当前位置:网站首页>一个简单LEGv8处理器的Verilog实现【四】【单周期实现基础知识及模块设计讲解】
一个简单LEGv8处理器的Verilog实现【四】【单周期实现基础知识及模块设计讲解】
2022-07-07 12:11:00 【凳子花*】
一、前言
原本思路是想把单周期实现的各个模块的原理先讲解一下,然后再开其它的博客来讲解各个模块的Verilog设计,但是我后来想了一下,这样子不方便大家理解,看到后面可能也忘了要实现的模块的功能。所以讲解模式修改为:边讲原理,边为大家展示Verilog实现,这样也可以加深理解。此外,除了讲解模块设计思想,还会把设计过程中用到的一些Verilog语法和规范给大家也讲解一下(这些内容都是以脚下留心这四个字开头的,并且高亮了,像这样:脚下留心)。
本篇博客解释实现一个处理器所需的原理和技术。当然目前设计的只是处理器的一种单周期实现,后续还会有更真实的流水线式的LEGv8实现。关于流水线和单周期的区别也将在后面进行讲解。
注: 由于不想分P太多,所以我打算把单周期实现写到一篇博客中来,而且还会有很多代码在里面,这会导致内容很多,所以大家学习一篇的时间可能比较长。
二、模块原理与设计
(一)指令分析
下面我们将要完成一种包含LEGv8核心指令集的一个实现,该实现是针对一个简单LEGv8处理器的Verilog实现【一】【实验简介】中提到的求阶乘和排序算法来选择指令完成的。一个简单LEGv8处理器的Verilog实现【二】【基础知识与实验分析】这篇博客对要实现的两个算法讲解了对应的LEGv8程序,用到的LEGv8指令总结如下:
在上述两个函数中用到的指令有:ADD、LSL、BR、ADDI、SUBI、SUBIS、STUR、LDUR、B、BL、B.GE、B.LT、B.LE、MUL、CMP、MOV。其中MOV和CMP属于伪指令。将上述指令组合成一个新的指令集如下:
| Instruction | Opcode | Opcode Size | 11-bit opcode range | 11-bit opcode range | Instruction Format |
|---|---|---|---|---|---|
| Start | end | ||||
| ADD(MOV) | 10001011000 | 11 | 112 | R | |
| LSL | 11010011011 | 11 | 1691 | R | |
| BR | 11010110000 | 11 | 1712 | R | |
| SUBS(CMP) | 11101011000 | 11 | 1880 | R | |
| ADDI | 1001000100 | 10 | 1160 | 1161 | I |
| SUBI | 1101000100 | 10 | 1672 | 1673 | I |
| SUBIS | 1111000100 | 10 | 1928 | 1929 | I |
| STUR | 11111000000 | 11 | 1984 | D | |
| LDUR | 11111000010 | 11 | 1986 | D | |
| B | 000101 | 6 | 160 | 191 | B |
| BL | 100101 | 6 | 1184 | 1215 | B |
| B.cond | 01010100 | 8 | 672 | 679 | CB |
这里将MOV指令当做ADD指令来实现,CMP指令当做SUBS指令来实现。 在实现过程中,除了上述指令外,还扩展了一些其他类似的简单指令,等用到的时候再讲。
(二)实现概述
在第二篇博客中,我们讲解了LEGv8指令集的6类指令,这里再复习一下:R型(算术运算指令格式,如ADD、AND、LSL、BR等)、I型(立即数格式,如ADDI、ORRI等)、D型(数据传输格式,如LDUR、STUR等)、B型(无条件分支格式,B和BL)、CB型(条件分支格式,B.cond、CBZ、CBNZ)和IM型(宽立即数格式,MOVZ、MOVK)。在我们的实验中,只关心前5类。有不知道的去看第二篇:一个简单LEGv8处理器的Verilog实现【二】【基础知识与实验分析】。
这些指令实现的前两步都是相同的:
1、程序计数器(PC)指向指令所在的存储单元,并从中取出指令 。
2、通过指令字段的内容,选择读取一个或两个寄存器。对于LDUR和CBZ指令,只需读取一个寄存器,而其他大多数指令需要读两个寄存器。
这两步之后,为完成指令而进行的步骤取决于具体的指令类型。幸运的是,对三种指令类型(存储访问、算术逻辑、分支)的每一类而言,其动作大致相同,与具体指令无关。
