当前位置:网站首页>【PyTorch实战】用RNN写诗
【PyTorch实战】用RNN写诗
2022-07-07 10:28:00 【镰刀韭菜】
1. 背景
自然语言处理(Natural Language Processing, NLP)是人工智能和语言学领域的分支学科,涉及研究方向宽泛,包括机器翻译、句法分析、信息检索等。 这里回顾两个基本概念:词向量(word vector)和循环神经网络(Recurrent Neural Network,RNN)。
1.1 词向量
自然语言处理主要研究语言信息,语言是由词和字组成,可以把语言转换成词或者字表示的集合。为了方便,常采用One-Hot编码格式,这种方法解决了分类器难以处理属性(Categorical)数据的问题,缺点是冗余太多,无法体现词与词之间的关系。而且在深度学习上,常常出现维度灾难,所以在深度学习中采用词向量的表示形式。
词向量(Word Vector),也被称为词嵌入(Word Embedding)。从概念上看,它是指把一个维数为所有词的数量的高维空间(几万个字,几十万个字)嵌入到一个维数低得多的连续向量空间(通常是128或者256维),每个单词或词组被映射为实数域上的向量。
词向量由专门的训练方法,例如GloVe。这里,词向量最重要的特征是相似词的词向量距离相近。每个词的词向量维度都是固定的,每一维都是连续的数。
在PyTorch中,针对词向量有一个专门的层nn.Embedding,用来实现词与词向量的映射。nn.Embedding具有一个权重,形状是(num_words, embedding_dim)。
Embedding的输入形状是N×W,N是batch size, W是序列的长度, 输出的形状是N×W×embedding_dim。输入必须是LongTensor, FloatTensor通过tensor.long()方法转换成LongTensor。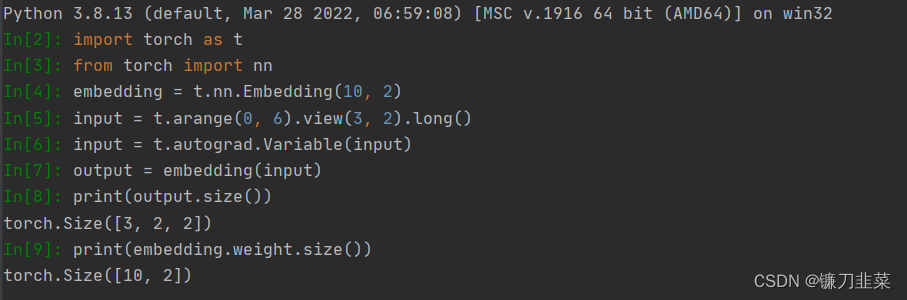
注意:Embedding的权重也是可以训练的,既可以采用随机初始化,也可以采用预训练好的词向量初始化。
1.2 RNN
RNN, 可以解决词与词之间的依赖问题,通过每次利用之前词的状态(hidden state)和当前词相结合计算新的状态。网络结构如下图所示: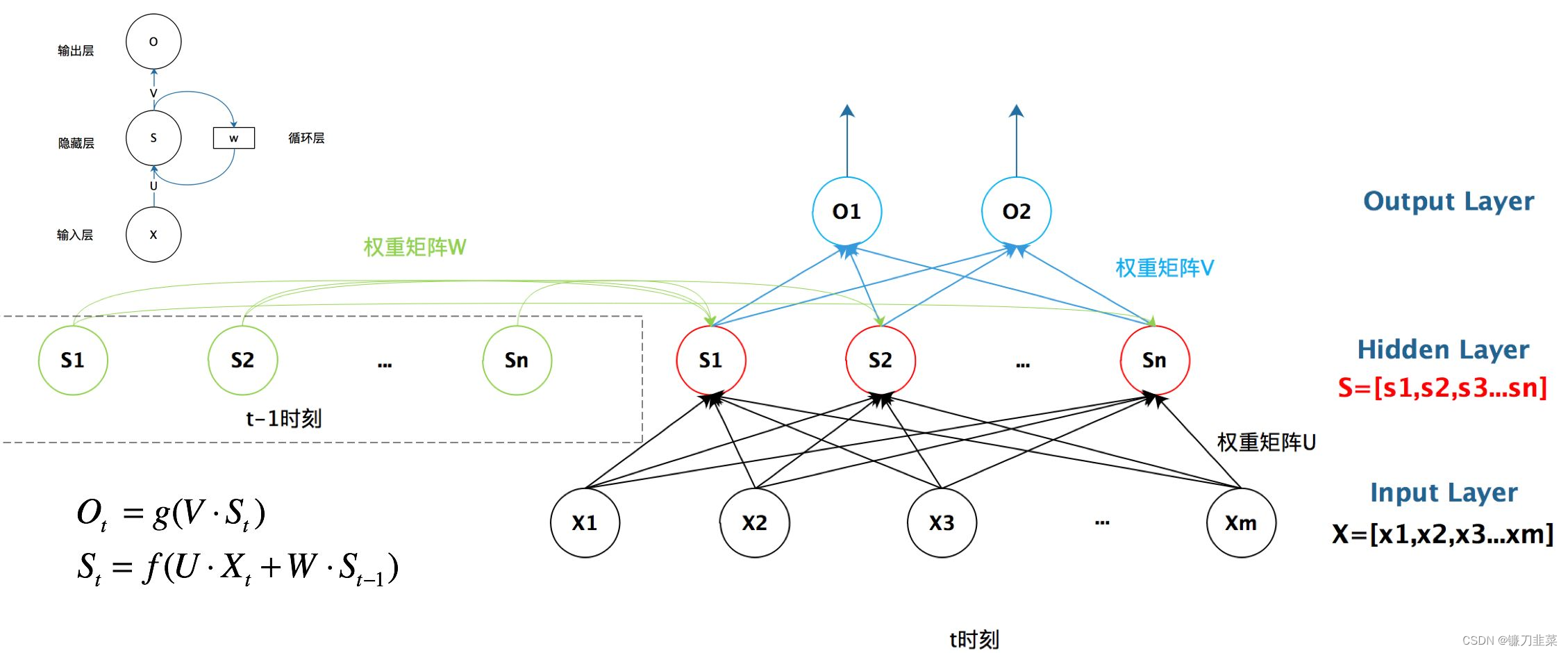
