当前位置:网站首页>Superscalar processor design yaoyongbin Chapter 10 instruction submission excerpt
Superscalar processor design yaoyongbin Chapter 10 instruction submission excerpt
2022-07-07 11:53:00 【Qi Qi】
10.1 summary
In superscalar processors , When instructions are executed inside the processor , It will not be executed in this strict serial way . But the processor wants to execute the program correctly , You must follow the serial sequence in the program , Generally, the last stage is added to the superscalar pipeline , It's called submission commit.
When an instruction reaches the commit stage , This instruction will be marked as completed in the reorder cache , It should be noted that , This state only indicates that the instruction has been calculated , It does not mean that it can leave the assembly line .
Only when the oldest instruction in the reorder cache changes to the completed state , This instruction is allowed to leave the pipeline , And use its results to update the status of the processor , This instruction is called retirement retire 了 . From this process, we can see that , An instruction may need to wait for a period of time before the pipeline is submitted , Can retire from the assembly line , The reordering cache is the key component to complete this function , Therefore, it is also the most important part of the pipeline submission stage .
Due to branch prediction failure and exceptions , An instruction that reaches the submission stage does not necessarily mean that it must be correct .
Only all instructions that entered the assembly line before this instruction retired , And this instruction is already in the completed state , It can retire and leave the assembly line .
Before an order retires , Its state is speculative , Only when this instruction really retires and leaves the assembly line , Only then can its result be updated to the state of the processor China , In this way, even if there is branch prediction failure or exception , Nor will the error state be exposed to programmers .
The distribution stage of the pipeline is the dividing point of the processor from sequential execution to out of order execution , that , The commit phase of the pipeline pulls the processor back from the out of order state to the sequential execution state . No matter what happens inside the superscalar processor , From the outside of the processor , It is always executed in the order specified in the program , Errors caused by any prediction technology , It will be solved inside the processor , Will not show these wrong States .
Maintain the seriality of program execution , It is also required by precise exceptions , The definition of an exact exception is when an instruction finds an exception , All the previous instructions of this instruction have been completed , This instruction and all subsequent instructions should not change the state of the processor .
For one N-way For superscalar processors , The submission phase of the pipeline requires at least N Order retirement , Only in this way can we ensure that the assembly line will not be blocked .
10.2 Reorder cache
10.2.1 The general structure
ROB The essence is a FIFO, It stores information about an instruction , For example, the type of this instruction , result , Type of destination register and exception .
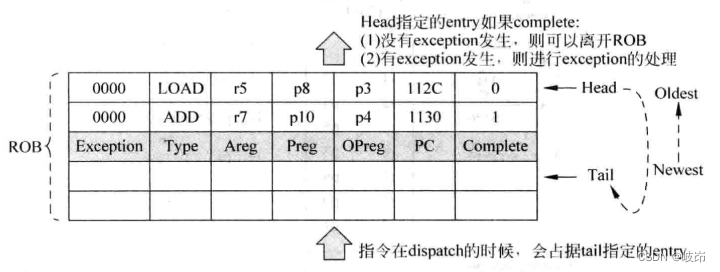
ROB The capacity of determines the maximum number of instructions executed simultaneously by the pipeline , The contents of the table items include
(a)Complete: Indicates whether an instruction has been executed ;
(b)Areg: The destination register specified by the instruction in the original program , It is given in the form of logical registers ;
(c)Preg: The directive Areg After renaming the register , Corresponding physical register number ;
(d)OPreg: The directive Areg Renamed new Preg Before , The corresponding old Preg, When the instruction is abnormal and the state is restored , This value will be used ;
(e)PC: The command corresponds to PC value , When an instruction is interrupted or abnormal , Need to save this instruction PC value , So that the program can be re executed ;
(f)Exception: If an exception occurs in the instruction , The type of this exception will be written here , When the order is to retire , This exception will be handled ;
(g)Type: The type of instruction will be recorded here , When the order is to retire , Different types of instructions will have different actions , for example store Instructions should be written D-Cache, The branch instruction should be released Checkpoint.
