当前位置:网站首页>爱可可AI前沿推介(7.7)
爱可可AI前沿推介(7.7)
2022-07-07 10:28:00 【智源社区】
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:神经网络(泛化)与乔姆斯基层次结构、下游任务训练数据需求估计、基于层次级间注意力改进Transformer语义分割、基于深度表格模型的迁移学习、模型大小对性别偏差的影响、深度离线强化学习隐正则化实证研究、基于跨语言环境无关表示改进视觉语言导航、离线强化学习策略应训练增强自适应性、基于预条件扩散采样加速基于分数生成模型
1、[LG] Neural Networks and the Chomsky Hierarchy
G Delétang, A Ruoss, J Grau-Moya, T Genewein, L K Wenliang, E Catt, M Hutter, S Legg, P A. Ortega
[DeepMind]
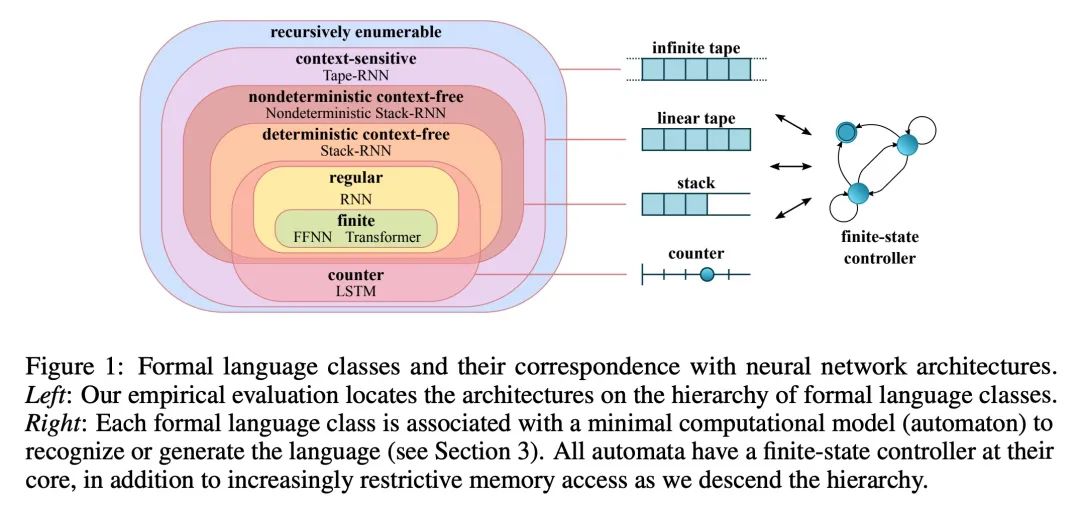
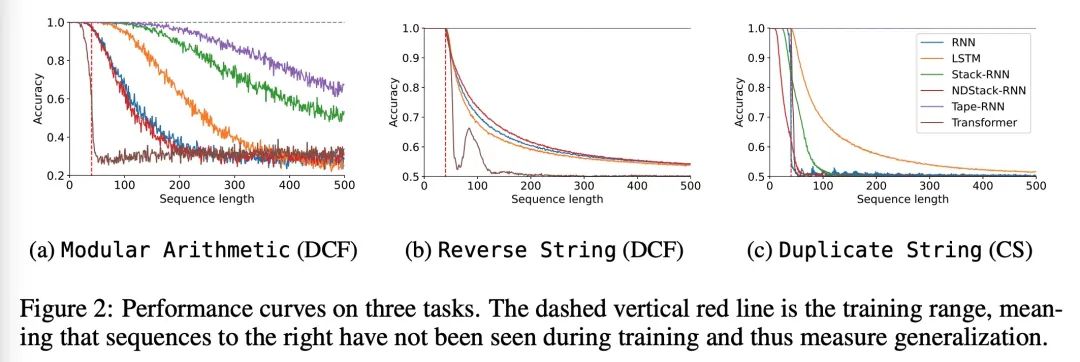
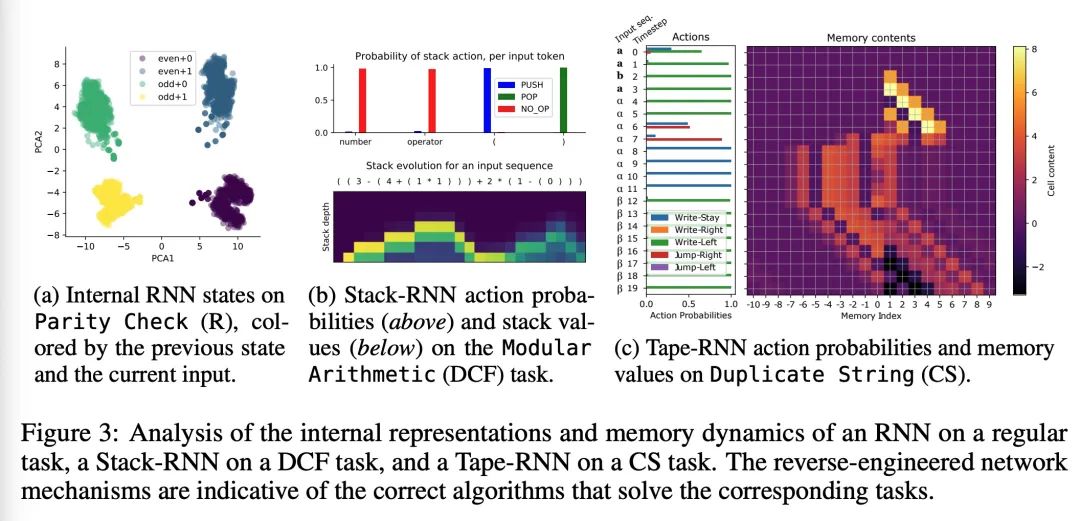
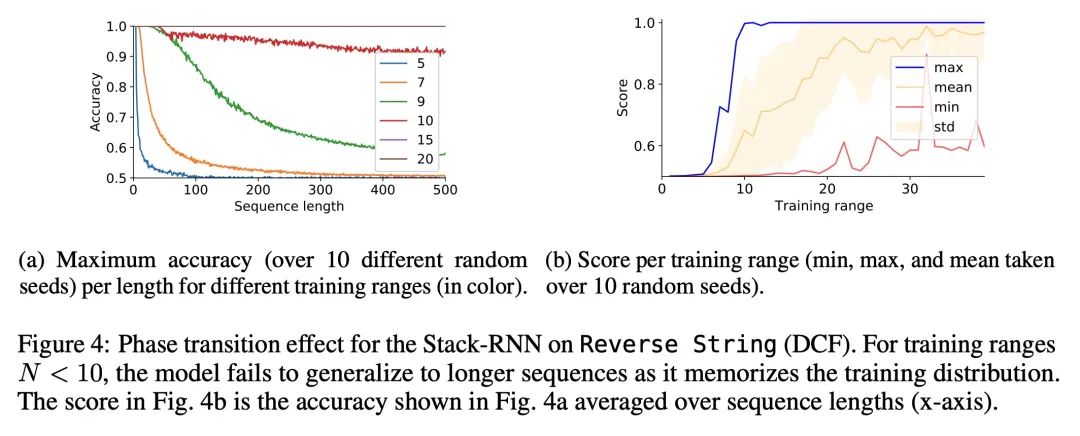
神经网络(泛化)与乔姆斯基层次结构。可靠的泛化是安全的机器学习和人工智能的核心所在。然而,了解神经网络何时以及如何泛化,仍然是该领域最重要的待解决问题之一。本文进行了一项广泛的实证研究(2200个模型,16个任务),以调研来自计算理论的见解是否能预测实践中神经网络泛化的极限。实验证明,根据乔姆斯基层次结构对任务进行分组,可以预测某些架构是否能泛化到分布外的输入。其中包括负面的结果,即大量数据和训练时间也无法带来任何非平凡的泛化,尽管模型有足够能力完全拟合训练数据。结果表明,对于所述的任务子集,RNN和Transformer未能对非常规任务实现泛化,LSTM可解决常规任务和反语言任务,而只有采用结构化记忆(如堆栈或记忆带)增强的网络可以成功地对无上下文和上下文敏感的任务实现泛化。
Reliable generalization lies at the heart of safe ML and AI. However, understanding when and how neural networks generalize remains one of the most important unsolved problems in the field. In this work, we conduct an extensive empirical study (2200 models, 16 tasks) to investigate whether insights from the theory of computation can predict the limits of neural network generalization in practice. We demonstrate that grouping tasks according to the Chomsky hierarchy allows us to forecast whether certain architectures will be able to generalize to out-ofdistribution inputs. This includes negative results where even extensive amounts of data and training time never led to any non-trivial generalization, despite models having sufficient capacity to perfectly fit the training data. Our results show that, for our subset of tasks, RNNs and Transformers fail to generalize on nonregular tasks, LSTMs can solve regular and counter-language tasks, and only networks augmented with structured memory (such as a stack or memory tape) can successfully generalize on context-free and context-sensitive tasks.
