当前位置:网站首页>【PyTorch实战】图像描述——让神经网络看图讲故事
【PyTorch实战】图像描述——让神经网络看图讲故事
2022-07-07 10:28:00 【镰刀韭菜】
Image Caption: 图像描述,又称为图像标注,就是从给定的图像生成一段描述文字。图像描述是深度学习中十分有趣的一个研究方向,也是计算机视觉的一个关键目标。 对于图像描述的任务,神经网络不仅要了解图中有哪些对象,对象之间的关系,还要使用自然语言来描述这些对象的关系。

图像描述用到的数据集通常是MS COCO。COCO数据集使用的是英文语料库,这里使用2017年9月~12月举办的AI Challenger比赛中的”图像中文描述“子任务的数据。
地址链接: https://pan.baidu.com/s/1K4DUjkqCyNNSysP31f5lJg?pwd=y35v 提取码: y35v
1. 图像描述介绍
利用深度学习完成图像描述的工作可以追溯到2014年百度研究院发表的Explain Images with Multimodal Recurrent Neural Networks论文,将深度卷积神经网络和深度循环神经网络结合,用于解决图像标注与图像和语句检索等问题。
另一篇论文:Show and tell: A neural image caption generator, 这篇论文提出的Caption模型如下图所示: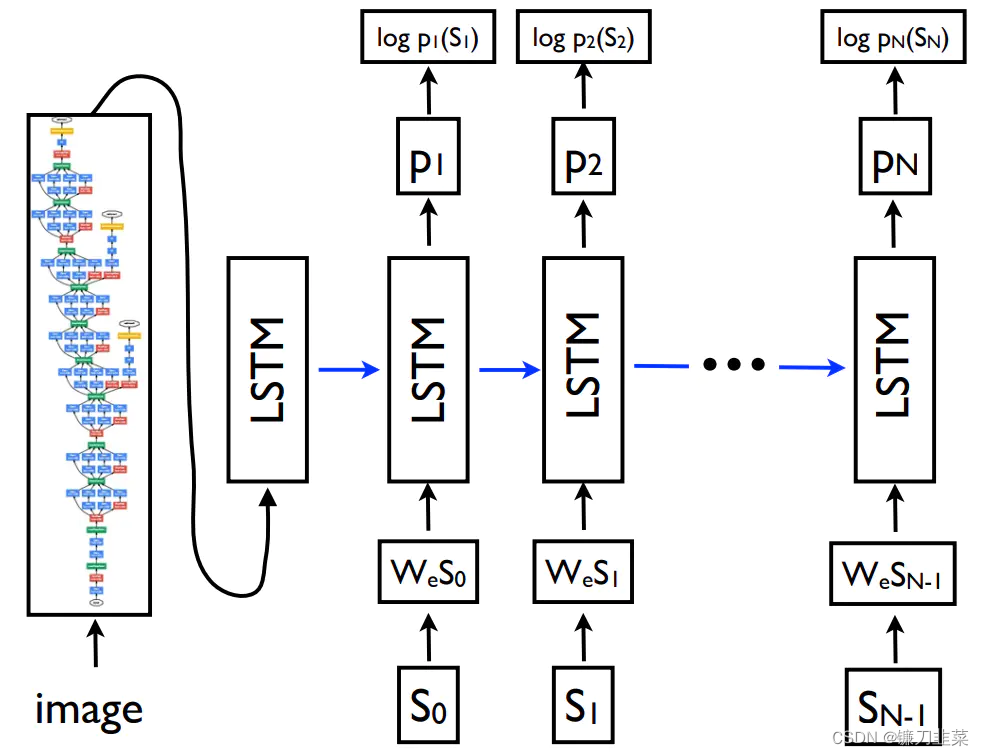
Image是原始图片,左边是GoogleLeNet,实际使用中可以用任意的深度学习网络结构代替(如VGG或ResNet等), S 0 , S 1 , S 2 , … … , S N S_0,S_1,S_2,……,S_N S0,S1,S2,……,SN是人工对图片进行描述的语句,例如“A dog is playing with a ball”,那么 S 0 S 6 S_0~S_6 S0 S6就是这7个单词。就是这几个单词对应的词向量。
论文中训练的方法如下:
- 图片经过神经网络提取到图片高层次的语义信息 f f f
- 将 f f f输入到LSTM中,并希望LSTM的输出是 S 0 S_0 S0
- 将 S 0 S_0 S0输入到LSTM中,并希望LSTM的输出是 S 1 S_1 S1
- 将 S 1 S_1 S1输入到LSTM中,并希望LSTM的输出是 S 2 S_2 S2
- 将 S 2 S_2 S2输入到LSTM中,并希望LSTM的输出是 S 3 S_3 S3
- …
- 以此类推,将 S N − 1 S_{N-1} SN−1输入到LSTM中,并希望LSTM的输出是 S N S_N SN
在论文中,作者使用了预训练好的GoogleLeNet获取图片在全连接分类层之前的输出,作为图像语义。训练的目标就是输出的词尽量和预期的词相符,所以图像描述问题最终也变成了一个分类问题,利用LSTM不断预测下一个最有可能出现的词。
2. 数据
2.1 数据介绍
AI Challenger图像中文描述比赛的数据分为两部分,第一个部分是图片,总共20万张,第二部分是一个caption_train_annotations_20170902.json文件,它以json的格式保存每张图片的描述,每个样本的格式如下,总共有20万条这样的样本。
- url:图片的下载地址(没用,因为已经提供了下载好的图片)。
- image_id:图片的文件名。
- caption:图片对应的五句描述。
url:
[{“url”: “http://img5.cache.netease.com/photo/0005/2013-09-25/99LA1FC60B6P0005.jpg”, “image_id”: “3cd32bef87ed98572bac868418521852ac3f6a70.jpg”, “caption”: [“\u4e00\u4e2a\u53cc\u81c2\u62ac\u8d77\u7684\u8fd0\u52a8\u5458\u8dea\u5728\u7eff\u8335\u8335\u7684\u7403\u573a\u4e0a”, “\u4e00\u4e2a\u62ac\u7740\u53cc\u81c2\u7684\u8fd0\u52a8\u5458\u8dea\u5728\u8db3\u7403\u573a\u4e0a”, “\u4e00\u4e2a\u53cc\u624b\u63e1\u62f3\u7684\u7537\u4eba\u8dea\u5728\u7eff\u8335\u8335\u7684\u8db3\u7403\u573a\u4e0a”, “\u4e00\u4e2a\u62ac\u8d77\u53cc\u624b\u7684\u7537\u4eba\u8dea\u5728\u78a7\u7eff\u7684\u7403\u573a\u4e0a”, “\u4e00\u4e2a\u53cc\u624b\u63e1\u62f3\u7684\u8fd0\u52a8\u5458\u8dea\u5728\u5e73\u5766\u7684\u8fd0\u52a8\u573a\u4e0a”]}, …
图片:
描述:
- “一个双臂抬起的运动员跪在绿茵茵的球场上”,
- “一个抬着双臂的运动员跪在足球场上”,
- “一个双手握拳的男人跪在绿茵茵的足球场上”,
- “一个抬起双手的男人跪在碧绿的球场上”,
- “一个双手握拳的运动员跪在平坦的运动场上”
描述具有的特点:
- 每句话的描述长短不一;
- 描述不涉及太多额外的知识,尽可能的客观;
- 尽可能点明图像的人物以及人物之间的关系。
数据处理主要涉及对图片的预处理和对描述的预处理。对图片的预处理相对比较简单,即将图片送入ResNet,获得指定层的输出并保存即可。对文字的预处理相对比较麻烦,分为以下几步:
- 中文分词
- 将词用序号表示(word2idx),并过滤低频词,即统计每个词出现的次数,然后删除一些频词太低的词。
- 将所有描述补齐到等长(pad_sequence)
- 利用pack_padded_sequence进行计算加速