Once instructions occupy the pipeline distribution stage ROB An item in a table , The number of this table item will always flow in the pipeline with this instruction , Such instructions at any time after , You can know how to ROB Find yourself .
Once an instruction becomes ROB The oldest instruction in , Use head pointer To indicate the oldest instruction , And its complete The status bit is also 1, It means that this instruction has met the conditions for retirement .
generally speaking , In the distribution stage of the assembly line , Each cycle can enter at most ROB The number of instructions will be equal to ROB The maximum number of instructions that can be retired per cycle , This can ensure the smooth flow of the assembly line .
10.2.2 Port requirements
The processor is executing , from ROB Some of the oldest instructions in ( from head pointer Appoint ), Choose those that have gone stale complete state , Make it retire from the assembly line .
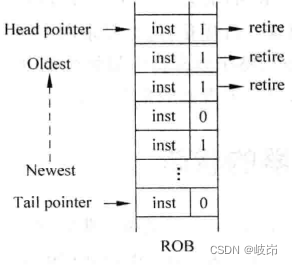
Need to be right ROB The oldest instruction in starts four consecutive ones complete Signal to judge , If a complete The signal is 0, Then all instructions behind it are not allowed to retire in this cycle .
For one 4-way For superscalar processors ,ROB At least support 4 Read ports , But this is far from ROB The number of ports you really need , Other stages of the assembly line are also right ROB There are port requirements , It is related to the architecture of the processor , If the processor uses ROB How to rename registers , Right now ROB The port requirements of are the most , These ports include :
(a) In the register renaming stage of the pipeline , Need from ROB Read from 4 Source operand of an instruction , Therefore need ROB At least support 8 Read ports .
(b) In the distribution stage of the assembly line , You need to ROB Write four instructions , Therefore need ROB Support 4 Two write ports .
(c) In the writeback stage of the pipeline , You need to ROB Write least 4 Orders , The reason why we use the least word , Because many processors issue width Be greater than machine width, The processor will put more FU To improve the parallelism of operations , This causes the result of each cycle of operation to be marked 4 individual .
ROB Need to support 12 Read ports and minimum 8 Two write ports , This multi port FIFO It is difficult to optimize in terms of area and delay , This is also the adoption of ROB One of the biggest problems faced by the architecture of register renaming ;ROB Will become the busiest part of the processor .
10.3 Manage processor status
There are two states inside the superscalar processor , One is the state defined by the instruction set , For example, the value of a general-purpose register ,PC Value and memory value , Call this state Architecture state; Another state is the internal state of superscalar processor , For example, rename the physical register used 、 Reorder cache 、 Launch queue and store buffer And other components , These states are generated by the processor during operation , Due to disordered execution , It is always ahead of the state defined by the instruction set . The state inside the processor is called speculative state. An instruction will update the state of the specified set definition in the processor only when it retires , It's like the processor makes the program execute in serial order .
Only one instruction meets the retirement conditions , Turn into ROB The oldest instruction in , Already in complete state , And no abnormality occurred , Only in this way can the internal state of the processor corresponding to this instruction be updated to the state defined by the instruction set .
Registers other than logic registers belong to the internal state of the processor , Should not be seen from outside the processor . In addition to the resources defined by the instruction set , for example PC register 、 Memory or general registers and other components , Other resources belong to the internal state of the processor .
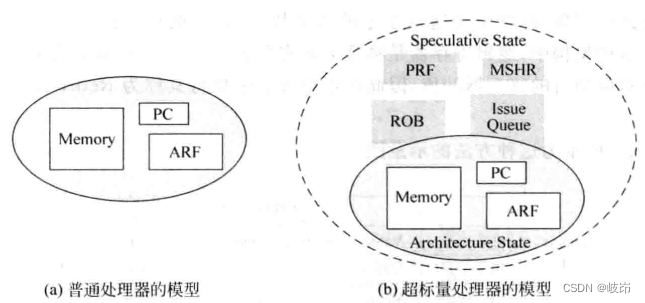
For most of the instructions defined in the instruction set , Will change the state of the processor , For example, ordinary operation instructions change the value of general registers , Instructions that access memory change the values of memory and general registers , Branch instruction changes PC Register value .
