当前位置:网站首页>UCORE LaB6 scheduler experiment report
UCORE LaB6 scheduler experiment report
2022-07-06 15:15:00 【Wuhu hanjinlun】
The experiment purpose
- Understand the scheduling management mechanism of the operating system
- be familiar with ucore System scheduler framework , And the default Round-Robin Scheduling algorithm
- Implement a based on the scheduler framework (Stride Scheduling) Scheduling algorithm to replace the default Scheduling Algorithm
Experimental content
Experiment 5 completed the user process management , Multiple processes can be run in user mode . But so far , The scheduling strategy adopted is very simple FIFO Scheduling strategy . This experiment , Mainly familiar ucore System scheduler framework , And based on this framework Round-Robin(RR) Scheduling algorithm . Then refer to RR Implementation of scheduling algorithm , complete Stride Scheduling Scheduling algorithm .
practice
practice 0: Fill in the existing experiment
This experiment relies on experiments 1/2/3/4/5. Please take your experiment 2/3/4/5 Fill in the code in this experiment. There are “LAB1”/“LAB2”/“LAB3”/“LAB4”“LAB5” The corresponding part of the notes . And ensure that the compilation passes . Be careful : In order to execute correctly lab6 Test application for , It may be necessary to test the completed experiments 1/2/3/4/5 Code for further improvements .
Use meld Comparison software , It is found that the following files need to be changed :
- proc.c
- default_pmm.c
- pmm.c
- swap_fifo.c
- vmm.c
- trap.c
The parts to be modified are as follows :trap.c Medium trap_dispatch function : The timer needs to be initialized where the clock is generated , be used for Scheduling algorithm
static void trap_dispatch(struct trapframe *tf)
{
.....
case IRQ_OFFSET + IRQ_TIMER:
ticks ++;
assert(current != NULL);
run_timer_list(); // Call this function to update the timer , And call the scheduling algorithm according to the parameters
break;
.....
}
run_timer_list Function is defined in sched.c in
proc.c Medium proc_struct Structure : Some member variables of user scheduling algorithm are added
static struct proc_struct * alloc_proc(void) {
......
// Lab6 newly added code
proc->rq = NULL; // The initialization run queue is empty
list_init(&(proc->run_link)); // Initialize the pointer of the run queue
proc->time_slice = 0; // Initialize time slice
proc->lab6_run_pool.left = proc->lab6_run_pool.right = proc->lab6_run_pool.parent = NULL;// Initialize all kinds of pointers to null , Including the parent process waiting
proc->lab6_stride = 0; // Process running progress initialization ( Aim at stride Scheduling algorithm , The same below )
proc->lab6_priority = 1; // Initialization priority
}
return proc;
}
Relevant explanations and definitions can be found in proc.h find :
struct run_queue *rq; // The pointer of the current process in the queue
list_entry_t run_link; // Pointer to the run queue
int time_slice; // Time slice
skew_heap_entry_t lab6_run_pool; // FOR LAB6 ONLY: the entry in the run pool
uint32_t lab6_stride; // Where has the representative implemented it now
uint32_t lab6_priority; // Process priority
Other files are copied directly to lab6 that will do
practice 1: Use Round Robin Scheduling algorithm ( No coding required )
Finish the exercise 0 after , I suggest you compare ( You can use kdiff3 Wait for file comparison software ) Completed by individuals lab5 And practice 0 Just revised after completion lab6 The difference between , Analysis and understanding lab6 use RR The execution process after Scheduling Algorithm . perform make grade, Most test cases should pass . But enforcement priority.c Should not pass .
Please complete in the experiment report :
- Please understand and analyze sched_class Usage of function pointers in , And combine Round Robin Scheduling algorithm description ucore Scheduling execution process
- Please briefly explain how to design and implement in the experiment report ” Multilevel feedback queue scheduling algorithm “, Give the outline design , Encourage detailed design
RR Scheduling algorithm execution process
So let's analyze this ucore How to achieve RR Algorithm :
Round Robin Scheduling algorithm : Let all runnable State processes are used in time-sharing and rotation CPU Time . The scheduler maintains the current runnable The orderly running queue of processes . After the time slice of the current process runs out , The scheduler places the current process at the end of the run queue , Then take out the process from its head for scheduling .
