当前位置:网站首页>从 CSV 文件迁移数据到 TiDB
从 CSV 文件迁移数据到 TiDB
2022-07-06 07:58:00 【添香小铺】
本文档介绍如何从 CSV 文件迁移数据到 TiDB。
TiDB Lightning 支持读取 CSV 格式的文件,以及其他定界符格式,如 TSV(制表符分隔值)。对于其他“平面文件”类型的数据导入,也可以参考本文档进行。
前提条件
第 1 步: 准备 CSV 文件
将所有要导入的 CSV 文件放在同一目录下,若要 TiDB Lightning 识别所有 CSV 文件,文件名必须满足以下格式:
- 包含整张表数据的 CSV 文件,需命名为
${db_name}.${table_name}.csv。 - 如果一张表分布于多个 CSV 文件,这些 CSV 文件命名需加上文件编号的后缀,如
${db_name}.${table_name}.003.csv。数字部分不需要连续,但必须递增,并且需要用零填充数字部分,保证后缀为同样长度。
第 2 步: 创建目标表结构
CSV 文件自身未包含表结构信息。要将 CSV 数据导入 TiDB,就必须为数据提供表结构。可以通过以下任一方法创建表结构:
方法一:使用 TiDB Lightning 创建表结构。
编写包含 DDL 语句的 SQL 文件如下:
- 文件名格式为
${db_name}-schema-create.sql,其内容需包含CREATE DATABASE语句。 - 文件名格式为
${db_name}.${table_name}-schema.sql,其内容需包含CREATE TABLE语句。
- 文件名格式为
方法二:手动在下游 TiDB 建库和表。
第 3 步: 编写配置文件
新建文件 tidb-lightning.toml,包含以下内容:
[lightning] # 日志 level = "info" file = "tidb-lightning.log" [tikv-importer] # "local":默认使用该模式,适用于 TB 级以上大数据量,但导入期间下游 TiDB 无法对外提供服务。 # "tidb":TB 级以下数据量也可以采用`tidb`后端模式,下游 TiDB 可正常提供服务。关于后端模式更多信息请参阅:https://docs.pingcap.com/tidb/stable/tidb-lightning-backends backend = "local" # 设置排序的键值对的临时存放地址,目标路径必须是一个空目录,目录空间须大于待导入数据集的大小,建议设为与 `data-source-dir` 不同的磁盘目录并使用闪存介质,独占 IO 会获得更好的导入性能 sorted-kv-dir = "/mnt/ssd/sorted-kv-dir" [mydumper] # 源数据目录。 data-source-dir = "${data-path}" # 本地或 S3 路径,例如:'s3://my-bucket/sql-backup?region=us-west-2' # 定义 CSV 格式 [mydumper.csv] # 字段分隔符,必须不为空。如果源文件中包含非字符串或数值类型的字段(如 binary, blob, bit 等),则不建议源文件使用默认的“,”简单分隔符,推荐“|+|”等非常见字符组合 separator = ',' # 引用定界符,可以为零或多个字符。 delimiter = '"' # CSV 文件是否包含表头。 # 如果为 true,则 lightning 会使用首行内容解析字段的对应关系。 header = true # CSV 是否包含 NULL。 # 如果为 true,CSV 文件的任何列都不能解析为 NULL。 not-null = false # 如果 `not-null` 为 false(即 CSV 可以包含 NULL), # 为以下值的字段将会被解析为 NULL。 null = '\N' # 是否将字符串中包含的反斜杠('\')字符作为转义字符处理 backslash-escape = true # 是否移除行尾的最后一个分隔符。 trim-last-separator = false [tidb] # 目标集群的信息 host = ${host} # 例如:172.16.32.1 port = ${port} # 例如:4000 user = "${user_name}" # 例如:"root" password = "${password}" # 例如:"rootroot" status-port = ${status-port} # 导入过程 Lightning 需要在从 TiDB 的“状态端口”获取表结构信息,例如:10080 pd-addr = "${ip}:${port}" # 集群 PD 的地址,Lightning 通过 PD 获取部分信息,例如 172.16.31.3:2379。当 backend = "local" 时 status-port 和 pd-addr 必须正确填写,否则导入将出现异常。
关于配置文件更多信息,可参阅 TiDB Lightning 配置参数。
第 4 步: 导入性能优化(可选)
导入文件的大小统一约为 256 MiB 时,TiDB Lightning 可达到最佳工作状态。如果导入单个 CSV 大文件,TiDB Lightning 在默认配置下只能使用一个线程来处理,这会降低导入速度。
要解决此问题,可先将 CSV 文件分割为多个文件。对于通用格式的 CSV 文件,在没有读取整个文件的情况下,无法快速确定行的开始和结束位置。因此,默认情况下 TiDB Lightning 不会自动分割 CSV 文件。但如果你确定待导入的 CSV 文件符合特定的限制要求,则可以启用 strict-format 模式。启用后,TiDB Lightning 会将单个 CSV 大文件分割为单个大小为 256 MiB 的多个文件块进行并行处理。