https://arxiv.org/abs/2207.02098

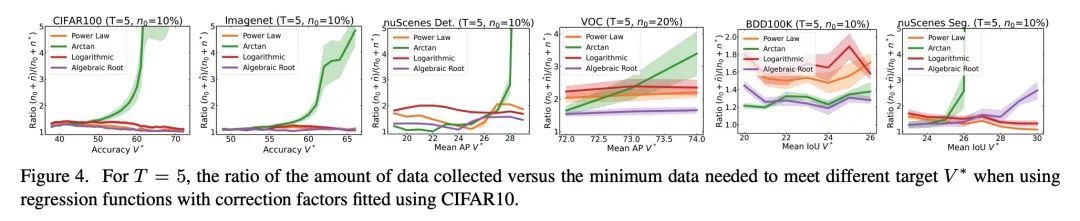
2、[CV] How Much More Data Do I Need? Estimating Requirements for Downstream Tasks
R Mahmood, J Lucas, D Acuna, D Li, J Philion, J M. Alvarez, Z Yu, S Fidler, M T. Law
[NVIDIA]
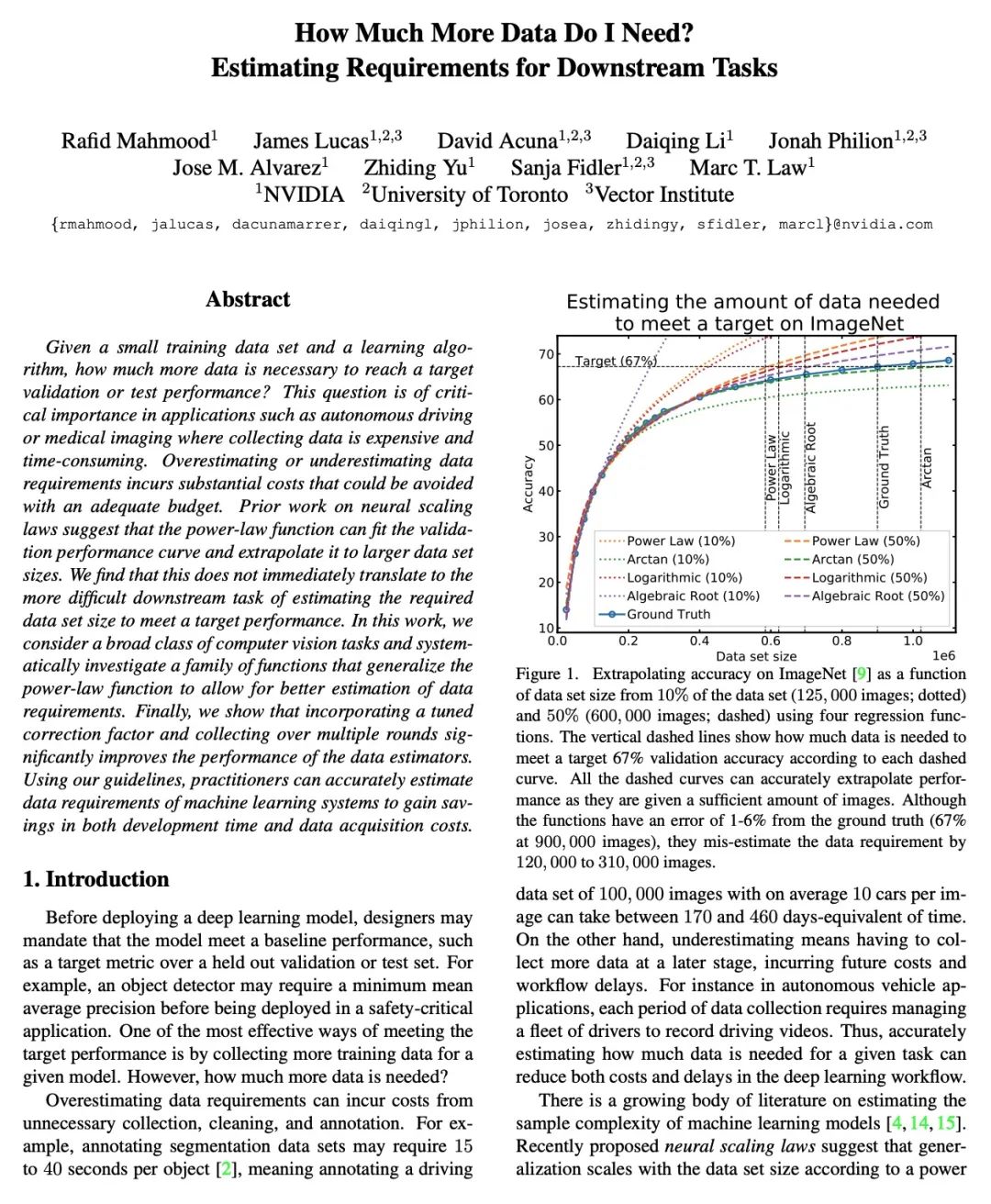
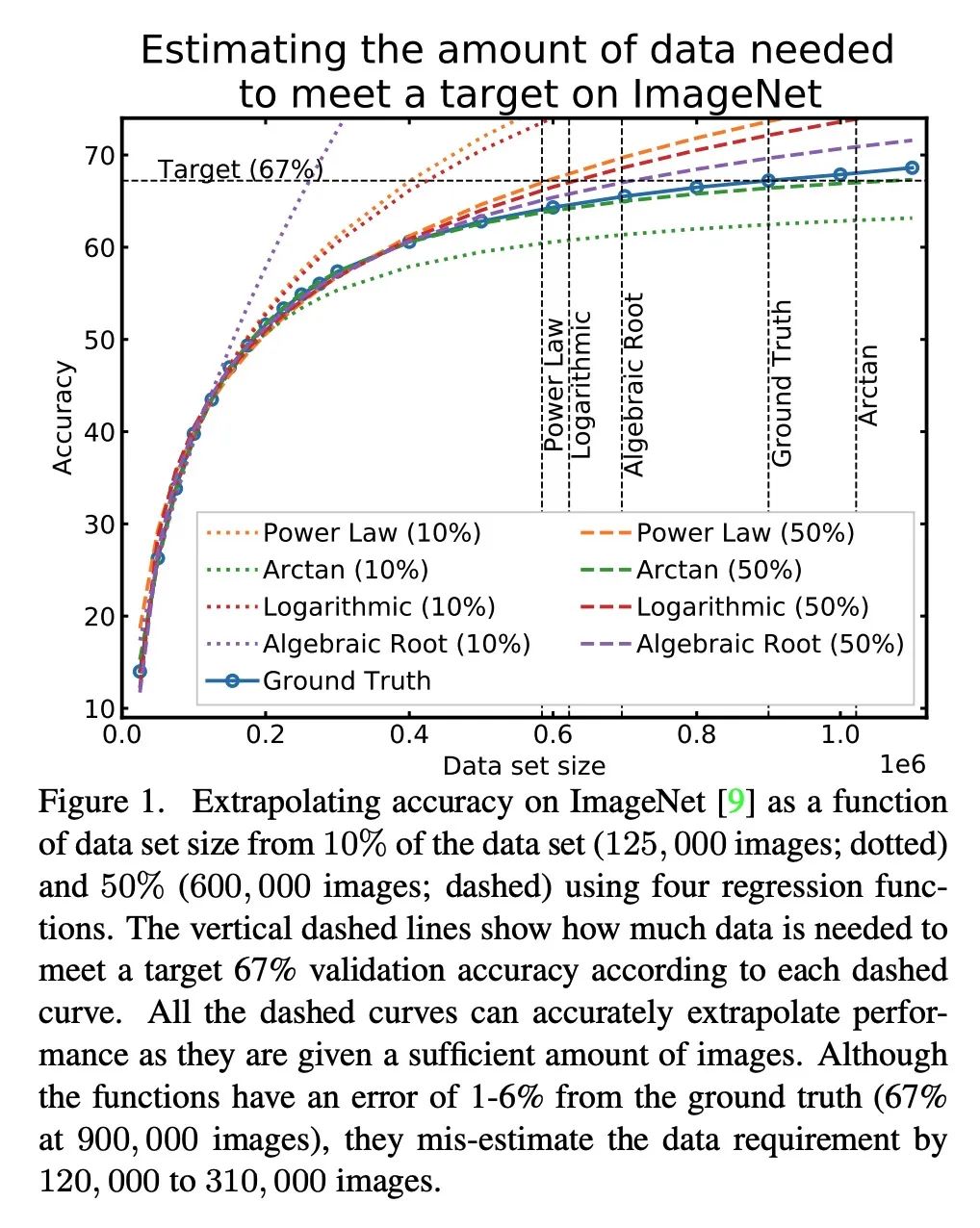
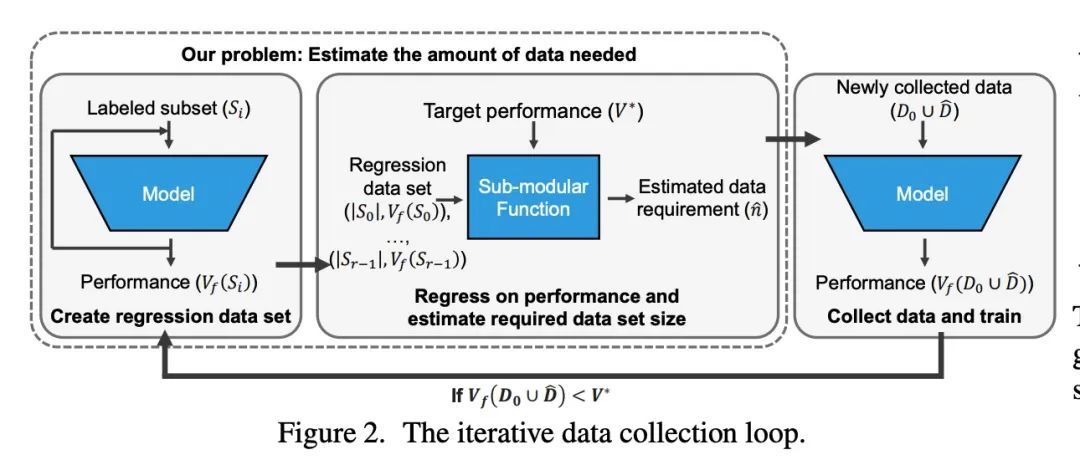
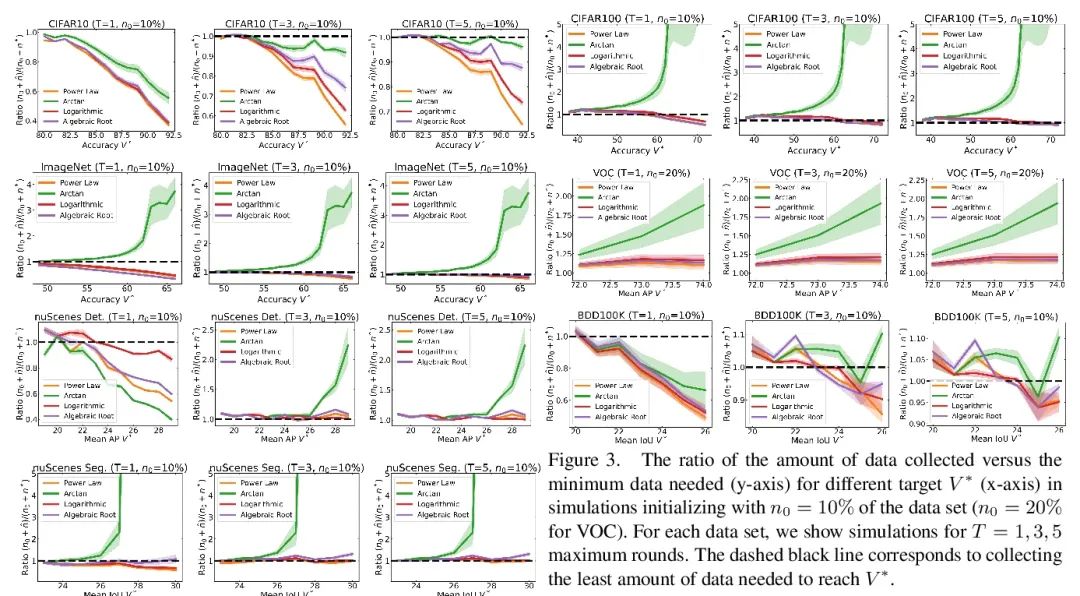
到底还要多少数据?下游任务训练数据需求估计。给定一个小的训练数据集和一个学习算法,还需要多少数据才能达到目标验证或测试性能?这个问题在无人驾驶或医学成像等应用中至关重要,因为在这些应用中,收集数据既昂贵又费时。高估或低估数据需求都会产生大量成本,而这些成本是可以通过充足的预算来避免的。之前关于神经缩放律的工作表明,幂律函数可以拟合验证性能曲线,并将其外推到更大的数据集规模。本文发现,这并不能直接应用到更困难的下游任务,来估计所需的数据集大小,以达到目标性能。本文考虑一类广泛的计算机视觉任务,系统研究了推广幂律函数的一系列函数,以更好地估计数据需求。实验表明,纳入微调的校正因子并在多轮中进行收集,能显著提高数据估计器的性能。使用所述指南,从业者可准确地估计机器学习系统的数据需求,以节约开发时间和数据采集成本。
Given a small training data set and a learning algorithm, how much more data is necessary to reach a target validation or test performance? This question is of critical importance in applications such as autonomous driving or medical imaging where collecting data is expensive and time-consuming. Overestimating or underestimating data requirements incurs substantial costs that could be avoided with an adequate budget. Prior work on neural scaling laws suggest that the power-law function can fit the validation performance curve and extrapolate it to larger data set sizes. We find that this does not immediately translate to the more difficult downstream task of estimating the required data set size to meet