当前位置:网站首页>Spark TPCDS Data Gen
Spark TPCDS Data Gen
2022-07-06 17:31:00 【zhixingheyi_tian】
开启 Spark-Shell
$SPARK_HOME/bin/spark-shell --master local[10] --jars {PATH}/spark-sql-perf-1.2/target/scala-2.12/spark-sql-perf_2.12-0.5.1-SNAPSHOT.jar
Gen Data
Gen TCPDS Parquet
val tools_path = "/opt/Beaver/tpcds-kit/tools"
val data_path = "hdfs://{IP}:9000/tpcds_parquet_tpcds_kit_1_0/1"
val database_name = "tpcds_parquet_tpcds_kit_1_0_scale_1_db"
val scale = "1"
val p = scale.toInt / 2048.0
val catalog_returns_p = (263 * p + 1).toInt
val catalog_sales_p = (2285 * p * 0.5 * 0.5 + 1).toInt
val store_returns_p = (429 * p + 1).toInt
val store_sales_p = (3164 * p * 0.5 * 0.5 + 1).toInt
val web_returns_p = (198 * p + 1).toInt
val web_sales_p = (1207 * p * 0.5 * 0.5 + 1).toInt
val format = "parquet"
val codec = "snappy"
val useDoubleForDecimal = false
val partitionTables = false
val clusterByPartitionColumns = partitionTables
import com.databricks.spark.sql.perf.tpcds.TPCDSTables
spark.sqlContext.setConf(s"spark.sql.$format.compression.codec", codec)
val tables = new TPCDSTables(spark, spark.sqlContext, tools_path, scale, useDoubleForDecimal)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "call_center", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "catalog_page", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "customer", 6)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "customer_address", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "customer_demographics", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "date_dim", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "household_demographics", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "income_band", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "inventory", 6)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "item", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "promotion", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "reason", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "ship_mode", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "store", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "time_dim", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "warehouse", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "web_page", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "web_site", 1)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "catalog_sales", catalog_sales_p)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "catalog_returns", catalog_returns_p)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "store_sales", store_sales_p)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "store_returns", store_returns_p)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "web_sales", web_sales_p)
tables.genData(data_path, format, true, partitionTables, clusterByPartitionColumns, false, "web_returns", web_returns_p)
tables.createExternalTables(data_path, format, database_name, overwrite = true, discoverPartitions = partitionTables)
Gen TPCH ORC
import com.databricks.spark.sql.perf.tpch._
val tools_path = "/opt/Beaver/tpch-dbgen"
val format = "orc"
val useDoubleForDecimal = false
val partitionTables = false
val scaleFactor = "1"
val data_path = s"hdfs://{IP}:9000/tpch_${format}_${scaleFactor}"
val numPartitions =1
val databaseName = s"tpch_${format}_${scaleFactor}_db"
val clusterByPartitionColumns = partitionTables
val tables = new TPCHTables(spark, spark.sqlContext,
dbgenDir = tools_path,
scaleFactor = scaleFactor,
useDoubleForDecimal = useDoubleForDecimal,
useStringForDate = false)
spark.sqlContext.setConf("spark.sql.files.maxRecordsPerFile", "200000000")
tables.genData(
location = data_path,
format = format,
overwrite = true, // overwrite the data that is already there
partitionTables, // do not create the partitioned fact tables
clusterByPartitionColumns, // shuffle to get partitions coalesced into single files.
filterOutNullPartitionValues = false, // true to filter out the partition with NULL key value
tableFilter = "", // "" means generate all tables
numPartitions = numPartitions) // how many dsdgen partitions to run - number of input tasks.
// Create the specified database
sql(s"drop database if exists $databaseName CASCADE")
sql(s"create database $databaseName")
// Create metastore tables in a specified database for your data.
// Once tables are created, the current database will be switched to the specified database.
tables.createExternalTables(data_path, format, databaseName, overwrite = true, discoverPartitions = false)
创建Metadata
Parquet create database/tables
val tools_path = "/opt/Beaver/tpcds-kit/tools"
val data_path = "hdfs://10.1.2.206:9000/user/sparkuser/part_tpcds_decimal_1000/"
val database_name = "sr242_parquet_part_tpcds_decimal_1000"
val scale = "1000"
val useDoubleForDecimal = false
val format = "parquet"
val partitionTables = true
import com.databricks.spark.sql.perf.tpcds.TPCDSTables
val tables = new TPCDSTables(spark, spark.sqlContext, tools_path, scale, useDoubleForDecimal)
tables.createExternalTables(data_path, format, database_name, overwrite = true, discoverPartitions = partitionTables)
Arrow create database/tables
val data_path= "hdfs://{IP}:9000/{PATH}/part_tpcds_decimal_1000/"
val databaseName = "arrow_part_tpcds_decimal_1000"
val tables = Seq("call_center", "catalog_page", "catalog_returns", "catalog_sales", "customer", "customer_address", "customer_demographics", "date_dim", "household_demographics", "income_band", "inventory", "item", "promotion", "reason", "ship_mode", "store", "store_returns", "store_sales", "time_dim", "warehouse", "web_page", "web_returns", "web_sales", "web_site")
val partitionTables = true
spark.sql(s"DROP database if exists $databaseName CASCADE")
if (spark.catalog.databaseExists(s"$databaseName")) {
println(s"$databaseName has exists!")
}else{
spark.sql(s"create database if not exists $databaseName").show
spark.sql(s"use $databaseName").show
for (table <- tables) {
if (spark.catalog.tableExists(s"$table")){
println(s"$table has exists!")
}else{
spark.catalog.createTable(s"$table", s"$data_path/$table", "arrow")
}
}
if (partitionTables) {
for (table <- tables) {
try{
spark.sql(s"ALTER TABLE $table RECOVER PARTITIONS").show
}catch{
case e: Exception => println(e)
}
}
}
}
使用ALTER 修改meta 信息
val data_path= "hdfs://{IP}:9000/{PATH}/part_tpcds_decimal_1000/"
val databaseName = "parquet_part_tpcds_decimal_1000"
val tables = Seq("call_center", "catalog_page", "catalog_returns", "catalog_sales", "customer", "customer_address", "customer_demographics", "date_dim", "household_demographics", "income_band", "inventory", "item", "promotion", "reason", "ship_mode", "store", "store_returns", "store_sales", "time_dim", "warehouse", "web_page", "web_returns", "web_sales", "web_site")
spark.sql(s"use $databaseName").show
for (table <- tables) {
try{
spark.sql(s"ALTER TABLE $table SET LOCATION '$data_path/$table'").show
}catch{
case e: Exception => println(e)
}
}
边栏推荐
- Dell笔记本周期性闪屏故障
- mysql: error while loading shared libraries: libtinfo.so.5: cannot open shared object file: No such
- [Batch dos - cmd Command - Summary and Summary] - String search, find, Filter Commands (FIND, findstr), differentiation and Analysis of Find and findstr
- Windows installation mysql8 (5 minutes)
- 迈动互联中标北京人寿保险,助推客户提升品牌价值
- A brief history of deep learning (I)
- [Niuke] [noip2015] jumping stone
- NEON优化:log10函数的优化案例
- 随时随地查看远程试验数据与记录——IPEhub2与IPEmotion APP
- Mongodb client operation (mongorepository)
猜你喜欢

