当前位置:网站首页>Deep learning: derivation of shallow neural networks and deep neural networks
Deep learning: derivation of shallow neural networks and deep neural networks
2022-07-06 08:21:00 【ShadyPi】
List of articles
I have written several blogs about neural networks before learning machine learning , Recently, I watched the video of Wu Enda's in-depth learning , The neural network is different from before , So take a note .
Basic structure and symbol convention
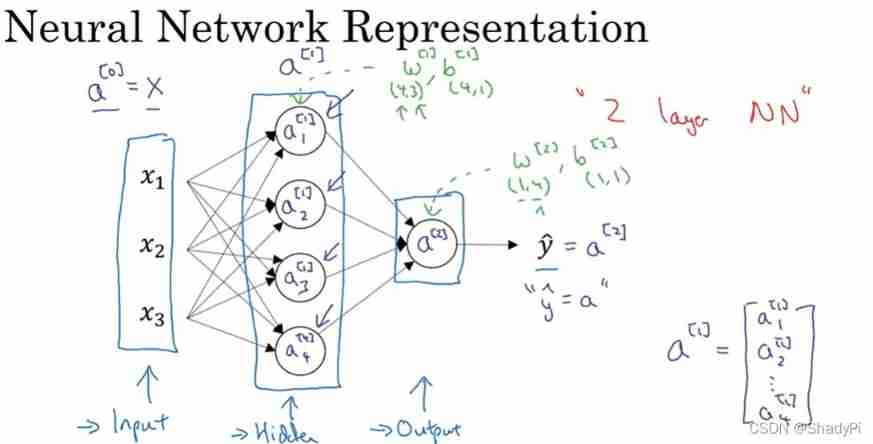
The basic structure is the input layer 、 Hidden layer , Middle layer , Incentive letter a a a Express , The layer label of the unit is placed in square brackets , The sample number in parentheses , So there is an input layer x x x( a [ 0 ] a^{[0]} a[0])、 Hidden layer a [ 1 ] a^{[1]} a[1] And output layer a [ 2 ] a^{[2]} a[2]. Weight is needed in the operation w w w And offset b b b, The functions in the unit are still logical functions σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1.
Declare data matrix X ( n × m ) X(n\times m) X(n×m), Weight matrices W [ l ] ( s l × s l − 1 ) W^{[l]}(s_l\times s_{l-1}) W[l](sl×sl−1) And bias matrix b [ l ] ( s l × 1 ) b^{[l]}(s_l\times 1) b[l](sl×1), Excitation matrix A [ l ] ( s l × m ) A^{[l]}(s_l\times m) A[l](sl×m), n [ l ] n^{[l]} n[l] It means the first one l l l The number of cells in the layer , Make
A [ 0 ] = X = [ ∣ ∣ ∣ x ( 1 ) x ( 2 ) ⋯ x ( m ) ∣ ∣ ∣ ] , W [ l ] = [ − w 1 [ l ] T − − w 2 [ l ] T − ⋯ − w n [ l ] [ l ] T − ] , b [ l ] = [ b 1 [ l ] b 2 [ l ] ⋮ b n [ l ] [ l ] ] A^{[0]}=X=\left[\begin{matrix} |&|& &|\\ x^{(1)}&x^{(2)}&\cdots&x^{(m)}\\ |&|& &|\\ \end{matrix}\right], W^{[l]}=\left[\begin{matrix} -&w_1^{[l]T}&-\\ -&w_2^{[l]T}&-\\ &\cdots&\\ -&w_{n^{[l]}}^{[l]T}&-\\ \end{matrix}\right], b^{[l]}=\left[\begin{matrix} b^{[l]}_1\\ b^{[l]}_2\\ \vdots\\ b^{[l]}_{n^{[l]}}\\ \end{matrix}\right] A[0]=X=⎣⎡∣x(1)∣∣x(2)∣⋯∣x(m)∣⎦⎤,W[l]=⎣⎢⎢⎢⎡−−−w1[l]Tw2[l]T⋯wn[l][l]T−−−⎦⎥⎥⎥⎤,b[l]=⎣⎢⎢⎢⎢⎡b1[l]b2[l]⋮bn[l][l]⎦⎥⎥⎥⎥⎤
There are also some supplements that can be seen Neural networks in machine learning .
