当前位置:网站首页>Yolov5 ajouter un mécanisme d'attention
Yolov5 ajouter un mécanisme d'attention
2022-07-05 05:17:00 【Maître ma.】
YOLOv5L'ajout d'un mécanisme d'attention peut être divisé en trois étapes:
1.common.pyAjouter un module d'attention
2.yolo.pyAjouter une condition de jugement
3.yamlAjouter le module approprié au fichier
Un.、CBAMAjout de mécanismes d'attention
(1)Incommon.pyAjouter unCBAMModule
1.Ouvre.modelsDans le dossiercommon.pyDocumentation
2.Mettez ce qui suitCBAMC3Copier et coller le code danscommon.pyDans le document
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
# écriture II,Les contenants séquentiels peuvent également être utilisés
# self.sharedMLP = nn.Sequential(
# nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
# nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return torch.mul(x, out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avg_out, max_out], dim=1)
out = self.sigmoid(self.conv(out))
return torch.mul(x, out)
class CBAMC3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAMC3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = ChannelAttention(c2, 16)
self.spatial_attention = SpatialAttention(7)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
# Changer le dernier module de convolution standard en un mécanisme d'attention pour extraire les caractéristiques
return self.spatial_attention(
self.channel_attention(self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))))
Comme le montre la figure ci - dessous, Cet article le colle ici à common.pyFin de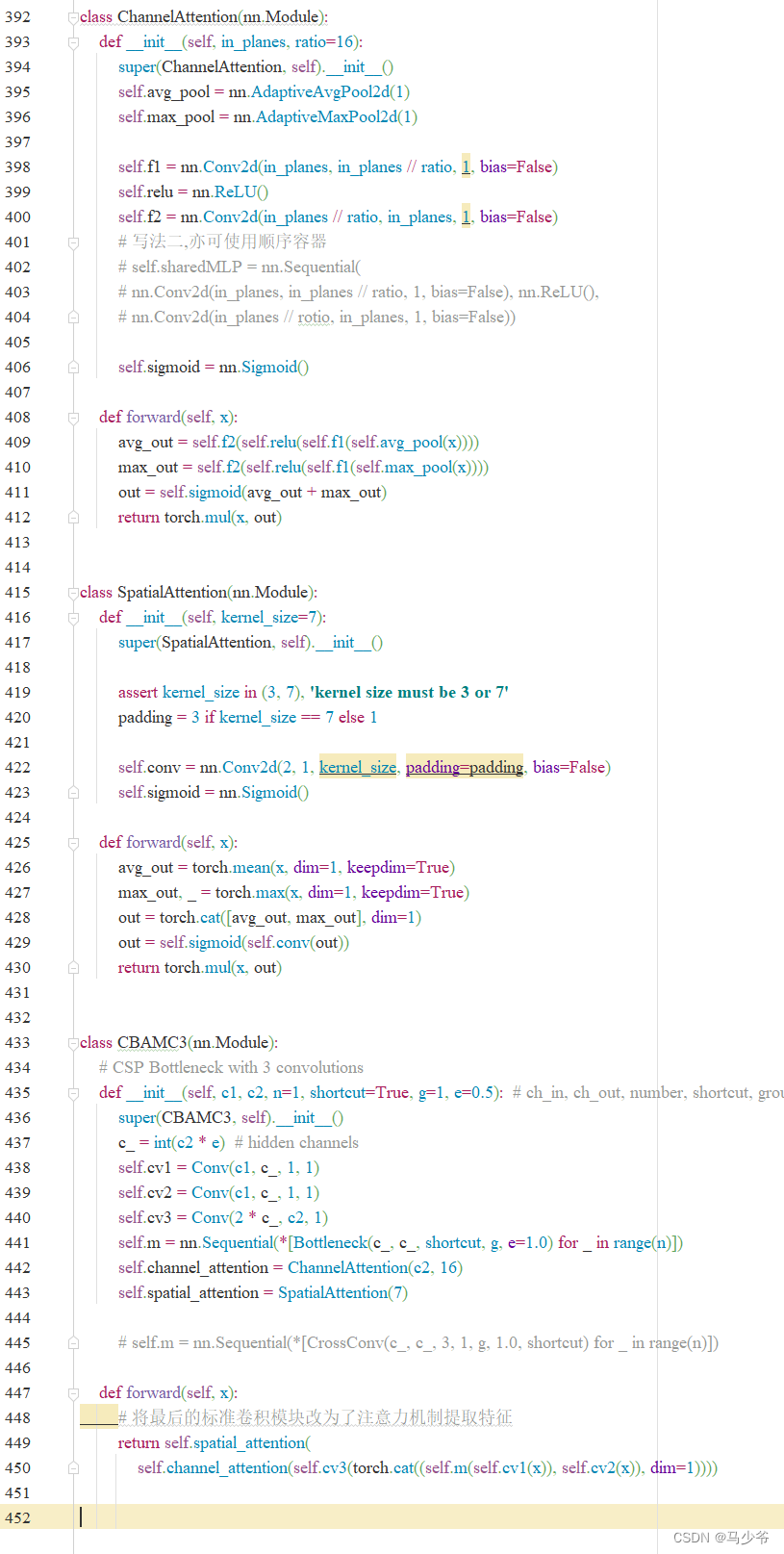
(2)Versyolo.pyAjout de fichiersCBAMC3Déclaration de jugement
1.Ouvre.modelsDans le dossieryolo.pyDocumentation
2.Séparément dans239Ligne et245Ajouter une ligneCBAMC3,Comme le montre la figure ci - dessous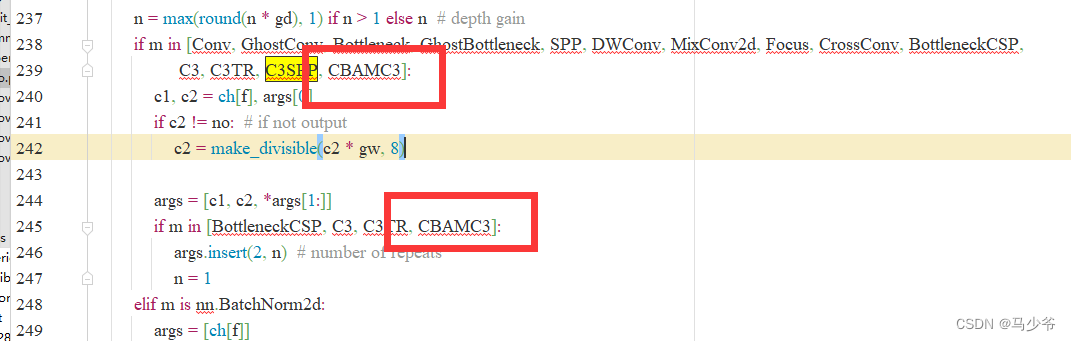
Encore une fois, n'oubliez pas de cliquer sur Save
3)ModifieryamlDocumentation
Le mécanisme d'attention peut être ajouté à backbone,Neck,HeadSection equivalente,Tout le monde peutyaml Modifier la structure du réseau dans le fichier 、 Ajouter d'autres modules, etc , Ensuite, cet article se concentrera sur le réseau de base (backbone)AjouterCBAMExemple de module, Ce n'est qu'une des façons d'ajouter
1.Inyolov5-5.0Sous le dossier projet,TrouvermodelsSous le dossieryolov5s.yamlDocumentation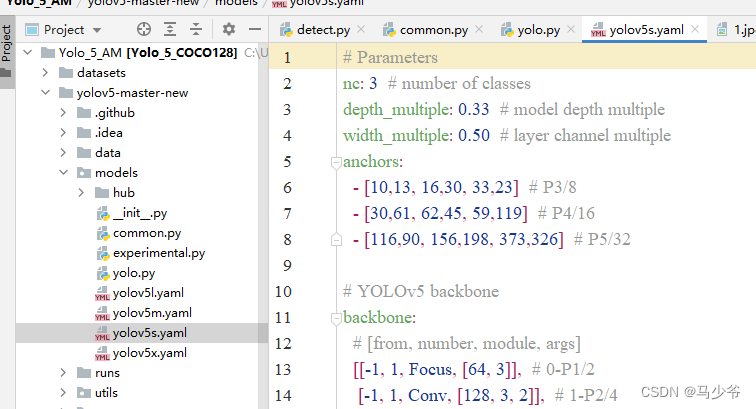