城联优品入股浩柏国际进军国际资本市场,已完成第一步
Boot - Prometheus push gateway use
![Explain in detail the matrix normalization function normalize() of OpenCV [norm or value range of the scoped matrix (normalization)], and attach norm_ Example code in the case of minmax](/img/87/3fee9e6f687b0c3efe7208a25f07f1.png)
Explain in detail the matrix normalization function normalize() of OpenCV [norm or value range of the scoped matrix (normalization)], and attach norm_ Example code in the case of minmax

重上吹麻滩——段芝堂创始人翟立冬游记
![[Niuke] [noip2015] jumping stone](/img/9f/b48f3c504e511e79935a481b15045e.png)
[Niuke] [noip2015] jumping stone

golang中的Mutex原理解析
动态规划思想《从入门到放弃》
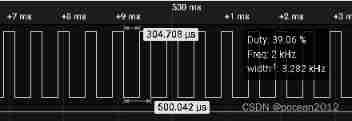
ESP Arduino (IV) PWM waveform control output
做微服务研发工程师的一年来的总结

Body mass index program, entry to write dead applet project
随机推荐
负载均衡性能参数如何测评?
Analysis of mutex principle in golang
Dynamic planning idea "from getting started to giving up"
Mongodb client operation (mongorepository)
mysql: error while loading shared libraries: libtinfo. so. 5: cannot open shared object file: No such
THREE.AxesHelper is not a constructor
[HFCTF2020]BabyUpload session解析引擎
Oracle:CDB限制PDB资源实战
「笔记」折半搜索(Meet in the Middle)
Oracle: Practice of CDB restricting PDB resources
Boot - Prometheus push gateway use
「精致店主理人」青年创业孵化营·首期顺德场圆满结束!
【JVM调优实战100例】05——方法区调优实战(下)
Taro中添加小程序 “lazyCodeLoading“: “requiredComponents“,
Part VI, STM32 pulse width modulation (PWM) programming
批量获取中国所有行政区域经边界纬度坐标(到县区级别)
[batch dos-cmd command - summary and summary] - jump, cycle, condition commands (goto, errorlevel, if, for [read, segment, extract string]), CMD command error summary, CMD error
Part 7: STM32 serial communication programming
系统休眠文件可以删除吗 系统休眠文件怎么删除
ARM裸板调试之JTAG调试体验