当前位置:网站首页>[statistical learning methods] learning notes - Chapter 5: Decision Tree
[statistical learning methods] learning notes - Chapter 5: Decision Tree
2022-07-07 12:34:00 【Sickle leek】
Statistical learning methods learning notes —— Decision tree
Decision tree (decision tree) It is a basic classification and regression method . The main advantage is that the model is readable , Fast classification . Decision tree learning usually consists of three steps : feature selection 、 Generation of decision tree and pruning of decision tree .
1. Decision tree model and learning
1.1 Decision tree model
Definition : Decision tree Classification decision tree model is a kind of tree structure that describes the classification of instances . The decision tree consists of nodes (node) And the directed side (directed edge) form . There are two types of nodes : Internal nodes (internal node) And leaf nodes (leaf node). Internal node represents a feature or attribute , A leaf node represents a class .
1.2 Decision tree and if-then The rules
Each path from the root node to the leaf node of the decision tree constructs a rule : The characteristics of the internal nodes of the path correspond to the conditions of the rules , The class of leaf node corresponds to the conclusion of rule .
Path of decision tree or its corresponding if-then Rule set has an important property : Mutually exclusive and complete . in other words , Every instance is covered by a path or a rule , And only covered by one path or one rule .
1.3 Decision tree and conditional probability distribution
The decision tree also represents the conditional probability distribution of a class under a given characteristic condition , This conditional probability distribution is defined in a partition of the feature space (partition) On , Dividing feature space into disjoint elements (cell) Or area (region), And defining a class probability distribution in each unit constitutes a conditional probability distribution .
A path of the decision tree corresponds to a unit in the partition . The conditional probability distribution represented by the decision tree is composed of the conditional probability distribution of the class under the given conditions of each unit . Leaf nodes ( unit ) The conditional probability on tends to favor a certain class , That is, the probability of belonging to a certain class is high .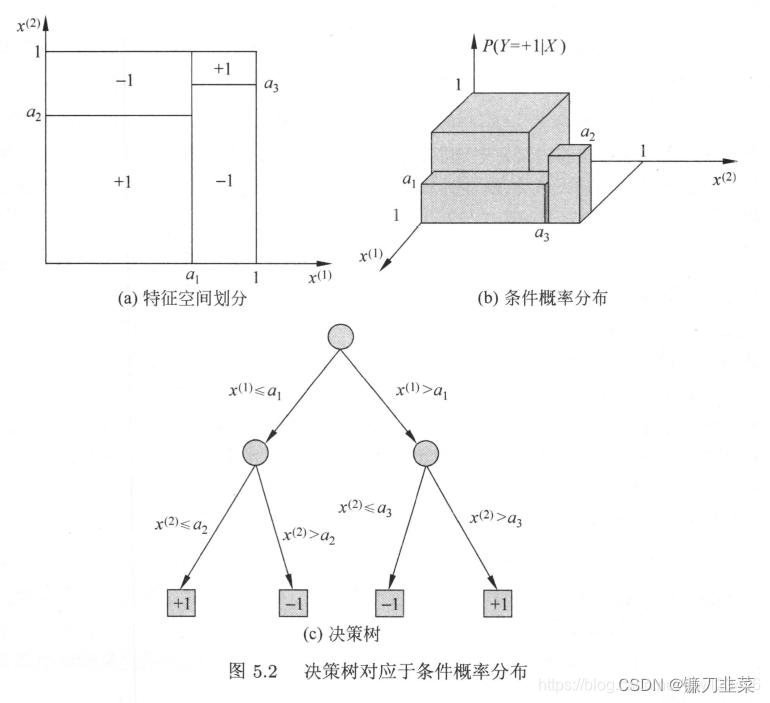
1.4 Decision tree learning
Suppose a given training data set D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } D = \{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} D={ (x1,y1),(x2,y2),⋯,(xN,yN)}, among , x i = ( x i 1 , x i 2 , ⋯ , x i n ) T x_i = (x_i^1,x_i^2,\cdots,x_i^n)^T xi=(xi1,xi2,⋯,xin)T Enter an instance for ( Eigenvector ), n n n For the number of features , y i ∈ { 1 , 2 , ⋯ , K } y_i \in \{1,2,\cdots,K\} yi∈{ 1,2,⋯,K} Tag for class , i = 1 , 2 , ⋯ , N i = 1,2, \cdots,N i=1,2,⋯,N, N N N Is sample size .
Decision tree learning The goal is yes Build a decision tree model according to the given training data , It can classify instances correctly .
Decision tree learning The essence On is A set of classification rules are summarized from the training data . There may be more than one decision tree that can correctly classify the training data , Or maybe none of them . We need a decision tree with less contradiction with the training data , meanwhile Good generalization ability .
Decision tree learning Use the loss function to express this goal . Loss function of decision tree learning It is usually a regularized maximum likelihood function . The strategy of decision tree learning is Minimization with loss function as objective function .
When the loss function is determined , The learning problem becomes the problem of selecting the optimal decision tree in the sense of loss function .