- x 1 , x 2 , x 3 , . . . , x T x_1,x_2,x_3,...,x_T x1,x2,x3,...,xT:输入词的序列(共有T个词),每个词都是一个向量,通常用词向量表示。
- S 0 , S 1 , S 2 , S 3 , . . . S T S_0,S_1,S_2,S_3,...S_T S0,S1,S2,S3,...ST:隐层元(共有T+1个),每个隐藏元都由之前的词计算得到,所以可以认为包含之前所有词的信息。 S 0 S_0 S0表示初始信息,一般采用全0的向量进行初始化。
- f f f:转换函数,根据当前输入 X t X_t Xt和前一个隐藏元的状态( S t − 1 S_{t-1} St−1),计算新的隐藏元状态 S t S_t St。可以认为 S t − 1 S_{t-1} St−1包含前 t − 1 t-1 t−1个词的信息,即 x 1 , x 2 , . . . , x t − 1 x_1,x_2,...,x_{t-1} x1,x2,...,xt−1,由 f f f利用 S t − 1 S_{t-1} St−1和 x t x_t xt计算得到的 S t S_t St,可以认为是包含前t个词的信息。需要注意的是,每一次计算 S t S_t St都用同一个 f f f。 f f f一般是一个矩阵乘法运算。
RNN最后会输出所有隐藏元的信息,一般只使用最后一个隐藏元的信息,可以认为它包含了整个句子的信息。
但是这种结构的RNN具有严重的梯度消失和梯度爆炸问题,难以训练。目前在深度学习中普遍使用的是一种称为LSTM的RNN结构。LSTM(Long Short Term Meomory Network, 长短期记忆网络),如下图所示: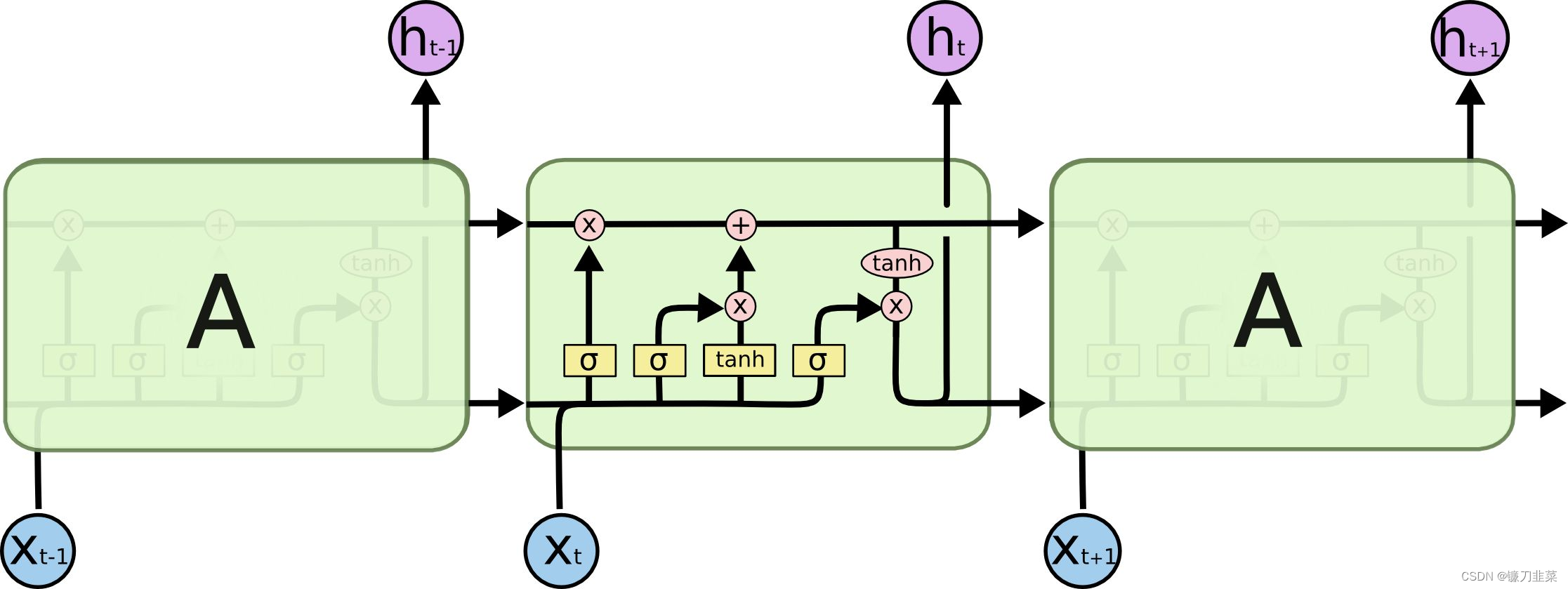
LSTM也是通过不断利用之前的状态和当前的输入来计算新的状态,但是其f函数更复杂,除了隐藏元状态(hidden state h),还有cell state c。每个LSTM单元的输出有两个,一个是下面的 h t h_t ht( h t h_t ht同时被创建分支引到上面去),一个是上面的 c t c_t ct。 c t c_t ct的存在能很好地抑制梯度消失和梯度爆炸等问题。
问题1:LSTM是如何实现长短期记忆功能的?
