当前位置:网站首页>Mongodb slow query optimization analysis strategy
Mongodb slow query optimization analysis strategy
2022-07-03 04:14:00 【Crocodile】
MongoDB Slow query analysis
- Turn on Profiling function , After it is enabled, relevant information will be collected on the running instance MongoDB Write operations for , The cursor , Database commands, etc , You can turn on the tool at the database level , It can also be turned on at the instance level .
The tool will write everything collected to system.profile Collection , The set is a capped collection http://docs.mongodb.org/manual/tutorial/manage-the-database-profiler/ - Inquire about system.profile Collection , Long query statements , For example, the execution exceeds 200ms Of
- Re pass
.explain()Number of rows affected by parsing , The analysis reason Optimize query statementsorAdd index
Turn on Profiling function
mongo shell In the open
Get into mongo shell, Enter the following command to start
db.setProfilingLevel(2);
Opening level description :
0: close , Don't collect any data .
1: Collect slow query data , The default is 100 millisecond .
2: Collect all the data
If you operate under a set , It is only effective for operations in this set
Set under all sets or start mongodb Set when , Then it will take effect for the entire instance
On at start up
mongod --profile=1 --slowms=200
Configuration file modification , Normal start
Add the following configuration in the configuration file :
profile = 1
slowms = 200
Other instructions
# Check the status : Level and time
db.getProfilingStatus()
# View levels
db.getProfilingLevel()
# Set the level and time
db.setProfilingLevel(1,200)
# close Profiling
db.setProfilingLevel(0)
# Delete system.profile aggregate
db.system.profile.drop()
# Create a new system.profile aggregate , The size is 1M
db.createCollection( "system.profile", {
capped: true, size:1000000 } )
# Re open Profiling
db.setProfilingLevel(1)
adopt system.profile Analyze
http://docs.mongodb.org/manual/reference /database-profiler/
adopt db.system.profile.find() Operation statements that can query records , Here's an example :
insertoperation
{
"op" : "insert",
"ns" : "Gps905.onlineTemp",
"command" : {
"insert" : "onlineTemp",
"ordered" : true,
"$db" : "Gps905"
},
"ninserted" : 1,
"keysInserted" : 1,
"numYield" : 0,
"locks" : {
"Global" : {
"acquireCount" : {
"r" : NumberLong(1),
"w" : NumberLong(1)
}
},
"Database" : {
"acquireCount" : {
"w" : NumberLong(1)
}
},
"Collection" : {
"acquireCount" : {
"w" : NumberLong(1)
}
}
},
"responseLength" : 60,
"protocol" : "op_query",
"millis" : 105,
"ts" : ISODate("2022-06-29T08:41:51.858Z"),
"client" : "127.0.0.1",
"allUsers" : [],
"user" : ""
}
The meanings of important fields are as follows
op: Operation type , Yes insert、query、update、remove、getmore、command
ns: Operational databases and collections
millis: Time spent in operation , millisecond
ts: Time stamp
If millis It's worth more , It needs to be optimized
- such as
queryExamples of operations
https://blog.csdn.net/weixin_34174105/article/details/91779187
{
"op" : "query", # Operation type , Yes insert、query、update、remove、getmore、command
"ns" : "onroad.route_model", # Set of operations
"query" : {
"$query" : {
"user_id" : 314436841,
"data_time" : {
"$gte" : 1436198400
}
},
"$orderby" : {
"data_time" : 1
}
},
"ntoskip" : 0, # Specify skip skip() Method Number of documents .
"nscanned" : 2, # In order to perform this operation ,MongoDB stay index Number of documents browsed in . Generally speaking , If nscanned The value is higher than nreturned Value , In order to find the target document, the database scans many documents . At this time, we can consider creating an index to improve efficiency .
"nscannedObjects" : 1, # In order to perform this operation ,MongoDB stay collection Number of documents browsed in .