其中对中文分词。英语采用空格区分单词,汉语则采用分词软件,最有效的是结巴分词,安装采用 pip install jieba。
import jieba
seq_list = jieba.cut("我正在学习深度学习知识",cut_all=False)
print(u"分词结果: "+"/".join(seq_list))
分词结果: 我/正在/学习/深度/学习/知识
注意:结巴分词利用自建的词典进行分词,还可以指定自己自定义的词典。
PyTorch中函数pack_padded_sequence专门对经过pad操作后的序列进行pack,因经过pad后的序列存在很多空白的填充值,使得在计算RNN时可能会影响隐藏元的取值,使其变得复杂,浪费计算资源。PackedSequence能够解决这一问题,它知道输入数据中哪些是pad的值,不会计算pad的数据输出,从而节省计算资源。具体方法:
- 对不同长度的句子,按长度(从长到短)进行排序并记录句子的长短;
- 对不同的句子,统一pad成一样的长度;
- 将上一步得到的variable和样本的长度输入pack_padded_sequence,会输出PackedSequence对象,这个对象可以输入到任何RNN类型的module中(包括RNN、LSTM和GRU),还能送入部分损失函数中(例如交叉熵损失函数)。
- PackedSequence可以通过pad_packed_sequence方法取出variable和length。这个操作可以看成是pack_padded_sequence的逆操作,但是一般不需要取出来,而是直接通过全连接层计算损失。
使用案例:
import torch as t
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
from torch import nn
sen1 = [1, 1, 1]
sen2 = [2,2,2,2]
sen3 = [3,3,3,3,3,3,3,3]
sen4 = [4,4,4,4,4,4]
sentences = [sen1,sen2,sen3,sen4]
sentences
Out[16]: [[1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3, 3, 3, 3, 3], [4, 4, 4, 4, 4, 4]]
sentences = sorted(sentences, key=lambda x: len(x), reverse=True)
sentences
Out[20]: [[3, 3, 3, 3, 3, 3, 3, 3], [4, 4, 4, 4, 4, 4], [2, 2, 2, 2], [1, 1, 1]]
# 长于5个词的截断到5个词
lengths = [5 if len(sen)>5 else len(sen) for sen in sentences]
lengths
Out[23]: [5, 5, 4, 3]
# pad数据, 太长的就截断,太短的就补零
def pad_sen(sen, length=5, padded_num=0):
...: origin_len = len(sen)
...: padded_sen = sen[:length]
...: padded_sen = padded_sen + [padded_num for _ in range(origin_len, length)]
...:
...: return padded_sen
...:
pad_sentences = [pad_sen(sen) for sen in sentences]
pad_sentences
Out[31]: [[3, 3, 3, 3, 3], [4, 4, 4, 4, 4], [2, 2, 2, 2, 0], [1, 1, 1, 0, 0]]
# 4 * 5 batch_size = 3, 词=5
pad_tensor = t.Tensor(pad_sentences).long()
# 5 * 4 batch_size = 4, 词=5
pad_tensor = pad_tensor.t()
pad_variable = t.autograd.Variable(pad_tensor)
pad_variable # 一列是一句话
Out[38]:
tensor([[3, 4, 2, 1],
[3, 4, 2, 1],
[3, 4, 2, 1],
[3, 4, 2, 0],
[3, 4, 0, 0]])
# 总共5个词,每个词用2维向量表示
embedding = nn.Embedding(5, 2)
# 5 * 4 * 2
pad_embeddings = embedding(pad_variable)
pad_embeddings
Out[43]:
tensor([[[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264]],
[[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264]],
[[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264]],
[[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 0.8121, 0.9832]],
[[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.8121, 0.9832],
[ 0.8121, 0.9832]]], grad_fn=<EmbeddingBackward0>)
# pack数据
packed_variable = pack_padded_sequence(pad_embeddings, lengths)
packed_variable # 输出也是PackedSequence
Out[47]:
PackedSequence(data=tensor([[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264],