For example, for the architecture of extending general registers to register renaming , You need to move the value of the destination register from the physical register to the general-purpose register ; For an architecture that uses a unified physical register for renaming, the destination register needs to be marked as an externally visible state in the physical register heap ;store The instruction requires Store buffer The corresponding value in is written to D-Cache in ; Branch instruction prediction failed for state recovery , And discard the wrong instructions in the pipeline , Start fetching instructions from the correct address again , Put what it takes checkpoint Release resources ; Abnormal instructions will cause the processor to discard all instructions in the pipeline , Jump to the entry of the corresponding exception handler .
In superscalar processors , Depending on the architecture , Different methods will be used to manage the state defined by the instruction set , There are two main methods :
(a) Use ROB Manage the state of the instruction set definition ;
(b) Use physical registers to manage the state defined by the instruction set
10.3.1 Use ROB Manage the state of the instruction set definition
To adopt ROB Architecture for renaming registers , An order before retirement , Will use ROB To save the result of the instruction , When it comes to retirement , The result of this instruction can update the state of the instruction set definition , At this time, the result of this instruction will be changed from ROB To the logical register defined by the instruction set . In this architecture , Logical registers are physically real , Because the value of the destination register corresponding to all retired instructions is stored in the logic register , Therefore, this method is also called Retire Register File, abbreviation RRF.
ROB It includes two main parts , That is, instruction information and instruction result . The type of instruction is recorded in the instruction information 、 The status of the instruction execution and the destination register of the instruction , The result of the instruction is recorded in the instruction result .
This design essentially utilizes ROB As a physical register , You can directly 4 An instruction is in ROB As their physical registers after register renaming , Therefore use ROB To manage the state of the instruction set definition , It can simplify the process of register renaming .
In general , Use ROB To manage the state of the instruction set definition , Will be launched corresponding to the structure using data capture , Because in this method , When an order retires , The result of this instruction needs to be changed from ROB Move to general register , If future instructions want to use the result of this instruction , You need to read from the general register . such , A register will exist in two places during its life cycle , If you use the method of data capture , When the result of an instruction is calculated in the execution stage of the pipeline , This result will be sent to the bypass network , such payload RAM You can capture this result , in other words , In the launch queue , All instructions that use this result as an operand will get this value , When these instructions are selected by the arbitration circuit , Directly from payload RAM You can get the number of all source registers , You don't need to worry about this register at this time ROB Is it in the general register . therefore ,payload RAM It is a necessary part of adopting data capture structure , When the instruction is renamed , Will access the rename mapping table , If you find that the value of the source register has been calculated , Then it can be directly from ROB Or read the value in the general register , Then write payload RAM in , Wait for this value to be captured from the bypass network . If the value of this register has not been calculated , Just put this register in ROB The address in is written payload RAM in , Wait for this value to be captured from the bypass network .
Use ROB Rename the register , And manage the state of the instruction set definition , It exactly matches the launch mode of data capture .
10.3.2 Use physical registers to manage the state defined by the instruction set
This method uses a unified physical register stack , All logic registers defined in the instruction set are mixed in this register heap . Of course , Register renaming in the future , It contains more registers , When an instruction is renamed by a register , Its destination register corresponds to a physical register , The advantage is :
(a) When the instruction is from ROB In retirement , There is no need to move the result of the instruction , It will still exist in the physical register , in other words , Once the source operand of the instruction is determined to exist there , It won't change in the future , This is convenient for the processor to realize low-power design .
(b) Based on ROB In the way of state management , Need from ROB Open up space in to store the results of instructions , But in the program , A considerable number of the instructions have no destination register , for example store Instructions , Compare instructions with branch instructions , therefore ROB There will be some space wasted . Using physical registers for state management avoids such problems . This method only allocates space for the instructions of the destination register , Instructions of other nonexistent destination registers , It does not correspond to any physical register . So use this method , The number of physical registers occupied is less than that at this time ROB Number of instructions in .