First , The scheduling in this experiment is based on the member function of scheduling class , The relevant definition is sched.h,sched_class Several member functions are defined , Wait a question 1 Will also analyze :
struct sched_class {
// The name of the scheduler
const char *name;
// Initialize the run queue
void (*init)(struct run_queue *rq);
// Process p Insert into the run queue q in
void (*enqueue)(struct run_queue *rq, struct proc_struct *proc);
// Process p From the run queue q Delete in
void (*dequeue)(struct run_queue *rq, struct proc_struct *proc);
// Return to the next executable process in the run queue
struct proc_struct *(*pick_next)(struct run_queue *rq);
// timetick Processing function of
void (*proc_tick)(struct run_queue *rq, struct proc_struct *proc);
};
In Experiment 6 , Implement a scheduling algorithm , You must have these five functions , To meet the scheduling class .
practice 1 Main analysis RR The execution process of scheduling algorithm .
RR The main implementation of the algorithm is default_sched.c In the definition of
The specific implementation process is as follows :
(1) First step : initialization rq Process queue for , And set the number of processes to zero , Specific in RR_init Function implementation :
static void RR_init(struct run_queue *rq) {
list_init(&(rq->run_list)); // Initialize the run queue
rq->proc_num = 0;
}
among ,struct run_queue Is defined as follows
struct run_queue {
list_entry_t run_list; // Process queue
unsigned int proc_num; // Number of processes
int max_time_slice; // Maximum time slice length (RR)
skew_heap_entry_t *lab6_run_pool;
// stay stride In the scheduling algorithm , in order to “ Slant pile ” A special process queue created by data structure , The essence is the process queue .
};
(2) The second step : Process queue operation : The process queue is a two-way linked list , When a process joins the queue , It will be added to the first place in the queue , And give it the initial number of time slices ; And update the number of processes in the queue , Specific in RR_enqueue Function implementation :
static void
RR_enqueue(struct run_queue *rq, struct proc_struct *proc)
{
// The process running queue cannot be empty
assert(list_empty(&(proc->run_link)));
// Put the process control block pointer to rq End of queue
list_add_before(&(rq->run_list), &(proc->run_link));
// If the process time slice runs out , Reset it to max_time_slice
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice) {
proc->time_slice = rq->max_time_slice;
}
proc->rq = rq;
rq->proc_num ++;
}
(3) The third step : Remove the process from the ready queue , And call it list_del_init Delete . meanwhile , Reduce the number of processes by one , Specific in RR_dequeue Function implementation :
static void
RR_dequeue(struct run_queue *rq, struct proc_struct *proc) {
assert(!list_empty(&(proc->run_link)) && proc->rq == rq);
list_del_init(&(proc->run_link)); // take proc Delete
rq->proc_num --;
}
(4) Step four : adopt list_next Function call , Will choose a process from the end of the team , Represents the process that should be executed at present . If you cannot select a process that is in a ready state , Then the return NULL, And give the execution right to the kernel thread idle,idle The function of is to constantly call schedule, Until the next executable process appears in the whole system , Specific in RR_pick_next Function implementation :
static struct proc_struct *
RR_pick_next(struct run_queue *rq) {
list_entry_t *le = list_next(&(rq->run_list));
if (le != &(rq->run_list))
{
return le2proc(le, run_link);
}
return NULL;
}
(5) Step five : Every time the time slice arrives , The time slice of the current execution process time_slice Then subtract one . If time_slice Down to zero , Then set the process member variable need_resched The label is 1, This will be executed after the next interrupt trap Function time , Because of the current process member variable need_resched The label is 1 And perform schedule function , Thus put the current execution process back to the end of the ready queue , From the ready queue header, the ready process that waits the longest on the ready queue is executed , Specific in RR_proc_tick Function implementation :
static void
RR_proc_tick(struct run_queue *rq, struct proc_struct *proc) {
if (proc->time_slice > 0) {
proc->time_slice --;
}
if (proc->time_slice == 0) {
proc->need_resched = 1;
}
}
(6) The first 6 Step : stay schedule When initializing , You need to fill in an initialization information , Then fill in the class function we implemented , Then the system can execute in this way :
struct sched_class default_sched_class = {
.name = "RR_scheduler",
.init = RR_init,
.enqueue = RR_enqueue,
.dequeue = RR_dequeue,
.pick_next = RR_pick_next,
.proc_tick = RR_proc_tick,
};
RR The execution process of the scheduling algorithm is as follows
Question answering
- Please understand and analyze sched_class Usage of function pointers in , And combine Round Robin Scheduling algorithm description ucore Scheduling execution process
sched_class The usage of each function pointer in has been analyzed in detail above , Now briefly review :
struct sched_class {
const char *name;// Scheduling class name
void (*init)(struct run_queue *rq);// Schedule queue initialization
void (*enqueue)(struct run_queue *rq, struct proc_struct *proc);// The team
void (*dequeue)(struct run_queue *rq, struct proc_struct *proc);// Out of the team
struct proc_struct *(*pick_next)(struct run_queue *rq);// Switch
void (*proc_tick)(struct run_queue *rq, struct proc_struct *proc);// Trigger
};
Let's combine Round Robin Scheduling algorithm to analyze ucore The process scheduling and execution process of the system .