[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264],
[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264],
[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[-0.5019, 0.4527],
[ 1.4539, -0.8153]], grad_fn=<PackPaddedSequenceBackward0>), batch_sizes=tensor([4, 4, 4, 3, 2]), sorted_indices=None, unsorted_indices=None)
# 输入2维(词向量长度),隐藏元长度为3
rnn = t.nn.LSTM(2, 3)
output, hn = rnn(packed_variable)
output = pad_packed_sequence(output)
output
Out[52]:
(tensor([[[ 0.1196, 0.0815, 0.0840],
[-0.0695, -0.0680, 0.2405],
[ 0.0309, -0.0104, 0.1873],
[-0.2330, 0.0528, 0.0075]],
[[ 0.1888, 0.1278, 0.1229],
[-0.1119, -0.1228, 0.2911],
[ 0.0386, -0.0304, 0.2468],
[-0.3550, 0.1099, 0.0170]],
[[ 0.2290, 0.1541, 0.1402],
[-0.1266, -0.1615, 0.3069],
[ 0.0408, -0.0499, 0.2678],
[-0.4142, 0.1606, 0.0280]],
[[ 0.2531, 0.1691, 0.1479],
[-0.1299, -0.1880, 0.3132],
[ 0.0427, -0.0663, 0.2759],
[ 0.0000, 0.0000, 0.0000]],
[[ 0.2681, 0.1777, 0.1513],
[-0.1292, -0.2064, 0.3162],
[ 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000]]], grad_fn=<CopySlices>),
tensor([5, 5, 4, 3]))
因为这里仅使用原来的验证集,所以用书里提供的代码对caption_validation_annotations_20170910.json进行预处理 ,保存为pickle格式的dict对象,名称为caption_validation.pth。
预处理代码如下:
# -*- coding: utf-8 -*-#
# ----------------------------------------------
# Name: data_preprocess.py
# Description: 对caption_validation_annotations_20170910.json进行预处理,保存成pickle格式的dict对象
# Author: PANG
# Date: 2022/7/3
# ----------------------------------------------
import torch as t
import numpy as np
import json
import jieba
import tqdm
class Config:
annotation_file = 'ai_challenger_caption_validation_20170910/caption_validation_annotations_20170910.json'
unknown = '</UNKNOWN>'
end = '</EOS>'
padding = '</PAD>'
max_words = 10000
min_appear = 2
save_path = 'caption_validation.pth'
# START='</START>'
# MAX_LENS = 25,
def process(**kwargs):
opt = Config()
for k, v in kwargs.items():
setattr(opt, k, v)
with open(opt.annotation_file) as f:
data = json.load(f)
# 8f00f3d0f1008e085ab660e70dffced16a8259f6.jpg -> 0
id2ix = {
item['image_id']: ix for ix, item in enumerate(data)}
# 0-> 8f00f3d0f1008e085ab660e70dffced16a8259f6.jpg
ix2id = {
ix: id for id, ix in (id2ix.items())}
assert id2ix[ix2id[10]] == 10
captions = [item['caption'] for item in data]
# 分词结果
cut_captions = [[list(jieba.cut(ii, cut_all=False)) for ii in item] for item in tqdm.tqdm(captions)]
word_nums = {
} # '快乐'-> 10000 (次)
def update(word_nums):
def fun(word):
word_nums[word] = word_nums.get(word, 0) + 1
return None
return fun
lambda_ = update(word_nums)
_ = {
lambda_(word) for sentences in cut_captions for sentence in sentences for word in sentence}