答:与传统的RNN相比,LSTM虽然仍然是基于 x t x_t xt和 h t − 1 h_{t-1} ht−1来计算 h t h_t ht,只不过对内部的结构进行了更加精心的设计,加入了输入门 i i i、遗忘门 f t f_t ft以及输出门 o t o_t ot三个门和一个内部记忆单元 c t c_t ct。
输入门控制当前计算的新状态以多大程度更新到记忆单元中;遗忘门控制前一步记忆单元中的信息有多大程度上被遗忘掉;输出门控制当前的输出有多大程度上取决于当前的记忆单元。
经典的LSTM中,第t步的更新计算公式为:
i t = σ ( W i x t + U i h t − 1 + b i ) i_t=\sigma (W_ix_t+U_ih_{t-1}+b_i) it=σ(Wixt+Uiht−1+bi)
f t = σ ( W f x t + U f h t − 1 + b f ) f_t=\sigma (W_fx_t+U_fh_{t-1}+b_f) ft=σ(Wfxt+Ufht−1+bf)
o t = σ ( W o x t + U o h t − 1 + b o ) o_t=\sigma (W_ox_t+U_oh_{t-1}+b_o) ot=σ(Woxt+Uoht−1+bo)
c ~ t = T a n h ( W c x t + U c h t − 1 ) \widetilde{c}_t=Tanh(W_cx_t+U_ch_{t-1}) ct=Tanh(Wcxt+Ucht−1)
c t = f t ⊙ c t − 1 + i t ⊙ c ~ t c_t=f_t\odot c_{t-1}+i_t\odot \widetilde{c}_t ct=ft⊙ct−1+it⊙ct
h t = o t ⊙ T a n h ( c t ) h_t=o_t\odot Tanh(c_t) ht=ot⊙Tanh(ct)
其中, i t i_t it是通过输入 x t x_t xt和上一步的隐含层输出 h t − 1 h_{t-1} ht−1进行线性变换,在经过激活函数 σ \sigma σ得到的。输入门 i t i_t it的结果是向量,其中每个元素是0到1之间的实数,用于控制各维度流过阀门的信息量; W i W_i Wi, U i U_i Ui两个矩阵和向量 b i b_i bi为输入门的参数,是在训练过程中需要学习得到的。遗忘门 f t f_t ft和输出门 o t o_t ot的计算方式与输入门类似,它们有各自的参数 W W W、 U U U和b。
与传统的RNN不同的是,从上一个记忆单元的状态 c t − 1 c_{t-1} ct−1到当前的状态 c t c_t ct的转移不一定完全取决于激活函数计算得到的状态,还由输入门和遗忘门共同控制。
在一个训练好的网络中,当输入的序列中没有重要信息时,LSTM的遗忘门的值接近于1,输入门的值接近于0,此时过去的记忆会被保存,从而实现了长期记忆功能;当输入的序列中出现了重要信息时。,LSTM应当将其存入记忆中,此时其输入门的值会接近于1;当输入的序列中出现了重要信息,且该信息意味着之前的记忆不再重要时,输入门的值接近1,而遗忘门的值接近于0,这样旧的记忆被遗忘,新的重要信息被记忆。经过这样的设计,整个网络更容易学习到序列之间的长期依赖。
问题2:LSTM里各模块分别使用什么激活函数,可以使用别的激活函数吗?