"keyUpdates" : 0, # Number of index updates , Changing an index key has a small performance overhead , Because the database must delete the old key, And insert a new key To B- Tree index
"numYield" : 1, # The number of times the operation was abandoned in order for other operations to complete . Generally speaking , When they need to access data that has not been completely read into memory , The operation will abort . This makes it possible to MongoDB In order to abandon the operation while reading data , There are other operations of data in memory
"lockStats" : {
# Lock information ,R: A global read lock ;W: Global write lock ;r: Read locks for specific databases ;w: Write locks for specific databases
"timeLockedMicros" : {
# It takes time for this operation to acquire a level lock . For the operation of requesting multiple locks , For example, yes. local Database lock to update oplog , This value is longer than the total length of the operation ( namely millis )
"r" : NumberLong(1089485),
"w" : NumberLong(0)
},
"timeAcquiringMicros" : {
# The time spent waiting for this operation to acquire a level lock .
"r" : NumberLong(102),
"w" : NumberLong(2)
}
},
"nreturned" : 1, // Number of documents returned
"responseLength" : 1669, // Returns the length of bytes , If that's a big number , Consider the value to return the required field
"millis" : 544, # Time consumed ( millisecond )
"execStats" : {
# A document , It includes execution Inquire about The operation of , For other operations , This value is an empty file , system.profile.execStats Shows a statistical structure like a tree , Each node provides query operations in the execution phase .
"type" : "LIMIT", ## Use limit Limit the number of returns
"works" : 2,
"yields" : 1,
"unyields" : 1,
"invalidates" : 0,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"isEOF" : 1, # Whether it is the end of the file
"children" : [
{
"type" : "FETCH", # Search the specified... According to the index document
"works" : 1,
"yields" : 1,
"unyields" : 1,
"invalidates" : 0,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"isEOF" : 0,
"alreadyHasObj" : 0,
"forcedFetches" : 0,
"matchTested" : 0,
"children" : [
{
"type" : "IXSCAN", # Scan index keys
"works" : 1,
"yields" : 1,
"unyields" : 1,
"invalidates" : 0,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"isEOF" : 0,
"keyPattern" : "{ user_id: 1.0, data_time: -1.0 }",
"boundsVerbose" : "field #0['user_id']: [314436841, 314436841], field #1['data_time']: [1436198400, inf.0]",
"isMultiKey" : 0,
"yieldMovedCursor" : 0,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0,
"matchTested" : 0,
"keysExamined" : 2,
"children" : [ ]
}
]
}
]
},
"ts" : ISODate("2022-06-29T08:41:51.858Z"), # When does the command execute
"client" : "127.0.0.1", # link ip Or host
"allUsers" : [
{
"user" : "martin_v8",
"db" : "onroad"
}
],
"user" : ""
}
type Parameters of fields :
COLLSCAN # Full table scan
IXSCAN # An index scan
FETCH # Search the specified... According to the index document
SHARD_MERGE # Return the data of each segment to merge
SORT # Indicates that sorting is done in memory ( With the old version of scanAndOrder:true Agreement )
LIMIT # Use limit Limit the number of returns
SKIP # Use skip Go ahead and skip
IDHACK # in the light of _id The query
SHARDING_FILTER # adopt mongos Query fragment data
COUNT # utilize db.coll.explain().count() And so on count operation
COUNTSCAN #count Don't use Index Conduct count At the time of the stage return
COUNT_SCAN #count Used Index Conduct count At the time of the stage return
SUBPLA # Not used to index $or Of the query stage return
TEXT # When using full-text index for query stage return
PROJECTION # When the return field is limited stage Return
- If nscanned It's a big number , Or close to the total number of records ( Number of documents ), Then you may not use index queries , It's a full table scan .
- If nscanned The value is higher than nreturned Value , In order to find the target document, the database scans many documents . At this time, we can consider creating an index to improve efficiency .
Statements in filter criteria
# Return is greater than the 100 Millisecond slow operation
db.system.profile.find({
millis : {
$gt : 100 } } ).pretty()
# Go back to the nearest 10 Bar record {$natrual: -1} Represents the reverse order of the inserted number
db.system.profile.find().sort({
ts : -1 }).limit(10).pretty()
# Return all operations , except command Type of
db.system.profile.find( {
op: {
$ne : 'command' } }).pretty()
# Returns a specific collection
db.system.profile.find( {
ns : 'mydb.test' } ).pretty()
# Return information from a specific time frame
db.system.profile.find({
ts : {
$gt : new ISODate("2015-10-18T03:00:00Z"), $lt : new ISODate("2015-10-19T03:40:00Z")}}).pretty()
# At a certain time , Restrict users , Sort by time consumed
db.system.profile.find( {
ts : {
$gt : newISODate("2015-10-12T03:00:00Z") , $lt : newISODate("2015-10-12T03:40:00Z") } }, {
user : 0 } ).sort( {
millis : -1 } )
# View the latest Profile Record :
db.system.profile.find().sort({
$natural:-1}).limit(1)
# List recent 5 The execution time of article is longer than 1ms Of Profile Record
show profile
explain Analyze the execution statement
https://docs.mongodb.org/manual/reference/database-profiler/
Same as MySQL similar ,MongoDB There is also a explain Command to know how the system handles query requests .