a target performance. In this work, we consider a broad class of computer vision tasks and systematically investigate a family of functions that generalize the power-law function to allow for better estimation of data requirements. Finally, we show that incorporating a tuned correction factor and collecting over multiple rounds significantly improves the performance of the data estimators. Using our guidelines, practitioners can accurately estimate data requirements of machine learning systems to gain savings in both development time and data acquisition costs.
https://arxiv.org/abs/2207.01725
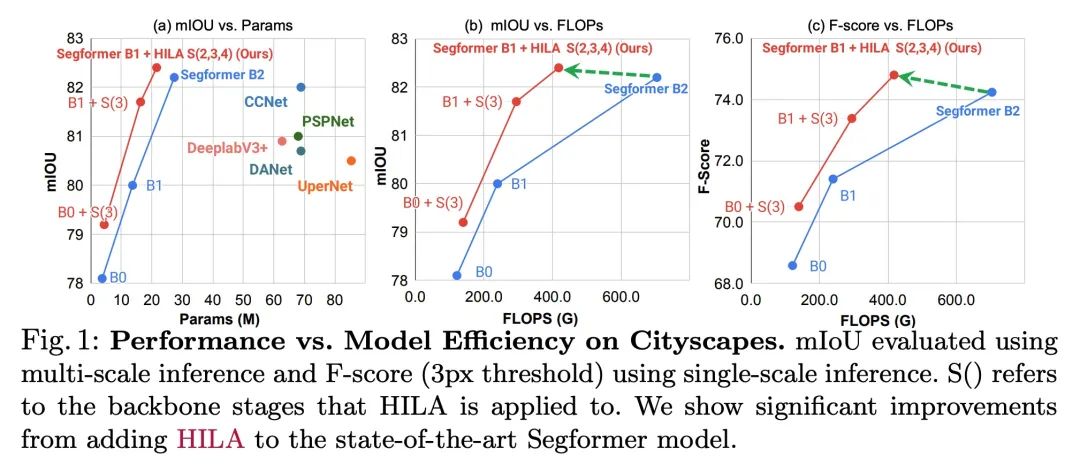
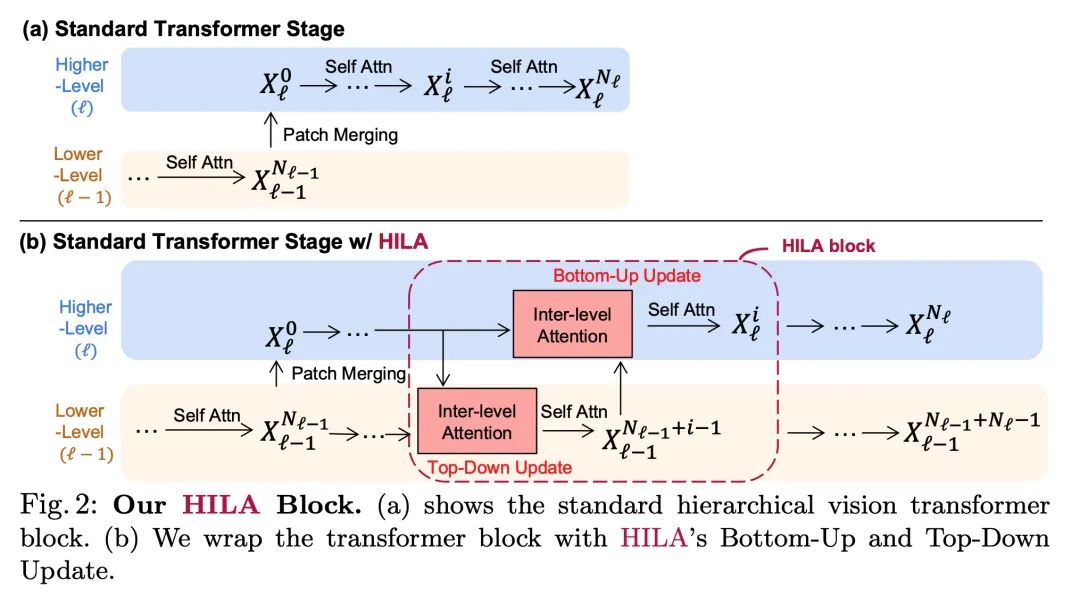
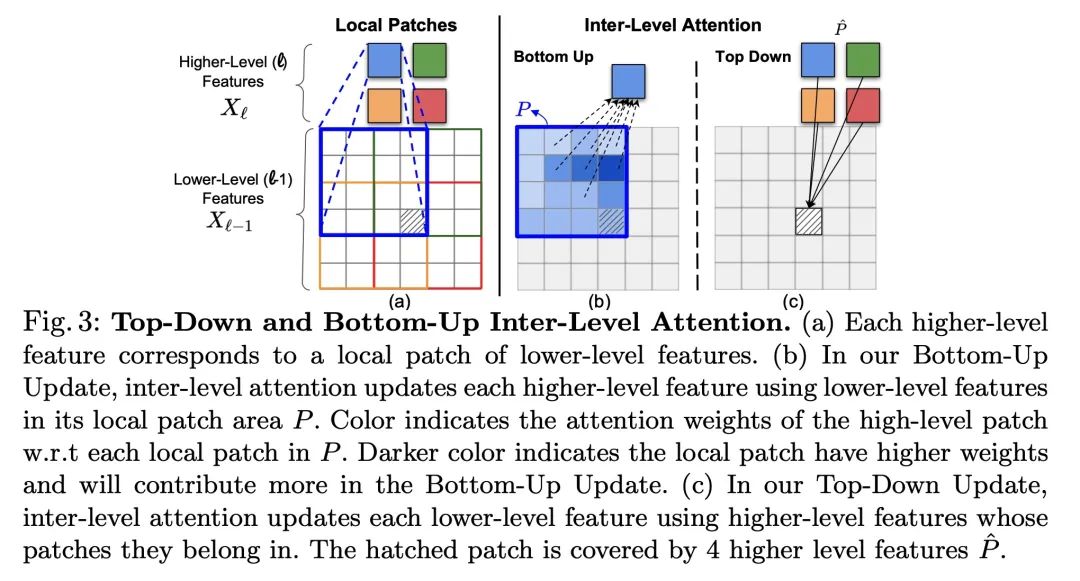
3、[CV] Improving Semantic Segmentation in Transformers using Hierarchical Inter-Level Attention
G Leung, J Gao, X Zeng, S Fidler
[University of Toronto]
基于层次级间注意力改进Transformer语义分割。现有的基于Transformers的图像骨架,通常将特征信息从低层向高层单向传播。这可能并不理想,因为准确划分物体边界的定位能力在较低的、高分辨率的特征图中最为突出,而能区分属于一个物体和另一个物体的图像信号的语义,通常在较高的处理水平上出现。本文提出层次级间注意力(Hierarchical Inter-Level Attention,HILA),一种基于注意力的方法,可以捕捉到不同层次特征间自下而上和自上而下的更新。HILA通过在骨干编码器中加入较高和较低层特征间的局部连接,扩展了层次视觉Transformers的结构。每次迭代通过让高层特征竞争分配来更新属于它们的低层特征,迭代解决目标-部分的关系来构建层次结构。这些改进的低级特征被用来重新更新高级特征。HILA可以被集成到大多数层次结构中,无需对基础模型做任何改变。将HILA添加到SegFormer和Swin Transformer中,显示出在语义分割中以较少的参数和FLOPS在精度上有明显的改善。