Decision tree learning The algorithm is usually a recursive selection of optimal features , The training data are segmented according to this feature , The process of making the best classification of each sub data set . This process corresponds to the division of feature space , It also corresponds to the construction of decision tree .
- Start , Build the root node , Put all training data in the root node . Choose an optimal feature , According to this feature, the training data is divided into subsets , Make each subset have the best classification under the current conditions .
- If these subsets can be classified basically correctly , Then build leaf nodes , Divide these subsets into corresponding leaf nodes ;
- If there are subsets that cannot be classified basically correctly , Then select new optimal features for these subsets , Continue to split it , Build the corresponding node .
- If you go on recursively , Until all training data subsets are basically correctly classified , Or no suitable characteristics . This generates a decision tree .
The decision tree generated by the above method may have a good classification ability for the training data , but It may not have a good classification ability for unknown test data , That is, fitting phenomenon may have occurred . We need to Prune the generated tree from bottom to top , Make the tree simpler , So that it has better generalization ability .
If There are many features , Or at the beginning of decision tree learning , Select features , Only features with sufficient classification ability for training data are left .
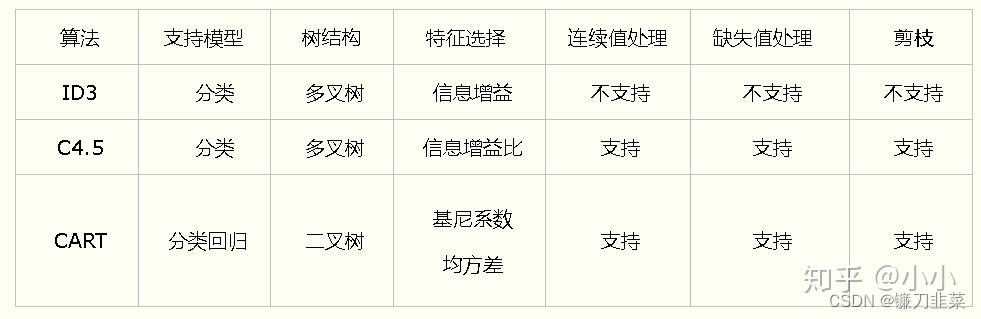
It can be seen that , Decision tree learning algorithm includes feature selection 、 The generation of decision tree and the pruning process of decision tree . Common algorithms for decision tree learning are ID3、C4.5 And CART.
2. feature selection
2.1 Feature selection problem
Feature selection is to select features with classification ability for training data . This can improve the efficiency of decision tree learning . If using a feature for classification results and random classification results are not very different , It is said that this feature has no classification ability . Generally, the criterion of feature selection is Information gain or Information gain ratio .
2.2 Information gain
In information theory and probability statistics , entropy (entropy) Is a measure of the uncertainty of a random variable . set up X Is a discrete random variable with finite values , The probability distribution is :
P ( X = x i ) = p i , i = 1 , 2 , . . . , n P(X=x_i)=p_i, i=1,2,...,n P(X=xi)=pi,i=1,2,...,n
Then the random variable X Entropy is defined as :
H ( X ) = − ∑ i = 1 n p i log p i H(X)=-\sum_{i=1}^n p_i\log {p_i} H(X)=−i=1∑npilogpi
if p i = 0 p_i=0 pi=0, The definition is 0 log 0 = 0 0\log 0=0 0log0=0. Usually logarithms are expressed in 2 To base or base on e Bottom ( Natural logarithm ), The units of entropy are called bits (bit) Or Nate (nat).
By definition , Entropy only depends on X The distribution of , And with the X The value of has nothing to do with , So you can also X The entropy of H ( p ) H(p) H(p), namely
H ( p ) = − ∑ i = 1 n p i log p i H(p)=-\sum_{i=1}^n p_i \log {p_i} H(p)=−i=1∑npilogpi
The greater the entropy , The greater the uncertainty of random variables . Verifiable from definition :
0 ≤ H ( p ) ≤ log n 0\le H(p)\le \log n 0≤H(p)≤logn
When a random variable takes only two values , for example 1,0 when , The distribution of is :
P ( X = 1 ) = p , P ( X = 0 ) = 1 − p , 0 ≤ p ≤ 1 P(X=1)=p, P(X=0)=1-p, 0\le p \le 1 P(X=1)=p,P(X=0)=1−p,0≤p≤1
The entropy is :
H ( p ) = − p log 2 p − ( 1 − p ) log 2 ( 1 − p ) H(p)=-p \log_2 p-(1-p)\log_2 {(1-p)} H(p)=−plog2p−(1−p)log2(1−p)
At this time , entropy H ( p ) H(p) H(p) Random probability p p p The curve of is shown in the figure 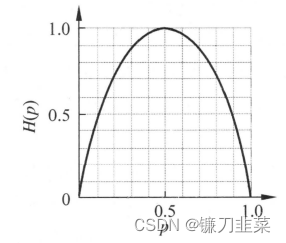
When p = 0 p=0 p=0 or p = 1 p=1 p=1 when H ( p ) = 0 H(p)=0 H(p)=0, Random variables have no uncertainty at all . When p = 0.5 p = 0.5 p=0.5 when , H ( p ) = 1 H ( p ) = 1 H(p)=1 , Entropy is the maximum , The random variable has the greatest uncertainty .
