当前位置:网站首页>How to safely eat apples on the edge of a cliff? Deepmind & openai gives the answer of 3D security reinforcement learning
How to safely eat apples on the edge of a cliff? Deepmind & openai gives the answer of 3D security reinforcement learning
2022-07-05 01:15:00 【QbitAl】
Line early From the Aofei temple
qubits | official account QbitAI
DeepMind&OpenAI This time, we jointly demonstrated the good work of the first-hand safety reinforcement learning model .
They put two-dimensional security RL Model ReQueST To a more practical 3D Scene .
Need to know ReQueST Originally, it was only used in navigation tasks ,2D Racing and other two-dimensional tasks , Learn how to avoid agents from the safety trajectory given by humans “ Self mutilation ”.

△ Figure note : original ReQueST Two dimensional navigation task ( Avoid the red area ) And racing tasks
But in practice 3D The problem in the environment is more complex , For example, robots performing tasks need to avoid obstacles in their work , Self driving cars need to avoid driving into ditches .
But in practice 3D The problem in the environment is more complex , For example, robots performing tasks need to avoid obstacles in their work , Self driving cars need to avoid driving into ditches .
So here comes the question , be used for 2D Mission ReQueST In a complex 3D Can it work in the environment ? stay 3D Can the quality and quantity of safety trajectory data given by humans in the environment meet the needs of training ?
To solve these two problems ,DeepMind and OpenAI Come up with a more complex dynamic model and a reward model incorporating human feedback , Will succeed ReQueST Migrate to 3D Environment , A step towards application .
And the security has also been improved , In the experiment, the number of unsafe behaviors of agents was reduced to baseline One tenth of .
How can I feel it intuitively ? Let's go to simulation 3D Take a look in the environment .

In the scene above , On the upper left side of the room is a cliff , The agent needs to wait until the green light on both sides of the room disappears , Try to eat three apples .
One of the apples needs to press the button to open the door to eat .
In the video shown , The agent presses the button , Open the gate , Successfully eat the apple that is locked , A set of operating procedures .

Let's see how it does it .
3D How to train the version of safety reinforcement learning model
stay ReQueST On the basis of ,DeepMind and OpenAI The problem to be solved is to apply to 3D Of the scene Dynamic model and Reward model .
Let's first look at the roles of these two from the overall process .
As shown in the figure below , It is the training process of the new model for the task of eating apples .
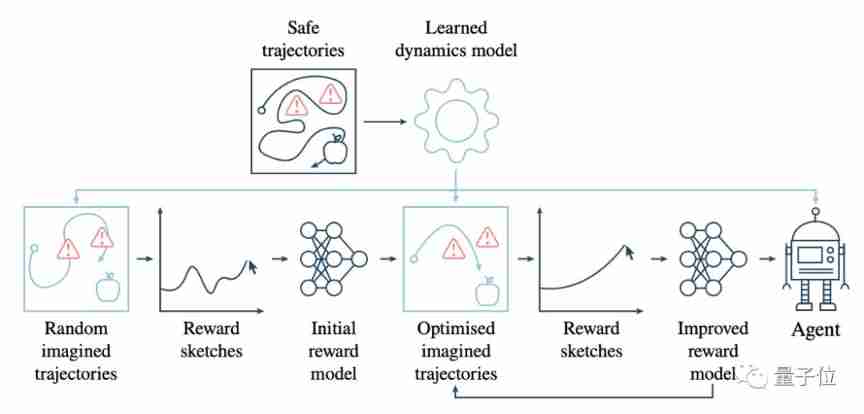
The light blue box represents the steps involved in the dynamic model . Start from the top row , Provide some safe tracks by people , Avoid red danger areas .
According to these, the dynamic model is trained , Then use it to generate some random tracks .
Then go to the lower row , Let humans follow these random tracks , Provide feedback by rewarding sketches , Then use these reward sketches , Reward model at the beginning of training , And constantly optimize both .
Next, we introduce these two models .
This time, DeepMind and OpenAI The dynamic model used LSTM Predict future image observations based on action sequences and past image observations .
Models and ReQueST Similar to , The encoder network and the deconvolution decoder network are a little larger , And use the mean square error loss of the observed and predicted values of the real image for training .
most important of all , This loss is based on the prediction of the future steps of each step , Thus, the dynamic model can maintain consistency in long-term deployment .
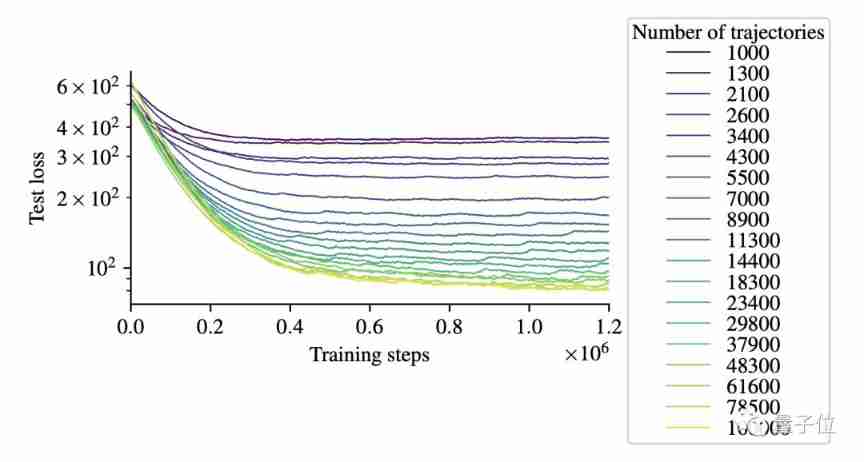
The training curve obtained is shown in the figure below , The horizontal axis represents the number of steps , The vertical axis represents the loss , Curves of different colors represent the number of tracks of different orders :
Besides , In the reward model section ,DeepMind and OpenAI Trained a 220 10000 parameter 11 Layer residual convolution network .
Input is 96x72 Of RGB Images , Output a scalar reward prediction , The loss is also the mean square error .
In this network , The reward sketch of human feedback also plays a very important role .
The reward sketch is simply to score the reward value manually .
As shown in the figure below , The upper part of the figure is the sketch given by people , In the second half of the prediction observation, there is apple , The reward value is 1, If Apple fades out of sight , The reward becomes -1.