答:关于激活函数的选取,在LSTM中,遗忘门、输入门和输出门使用Sigmoid函数作为激活函数;在生成候选记忆时,使用双曲正切函数Tanh作为激活函数。值得注意的是,这两个激活函数都是饱和的,也就是说在输入达到一定值的情况下,输出就不会发生明显变化了。
如果是用非饱和的激活函数,例如ReLU,那么将难以实现门控的效果。
- Sigmoid函数的输出在0~1之间,符合门控的物理定义。且当输入较大或较小时,其输出会非常接近1或者0,从而保证该门开或关。
- 在生成候选记忆时,使用Tanh函数,是因为其输出在-1~1之间,这与大多数场景下特征分布是0中心的吻合。此外,Tanh函数在输入为0附近相比Sigmoid函数具有更大的梯度,通常使模型收敛更快。
激活函数的选择也不是一成不变的。例如在原始的LSTM中,使用的激活函数是Sigmoid函数的变种, h ( x ) = 2 s i g m o i d ( x ) − 1 , g ( x ) = 4 s i g m o i d ( x ) − 2 h(x)=2sigmoid(x)-1, g(x)=4sigmoid(x)-2 h(x)=2sigmoid(x)−1,g(x)=4sigmoid(x)−2,这两个函数的范围分别是[-1, 1]和[-2, 2]。并且在原始的LSTM中,只有输入门和输出门,没有遗忘门,其中输入经过输入门后是直接与记忆相加的,所以输入门控 g ( x ) g(x) g(x)的值是0中心的。
后来经过实验表明,增加遗忘门对LSTM的性能有很大的提升,并且 h ( x ) h(x) h(x)使用Tanh比 2 ∗ s i g m o i d ( x ) − 1 2\ast sigmoid(x)-1 2∗sigmoid(x)−1要好,所以现代LSTM采用Sigmoid和Tanh作为激活函数。事实上,在门控中,使用Sigmoid函数是几乎所有现代神经网络模块的共同选择。例如在门控循环单元和注意力机制中,也广泛使用Sigmoid函数作为门控的激活函数。
此外,在一些对计算能力有限制的设备,例如可穿戴设备中,由于Sigmoid函数求指数需要一定的计算量,此时会使用 0 / 1 0/1 0/1门(hard gate)让门空输出为0或1的离散值,即当输入小于阈值时门控输出为0;当输入大于 阈值时,输出为1。从而在性能下降不显著的情况下,减少计算量。
经典的LSTM在计算各门控时,通常使用输入 x t x_t xt和隐层输出 h t − 1 h_{t-1} ht−1参与门控计算,例如对输入 门的更新: i t = σ ( W i x t + U i h t − 1 + b i ) i_t=\sigma (W_ix_t+U_ih_{t-1}+b_i) it=σ(Wixt+Uiht−1+bi)。其最常见的变种就是加入了窥孔机制,让记忆 c t − 1 c_{t-1} ct−1也参与到门控的计算中,此时输入门的更新方式变为:
i t = σ ( W i x t + U i h t − 1 + V i c t − 1 + b i ) i_t=\sigma (W_ix_t +U_ih_{t-1}+V_ic_{t-1}+b_i) it=σ(Wixt+Uiht−1+Vict−1+bi)
一个在Pytorch中使用LSTM的示例:
# -*- coding: utf-8 -*-#
# ----------------------------------------------
# Name: LSTMdemo.py
# Description:
# Author: PANG
# Date: 2022/6/27
# ----------------------------------------------
import torch as t
from torch import nn
from torch.autograd import Variable
# 输入词用10维词向量表示
# 隐层元用20维向量表示
# 两层的lstm
rnn = nn.LSTM(10, 20, 2)
# 输入每句话有5个词
# 每个词有10维的词向量表示
# 总共有3句话(batch size)
input = Variable(t.randn(5, 3, 10))
# 1个隐藏元(hidden state和cell state)的初始值
# 形状(num_layers, batch_size, hidden_size)
h0 = Variable(t.zeros(2, 3, 20))
c0 = Variable(t.zeros(2, 3, 20))
# output是最后一层所有隐藏元的值
# hn和cn是所有层(这里有两层)的最后一个隐藏元的值
output, (hn, cn) = rnn(input, (h0, c0))
print(output.size())
print(hn.size())
print(cn.size())
# 输出
torch.Size([5, 3, 20])
torch.Size([2, 3, 20])
torch.Size([2, 3, 20])
注意:output的形状与LSTM的层数无关,只与序列长度有关, 而hn和cn则相反。
除了LSTM, PyTorch中还有LSTMCell。LSTM是对一个LSTM层的抽象,可以看成是由多个LSTMCell组成。而使用LSTMCell则可以进行更精细化的操作。LSTM还有一种变体称为GRU(Gated Recurrent Unit),相较于LSTM,GRU的速度更快,效果也接近。对速度要求比较严苛的场景可以使用GRU。
2. CharRNN
CharRNN的作者是Andrej karpathy。CharRNN从海量文本中学习英文字母(注意,是字母,不是单词)的组合,并能够自动生成相对应的文本。
CharRNN的原理十分简单,它分为训练和生成两部分。训练的时候如下图所示: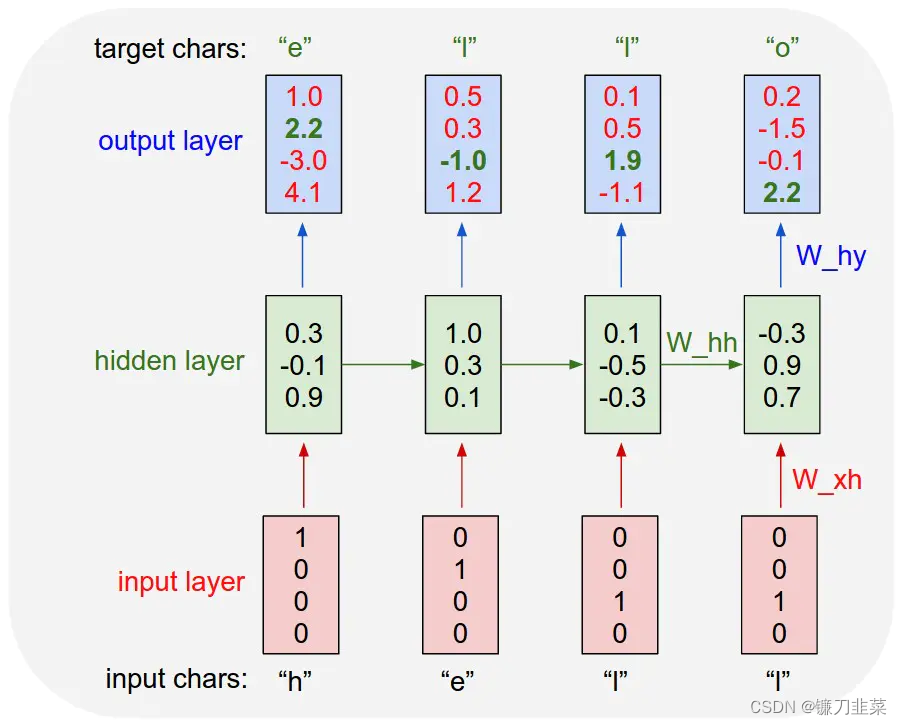
上图展示了Char-RNN的原理。以要让模型学习写出“hello”为例,Char-RNN的输入输出层都是以字符为单位。输入“h”,应该输出“e”;输入“e”,则应该输出后续的“l”。输入层我们可以用只有一个元素为1的向量来编码不同的字符,例如,h被编码为“1000”、“e”被编码为“0100”,而“l”被编码为“0010”。