- ucore call
sched_initThe function is used to initialize the related ready queue . - stay
proc_initFunction , Set up the first kernel process , And add it to the ready queue - When all initialization is complete ,ucore perform
cpu_idlefunction , And insidescheduleFunction , callsched_class_enqueueAdd the current process to the ready queue ( Because the current process will be switched out CPU 了 )
then , callsched_class_pick_nextGet ready queue can be rotated to CPU The process of . If there are available processes , Callsched_class_dequeuefunction , Remove the process from the ready queue , And execute it later proc_run Function to switch the process context . - It should be noted that , Every time the time is interrupted, the function will be called
sched_class_proc_tick. This function will reduce the remaining time slice of the current running process . If the time slice is reduced to 0, Is setneed_reschedby 1, And after the time interrupt routine is completed , staytrapProcess switching in the remaining code of the function .
Now answer the second question :
- Please briefly explain how to design and implement in the experiment report ” Multilevel feedback queue scheduling algorithm “, Give the outline design , Encourage detailed design
Multilevel feedback scheduling is a scheduling method that uses multiple scheduling queues , The biggest difference between it and multi-level queue scheduling is that processes can move between different scheduling queues , In other words, some strategies can be formulated to determine whether a process can be upgraded to a higher priority queue or downgraded to a lower priority queue . Through this algorithm, both high priority jobs and short jobs can be responded ( process ) make short shrift of sth . The core idea of multi-level feedback queue designed during implementation is : The time slice size increases as the priority level increases . meanwhile , The process is not completed in the current time slice Then it will be reduced to the next priority . Multiple queues can be maintained during implementation , Each new process joins the first queue , When you need to select a process to call in and execute , Search backwards from the first queue , Encountered a queue that is not empty , Then take a process out of this queue and call it in for execution . If the process transferred in from a queue still does not end after the time slice runs out , Then add this process to a queue after the queue in which it was transferred , And the time slice doubles .
Next, according to the book MLFQ And the above RR Scheduling algorithm to simple implementation MLFQ Algorithm
- Suppose the process has 3 A scheduling priority , Respectively 0、1、2, among 0 Bit highest priority ,2 Bit lowest priority . For support 3 Different priorities , Open in the run queue 3 A queue , Named as
rq -> run_list[0..3]. besides , stayproc_structAddpriorityMember indicates the priority of the process , Initialize to 0, That is, directly add the highest priority . - Process queue initialization , and RR The algorithm implementation is the same , The difference is that you need to initialize 3 A queue , They correspond to each other 0、1、2, Just slightly modify
RR_initFunction . - Judge proc Time slice of process proc -> time_slice Is it 0, If 0, be proc -> priority += 1, Explain that the process should be degraded , Otherwise unchanged . according to proc Add to the list of corresponding priorities . The length of the time slice is also related to the priority , The time slice length of low priority is set to twice that of high priority , Specific in
enqueueFunction implementation . - take proc The process is deleted from the corresponding priority run queue , and RR The algorithm is pretty much the same , stay
dequeueFunction implementation . - Select the next process to be executed by algorithm . Here, in order to avoid starvation of low priority processes , Can be set to high priority per process 100 After unit time , Low priority processing 30 Unit time Similar ideas . Use this method to avoid starvation of low priority processes , Specific in
pick_nextFunction implementation . - Every time the clock interrupts , Reduce the time slice of the current process . if 0, Then mark the process as requiring scheduling , and RR Similar algorithm , Specific in
proc_tickFunction implementation .
