当前位置:网站首页>【全網最全】 |MySQL EXPLAIN 完全解讀
【全網最全】 |MySQL EXPLAIN 完全解讀
2022-07-06 01:22:00 【菜鳥是大神】
TIPS
本文基於MySQL 8.0編寫,理論支持MySQL 5.0及更高版本。
EXPLAIN使用
explain可用來分析SQL的執行計劃。格式如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | {EXPLAIN | DESCRIBE | DESC}
tbl_name [col_name | wild]
{EXPLAIN | DESCRIBE | DESC}
[explain_type]
{explainable_stmt | FOR CONNECTION connection_id}
{EXPLAIN | DESCRIBE | DESC} ANALYZE select_statement
explain_type: {
FORMAT = format_name
}
format_name: {
TRADITIONAL
| JSON
| TREE
}
explainable_stmt: {
SELECT statement
| TABLE statement
| DELETE statement
| INSERT statement
| REPLACE statement
| UPDATE statement
}
|
示例:
1 2 3 4 5 6 7 8 9 10 11 12 | EXPLAIN format = TRADITIONAL json SELECT tt.TicketNumber, tt.TimeIn,
tt.ProjectReference, tt.EstimatedShipDate,
tt.ActualShipDate, tt.ClientID,
tt.ServiceCodes, tt.RepetitiveID,
tt.CurrentProcess, tt.CurrentDPPerson,
tt.RecordVolume, tt.DPPrinted, et.COUNTRY,
et_1.COUNTRY, do.CUSTNAME
FROM tt, et, et AS et_1, do
WHERE tt.SubmitTime IS NULL
AND tt.ActualPC = et.EMPLOYID
AND tt.AssignedPC = et_1.EMPLOYID
AND tt.ClientID = do.CUSTNMBR;
|
結果輸出展示:
| 字段 | format=json時的名稱 | 含義 |
|---|---|---|
| id | select_id | 該語句的唯一標識 |
| select_type | 無 | 查詢類型 |
| table | table_name | 錶名 |
| partitions | partitions | 匹配的分區 |
| type | access_type | 聯接類型 |
| possible_keys | possible_keys | 可能的索引選擇 |
| key | key | 實際選擇的索引 |
| key_len | key_length | 索引的長度 |
| ref | ref | 索引的哪一列被引用了 |
| rows | rows | 估計要掃描的行 |
| filtered | filtered | 錶示符合查詢條件的數據百分比 |
| Extra | 沒有 | 附加信息 |
結果解讀
id
該語句的唯一標識。如果explain的結果包括多個id值,則數字越大越先執行;而對於相同id的行,則錶示從上往下依次執行。
select_type
查詢類型,有如下幾種取值:
| 查詢類型 | 作用 |
|---|---|
| SIMPLE | 簡單查詢(未使用UNION或子查詢) |
| PRIMARY | 最外層的查詢 |
| UNION | 在UNION中的第二個和隨後的SELECT被標記為UNION。如果UNION被FROM子句中的子查詢包含,那麼它的第一個SELECT會被標記為DERIVED。 |
| DEPENDENT UNION | UNION中的第二個或後面的查詢,依賴了外面的查詢 |
| UNION RESULT | UNION的結果 |
| SUBQUERY | 子查詢中的第一個 SELECT |
| DEPENDENT SUBQUERY | 子查詢中的第一個 SELECT,依賴了外面的查詢 |
| DERIVED | 用來錶示包含在FROM子句的子查詢中的SELECT,MySQL會遞歸執行並將結果放到一個臨時錶中。MySQL內部將其稱為是Derived table(派生錶),因為該臨時錶是從子查詢派生出來的 |
| DEPENDENT DERIVED | 派生錶,依賴了其他的錶 |
| MATERIALIZED | 物化子查詢 |
| UNCACHEABLE SUBQUERY | 子查詢,結果無法緩存,必須針對外部查詢的每一行重新評估 |
| UNCACHEABLE UNION | UNION屬於UNCACHEABLE SUBQUERY的第二個或後面的查詢 |
table
錶示當前這一行正在訪問哪張錶,如果SQL定義了別名,則展示錶的別名
partitions
當前查詢匹配記錄的分區。對於未分區的錶,返回null
type
連接類型,有如下幾種取值,性能從好到壞排序 如下:
system:該錶只有一行(相當於系統錶),system是const類型的特例
const:針對主鍵或唯一索引的等值查詢掃描, 最多只返回一行數據. const 查詢速度非常快, 因為它僅僅讀取一次即可