2.backboneDans le réseau de base4- Oui.C3 Remplacer le module par le texte suivant: CBAMC3,Comme le montre la figure ci - dessous:


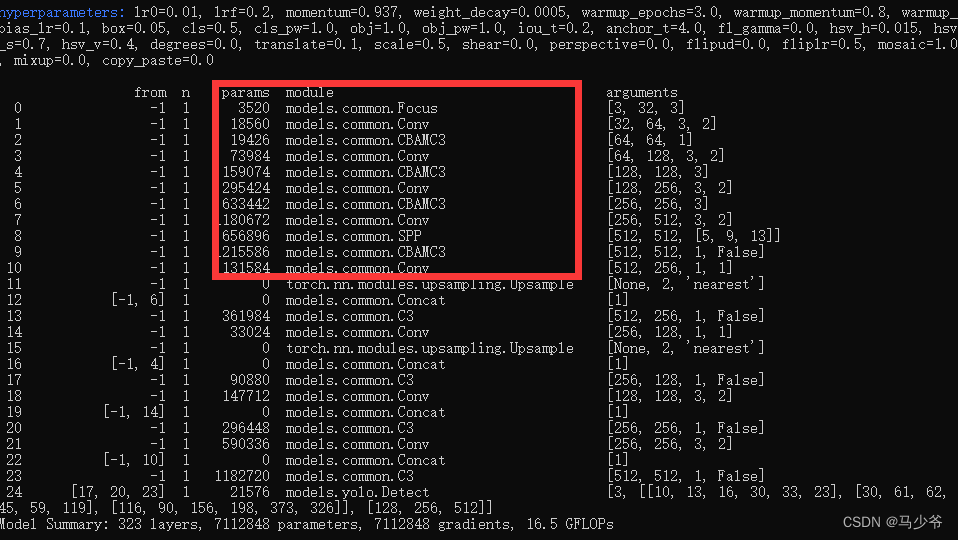
On est là.yolov5s Ajout de CBAMMécanisme d'attention
Ensuite, commencez à former le modèle ,Et nous pouvons voirCBAMC3 Le module a été ajouté avec succès au réseau de base
2.、SEAjout de mécanismes d'attention
(Étapes etCBAMSimilaire)
(1)Incommon.pyAjouter unSEModule
1.Ouvre.modelsDans le dossiercommon.pyDocumentation
2.Mettez ce qui suitSECopier et coller le code danscommon.pyDans le document
class SE(nn.Module):
def __init__(self, c1, c2, r=16):
super(SE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
print(x.size())
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
Comme le montre la figure ci - dessous, Cet article le colle ici à common.pyFin de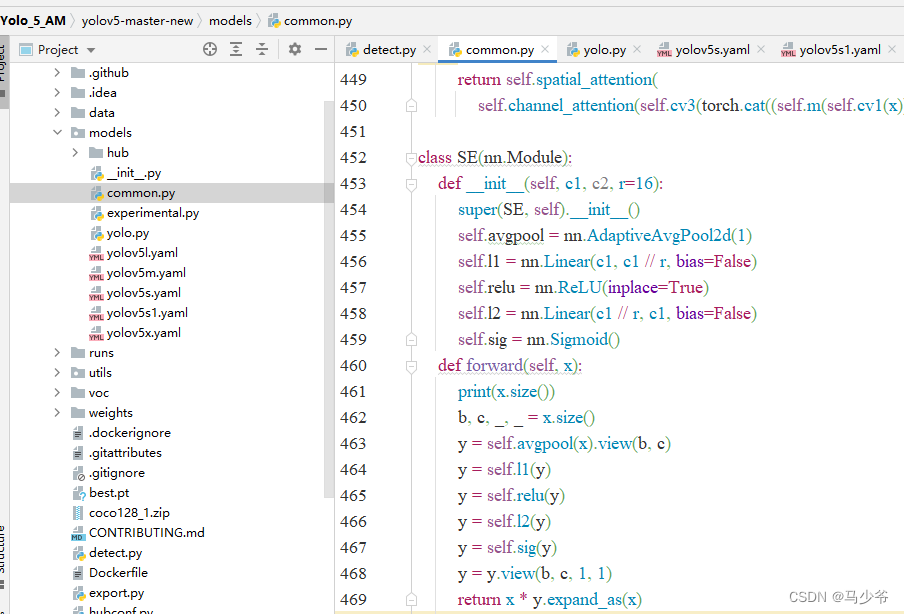
(2)Versyolo.pyAjout de fichiersSEDéclaration de jugement
1.Ouvre.modelsDans le dossieryolo.pyDocumentation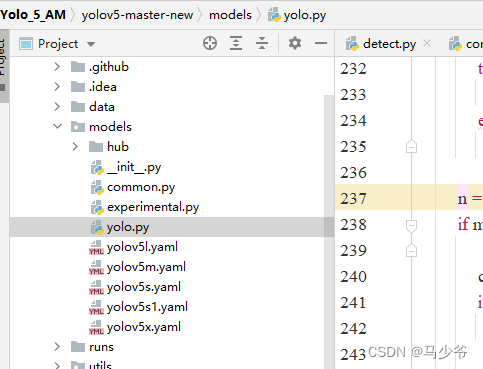
2.Séparément dans238Ligne et245Ajouter une ligneSE,Comme le montre la figure ci - dessous