LEGv8指令集的简洁和规整使许多指令的执行很相似,因而简化了实现过程。 例如,除无条件分支(跳转)指令外的所有指令,在读取寄存器后,都要使用算术逻辑单元(ALU)。存储访问指令用ALU计算地址,算术逻辑指令用ALU执行操作,分支指令用ALU与0进行比较。
在使用ALU之后,完成不同指令所需的动作就有所不同了。存储访间指令需要访问内存以便读取或存储数据。算术逻辑指令或取数指令将来自ALU或存储器的数据写入寄存骈。最后,对于条件分支指令,需要根据比较的结果决定是否改变下一条指令地址;如果不修改,则将PC加4获得顺序的下一条指令。
尽管指令之间的执行存在差异,但我们仍然将指令的执行过程分为5个阶段,分别是:取指(Instruction Fetch,IF)、译码(Instruction Decode,ID)、执行(Executation,EX)、存储(Memory,MEM)和写回(Write Back,WB)。这5个阶段贯穿我们设计始终,非常重要。
本次设计要实现的CPU顶层如下图所示: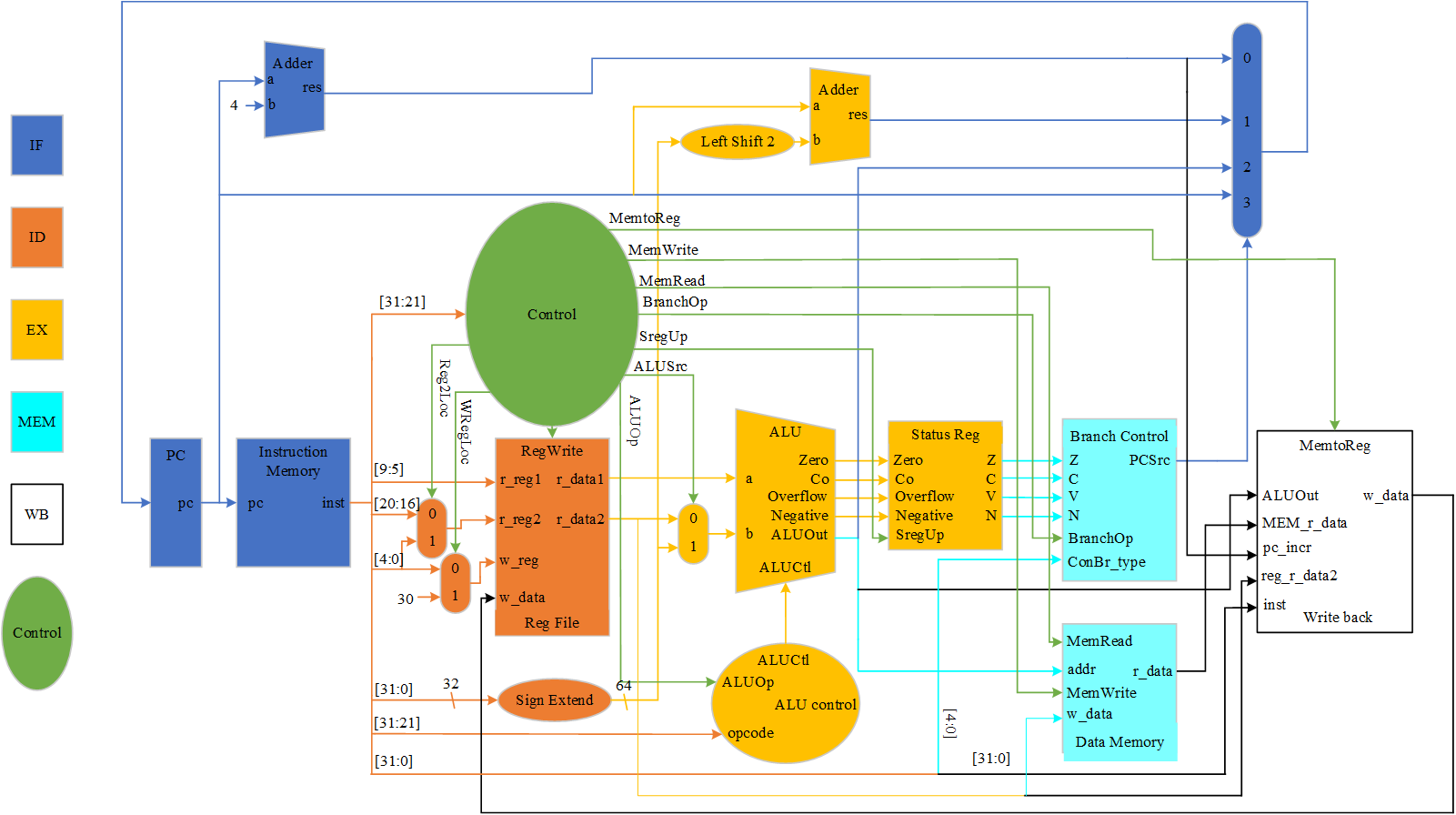
图1 LEGv8 CPU顶层
上图为LEGv8实现的视图,描述了各功能单元及其互联。所有指令的执行都开始于使用程序计数器PC获得指令在指令存储器中的地址,即取指IF。取到指令后,指令所使用的寄存器操作数由指令中的对应字段决定(译码ID),在取到寄存器操作数之后,可以用来计算存储器地址(对于存取类指令), 或者计算算术运算结果(对于整数算术逻辑类指令),或者与0进行比较(对于分支类指令)(执行EX)。 如果指令是算术逻辑指令,ALU的结果必须写回寄存器(写回WB)。如果是存取类指令,ALU的结果可作为读写存储器的地址(存储MEM)。ALU或存储器的结果可写回寄存器文件(写回WB)。分支指令需要使用ALU的输出来决定下一个指令地址,该地址可能来自ALU(在ALU中将PC值与分支偏移量相加), 也可能来自一个加法器(当前PC值加4)(设计时把这一阶段放在存储阶段MEM级,因为要考虑后续冒险检测)。连接功能单元的线上的箭头用来指示信息流动的方向。
各个阶段在图中都以不同的颜色标出。
此外,图中功能单元的控制是依赖于指令类型的。例如, load指令读数据存储器,而store指令写数据存储器。寄存器文件只在取数指令和算术逻辑指令时写入。很显然,ALU根据不同的指令执行不同的操作(后面会描述ALU的设计细节)。 类似于多路选择器,这些操作都由控制信号确定,而控制信号由指令的某些字段所决定。图中的控制单元(control unit)以指令为输入,决定如何设置功能单元和两个多选器的控制信号。
(三)模块设计
1、头文件
在讲解其他模块设计之前,我们先讲解一下各个模块所需的头文件,即代码中的common.vh。
脚下留心: 在这次设计中,我把所需要的一些信息全部放入到了一个头文件中。但事实上,在你进行设计时,你可以根据模块的需要,把所需内容放到不同的文件中,即多个头文件。(类似于C语言,可以一个模块写一个头文件)。
common.vh如下:
`ifndef COMMON_HEADER
`define COMMON_HEADER
//*******************************
// Definition of data type
//*******************************
// Size of a WORD
`define WORD 64
// Size of a HALF_WORD
`define HALF_WORD 32
// Length of instructions
`define INST_SIZE `HALF_WORD
//*******************************
// Definition of file path
//*******************************
/
// Single Cycle Factorial
// Instruction memory file
`define SINGLE_CYCLE_FACT_INST_FILE "data/factorial/SingleCycle/inst_mem.txt"
// Data file
`define SINGLE_CYCLE_FACT_DATA_FILE "data/factorial/SingleCycle/data_mem.txt"
// Pipeline Factorial
// Instruction memory file
`define PIPELINE_FACT_INST_FILE "data/factorial/Pipeline/inst_mem.txt"
// Data file