Spread forward
Yes Neural network vectorization derivation in machine learning Bottoming , Plus forward propagation is relatively simple , Let's go directly to multiple groups of data + Multiple hidden layers .
The middle vector z [ l ] z^{[l]} z[l] by
z [ l ] = [ z 1 [ l ] z 2 [ l ] ⋮ z n [ l ] [ l ] ] = [ w 1 [ l ] T a [ l − 1 ] + b 1 [ l ] w 2 [ l ] T a [ l − 1 ] + b 2 [ l ] ⋮ w n [ l ] [ l ] T a [ l − 1 ] + b n [ l ] [ l ] ] = W [ l ] a [ l − 1 ] + b [ l ] z^{[l]}=\left[\begin{matrix} z^{[l]}_1\\ z^{[l]}_2\\ \vdots\\ z^{[l]}_{n^{[l]}}\\ \end{matrix}\right]= \left[\begin{matrix} w^{[l]T}_1a^{[l-1]}+b_1^{[l]}\\ w^{[l]T}_2a^{[l-1]}+b_2^{[l]}\\ \vdots\\ w^{[l]T}_{n^{[l]}}a^{[l-1]}+b_{n^{[l]}}^{[l]}\\ \end{matrix}\right]= W^{[l]}a^{[l-1]}+b^{[l]} z[l]=⎣⎢⎢⎢⎢⎡z1[l]z2[l]⋮zn[l][l]⎦⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎡w1[l]Ta[l−1]+b1[l]w2[l]Ta[l−1]+b2[l]⋮wn[l][l]Ta[l−1]+bn[l][l]⎦⎥⎥⎥⎥⎤=W[l]a[l−1]+b[l]
So by the z [ l ] ( i ) z^{[l](i)} z[l](i) A matrix of Z [ l ] Z^{[l]} Z[l] by
Z [ l ] = [ ∣ ∣ ∣ z [ l ] ( 1 ) z [ l ] ( 2 ) ⋯ z [ l ] ( m ) ∣ ∣ ∣ ] = W [ l ] A [ l − 1 ] + b [ l ] Z^{[l]}=\left[\begin{matrix} |&|& &|\\ z^{[l](1)}&z^{[l](2)}&\cdots&z^{[l](m)}\\ |&|& &|\\ \end{matrix}\right]= W^{[l]}A^{[l-1]}+b^{[l]} Z[l]=⎣⎡∣z[l](1)∣∣z[l](2)∣⋯∣z[l](m)∣⎦⎤=W[l]A[l−1]+b[l]
And the excitation matrix of the hidden layer A [ l ] A^{[l]} A[l] Namely
A [ l ] = [ ∣ ∣ ∣ a [ l ] ( 1 ) a [ l ] ( 2 ) ⋯ a [ l ] ( m ) ∣ ∣ ∣ ] = σ ( Z [ l ] ) = σ ( W [ l ] A [ l − 1 ] + b [ l ] ) A^{[l]}=\left[\begin{matrix} |&|& &|\\ a^{[l](1)}&a^{[l](2)}&\cdots&a^{[l](m)}\\ |&|& &|\\ \end{matrix}\right]=\sigma(Z^{[l]}) =\sigma(W^{[l]}A^{[l-1]}+b^{[l]}) A[l]=⎣⎡∣a[l](1)∣∣a[l](2)∣⋯∣a[l](m)∣⎦⎤=σ(Z[l])=σ(W[l]A[l−1]+b[l])
Other activation functions
Before, our neural networks were all logical functions used by logistic regression , But in fact, there are many better choices in Neural Networks .