practice 2: Realization Stride Scheduling Scheduling algorithm ( Need to code )
First of all, it needs to be replaced RR Implementation of scheduler , The box default_sched_stride_c Cover default_sched.c. Then according to this file and subsequent documents Stride Relevant description of the calibrator , complete Stride Implementation of scheduling algorithm .
The following experimental documents give Stride General description of scheduling algorithm . Here is given Stride Some related information about scheduling algorithm ( At present, there is a lack of Chinese information on the Internet ).
- strid-shed paper location1
- strid-shed paper location2
- Can also be GOOGLE “Stride Scheduling” To find relevant information
perform :make grade. If the displayed application tests all output ok, Is basically correct . If it's just priority.c Can't get through , Executable make run-priority Command to debug it separately . See the appendix for the general implementation results .( It uses qemu-1.0.1 ).
Please briefly describe your design and implementation process in the experimental report .
Stride Introduction to scheduling algorithm
ucore Of Round-Robin The algorithm can ensure that each process gets CPU Resources are equal , But we hope that the scheduler can allocate reasonable for each process more intelligently CPU resources , Let the time resources obtained by each process be proportional to their priority . and Stride Scheduling Scheduling algorithm is such a typical and simple algorithm .
The algorithm has the following characteristics :
- Controllability : Can prove that Stride Scheduling The number of times a process is scheduled is proportional to its priority
- deterministic : Regardless of timer events , The whole scheduling mechanism is predictable and reproducible .
Two important variables of the algorithm :
- stride: Stride , Indicates the current scheduling right of the process . Each time you need to schedule, you have priority stride The process with the smallest value is scheduled . After each dispatch stride add pass.
- pass: Represents the number of steps forward each time . This value is only related to priority . Can make
P.pass =BigStride /P.priority, therefore pass Inversely proportional to priority . The time allocated to each process will be proportional to its priority , because pass The smaller it is, the more times it will be scheduled .
The basic idea of the algorithm is :
- Every runnable Set a current state for the process stride, Indicates the current scheduling right of the process . In addition, define its corresponding pass value , Indicates that the corresponding process is after scheduling ,stride The cumulative value needed .
- Every time you need to schedule , From the current runnable State in the process of choosing stride Minimal process scheduling .
- For processes that get scheduled P, The corresponding stride Add its corresponding step pass( It is only related to the priority of the process ).
- After a fixed period of time , go back to 2. step , Reschedule the current stride The smallest process .
Stride Implementation of algorithm
(1) First step : Compare
adopt comp function , Compare the current stride The smallest process , To schedule it , The specific implementation is as follows :
static int
proc_stride_comp_f(void *a, void *b)
{
struct proc_struct *p = le2proc(a, lab6_run_pool);
struct proc_struct *q = le2proc(b, lab6_run_pool);
int32_t c = p->lab6_stride - q->lab6_stride;// Subtract steps , Compare the size relationship through positive and negative
if (c > 0) return 1;
else if (c == 0) return 0;
else return -1;
}
The following steps are the same RR Algorithm is the same , Implement five functions
(2) The second step : initialization
The treatment here is the same as that before RR No difference between .
