之前,我们还使用1x1卷积来调整每个块特征的通道维度,以便它们具有相同数量的通道。该操作背后的直觉是,假设对于网络中的所有块,在云和雪检测任务中应以相同的重要性查看特征。来自两个分支的所有块的最终连接特征M可以表示为: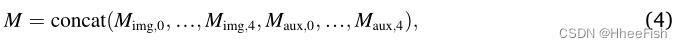
其中,下标“img”和“aux”分别指来自BGRI图像分支和辅助信息分支的特征。下标“0–4”表示密集特征提取模块的“Conv_ 0”、“Dense_ block_ 1”、“Dense_ block_ 2”、“Dense_ block_ 3”和“Dense_ block_ 4”中的上采样特征。
2.3.3.损失设置
在所提出的地理信息网中,使用预测层(带1×1滤波器的卷积层)生成不同类别的像素级分数图:背景S1、云S2和雪S3。使用softmax函数对输出分数图进行归一化,并转换像素分数(−∞,∞)到 概率[0,1]。每个类t={1,2,3}的概率图Pt可以表示为:
由于云和雪的检测本质上是一个像素级分类过程,因此通过使用标准像素级分类损失(也称为交叉熵损失)来训练网络。假设ym∈ {0,1}表示m类的地面真值标签。每个像素的损失函数表示如下:
最后,计算训练集中所有图像的所有像素的平均损失作为最终损失函数。
3.Levir_CS:一种新的大规模云雪检测数据集
建立了一个称为“Levir_CS”的大规模数据集,其中“C”分别表示云,“S”分别表示雪。由于作者实验室的名称为“学习、视觉和遥感实验室”,与(邹和施,2017)类似,该数据集的名称以“Levir”开头。尽管过去已经发布了一些关于该主题的公共数据集,但它们相对较小,不包含地理信息。此外,之前没有用于雪检测的公共数据集。表2显示了我们的数据集与其他公共云检测数据集之间的比较(Scaramuzza等人,2011;Foga等人,2017;Li等人,2017)。与表2中列出的其他数据集相比,LEVIR_CS中的场景数比其他数据集大20×以上,因此,拟议的数据集被称为“大规模”。拟议的Levir_CS数据集位于https://github.com/permanentCH5/GeoInfoNet
高分一号卫星(GF-1)在太阳同步轨道上运行,其中角度为98.0506◦ 平均轨道高度为645公里。回访时间为4天。下降节点为上午10:30。GF-1宽视场传感器(GF-1 WFV)的辐射分辨率为10位。一个GF-1 WFV场景,每个场景宽211公里,长192公里,在所有四个波段的瞬时视野(IFOV)为16米×16米。光谱范围为450 nm至890 nm。具体而言,这些波段的光谱范围分别为450–520 nm(蓝色波段或波段1)、520–590 nm(绿色波段或波段2)、630–690 nm(红色波段或波段3)、770–890 nm(近红外波段或波段4)。
图7。提出的Levir_CS数据集中具有不同类型地面特征的一些示例场景。在每个场景的顶部,给出了地面特征的类型。在每个场景的底部,显示了中心点的经纬度和图像的平均高度。
我们提出的Levir_CS总共由4168个GF-1WFV场景组成。这些场景被随机分为两组,一组包含3068个场景的训练集和一组包含1100个场景的测试集。数据集中的场景具有全局分布,如图6所示。它们涵盖不同类型的地面特征,如平原、高原、水、沙漠、冰等。也有上述地面特征类型的组合。图7显示了一些示例场景。此外,由于这些场景是全球分布的,因此,这些场景可能包含不同类型的气候条件,例如沙漠气候(见图7(c))或海洋气候(见图7(b,e)),这可能有助于类似于(Bi等人,2019)的相关研究。所有场景均于2013年5月至2019年2月采集,下载自http://www.cresda。com/。
在拟议的LEVIR_CS数据集中,对于每个场景,使用了经过辐射校准过程的1A级产品数据,并且当前数据没有经过系统的几何校正。这是因为在许多实际情况下,需要在此产品级别执行云和雪检测,以节省几何校正时间或快速浏览。数据集用户可以根据提供的有理多项式系数(RPC)文件获得ac,以便在需要时进行系统的几何校正。此外,为了减少每个场景的处理时间并加速全局信息的学习过程,类似于(Zou等人,2019),LEVIR_CS数据集中的图像是10倍降采样。对于LEVIR_CS数据集中的每个场景,图像大小为1320×1200,空间分辨率为160m。所有四个波段均使用。因此,DEM(90 m)的分辨率在高度图生成中足够高。因此,选择SRTM数据作为DEM源。
