当前位置:网站首页>CBAM for in-depth understanding of the attention mechanism in CV
CBAM for in-depth understanding of the attention mechanism in CV
2022-07-08 02:18:00 【Strawberry sauce toast】
CV Medium Attention Mechanism summary ( Two ):CBAM
CBAM:Convolutional Block Attention Module
Thesis link :CBAM(ECCV 2018)
1. Abstract
1.1 CBAM Summary
Given an intermediate feature map, our module sequentially infers attention maps along two separate dimensions, channel and spatial, then the attention maps are multiplied to the input feature map for adaptive feature refinement.
And SE Different modules ,CBAM Combined with passageway And Space Attention mechanism . The author believes that channel attention determines “what is important", Spatial attention determines "where is important".
1.2 CV in Attention The role of mechanism
Besides , The author in Introduction It concisely expounds Attention The role of mechanism , namely :
Attention not only tells where to focus, it also improves the representation of interests.
Our goal is to increase representation power by using attention mechanism: focusing on important features and suppressing unnecessary ones.
Using attention mechanism can improve the ability of network feature expression .
1.3 CBAM The advantages of modules
CBAM It has the following two advantages :
- And SE comparison , Improved channel attention module , Added spatial attention module ;
- And BAM comparison , Not just for bottleneck in , Instead, it can be used in any intermediate convolution module , It's a plug-and-play( Plug and play ) The attention module .
Two 、 Module details
The CBAM The module is shown in the figure below :
The following is combined with article 3 Section elaborates CBAM Implementation details of the module .
2.1 Channel Attention Module:focusing on “what”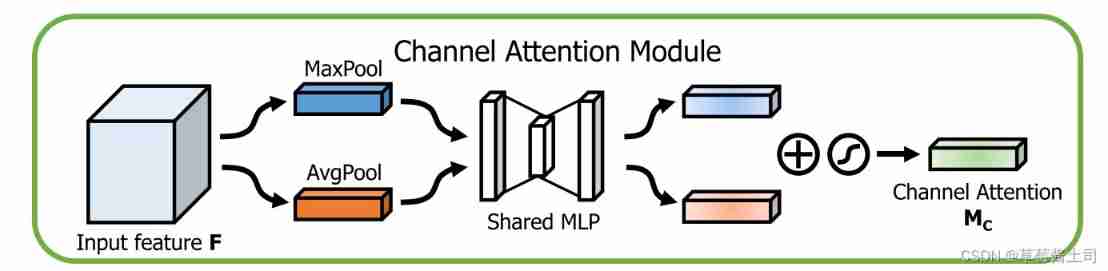
And SE The difference between modules is that , The author added max-pooling operation , also AvgPool And MaxPool Share the same multi-layer perceptron (multi-layer perceptron, MLP) Reduce learnable parameters .
therefore ,CBAM The channel attention extraction of can be expressed by the following formula :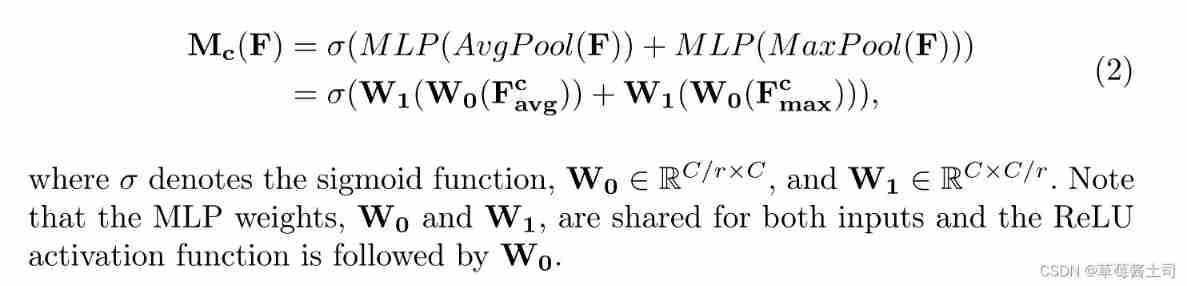
2.2 Spatial Attention Module: focusing on “where”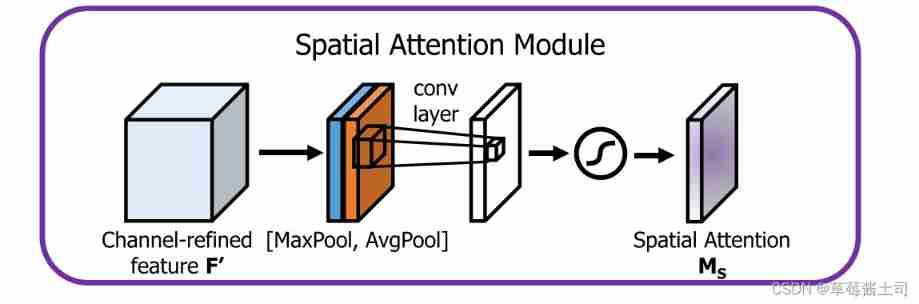
First , Perform maximum aggregation and average aggregation on the channel dimension respectively , The magnitude is H × W H\times W H×W
Characteristic graph , Then the number of input channels is 2, The number of output channels is 1 The convolution layer extracts spatial attention , The formula is as follows :
2.3 Arrangement of attention modules
Combine channel attention with spatial attention , Get the weighted feature .
The combination sequence and mode of channel attention and spatial attention ( Pictured 1 Shown ):
- Channel in the former , Space behind
- Space comes first , Channel in the
- Serial
- parallel
For the combination sequence and mode , The author proved it by ablation experiment .
2.4 Usage mode
Combination with residual network :
3、 ... and 、PyTorch Realization
import torch
from torch import nn
class ChannelAttentionModule(nn.Module):
def __init__(self, channel, reduction=16):
super(ChannelAttentionModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.max_pool = nn.AdaptiveMaxPool2d((1, 1))
self.shared_MLP = nn.Sequential(
nn.Conv2d(channel, channel // reduction, kernel_size=1, stride=1, padding=0, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, kernel_size=1, stride=1, padding=0, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.shared_MLP(self.avg_pool(x))
max_out = self.shared_MLP(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttentionModule(nn.Module):
def __init__(self, kernel_size=7, padding=3):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1,
kernel_size=kernel_size, stride=1, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True) # torch.max returns (values, indices)
out = torch.cat([avg_out, max_out], dim=1)
out = self.conv2d(out)
return self.sigmoid(out)
class CBAM(nn.Module):
def __init__(self, channel, reduction, kernel_size, padding):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(channel, reduction)
self.spatial_attention = SpatialAttentionModule(kernel_size, padding)
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
边栏推荐
- 直接加比较合适
- Keras深度学习实战——基于Inception v3实现性别分类
- Ml backward propagation
- The circuit is shown in the figure, r1=2k Ω, r2=2k Ω, r3=4k Ω, rf=4k Ω. Find the expression of the relationship between output and input.
- cv2-drawline
- Redisson distributed lock unlocking exception
- Semantic segmentation | learning record (2) transpose convolution
- 发现值守设备被攻击后分析思路
- How does the bull bear cycle and encryption evolve in the future? Look at Sequoia Capital
- Leetcode question brushing record | 27_ Removing Elements
猜你喜欢