# [ (10000,u'快乐'),(9999,u'开心') ...]
word_nums_list = sorted([(num, word) for word, num in word_nums.items()], reverse=True)
#### 以上的操作是无损,可逆的操作###############################
# **********以下会删除一些信息******************
# 1. 丢弃词频不够的词
# 2. ~~丢弃长度过长的词~~
words = [word[1] for word in word_nums_list[:opt.max_words] if word[0] >= opt.min_appear]
words = [opt.unknown, opt.padding, opt.end] + words
word2ix = {
word: ix for ix, word in enumerate(words)}
ix2word = {
ix: word for word, ix in word2ix.items()}
assert word2ix[ix2word[123]] == 123
ix_captions = [[[word2ix.get(word, word2ix.get(opt.unknown)) for word in sentence]
for sentence in item]
for item in cut_captions]
readme = u""" word:词 ix:index id:图片名 caption: 分词之后的描述,通过ix2word可以获得原始中文词 """
results = {
'caption': ix_captions,
'word2ix': word2ix,
'ix2word': ix2word,
'ix2id': ix2id,
'id2ix': id2ix,
'padding': '</PAD>',
'end': '</EOS>',
'readme': readme
}
t.save(results, opt.save_path)
print('save file in %s' % opt.save_path)
def test(ix, ix2=4):
results = t.load(opt.save_path)
ix2word = results['ix2word']
examples = results['caption'][ix][4]
sentences_p = (''.join([ix2word[ii] for ii in examples]))
sentences_r = data[ix]['caption'][ix2]
assert sentences_p == sentences_r, 'test failed'
test(1000)
print('test success')
if __name__ == '__main__':
# import fire
#
# fire.Fire()
# python data_preprocess.py process --annotation-file=/data/annotation.json --max-words=5000
process()
caption_validation.pth中的内容如下:
import torch as t
data = t.load('D:\MyProjects\deeplearningDay100\Image_Caption\caption_validation.pth')
list(data.keys())
Out[4]: ['caption', 'word2ix', 'ix2word', 'ix2id', 'id2ix', 'padding', 'end', 'readme']
print(data['readme'])
word:词
ix:index
id:图片名
caption: 分词之后的描述,通过ix2word可以获得原始中文词
字典中各个键值对的含义如下:
- word2idx: 长度为5911的字典,词对应的序号,例如“女人”->10
- id2word:长度为5911的字典,序号对应的词,例如10 -> “女人”
- id2ix:长度为30000的字典,图片文件名对应的序号,例如’a20401efd162bd6320a2203057019afbf996423c.jpg’ -> 9
- ix2id:长度为30000的字典,序号对应的图片文件名,例如9 -> ‘a20401efd162bd6320a2203057019afbf996423c.jpg’
- end: 结束标识符</EOS>
- padding:pad标识符</PAD>
- caption:长度为30000的列表,每一项是个长度为5的列表,保存图片都应为五句描述。描述的数据经过分词,并将词映射到序号。可以通过word2ix查看词和序号的对应关系。

一个使用案例:
import torch as t
data = t.load('D:\MyProjects\deeplearningDay100\Image_Caption\caption_validation.pth')
ix2word = data['ix2word']
ix2id = data['ix2id']
caption = data['caption']
img_ix = 100 # 第100张图片
# 图片对应的描述
img_caption = caption[img_ix]
# 图片文件名
img_id = ix2id[img_ix]
img_caption
Out[15]:
[[60, 3, 46, 15, 4, 833, 230, 3, 7, 37, 11, 34, 9, 207, 41, 3, 10, 5, 177],
[46, 15, 4, 9, 50, 31, 3, 7, 110, 28, 9, 52, 3, 10, 5, 0],
[46, 15, 4, 7, 3, 37, 11, 28, 9, 756, 609, 3, 10, 5, 177],
[4, 7, 3, 29, 11, 28, 19, 223, 8, 229, 3, 10, 13, 5, 46, 15],
[46, 15, 4, 19, 57, 193, 6, 3, 7, 104, 28, 63, 207, 31, 3, 10, 5, 81]]
img_id
Out[16]: '644441869019a08b76a6eacc3d4ac4c21142e036.jpg'
# 通过ix2word获得对应的词
sen = img_caption[0]
sen = [ix2word[_] for _ in sen]
print(''.join(sen))
干净的大厅里一个十指交叉的男人前面有一群穿着黄色衣服的女人在跳舞

2.2 图像数据处理
需要利用神经网络提取图像的特征。具体地,就是利用ResNet提取图片在倒数第二层(池化层的输出,全连接层的输入)的2048维度的向量。有两种解决方案:
- 复制并修改torchvision中的ResNet源码,让它在倒数第二层就输出返回
- 直接把最后一层删除并替换成一个恒等映射。
首先,看一下torchvision中ResNet的forward源码,我们的目标是获得x=self.avgpool(x)的输出。
class ResNet(nn.Module):
def __init__(
self,
block: Type[Union[BasicBlock, Bottleneck]],
layers: List[int],
num_classes: int = 1000,
zero_init_residual: bool = False,
groups: int = 1,
width_per_group: int = 64,
replace_stride_with_dilation: Optional[List[bool]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
_log_api_usage_once(self)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError(
"replace_stride_with_dilation should be None "
f"or a 3-element tuple, got {
