01 Think about it as a whole 
Mention the integration of flow and batch , I have to mention the traditional big data platform —— Lambda framework . It can effectively support offline and real-time data development requirements , However, the high development and maintenance costs and inconsistent data caliber caused by the separation of the stream and batch data links cannot be ignored .
It is ideal to meet the data processing requirements of both streams and batches through a set of data links , namely Stream batch integration . In addition, we believe that there are still some intermediate stages in the integration of flow and batch , For example, it is of great significance to only realize the unification of computing or storage .
Take the example of computing unification only , Some data applications require high real-time performance , For example, we hope that the end-to-end data processing delay will not exceed one second , This is for the current open source 、 It is a great challenge for the unified storage of stream and batch . Take the data Lake as an example , Its data visibility is similar to commit Interval dependent , And then Flink do checkpoint Is related to the time interval , This feature is combined with the length of the data processing link , It can be seen that it is not easy to do end-to-end processing for one second . So for this kind of demand , It is also feasible to achieve only computational unification . Reduce the development and maintenance costs of users through unified calculation , Solve the problem of inconsistent data caliber .

In the process of the integration of flow and batch Technology , The challenges can be summarized as follows 4 In terms of :
- The first is the real-time data . How to reduce the end-to-end data delay to the second level is a great challenge , Because it involves both computing engine and storage technology . It is essentially a performance issue , It is also a long-term goal .
- The second challenge is how to be compatible with the offline batch processing capability that has been widely used in the field of data processing . This involves two levels of development and scheduling , The development level is mainly about reuse , For example, how to reuse the data model of existing offline tables , How to reuse user-defined development that users are already using Hive UDF etc. . The main problem in the scheduling level is how to reasonably integrate with the scheduling system .
- The third challenge is resources and deployment . For example, through different types of streams 、 Mixed deployment of batch applications to improve resource utilization , And how to base it on metrics To build resilience , Further improve resource utilization .
- The last challenge is also the most difficult one : User concept . Most users are usually limited to technical exchange or verification for relatively new technical concepts , Even if the actual problem can be solved after verification , We also need to wait for the right business to test the water . This question has also led to some thinking , On the platform side, we must look at problems from the perspective of users , Reasonably evaluate the cost of changing the user's existing technical architecture and the user's benefits 、 Potential risks of business migration, etc .
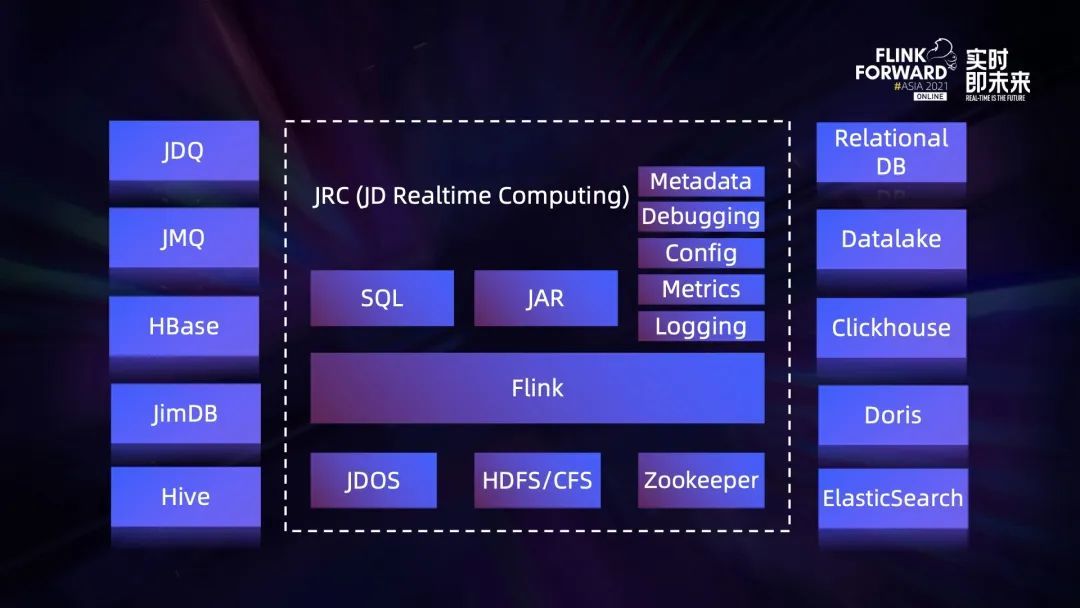
The above figure is a panorama of JD real-time computing platform , It is also the carrier for us to realize the integration of flow and batch . In the middle of the Flink Deep customization based on the open source community version . The cluster built on this version , External dependencies consist of three parts ,JDOS、HDFS/CFS and Zookeeper.