Conditional entropy (conditional entropy) H ( Y ∣ X ) H(Y|X) H(Y∣X) I have a random variable X X X Is a random variable Y Y Y uncertainty . H ( Y ∣ X ) H(Y|X) H(Y∣X) Defined as X X X Given the conditions Y Y Y The entropy pair of the conditional probability distribution X X X Mathematical expectation
H ( Y ∣ X ) = ∑ i = 1 n p i H ( Y ∣ X = x i ) H(Y|X)=\sum_{i=1}^n p_iH(Y|X=x_i) H(Y∣X)=i=1∑npiH(Y∣X=xi)
here p i = P ( X = x i ) , i = 1 , 2 , . . . , n p_i=P(X=x_i), i=1,2,...,n pi=P(X=xi),i=1,2,...,n.
When the probability in entropy and conditional entropy is obtained by maximum likelihood estimation , The corresponding entropy and conditional entropy are called Experience in entropy (empirical entropy) and Empirical condition entropy (empirical conditional entropy). here , If by 0 probability , Then order 0 log 0 = 0 0\log 0=0 0log0=0.
Information gain (information gain) Express To learn that feature X The information that makes the class Y The degree to which the uncertainty of information is reduced .
Definition ( Information gain ): features A A A On the training data set D D D Information gain of g ( D , A ) g(D,A) g(D,A) Defined as a set D D D The experience of the entropy H ( D ) H(D) H(D) With the characteristics of A A A Given the conditions D D D Entropy of empirical conditions H ( D ∣ A ) H(D|A) H(D∣A) The difference between the , namely
g ( D , A ) = H ( D ) − H ( D ∣ A ) (5.6) g(D,A) = H(D) - H(D|A) \tag{5.6} g(D,A)=H(D)−H(D∣A)(5.6)
In a general way , entropy H ( Y ) H(Y) H(Y) And condition entropy H ( Y ∣ X ) H(Y|X) H(Y∣X) The difference is called Mutual information (mutual information). The information gain in decision tree learning is equivalent to the mutual information of class and feature in training data set .
Decision tree learning applies information gain criteria to select features : Given training set D D D And characteristics A A A, Experience in entropy H ( D ) H(D) H(D) Represents a pair of data sets D D D The uncertainty of classification . And empirical conditional entropy H ( D ∣ A ) H(D|A) H(D∣A) It means in the feature A A A Given the conditions for the dataset D D D The uncertainty of classification . So their difference , Information gain , It means that due to the characteristics A A A And make the data set D D D The degree to which the uncertainty of classification is reduced . obviously , Information gain depends on features , Different features often have different information gain . Features with large information gain have stronger classification ability .
Then we get the feature selection method according to the information gain criterion : On the training data set ( Or subset ) D D D, Calculate the information gain of each feature , And compare their sizes , Select the feature with maximum information gain .
Algorithm ( Algorithm of information gain ):
Input : Training data set D And characteristics A;
Output : features A On the training data set D Information gain of g ( D , A ) g(D, A) g(D,A).
2.3 Information gain ratio
Take information gain as the feature of dividing training data set , There is a problem of choosing more features . Use Information gain ratio (information gain ratio) This problem can be corrected .
Definition ( Information gain ratio ): features A On the training data set D The information gain ratio of g R ( D , A ) g_R(D,A) gR(D,A) Defined as its information gain g ( D , A ) g(D,A) g(D,A) With training datasets D About the characteristics of A The entropy of the value of H A ( D ) H_A(D) HA(D) The ratio of the , namely :
g R ( D , A ) = g ( D , A ) H A ( D ) g_R(D,A)=\frac{g(D,A)}{H_A(D)} gR(D,A)=HA(D)g(D,A)
among , H A ( D ) = − ∑ i = 1 n ∣ D i ∣ D log 2 ∣ D i ∣ D H_A(D)=- \sum_{i=1}^n \frac{|D_i|}{D} \log_2 \frac{|D_i|}{D} HA(D)=−∑i=1nD∣Di∣log2D∣Di∣,n Is the characteristic A Number of values .
3. Decision tree generation
3.1 ID3 Algorithm
ID3 The core of the algorithm is to apply the information gain criterion to select features on each node of the decision tree , Build the decision tree recursively . The way to do it is : From the root node (root node) Start , Calculate the information gain of all possible features for nodes , The feature with the largest information gain is selected as the feature of the node , The sub nodes are established according to the different values of the feature ; Then call the above method recursively to the child node , Build decision tree ; Until the information gain of all features is very small or no features can be selected , Finally, a decision tree is obtained .ID3 It's equivalent to using the maximum likelihood method to select the probability model .