replace_stride_with_dilation}"
)
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
def _make_layer(
self,
block: Type[Union[BasicBlock, Bottleneck]],
planes: int,
blocks: int,
stride: int = 1,
dilate: bool = False,
) -> nn.Sequential:
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(
block(
self.inplanes, planes, stride, downsample, self.groups, self.base_width, previous_dilation, norm_layer
)
)
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(
self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
dilation=self.dilation,
norm_layer=norm_layer,
)
)
return nn.Sequential(*layers)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x) # 获取这里的输出
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
第一种做法:修改forward函数
from torchvision.models import resnet50
def new_forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
# x = self.fc(x)
return x
model = resnet50(pretrained=True)
model.forward = lambda x:new_forward(model, x)
model = model.cuda()
第二种做法:删除model的全连接层,将它改成一个恒等映射
resnet50 = tv.models.resnet50(pretrained=True)
del resnet50.fc
resnet50.fc = lambda x: x
resnet50.cuda()
修改完ResNet的结构之后,就可以提取30000张图片的feature。代码如下:
# -*- coding: utf-8 -*-#
# ----------------------------------------------
# Name: feature_extract.py
# Description: 修改ResNet导数第二层,提取图片特征
# Author: PANG
# Date: 2022/7/3
# ----------------------------------------------
import os
import torch
import torchvision as tv
from PIL import Image
from torch.utils import data
from torchvision.models import resnet50
from Image_Caption.config import Config
torch.set_grad_enabled(False)
opt = Config()
IMAGENET_MEAN = [0.485, 0.456, 0.406]
IMAGENET_STD = [0.229, 0.224, 0.225]
normalize = tv.transforms.Normalize(mean=IMAGENET_MEAN, std=IMAGENET_STD)
# 方案1:修改forward函数
def new_forward(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
# x = self.fc(x)
return x
# 方案2: 删除model的全连接层,将它改成一个恒等映射
# model = resnet50(pretrained=False)
# model.load_state_dict(torch.load("resnet50-19c8e357.pth"))
# del model.fc
# model.fc = lambda x:x
# model = model.cuda()
class CaptionDataset(data.Dataset):
def __init__(self, caption_data_path):
self.transforms = tv.transforms.Compose([
tv.transforms.Resize(256),
tv.transforms.CenterCrop(256),
tv.transforms.ToTensor(),
normalize
])
data = torch.load(caption_data_path)
self.ix2id = data['ix2id']
self.imgs = [os.path.join(opt.img_path, self.ix2id[_]) for _ in range(len(self.ix2id))]
def __getitem__(self, index):
img = Image.open(self.imgs[index]).convert('RGB')
img = self.transforms(img)
return img, index
def __len__(self):
return len(self.imgs)
def get_dataloader(opt):
dataset = CaptionDataset(opt.caption_data_path)
dataloader = data.DataLoader(dataset, batch_size=opt.batch_size, shuffle=False, num_workers=opt.num_workers)
return dataloader
def feature_extract():
# 数据, 获取30000张图片
opt.batch_size = 32 # 可以设置大一些
dataloader = get_dataloader(opt)
results = torch.Tensor(len(dataloader.dataset), 2048).fill_(0)
batch_size = opt.batch_size
# 模型
model = resnet50(pretrained=False)
model.load_state_dict(torch.load("resnet50-19c8e357.pth"))
# 用新的forward函数覆盖旧的forward函数
model.forward = lambda x: new_forward(model, x)
model = model.cuda()
# 前向传播,获取feature
for ii, (imgs, indexs) in enumerate(dataloader):
# 确保序号没有对应错
assert indexs[0] == batch_size * ii
imgs = imgs.cuda()
features = model(imgs)
results[ii * batch_size:(ii + 1) * batch_size] = features.data.cpu()
print(ii * batch_size)
# 30000 * 2048 30000张图片,每张图片2048维的feature
torch.save(results, 'results_val_2048.pth')
if __name__ == '__main__':
feature_extract()
注意:dataloader不要shuffle,要按顺序,这样才能和ix2id中的序号和图片文件名一一对应。
2.3 数据加载
首先,将数据封装成dataset。