- JDOS It's from Jingdong Kubernetes platform , At present, all of us Flink Computing tasks are containerized , Are running on this platform ;
- Flink The status backend of the has HDFS and CFS Two options , among CFS It is the object storage developed by JD ;
- Flink Cluster high availability is based on Zookeeper Built .
In terms of application development mode , Provided by the platform SQL and Jar Package two ways , among Jar Support users to upload directly Flink application Jar Package or provide Git The address is packaged by the platform . In addition, our platform based functions are relatively perfect , For example, basic metadata services 、SQL Debugging function , The product side supports all parameter configurations , And based on metrics Monitoring of 、 Task log query, etc .
Connecting to data sources , The platform passes connector It supports a variety of data source types , among JDQ Based on open source Kafka customized , It is mainly applied to message queues in big data scenarios ;JMQ It was developed by JD , It is mainly used in message queue of online system ;JimDB It is a distributed self-developed by JD KV Storage .

At present Lambda Architecture , Suppose that the data of the real-time link is stored in JDQ, Offline link data exists Hive In the table , Even if the same business model is being calculated , The definition of metadata is often different , Therefore, we introduce a unified logical model to be compatible with the metadata of both real-time and offline sides .
In the calculation process , adopt FlinkSQL combination UDF To realize the flow batch unified calculation of business logic , In addition, the platform will provide a large number of public services UDF, It also supports users to upload customized UDF. Output of calculation results , We also introduce a unified logical model to shield the differences between the two ends of the flow batch . For scenarios that only achieve computational unification , The calculation results can be written to the corresponding storage of the stream batch , To ensure that the real-time performance of the data is consistent with the previous .
For scenarios where both computing and storage are unified , We can write the calculation results directly to the unified storage of the stream batch . We chose Iceberg As a unified storage of stream and batch , Because it has good architecture design , For example, it will not be bound to a specific engine, etc .
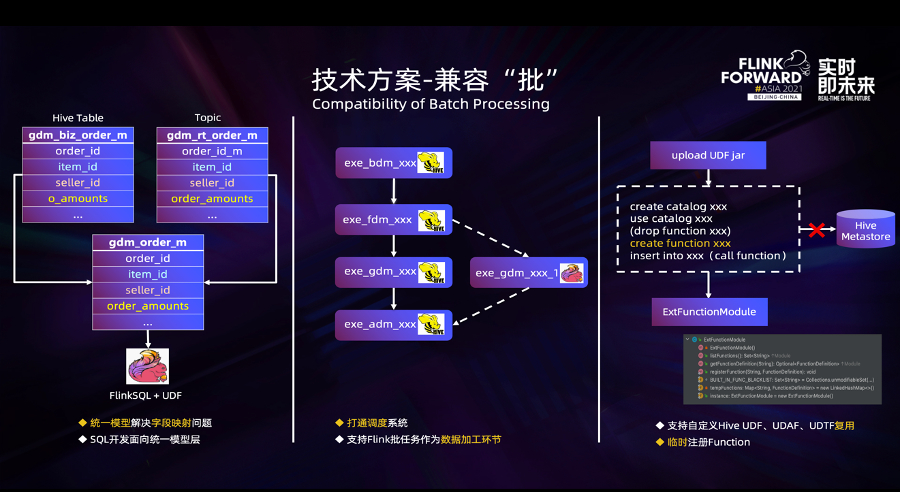
In terms of compatible batch processing capability , We have mainly carried out the following three aspects of work :
First of all , Reuse... In offline data warehouse Hive surface .