eq_ref:當使用了索引的全部組成部分,並且索引是PRIMARY KEY或UNIQUE NOT NULL 才會使用該類型,性能僅次於system及const。
1 2 3 4 5 6 7 8
-- 多錶關聯查詢,單行匹配 SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; -- 多錶關聯查詢,聯合索引,多行匹配 SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
ref:當滿足索引的最左前綴規則,或者索引不是主鍵也不是唯一索引時才會發生。如果使用的索引只會匹配到少量的行,性能也是不錯的。
1 2 3 4 5 6 7 8 9 10 11
-- 根據索引(非主鍵,非唯一索引),匹配到多行 SELECT * FROM ref_table WHERE key_column=expr; -- 多錶關聯查詢,單個索引,多行匹配 SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; -- 多錶關聯查詢,聯合索引,多行匹配 SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;
TIPS
最左前綴原則,指的是索引按照最左優先的方式匹配索引。比如創建了一個組合索引(column1, column2, column3),那麼,如果查詢條件是:
- WHERE column1 = 1、WHERE column1= 1 AND column2 = 2、WHERE column1= 1 AND column2 = 2 AND column3 = 3 都可以使用該索引;
- WHERE column1 = 2、WHERE column1 = 1 AND column3 = 3就無法匹配該索引。
fulltext:全文索引
ref_or_null:該類型類似於ref,但是MySQL會額外搜索哪些行包含了NULL。這種類型常見於解析子查詢
1 2
SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL;
index_merge:此類型錶示使用了索引合並優化,錶示一個查詢裏面用到了多個索引
unique_subquery:該類型和eq_ref類似,但是使用了IN查詢,且子查詢是主鍵或者唯一索引。例如:
1
value IN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery:和unique_subquery類似,只是子查詢使用的是非唯一索引
1
value IN (SELECT key_column FROM single_table WHERE some_expr)
range:範圍掃描,錶示檢索了指定範圍的行,主要用於有限制的索引掃描。比較常見的範圍掃描是帶有BETWEEN子句或WHERE子句裏有>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE、IN()等操作符。
1 2 3 4 5
SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20; SELECT * FROM tbl_name WHERE key_column IN (10,20,30);
index:全索引掃描,和ALL類似,只不過index是全盤掃描了索引的數據。當查詢僅使用索引中的一部分列時,可使用此類型。有兩種場景會觸發:
- 如果索引是查詢的覆蓋索引,並且索引查詢的數據就可以滿足查詢中所需的所有數據,則只掃描索引樹。此時,explain的Extra 列的結果是Using index。index通常比ALL快,因為索引的大小通常小於錶數據。
- 按索引的順序來查找數據行,執行了全錶掃描。此時,explain的Extra列的結果不會出現Uses index。
ALL:全錶掃描,性能最差。
possible_keys
展示當前查詢可以使用哪些索引,這一列的數據是在優化過程的早期創建的,因此有些索引可能對於後續優化過程是沒用的。
key
錶示MySQL實際選擇的索引
key_len
索引使用的字節數。由於存儲格式,當字段允許為NULL時,key_len比不允許為空時大1字節。
key_len計算公式: explain之key_len計算 - yayun - 博客園
ref
錶示將哪個字段或常量和key列所使用的字段進行比較。
如果ref是一個函數,則使用的值是函數的結果。要想查看是哪個函數,可在EXPLAIN語句之後緊跟一個SHOW WARNING語句。
rows
MySQL估算會掃描的行數,數值越小越好。
filtered
錶示符合查詢條件的數據百分比,最大100。用rows × filtered可獲得和下一張錶連接的行數。例如rows = 1000,filtered = 50%,則和下一張錶連接的行數是500。
TIPS
在MySQL 5.7之前,想要顯示此字段需使用explain extended命令;
MySQL.5.7及更高版本,explain默認就會展示filtered
Extra
展示有關本次查詢的附加信息,取值如下:
Child of ‘table’ pushed [email protected]
此值只會在NDB Cluster下出現。
const row not found
例如查詢語句SELECT … FROM tbl_name,而錶是空的
Deleting all rows