The only difference is , Initialize the process queue for lab6_run_pool( Experiment 6 process pool ) To operate , Because the data structure of slanted heap is used , In the code , The corresponding structure has been established for this variable , So we need to do this . If you still initialize rq, So because of rq It is based on bidirectional linked list , There will be some mistakes , The specific implementation is as follows :
static void
stride_init(struct run_queue *rq) {
/* LAB6: YOUR CODE */
list_init(&(rq->run_list));// Initialize the information of the scheduler class
rq->lab6_run_pool = NULL;// Initialize the current running queue to an empty container structure .
rq->proc_num = 0;// Set up rq->proc_num by 0
}
(3) The third step : The team
Initialize the process that just entered the run queue proc Of stride attribute , Then compare the team head element with the step size of the current process , Select the operation with the smallest number of steps , Insert it into the running queue , This is not placed at the head of the queue . Finally, initialize the time slice , Then add one to the number of running queue processes .
static void
stride_enqueue(struct run_queue *rq, struct proc_struct *proc) {
// take proc The corresponding heap is inserted into rq in
rq->lab6_run_pool = skew_heap_insert(rq->lab6_run_pool, &(proc->lab6_run_pool), proc_stride_comp_f);
// Update proc Time slice of
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice)
proc->time_slice = rq->max_time_slice;
// take proc Of rq Point to the general rq,rq Number of processes in +1
proc->rq = rq;
rq->proc_num++;
}
(4) Step four : Out of the team
When the process is moved from the run queue , You need to delete the process from the skew heap , And reduce the count of processes running the queue by one .
static void
stride_dequeue(struct run_queue *rq, struct proc_struct *proc) {
// take proc Remove... From the heap
rq->lab6_run_pool = skew_heap_remove(rq->lab6_run_pool, &(proc->lab6_run_pool), proc_stride_comp_f);
// take rq The number of processes minus 1
rq->proc_num--;
}
(5) Step five : Select process scheduling
Select the next process to schedule , Just choose stride The process with the smallest value is sufficient , So take the heap top process out , And restore the heap .
static struct proc_struct *
stride_pick_next(struct run_queue *rq)
{
if (rq->lab6_run_pool == NULL)
{
return NULL;
}
// Get the top element , And restore its heap
struct proc_struct *p = le2proc(rq->lab6_run_pool, lab6_run_pool);
// take p Of the corresponding process stride add pass value
p->lab6_stride += BIG_STRIDE / p->lab6_priority;
return p;
}
(6) Step six : Time slice