Existing transformer-based image backbones typically propagate feature information in one direction from lower to higher-levels. This may not be ideal since the localization ability to delineate accurate object boundaries, is most prominent in the lower, high-resolution feature maps, while the semantics that can disambiguate image signals belonging to one object vs. another, typically emerges in a higher level of processing. We present Hierarchical Inter-Level Attention (HILA), an attention-based method that captures Bottom-Up and Top-Down Updates between features of different levels. HILA extends hierarchical vision transformer architectures by adding local connections between features of higher and lower levels to the backbone encoder. In each iteration, we construct a hierarchy by having higher-level features compete for assignments to update lower-level features belonging to them, iteratively resolving object-part relationships. These improved lower-level features are then used to re-update the higher-level features. HILA can be integrated into the majority of hierarchical architectures without requiring any changes to the base model. We add HILA into SegFormer and the Swin Transformer and show notable improvements in accuracy in semantic segmentation with fewer parameters and FLOPS. Project website and code: this https URL
https://arxiv.org/abs/2207.02126


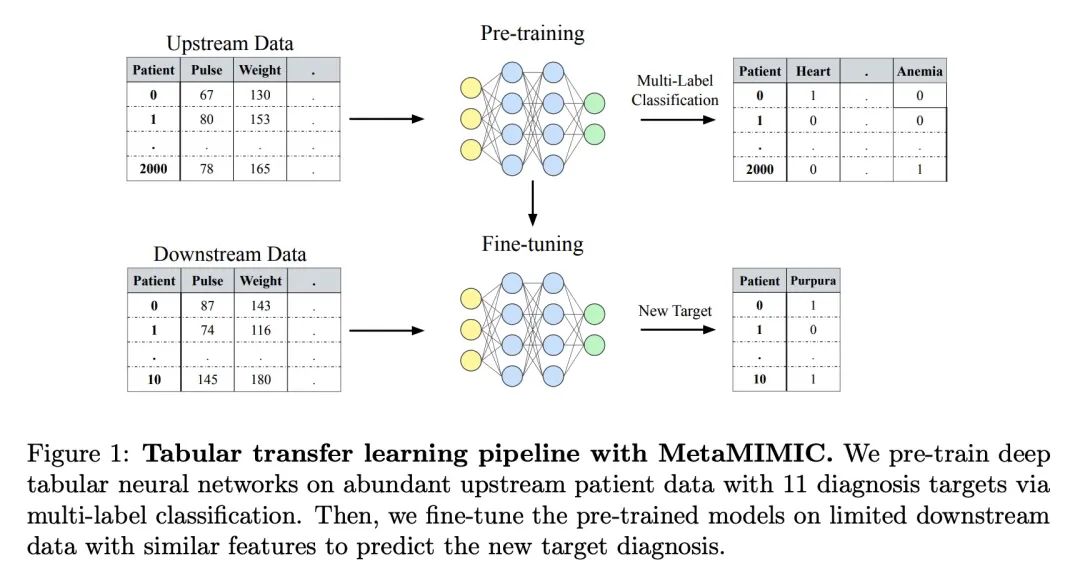
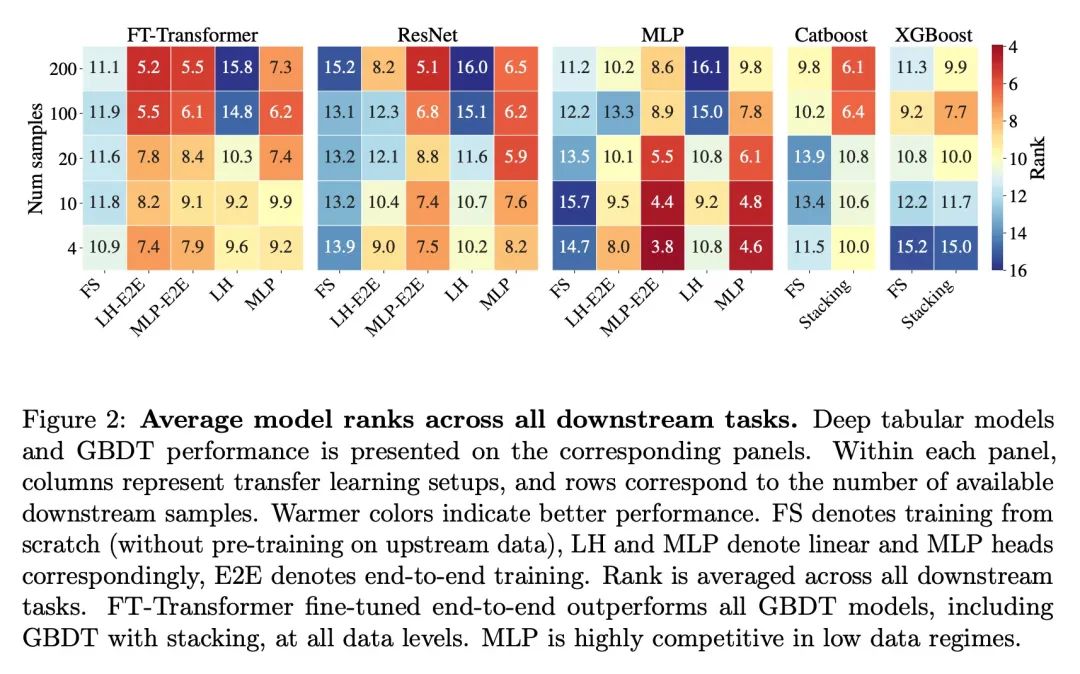
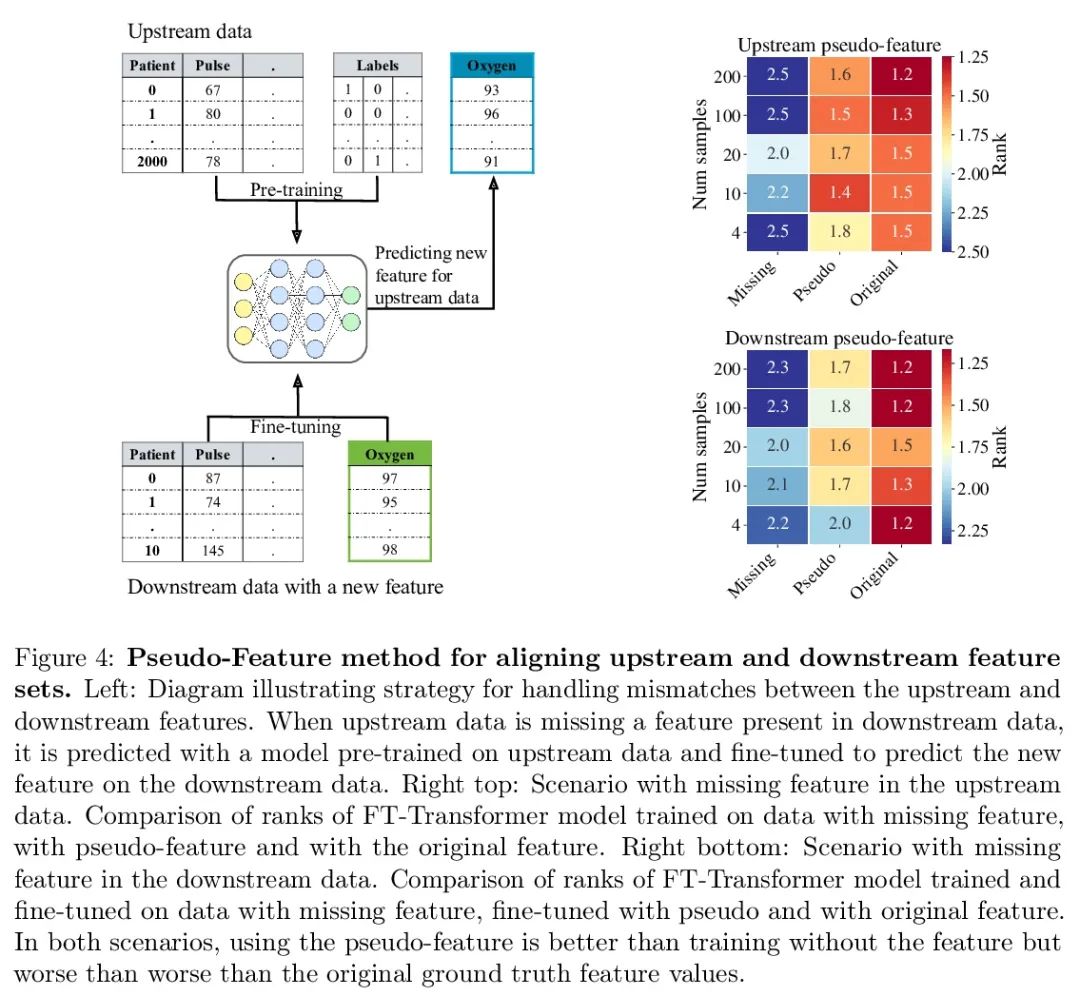
4、[LG] Transfer Learning with Deep Tabular Models
R Levin, V Cherepanova, A Schwarzschild, A Bansal, C. B Bruss, T Goldstein...