class CaptionDataset(data.Dataset):
def __init__(self, opt):
""" Attributes: _data (dict): 预处理之后的数据,包括所有图片的文件名,以及处理过后的描述 all_imgs (tensor): 利用resnet50提取的图片特征,形状(30000,2048) caption(list): 长度为3万的list,包括每张图片的文字描述 ix2id(dict): 指定序号的图片对应的文件名 start_(int): 起始序号,训练集的起始序号是0,验证集的起始序号是29000, 即前29000张图片是训练集,剩下的1000张图片是验证集 len_(init): 数据集大小,如果是训练集,长度就是29000,验证集长度为1000 traininig(bool): 是训练集(True),还是验证集(False) """
self.opt = opt
data = torch.load(opt.caption_data_path)
word2ix = data['word2ix']
self.captions = data['caption']
self.padding = word2ix.get(data.get('padding'))
self.end = word2ix.get(data.get('end'))
self._data = data
self.ix2id = data['ix2id']
self.all_imgs = torch.load(opt.img_feature_path)
def __getitem__(self, index):
""" 返回: - img: 图像features 2048的向量 - caption: 描述,形如LongTensor([1,3,5,2]),长度取决于描述长度 - index: 下标,图像的序号,可以通过ix2id[index]获取对应图片文件名 """
img = self.all_imgs[index]
caption = self.captions[index]
# 5句描述随机选一句
rdn_index = np.random.choice(len(caption), 1)[0]
caption = caption[rdn_index]
return img, torch.LongTensor(caption), index
def __len__(self):
return len(self.ix2id)
def train(self, training=True):
""" 在训练集和测试集之间切换,training为True,getitem返回训练集的数据,否则返回验证集的数据 :param training: :return: """
self.training = training
if self.training:
self._start = 0
self.len_ = len(self._data) - 1000
else:
self._start = len(self.ix2id) - 1000
self.len_ = 1000
return self
注意:在__getitem__中,dataset会返回一个样本的数据,在dataloader中,会将每个样本的数据拼接成一个batch,可是由于描述的长短不一,无法拼接成一个batch,这需要自己实现一个collate_fn,将每一个batch长短不一的数据拼接成一个tensor。
def create_collate_fn(padding, eos, max_length=50):
def collate_fn(img_cap):
""" 将多个样本拼接在一起成一个batch 输入: list of data,形如 [(img1, cap1, index1), (img2, cap2, index2) ....] 拼接策略如下: - batch中每个样本的描述长度都是在变化的,不丢弃任何一个词\ - 选取长度最长的句子,将所有句子pad成一样长 - 长度不够的用</PAD>在结尾PAD - 没有START标识符 - 如果长度刚好和词一样,那么就没有</EOS> 返回: - imgs(Tensor): batch_sie*2048 - cap_tensor(Tensor): batch_size*max_length - lengths(list of int): 长度为batch_size - index(list of int): 长度为batch_size """
img_cap.sort(key=lambda p: len(p[1]), reverse=True)
imgs, caps, indexs = zip(*img_cap)
imgs = torch.cat([img.unsqueeze(0) for img in imgs], 0)
lengths = [min(len(c) + 1, max_length) for c in caps]
batch_length = max(lengths)
cap_tensor = torch.LongTensor(batch_length, len(caps)).fill_(padding)
for i, c in enumerate(caps):
end_cap = lengths[i] - 1
if end_cap < batch_length:
cap_tensor[end_cap, i] = eos
cap_tensor[:end_cap, i].copy_(c[:end_cap])
return imgs, (cap_tensor, lengths), indexs
return collate_fn
封装完成之后,就可以在训练时调用了:
def get_dataloader(opt):
dataset = CaptionDataset(opt)
n_train = int(len(dataset) * 0.9)
split_train, split_valid = random_split(dataset=dataset, lengths=[n_train, len(dataset) - n_train])
train_dataloader = data.DataLoader(split_train, batch_size=opt.batch_size, shuffle=opt.shuffle, num_workers=0,
collate_fn=create_collate_fn(dataset.padding, dataset.end))
valid_dataloader = data.DataLoader(split_valid, batch_size=opt.batch_size, shuffle=opt.shuffle, num_workers=0,
collate_fn=create_collate_fn(dataset.padding, dataset.end))
return train_dataloader, valid_dataloader
# dataloader = data.DataLoader(dataset, batch_size=opt.batch_size, shuffle=opt.shuffle, num_workers=0,
# collate_fn=create_collate_fn(dataset.padding, dataset.end))
# return dataloader
if __name__ == '__main__':
from Image_Caption.config import Config
opt = Config()
opt.num_workers = 0 # 添加: 线程数设置为1
dataloader = get_dataloader(opt)
for ii, data in enumerate(dataloader):
print(ii, data)
break
3. 模型与训练
在完成数据处理之后,就可以利用PyTorch训练模型进行训练了。
(1)图片经过ResNet提取成2028维度的向量,然后利用全连接层转成256维向量,可以认为从图像的语义空间转成了词向量的语义空间。
(2)描述经过Embedding层,每个词都变成了256维的向量
(3)将第一步和第二步得到的词向量拼接在一起,送入LSTM中,计算每个词的输出。
