当前位置:网站首页>十二、排序
十二、排序
2022-07-07 06:37:00 【Dragon Fly】
文章目录
1、排序概述
\qquad 排序就是将一组杂乱无章的数据按照一定的规律顺次排列起来,即将无序序列排成有序序列(由小到大或者由大到小)的运算。如果参加排序的数据包含多个数据域,那么排序往往是针对某一个数据域而言的。
\qquad 排序方法的分类可以分为以下几类:
\qquad 按照存储介质可以分为内部排序和外部排序,内部排序:数据量不大,数据在内存,无需内外存交换数据;外部排序:数据量比较大,数据在外存。外部排序是,要将数据分批调入内存来排序,中间结果还要及时放入外存,显然外部排序要复杂的多。
\qquad 按照比较器的个数可以分为:串行排序:单处理机,同一时刻比较一对元素;和并行排序,多处理机,同一时刻比较多对元素。
\qquad 按照主要操作可以分为:比较排序,用比较的方法,如插入排序,交换排序,选择排序和归并排序等;基数排序,不比较元素的大小,仅仅根据元素本身的取值确定其有序位置。
\qquad 按照辅助空间可以分为原地排序,辅助空间用量为 O ( 1 ) O(1) O(1)的方法,所占的辅助存储空间与参加排序的数据量大小无关;非原地排序,辅助空间用量超过 O ( 1 ) O(1) O(1)的排序方法。
\qquad 按照稳定性可以分为:稳定排序,能够使任何数值相等的元素,排序之后相对次序不变;非稳定排序,不是稳定排序的方法。排序的稳定性只对数据类型数据排序有意义,例如:
\qquad 排序方法是否稳定,并不能衡量一个排序算法的优劣。
\qquad 按照自然性可以分为:自然排序,输入数据越有序,排序的速度越快的排序方法;非自然排序,不是自然排序的方法。
2、插入排序
\qquad 基本思想是:每一步将一个待排序的对象,按其关键码的大小,插入到前面已经排好序的一组对象的适当位置上,直到对象全部插入为止。即边插入边排序,保证子序列中随时都是排好序的。
\qquad 插入排序按照插入位置搜索的方法不同,可以分为以下几种类型:直接插入排序是使用顺序法定位插入位置;二分插入排序是使用二分法定位插入位置;希尔排序是使用缩小增量多遍插入排序。
2.1 直接插入排序
\qquad 直接插入排序的流程如下图所示:
\qquad 上述查找过程之中,每一次查找都要进行两次比较,即判断 j j j是否越界和比较值的大小,可以在序列的首部,0元素位置增加一个哨兵,从而无需进行越界判断:
\qquad 直接插入排序的算法流程如下所示:
void InsertSort(SqList &L){
for(int i = 2; i <= L.Length; ++i){
if(L.r[i].key < L.r[i-1].key){
L.r[0] = L.r[i]; //当前元素复制为哨兵
for(int j = i-1; L.r[0].key < L.r[j].key; --j)
L.r[j+1] = L.r[j]; //记录后移
L.r[j+1] = L.r[0]; //插入到正确位置
}
}
}