Algorithm (ID3 Algorithm ):
Input : Training data set D, Feature set A, threshold ε ε \varepsilonε εε;
Output : Decision tree T
(1) if D All instances in belong to the same class C k C_k Ck, be T It is a single node tree , And C k C_k Ck As a class token for this node , return T;
(2) if A For an empty set , be T It is a single node tree , And will D The class with the largest number of instances in C k C_k Ck As a class token for this node , return T;
(3) otherwise , Calculate according to the algorithm introduced above A Feature pairs in D Information gain of , Select the feature with maximum information gain A g A_g Ag;
(4) If A g A_g Ag The information gain of is less than the threshold ε ε \varepsilonε εε( Set the threshold to prevent the score from being too fine ), Then put T It is a single node tree , And will D The class with the largest number of instances in C k C_k Ck As a class token for this node , return T;
(5) otherwise , Yes A g A_g Ag Every possible value of a i a_i ai, In accordance with the A g = a i A_g = a_i Ag=ai take D Split into several non empty subsets D i D_i Di, take D i D_i Di Use the class with the largest number of instances in as a marker , Building child nodes , The tree is composed of nodes and their children T, return T;
(6) Right. i Child node , With D i D_i Di As the training set , With A − { A g } A - \{A_g\} A−{ Ag} Is a feature set , Call step recursively 1~5, Get the subtree T i T_i Ti, return T i T_i Ti.
3.2 C4.5 Generation algorithm of
C4.5 Algorithm and ID3 The algorithm is compared with , In the process of generation , Using information gain ratio to select features .
Algorithm (C4.5 Generation algorithm of )
In these two algorithms Control the depth or width of the generated tree by setting a threshold , This practice is called pre pruning . Another way is After generating the decision tree , Then prune , It's called back pruning .
4. Pruning of the decision tree
The decision tree generation algorithm recursively generates the decision tree , Until it can't continue . The tree generated in this way often classifies the training data very accurately , But the classification of unknown test data is not so accurate , That is to say Over fitting phenomenon . The solution to this problem is to consider reducing the complexity of the decision tree , Simplify the generated decision tree .
The process of simplifying the generated tree in decision tree learning is called prune (pruning). Pruning cuts some subtree or leaf nodes from the generated tree , And take its root node or parent node as a new leaf node , So as to simplify the classification tree model .
Decision tree pruning often By minimizing the loss function of the whole decision tree (loss function) To achieve .
Set tree T The number of leaf nodes is |T|,t It's a tree. T Leaf nodes of , The leaf node has N t N_t Nt A sample points , among k The sample points of class are N t k N_{tk} Ntk individual , k = 1 , 2 , . . . , K k=1,2,...,K k=1,2,...,K, H t ( T ) H_t(T) Ht(T) For leaf nodes t Empirical entropy on , α ≥ 0 \alpha \ge 0 α≥0 Is the parameter , Then the loss function of decision tree learning can be defined as :
C α ( T ) = ∑ t = 1 ∣ T ∣ N t H t ( T ) + α ∣ T ∣ C_\alpha (T)=\sum_{t=1}^{|T|} N_tH_t(T)+\alpha |T| Cα(T)=t=1∑∣T∣NtHt(T)+α∣T∣
Where the empirical entropy is :
H t ( T ) = − ∑ k N t k N t log N t k N t H_t(T)=-\sum_k \frac{N_{tk}}{N_t} \log \frac{N_{tk}}{N_t} Ht(T)=−k∑NtNtklogNtNtk
among , C ( T ) C(T) C(T) Represents the prediction error of the model to the training data , That is, the fitting degree of the model and the training data , When the entropy of leaf nodes is smaller , That is, the smaller the loss , Represents the lower the level of chaos , The better the classification ;
∣ T ∣ ∣T∣ ∣T∣ Represents the complexity of the model . When the number of leaf nodes is larger , It shows that the more complex the decision tree , The worse the generalization ability . The larger α \alpha α Promote the selection of simpler trees . When α = 0 \alpha = 0 α=0 It means only considering the fitting degree between the model and the training data , Regardless of complexity .
prune , Is that when α \alpha α When it's certain , Choose the model with the smallest loss function . The decision tree generation algorithm learns local models , The decision tree pruning learning model as a whole .
Algorithm ( Tree pruning algorithm ):
Input : Generate the whole tree of algorithm Chen Sheng T, Parameters α \alpha α
Output : The sub tree after construction T α T_\alpha Tα
(1) Calculate the empirical entropy of each node
(2) Recursively retract from the leaf node of the tree .