對於DELETE語句,某些引擎(例如MyISAM)支持以一種簡單而快速的方式删除所有的數據,如果使用了這種優化,則顯示此值
Distinct
查找distinct值,當找到第一個匹配的行後,將停止為當前行組合搜索更多行
FirstMatch(tbl_name)
當前使用了半連接FirstMatch策略,詳見 FirstMatch Strategy - MariaDB Knowledge Base ,翻譯 semi-join子查詢優化 -- FirstMatch策略 - abce - 博客園
Full scan on NULL key
子查詢中的一種優化方式,在無法通過索引訪問null值的時候使用
Impossible HAVING
HAVING子句始終為false,不會命中任何行
Impossible WHERE
WHERE子句始終為false,不會命中任何行
Impossible WHERE noticed after reading const tables
MySQL已經讀取了所有const(或system)錶,並發現WHERE子句始終為false
LooseScan(m..n)
當前使用了半連接LooseScan策略,詳見 LooseScan Strategy - MariaDB Knowledge Base ,翻譯 MySQL5.6 Semi join優化策略之LooseScan 策略 |
No matching min/max row
沒有任何能滿足例如 SELECT MIN(…) FROM … WHERE condition 中的condition的行
no matching row in const table
對於關聯查詢,存在一個空錶,或者沒有行能够滿足唯一索引條件
No matching rows after partition pruning
對於DELETE或UPDATE語句,優化器在partition pruning(分區修剪)之後,找不到要delete或update的內容
No tables used
當此查詢沒有FROM子句或擁有FROM DUAL子句時出現。例如:explain select 1
Not exists
MySQL能對LEFT JOIN優化,在找到符合LEFT JOIN的行後,不會為上一行組合中檢查此錶中的更多行。例如:
1 2
SELECT * FROM t1 LEFT JOIN t2 ON t1.id=t2.id WHERE t2.id IS NULL;
假設t2.id定義成了
NOT NULL,此時,MySQL會掃描t1,並使用t1.id的值查找t2中的行。 如果MySQL在t2中找到一個匹配的行,它會知道t2.id永遠不會為NULL,並且不會掃描t2中具有相同id值的其餘行。也就是說,對於t1中的每一行,MySQL只需要在t2中只執行一次查找,而不考慮在t2中實際匹配的行數。在MySQL 8.0.17及更高版本中,如果出現此提示,還可錶示形如 NOT IN (subquery) 或 NOT EXISTS (subquery) 的WHERE條件已經在內部轉換為反連接。這將删除子查詢並將其錶放入最頂層的查詢計劃中,從而改進查詢的開銷。通過合並半連接和反聯接,優化器可以更加自由地對執行計劃中的錶重新排序,在某些情况下,可讓查詢提速。你可以通過在EXPLAIN語句後緊跟一個SHOW WARNING語句,並分析結果中的Message列,從而查看何時對該查詢執行了反聯接轉換。
Note
兩錶關聯只返回主錶的數據,並且只返回主錶與子錶沒關聯上的數據,這種連接就叫反連接
Plan isn’t ready yet
使用了EXPLAIN FOR CONNECTION,當優化器尚未完成為在指定連接中為執行的語句創建執行計劃時, 就會出現此值。
Range checked for each record (index map: N)
MySQL沒有找到合適的索引去使用,但是去檢查是否可以使用range或index_merge來檢索行時,會出現此提示。index map N索引的編號從1開始,按照與錶的SHOW INDEX所示相同的順序。 索引映射值N是指示哪些索引是候選的比特掩碼值。 例如0x19(二進制11001)的值意味著將考慮索引1、4和5。
示例:下面例子中,name是varchar類型,但是條件給出整數型,涉及到隱式轉換。
圖中t2也沒有用到索引,是因為查詢之前我將t2中name字段排序規則改為utf8_bin導致的鏈接字段排序規則不匹配。1 2 3
explain select a.* from t1 a left join t2 b on t1.name = t2.name where t2.name = 2;
結果:
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | t2 | NULL | ALL | idx_name | NULL | NULL | NULL | 9 | 11.11 | Using where |
| 1 | SIMPLE | t1 | NULL | ALL | idx_name | NULL | NULL | NULL | 5 | 11.11 | Range checked for each record (index map: 0x8) |
Recursive
出現了遞歸查詢。詳見 “WITH (Common Table Expressions)”
Rematerialize
用得很少,使用類似如下SQL時,會展示Rematerialize
1 2 3 4 5 6
SELECT ... FROM t, LATERAL (derived table that refers to t) AS dt ...