\qquad 算法复杂度分析:实现排序的基本操作有两个,“比较”序列中两个关键字的大小和“移动”记录。最好的情况下,关键在在记录序列中有序,比较的次数等于: ∑ i = 2 n 1 = n − 1 \sum_{i=2}^{n}1=n-1 ∑i=2n1=n−1,移动的次数为0。最坏情况下,关键字在记录序列中逆序有序,则比较的次数为: ∑ i = 2 n ( i − 1 ) = n ( n − 1 ) 2 \sum_{i=2}^{n}{(i-1)}=\frac{n(n-1)}{2} ∑i=2n(i−1)=2n(n−1),移动的次数为 ∑ i = 2 n ( i + 1 ) = ( n + 4 ) ( n − 1 ) 2 \sum_{i=2}^{n}{(i+1)}=\frac{(n+4)(n-1)}{2} ∑i=2n(i+1)=2(n+4)(n−1)。
\qquad 顺序插入排序,原始数据越接近有序,排序速度越快。最好情况下,输入数据时逆有序的,时间复杂度为 O ( n 2 ) O(n^2) O(n2),平均情况下,耗时差不多是最坏情况的一半。最好情况下的时间复杂度为 O ( 1 ) O(1) O(1)。空间复杂度为 O ( 1 ) O(1) O(1),是一个稳定的排序。
2.2 折半插入排序
\qquad 查找插入位置时使用折半查找法,叫做折半插入排序。折半插入法的流程如下所示:
void BInsertSort(SqList &L){
for(i = 2; i <= L.length; ++i){
L.r[0]=L.r[i];//将当前需要插入的元素放到哨兵位置
int low = 1, high = i-1; //采用二分查找法查找插入位置
while(low<=high){
mid = (low+high)/2;
if(L.r[0].key<L.r[mid].key)hight = mid-1;
else low = mid + 1;
}//循环结束时,high+1的位置则为插入位置
for(int j = i-1; j >= high+1; --j) L.r[j+1]=L.r[j];
L.r[high+1] = L.r[0];//插入到正确位置
}
}
\qquad 折半查找比顺序查找快,所以折半插入排序平均性能比直接插入排序快;并且折半插入排序所需要的关键码的比较次数与待排序的对象序列的初始排列无关,仅与对象个数有关。在插入第 i i i个对象时,需要经过 ⌊ l o g 2 i ⌋ + 1 \lfloor log_2^i \rfloor+1 ⌊log2i⌋+1次关键码的比较,才能确定插入位置。在n比较大时,总关键码的比较次数比直接插入排序的最坏情况好得多,单比最好情况要差。若需要排序对象的初始排序已经基本有序了,则直接插入排序比折半插入排序的时间效率要高。
\qquad 折半插入排序对象移动次数和直接插入排序相同,依赖于对象的初始排列;减少了比较次数,没有减少移动次数,平均性能优于直接插入排序。折半插入排序的时间复杂度为 O ( n 2 ) O(n^2) O(n2),空间复杂度为 O ( 1 ) O(1) O(1),是一种稳定的排序方法。
2.3 希尔排序
\qquad 在之前的直接插入排序和折半插入排序中,比较一次,只移动一步,希尔排序想要比较一次,移动一大步,从而减少移动的时间复杂度。希尔排序的基本思想:先将整个待排序的序列分割成若干个子序列,分别进行直接插入排序。待整个序列中的记录“基本有序”时,再对全体进行一次直接插入排序,所以希尔排序是一个缩小增量的多遍插入排序方法。希尔排序的思想如下所示:
\qquad 首先呢定义增量序列 D k : D M > D M − 1 > , . . . , > D 1 = 1 D_k: D_M>D_{M-1}>,...,>D_1=1 Dk:DM>DM−1>,...,>D1=1,之后对每个 D k D_k Dk进行 D k D_k Dk间隔插入排序,示意图如下所示: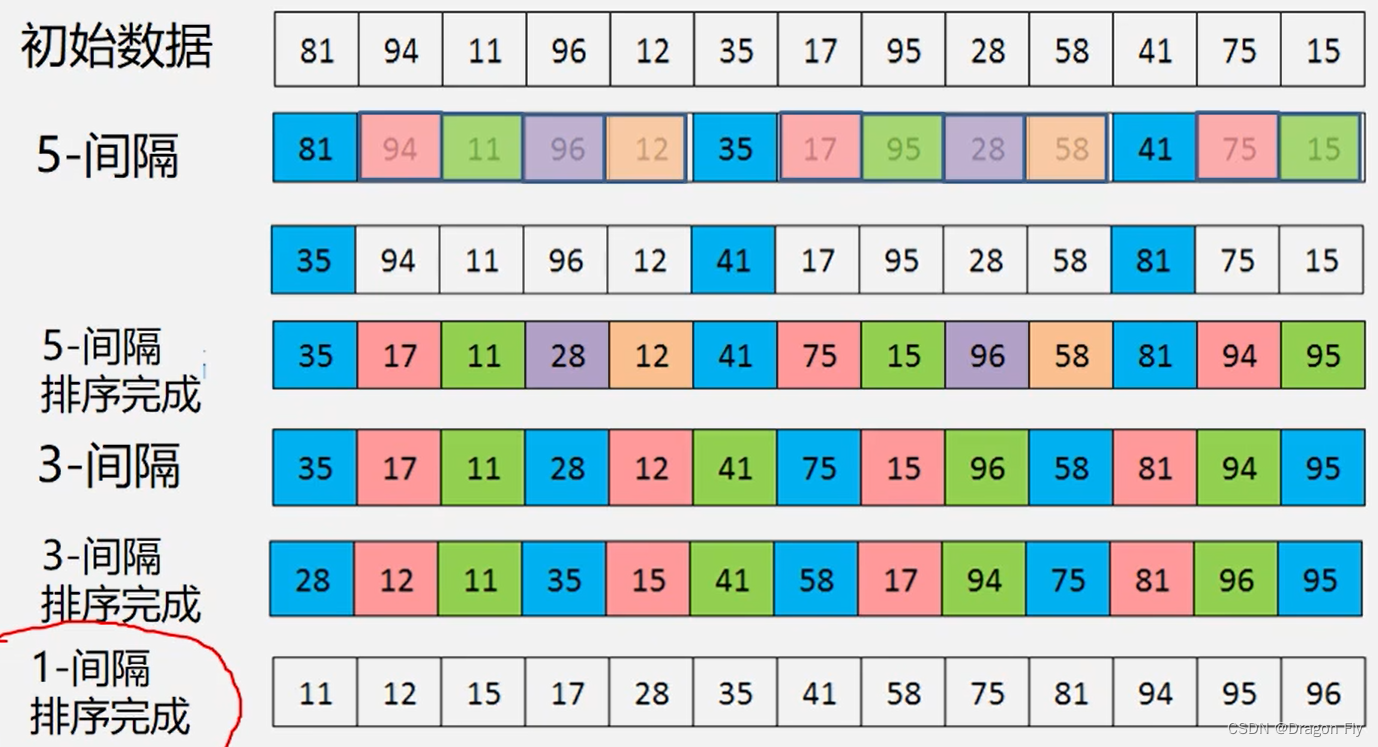