`define PIPELINE_FACT_DATA_FILE "data/factorial/Pipeline/data_mem.txt"
/
// Single Cycle Bubble Sort
// Instruction memory file
`define SINGLE_CYCLE_SORT_INST_FILE "data/bubble_sort/SingleCycle/inst_mem.txt"
// Data file
`define SINGLE_CYCLE_SORT_DATA_FILE "data/bubble_sort/SingleCycle/data_mem.txt"
// Data file TB sorted
`define SINGLE_CYCLE_SORT_DATA_FILE_TB "data/bubble_sort/SingleCycle/data_mem_tb_sorted.txt"
// Pipeline Bubble Sort
// Instruction memory file
`define PIPELINE_SORT_INST_FILE "data/bubble_sort/Pipeline/inst_mem.txt"
// Data file
`define PIPELINE_SORT_DATA_FILE "data/bubble_sort/Pipeline/data_mem.txt"
// Data file TB sorted
`define PIPELINE_SORT_DATA_FILE_TB "data/bubble_sort/Pipeline/data_mem_tb_sorted.txt"
/
// Bubble sort test 0
// Instruction memory file
`define SORT_INST_FILE "data/bubble_sort/0/inst_mem.txt"
// Data file
`define SORT_DATA_FILE "data/bubble_sort/0/data_mem.txt"
/
// Test
// Instruction memory file
`define TEST_INST_FILE "data/test/inst_mem.txt"
// Data memory for test
`define TEST_DATA_FILE "data/test/data_mem.txt"
//*******************************
// Definition of instruction opcode
//*******************************
`define ADD 11'b10001011000
`define ADDI 11'b1001000100?
`define ADDS 11'b10101011000
`define ADDIS 11'b1011000100?
`define AND 11'b10001010000
`define ANDI 11'b1001001000?
`define ANDS 11'b11101010000
`define ANDIS 11'b1111001000?
`define B 11'b000101?????
`define BL 11'b100101?????
`define BR 11'b11010110000
`define BCOND 11'b01010100???
`define CBZ 11'b10110100???
`define CBNZ 11'b10110101???
`define CMPI 11'b1100001110?
`define DIV 11'b10011010110
`define EOR 11'b11001010000
`define EORI 11'b1101001000?
`define LDURS 11'b10111100010
`define STURS 11'b10111100000
`define LDURD 11'b11111100010
`define STURD 11'b11111100000
`define LDA 11'b10010110101
`define LDUR 11'b11111000010
`define LDURB 11'b00111000010
`define LDURH 11'b01111000010
`define LDURSW 11'b10111000100
`define LSL 11'b11010011011
`define LSR 11'b11010011010
`define MOVK 11'b111100101??