使用RNN的学习目标是,可以让生成的下一个字符尽量与训练样本里的目标输出一致。在图一的例子中,根据前两个字符产生的状态和第三个输入“l”预测出的下一个字符的向量为<0.1, 0.5, 1.9, -1.1>,最大的一维是第三维,对应的字符则为“0010”,正好是“l”。这就是一个正确的预测。但从第一个“h”得到的输出向量是第四维最大,对应的并不是“e”,这样就产生代价。学习的过程就是不断降低这个代价。学习到的模型,对任何输入字符可以很好地不断预测下一个字符,如此一来就能生成句子或段落。
正如上所述,CharRNN可以看成一个分类问题:根据当前字符,预测下一个字符。对于英文字符来说,文本中用到的总共只有不超过128个字符(假设就是128个字符),所以预测问题就可以改成128分类问题:将每一个隐藏元的输出,输入到一个全连接层,计算输出属于128个字符的概率,计算交叉熵损失即可。
总之,CharRNN通过利用当前字的隐藏元状态预测下一个字,把生成问题变成了分类问题。
训练完成之后,就可以利用网络进行文本生成来写诗和剧本了。生成步骤如下:
- 首先输入一个起始的字符(一般用<start>标识),计算输出属于每个字符的概率。
- 选择概率最大的一个字符作为输出。
- 将上一步的输出作为输入,继续输入到网络中,计算输出属于每个字符的概率
- …
最终将所有字拼接组合在一起,就得到最后的生成结果。当然,CharRNN也有一些不够严谨之处,例如它使用One-hot编码,而不是词向量,使用RNN而不是LSTM。
3. 用PyTorch实现CharRNN
实验采用的数据集是Github上中文诗词爱好者收集的5万首唐诗原文,并整合成一个numpy的压缩包tang.npz,里面包含三个对象:
- data: (57580, 125)的numpy数组,共有57580首诗歌,每首诗歌的长度为125个字符(不足125补空格,超过125的丢弃)。
- word2ix:每个词和它对应的序号
- ix2word:每个序号和它对应的词
其中,data对诗歌的处理步骤如下:
- 先将诗句转换成list,并在前面和后面加上起始符<start>和终止符<end>。
- 对于长度达不到125个字符的诗歌,在前面补上空格(用</\s>表示),直到长度达到125。
- 对于长度超过125字符的诗歌,把结尾的词截断。
- 将每个字都转换成对应的序号。
- 将序号list转成numpy数组。
数据处理完之后,本次实验的文件组织架构如下:
data.py
main.py
model.py
tang.npz
utils.py
其中几个比较重要的文件如下:
- main.py:包含程序配置、训练和生成。
- model.py:模型定义。
- utils.py:可视化工具visdom的封装。
- tang.npz:将5万多首唐诗预处理成numpy数据。
- data.py:对原始的唐诗文本进行预处理,如果直接使用tang.npz,则不需要对json的数据进行处理。
程序中主要的配置选项和命令行参数如下
class Config(object):
data_path = 'data/' # 诗歌的文本文件存放路径
pickle_path = 'tang.npz' # 预处理好的二进制文件
author = None # 只学习某位作者的诗歌
constrain = None # 长度限制
category = 'poet.tang' # 类别,唐诗还是宋诗歌(poet.song)
lr = 1e-3
weight_decay = 1e-4
use_gpu = True
epoch = 20
batch_size = 128
maxlen = 125 # 超过这个长度的之后字被丢弃,小于这个长度的在前面补空格
plot_every = 20 # 每20个batch 可视化一次
# use_env = True # 是否使用visodm
env = 'poetry' # visdom env
max_gen_len = 200 # 生成诗歌最长长度
debug_file = 'debug/debug.txt'
model_path = None # 预训练模型路径
prefix_words = '细雨鱼儿出,微风燕子斜。' # 不是诗歌的组成部分,用来控制生成诗歌的意境
start_words = '闲云潭影日悠悠' # 诗歌开始
acrostic = False # 是否是藏头诗
model_prefix = 'checkpoints/tang' # 模型保存路径
在data.py中主要有以下三个函数:
- _parseRawData:解析原始的json数据,提取成list。
- pad_sequences:将不同长度的数据截断或补齐成一样的长度。
- get_data:给主程序调用的接口。如果二进制文件存在,则直接读取二进制的numpy文件;否则读取文本文件进行处理,并将处理结果保存成二进制文件。
其中get_data函数代码如下:
def get_data(opt):
""" :param opt: 配置选项,Config对象 :return: data: numpy 数组, 每一行是一首诗对应的字的下标 """
if os.path.exists(opt.pickle_path):
data = np.load(opt.pickle_path, allow_pickle=True)
data, word2ix, ix2word = data['data'], data['word2ix'].item(), data['ix2word'].item()
return data, word2ix, ix2word
# 如果没有处理好的二进制文件,则处理原始的json文件
data = _parseRawData(opt.author, opt.constrain, opt.data_path, opt.category)
words = {
_word for _sentence in data for _word in _sentence}
word2ix = {
_word: _ix for _ix, _word in enumerate(words)}
word2ix['<EOP>'] = len(word2ix) # 终止标识符