\qquad 希尔排序的增量序列应该是互为质数的。希尔排序的流程如下所示:
void ShellSort(SqList &L, int delta[], int t)
{
//按照增量序列delta[0,...,t-1]对顺序表L作希尔排序
for(int k = 0; k < t; ++k)
ShellInsert(L,delta[k]); //做一遍增量为delta[k]的插入排序
}
void ShellInsert(SqList &L, int dk){
for(int i = dk+1; i <=L.length; ++i){
if(L.r[i].key<L.r[i-dk].key){
L.r[0]=L.r[i];
for(int j = i-dk; L.r[0].key < L.r[j].key; j = j - dk){
L.r[j+dk] = L.r[j];
}
L.r[j+dk] = L.r[0];
}
}
}
\qquad 希尔排序的效率与增量序列的取值有关,
\qquad 希尔排序是一种不稳定的排序算法。希尔排序的空间复杂度为 O ( 1 ) O(1) O(1)。希尔排序的最佳增量序列尚未解决,但增量序列的最后一个增量值必须为1,所有增量之间必须没有除了1之外的其他公因子,同时希尔排序不适宜在链式存储结构上实现。
3、交换排序
3.1 冒泡排序
\qquad 冒泡排序数据交换排序的一种,交换排序的基本思想:两两比较,如果发生逆序则进行交换,直到所有记录都已经排好序为止。常见的交换排序方法:冒号排序 O ( n 2 ) O(n^2) O(n2),快速排序 O ( n l o n g n ) O(nlong_n) O(nlongn)。
\qquad 冒泡排序两两元素之间进行比较,若有n个元素,则需要比较n-1趟才能将所有的元素均排列成有序状态。第m趟需要比较n-m次。冒泡排序的流程如下所示:
void Bubble_sort(Sqlist &L)
{
int n = L.length;
for(int m = 0; m < n-1; ++m){
//总共需要比较n-1趟
for(int j = 0; j < n-m; ++j){
//每一趟需要比较n-m次
if(L.r[j] > L.r[j+1]){
//进行比较
RedType x = L.r[j];//交换
L.r[j] = L.r[j+1];
L.r[j+1] = x;
}
}
}
}
\qquad 一旦某一趟比较时没有出现元素交换,说明当前序列已经排好序了,就可以直接结束冒泡排序算法。基于这个思想,可以写出下述流程:
void Bubble_sort(Sqlist &L)
{
int n = L.length;
bool flag = true;
for(int m = 0; m < n-1 && flag == true; ++m){
//总共需要比较n-1趟
flag = false;
for(int j = 0; j < n-m; ++j){
//每一趟需要比较n-m次
if(L.r[j] > L.r[j+1]){
//进行比较
flag = true;
RedType x = L.r[j];//交换
L.r[j] = L.r[j+1];
L.r[j+1] = x;
}
}
}
}