Scanned N databases
錶示在處理INFORMATION_SCHEMA錶的查詢時,掃描了幾個目錄,N的取值可以是0,1或者all。詳見 “Optimizing INFORMATION_SCHEMA Queries”
Select tables optimized away
優化器確定:①最多返回1行;②要產生該行的數據,要讀取一組確定的行,時會出現此提示。一般在用某些聚合函數訪問存在索引的某個字段時,優化器會通過索引直接一次定比特到所需要的數據行完成整個查詢時展示,例如下面這條SQL。
1 2 3
explain select min(id) from t1;
Skip_open_table, Open_frm_only, Open_full_table
這些值錶示適用於INFORMATION_SCHEMA錶查詢的文件打開優化;
- Skip_open_table:無需打開錶文件,信息已經通過掃描數據字典獲得
- Open_frm_only:僅需要讀取數據字典以獲取錶信息
- Open_full_table:未優化的信息查找。錶信息必須從數據字典以及錶文件中讀取
Start temporary, End temporary
錶示臨時錶使用Duplicate Weedout策略,詳見 DuplicateWeedout Strategy - MariaDB Knowledge Base ,翻譯 semi-join子查詢優化 -- Duplicate Weedout策略 - abce - 博客園
unique row not found
對於形如 SELECT … FROM tbl_name 的查詢,但沒有行能够滿足唯一索引或主鍵查詢的條件
Using filesort
當Query 中包含 ORDER BY 操作,而且無法利用索引完成排序操作的時候,MySQL Query Optimizer 不得不選擇相應的排序算法來實現。數據較少時從內存排序,否則從磁盤排序。Explain不會顯示的告訴客戶端用哪種排序。官方解釋:“MySQL需要額外的一次傳遞,以找出如何按排序順序檢索行。通過根據聯接類型瀏覽所有行並為所有匹配WHERE子句的行保存排序關鍵字和行的指針來完成排序。然後關鍵字被排序,並按排序順序檢索行”
Using index
僅使用索引樹中的信息從錶中檢索列信息,而不必進行其他查找以讀取實際行。當查詢僅使用屬於單個索引的列時,可以使用此策略。例如:
1
explain SELECT id FROM t
Using index condition
錶示先按條件過濾索引,過濾完索引後找到所有符合索引條件的數據行,隨後用 WHERE 子句中的其他條件去過濾這些數據行。通過這種方式,除非有必要,否則索引信息將可以延遲“下推”讀取整個行的數據。詳見 “Index Condition Pushdown Optimization” 。例如:
TIPS
MySQL分成了Server層和引擎層,下推指的是將請求交給引擎層處理。
理解這個功能,可創建所以INDEX (zipcode, lastname, firstname),並分別用如下指令,
1 2
SET optimizer_switch = 'index_condition_pushdown=off'; SET optimizer_switch = 'index_condition_pushdown=on';
開或者關閉索引條件下推,並對比:
1 2 3 4
explain SELECT * FROM people WHERE zipcode='95054' AND lastname LIKE '%etrunia%' AND address LIKE '%Main Street%';
的執行結果。