`define MOVZ 11'b110100101??
`define MUL 11'b10011011000
`define ORR 11'b10101010000
`define ORRI 11'b1011001000?
`define STUR 11'b11111000000
`define STURB 11'b00111000000
`define STURH 11'b01111000000
`define STURW 11'b10111000000
`define SUB 11'b11001011000
`define SUBI 11'b1101000100?
`define SUBS 11'b11101011000
`define SUBIS 11'b1111000100?
//*******************************
// Conditional branch rt values
//*******************************
`define BCOND_NV 5'b00000 // Always, NV exists only to provide a valid disassembly of the ‘00000b’ encoding, and otherwise behaves identically to AL.
`define BCOND_EQ 5'b00001 // Equal, Z == 1
`define BCOND_NE 5'b00010 // Not equal, Z == 0
`define BCOND_CS 5'b00011 // AKA HS, Unsigned higher or same( Carry set ), C == 1
`define BCOND_LE 5'b00100 // Signed less than or equal, !( Z == 0 && N == V )
`define BCOND_CC 5'b00101 // AKA LO, unsigned lower( Carry clear ), C == 0
`define BCOND_MI 5'b00111 // Minus( negative ), N == 1
`define BCOND_PL 5'b01000 // Plus( positive or zero ), N == 0
`define BCOND_VS 5'b01001 // Overflow set , V == 1
`define BCOND_VC 5'b01010 // Overflow clear, V == 0
`define BCOND_HI 5'b01011 // Unsigned higher, C == 1 && Z == 0
`define BCOND_LS 5'b01100 // Unsigned lower or same, !( C == 1 && Z == 0 )
`define BCOND_GE 5'b01101 // Signed greater than or equal, N == V
`define BCOND_LT 5'b01110 // Signed less than, N != V
`define BCOND_GT 5'b01111 // Signed greater than, Z == 0 && N == V
`define BCOND_AL 5'b11111 // Always
//*******************************
// Conditional branch ops
//*******************************
`define BCOND_OP_NONE 3'b000
`define BCOND_OP_BRANCH 3'b001
`define BCOND_OP_COND 3'b010
`define BCOND_OP_ZERO 3'b011
`define BCOND_OP_NZERO 3'b100
`define BCOND_OP_ALU 3'b101
`define BCOND_OP_NOINC 3'b110
//*******************************
// ALU control signals
//*******************************
`define ALU_AND 4'b0000
`define ALU_OR 4'b0001
`define ALU_ADD 4'b0010
`define ALU_MUL 4'b0011
`define ALU_SUB 4'b0110
`define ALU_PASS 4'b0111
`define ALU_NOR 4'b1100
`define ALU_XOR 4'b0100
`define ALU_LSL 4'b1000
`define ALU_LSR 4'b1001
`define ALU_NONE 4'b1111
`define TB_BEGIN \
$display("\n========= BEGIN TESTBENCH %m =========\n");
`define TB_END \
#`CYCLE $display("\n========== END TESTBENCH %m =========\n");
`define CYCLE 10
`define HALF_CYCLE (`CYCLE/2)
`endif
首先映入眼帘的是这两句:
`ifndef COMMON_HEADER
`define COMMON_HEADER
......
`endif
脚下留心: 经常写C/C++的同学应该知道,这是为了防止头文件的重复包含。
继续看代码,后面基本都是这种格式:
//*******************************
// 注释
//*******************************
内容... // 注释
脚下留心: 大家以后写代码也可以按照这种格式,上面先来段注释讲清楚下面的内容是什么,然后再写具体内容,具体内容后面又可以跟一些更加详细的注释。毕竟俗话说得好:代码过了一个月,只有你自己和老天能看懂;过了三个月,就只有老天能看懂了;再过三个月,谁来都不好使。所以大家一定要养成写注释的好习惯!!!