\qquad 冒泡排序的时间复杂度,最好的情况下(序列本来就是正序的),需要比较次数为n-1,无需进行移动,这时间复杂度为 O ( n ) O(n) O(n)。最坏情况下(序列本来是逆序的),需要比较的次数为 ∑ i = 1 n − 1 ( n − i ) = 1 2 ( n 2 − n ) \sum_{i=1}^{n-1}(n-i)=\frac{1}{2}(n^2-n) ∑i=1n−1(n−i)=21(n2−n),移动次数为:发现一次比较逆序就要进行一次交换移动,需要3次赋值,所以移动次数为: 3 ∑ i = 1 n − 1 ( n − i ) = 3 2 ( n 2 − n ) 3\sum_{i=1}^{n-1}(n-i)=\frac{3}{2}(n^2-n) 3∑i=1n−1(n−i)=23(n2−n),所以冒泡排序最坏的时间复杂度为: O ( n 2 ) O(n^2) O(n2)。冒泡排序需要额外用到一个辅助空间,所以空间复杂度为 O ( 1 ) O(1) O(1),冒泡排序是一种稳定的排序。
3.2 快速排序
\qquad 快速排序的基本思想是一种递归的思想,首先在序列中任意选取一个元素,如第一个作为中心(pivot);之后将所有比中心元素小的元素放到它前面,将所有比中心元素大的元素放到它后面,这样形成两个子表;之后对于各个子表再重新选择中心元素并依据上述规则进行调整,直到每个子表的元素只剩一个。
\qquad 交换排序比较重要的部分是寻找中间点pivot的位置,寻找中间点位置的方法是从两头到中间的交替式逼近法: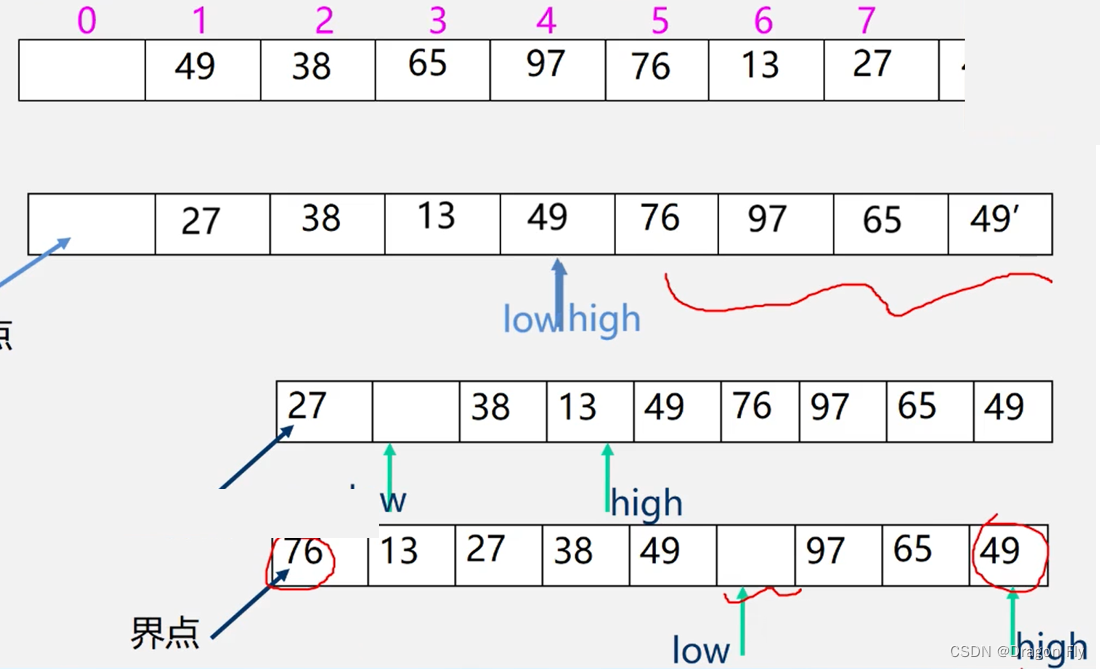
\qquad 之后对于每个子表的操作可以采用递归的算法。快速排序算法的流程如下所示:
void main(){
Qsort(L, 1, L.length);
}
void QSort(SqList &L, int low, int high){
if(low < high){
//若表长大于1
pivotLoc = Partition(L, low, high);//寻找pivot的位置,将表一份为二
QSort(L, low, pivotLoc - 1); //对低子表进行递归排序
QSort(L, pivotLoc - 1, high); //对高子表进行递归排序
}
}
int Partition(SqList &L, int low, int high){
L.r[0] = L.r[low];
int povotKey = L.r[low].key;
while(low<high){
while(low<high && L.r[high].key >= pivotKey) --high;//找一个小于中心点的值从后往前搬
L.r[low] = L.r[hgih];
while(low<high && L.r[low] <= pivotKey) ++low;//找一个大于中心点的值从前往后搬
L.r[high] = L.r[low];
}
L.r[low] = L.r[0];
return low;
}
\qquad 快速排序的时间复杂度为 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n),其中,递归调用的算法复杂度为 O ( l o g 2 n ) O(log_2n) O(log2n),寻找中心点的时间复杂度为 O ( n ) O(n) O(n),快速排序是内排序算法中最好的一个。