Use explain command , Optimize for executing statements
SECONDARY> db.route_model.find({
"user_id" : 313830621, "data_time" : {
"$lte" : 1443715200, "$gte" : 1443542400 } }).explain()
{
"cursor" : "BtreeCursor user_id_1_data_time_-1", # Returns the cursor type , Yes BasicCursor and BtreeCursor, The latter means that the index is used .
"isMultiKey" : false,
"n" : 23, # Number of document lines returned .
"nscannedObjects" : 23, # This is a MongoDB The number of times to find the actual document on the disk according to the index pointer . If the query contains query criteria that are not part of the index , Or ask to return fields that are not in the index ,MongoDB You must find the document pointed to by each index entry in turn .
"nscanned" : 23, # If index is used , Then this number is the number of index entries searched , If this query is a full table scan , Then this number represents the number of documents checked
"nscannedObjectsAllPlans" : 46,
"nscannedAllPlans" : 46,
"scanAndOrder" : false, #MongoDB Whether the result set is sorted in memory
"indexOnly" : false, #MongoDB Whether the query can be completed only by using the index
"nYields" : 1, # In order to make the write request execute smoothly , The number of times this query was suspended . If there is a write request, it needs to be processed , Queries will periodically release their locks , So that the writing can be executed smoothly
"nChunkSkips" : 0,
"millis" : 1530, # The number of milliseconds taken by the database to execute this query . The smaller the number , The more efficient
"indexBounds" : {
# This field describes the usage of the index , The traversal range of the index is given
"user_id" : [
[
313830621,
313830621
]
],
"data_time" : [
[
1443715200,
1443542400
]
]
},
"server" : "a7cecd4f9295:27017",
"filterSet" : false,
"stats" : {
"type" : "FETCH",
"works" : 25,
"yields" : 1,
"unyields" : 1,
"invalidates" : 0,
"advanced" : 23,
"needTime" : 0,
"needFetch" : 0,
"isEOF" : 1,
"alreadyHasObj" : 0,
"forcedFetches" : 0,
"matchTested" : 0,
"children" : [
{
"type" : "IXSCAN",# The index is used here
"works" : 23,
"yields" : 1,
"unyields" : 1,
"invalidates" : 0,
"advanced" : 23,
"needTime" : 0,
"needFetch" : 0,
"isEOF" : 1,
"keyPattern" : "{ user_id: 1.0, data_time: -1.0 }",
"boundsVerbose" : "field #0['user_id']: [313830621.0, 313830621.0], field #1['data_time']: [1443715200.0, 1443542400.0]",
"isMultiKey" : 0,
"yieldMovedCursor" : 0,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0,
"matchTested" : 0,
"keysExamined" : 23,
"children" : [ ]
}
]
}
}
For analysis, please refer to appeal system.profile analysis
边栏推荐