word2ix['<START>'] = len(word2ix) # 起始标识符
word2ix['</s>'] = len(word2ix) # 空格
ix2word = {
_ix: _word for _word, _ix in list(word2ix.items())}
# 为每首诗歌加上起始符和终止符
for i in range(len(data)):
data[i] = ["<START>"] + list(data[i]) + ["<EOP>"]
# 将每首诗歌保存的内容由‘字’变成‘数’
# 形如[春,江,花,月,夜]变成[1,2,3,4,5]
new_data = [[word2ix[_word] for _word in _sentence] for _sentence in data]
# 诗歌长度不够opt.maxlen的在前面补空格,超过的,删除末尾的
pad_data = pad_sequences(new_data, maxlen=opt.maxlen, padding='pre', truncating='post', value=len(word2ix) - 1)
# 保存成二进制文件
np.savez_compressed(opt.pickle_path, data=pad_data, word2ix=word2ix, ix2word=ix2word)
return pad_data, word2ix, ix2word
模型构建的代码保存在model.py中,代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class PoetryModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(PoetryModel, self).__init__()
self.hidden_dim = hidden_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=2)
self.linear1 = nn.Linear(self.hidden_dim, vocab_size)
def forward(self, input, hidden=None):
seq_len, batch_size = input.size()
if hidden is None:
# 2是因为有两层LSTM
h_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
c_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
else:
h_0, c_0 = hidden
# size: (seq_len, batch_size, embeding_dim)
embeds = self.embeddings(input)
# output size: (seq_len, batch_size, hidden_dim)
output, hidden = self.lstm(embeds, (h_0, c_0))
# size: (seq_len*batch_size, vocab_size)
output = self.linear1(output.view(seq_len * batch_size, -1))
return output, hidden
总而言之,输入的字词序号经过nn.Embedding得到相应的词向量表示,然后利用两层LSTM提取词的所有隐藏元的信息,再利用隐藏元的信息进行分类,判断输出属于每一个词的概率。
训练相关的代码保存于main.py中:
def train(**kwargs):
for k, v in kwargs.items():
setattr(opt, k, v)
opt.device = t.device('cuda') if opt.use_gpu else t.device('cpu')
device = opt.device
vis = Visualizer(env=opt.env)
# 获取数据
data, word2ix, ix2word = get_data(opt)
data = t.from_numpy(data)
dataloader = t.utils.data.DataLoader(data, batch_size=opt.batch_size, shuffle=True, num_workers=1)
# 模型定义
model = PoetryModel(len(word2ix), 128, 256)
optimizer = t.optim.Adam(model.parameters(), lr=opt.lr)
criterion = nn.CrossEntropyLoss()
if opt.model_path:
model.load_state_dict(t.load(opt.model_path))
model.to(device)
loss_meter = meter.AverageValueMeter()
for epoch in range(opt.epoch):
loss_meter.reset()
for ii, data_ in tqdm.tqdm(enumerate(dataloader)):
# 训练
data_ = data_.long().transpose(1, 0).contiguous()
data_ = data_.to(device)
optimizer.zero_grad()
# 实现错位的方式
# 前者包含从第0个词直到最后一个词(不包含),后者是第一个词到结尾(包括最后一个词)
input_, target = data_[:-1, :], data_[1:, :]
output, _ = model(input_)
loss = criterion(output, target.view(-1))
loss.backward()
optimizer.step()
loss_meter.add(loss.item())
# 可视化
if (1 + ii) % opt.plot_every == 0:
if os.path.exists(opt.debug_file):