tanh function
tanh ( z ) = e z − e − z e z + e − z \tanh(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}} tanh(z)=ez+e−zez−e−z
The image below :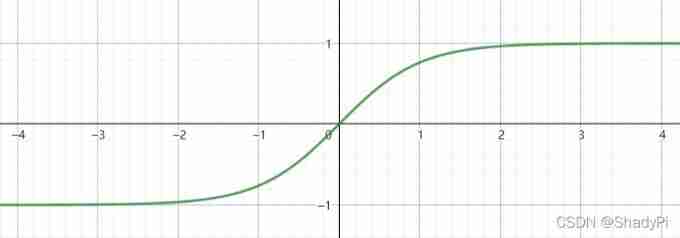
tanh \tanh tanh Functions are almost strictly superior to logical functions , because tanh \tanh tanh Function so that the average value of the excitation is 0 about , This can make the calculation of the next level easier . Except at the output layer , What we expect is 0 ∼ 1 0\sim 1 0∼1 Between the output , At this time, we can use logical functions in the output layer .
The derivative of this function is
tanh ′ ( z ) = 1 − ( tanh ( z ) ) 2 \tanh'(z)=1-(\tanh(z))^2 tanh′(z)=1−(tanh(z))2
ReLU function
But logical functions and tanh \tanh tanh Every function has a problem , That is when the absolute value of coordinates is very large , The gradient of the function becomes very small , In this way, when we run an algorithm similar to gradient descent, the convergence speed will become very slow . and ReLU Function can solve this problem , The expression is
ReLU ( z ) = max ( 0 , z ) \text{ReLU}(z)=\max(0,z) ReLU(z)=max(0,z)
The image is :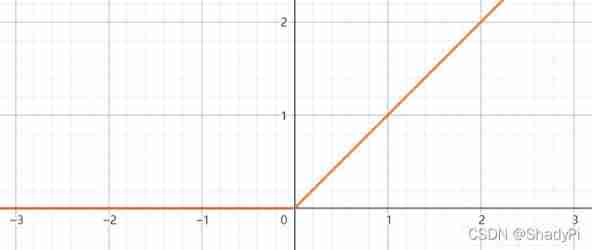
such , as long as z > 0 z>0 z>0, The derivative is 1, and z < 0 z<0 z<0 The time derivative is 0. Although mathematically z = 0 z=0 z=0 There is no derivative at , however z z z The value is just 0 The probability is very small , And we can artificially define it as 1 or 0, This is harmless in practical application .
In general , If you want to do a binary classification problem , We might use it tanh \tanh tanh function , Add a logic function to the output layer , At other times, it is generally the default ReLU function .
Leaky ReLU
In practice ,ReLU Functions usually perform well , But because the derivative of its negative part is 0, So for this part, its gradient descent rate will be very slow , Although in a network , We will have many positive parts , Make the whole parameters still learn at a faster speed . If you are not at ease , You can also set a smaller slope for the negative part , such as 0.01 0.01 0.01, In this way, the activation function is expressed as