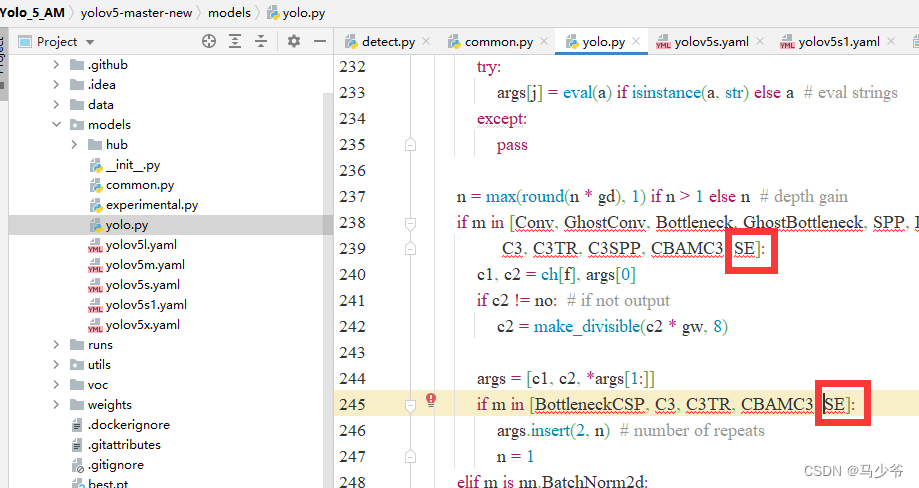
Encore une fois, n'oubliez pas de cliquer sur Save
(3)ModifieryamlDocumentation
Le mécanisme d'attention peut être ajouté à backbone,Neck,HeadSection equivalente,Tout le monde peutyaml Modifier la structure du réseau dans le fichier 、 Ajouter d'autres modules, etc .AvecCBAM Le processus d'ajout est le même pour , Ensuite, cet article se concentrera sur le réseau de base (backbone)AjouterSEExemple de module, Ce n'est qu'une des façons d'ajouter
1.Inyolov5-5.0Sous le dossier projet,TrouvermodelsSous le dossieryolov5s.yamlDocumentation
2.backbone Ajouter le code suivant à la fin du réseau de base ,Comme le montre la figure ci - dessous:
( Notez que les virgules sont en anglais , Et attention à l'alignement )
[-1, 1, SE, [1024, 4]],
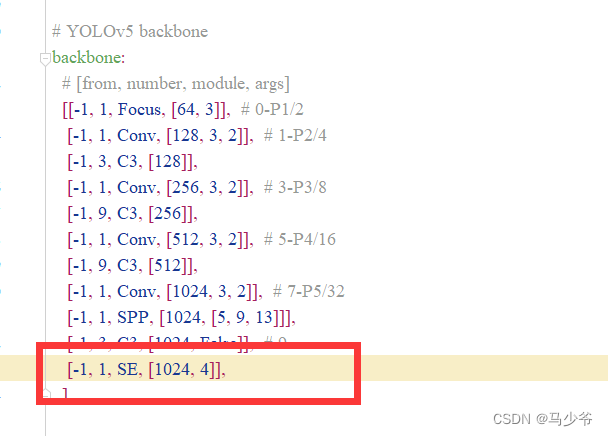
On est là.yolov5s Ajout de SEMécanisme d'attention
( Après avoir exécuté les modifications de code sur le serveur , N'oubliez pas de cliquer sur Enregistrer dans le coin supérieur droit de l'éditeur de texte )
Ensuite, commencez à former le modèle ,Et nous pouvons voirSE Le module a été ajouté avec succès au réseau de base 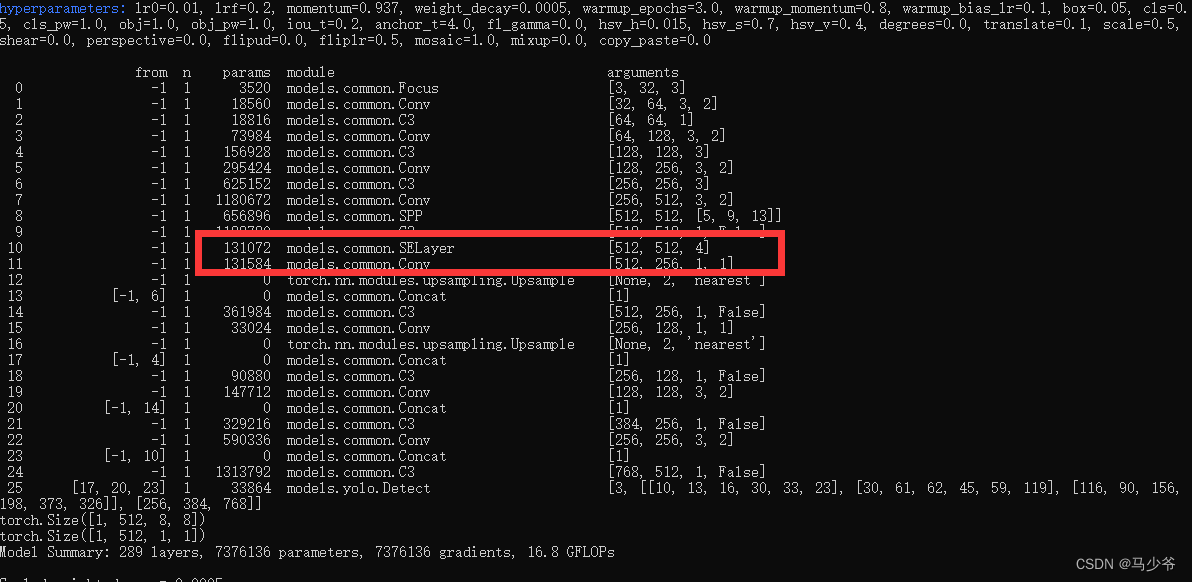