\qquad 快速排序不是原地排序,因为快速排序使用了递归的思想,需要调用系统栈的支持,栈的长度取决于递归调用的深度,在平均情况下需要 O ( l o g n ) O(logn) O(logn)的栈空间,最快情况下,栈空间可以达到 O ( n ) O(n) O(n)。快速排序是一种不稳定的排序方法。
\qquad 快速排序不适用于对原本有序或者基本有序的记录序列进行排序,这样的序列会使得快速排序的效率近似退化称为冒泡排序。划分元素的选取是影响快速排序时间性能的关键,输入数据的次序越乱,所选划分元素值的随机性越好,排序速度越快,所以快速排序不是自然排序的方法。改变元素的选取方法,最多只能改变算法平均情况下的时间性能,不能改变最坏情况下的时间性能,最坏情况下,快速排序的时间复杂度总是 O ( n 2 ) O(n^2) O(n2)。
4、选择排序
4.1 简单选择排序
\qquad 简单选择排序的基本思想是:在待排序的数据中选出最大(小)的元素放在其最终位置。简单排序算法的流程如下所示:
void SelectSort(SqList &L){
for(int i = 1; i < L.length; ++i){
int k = i;
for(int j = i+1; j <= L.length; ++j){
if(L.r[j].key < L.r[k].key) k = j;//记录最小值的位置
}
if(k!=i){
int t = L.r[i];
L.r[i] = L.r[k];
L.r[k] = t;//交换
}
}
}
\qquad 简单选择排序在最好情况下的移动次数为0,最坏情况下的移动次数为 3 ( n − 1 ) 3(n-1) 3(n−1)。对于比较次数,无论序列处于什么状态,比较次数都是相同的 ∑ i = 1 n − 1 ( n − i ) = n ( n − 1 ) 2 \sum_{i=1}^{n-1}(n-i)=\frac{n(n-1)}{2} ∑i=1n−1(n−i)=2n(n−1)。所以简单选择排序的时间复杂度为 O ( n 2 ) O(n^2) O(n2),空间复杂度为 O ( 1 ) O(1) O(1)。简单选择排序是不稳定的排序。
4.2 堆排序
\qquad 堆的定义: 若n个元素的序列 { a 1 , a 2 , . . . , a n } \{a_1, a_2, ..., a_n\} { a1,a2,...,an}满足 { a i ≤ a 2 i a i ≤ a 2 i − 1 \begin{cases} a_i \leq a_{2i}\\ a_{i} \leq a_{2i-1}\end{cases} { ai≤a2iai≤a2i−1则称序列为小根堆;若满足 { a i ≥ a 2 i a i ≥ a 2 i − 1 \begin{cases} a_i \geq a_{2i}\\ a_{i} \geq a_{2i-1}\end{cases} { ai≥a2iai≥a2i−1则称序列为大根堆。
\qquad 从堆的定义来看,堆实质是满足“二叉树中任一非叶子节点均小于(大于)它的孩子结点”的完全二叉树。
\qquad 对排序的基本方法:若在输出堆顶的最小值之后,使得剩余 n − 1 n-1 n−1个元素的序列重新又建成一个堆,则得到n个元素的次小值(次大值)… …如此反复,便能得到一个有序序列,这个过程称之为对排序。
4.2.1 调整剩余元素为新的堆
\qquad 将小根堆输出堆顶元素之后,剩余元素调整称为新的堆的过程如下所示:在输出堆顶元素之后,用堆中最后一个元素代替之;之后将根结点的值与左、右子树的根节点值进行比较,并与其中的小者进行交换;重复上述操作,直至到叶子节点,将得到新的堆,称这个从堆顶到叶子的调整过程为“筛选”。筛选过程的代码如下所示:
void HeapAdjust(int R[], int length, int s){
int rc = R[s];
for(int j = 2*s; j < length; ++j){
if(j + 1 < length && R[j] < R[j+1])++j;
if(rc >= R[j]) break;//找到rc应该插入的位置
R[s] = R[j];//rc的位置不断往下移动
s = j;
}
R[s] = rc;//将rc插入到最终找到的rc的位置上
}
\qquad 所以,对于一个无序的序列,进行反复筛选只有便可以得到一个堆。从最后一个非叶子结点开始,向前调整,依次调整 n / 2 , n / 2 − 1 , n / 2 − 2 , . . . , n / 2 − ( n / 2 − 1 ) n/2, n/2-1, n/2-2, ... , n/2-(n/2-1) n/2,n/2−1,n/2−2,...,n/2−(n/2−1)的子树,直到所有数均为大根堆或者小根堆为止。无需序列进行调整的代码如下所示:
void AllHeapAdjust(int R[], int length, int s){
for(int i = n/2; i >= 1; --i)
HeapAdjust(R, length, i);
}
\qquad 整个堆排序算法的流程如下所示:
void HeapSort(int R[]){
int i = 0;
for(int i = n/2; i >= 1; --i)
HeapAdjust(R, i, n);//建立初始堆
for(int i = n; i > 1; --i){
Swap(R[1], R[i]);//根与最后一个元素进行交换
HeapAdjust(R, 1, i - 1);//对R[1]到R[i-1]重新建立堆
}
}
\qquad 对于堆排序来说,最坏最坏情况下的时间复杂度均为 O ( n l o g n ) O(nlogn) O(nlogn)。堆排序的空间复杂度为 O ( 1 ) O(1) O(1),同时堆排序是不稳定的排序方式。
5、归并排序
\qquad 归并排序的基本思想是:将两个或者两个以上的有序子序列“归并”成一个有序序列。在内部排序中,通常采用2-路归并排序,即将两个位置相邻的有序子序列 R [ 1 , . . . , m ] R[1,...,m] R[1,...,m]和 R [ m + 1 , . . . , n ] R[m+1,...,n] R[m+1,...,n]归并成一个有序序列 R [ 1 , . . . , n ] R[1,...,n] R[1,...,n]。2-路归并排序的示意如下图所示: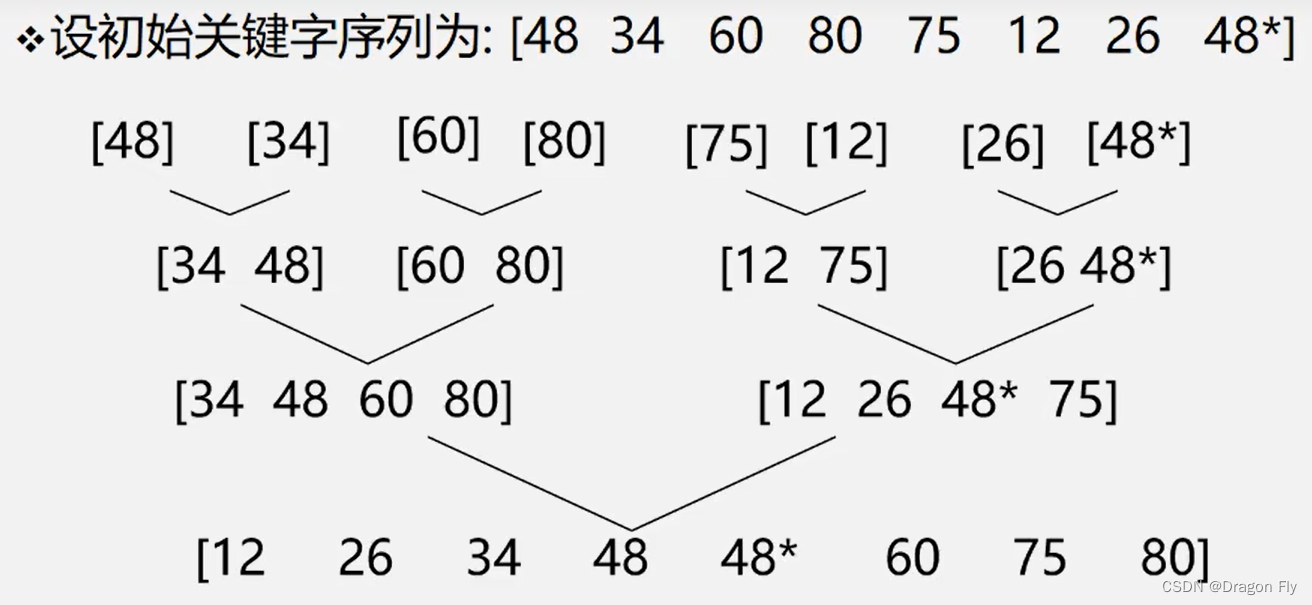
\qquad 有 n n n个元素的序列最多需要合并的次数为 l o g 2 n log_2n log2n。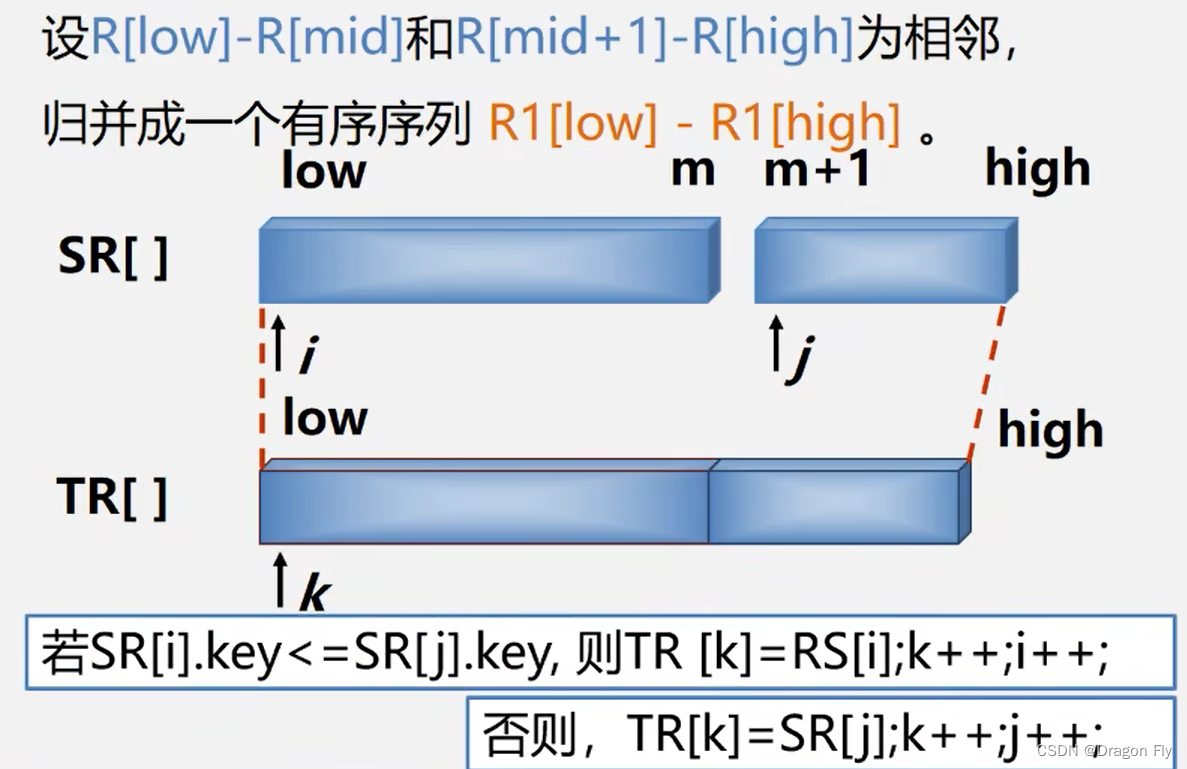
\qquad 归并排序的时间效率为 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n);空间效率为 O ( n ) O(n) O(n),因为归并排序需要一个与原始序列同样大小的辅助序列;归并排序是一个稳定排序。
6、基数排序