Leaky ReLU ( z ) = max ( 0.01 z , z ) \text{Leaky ReLU}(z)=\max(0.01z,z) Leaky ReLU(z)=max(0.01z,z)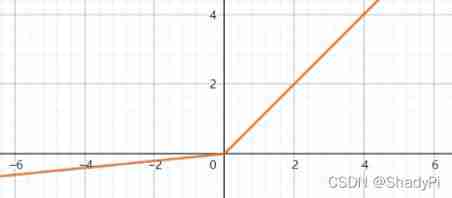
Back propagation
Shallow neural networks
Backward propagation is more complex , Let's first push a shallow neural network :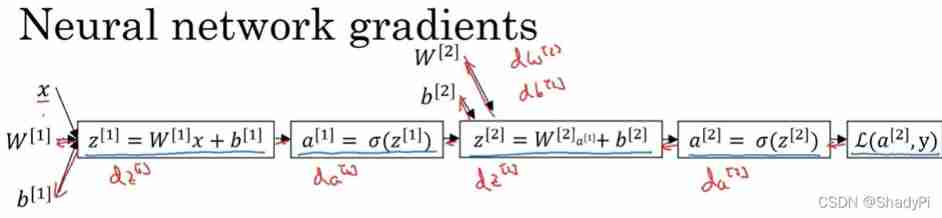
First , For the last cost function , Its value is
L ( a [ 2 ] , y ) = − y log a [ 2 ] − ( 1 − y ) log ( 1 − a [ 2 ] ) \mathcal{L}(a^{[2]},y)=-y\log a^{[2]}-(1-y)\log(1-a^{[2]}) L(a[2],y)=−yloga[2]−(1−y)log(1−a[2])
Yes a [ 2 ] a^{[2]} a[2] Find differentiation , Available
d L d a [ 2 ] = − y a [ 2 ] + 1 − y 1 − a [ 2 ] \frac{d\mathcal{L}}{da^{[2]}}=-\frac{y}{a^{[2]}}+\frac{1-y}{1-a^{[2]}} da[2]dL=−a[2]y+1−a[2]1−y
be z [ 2 ] z^{[2]} z[2] The differential of the cost function is
d L d z [ 2 ] = d L d a [ 2 ] d a [ 2 ] d z [ 2 ] = ( − y a [ 2 ] + 1 − y 1 − a [ 2 ] ) a [ 2 ] ( 1 − a [ 2 ] ) = a [ 2 ] − y \frac{d\mathcal{L}}{dz^{[2]}}=\frac{d\mathcal{L}}{da^{[2]}}\frac{d a^{[2]}}{dz^{[2]}}=(-\frac{y}{a^{[2]}}+\frac{1-y}{1-a^{[2]}})a^{[2]}(1-a^{[2]})=a^{[2]}-y dz[2]dL=da[2]dLdz[2]da[2]=(−a[2]y+1−a[2]1−y)a[2](1−a[2])=a[2]−y
Calculated after d L d W [ 2 ] \frac{d\mathcal{L}}{dW^{[2]}} dW[2]dL and d L d b [ 2 ] \frac{d\mathcal{L}}{db^{[2]}} db[2]dL by
d L d W [ 2 ] = d L d z [ 2 ] a [ 1 ] T d L d b [ 2 ] = d L d z [ 2 ] \frac{d\mathcal{L}}{dW^{[2]}}=\frac{d\mathcal{L}}{dz^{[2]}}a^{[1]T}\\ \frac{d\mathcal{L}}{db^{[2]}}=\frac{d\mathcal{L}}{dz^{[2]}} dW[2]dL=dz[2]dLa[1]Tdb[2]dL=dz[2]dL
Now the derivation is half done , Let's calculate again a [ 1 ] a^{[1]} a[1] The derivative of is
d L d a [ 1 ] = W [ 2 ] T d L d z [ 2 ] \frac{d\mathcal{L}}{da^{[1]}}=W^{[2]T}\frac{d\mathcal{L}}{dz^{[2]}} da[1]dL=W[2]Tdz[2]dL
because z [ 2 ] z^{[2]} z[2] yes n [ 2 ] × 1 n^{[2]}\times 1 n[2]×1 Of , W [ 2 ] W^{[2]} W[2] yes n [ 2 ] × n [ 1 ] n^{[2]}\times n^{[1]} n[2]×n[1] Of , So it needs to be transposed here . after , Ask again for z [ 1 ] z^{[1]} z[1] The derivative of , Just multiply this by d a [ 1 ] d z [ 1 ] \frac{d a^{[1]}}{dz^{[1]}} dz[1]da[1]( ∗ * ∗ Indicates bitwise multiplication ):