Trois、 Plusieurs autres codes du mécanisme d'attention
Le processus d'ajout n'est plus répété , Imiter au - dessus CBAMEtSE Le processus d'ajout de
(1)ECA Code du mécanisme d'attention
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
x=x*y.expand_as(x)
return x * y.expand_as(x)
(2)CA Code du mécanisme d'attention :
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
Références:https://blog.csdn.net/thy0000/article/details/125016410
边栏推荐
- Leetcode word search (backtracking method)
- Bubble sort summary
- 2022/7/2 question summary
- Reverse one-way linked list of interview questions
- 十年不用一次的JVM调用
- Merge sort
- Download xftp7 and xshell7 (official website)
- 64 horses, 8 tracks, how many times does it take to find the fastest 4 horses at least
- 使用Room数据库报警告: Schema export directory is not provided to the annotation processor so we cannot expor
- 2022/7/1学习总结
猜你喜欢
UE 虚幻引擎,项目结构
![[interval problem] 435 Non overlapping interval](/img/a3/2911ee72635b93b6430c2efd05ec9a.jpg)
[interval problem] 435 Non overlapping interval
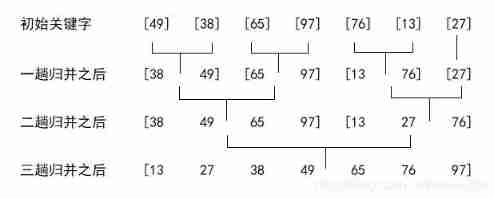
Merge sort

Double pointer Foundation
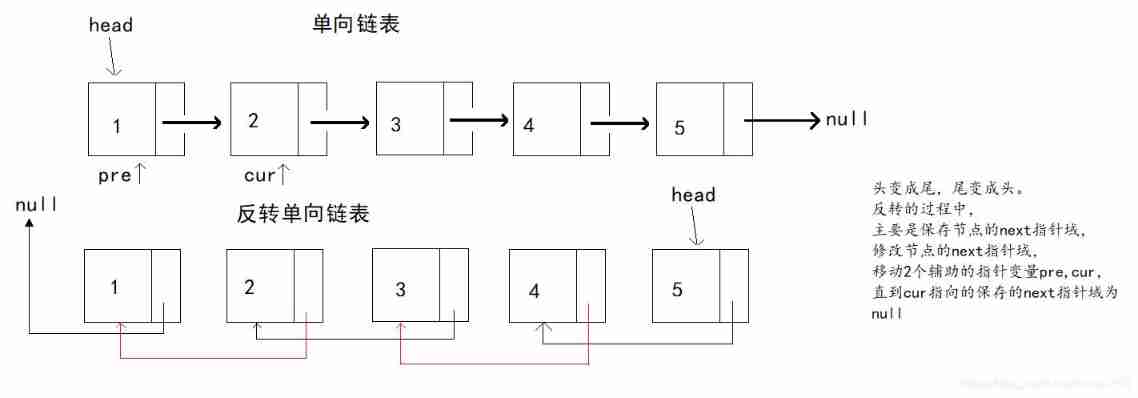
Reverse one-way linked list of interview questions

Embedded database development programming (V) -- DQL

The present is a gift from heaven -- a film review of the journey of the soul
Unity check whether the two objects have obstacles by ray

LeetCode之單詞搜索(回溯法求解)
Web APIs DOM节点
随机推荐
cocos_ Lua loads the file generated by bmfont fnt
Three dimensional dice realize 3D cool rotation effect (with complete source code) (with animation code)
The present is a gift from heaven -- a film review of the journey of the soul
Stm32cubemx (8): RTC and RTC wake-up interrupt
[turn]: OSGi specification in simple terms
Recherche de mots pour leetcode (solution rétrospective)
Collapse of adjacent vertical outer margins
[sum of two numbers] 169 sum of two numbers II - enter an ordered array
Magnifying glass effect
Lua wechat avatar URL
Basic knowledge points of dictionary
Do a small pressure test with JMeter tool
Unity check whether the two objects have obstacles by ray
Shell Sort
Vs2015 secret key
National teacher qualification examination in the first half of 2022
十年不用一次的JVM调用
LeetCode之單詞搜索(回溯法求解)
TF-A中的工具介绍
Reverse one-way linked list of interview questions