在拟议的LEVIR_CS数据集中,对于每个场景,都提供了地理参考多光谱图像、数字高程模型图像和相应的地面实况图像。数据集中使用的地图投影系统是世界大地测量系统(WGS),使用的是最新版本(WGS 84)。通过该地图投影系统,每个场景的所有图像都可以通过地理信息进行登记。因此,气候条件与地理参考图像的生成无关。对于生成数字高程模型图像,每个场景的平均生成时间为45.62秒。
对于数据集中的所有图像,它们的像素级标签掩码被手动标记为三类:“背景”(标记为0)、“云”(标记为127)和“雪”(标记为255)。与(李等人,2017年)类似,标记过程在Adobe Photoshop中完成。原始图像的蓝色、绿色和红色波段组合成RGB图像,用于手动标记。为了提高标记效率,与(Lu等人,2019)类似,首先通过手动设置阈值来执行预分割,如传统物理方法(Zhong等人,2017)所示。然后,对这些预分割区域进行粗像素分类。云区或雪区的边界通常是模糊的。与之前的研究(李等人,2017年、2019a)一样,使用画笔工具(小于10像素)或套索工具仔细标记图像的这些区域。对于薄云区域,如果地面覆盖不可见,则将其标记为云。对于阴影区域,由于其非常暗且该区域不可见,因此将其标记为背景。在标记困难区域时,使用放大镜工具(局部区域放大超过200%),这有助于标记人员识别像素的确切类别。云阴影检测不是本文的重点,因此,该类没有标记。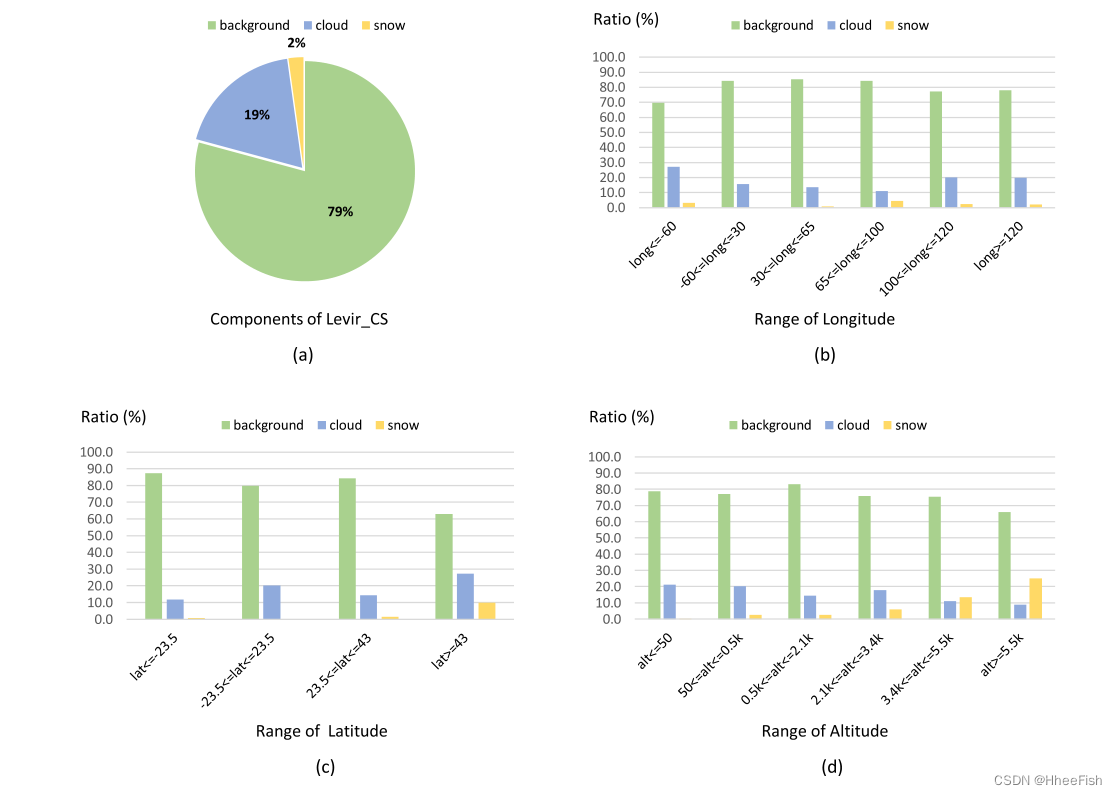
图8。Levir_CS数据集的统计数据来自不同的视图。(a) 三个类别的像素数量:背景占最多(79.2%),而雪占最少(2.2%)。云像素占整个像素总数的18.6%。(b) -(d)分别从经度、纬度和高度视图标记组件。可以看出,这三个类别在不同地区的分布非常不同。
图8显示了Levir_CS数据集的统计信息。从不同视图计算标签组件的分布。如图8(a)所示,在Levir_CS中,背景像素占最多(79.2%),而雪占最少(2.2%)。云像素占整个像素总数的18.6%。图8(b)-(d)分别显示了经度、纬度和海拔视图中的标签组件。从这些图中可以总结出以下观察结果:
- 在不同的位置,这三类像素的总体非常不同
- 云在不同的地理位置很常见。例如,在北美,云以不同的种类和形式出现(Sun等人,2017年)
- 从经度的角度来看,可以看出,在以下范围内下雪的可能性较小:−60◦⩽长的⩽30◦ (大西洋)(参见图7(c,e)示例),而在65◦⩽长的⩽100◦, 更容易找到积雪(示例见图7(d))从纬度的角度来看,可以看出大部分雪出现在高纬度(lat)⩾43◦) (示例见图7(f))。
- 根据(Tran等人,2019年)的数据,在美国,高纬度地区的雪日数较高。此外,在极地高纬度地区,冰雪在某些季节不会融化(Selkowitz和Forster,2016)。赤道地区几乎没有积雪(−23.5◦⩽拉丁美洲⩽23.5◦)(示例见图7(a、c、e)。
- 从海拔高度来看,可以看出,在海拔低于500米的地区,云量百分比较高(例如见图7(a、b、e)),雪百分比随着海拔高度的增加而逐渐增加(例如见图7(d、f))。通常,高海拔地区是山区,这里的积雪随季节有规律地变化(王等人,2018)。对于海拔3400米以上的地区,发现雪比发现云更容易(示例见图7(d))。
从以上统计数据可以看出,利用地理信息进行云雪检测具有重要意义。
边栏推荐
- Guangzhou held work safety conference
- [Q&A]AttributeError: module ‘signal‘ has no attribute ‘SIGALRM‘
- Day-24 UDP, regular expression
- [binary tree] delete points to form a forest
- 《ASP.NET Core 6框架揭秘》样章[200页/5章]
- Multi row and multi column flex layout
- [pytorch practice] image description -- let neural network read pictures and tell stories
- Talk about four cluster schemes of redis cache, and their advantages and disadvantages
- 谷歌浏览器如何重置?谷歌浏览器恢复默认设置?
- Query whether a field has an index with MySQL
猜你喜欢
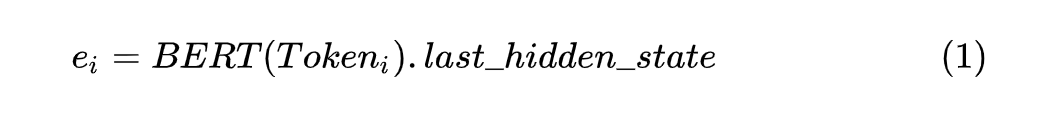
ACL 2022 | 序列标注的小样本NER:融合标签语义的双塔BERT模型