index condition pushdown從MySQL 5.6開始支持,是MySQL針對特定場景的優化機制,感興趣的可以看下 MySQL 索引條件下推 Index Condition Pushdown_李如磊的技術博客_51CTO博客
Using index for group-by
數據訪問和 Using index 一樣,所需數據只須要讀取索引,當Query 中使用GROUP BY或DISTINCT 子句時,如果分組字段也在索引中,Extra中的信息就會是 Using index for group-by。詳見 “GROUP BY Optimization”
1 2
-- name字段有索引 explain SELECT name FROM t1 group by name
Using index for skip scan
錶示使用了Skip Scan。詳見 Skip Scan Range Access Method
Using join buffer (Block Nested Loop), Using join buffer (Batched Key Access)
使用Block Nested Loop或Batched Key Access算法提高join的性能。詳見 【mysql】關於ICP、MRR、BKA等特性 - 踏雪無痕SS - 博客園
Using MRR
使用了Multi-Range Read優化策略。詳見 “Multi-Range Read Optimization”
Using sort_union(…), Using union(…), Using intersect(…)
這些指示索引掃描如何合並為index_merge連接類型。詳見 “Index Merge Optimization” 。
Using temporary
為了解决該查詢,MySQL需要創建一個臨時錶來保存結果。如果查詢包含不同列的GROUP BY和 ORDER BY子句,通常會發生這種情况。
1 2
-- name無索引 explain SELECT name FROM t1 group by name
Using where
如果我們不是讀取錶的所有數據,或者不是僅僅通過索引就可以獲取所有需要的數據,則會出現using where信息
1
explain SELECT * FROM t1 where id > 5
Using where with pushed condition
僅用於NDB
Zero limit
該查詢有一個limit 0子句,不能選擇任何行
1
explain SELECT name FROM resource_template limit 0
擴展的EXPLAIN
EXPLAIN可產生額外的擴展信息,可通過在EXPLAIN語句後緊跟一條SHOW WARNING語句查看擴展信息。
TIPS
- 在MySQL 8.0.12及更高版本,擴展信息可用於SELECT、DELETE、INSERT、REPLACE、UPDATE語句;在MySQL 8.0.12之前,擴展信息僅適用於SELECT語句;
- 在MySQL 5.6及更低版本,需使用EXPLAIN EXTENDED xxx語句;而從MySQL 5.7開始,無需添加EXTENDED關鍵詞。
使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | mysql> EXPLAIN
SELECT t1.a, t1.a IN (SELECT t2.a FROM t2) FROM t1\G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t1
type: index
possible_keys: NULL
key: PRIMARY
key_len: 4
ref: NULL
rows: 4
filtered: 100.00