[University of Washington & University of Maryland & Capital One & New York University]
基于深度表格模型的迁移学习。最近针对表格数据的深度学习工作,表明了深度表格模型的强大性能,缩小了梯度提升决策树和神经网络之间的差距。除了精度,神经模型的一个主要优势,是它们可以学习可重复使用的特征,并且容易在新领域中进行微调。这一特性在计算机视觉和自然语言应用中经常被利用,当特定任务的训练数据匮乏时,迁移学习是非常必要的。本文证明了上游数据使表格神经网络比广泛使用的GBDT模型具有决定性的优势,为表格迁移学习提出了一个现实的医疗诊断基准,并提出关于如何使用上游数据来提高各种表格神经网络架构性能的指南。最后,为上下游特征集不同的情况提出了一种伪特征方法,这种情况是在现实世界应用中广泛存在的表格式特定问题。
Recent work on deep learning for tabular data demonstrates the strong performance of deep tabular models, often bridging the gap between gradient boosted decision trees and neural networks. Accuracy aside, a major advantage of neural models is that they learn reusable features and are easily fine-tuned in new domains. This property is often exploited in computer vision and natural language applications, where transfer learning is indispensable when task-specific training data is scarce. In this work, we demonstrate that upstream data gives tabular neural networks a decisive advantage over widely used GBDT models. We propose a realistic medical diagnosis benchmark for tabular transfer learning, and we present a how-to guide for using upstream data to boost performance with a variety of tabular neural network architectures. Finally, we propose a pseudo-feature method for cases where the upstream and downstream feature sets differ, a tabular-specific problem widespread in real-world applications. Our code is available at github.com/LevinRoman/tabular-transfer-learning.
https://arxiv.org/abs/2206.15306


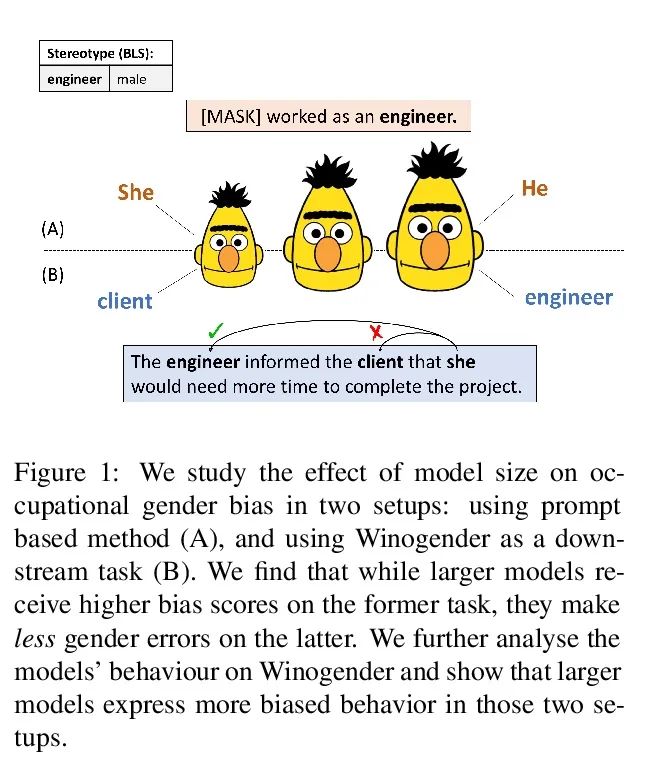
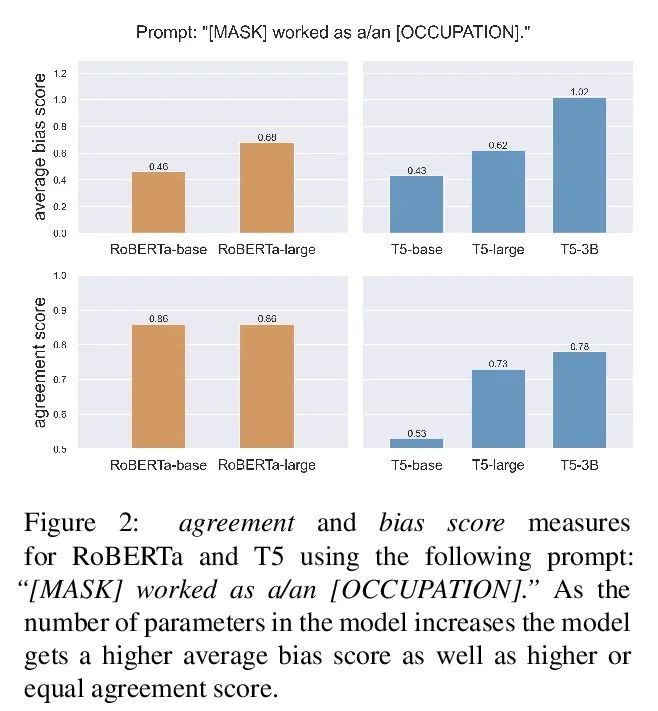
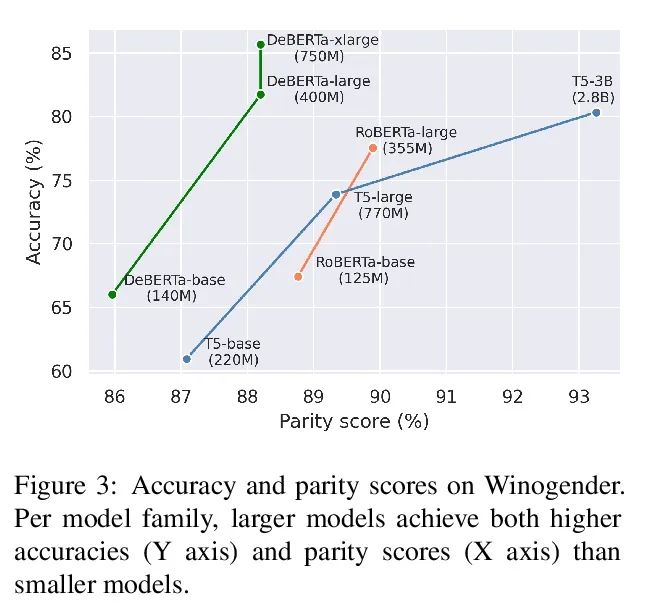
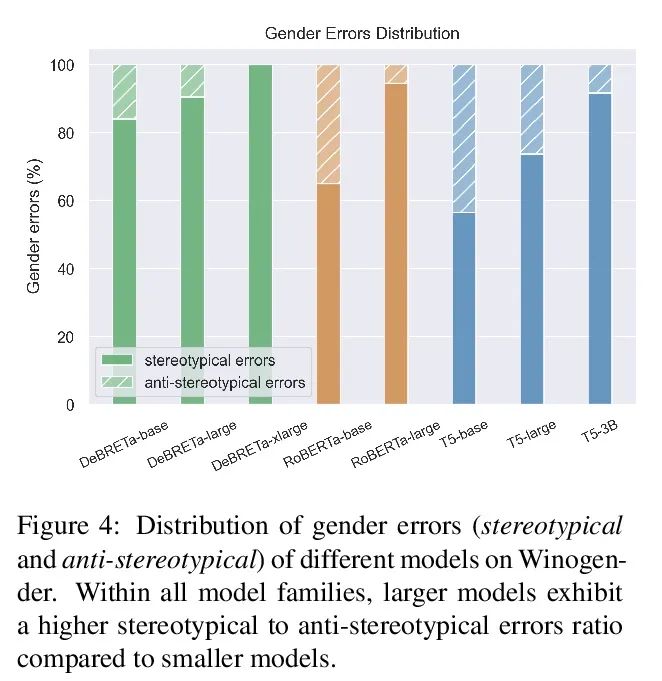
5、[CL] Fewer Errors, but More Stereotypes? The Effect of Model Size on Gender Bias
Y Tal, I Magar, R Schwartz
[The Hebrew University of Jerusalem]
错误越少,越刻板?模型大小对性别偏差的影响。预训练模型的规模在不断扩大,其在各种NLP任务上的表现也越来越好。然而,随着记忆能力的增长,与训练模型可能会接受更多的社会偏见。本文研究了模型规模和其性别偏差(特别是职业性别偏见)之间的联系。在两个设置中测量了三种掩码语言模型族(RoBERTa、DeBERTa和T5)的偏差:直接用基于提示的方法,以及采用下游任务(Winogender)。结果发现,一方面,较大的模型在前一个任务中显示出较高的偏差分数,但当在后者中评估时,其性别错误较少。为了研究这些可能冲突的结果,本文仔细调研了不同模型在Winogender上的行为。发现虽然大模型的表现优于小模型,但其错误是由性别偏差造成的概率更高。此外,与反性别偏差错误相比,刻板印象的比例随着模型的大小而增长。本文的发现强调了模型规模增大可能带来的潜在风险。
The size of pretrained models is increasing, and so is their performance on a variety of NLP tasks. However, as their memorization capacity grows, they might pick up more social biases. In this work, we examine the connection between model size and its gender bias (specifically, occupational gender bias). We measure bias in three masked language model families (RoBERTa, DeBERTa, and T5) in two setups: directly using prompt based method, and using a downstream task (Winogender). We find on the one hand that larger models receive higher bias scores on the former task, but when evaluated on the latter, they make fewer gender errors. To examine these potentially conflicting results, we carefully investigate the behavior of the different models on Winogender. We find that while larger models outperform smaller ones, the probability that their mistakes are caused by gender bias is higher. Moreover, we find that the proportion of stereotypical errors compared to antistereotypical ones grows with the model size. Our findings highlight the potential risks that can arise from increasing model size.