JVM memory and garbage collection-3-runtime data area / method area

XXL job of distributed timed tasks

List of top ten domestic industrial 3D visual guidance enterprises in 2022
Talk about the realization of authority control and transaction record function of SAP system

《通信软件开发与应用》课程结业报告

Talk about the cloud deployment of local projects created by SAP IRPA studio
Completion report of communication software development and Application

科普 | 什么是灵魂绑定代币SBT?有何价值?

Little knowledge about TXE and TC flag bits

Coreldraw2022 download and install computer system requirements technical specifications
随机推荐
Nmap tool introduction and common commands
Le chemin du poisson et des crevettes
OpenGL/WebGL着色器开发入门指南
谈谈 SAP 系统的权限管控和事务记录功能的实现
Applet running under the framework of fluent 3.0
分布式定时任务之XXL-JOB
云原生应用开发之 gRPC 入门
谈谈 SAP iRPA Studio 创建的本地项目的云端部署问题
Why did MySQL query not go to the index? This article will give you a comprehensive analysis
Ml self realization / linear regression / multivariable
leetcode 866. Prime Palindrome | 866. prime palindromes
Wechat applet uniapp page cannot jump: "navigateto:fail can not navigateto a tabbar page“
Matlab r2021b installing libsvm
How to use diffusion models for interpolation—— Principle analysis and code practice
Cross modal semantic association alignment retrieval - image text matching
Xmeter newsletter 2022-06 enterprise v3.2.3 release, error log and test report chart optimization
【每日一题】736. Lisp 语法解析
Redisson distributed lock unlocking exception
leetcode 873. Length of Longest Fibonacci Subsequence | 873. 最长的斐波那契子序列的长度
nmap工具介紹及常用命令