ipdb.set_trace()
vis.plot('loss', loss_meter.value()[0])
# 诗歌原文
poetrys = [[ix2word[_word] for _word in data_[:, _iii].tolist()] for _iii in range(data_.shape[1])][:16]
vis.text('</br>'.join([''.join(poetry) for poetry in poetrys]), win=u'origin_poem')
gen_poetries = []
# 分别以这几个字作为诗歌的第一个字,生成8首诗
for word in list(u'春江花月夜凉如水'):
gen_poetry = ''.join(generate(model, word, ix2word, word2ix))
gen_poetries.append(gen_poetry)
vis.text('</br>'.join([''.join(poetry) for poetry in gen_poetries]), win=u'gen_poem')
t.save(model.state_dict(), '%s_%s.pth' % (opt.model_prefix, epoch))
(1)给定诗歌开头的几个字,续写诗歌。
def generate(model, start_words, ix2word, word2ix, prefix_words=None):
""" 给定几个词,根据这几个词接着生成一首完整的诗歌 start_words:u'春江潮水连海平' 比如start_words 为 春江潮水连海平,可以生成: """
results = list(start_words)
start_word_len = len(start_words)
# 手动设置第一个词为<START>
input = t.Tensor([word2ix['<START>']]).view(1, 1).long()
if opt.use_gpu: input = input.cuda()
hidden = None
if prefix_words:
for word in prefix_words:
output, hidden = model(input, hidden)
input = input.data.new([word2ix[word]]).view(1, 1)
for i in range(opt.max_gen_len):
output, hidden = model(input, hidden)
if i < start_word_len:
w = results[i]
input = input.data.new([word2ix[w]]).view(1, 1)
else:
top_index = output.data[0].topk(1)[1][0].item()
w = ix2word[top_index]
results.append(w)
input = input.data.new([top_index]).view(1, 1)
if w == '<EOP>':
del results[-1]
break
return results
(2)生成藏头诗
def gen_acrostic(model, start_words, ix2word, word2ix, prefix_words=None):
""" 生成藏头诗 start_words : u'深度学习' 生成: 深木通中岳,青苔半日脂。 度山分地险,逆浪到南巴。 学道兵犹毒,当时燕不移。 习根通古岸,开镜出清羸。 """
results = []
start_word_len = len(start_words)
input = (t.Tensor([word2ix['<START>']]).view(1, 1).long())
if opt.use_gpu: input = input.cuda()
hidden = None
index = 0 # 用来指示已经生成了多少句藏头诗
# 上一个词
pre_word = '<START>'
if prefix_words:
for word in prefix_words:
output, hidden = model(input, hidden)
input = (input.data.new([word2ix[word]])).view(1, 1)
for i in range(opt.max_gen_len):
output, hidden = model(input, hidden)
top_index = output.data[0].topk(1)[1][0].item()
w = ix2word[top_index]
if (pre_word in {
u'。', u'!', '<START>'}):
# 如果遇到句号,藏头的词送进去生成
if index == start_word_len:
# 如果生成的诗歌已经包含全部藏头的词,则结束
break
else:
# 把藏头的词作为输入送入模型
w = start_words[index]
index += 1
input = (input.data.new([word2ix[w]])).view(1, 1)
else:
# 否则的话,把上一次预测是词作为下一个词输入
input = (input.data.new([word2ix[w]])).view(1, 1)
results.append(w)
pre_word = w
return results
4. 结果分析
首先,执行python -m visdom.server 启动visdom可视化界面
(1) python main.py train --plot-every=150 --batch-size=8 --pickle-path='tang.npz' --lr=1e-3 --env='poetry3' --epoch=50 --num_workers=0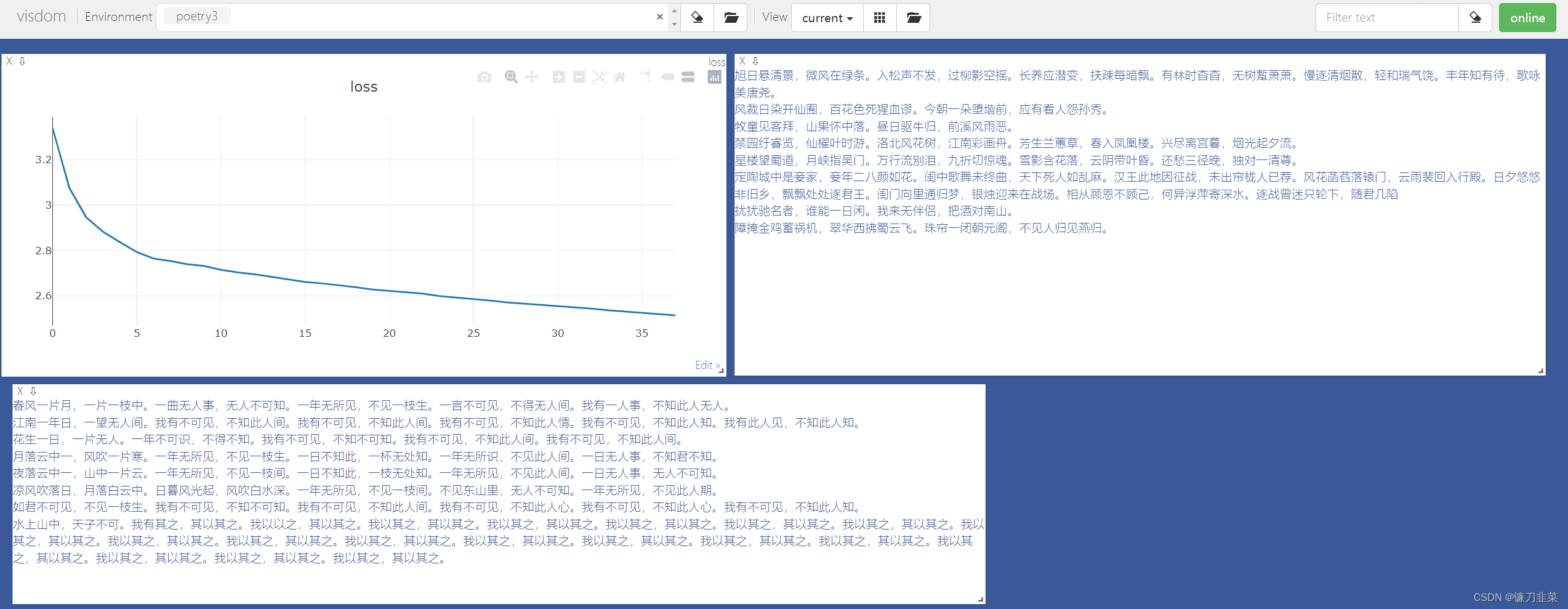