https://arxiv.org/abs/2206.09860

另外几篇值得关注的论文:
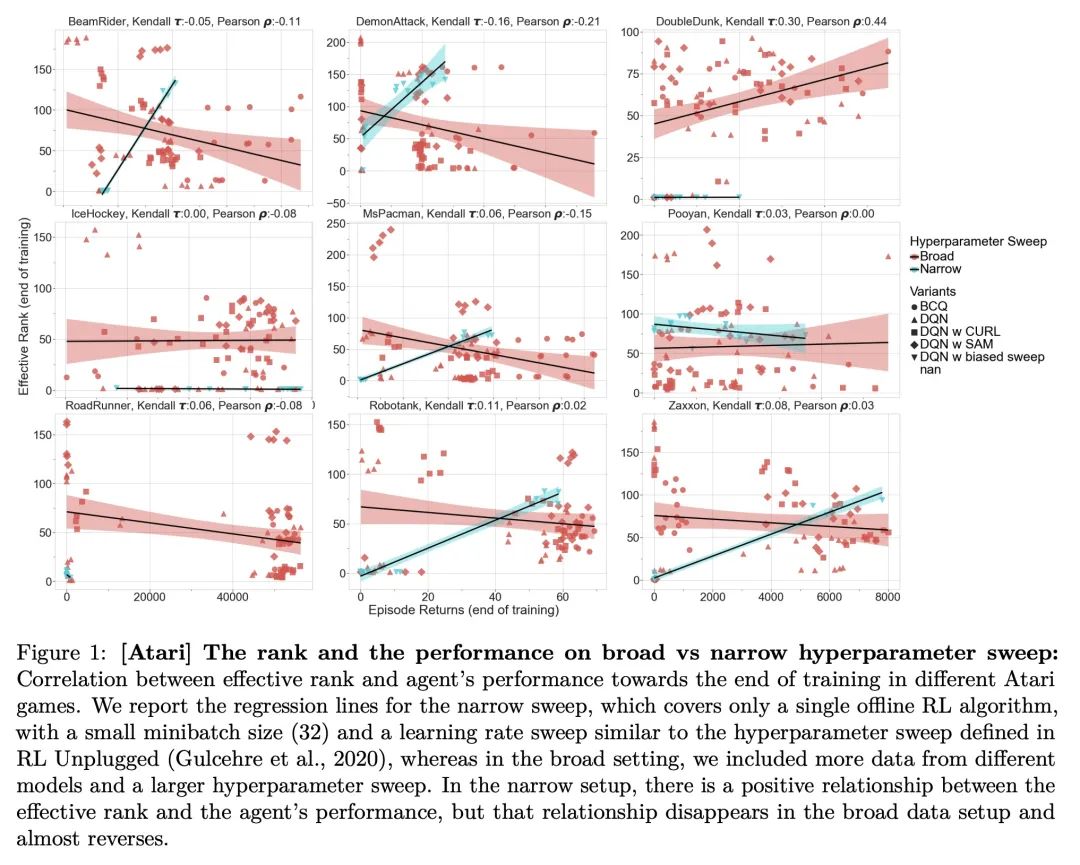
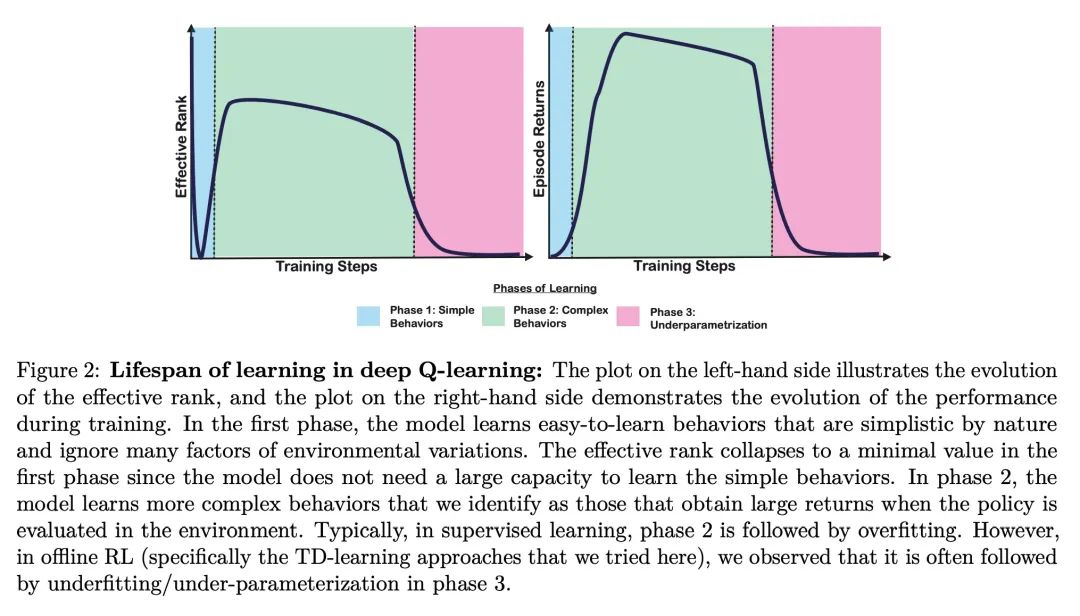
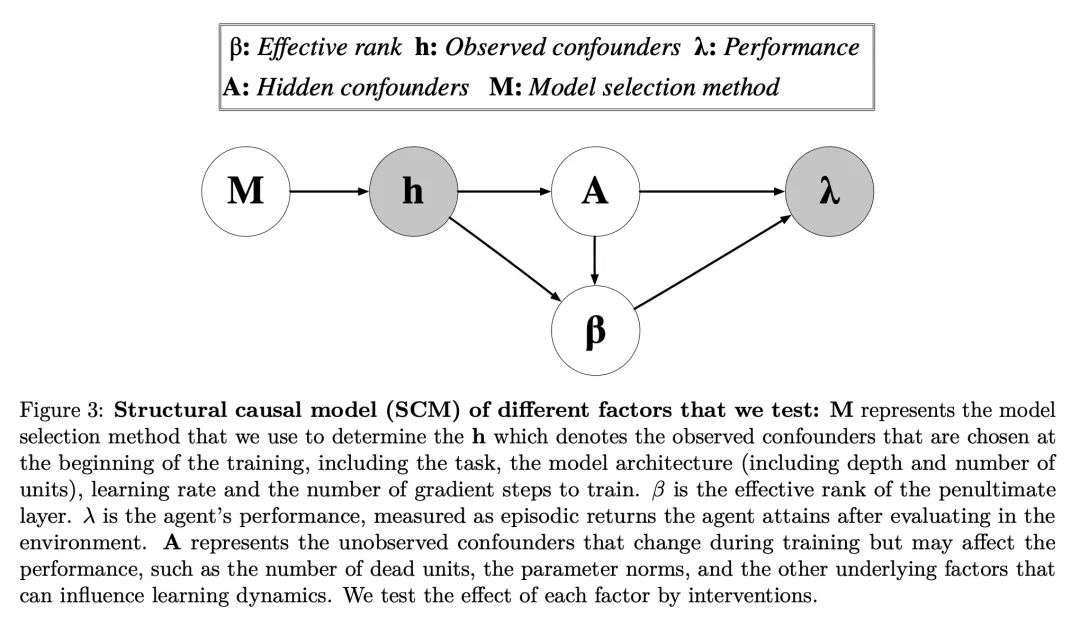
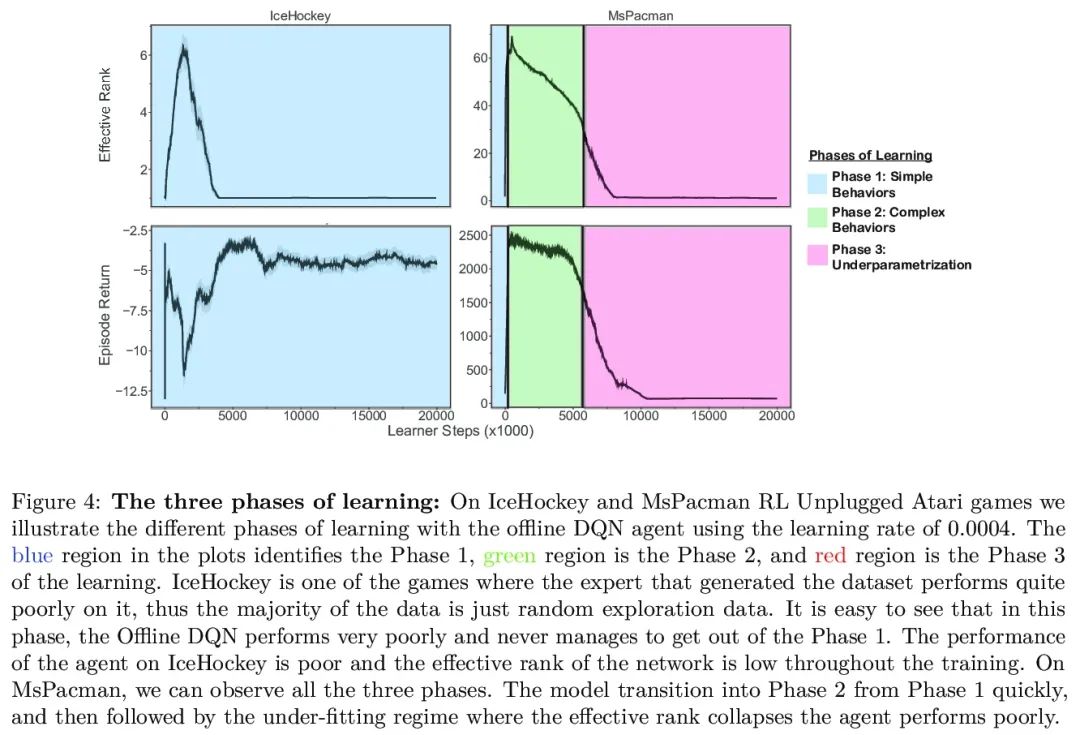
[LG] An Empirical Study of Implicit Regularization in Deep Offline RL
深度离线强化学习隐正则化实证研究
C Gulcehre, S Srinivasan, J Sygnowski, G Ostrovski, M Farajtabar, M Hoffman, R Pascanu, A Doucet
[DeepMind]
https://arxiv.org/abs/2207.02099

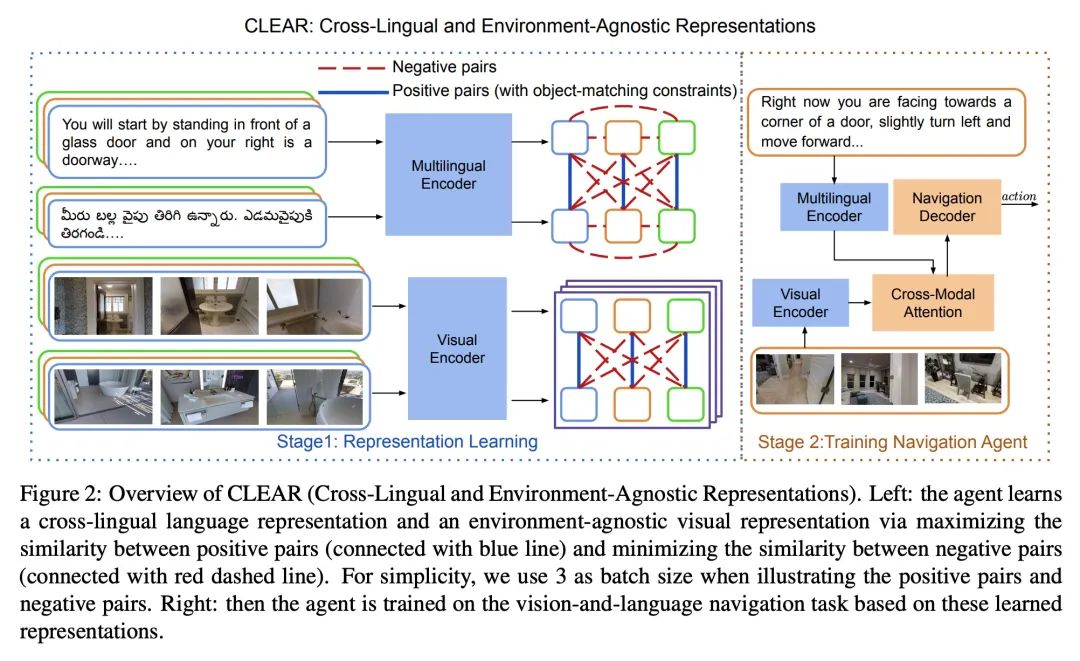
[CV] CLEAR: Improving Vision-Language Navigation with Cross-Lingual, Environment-Agnostic Representations
CLEAR:基于跨语言环境无关表示改进视觉语言导航
J Li, H Tan, M Bansal
[UNC Chapel Hill]
https://arxiv.org/abs/2207.02185




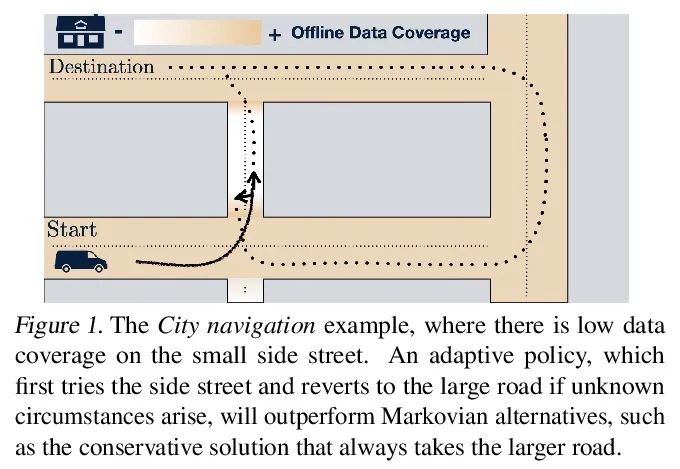
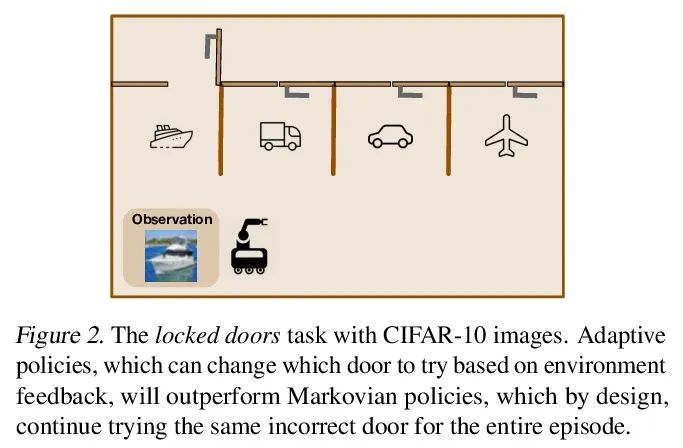
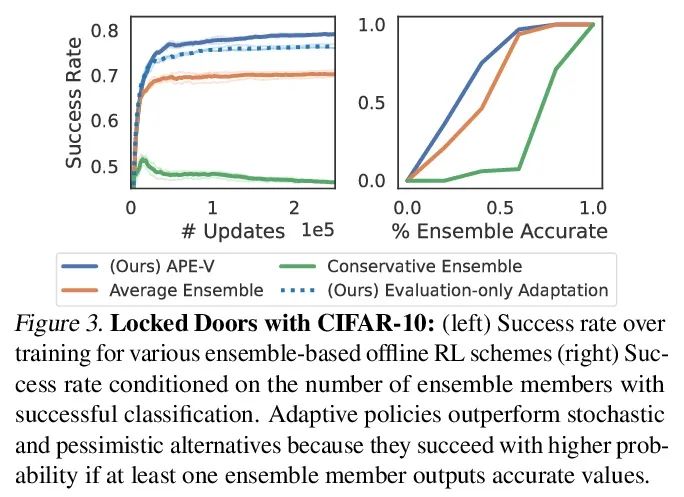
[LG] Offline RL Policies Should be Trained to be Adaptive