(4)利用每个词的输出进行分类,预测下一个词(分类)
class CaptionModel(nn.Module):
def __init__(self, opt, word2ix, ix2word):
super(CaptionModel, self).__init__()
self.ix2word = ix2word
self.word2ix = word2ix
self.opt = opt
self.fc = nn.Linear(2048, opt.rnn_hidden) # 利用全连接层转成256维的向量
self.rnn = nn.LSTM(opt.embedding_dim, opt.rnn_hidden, num_layers=opt.num_layers)
self.classifier = nn.Linear(opt.rnn_hidden, len(word2ix))
self.embedding = nn.Embedding(len(word2ix), opt.embedding_dim)
# if opt.share_embedding_weights:
# # rnn_hidden=embedding_dim的时候才可以
# self.embedding.weight
def forward(self, img_feats, captions, lengths):
embeddings = self.embedding(captions)
# img_feats是2048维的向量,通过全连接层转为256维的向量,和词向量一样
img_feats = self.fc(img_feats).unsqueeze(0)
# 将img_feats看成第一个词的词向量,和其他词向量拼接在一起
embeddings = torch.cat([img_feats, embeddings], 0)
# PackedSequence
packed_embeddings = pack_padded_sequence(embeddings, lengths)
outputs, state = self.rnn(packed_embeddings)
# lstm的输出作为特征用来分类预测下一个词的序号
# 因为输入是PackedSequence, 所以输出的output也是PackedSequence
# PackedSequence的第一个元素是Variable, 即outputs[0]
# 第二个元素是batch_size, 即batch中每个样本的长度
pred = self.classifier(outputs[0])
return pred, state
def generate(self, img, eos_token='</EOS>', beam_size=3, max_caption_length=30, length_normalization_factor=0.0):
""" 根据图片生成描述,主要是使用beam search算法以得到更好的描述 beam search算法是一个动态规划算法,它每次搜索的时候,不是只记下最可能的一个词,而是记住最可能的k个词,然后继续搜索下一个词, 找到k^2个序列,保存概率最大的k,就这样不断搜索直到最后得到最优结果。 """
cap_gen = CaptionGenerator(embedder=self.embedding,
rnn=self.rnn,
classifier=self.classifier,
eos_id=self.word2ix[eos_token],
beam_size=beam_size,
max_caption_length=max_caption_length,
length_normalization_factor=length_normalization_factor)
if next(self.parameters()).is_cuda:
img = img.cuda()
img = img.unsqueeze(0)
img = self.fc(img).unsqueeze(0)
sentences, score = cap_gen.beam_search(img)
sentences = [' '.join([self.ix2word[idx.item()] for idx in sent]) for sent in sentences]
return sentences
这里比较复杂的地方在于PackedSequence的使用,由于LSTM的输入是PackedSequence,所以输出也是PackedSequence,PackedSequence是一个特殊的tuple,即可以通过packedsequence.data获得对应的variable,也可以通过packedsequence[0]获得。如果想要获得对应的tensor,则需要packedsequence.data.data,第一个data得到的是variable,第二个data得到的是tensor。因为总共大约有10000个词,所以最终变成了一个10000分类问题,采用交叉熵损失作为目标函数。
训练部分代码如下:
def train(**kwargs):
opt = Config()
for k, v in kwargs.items():
setattr(opt, k, v)
device = torch.device('cuda') if opt.use_gpu else torch.device('cpu')
opt.caption_data_path = 'caption_validation.pth' # 原始数据
opt.test_img = 'example.jpeg' # 输入图片
# opt.model_ckpt='caption_0914_1947' # 预训练的模型
# 数据
vis = Visualizer(env=opt.env)
# dataloader = get_dataloader(opt)
train_dataloader, valid_dataloader = get_dataloader(opt)
# 数据预处理
_data = torch.load(opt.caption_data_path, map_location=lambda s, l: s)
word2ix, ix2word = _data['word2ix'], _data['ix2word']
# _data = dataloader.dataset._data
# word2ix, ix2word = _data['word2ix'], _data['ix2word']
max_loss = 263
# 模型
model = CaptionModel(opt, word2ix, ix2word)
if opt.model_ckpt:
model.load(opt.model_ckpt)
optimizer = model.get_optimizer(opt.lr)
criterion = torch.nn.CrossEntropyLoss()
model.to(device)
# 统计
loss_meter = meter.AverageValueMeter()
valid_losses = meter.AverageValueMeter()
for epoch in range(opt.max_epoch):
loss_meter.reset()
valid_losses.reset()
for ii, (imgs, (captions, lengths), indexes) in tqdm.tqdm(enumerate(train_dataloader)):
# 训练
optimizer.zero_grad()
imgs = imgs.to(device)
captions = captions.to(device)
input_captions = captions[:-1]
target_captions = pack_padded_sequence(captions, lengths)[0]
score, _ = model(imgs, input_captions, lengths)
loss = criterion(score, target_captions)
loss.backward()
optimizer.step()
loss_meter.add(loss.item())
# 可视化
if (ii + 1) % opt.plot_every == 0:
if os.path.exists(opt.debug_file):
ipdb.set_trace()
vis.plot('loss', loss_meter.value()[0])
# 可视化原始图片 + 可视化人工的描述语句
raw_img = _data['ix2id'][indexes[0]]
img_path = opt.img_path + raw_img
raw_img = Image.open(img_path).convert('RGB')
raw_img = tv.transforms.ToTensor()(raw_img)
raw_caption = captions.data[:, 0]
raw_caption = ''.join([_data['ix2word'][ii.item()] for ii in raw_caption])
vis.text(raw_caption, u'raw_caption')
vis.img('raw', raw_img, caption=raw_caption)
# 可视化网络生成的描述语句
results = model.generate(imgs.data[0])
vis.text('</br>'.join(results), u'caption')
model.eval()
total_loss = 0
with torch.no_grad():
for ii, (imgs, (captions, lengths), indexes) in enumerate(valid_dataloader):
imgs = imgs.to(device)
captions = captions.to(device)
input_captions = captions[:-1]
target_captions = pack_padded_sequence(captions, lengths)[0]
score, _ = model(imgs, input_captions, lengths)
loss = criterion(score, target_captions)
total_loss += loss.item()
model.train()
valid_losses.add(total_loss)
if total_loss < max_loss:
max_loss = total_loss
torch.save(model.state_dict(), 'checkpoints/model_best.pth')
print(max_loss)
plt.figure(1)
plt.plot(loss_meter)
plt.figure(2)
plt.plot(valid_losses)
plt.show()
3. 实验结果
实验效果不是很好,如下所示:
总体来看,模型能够提取出图片的基本元素和对象之间的关系,但是生成的描述质量距离人类的水平还有不小的距离。
参考资料
[1] 《深度学习框架PyTorch:入门到实践》
[2] Yang SiCheng: 【PyTorch】13 Image Caption:让神经网络看图讲故事
[3] 今天敲代码了么: pytorch入门与实践学习笔记:chapter10 神经网络看图讲故事
边栏推荐
- NGUI-UILabel
- 《通信软件开发与应用》课程结业报告
- 112. Network security penetration test - [privilege promotion article 10] - [Windows 2003 lpk.ddl hijacking rights lifting & MSF local rights lifting]
- College entrance examination composition, high-frequency mention of science and Technology
- Completion report of communication software development and Application
- 跨域问题解决方案
- What are the technical differences in source code anti disclosure
- 2022年在启牛开华泰的账户安全吗?
- SQL blind injection (WEB penetration)
- 关于 Web Content-Security-Policy Directive 通过 meta 元素指定的一些测试用例
猜你喜欢

<No. 9> 1805. 字符串中不同整数的数目 (简单)
Processing strategy of message queue message loss and repeated message sending
<No. 9> 1805. Number of different integers in the string (simple)
金融数据获取(三)当爬虫遇上要鼠标滚轮滚动才会刷新数据的网页(保姆级教程)
Idea 2021 Chinese garbled code

Sonar:cognitive complexity

Completion report of communication software development and Application
EPP+DIS学习之路(1)——Hello world!
Unity 贴图自动匹配材质工具 贴图自动添加到材质球工具 材质球匹配贴图工具 Substance Painter制作的贴图自动匹配材质球工具
Solve server returns invalid timezone Go to ‘Advanced’ tab and set ‘serverTimezone’ property manually
随机推荐
让数字管理好库存
@What happens if bean and @component are used on the same class?
Several methods of checking JS to judge empty objects
【玩转 RT-Thread】 RT-Thread Studio —— 按键控制电机正反转、蜂鸣器
How to connect 5V serial port to 3.3V MCU serial port?
108. Network security penetration test - [privilege escalation 6] - [windows kernel overflow privilege escalation]
开发一个小程序商城需要多少钱?
Cenos openssh upgrade to version 8.4
About web content security policy directive some test cases specified through meta elements
Epp+dis learning road (2) -- blink! twinkle!
Xiaohongshu microservice framework and governance and other cloud native business architecture evolution cases
RHSA first day operation
Fleet tutorial 14 basic introduction to listtile (tutorial includes source code)
Problem: the string and characters are typed successively, and the results conflict
静态Vxlan 配置
Review and arrangement of HCIA
《看完就懂系列》天哪!搞懂节流与防抖竟简单如斯~
Minimalist movie website
Superscalar processor design yaoyongbin Chapter 10 instruction submission excerpt
Tutorial on the principle and application of database system (011) -- relational database