d L d z [ 1 ] = W [ 2 ] T d L d z [ 2 ] ∗ g [ 1 ] ′ ( z [ 1 ] ) \frac{d\mathcal{L}}{dz^{[1]}}=W^{[2]T}\frac{d\mathcal{L}}{dz^{[2]}}*g^{[1]'}(z^{[1]}) dz[1]dL=W[2]Tdz[2]dL∗g[1]′(z[1])
And calculation d L d W [ 1 ] \frac{d\mathcal{L}}{dW^{[1]}} dW[1]dL and d L d b [ 1 ] \frac{d\mathcal{L}}{db^{[1]}} db[1]dL Process and Chapter 2 The layers are almost identical :
d L d W [ 1 ] = d L d z [ 1 ] a [ 0 ] T d L d b [ 1 ] = d L d z [ 1 ] \frac{d\mathcal{L}}{dW^{[1]}}=\frac{d\mathcal{L}}{dz^{[1]}}a^{[0]T}\\ \frac{d\mathcal{L}}{db^{[1]}}=\frac{d\mathcal{L}}{dz^{[1]}} dW[1]dL=dz[1]dLa[0]Tdb[1]dL=dz[1]dL
The above derivation is for a single sample , Backward propagation is required for multiple samples , Stack the sample column vectors by column , You can apply the results derived above , It's all n [ l ] × 1 n^{[l]}\times1 n[l]×1 The matrix becomes n [ l ] × m n^{[l]}\times m n[l]×m, then b b b The vector needs to be summed once in the horizontal direction ( To simplify the expression , We use it d Z [ 2 ] dZ^{[2]} dZ[2] According to matrix Z [ 2 ] Z^{[2]} Z[2] The result of deriving the cost function , Other matrices are the same ):
d Z [ 2 ] = ( A [ 2 ] − Y ) d W [ 2 ] = 1 m d Z [ 2 ] A [ 1 ] T d b [ 2 ] = 1 m n p . s u m ( d Z [ 2 ] , a x i s = 1 , k e e p d i m s = T r u e ) d Z [ 1 ] = W [ 2 ] T d Z [ 2 ] ∗ g [ 1 ] ′ ( Z [ 1 ] ) d W [ 1 ] = 1 m d Z [ 1 ] X T d b [ 1 ] = 1 m n p . s u m ( d Z [ 1 ] , a x i s = 1 , k e e p d i m s = T r u e ) \begin{aligned} &dZ^{[2]}=(A^{[2]}-Y)\\ &dW^{[2]}=\frac{1}{m}dZ^{[2]}A^{[1]T}\\ &db^{[2]}=\frac{1}{m}np.sum(dZ^{[2]},axis=1,keepdims=True)\\ &dZ^{[1]}=W^{[2]T}dZ^{[2]}*g^{[1]'}(Z^{[1]})\\ &dW^{[1]}=\frac{1}{m}dZ^{[1]}X^T\\ &db^{[1]}=\frac{1}{m}np.sum(dZ^{[1]},axis=1,keepdims=True)\\ \end{aligned} dZ[2]=(A[2]−Y)dW[2]=m1dZ[2]A[1]Tdb[2]=m1np.sum(dZ[2],axis=1,keepdims=True)dZ[1]=W[2]TdZ[2]∗g[1]′(Z[1])dW[1]=m1dZ[1]XTdb[1]=m1np.sum(dZ[1],axis=1,keepdims=True)keepdims The function of is to let Python Don't put our column vector (n,1) Become rank 1 Matrix (n,), That could lead to hard to find bug.