\qquad 基数排序的基本思想是:分配+收集。基数排序也叫桶排序或者箱排序,首先设置若干个箱子,将关键字为k的记录放入到第k个箱子中,然后再按序号将非空的箱子进行连接;
\qquad 基数排序要求数字是有范围的,均由0-9这是个数字组成,则只需要设置十个箱子,相继按照个,十,百…进行排序。基数排序的实例如下所示,首先将所有数字以个位数为关键字扔到不同的箱子中,之后依次将各个箱子中的数字进行收集;第二次将所有数字以十位数为关键字扔到不同的箱子中,之后依次将各个箱子中的数字进行收集;第三次将所有数字以百位数为关键字扔到不同的箱子中,之后依次将各个箱子中的数字进行收集… …
\qquad 基数排序的时间效率为: O ( k ∗ ( n + m ) ) O(k*(n+m)) O(k∗(n+m)),其中 k k k表示关键字的个数, m m m表示关键字取值范围为 m m m个值。基数排序的空间效率为 O ( n + m ) O(n+m) O(n+m),基数排序是一种稳定的排序方法。
7、各种排序方法的比较
\qquad 按照平均时间性能来分,
\qquad 时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)的方法有:快速排序,堆排序和归并排序,其中以快速排序为最好;
\qquad 时间复杂度为 O ( n 2 ) O(n^2) O(n2)的方法有:直接插入排序,冒泡排序和简单选择排序,其中以直接插入排序为最好,特别是对于关键字近似有序的记录序列尤为如此;
\qquad 时间复杂度为 O ( n ) O(n) O(n)的方法只有基数排序。
\qquad 简单选择排序,堆排序和归并排序的时间性能不随记录序列中关键字的分布而改变。
\qquad 按照平均空间性能来分,
\qquad 所有简单的排序方法,如直接插入,冒泡排序,简单选择排序和堆排序的空间复杂度为 O ( 1 ) O(1) O(1)
\qquad 快速排序基于递归的思想,需要用到栈的辅助空间,空间复杂度为 O ( l o g n ) O(logn) O(logn)
\qquad 归并排序所需辅助空间较多,空间复杂度为 O ( n ) O(n) O(n)
\qquad 基于线性表的基数排序所需辅助空间最多,为 O ( n + m ) O(n+m) O(n+m)
\qquad 所有排序方法的比较如下表所示: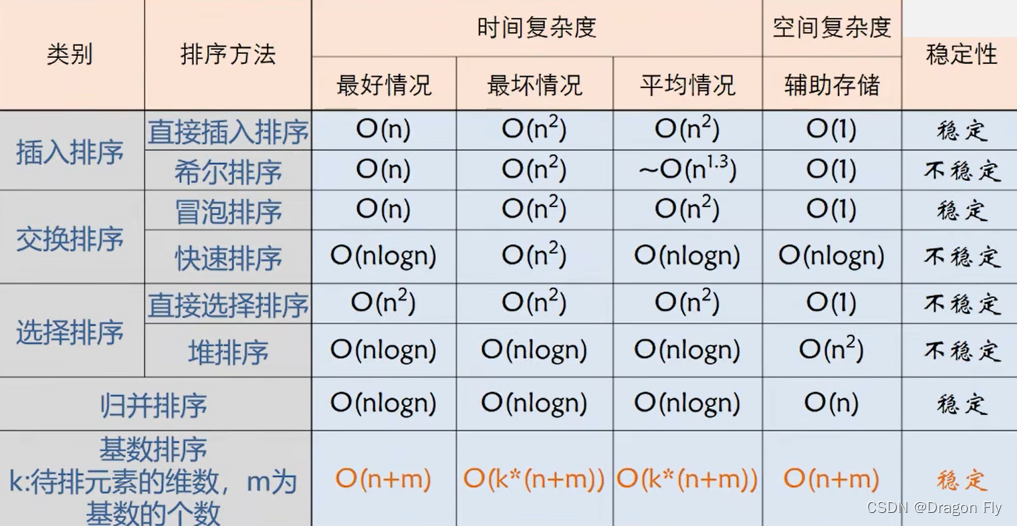
THE END
边栏推荐
- Simulation volume leetcode [general] 1705 The maximum number of apples to eat
- Led analog and digital dimming
- JVM 内存结构 详细学习笔记(一)
- Locust performance test 5 (analysis)
- Idea development environment installation
- UnityShader入门精要个人总结--基础篇(一)
- Storage of data in memory
- STM32 serial port register library function configuration method
- 硬件大熊原创合集(2022/06更新)
- Leetcode question brushing record (array) combination sum, combination sum II