下面来介绍该头文件的内容:
Definition of data type下面是一些数据位宽的定义,我们要实现的LEGv8处理器是32位指令,但是是64位的地址,所以在这里,定义一个字为64位,半字为32位。同时定义指令位宽为半字。
Definition of file path下面是一些文件路径的定义,定义了我们最终使用到的指令文件和数据文件等。
脚下留心: 如果我们代码中多次用到了一些东西,不妨通过宏定义来简化代码,增加可读性。
Definition of instruction opcode下面是LEGv8指令集中各指令的操作码opcode,事实上我们并不需要定义这么多指令操作码,只要定义用到的指令即可。但是为了方便后续进行指令拓展,所以我这里把大部分指令操作码都定义好了。opcode不是我们自己定义的,可以直接在课本中查到,打开英文版课本,翻到倒数第二页就能看到: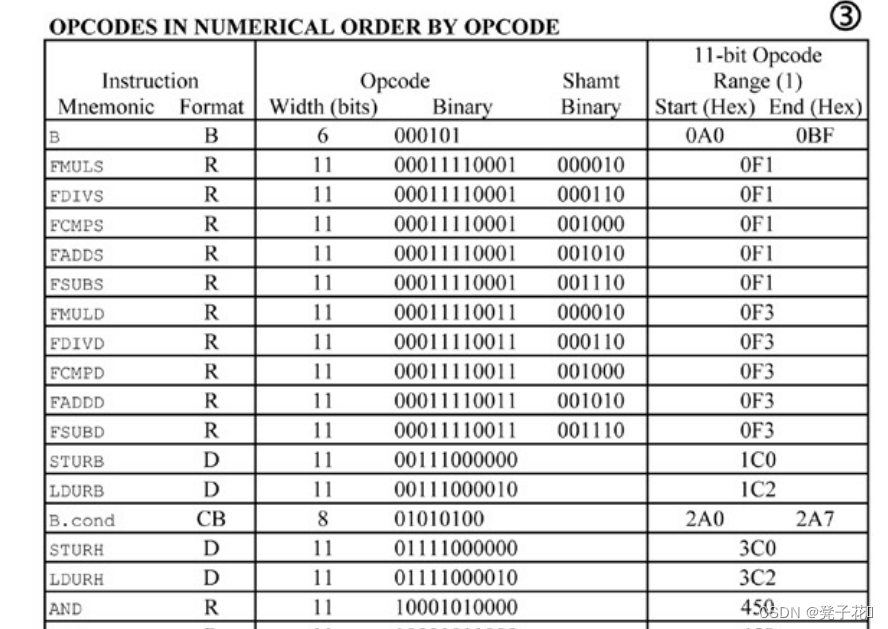
脚下留心: 仔细观察一下代码可以发现,对于opcode不是11位的指令来说,定义中用到了很多???,表示不关心这些位。
Conditional branch rt values下面是条件分支判断码,用于B.cond指令判断是否需要进行跳转。这些定义你可以人为赋值进行定义,但事实上,ARMv8处理器中早已经定义好了: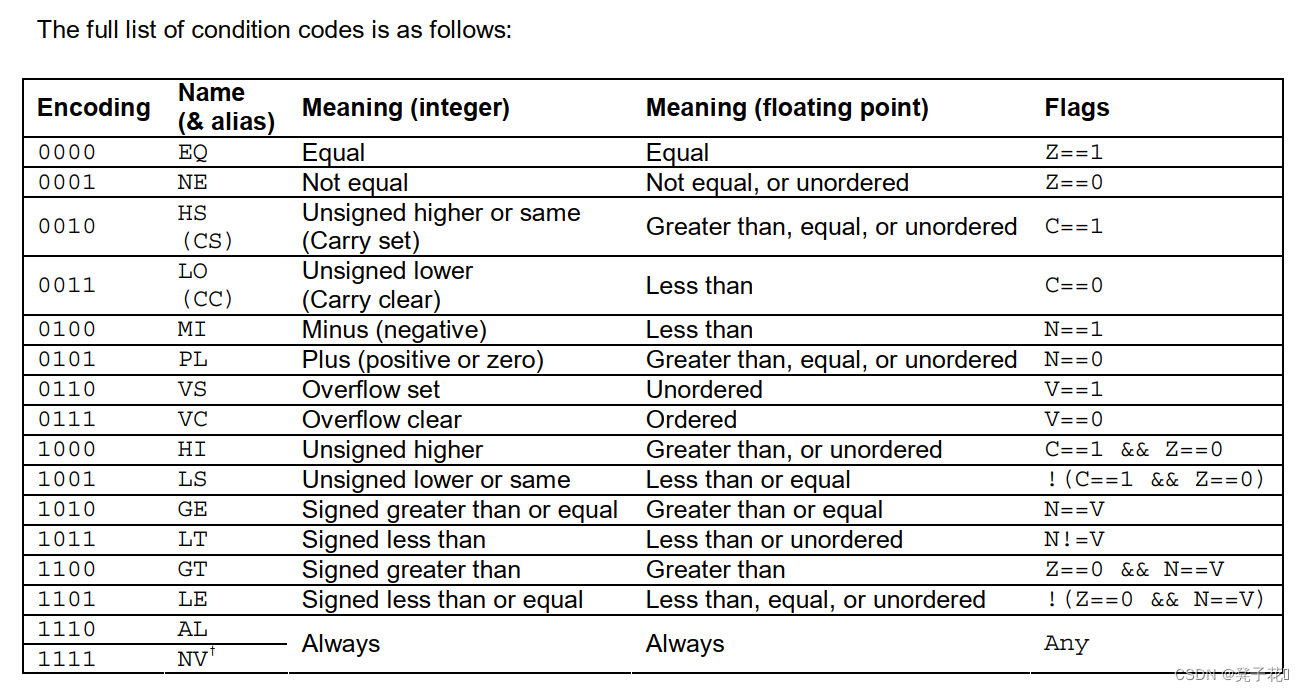
上图是我在网上搜到的ARM_v8_Instruction_Set_Architecture_(Overview).pdf中找到的,感兴趣的同学可以自己搜一下,但这个pdf对我们实现没有太大帮助,所以我没有给大家放到网盘中。看上图足矣。
细心的同学会发现我代码中的定义和上图中定义不一样,是的,我用的自己的定义hhh,不是很规范,有需要的同学可以试着改改。而且我这里用了5位来定义,主要是因为B.cond指令中的rt是5位的,正好匹配。(什么?你问我这和rt有什么关系?这就没好好看了奥,一个简单LEGv8处理器的Verilog实现【二】【基础知识与实验分析】这篇文章讲解B.cond的时候有说到,忘记的同学回去看看)。
Conditional branch ops主要是定义了一些用于判断条件跳转类型的值。这个后面讲代码设计的时候再具体解释。
ALU control signals下面主要是定义了一些ALU控制信号,控制ALU到底是执行加减乘除还是什么操作。
最后就是一些TB中的宏定义,方便操作。
2、多路选择器模块
讲解完头文件,继续回来看图1。在图1中发现有这样几个模块: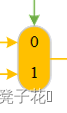
这种模块的输入数据来自两个或者多个不同的源。例如,写入PC的值可能来自两个加法器中的一个,写入寄存器文件的数据可能来自ALU或者数据存储器,而ALU的第二个输入可能来自寄存器或指令中的立即数字段。实际上,这些数据线不能简单地直接连在一起,必须增加一个逻辑单元用以从不同的数据来源中选择一个并送给目标单元。