- The longest subarray length with a positive product of 1567 recorded by leecode
- PostgreSQL database high availability Patroni source code learning - etcd class
- 在 .NET 6 项目中使用 Startup.cs
- Appium自动化测试框架
- Busycal latest Chinese version
- [Blue Bridge Road - bug free code] pcf8591 - code analysis of AD conversion
- xrandr修改分辨率与刷新率
- [Apple Push] IMessage group sending condition document (push certificate) development tool pushnotification
- [mathematical logic] predicate logic (predicate logic basic equivalent | eliminate quantifier equivalent | quantifier negative equivalent | quantifier scope contraction expansion equivalent | quantifi
- Half of 2022 is over, so we must hurry up
猜你喜欢

在 .NET 6 项目中使用 Startup.cs

Wechat applet + Alibaba IOT platform + Hezhou air724ug build a serverless IOT system (III) -- wechat applet is directly connected to Alibaba IOT platform aliiot

Appium automated testing framework
IPv6 foundation construction experiment
2022 P cylinder filling examination content and P cylinder filling practice examination video

【刷题篇】多数元素(超级水王问题)
![[brush questions] connected with rainwater (one dimension)](/img/21/318fcb444b17be887562f4a9c1fac2.png)
[brush questions] connected with rainwater (one dimension)
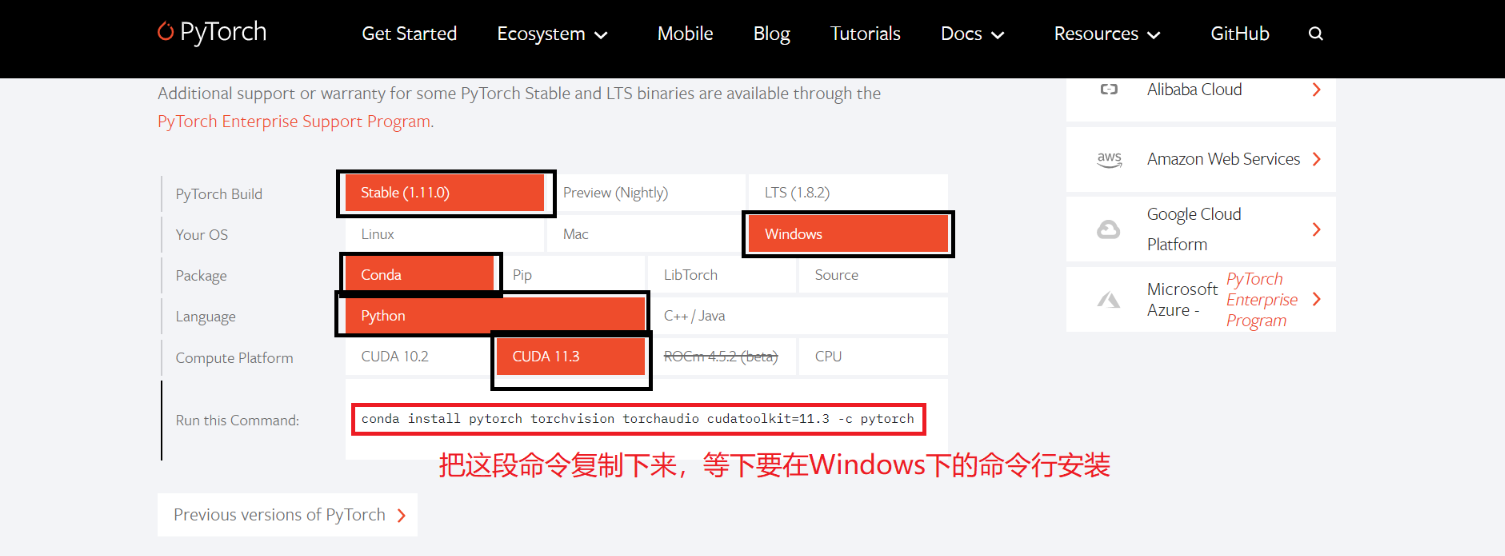
How to download pytorch? Where can I download pytorch?
Five elements of user experience

Nat. Comm. | use tensor cell2cell to deconvolute cell communication with environmental awareness
随机推荐
JS native common knowledge
Basic types of data in TS
树莓派如何连接WiFi
[set theory] set concept and relationship (true subset | empty set | complete set | power set | number of set elements | power set steps)
重绘和回流
2022deepbrainchain biweekly report no. 104 (01.16-02.15)
[brush questions] find the number pair distance with the smallest K
[Apple Push] IMessage group sending condition document (push certificate) development tool pushnotification
Mutex and rwmutex in golang
拆一辆十万元的比亚迪“元”,快来看看里面的有哪些元器件。
[mathematical logic] predicate logic (toe normal form | toe normal form conversion method | basic equivalence of predicate logic | name changing rules | predicate logic reasoning law)
Nodejs Foundation: shallow chat URL and querystring module
Is pytorch open source?
How to process the current cell with a custom formula in conditional format- How to address the current cell in conditional format custom formula?
js/ts底层实现双击事件
[NLP]—sparse neural network最新工作简述
nodejs基础:浅聊url和querystring模块
The longest subarray length with a positive product of 1567 recorded by leecode
Supervised pre training! Another exploration of text generation!
Taking two column waterfall flow as an example, how should we build an array of each column