(3) If a group of leaf nodes retract to the whole tree before and after the parent node, they are T B T_B TB And T A T_A TA, The corresponding loss functions are C α ( T B ) C_\alpha(T_B) Cα(TB) And C α ( T A ) C_\alpha(T_A) Cα(TA), if C α ( T A ) ≤ C α ( T B ) C_\alpha(T_A) \leq C_\alpha(T_B) Cα(TA)≤Cα(TB), Then prune , Change the parent node into a new leaf node ;
(4) Return steps 2, Until we can't continue , Get the subtree with the smallest loss function T α T_\alpha Tα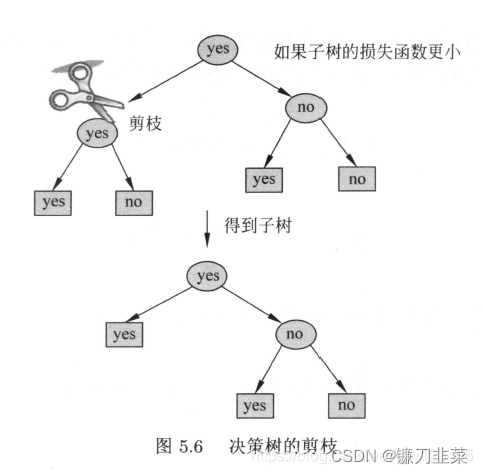
Simply speaking , Namely If you subtract a branch , Make this branch a leaf node , The loss function corresponding to the new tree is smaller , Then you can prune , Otherwise, you can't prune .
5. CART Algorithm
Classification and regression trees (classification and regression tree, CART) Model is a widely used decision tree learning method . It can be used for both classification and regression .
The decision tree it generates is a binary tree . It's described above ID3 Algorithm and C4.5 In the algorithm, , If one of the features has more than one ( More than two ) Category , Then it needs to be divided into multiple branches . however CART Algorithm no matter how many categories , It is only divided into two parts .
CART The algorithm consists of the following two steps :
(1) Decision tree generation : Generating decision tree based on training data set , The decision tree should be as large as possible ;
(2) Decision tree pruning : Prune the generated tree with the validation data set and select the optimal subtree , In this case, the minimum loss function is used as the pruning criterion .
5.1 CART Generate
The generation of decision tree is the process of Constructing Binary Decision Tree recursively . Use the square error minimization criterion for the regression tree , Use Gini index for classification tree (Gini index) Minimization criterion , Make feature selection , Generate binary tree .
- The formation of regression trees
hypothesis X and Y Input and output variables , also Y Is a continuous variable , Given data set D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , , . . . , ( x N , y N ) } D=\{(x_1,y_1),(x_2,y_2),,...,(x_N,y_N)\} D={ (x1,y1),(x2,y2),,...,(xN,yN)}, Consider how to generate a regression tree .
A regression tree corresponds to the input space ( Feature space ) And the output value on the divided unit . Suppose that the input space has been divided into M A unit R 1 , R 2 , . . . , R M R_1,R_2,...,R_M R1,R2,...,RM, And in each unit R m R_m Rm It has a fixed output value on it c m c_m cm, So the regression tree model can be expressed as
f ( x ) = ∑ m = 1 M c m I ( x ∈ R m ) f(x)=\sum_{m=1}^M c_m I(x\in R_m) f(x)=m=1∑McmI(x∈Rm)
When the partition of the input space is determined , You can use the squared error ∑ x i ∈ R m ( y i − f ( x i ) ) 2 \sum_{x_i \in R_m} (y_i-f(x_i))^2 ∑xi∈Rm(yi−f(xi))2 To express the prediction error of the regression tree on the training data , The optimal output value of each element is solved by the criterion of minimum square error .
Easy to know , unit R m R_m Rm Upper c m c_m cm The optimal value c ^ m \hat{c}_m c^m yes R m R_m Rm All input instances on x i x_i xi Corresponding output y i y_i yi The average of , namely
c ^ m = a v e ( y i ∣ x i ∈ R m ) \hat{c}_m=ave(y_i|x_i\in R_m) c^m=ave(yi∣xi∈Rm)
The problem is how to divide the input space . Here the heuristic Methods , Select the first j A variable x ( j ) x^{(j)} x(j) And the value it takes s s s As a segmentation variable (spliting variable) And the syncopation point (spliting potting), And define two regions :
R 1 ( j , s ) = { x ∣ x ( j ) ≤ s } and R 2 ( j , s ) = { x ∣ x ( j ) > s } R_1(j, s)=\{x| x^{(j)}\le s\} and R_2(j, s)=\{x|x^{(j)}>s\} R1(j,s)={ x∣x(j)≤s} and R2(j,s)={ x∣x(j)>s}
Then find the optimal segmentation variable j And the optimal tangent point s. In particular , solve
min j , s [ min c 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + min c 2 ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 ] \min_{j,s}[\min_{c_1}\sum_{x_i\in R_1(j,s)} (y_i-c_1)^2+\min_{c_2} \sum_{x_i\in R_2(j,s)}(y_i-c_2)^2] j,smin[c1minxi∈R1(j,s)∑(yi−c1)2+c2minxi∈R2(j,s)∑(yi−c2)2]
For fixed input variables j You can find the optimal tangent point s.
c ^ 1 = a v e ( y i ∣ x i ∈ R 1 ( j , s ) ) and c ^ 2 = a v e ( y i ∣ x i ∈ R 2 ( j , s ) ) \hat{c}_1=ave(y_i|x_i\in R_1(j,s)) and \hat{c}_2=ave(y_i|x_i \in R_2(j,s)) c^1=ave(yi∣xi∈R1(j,s)) and c^2=ave(yi∣xi∈R2(j,s))
Traverse all input variables , Find the optimal segmentation variable j, Form a pair of (j, s). According to this, the input space is divided into two trends . next , Repeat the above division process for each area . Until the stop condition is met , This generates a regression tree . Such a regression tree is usually called Least squares regression tree (least squares regression tree).