这种选择操作通常可由一个称为多路选择器(multiplexor)的器件完成,尽管该单元叫数据选择器(data selector)可能更合适。多路选择器通过设置控制信号选择不同输入,控制信号主要根据当前执行指令中包含的信息设定。
从图1可以看到,我们实际上用到了两种多路选择器,分别是二选一多路选择器和四选一多路选择器,我们通过MUX2和MUX4表示。对于MUX2来说,输入有两个数据信号,和一个控制信号,输出是被选择的数据,所以控制信号只需要1位(通过0和1选择)即可。MUX4的输入有4个输入数据,一个控制信号,输出也是一个被选择的数据,所以控制信号需要2位(通过这两位信号组合分别是00/01/10/11)来选择。请注意上面所说的输入数据的位数我们并没有特殊强调,所以理论上可以是任意位,没有特殊要求,但选择信号位数一般是固定的。
MUX2的Verilog代码如下(文件名为mux2.v):
`timescale 1ns/1ps
//******************************************************************
//
//*@File Name: mux2.v
//
//*@File Type: verilog
//
//*@Version : 0.0
//
//*@Author : Zehua Dong, SIGS
//
//*@E-mail : [email protected]
//
//*@Date : 2022/3/28 22:53:07
//
//*@Function : 2-1 multiplexer.
//
//******************************************************************
//
// Header file
`include "common.vh"
//
// Module
module mux2 #(
parameter SIZE = `WORD )(
a ,
b ,
sel ,
out
);
input [SIZE - 1 : 0] a ;
input [SIZE - 1 : 0] b ;
input sel;
output [SIZE - 1 : 0] out;
wire [SIZE - 1 : 0] a ;
wire [SIZE - 1 : 0] b ;
wire sel;
wire [SIZE - 1 : 0] out;
assign out = sel ? b : a;
endmodule
通过GVIM写Verilog的流程在一个简单LEGv8处理器的Verilog实现【三】【工具使用和编程规范】中已经讲解过了,所以这里不再赘述。
脚下留心: 首先第一行是`timescale 1ns/1ps,这句是很重要的,定义了你仿真时的步长和精度,建议每个模块都写上这句话。具体理解可以看:对`timescale的深入理解。
脚下留心: 写代码时,首先在开始给出注释头,表明作者、Email、文件修改历史等信息。这些都不需要手动敲,我在讲解GVIM模板时就给出了我的模板,大家直接改改就能用。参照:gvim【二】【ab命令快速制作verilog模板】.