(c)ROB It's a way of centralized management , All instructions need to read operands from , At the same time, all instructions also need to write the results , Plus ROB Both the occupation and recycling of space need the support of the read-write port , Therefore, this requires a large number of read and write ports , Will make ROB Become very bloated , Seriously drag down the speed of the processor .
The disadvantage is that : The process of renaming registers is complicated , In the use of ROB When it comes to state management , Just write an instruction to ROB You can complete the renaming process , When this instruction leaves the pipeline smoothly , This mapping relationship is naturally released , In the way of using physical registers for state management , An extra table is needed to store those physical registers that are free , And the relationship establishment and release process of rename mapping are relatively complex .
10.4 Handling of special cases
Because modern superscalar processors use many prediction methods to execute instructions , Not all instructions in the assembly line can retire , For example, branch prediction failure and exception . There are also instructions that need to be paid attention to in the submission phase of the pipeline store Instructions , Because it can really change the state of the processor only when it retires .
10.4.1 Processing of branch prediction failure
After finding branch prediction failure , The state recovery process of the processor can be divided into two independent tasks , The state recovery of the front end and the state recovery of the back end , They are delimited by the register renaming stage of the pipeline . The state recovery of the front end is relatively simple , Just erase all the instructions before renaming the stage in the pipeline , Speculate the branch prediction and restore the historical state table , And use the correct address to get instructions ; Back end recovery is a little more complicated , All internal components of the processor need to be , for example issue queue、store buffer, and ROB Wait for the wrong instructions to be erased , You also need to rename the mapping table RAT Resume , In order to put those wrong instructions on RAT Modify , The physical registers and... Occupied by the wrong instruction at the same time ROB Space also needs to be released .
When branch prediction fails , Most of the recovery tasks are related to register renaming , Because most of the instructions on the wrong path have gone through this step . The repair of rename method is as follows :
(1) Based on ROB State repair in the renamed schema
Based on ROB In the architecture of register renaming , There is a real register heap , It corresponds to all registers defined in the instruction set one by one , It becomes ARF.
A retired instruction changes the value of the destination register from ROB Move to ARF in , It does not necessarily mean that future instructions need to start from ARF Read the value of this register in .
stay ROB Each instruction in will check whether it is the latest mapping relationship , Only when an instruction comes from ROB In retirement , Find yourself the latest mapping relationship , Only in this way can RAT The corresponding content in is changed to ARF state .
from ROB How can I check whether I have the latest mapping relationship with an instruction in retirement ? When this order retires , Use its destination register to read RAT, Read out the corresponding... Of this logic register at this time ROB pointer.
When branch prediction failure is found in the pipeline , At this time, some instructions in the pipeline enter the pipeline before the branch instruction , They can continue to be executed , Therefore, when branch instruction prediction fails , Do not repair the state immediately , Instead, stop fetching new instructions , Let the assembly line continue , This process is called draining the assembly line drain out.
This is based on ROB Register rename method , Not only is the rename process itself easy to implement , When the branch prediction fails, the state recovery is also relatively simple , The hardware is also relatively small .
(2) Based on unity PRF State repair in the renamed schema
In this architecture , There are two rename mapping tables in the pipeline , One is used in the register rename phase of the pipeline , Its state is speculative , Called the preceding paragraph RAT; The other is used in the pipeline submission stage , All instructions to retire from the assembly line , If it has a destination register , Will update this form , So it is always right , Call it the back end RAT.
The instruction that enters the pipeline before the branch instruction ( Including the branch instruction itself ) When they leave the assembly line smoothly , At this time, all instructions in the pipeline are on the wrong path , All instructions in the pipeline can be erased , Then put the back end RAT Copy all to the register used in the rename phase RAT, That's done RAT back , At this point, you can take the address from the correct address to execute .
You will also encounter when the branch instruction exists before D-Cache miss Instructions , The penalty for branch prediction failure due to long waiting time of branch instruction is too large .
If branch prediction fails in the pipeline , The state can be restored immediately , Instead of waiting for branch instructions to retire from the pipeline , This will speed up , Thus reducing punishment .