Algorithm ( Least square regression tree generation algorithm ):
Input : Training data set D
Output : Back to the tree f ( x ) f(x) f(x)
In the input space where the training data set is located , Recursively divide each region into two sub regions and determine the output value on each sub region , Building binary decision tree ;
(1) Choose the best segmentation variable j And the syncopation point s, solve :
min j , s [ min c 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + min c 2 ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 ] \min_{j,s}[\min_{c_1}\sum_{x_i\in R_1(j,s)} (y_i-c_1)^2+\min_{c_2} \sum_{x_i\in R_2(j,s)}(y_i-c_2)^2] j,smin[c1minxi∈R1(j,s)∑(yi−c1)2+c2minxi∈R2(j,s)∑(yi−c2)2]
Traverse the variable j, For fixed segmentation variables j Scanning segmentation point s, Select the pair that minimizes the above formula (j, s).
(2) Use the selected right (j, s) Divide the area and determine the output value of the response :
R 1 ( j , s ) = { x ∣ x ( j ) ≤ s } and R 2 ( j , s ) = { x ∣ x ( j ) > s } R_1(j, s)=\{x| x^{(j)}\le s\} and R_2(j, s)=\{x|x^{(j)}>s\} R1(j,s)={ x∣x(j)≤s} and R2(j,s)={ x∣x(j)>s}
c ^ m = 1 N m ∑ x i ∈ R m ( j , s ) y i , x ∈ R m , m = 1 , 2 \hat{c}_m=\frac{1}{N_m}\sum_{x_i\in R_m(j, s)} y_i, x\in R_m, m=1,2 c^m=Nm1xi∈Rm(j,s)∑yi,x∈Rm,m=1,2
(3) Continue calling steps on two sub areas (1)(2). Until the stop condition is met .
(4) Divide the input space into M Regions R 1 , R 2 , . . . , R M R_1,R_2,...,R_M R1,R2,...,RM, Generate decision tree :
f ( x ) = ∑ m = 1 M c ^ m I ( x ∈ R m ) f(x)=\sum_{m=1}^M \hat{c}_m I(x\in R_m) f(x)=m=1∑Mc^mI(x∈Rm)
- The generation of the classification tree
The classification tree uses Gini index to select the best features , At the same time, the optimal binary segmentation point of the feature is determined .
Definition ( gini index ) Classification problem . Suppose there is K K K Classes , The sample point is the first k k k The probability of each class is p k p_k pk, Then the gini index of the probability distribution is defined as G i n i ( p ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 (5.12) Gini(p) = \sum_{k=1} ^ K p_k(1-p_k) = 1 - \sum_{k=1}^K p_k^2 \tag{5.12} Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2(5.12)
It's used here ∑ k = 1 K p k = 1 \sum_{k=1}^K p_k = 1 ∑k=1Kpk=1
For class II Classification Problems , If the sample point belongs to the 1 The probability of each class is p, Then the Gini index of the probability distribution is
G i n i ( p ) = 2 p ( 1 − p ) Gini(p)=2p(1−p) Gini(p)=2p(1−p)
For a given set of samples D, Its Gini index is
G i n i ( D ) = 1 − ∑ k = 1 K ( C k D ) 2 Gini(D)=1-\sum_{k=1}^K (\frac{C_k}{D})^2 Gini(D)=1−k=1∑K(DCk)2
here , C k C_k Ck yes D Belong to No k Sample subset of class ,K It's the number of classes .
If the sample set D According to the characteristics of A Whether to take a possible value a Be divided into D 1 D_1 D1 and D 2 D_2 D2 Two parts , namely
D 1 = { ( x , y ) ∈ D ∣ A ( x ) = a } , D 2 = D − D 1 D_1 = \{(x,y) \in D|A(x) = a\} ,D_2 = D - D_1 D1={ (x,y)∈D∣A(x)=a},D2=D−D1
It's in the characteristics A Under the condition of , aggregate D The Gini index of is defined as
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) (5.15) Gini(D,A) = \frac{|D_1|}{|D|}Gini(D_1) + \frac{|D_2|}{|D|}Gini(D_2) \tag{5.15} Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)(5.15)
gini index G i n i ( D ) Gini(D) Gini(D) Represents a collection D D D uncertainty , gini index G i n i ( D , A ) Gini(D,A) Gini(D,A) Express the classics A = a A=a A=a Split set D D D uncertainty . The larger the Gini index , The greater the uncertainty .