脚下留心: 看代码格式,首先包含头文件,然后写模块端口时注意尽量让一个端口一行,并进行对齐,这样写有助于你后面进行例化,此外还可以很清晰的显示出你有哪些端口,每个端口后面还可以很方便的添加注释。端口在写的时候尽量集中一些,什么意思呢,就是先写输入端口,然后再写输出端口,例如下面:
module mux2 #(
parameter SIZE = `WORD )(
a ,
b ,
sel ,
out
);
a, b, sel都是输入,写到一起,out是输出,写到最后。当然这个不是固定的,只是我的习惯,大家可以根据自己需要进行调整。
细心的同学会发现上面的端口后面的逗号都是列对齐的,事实上,是否采用这种做法根据你的平台来决定。对于某些Linux中的工具,可能会把空格识别为你的端口名,但如果Windows的Vivado或者ModelSim则不会有这种问题。所以大家根据自己的平台决定。
那么为什么要加那么多空格列对齐呢,这样不是更麻烦吗?答案有两个:一是美观,对齐之后看着很好看,适合强迫症,当然这没有太大作用;二是方便后续代码编写,当你写input、output的时候可以进行列操作,写例化模块的时候也可以进行列操作…所以我建议可以对齐,具体请看:gvim【二】【ab命令快速制作verilog模板】中的演示。
脚下留心: 此外,上面的代码还用到了参数parameter,这种写法可以用来进行参数例化,即后面可以在例化时指定参数的值,非常方便,建议掌握。这里我们将输入输出数据的位宽都设置为参数SIZE,后面例化可以指定为64bit或者其他bit。参数例化还有其他写法,大家可以自行百度一下,不想百度也可,直接记住我上面的写法就够用。
脚下留心: 在写端口时建议大家按照我那种写法来,即模块端口只有名字,而不声明输入输出和位宽等,例如这样:
module mux2 #(
parameter SIZE = `WORD )(
input [63:0] a ,
input [63:0] b ,
input sel ,
output [63:0] out
);
这样写也可以,但是有些编译器可能不支持这种写法,输出的类型也容易出错漏掉,而且万一出错了是很难发现错误的。
格式讲解完了,接下来就是代码实现,其实mux2很简单,就一行核心语句。
assign out = sel ? b : a;
脚下留心: 这里用到了三目运算符,即? : ,这种写法可能会经常用到,建议掌握。其意思为:?前面的条件是否为真,如果是则输出:前面的值,否则输出:后面的值。所以这句代码的意思是如果sel为1,则out为b,否则out为a。
当然,你也可以用下面这种方式来实现这个二选一多路选择器:
if(sel == 1'b0)
out = a;
else
out = b;
这段代码的意思是如果sel为0则out为a,否则out为b。但是这样写有个缺点就是,在判断sel为0的时候用到了比较器,也就是代码中的==可能会被综合成比较器,比较器占用的面积是比较大的。所以可以这样写:
if(!&sel)
out = a;
else
out = b;
&在Verilog中表示按位与,!表示逻辑反,也可以使用~按位取反。逻辑反的意思是无论sel是多少位,最后的结果都只能是1位;按位取反之后的结果的位数与原来的数据位数相同。
那么为什么这么写要比直接写比较器好呢?这是因为!&sel只用到了一个与门和非门,这两的面积远远小于比较器面积。当然这只是理想情况下的示例,实际上在综合的时候可能会自动优化代码,但大家还是要有这种思想。
呼~ ,一个小小的mux2就讲了这么久~,但这是因为我们才第一个代码,需要讲的格式比较多,后面就会比较少介绍格式啦。
接下来讲一下mux4:
`timescale 1ns/1ps
//******************************************************************
//*@File Name: mux4.v
//*@File Type: verilog
//*@Version : 0.0
//*@Author : Zehua Dong, SIGS
//*@E-mail : [email protected]
//*@Date : 2022/3/29 20:26:55
//*@Function : 4-1 multiplexer.
//******************************************************************
//
// Header file
`include "common.vh"
//
// Module
module mux4 #(
parameter SIZE = `WORD )(
a ,
b ,
c ,
d ,
sel ,
out
);
input [SIZE - 1 : 0] a ;
input [SIZE - 1 : 0] b ;
input [SIZE - 1 : 0] c ;
input [SIZE - 1 : 0] d ;
input [1:0] sel;
output [SIZE - 1 : 0] out;
wire [SIZE - 1 : 0] a ;
wire [SIZE - 1 : 0] b ;
wire [SIZE - 1 : 0] c ;
wire [SIZE - 1 : 0] d ;
wire [1:0] sel;
reg [SIZE - 1 : 0] out;
always @(*) begin
case( sel )
2'b00: out = a;
2'b01: out = b;
2'b10: out = c;
2'b11: out = d;
default: out = 'b0;
endcase
end
endmodule
mux4设计和mux2类似,只不过输入端口变成了4个数据和1个两位的选择信号。不过此次在进行选择的时候我们没有用三目运算符,而是另一种写法case。case是一种没有优先级的判断结构,当然你也可以用if…else…,但是建议这里用case语句。具体if…else…和case综合出来的电路区别请看:书写Verilog 有什么奇技淫巧。
脚下留心: 这里要注意case语句一定要跟上default,不然综合出来的就可能会是锁存器,锁存器会导致我们的功能不正确,所以一定要养成好习惯。还有if语句用于组合逻辑中时,后面一定要跟上else语句;用于时序逻辑也建议跟上,当然等你后面写熟练了,可能就不需要了。
注: 此处建议大家关注一下上面这个链接的公众号,我没有收到广告费,也不认识他,但是他的内容很适合我们进行学习,而且每篇文章质量也可以,所以大家可以多看看多学习。
(* ̄︶ ̄)~ mux4讲解结束,怎么样,是不是很简单︿( ̄︶ ̄)︿
PC模块
单周期与流水线区别
单周期CPU每条指令使用一个较长的时钟周期,并遵循图1中的一般形式。在本次设计中,每条指令在一个时钟沿上开始执行,并在下一个时钟沿完成。尽管这种方法易千理解,但是并不实际,因为时钟周期必须延长以满足执行时间最长的指令。在实现了这种简单计算机的控制后,我们将会讨论一种流水的实现方式及其带来的复杂性。