Extra: Using index
*************************** 2. row ***************************
id: 2
select_type: SUBQUERY
table: t2
type: index
possible_keys: a
key: a
key_len: 5
ref: NULL
rows: 3
filtered: 100.00
Extra: Using index
2 rows in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select `test`.`t1`.`a` AS `a`,
<in_optimizer>(`test`.`t1`.`a`,`test`.`t1`.`a` in
( <materialize> (/* select#2 */ select `test`.`t2`.`a`
from `test`.`t2` where 1 having 1 ),
<primary_index_lookup>(`test`.`t1`.`a` in
<temporary table> on <auto_key>
where ((`test`.`t1`.`a` = `materialized-subquery`.`a`))))) AS `t1.a
IN (SELECT t2.a FROM t2)` from `test`.`t1`
1 row in set (0.00 sec)
|
由於SHOW WARNING的結果並不一定是一個有效SQL,也不一定能够執行(因為裏面包含了很多特殊標記)。特殊標記取值如下:
<auto_key>自動生成的臨時錶key
<cache>(expr)錶達式(例如標量子查詢)執行了一次,並且將值保存在了內存中以備以後使用。對於包括多個值的結果,可能會創建臨時錶,你將會看到
<temporary table>的字樣<exists>(query fragment)子查詢被轉換為
EXISTS<in_optimizer>(query fragment)這是一個內部優化器對象,對用戶沒有任何意義
<index_lookup>(query fragment)使用索引查找來處理查詢片段,從而找到合格的行
<if>(condition, expr1, expr2)如果條件是true,則取expr1,否則取expr2
<is_not_null_test>(expr)驗證錶達式不為NULL的測試
<materialize>(query fragment)使用子查詢實現
materialized-subquery.col_name在內部物化臨時錶中對col_name的引用,以保存子查詢的結果
<primary_index_lookup>(query fragment)使用主鍵來處理查詢片段,從而找到合格的行
<ref_null_helper>(expr)這是一個內部優化器對象,對用戶沒有任何意義
/* select#N */ select_stmtSELECT與非擴展的EXPLAIN輸出中id=N的那行關聯
outer_tables semi join (inner_tables)半連接操作。inner_tables展示未拉出的錶。詳見 “Optimizing Subqueries, Derived Tables, and View References with Semijoin Transformations”
<temporary table>錶示創建了內部臨時錶而緩存中間結果
當某些錶是const或system類型時,這些錶中的列所涉及的錶達式將由優化器盡早評估,並且不屬於所顯示語句的一部分。但是,當使用FORMAT=JSON時,某些const錶的訪問將顯示為ref。
估計查詢性能