The figure below shows the Gini index in the class II classification problem Gini§、 entropy ( Unit bit ) Half H ( p ) / 2 H(p)/2 H(p)/2 And classification error rate . Abscissa represents probability p, The ordinate represents the loss . It can be seen that the curve of Gini index and entropy half is very close , Can approximately represent the classification error rate .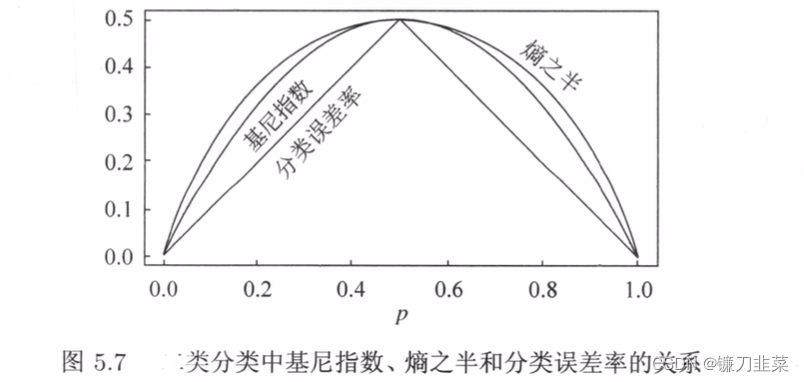
Algorithm (CART generating algorithm ):
Input : Training data set D, The conditions for stopping the calculation ;
Output :CART Decision tree
According to the training data set , Start at the root node , Recursively perform the following operations on each node , Building binary decision tree :
5.2 CART prune
CART Pruning algorithm from ” Complete growth “ Subtract some subtrees from the bottom of the decision tree , Make the decision tree smaller ( The model becomes simpler ), So that we can have a more accurate prediction of unknown data .
CART The pruning algorithm consists of two steps : First, the decision tree generated from the generation algorithm T 0 T_0 T0 The bottom begins to prune constantly , until T 0 T_0 T0 The root node , Form a sub sequence tree { T 0 , T 1 , . . . , T n } \{T_0,T_1,...,T_n\} { T0,T1,...,Tn}; And then through Cross validation Test the subtree sequence on an independent validation data set , Select the optimal subtree .
prune , Form a sub sequence tree
In the pruning process , Calculate the loss function of the subtree C α ( T ) = C ( T ) + α ∣ T ∣ C_\alpha(T)=C(T)+\alpha|T| Cα(T)=C(T)+α∣T∣, among T For any subtree ,C(T) For the prediction error of training data ( Such as Gini index ), ∣ T ∣ |T| ∣T∣ Is the number of leaf nodes of the subtree , α ≥ 0 \alpha \ge 0 α≥0 Is the parameter , C α ( T ) C_\alpha (T) Cα(T) The parameter is α \alpha α Time subtree T The overall loss of . Parameters α \alpha α Weigh the fitting degree of training data and the complexity of the model .
To be fixed α \alpha α, There must be a loss function C α ( T ) C_\alpha (T) Cα(T) The smallest subtree , Express it as T α T_\alpha Tα. T α T_\alpha Tα In loss function C α ( T ) C_\alpha (T) Cα(T) It is optimal in the smallest sense .The subtree sequence obtained by pruning { T 0 , T 1 , . . . , T n } \{T_0,T_1,...,T_n\} { T0,T1,...,Tn} The optimal subtree is selected through cross validation T α T_\alpha Tα
In particular , Using independent validation data sets , Test subtree sequence T 0 , T 1 , . . . , T n T_0,T_1,...,T_n T0,T1,...,Tn Square error or Gini index of each tree in . The decision tree with the smallest square error or Gini index is considered to be the optimal decision tree . In the subtree sequence , Each subtree T 0 , T 1 , . . . , T n T_0,T_1,...,T_n T0,T1,...,Tn All correspond to a parameter α 1 , α 2 , . . . α n \alpha_1,\alpha_2,...\alpha_n α1,α2,...αn, therefore , When the optimal subtree T k T_k Tk When it's certain , Corresponding α k \alpha_k αk It's also certain that , That is, the optimal decision tree T α T_\alpha Tα.
Algorithm (CART Pruning algorithm )
Input :CART Algorithm generated decision tree T 0 T_0 T0
Output : Optimal decision tree T α T_\alpha Tα
(1) set up k = 0 , T = T 0 k=0, T=T_0 k=0,T=T0
(2) set up α = + ∞ \alpha=+\infty α=+∞
(3) From bottom to top to each internal node t Calculation C ( T ) C(T) C(T), ∣ T t ∣ |T_t| ∣Tt∣ as well as g ( t ) = C ( t ) − C ( T t ) ∣ T t − 1 ∣ , α = min ( α , g ( t ) ) g(t)=\frac{C(t)-C(T_t)}{|T_t-1|}, \alpha = \min (\alpha, g(t)) g(t)=∣Tt−1∣C(t)−C(Tt),α=min(α,g(t)), here , T t T_t Tt Said to t The subtree of the root node , C ( T t ) C(T_t) C(Tt) It's the prediction error of training data , ∣ T t ∣ |T_t| ∣Tt∣ yes T t T_t Tt The number of leaf nodes of .