注: 这里很重要,有些同学死活理解不了单周期和流水线的区别,因为后面可以看到单周期实现过程中事实上也是用到了D触发器的(例如PC或者寄存器堆)。有些同学可能就会想当然认为一条指令是在多个周期内完成的,这当然是不对的,对CPU指令执行时的时序理解还是不深刻。
好的,本节就先讲到这里,如果你有收获且乐意的话,麻烦点个赞哦,收藏也可以哇( ̄▽ ̄)~*
博客结构安排
本系列博客共分为5篇:
第一篇对一些处理器基础知识进行简单讲解,并讲清楚实验要求。
第二篇从指令、寄存器、汇编器的角度对设计处理器所需要的基础知识进行较为详细的讲解,并对实验所需汇编程序进行了分析。
第三篇讲解数字IC设计所需要的一些工具以及使用方法,并讲解了一些编程规范。
第四篇主要是针对单周期CPU的基础理论和模块设计进行讲解,在讲Verilog实现的时候,顺带讲了很多编程规范。
本系列其他博客
- 一个简单LEGv8处理器的Verilog实现【一】【实验简介】
- 一个简单LEGv8处理器的Verilog实现【二】【基础知识与实验分析】
- 一个简单LEGv8处理器的Verilog实现【三】【工具使用和编程规范】
- 一个简单LEGv8处理器的Verilog实现【四】【单周期实现基础知识及模块设计讲解】
源码下载
参考资料
- 《MK.Computer.Organization.and.Design.The.Hardware.Software.Interface.ARM.Edition》
参考资料下载
链接:https://pan.baidu.com/s/1dtpFTsJ5fdEmnPDyX66U1Q
提取码:b26b
边栏推荐
- mysql ”Invalid use of null value“ 解决方法
- Selenium库
- 【日常训练】648. 单词替换
- Enregistrement de la navigation et de la mise en service du robot ROS intérieur (expérience de sélection du rayon de dilatation)
- 2022-7-6 Leetcode 977.有序数组的平方
- IP and long integer interchange
- When FC connects to the database, do you have to use a custom domain name to access it outside?
- What parameters need to be reconfigured to replace the new radar of ROS robot
- 118. 杨辉三角
- The delivery efficiency is increased by 52 times, and the operation efficiency is increased by 10 times. See the compilation of practical cases of financial cloud native technology (with download)
猜你喜欢
Redis can only cache? Too out!
2022-7-6 Leetcode 977. Square of ordered array

为租客提供帮助
Indoor ROS robot navigation commissioning record (experience in selecting expansion radius)

2022-7-6 使用SIGURG来接受外带数据,不知道为什么打印不出来
Selenium库
2022-7-6 sigurg is used to receive external data. I don't know why it can't be printed out

docker部署oracle

Flask session forged hctf admin

社会责任·价值共创,中关村网络安全与信息化产业联盟对话网信企业家海泰方圆董事长姜海舟先生
随机推荐
Co create a collaborative ecosystem of software and hardware: the "Joint submission" of graphcore IPU and Baidu PaddlePaddle appeared in mlperf
Dry goods | summarize the linkage use of those vulnerability tools
请问指南针股票软件可靠吗?交易股票安全吗?
2022-7-6 Leetcode 977. Square of ordered array
Solve the cache breakdown problem
LeetCode简单题分享(20)
【面试高频题】难度 2.5/5,简单结合 DFS 的 Trie 模板级运用题
Help tenants
IP address home location query full version
AutoCAD - how to input angle dimensions and CAD diameter symbols greater than 180 degrees?
What parameters need to be reconfigured to replace the new radar of ROS robot
Navicat run SQL file import data incomplete or import failed
When FC connects to the database, do you have to use a custom domain name to access it outside?
mysql ”Invalid use of null value“ 解决方法
Selenium库
2022-7-6 Leetcode27. Remove the element - I haven't done the problem for a long time. It's such an embarrassing day for double pointers
Drawerlayout suppress sideslip display
Excuse me, when using Flink SQL sink data to Kafka, the execution is successful, but there is no number in Kafka
FCOS3D label assignment
Excusez - moi, l'exécution a été réussie lors de l'utilisation des données de puits SQL Flink à Kafka, mais il n'y a pas de nombre dans Kafka