Use checkpoint Method can quickly restore the state , This method will change the state of the processor before each branch instruction , Save the state of the processor , For example, after the branch instruction, before the subsequent instruction changes the rename mapping table , Save the contents of this form , In this way, when finding branch instructions that fail to predict branches in the future , You can use the number of this branch instruction to erase the instructions on the wrong path in the pipeline , Use at the same time checkpoint The resource restores the state of the processor , Then you can take instructions from the correct path and execute .
The number of branch instructions is likely to increase , however checkpoint It is difficult to increase the number . The solution is to do checkpoint Also make predictions , Because the prediction accuracy of many branch instructions is very high , Assign to it checkpoint resources , Most of the time is wasted .
When a branch instruction is not allocated checkpoint resources , But it is finally found that the branch prediction fails , How to restore the state of the processor , Of course, you can wait for this branch instruction to retire . utilize ROB The renamed mapping table is restored , Compared with the use of checkpoint Method , This method must be much slower , But it consumes less hardware , It can be used as a supplementary method .
10.4.2 Exception handling
A method is needed to record the exceptions of all instructions , Then handle all exceptions in the original order in the program according to the instructions , Capable of this task , Reorder cache .
In order to handle exceptions in the correct order , The exception of an instruction needs to be handled , It must be ensured that all data exceptions before it have been handled , The easiest time to accomplish this task is when an instruction is about to retire , At this time, all the instructions before this instruction have successfully left the pipeline .
After handling the precise exception , Can accurately return , There may be two situations where you return , You can return to the instruction itself where the exception occurred , Re execute this instruction , You can also not re execute the instruction with exception , Instead, it returns to its next instruction to start execution .
Before jumping to the corresponding exception handler , You need to erase all the instructions after this exception generating instruction in the pipeline , And restore their modifications to the processor state , It's like these instructions never happen .
When an instruction comes from ROB Before retirement , If it is found that it has recorded abnormal launches before , here ROB In fact, all of them are not allowed to retire and change the state of the processor .
Recovery at Retire The exception handling method of has another advantage , That is, many exceptions of instructions do not really need to be handled , If these instructions are on the path where branch prediction failed , They will be erased from the assembly line , Therefore, their exceptions are actually invalid .
Another repair process is based on reordering the cache , from ROB The latest instruction written in starts , Write the old mapping relationship of each instruction to the rename mapping table one by one , In this way, the status of this table can be restored , This method is mentioned above WALK.
Using unified PRF Register renaming , and RAT There are two related tables , A table is used to store those physical registers that are idle , be called Free Register Pool; Another table is used to store whether the value of each physical register has been calculated , be called Busy Table. When an exception occurs , These two parts also need to be restored .
For the processor when the exception occurs , If the ROB Rename the schema , Use Recovery at Retire The way is appropriate , And for adopting unified PRF Schema to rename , You need to use WALK Method .
Compared with branch prediction failure , The frequency of exceptions will be lower .
10.4.3 Interrupt handling
stay MIPS In the processor , Exceptions are generated by instructions executed inside the processor , Therefore, exceptions are always synchronized with an instruction ; Interrupts are generated outside the processor , It has no necessary correspondence with the instructions executed inside the processor , Therefore, interrupts are asynchronous . There are two ways to deal with it :
(1) Deal with it now . When the launch is interrupted , Erase all instructions in the pipeline at this time , Restore the state of the processor , And put the oldest instruction in the pipeline PC It's worth saving , Then jump to the corresponding interrupt handler , When returning from it , Will use the saved when the interrupt occurs PC Value to reread the instruction . The advantage is the fastest response , Low efficiency .
(2) Delays in processing . When the interrupt occurs , The pipeline stops fetching instructions , But wait until all instructions in the pipeline retire before processing this interrupt . Questions to consider :
(a) If these instructions in the pipeline happen D-Cache defect , Then it will take a long time to solve , Cause too long interrupt response time .
(b) If a branch prediction failure instruction is found in the pipeline , First of all, we need to deal with this situation , Restore the processor state , This also takes some time , It also increases the interrupt response time .