(4) Yes g ( t ) = α g(t)=\alpha g(t)=α Internal node of t Pruning , And for leaf nodes t WithMajority votingDetermine its class , Get the tree T
(5) set up k = k + 1 , α k = α , T k = T k=k+1, \alpha_k=\alpha, T_k=T k=k+1,αk=α,Tk=T
(6) If T k T_k Tk It is not a tree composed of root node and two leaf nodes , Then go back to step (3); Otherwise the T k = T n T_k=T_n Tk=Tn
(7) Using cross validation in subtree sequence { T 0 , T 1 , . . . , T n } \{T_0,T_1,...,T_n\} { T0,T1,...,Tn} Select the best subtree T α T_\alpha Tα.
summary
No matter what ID3,C4.5,CART It is to choose an optimal feature to make classification decision , But most , Classification decision is not determined by a certain feature , It's a set of features . The decision tree obtained in this way is more accurate , This decision tree is called Multivariate decision trees (multi-variate decision tree). When selecting the best feature , Multivariable decision tree is not to select an optimal feature , Instead, choose an optimal linear combination of features to make a decision . Representative algorithm OC1.
Advantages of decision trees :
(1) Compared to black box classification models like neural networks , The decision tree can be explained logically .
(2) You can deal with both discrete and continuous values . Many algorithms just focus on discrete or continuous values .
(3) The cost of using decision tree prediction is O(log2m).m Sample size .
(4) Good fault tolerance for outliers , High robustness .
Disadvantages of using decision trees :
(1) Decision tree algorithm is very easy to over fit , This leads to weak generalization ability . It can be improved by setting the minimum number of samples and limiting the depth of decision tree .
(2) The decision tree will change a little because of the sample , Cause dramatic changes in tree structure . This can be solved by integrated learning and so on .
(3) If the sample size of some features is too large , Generating decision trees tends to favor these features . This can be improved by adjusting the sample weight .
Reference material
[1] 《 Statistical learning method 》 expericnce
[2] You know : Little 《 Statistical learning method 》( The fifth chapter ) Decision tree
边栏推荐
- 通讯协议设计与实现
- SQL Lab (36~40) includes stack injection, MySQL_ real_ escape_ The difference between string and addslashes (continuous update after)
- <No. 9> 1805. Number of different integers in the string (simple)
- Tutorial on the principle and application of database system (008) -- exercises on database related concepts
- SQL blind injection (WEB penetration)
- Sort out the garbage collection of JVM, and don't involve high-quality things such as performance tuning for the time being
- Apache installation problem: configure: error: APR not found Please read the documentation
- SQL lab 1~10 summary (subsequent continuous update)
- 【统计学习方法】学习笔记——逻辑斯谛回归和最大熵模型
- 牛客网刷题网址
猜你喜欢

【统计学习方法】学习笔记——支持向量机(上)
Unity map auto match material tool map auto add to shader tool shader match map tool map made by substance painter auto match shader tool

即刻报名|飞桨黑客马拉松第三期盛夏登场,等你挑战

【深度学习】图像多标签分类任务,百度PaddleClas

对话PPIO联合创始人王闻宇:整合边缘算力资源,开拓更多音视频服务场景
Visual studio 2019 (localdb) \mssqllocaldb SQL Server 2014 database version is 852 and cannot be opened. This server supports version 782 and earlier
ENSP MPLS layer 3 dedicated line

Learning and using vscode
SQL head injection -- injection principle and essence
【PyTorch实战】用RNN写诗
随机推荐
SQL lab 26~31 summary (subsequent continuous update) (including parameter pollution explanation)
OSPF exercise Report
MPLS experiment
Utiliser la pile pour convertir le binaire en décimal
Introduction and application of smoothstep in unity: optimization of dissolution effect
Multi row and multi column flex layout
平安证券手机行开户安全吗?
SQL lab 1~10 summary (subsequent continuous update)
【玩转 RT-Thread】 RT-Thread Studio —— 按键控制电机正反转、蜂鸣器
【统计学习方法】学习笔记——支持向量机(上)
Apache installation problem: configure: error: APR not found Please read the documentation
Tutorial on principles and applications of database system (010) -- exercises of conceptual model and data model
Static vxlan configuration
"Series after reading" my God! It's so simple to understand throttling and anti shake~
JS to convert array to tree data
Realize all, race, allsettled and any of the simple version of promise by yourself
Customize the web service configuration file
Pule frog small 5D movie equipment | 5D movie dynamic movie experience hall | VR scenic area cinema equipment
密码学系列之:在线证书状态协议OCSP详解
BGP third experiment report