(2)生成一首诗(指定开头、指定意境和格律)python main.py gen --model-path='checkpoints/tang_49.pth' --start-words='孤帆远影碧空尽,' --prefix-words='朝辞白帝彩云间,千里江陵一日还。'
(3)生成一首藏头诗(指定藏头,指定意境格律)python main.py gen --model-path='checkpoints/tang_49.pth' --acrostic=True --start-words='深度学习' --prefix-words='大漠孤烟直,长河落日圆。'
参考资料
[1] Char RNN原理介绍以及文本生成实践
[2] 简单的Char RNN生成文本
边栏推荐
- Will the filing free server affect the ranking and weight of the website?
- Review and arrangement of HCIA
- SQL lab 11~20 summary (subsequent continuous update) contains the solution that Firefox can't catch local packages after 18 levels
- The left-hand side of an assignment expression may not be an optional property access.ts(2779)
- An error occurred when vscade tried to create a file in the target directory: access denied [resolved]
- VSCode的学习使用
- 千人规模互联网公司研发效能成功之路
- idea 2021中文乱码
- Xiaohongshu microservice framework and governance and other cloud native business architecture evolution cases
- [data clustering] realize data clustering analysis based on multiverse optimization DBSCAN with matlab code
猜你喜欢

Learning and using vscode
Introduction and application of smoothstep in unity: optimization of dissolution effect

Baidu digital person Du Xiaoxiao responded to netizens' shouts online to meet the Shanghai college entrance examination English composition
金融数据获取(三)当爬虫遇上要鼠标滚轮滚动才会刷新数据的网页(保姆级教程)

(待会删)yyds,付费搞来的学术资源,请低调使用!

<No. 8> 1816. Truncate sentences (simple)

SQL lab 11~20 summary (subsequent continuous update) contains the solution that Firefox can't catch local packages after 18 levels

Attack and defense world - PWN learning notes
Simple network configuration for equipment management

全球首堆“玲龙一号”反应堆厂房钢制安全壳上部筒体吊装成功
随机推荐
PowerShell cs-utf-16le code goes online
Tutorial on the principle and application of database system (011) -- relational database
110.网络安全渗透测试—[权限提升篇8]—[Windows SqlServer xp_cmdshell存储过程提权]
An error occurred when vscade tried to create a file in the target directory: access denied [resolved]
The function of adding @ before the path in C #
110. Network security penetration test - [privilege promotion 8] - [windows sqlserver xp_cmdshell stored procedure authorization]
EPP+DIS学习之路(1)——Hello world!
How much does it cost to develop a small program mall?
File upload vulnerability - upload labs (1~2)
Customize the web service configuration file
千人规模互联网公司研发效能成功之路
Hi3516全系统类型烧录教程
Cenos openssh upgrade to version 8.4
SQL Lab (46~53) (continuous update later) order by injection
What are the top-level domain names? How is it classified?
【深度学习】图像多标签分类任务,百度PaddleClas
gcc 编译报错
SQL lab 26~31 summary (subsequent continuous update) (including parameter pollution explanation)
《通信软件开发与应用》课程结业报告
SQL head injection -- injection principle and essence