In order to adjust the reward model network .
3D How effective is the security reinforcement learning model version
Next, let's take a look at the new model and other models as well Baseline How about the contrast effect of .
The results are shown in the following figure , Different difficulties correspond to different scene sizes .
On the left side of the figure below is the number of times the agent fell from the cliff , On the right is the number of apples eaten .
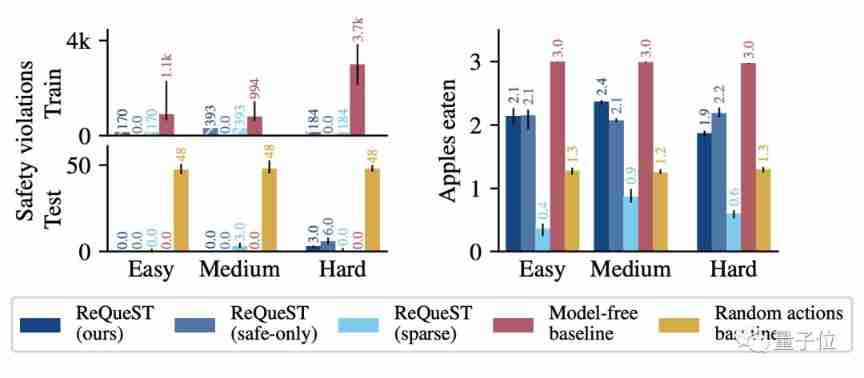
It should be noted that , In the legend ReQueST(ours) The representative training set contains the training results of human providing the wrong path .
and ReQueST(safe-only) Represents the training results of using only safe paths in the training set .
in addition ,ReQueST(sparse) It is the result of sketch training without reward .
It can be seen from it that , although Model-free This article baseline Ate all the apples , But at the expense of a lot of security .
and ReQueST The average agent can eat two of the three apples , And the number of falls off the cliff is only baseline One tenth of , Outstanding performance .
Judging from the difference between reward models , Reward sketch training ReQueST And sparse label training ReQueST The effect varies greatly .
Sparse label training ReQueST On average, you can't eat an apple .
It seems ,DeepMind and OpenAI There are indeed improvements in these two points .
Reference link :
[1]https://www.arxiv-vanity.com/papers/2201.08102/
[2]https://deepmind.com/blog/article/learning-human-objectives-by-evaluating-hypothetical-behaviours
边栏推荐
猜你喜欢

小程序直播 + 电商,想做新零售电商就用它吧!

Behind the cluster listing, to what extent is the Chinese restaurant chain "rolled"?
【大型电商项目开发】性能压测-优化-中间件对性能的影响-40
资深测试/开发程序员写下无bug?资历(枷锁)不要惧怕错误......
Pycharm professional download and installation tutorial
Redis(1)之Redis简介

测试部新来了个00后卷王,上了年纪的我真的干不过了,已经...

Four pits in reentrantlock!
Take you ten days to easily complete the go micro service series (IX. link tracking)

POAP:NFT的采用入口?
随机推荐
Global and Chinese market of optical densitometers 2022-2028: Research Report on technology, participants, trends, market size and share
Poap: the adoption entrance of NFT?
微信小程序:星宿UI V1.5 wordpress系统资讯资源博客下载小程序微信QQ双端源码支持wordpress二级分类 加载动画优化
微信小程序:微群人脉微信小程序源码下载全新社群系统优化版支持代理会员系统功能超高收益
Yyds dry goods inventory [Gan Di's one week summary: the most complete and detailed in the whole network]; detailed explanation of MySQL index data structure and index optimization; remember collectio
Global and Chinese market of veterinary thermometers 2022-2028: Research Report on technology, participants, trends, market size and share
Introduction to the gtid mode of MySQL master-slave replication
User login function: simple but difficult
Heartless sword English translation of Xi Murong's youth without complaint
[pure tone hearing test] pure tone hearing test system based on MATLAB
BGP comprehensive experiment
多模输入事件分发机制详解
Database postragesql lock management
SAP UI5 应用的主-从-从(Master-Detail-Detail)布局模式的实现步骤
Digital DP template
JS implementation determines whether the point is within the polygon range
"Upside down salary", "equal replacement of graduates" these phenomena show that the testing industry has
Postman automatically fills headers
Package What is the function of JSON file? What do the inside ^ angle brackets and ~ tilde mean?
Database postragesq peer authentication