多數情况下,你可以通過計算磁盤的搜索次數來估算查詢性能。對於比較小的錶,通常可以在一次磁盤搜索中找到行(因為索引可能已經被緩存了),而對於更大的錶,你可以使用B-tree索引進行估算:你需要進行多少次查找才能找到行:log(row_count) / log(index_block_length / 3 * 2 / (index_length + data_pointer_length)) + 1
在MySQL中,index_block_length通常是1024字節,數據指針一般是4字節。比方說,有一個500,000的錶,key是3字節,那麼根據計算公式 log(500,000)/log(1024/3*2/(3+4)) + 1 = 4 次搜索。
該索引將需要500,000 * 7 * 3/2 = 5.2MB的存儲空間(假設典型的索引緩存的填充率是2/3),因此你可以在內存中存放更多索引,可能只要一到兩個調用就可以找到想要的行了。
但是,對於寫操作,你需要四個搜索請求來查找在何處放置新的索引值,然後通常需要2次搜索來更新索引並寫入行。
前面的討論並不意味著你的應用性能會因為log N而緩慢下降。只要內容被OS或MySQL服務器緩存,隨著錶的變大,只會稍微變慢。在數據量變得太大而無法緩存後,將會變慢很多,直到你的應用程序受到磁盤搜索約束(按照log N增長)。為了避免這種情况,可以根據數據的增長而增加key的。對於MyISAM錶,key的緩存大小由名為key_buffer_size的系統變量控制,
边栏推荐
- 关于softmax函数的见解
- Exciting, 2022 open atom global open source summit registration is hot
- Finding the nearest common ancestor of binary search tree by recursion
- Leetcode 208. 实现 Trie (前缀树)
- Four dimensional matrix, flip (including mirror image), rotation, world coordinates and local coordinates
- [day 30] given an integer n, find the sum of its factors
- 电气数据|IEEE118(含风能太阳能)
- MobileNet系列(5):使用pytorch搭建MobileNetV3并基于迁移学习训练
- Paging of a scratch (page turning processing)
- 基於DVWA的文件上傳漏洞測試
猜你喜欢

About error 2003 (HY000): can't connect to MySQL server on 'localhost' (10061)

现货白银的一般操作方法
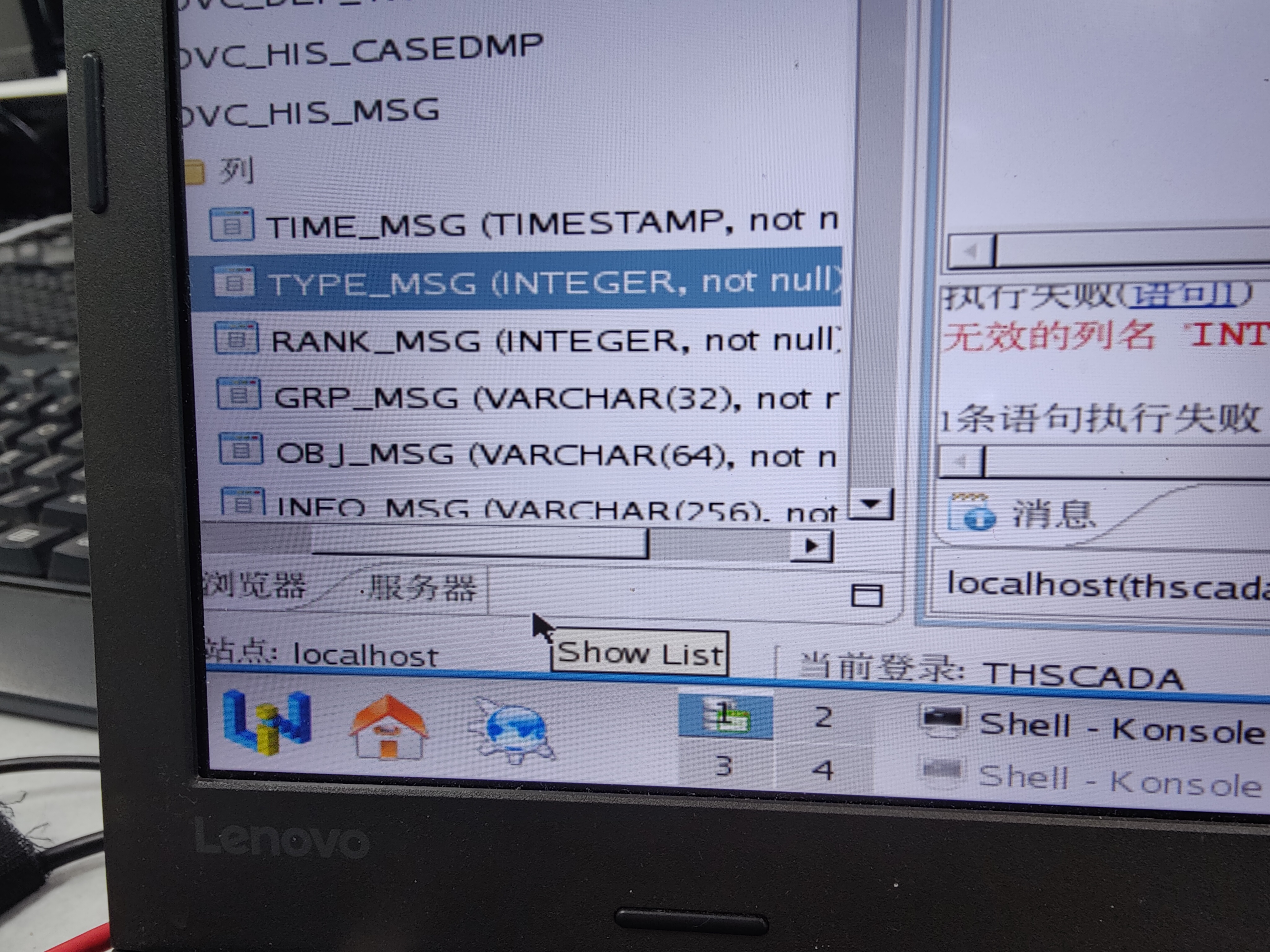
Who knows how to modify the data type accuracy of the columns in the database table of Damon

leetcode刷题_验证回文字符串 Ⅱ

Cf:c. the third problem
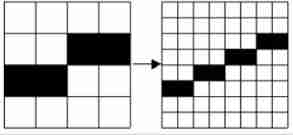
Four commonly used techniques for anti aliasing
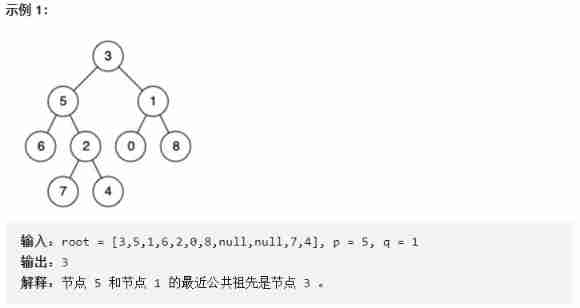
Finding the nearest common ancestor of binary tree by recursion