Deep neural network
The shallow network above has only two layers , And for complex problems , Increase the number of layers of the network ( depth ) It is much more effective than forcing nodes to be added in a hidden layer , So we need to transform the above derivation into a more general form , That is, the following four formulas :
d Z [ l ] = d A [ l ] ∗ g [ l ] ′ ( Z [ l ] ) d W [ l ] = 1 m d Z [ l ] A [ l − 1 ] T d b [ l ] = 1 m n p . s u m ( d Z [ l ] , a x i s = 1 , k e e p d i m s = T r u e ) d A [ l − 1 ] = W [ l ] T d Z [ l ] \begin{aligned} &dZ^{[l]}=dA^{[l]}*g^{[l]'}(Z^{[l]})\\ &dW^{[l]}=\frac{1}{m}dZ^{[l]}A^{[l-1]T}\\ &db^{[l]}=\frac{1}{m}np.sum(dZ^{[l]},axis=1,keepdims=True)\\ &dA^{[l-1]}=W^{[l]T}dZ^{[l]} \end{aligned} dZ[l]=dA[l]∗g[l]′(Z[l])dW[l]=m1dZ[l]A[l−1]Tdb[l]=m1np.sum(dZ[l],axis=1,keepdims=True)dA[l−1]=W[l]TdZ[l]
Initial input d A [ L ] dA^{[L]} dA[L] Determined by the excitation function of the output node , about m m m Group samples , Its value is
d A [ L ] = [ d L d a [ L ] ( 1 ) d L d a [ L ] ( 2 ) ⋯ d L d a [ L ] ( m ) ] dA^{[L]}=\left[\begin{matrix} \frac{d\mathcal{L}}{da^{[L](1)}}&\frac{d\mathcal{L}}{da^{[L](2)}}&\cdots&\frac{d\mathcal{L}}{da^{[L](m)}} \end{matrix}\right] dA[L]=[da[L](1)dLda[L](2)dL⋯da[L](m)dL]
From the above formula , We can input d A [ l ] dA^{[l]} dA[l], Output d A [ l − 1 ] dA^{[l-1]} dA[l−1], At the same time, calculate the weight of each layer and the gradient of offset .
边栏推荐
- Asia Pacific Financial Media | "APEC industry +" Western Silicon Valley invests 2trillion yuan in Chengdu Chongqing economic circle to catch up with Shanghai | stable strategy industry fund observatio
- Circular reference of ES6 module
- How to use information mechanism to realize process mutual exclusion, process synchronization and precursor relationship
- Artcube information of "designer universe": Guangzhou implements the community designer system to achieve "great improvement" of urban quality | national economic and Information Center
- 根据csv文件某一列字符串中某个数字排序
- TiDB备份与恢复简介
- 【云原生】手把手教你搭建ferry开源工单系统
- Summary of MySQL index failure scenarios
- 使用 BR 恢复 S3 兼容存储上的备份数据
- [2022 广东省赛M] 拉格朗日插值 (多元函数极值 分治NTT)
猜你喜欢

化不掉的钟薛高,逃不出网红产品的生命周期

The resources of underground pipe holes are tight, and the air blowing micro cable is not fragrant?

The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower

The State Economic Information Center "APEC industry +" Western Silicon Valley will invest 2trillion yuan in Chengdu Chongqing economic circle, which will surpass the observation of Shanghai | stable
IP lab, the first weekly recheck
Nft智能合约发行,盲盒,公开发售技术实战--合约篇
ESP系列引脚說明圖匯總
All the ArrayList knowledge you want to know is here
![[Yugong series] February 2022 U3D full stack class 011 unity section 1 mind map](/img/c3/1b6013bfb2441219bf621c3f0726ea.jpg)
[Yugong series] February 2022 U3D full stack class 011 unity section 1 mind map
Convolution, pooling, activation function, initialization, normalization, regularization, learning rate - Summary of deep learning foundation
随机推荐
flask返回文件下载
PHP - Common magic method (nanny level teaching)
使用 TiDB Lightning 恢复 S3 兼容存储上的备份数据
[untitled]
24. Query table data (basic)
Résumé des diagrammes de description des broches de la série ESP
vulnhub hackme: 1
Upgrade tidb with tiup
Tidb backup and recovery introduction
How to use information mechanism to realize process mutual exclusion, process synchronization and precursor relationship
2. File operation - write
leetcode刷题 (5.31) 字符串
MFC 给列表控件发送左键单击、双击、以及右键单击消息
sys.argv
C语言自定义类型:结构体
使用 BR 备份 TiDB 集群数据到兼容 S3 的存储
Upgrade tidb operator
备份与恢复 CR 介绍
【T31ZL智能视频应用处理器资料】
Let the bullets fly for a while