Take the data source side as an example , In order to shield the flow in the left figure of the above figure 、 Difference in metadata between two ends of a batch , We define the logical model gdm_order_m surface , And the user needs to specify Hive Table and Topic The mapping relationship between the fields in and the fields in this logical table . The definition of mapping relationship here is very important , Because it is based on FlinkSQL The calculation of only needs to face this logic table , Without caring about the actual Hive Table and Topic Field information in . Pass... At run time connector When creating flow tables and batch tables , The fields in the logical table will be replaced by the actual fields through the mapping relationship .
On the product side , We can bind the flow table and batch table to the logical table respectively , Specify the mapping relationship between fields by dragging . This mode makes our development method different from before , The previous method is to create a new task and specify whether it is a flow task or a batch task , Then proceed SQL Development , Then specify the task related configuration , Finally release the task . In the flow batch integration mode , The development mode changes to complete first SQL Development of , This includes logical 、 Physical DDL The definition of , And the specification of the field mapping relationship between them ,DML Preparation of , Then specify the configuration related to the flow batch task , Finally, two tasks of stream batch are released .
second , Get through with the dispatching system .
The data processing of offline data warehouse is basically based on Hive/Spark Combined with scheduling mode , The figure in the middle of the above figure is taken as an example , The processing of data is divided into 4 Stages , Corresponding to the data warehouse respectively BDM、FDM、GDM and ADM layer . With Flink Ability enhancement , The user wants to put GDM The data processing task of the layer is replaced by FlinkSQL Batch tasks for , This requires putting FlinkSQL Batch tasks are embedded in the current data processing process , As a link in the middle .
To solve this problem , In addition to the task itself, it supports configuring scheduling rules , We also got through the dispatching system , It inherits the dependency of the parent task , And synchronize the information of the task itself to the scheduling system , Supports parent tasks as downstream tasks , So as to achieve the goal of FlinkSQL As one of the links of raw data processing .
Third , User defined Hive UDF、UDAF And UDTF Reuse of .
For existing systems based on Hive Off line machining task of , If the user has developed UDF function , So the best way is to migrate Flink Time for these UDF Direct reuse , Not according to Flink UDF Define reimplementation .
stay UDF On the compatibility of , For the use of Hive Scenarios with built-in functions , The community provided load hive modules programme . If users want to use their own Hive UDF, By using create catalog、use catalog、create function, Last in DML To implement , This process will Function Register with Hive Of Metastore in . From the perspective of platform management , We want users to UDF It has certain isolation , Restrict users Job Granularity , Reduce with Hive Metastore Interaction and the risk of generating dirty function metadata .
Besides , When the meta information has been registered , I hope that next time I can Flink The platform side is in normal use , If not used if not exist grammar , It usually takes drop function, Proceed again create operation . But this way is not elegant , At the same time, there are restrictions on the use of users . Another solution is that users can register temporary Hive UDF, stay Flink1.12 Register temporary UDF The way is create temporary function, But it's time to Function Need to achieve UserDefinedFunction The interface can pass the following verification , Otherwise, the registration will fail .
So we didn't use create temporary function, It's right create function Made some adjustments , Expanded ExtFunctionModule, Will be resolved FunctionDefinition Sign up to ExtFunctionModule in , Did it once Job Level of temporary registration . The advantage of this is that it won't pollute Hive Metastore, Provides good isolation , At the same time, there is no restriction on users' usage habits , Provides a good experience .
But the problem is in the community 1.13 The version of has been comprehensively solved . By introducing Hive Parser and other extensions , It is already possible to implement UDF、GenericUDF Interface customization Hive Function by create temporary function Syntax to register and use .