猜你喜欢
![Pytest+request+allure+excel interface automatic construction from 0 to 1 [familiar with framework structure]](/img/33/9fde4bce4866b988dd2393a665a48c.jpg)
Pytest+request+allure+excel interface automatic construction from 0 to 1 [familiar with framework structure]
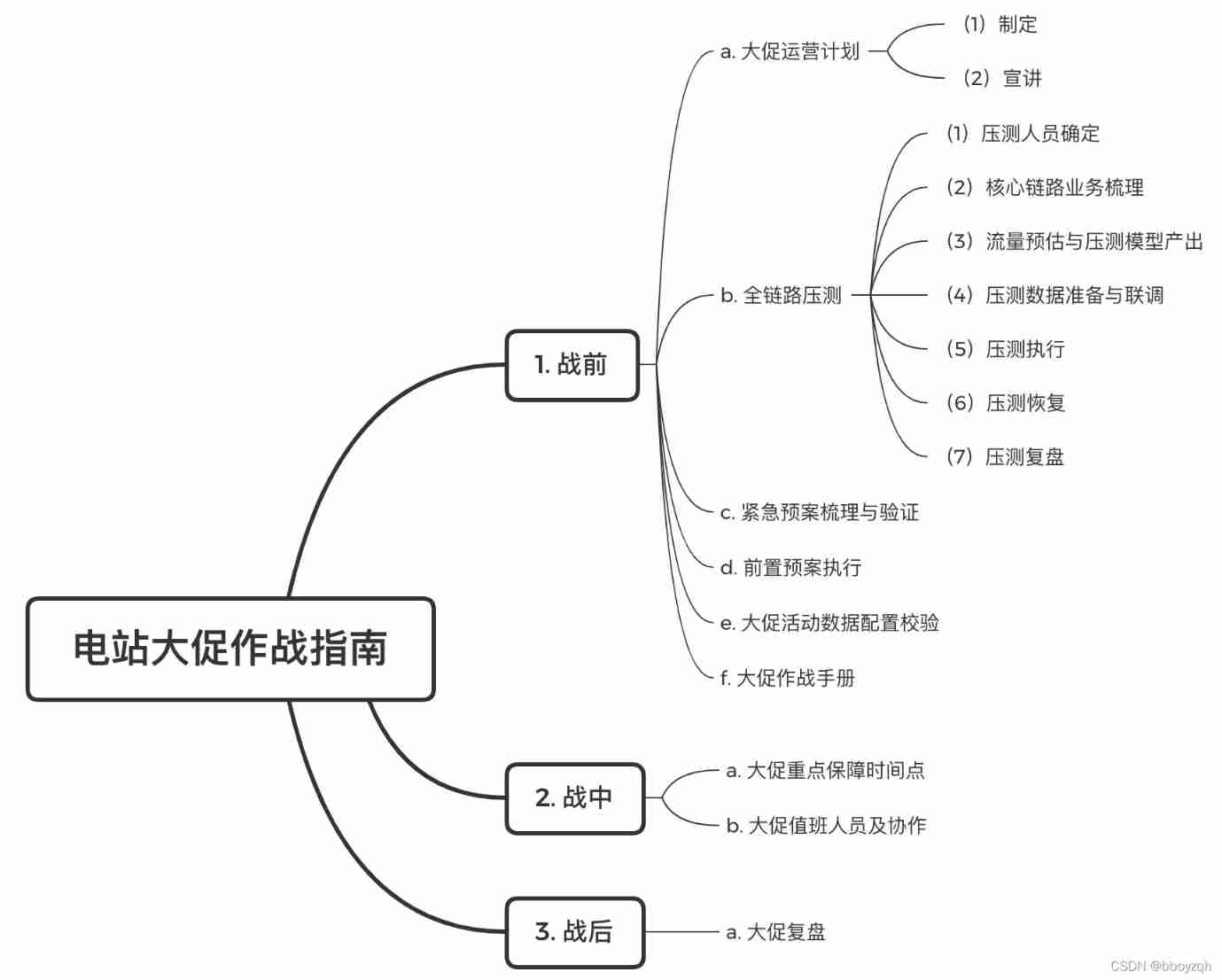
E-commerce campaign Guide

C language pointer (Part 2)
stm32和电机开发(从单机版到网络化)
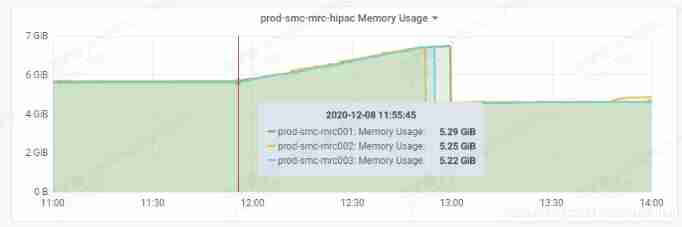
On December 8th, 2020, the memory of marketing MRC application suddenly increased, resulting in system oom
Postman data driven
【云原生】DevOps(一):DevOps介绍及Code工具使用
JVM garbage collection detailed learning notes (II)

Hard core sharing: a common toolkit for hardware engineers
【SVN】SVN是什么?怎么使用?
随机推荐
[chaosblade: node disk filling, killing the specified process on the node, suspending the specified process on the node]
Entity of cesium data visualization (Part 1)
UnityShader入门精要个人总结--基础篇(一)
C language pointer (Part 2)
【istio简介、架构、组件】
Run can start normally, and debug doesn't start or report an error, which seems to be stuck
Reading notes of pyramid principle
Panel display technology: LCD and OLED
Unittest simple project
SiteMesh getting started example
JWT certification used in DRF
NVIC中断优先级管理
ChaosBlade:混沌工程简介(一)
Expérience de port série - simple réception et réception de données
OpenGL frame buffer
Regularly modify the system time of the computer
[istio introduction, architecture, components]
Led analog and digital dimming
2021 year end summary
STM32串口寄存器库函数配置方法