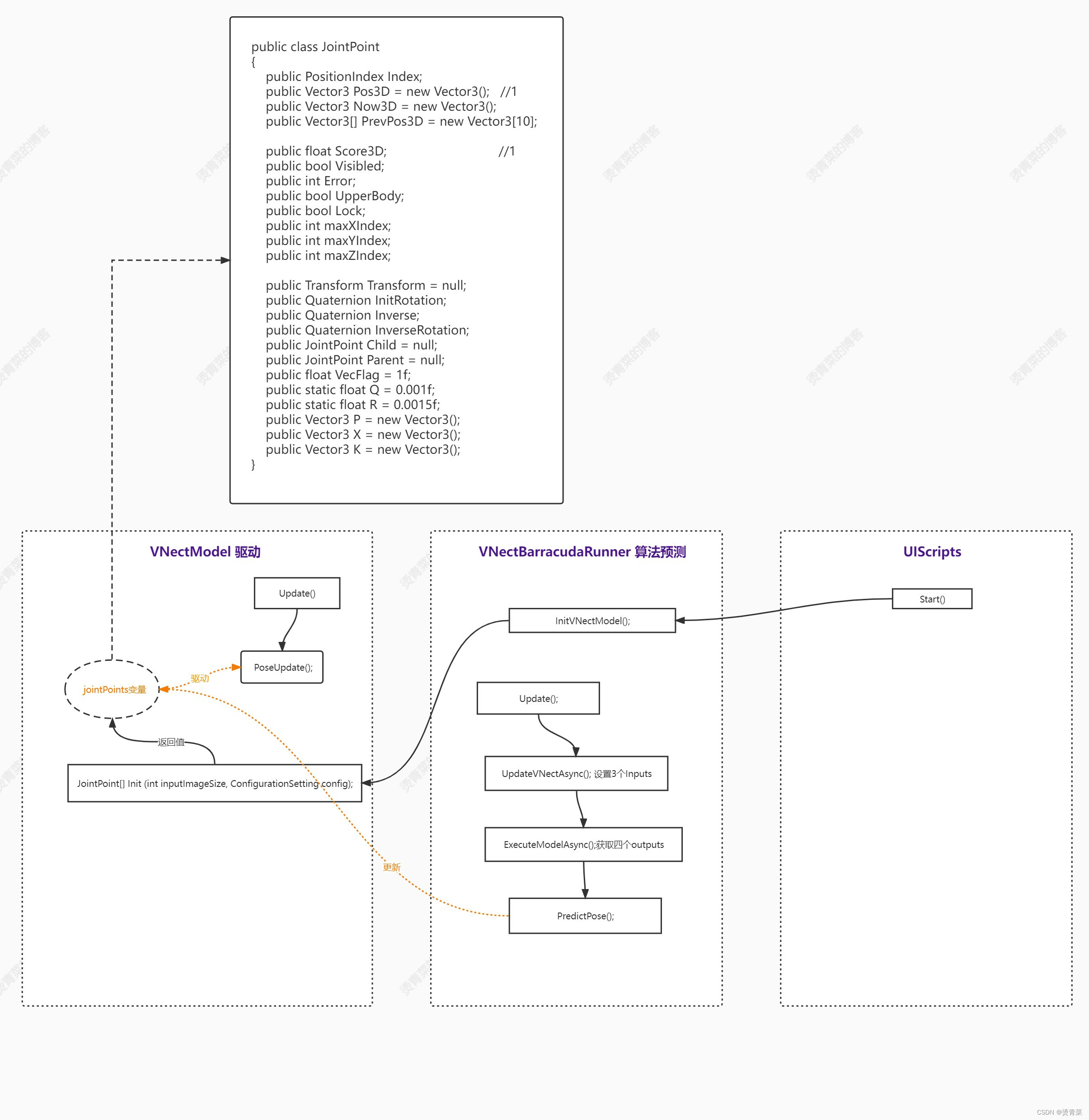
ThreeDPoseTracker项目解析

A picture to understand! Why did the school teach you coding but still not

What is the most suitable book for programmers to engage in open source?
随机推荐
Zhuhai laboratory ventilation system construction and installation instructions
Questions about database: (5) query the barcode, location and reader number of each book in the inventory table
Installation and use of esxi
Four dimensional matrix, flip (including mirror image), rotation, world coordinates and local coordinates
Unity VR solves the problem that the handle ray keeps flashing after touching the button of the UI
037 PHP login, registration, message, personal Center Design
Remember that a version of @nestjs/typeorm^8.1.4 cannot be obtained Env option problem
FFT 学习笔记(自认为详细)
Dede collection plug-in free collection release push plug-in
Finding the nearest common ancestor of binary search tree by recursion
[机缘参悟-39]:鬼谷子-第五飞箝篇 - 警示之二:赞美的六种类型,谨防享受赞美快感如同鱼儿享受诱饵。
Recoverable fuse characteristic test
Cf:d. insert a progression [about the insert in the array + the nature of absolute value + greedy top-down]
1791. Find the central node of the star diagram / 1790 Can two strings be equal by performing string exchange only once
Une image! Pourquoi l'école t'a - t - elle appris à coder, mais pourquoi pas...
About error 2003 (HY000): can't connect to MySQL server on 'localhost' (10061)
Cf:h. maximum and [bit operation practice + K operations + maximum and]
How to extract MP3 audio from MP4 video files?
Threedposetracker project resolution
Exciting, 2022 open atom global open source summit registration is hot