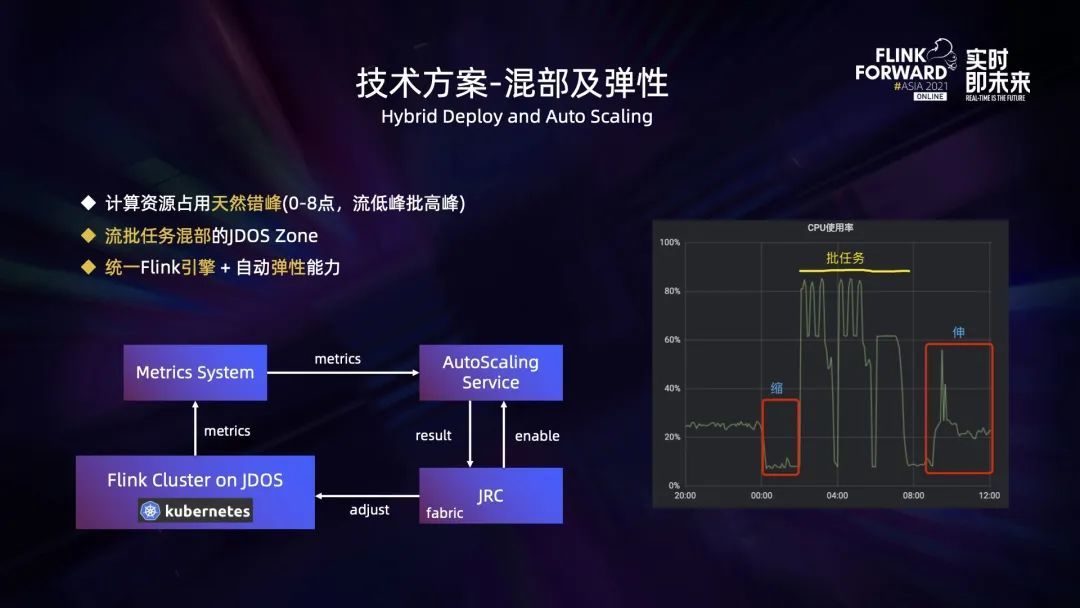
In terms of resource utilization , Stream processing and batch processing are natural peak shifting . For batch processing , Offline warehouse every day 0 Click to calculate the data of the past day , The data processing of all offline reports will be completed before the next day , So usually 00:00 To 8:00 It is a time period in which batch computing tasks consume a lot of resources , During this period, the online traffic is usually low . The load of stream processing is positively correlated with the online traffic , Therefore, the resource requirements for stream processing in this time period are relatively low . In the morning 8 Point to night 0 spot , Online traffic is high , Most of the batch tasks in this time period will not be triggered for execution .
Based on this natural peak staggering , We can do it in the exclusive JDOS Zone In order to improve the utilization rate of resources, different types of stream batch applications are mixed , And if it is used uniformly Flink Engine to process stream batch applications , The utilization rate of resources will be higher .
At the same time, in order to make the application dynamically adjust based on traffic , We have also developed services that automatically scale elastically (Auto-Scaling Service). It works as follows : Running on the platform Flink Task escalation metrics Information to metrics System ,Auto-Scaling Service Will be based on metrics Some key indicators in the system , such as TaskManager Of CPU Usage rate 、 The back pressure of the task is used to determine whether the task needs to increase or decrease computing resources , And feed back the adjustment results to JRC platform ,JRC The platform is built-in fabric The client synchronizes the adjustment results to JDOS platform , To complete the TaskManager Pod Number adjustment . Besides , Users can go to JRC The platform determines whether to enable this function for tasks through configuration .
The chart on the right of the above figure shows us in JDOS Zone During the pilot test of the flow batch mixing department and the elastic scaling service CPU usage . You can see 0 The point flow task has been reduced , Release resources to batch tasks . The new task we set up is 2 Start at , So from 2 It starts at o'clock and ends in the morning ,CPU The utilization rate of is relatively high , Up to 80% above . After the batch task runs , When online traffic starts to grow , The flow task has been expanded ,CPU The utilization rate of has also increased .
More on :
https://blog.stackanswer.com/articles/2022/07/01/1656663988707.html
![[flutter topic] 64 illustration basic textfield text input box (I) # yyds dry goods inventory #](/img/1c/deaf20d46e172af4d5e11c28c254cf.jpg)

![[wave modeling 1] theoretical analysis and MATLAB simulation of wave modeling](/img/c4/46663f64b97e7b25d7222de7025f59.png)