(c) If an exception is found in the pipeline , Then deal with the exception first , Or deal with the interrupt first ? Generally speaking , The interrupt should be handled first , Because many types of exception handling take a long time .
10.4.4 store Processing of instructions
store Even if the instruction is calculated , The results will also be temporarily stored store buffer, until store When ordering retirement , Will be store buffer The corresponding content in is written Cache in .
once store Instructions are written D-Cache launch miss, It takes a long time to make it leave ROB, And that's what happened ROB The block , Even if store Many instructions have been executed , be in complete state , But because of store Orders stand in front and cannot retire , Cause processor performance degradation .
The simplest way to solve the above problem is to store buffer Add a status bit in , Used to mark a store Whether the instruction has met the conditions for retirement , Such a piece store Instructions are in the cache 3 Status , That is, it has not been completed , It has been executed and left the assembly line smoothly .
When one store Instructions are distributed in the pipeline , Occupy in the order specified in the program store buffer Space , And marked incomplete .
When store Instructions become pipelined and have got addresses and data , But it has not yet become the oldest instruction in the pipeline , It's in complete state .
When store When instructions become the oldest instructions in the assembly line and retire , That is to leave the assembly line smoothly .
store Instructions are executed in the order specified in the program , Of course, it is more necessary to update the status of the processor in this order , therefore store buffer Is in accordance with the FIFO How to manage .
once store buffer There is no more free space to write , At this time, you cannot receive new store Instructions , The pipeline before the distribution phase needs to be suspended . cause store The actual available capacity decreases . Limit the improvement of processor performance .
If you don't want to cause store buffer Reduction in actual usable capacity , Those who have retired store Instructions are stored in a different from store buffer The place of , This place can be called write back buffer, The hardware will automatically wirte back buffer Of store The instructions of write D-Cache in .
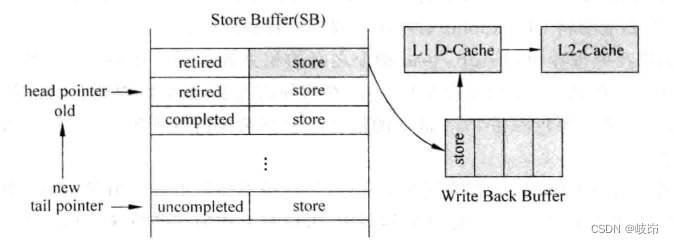
Every one of them store Once retired , Just take it from store buffer writes write back buffer in , in other words , At this time, this store Instructions can leave ROB and store buffer Two parts . In this method ,write back buffer Has become part of the processor state .laod Instruction required store buffer and write back buffer Find in two caches , This increases the design complexity .
At the same time of entering, you need to find out whether there is the same store Instructions , If there is , Then you need to make it invalid , Only in this way can we ensure the following load Command lookup write back buffer, Use the latest results .
10.4.5 The limitation of instructions leaving the pipeline
If ROB The oldest 4 All instructions are already in complete state , There are no branch instructions that fail to predict , No instructions generate exceptions , So this 4 An instruction can leave the pipeline in one cycle ?
In theory , this 4 Instructions can indeed retire and leave the assembly line in one cycle , however , This requires more write ports for many other components of the processor :
(1) Each cycle has 4 strip store Instructions , signify D-Cache the latter write back huffer Need to support 4 Two write ports .
(2) Every cycle 4 Branch instruction retirement path , It means that each cycle needs to 4 The information of branch instructions is written back to the branch predictor chapter , This requires all components in the branch predictor to support 4 Two write ports , At the same time, we also need to be able to checkpoint Resources are released every cycle 4 individual .
Increasing the complexity of hardware design for these infrequent situations is not worth the loss , So in superscalar processors , These special instructions can be limited . for example , At most one branch instruction can be retired in each cycle .
In the submission stage of the pipeline, you need to deal with the exception of the instruction , Because you need to jump to the corresponding exception handler , Therefore, only one instruction exception can be processed per cycle , So find the first exception that produces an exception , And mask all the instructions after this instruction , They are not allowed to retire in this cycle .