The function is used to process the clock , and RR Similar algorithm , If time slice Greater than 0, Then reduce the value by one . Otherwise, it is considered that its time slice is used up , Need to schedule .
static void
stride_proc_tick(struct run_queue *rq, struct proc_struct *proc)
{
if (proc->time_slice == 0)
{
proc->need_resched = 1;
}
else
{
--proc->time_slice;
}
}
After finishing the function , The original default_sched_class notes . use stride Scheduling class of Algorithm :
struct sched_class default_sched_class = {
.name = "stride_scheduler",
.init = stride_init,
.enqueue = stride_enqueue,
.dequeue = stride_dequeue,
.pick_next = stride_pick_next,
.proc_tick = stride_proc_tick,
};
function make qemu View the run results 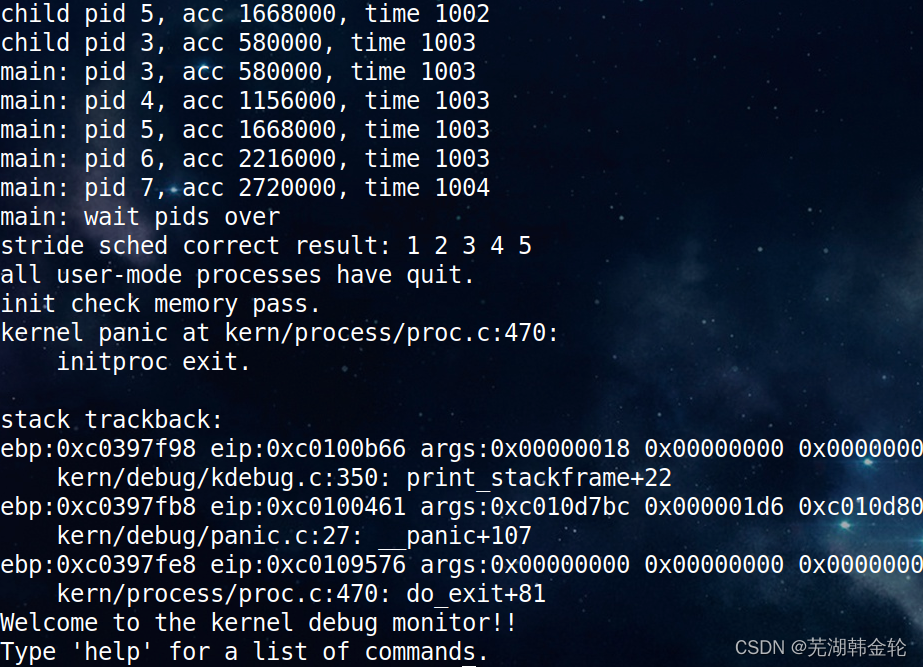
Run the command make grade Check your grades :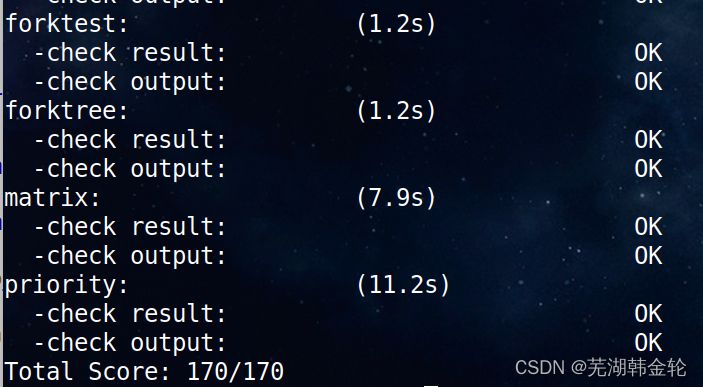
Extended exercises Challenge 1 : Realization Linux Of CFS Scheduling algorithm
stay ucore Under the scheduler framework of Linux Of CFS Scheduling algorithm . Can read related Linux Kernel books or query online materials , Can understand CFS The details of the , Then it is roughly realized in ucore in .
Let's start the experiment :
CFS The algorithm is to make the running time of each process as same as possible , Then record the running time of each process . Add an attribute to the process control block structure to indicate the running time . Every time you need to schedule , Select the process that has run the least time to call CPU perform .CFS Red black tree is widely used in the implementation of the algorithm , However, the implementation of red black tree is too complex and the heap has been implemented and can meet the requirements , Therefore, heap will be used here .
stay run_queue Add a heap , practice 2 Already used in skew_heap_entry_t * lab6_run_pool; Continue to use .
struct run_queue {
list_entry_t run_list;
unsigned int proc_num;
int max_time_slice;
// For LAB6 ONLY
skew_heap_entry_t *lab6_run_pool;
}
stay proc_struct Several variables are added to help complete the algorithm :
struct proc_struct {
....
//--------------- be used for CFS Algorithm --------------------------------------------------
int fair_run_time; // Virtual runtime
int fair_priority; // Priority factor : from 1 Start , The greater the numerical , The faster time goes
skew_heap_entry_t fair_run_pool; // Run the process pool
}
take proc During initialization, the three added variables are initialized together :
skew_heap_init(&(proc->fair_run_pool));
proc->fair_run_time = 0;
proc->fair_priority = 1;
The algorithm is realized :
Comparison function :proc_fair_comp_f, In fact, this function and exercise 2 Of stride In the algorithm comp The idea of function is consistent .