离线强化学习策略应训练增强自适应性
D Ghosh, A Ajay, P Agrawal, S Levine
[UC Berkeley & MIT]
https://arxiv.org/abs/2207.02200


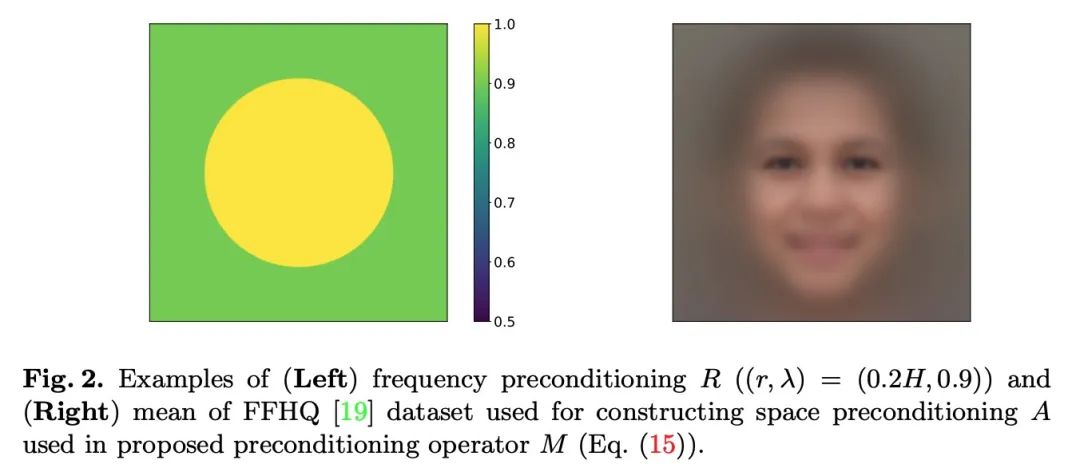
[CV] Accelerating Score-based Generative Models with Preconditioned Diffusion Sampling
基于预条件扩散采样加速基于分数生成模型
H Ma, L Zhang, X Zhu, J Feng
[Fudan University & University of Surrey]
https://arxiv.org/abs/2207.02196




边栏推荐
- 解密GD32 MCU产品家族,开发板该怎么选?
- SQL Lab (46~53) (continuous update later) order by injection
- College entrance examination composition, high-frequency mention of science and Technology
- Airserver automatically receives multi screen projection or cross device projection
- How to use PS link layer and shortcut keys, and how to do PS layer link
- 编译 libssl 报错
- Minimalist movie website
- Upgrade from a tool to a solution, and the new site with praise points to new value
- @Bean与@Component用在同一个类上,会怎么样?