边栏推荐
- Stm32f1 and stm32subeide programming example -max7219 drives 8-bit 7-segment nixie tube (based on SPI)
- 【系统设计】指标监控和告警系统
- Mastering the new functions of swiftui 4 weatherkit and swift charts
- Swiftui swift internal skill: five skills of using opaque type in swift
- Use references
- 通过环境变量将 Pod 信息呈现给容器
- 【紋理特征提取】基於matlab局部二值模式LBP圖像紋理特征提取【含Matlab源碼 1931期】
- 博客搬家到知乎
- Excel公式知多少?
- 人大金仓受邀参加《航天七〇六“我与航天电脑有约”全国合作伙伴大会》
猜你喜欢
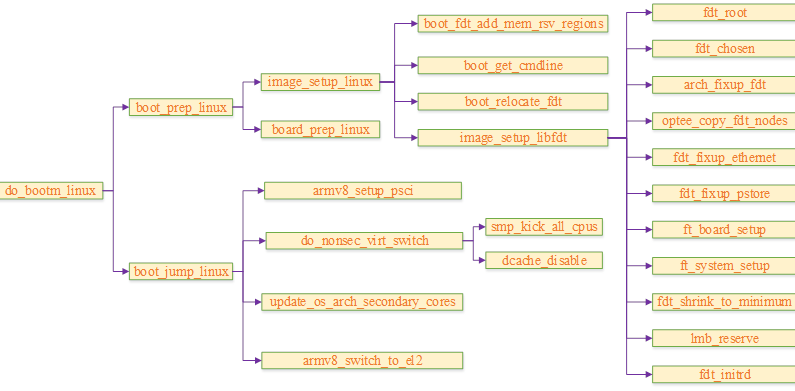
Talk about SOC startup (VII) uboot startup process III

Unsupervised learning of visual features by contracting cluster assignments

聊聊SOC启动(十一) 内核初始化
.NET MAUI 性能提升
Talk about SOC startup (IX) adding a new board to uboot
总结了200道经典的机器学习面试题(附参考答案)
Visual Studio 2019 (LocalDB)\MSSQLLocalDB SQL Server 2014 数据库版本为852无法打开,此服务器支持782版及更低版本
![[filter tracking] comparison between EKF and UKF based on MATLAB extended Kalman filter [including Matlab source code 1933]](/img/90/ef2400754cbf3771535196f6822992.jpg)
[filter tracking] comparison between EKF and UKF based on MATLAB extended Kalman filter [including Matlab source code 1933]
Explore cloud database of cloud services together
【神经网络】卷积神经网络CNN【含Matlab源码 1932期】
随机推荐
本地navicat连接liunx下的oracle报权限不足
There are ways to improve self-discipline and self-control
Talk about SOC startup (11) kernel initialization
R语言使用quantile函数计算评分值的分位数(20%、40%、60%、80%)、使用逻辑操作符将对应的分位区间(quantile)编码为分类值生成新的字段、strsplit函数将学生的名和姓拆分
Talk about SOC startup (VII) uboot startup process III
About how to install mysql8.0 on the cloud server (Tencent cloud here) and enable local remote connection
[Yugong series] go teaching course 005 variables in July 2022
请查收.NET MAUI 的最新学习资源
Flet教程之 16 Tabs 选项卡控件 基础入门(教程含源码)
HCIA复习整理
Visual Studio 2019 (LocalDB)\MSSQLLocalDB SQL Server 2014 数据库版本为852无法打开,此服务器支持782版及更低版本
Electron adding SQLite database
5V串口接3.3V单片机串口怎么搞?
Onedns helps college industry network security
Apprentissage comparatif non supervisé des caractéristiques visuelles par les assignations de groupes de contrôle
Briefly introduce closures and some application scenarios
Mise en œuvre du codage Huffman et du décodage avec interface graphique par MATLAB
Neural approvals to conversational AI (1)
STM32F1与STM32CubeIDE编程实例-315M超再生无线遥控模块驱动
Rationaldmis2022 advanced programming macro program