// Be similar to stride Algorithm , Here we need to compare the two processes fair_run_time
static int proc_fair_comp_f(void *a, void *b)
{
struct proc_struct *p = le2proc(a, fair_run_pool);
struct proc_struct *q = le2proc(b, fair_run_pool);
int c = p->fair_run_time - q->fair_run_time;
if (c > 0) return 1;
else if (c == 0) return 0;
else return -1;
}
initialization :
//init function
static void fair_init(struct run_queue *rq) {
// The process pool is empty , The process for 0
rq->lab6_run_pool = NULL;
rq->proc_num = 0;
}
Join the queue :
// Be similar to stride Dispatch
static void fair_enqueue(struct run_queue *rq, struct proc_struct *proc)
{
// take proc The corresponding heap is inserted into rq in
rq->lab6_run_pool = skew_heap_insert(rq->lab6_run_pool, &(proc->fair_run_pool), proc_fair_comp_f);
// Update proc Time slice of
if (proc->time_slice == 0 || proc->time_slice > rq->max_time_slice)
proc->time_slice = rq->max_time_slice;
proc->rq = rq;
rq->proc_num ++;
}
Out of line :
static void fair_dequeue(struct run_queue *rq, struct proc_struct *proc) {
rq->lab6_run_pool = skew_heap_remove(rq->lab6_run_pool, &(proc->fair_run_pool), proc_fair_comp_f);
rq->proc_num --;
}
Select the next process :
//pick_next, Select the top element
static struct proc_struct * fair_pick_next(struct run_queue *rq) {
if (rq->lab6_run_pool == NULL)
return NULL;
skew_heap_entry_t *le = rq->lab6_run_pool;
struct proc_struct * p = le2proc(le, fair_run_pool);
return p;
}
Need to update the virtual runtime , The amount of increase is the priority coefficient
// On every update , Update the virtual runtime to a priority related coefficient
static void
fair_proc_tick(struct run_queue *rq, struct proc_struct *proc) {
if (proc->time_slice > 0) {
proc->time_slice --;
proc->fair_run_time += proc->fair_priority;
}
if (proc->time_slice == 0) {
proc->need_resched = 1;
}
}
The operation results are as follows 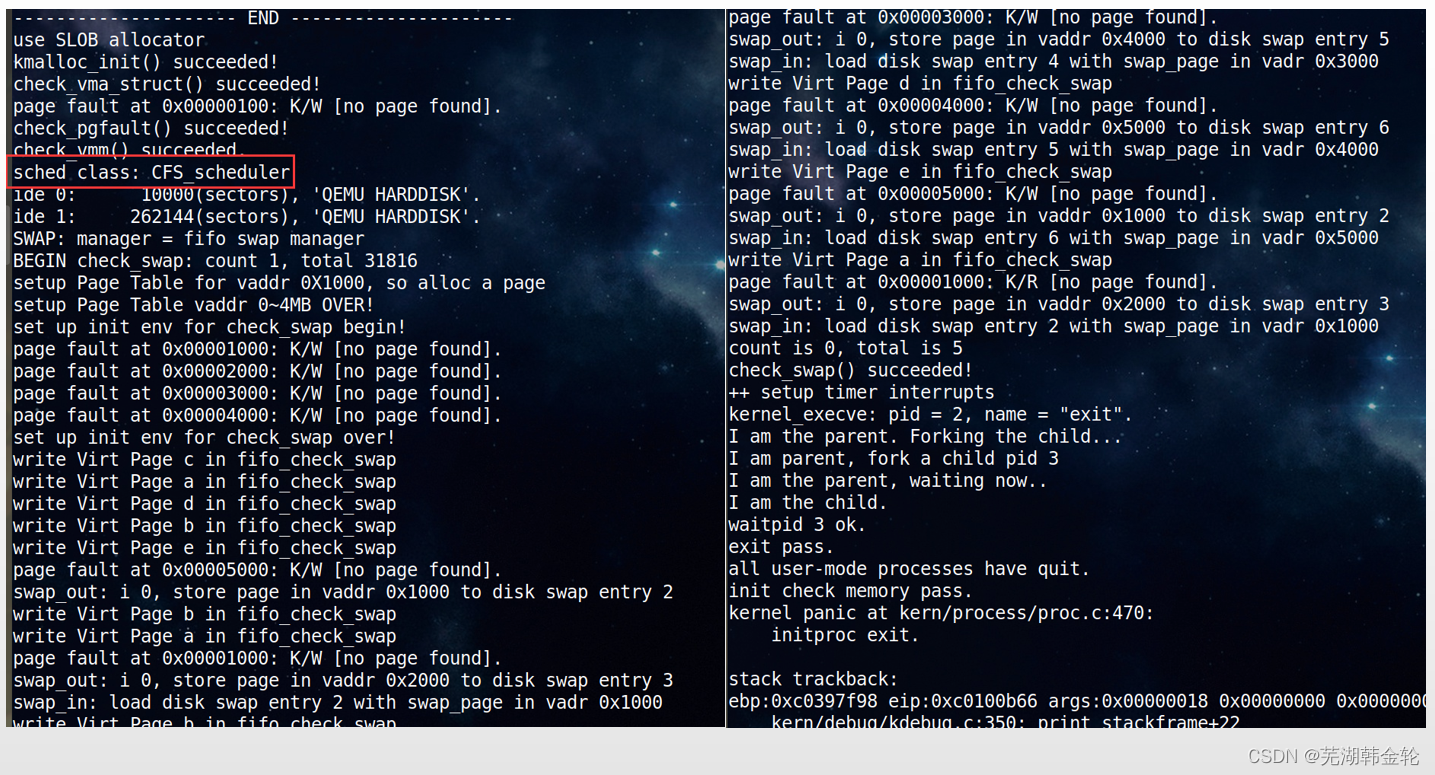
Extended exercises Challenge 2 : stay ucore Realize as many basic scheduling algorithms as possible (FIFO, SJF,…), And design various test cases , It can quantitatively analyze the differences of various scheduling algorithms in various indicators , Explain the scope of application of the scheduling algorithm .