- 百度数字人度晓晓在线回应网友喊话 应战上海高考英语作文
猜你喜欢
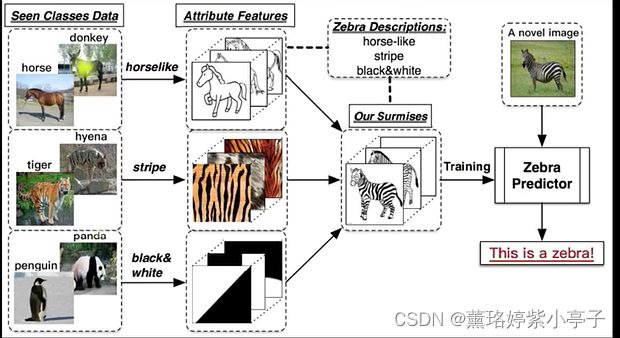
Zero shot, one shot and few shot

wallys/Qualcomm IPQ8072A networking SBC supports dual 10GbE, WiFi 6

对话PPIO联合创始人王闻宇:整合边缘算力资源,开拓更多音视频服务场景
Dialogue with Wang Wenyu, co-founder of ppio: integrate edge computing resources and explore more audio and video service scenarios
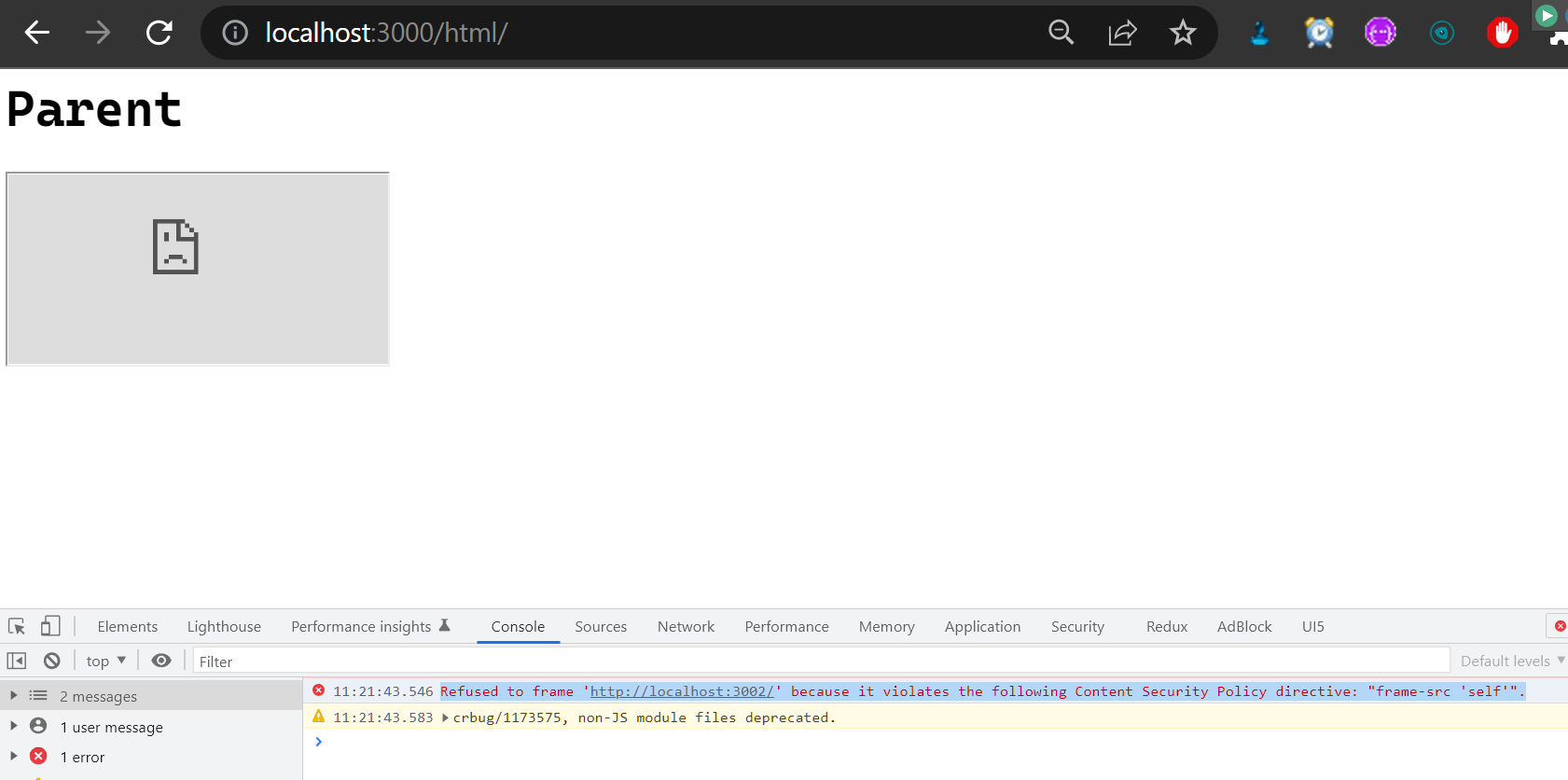
关于 Web Content-Security-Policy Directive 通过 meta 元素指定的一些测试用例

Learning and using vscode
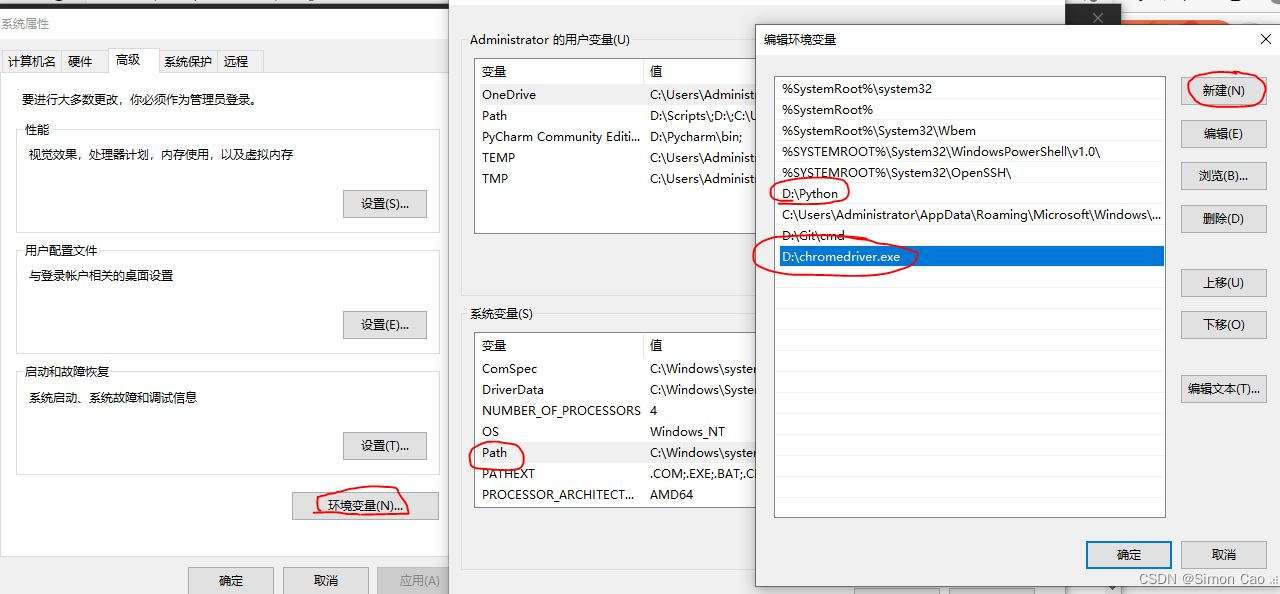
金融数据获取(三)当爬虫遇上要鼠标滚轮滚动才会刷新数据的网页(保姆级教程)
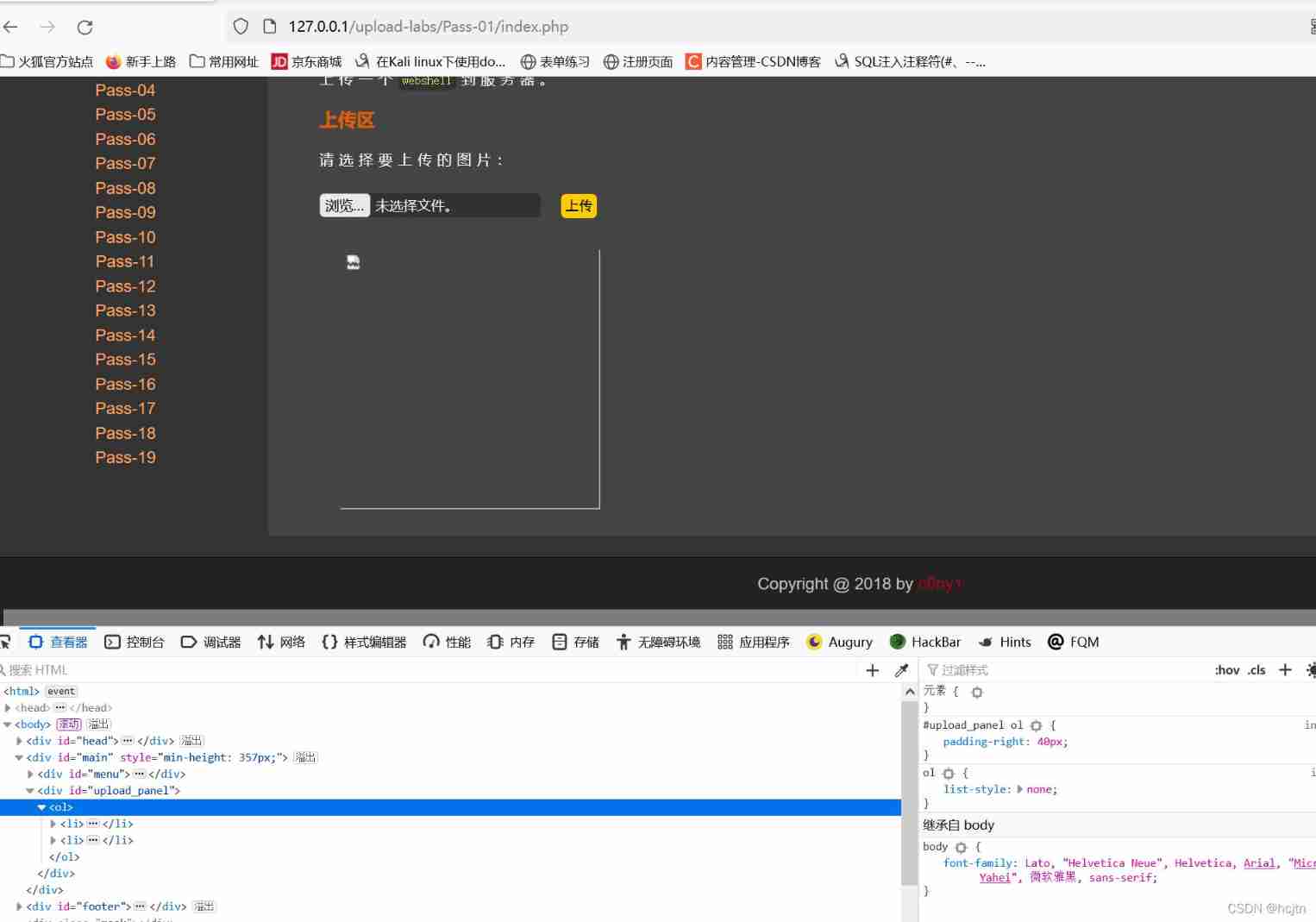
File upload vulnerability - upload labs (1~2)

The left-hand side of an assignment expression may not be an optional property access.ts(2779)

《通信软件开发与应用》课程结业报告
随机推荐
百度数字人度晓晓在线回应网友喊话 应战上海高考英语作文
跨域问题解决方案
盘点JS判断空对象的几大方法
<No. 9> 1805. 字符串中不同整数的数目 (简单)
《通信软件开发与应用》课程结业报告
Sonar:Cognitive Complexity认知复杂度
The left-hand side of an assignment expression may not be an optional property access.ts(2779)
SQL blind injection (WEB penetration)
Utiliser la pile pour convertir le binaire en décimal
如何理解服装产业链及供应链
小红书微服务框架及治理等云原生业务架构演进案例
TypeScript 接口继承
How much does it cost to develop a small program mall?
The road to success in R & D efficiency of 1000 person Internet companies
Baidu digital person Du Xiaoxiao responded to netizens' shouts online to meet the Shanghai college entrance examination English composition
什么是ESP/MSR 分区,如何建立ESP/MSR 分区
Simple network configuration for equipment management
利用栈来实现二进制转化为十进制
DOM parsing XML error: content is not allowed in Prolog
【PyTorch实战】用RNN写诗