Leetcode skimming: binary tree 27 (delete nodes in the binary search tree)

Sorting, dichotomy
![[statistical learning methods] learning notes - improvement methods](/img/c5/515f171995da8e424de290228b54f8.png)
[statistical learning methods] learning notes - improvement methods

明星企业普渡科技大裁员:曾募资超10亿 腾讯红杉是股东

MPLS experiment
Multi row and multi column flex layout

Day22 deadlock, thread communication, singleton mode
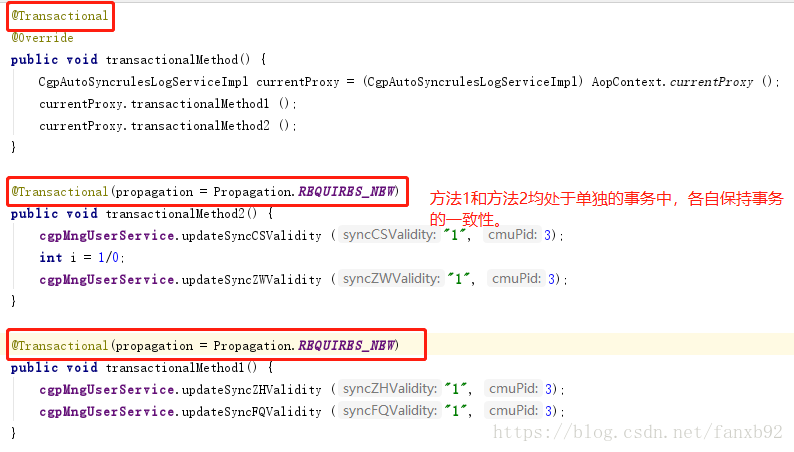
How to apply @transactional transaction annotation to perfection?
Airserver automatically receives multi screen projection or cross device projection
随机推荐
《ASP.NET Core 6框架揭秘》样章[200页/5章]
Leetcode brush questions: binary tree 19 (merge binary tree)
Four functions of opencv
[statistical learning methods] learning notes - Chapter 4: naive Bayesian method
CMU15445 (Fall 2019) 之 Project#2 - Hash Table 详解
layer弹出层的关闭问题
Charles: four ways to modify the input parameters or return results of the interface
.Net下极限生产力之efcore分表分库全自动化迁移CodeFirst
Day-18 hash table, generic
[Q&A]AttributeError: module ‘signal‘ has no attribute ‘SIGALRM‘
[learn wechat from 0] [00] Course Overview
Visual stdio 2017 about the environment configuration of opencv4.1
xshell评估期已过怎么办
认养一头牛冲刺A股:拟募资18.5亿 徐晓波持股近40%
2022a special equipment related management (boiler, pressure vessel and pressure pipeline) simulated examination question bank simulated examination platform operation
Image pixel read / write operation
On valuation model (II): PE index II - PE band
非分区表转换成分区表以及注意事项
ICLR 2022 | 基于对抗自注意力机制的预训练语言模型
[deep learning] image multi label classification task, Baidu paddleclas