Summary of the experiment
Through this experiment RR Dispatch and Stride Scheduling has a deeper learning and understanding , Through the acceptance and the questions of the teaching assistants, we can grasp this part more firmly , The implementation of these two scheduling algorithms is based on scheduling class quintuples : initialization 、 The team 、 Out of the team 、 Choose the next 、 Interrupt handling . The difference is that Stride Based on the idea of comparing step size and process execution progress , Require frequent comparisons Stride value , Therefore, the function suitable for inclined stack is selected , In terms of code , Not much difference . I believe that the content and harvest of this experiment will be of great help to future learning .
边栏推荐
- Rearrange spaces between words in leetcode simple questions
- Mysql database (III) advanced data query statement
- How to use Moment. JS to check whether the current time is between 2 times
- Should wildcard import be avoided- Should wildcard import be avoided?
- Mysql database (V) views, stored procedures and triggers
- Nest and merge new videos, and preset new video titles
- 遇到程序员不修改bug时怎么办?我教你
- Global and Chinese markets of Iam security services 2022-2028: Research Report on technology, participants, trends, market size and share
- MySQL数据库(一)
- Fundamentals of digital circuits (I) number system and code system
猜你喜欢
Login the system in the background, connect the database with JDBC, and do small case exercises

線程及線程池
Build your own application based on Google's open source tensorflow object detection API video object recognition system (II)
Video scrolling subtitle addition, easy to make with this technique

Servlet
CSAPP家庭作業答案7 8 9章

The minimum sum of the last four digits of the split digit of leetcode simple problem
How to rename multiple folders and add unified new content to folder names

Build your own application based on Google's open source tensorflow object detection API video object recognition system (I)
![Cadence physical library lef file syntax learning [continuous update]](/img/0b/75a4ac2649508857468d9b37703a27.jpg)
Cadence physical library lef file syntax learning [continuous update]
随机推荐
Threads and thread pools
软件测试Bug报告怎么写?
Statistics 8th Edition Jia Junping Chapter 1 after class exercises and answers summary
软件测试工作太忙没时间学习怎么办?
Example 071 simulates a vending machine, designs a program of the vending machine, runs the program, prompts the user, enters the options to be selected, and prompts the selected content after the use
Global and Chinese markets for GaN on diamond semiconductor substrates 2022-2028: Research Report on technology, participants, trends, market size and share
Fundamentals of digital circuits (III) encoder and decoder
Sleep quality today 81 points
DVWA exercise 05 file upload file upload
Thinking about three cups of tea
JDBC介绍
Global and Chinese markets of Iam security services 2022-2028: Research Report on technology, participants, trends, market size and share
Mysql的事务
Global and Chinese market of pinhole glossmeter 2022-2028: Research Report on technology, participants, trends, market size and share
MySQL development - advanced query - take a good look at how it suits you
Fundamentals of digital circuits (I) number system and code system
[200 opencv routines] 98 Statistical sorting filter
Pedestrian re identification (Reid) - Overview
Mysql database (II) DML data operation statements and basic DQL statements
Collection集合与Map集合