注意
如果 CSV 文件不是严格格式,但 strict-format 被误设为 true,跨多行的单个完整字段会被分割成两部分,导致解析失败,甚至不报错地导入已损坏的数据。
严格格式的 CSV 文件中,每个字段仅占一行,即必须满足以下条件之一:
- delimiter 为空;
- 每个字段不包含 CR (\r)或 LF(\n)。
如果你确认满足条件,可按如下配置开启 strict-format 模式以加快导入速度。
[mydumper] strict-format = true
第 5 步: 执行导入
运行 tidb-lightning。如果直接在命令行中启动程序,可能会因为 SIGHUP 信号而退出,建议配合 nohup 或 screen 等工具,如:
nohup tiup tidb-lightning -config tidb-lightning.toml > nohup.out 2>&1 &
导入开始后,可以采用以下任意方式查看进度:
- 通过
grep日志关键字progress查看进度,默认 5 分钟更新一次。 - 通过监控面板查看进度,请参考 TiDB Lightning 监控。
- 通过 Web 页面查看进度,请参考 Web 界面。
导入完毕后,TiDB Lightning 会自动退出。查看日志的最后 5 行中会有 the whole procedure completed,则表示导入成功。
注意
无论导入成功与否,最后一行都会显示 tidb lightning exit。它只是表示 TiDB Lightning 正常退出,不代表任务完成。
如果导入过程中遇到问题,请参见 TiDB Lightning 常见问题。
其他格式的文件
若数据源为其他格式,除文件名仍必须以 .csv 结尾外,配置文件 tidb-lightning.toml 的 [mydumper.csv] 格式定义同样需要做相应修改。常见的格式修改如下:
TSV:
# 格式示例 # ID Region Count # 1 East 32 # 2 South NULL # 3 West 10 # 4 North 39 # 格式配置 [mydumper.csv] separator = "\t" delimiter = '' header = true not-null = false null = 'NULL' backslash-escape = false trim-last-separator = false
TPC-H DBGEN:
# 格式示例 # 1|East|32| # 2|South|0| # 3|West|10| # 4|North|39| # 格式配置 [mydumper.csv] separator = '|' delimiter = '' header = false not-null = true backslash-escape = false trim-last-separator = true
边栏推荐
- National economic information center "APEC industry +": economic data released at the night of the Spring Festival | observation of stable strategy industry fund
- opencv学习笔记八--答题卡识别
- Transformer principle and code elaboration
- Inspiration from the recruitment of bioinformatics analysts in the Department of laboratory medicine, Zhujiang Hospital, Southern Medical University
- 珠海金山面试复盘
- Database basic commands
- Asia Pacific Financial Media | female pattern ladyvision: forced the hotel to upgrade security. The drunk woman died in the guest room, and the hotel was sentenced not to pay compensation | APEC secur
- The Vice Minister of the Ministry of industry and information technology of "APEC industry +" of the national economic and information technology center led a team to Sichuan to investigate the operat
- Launch APS system to break the problem of decoupling material procurement plan from production practice
- . Net 6 learning notes: what is NET Core
猜你喜欢

Asia Pacific Financial Media | art cube of "designer universe": Guangzhou community designers achieve "great improvement" in urban quality | observation of stable strategy industry fund
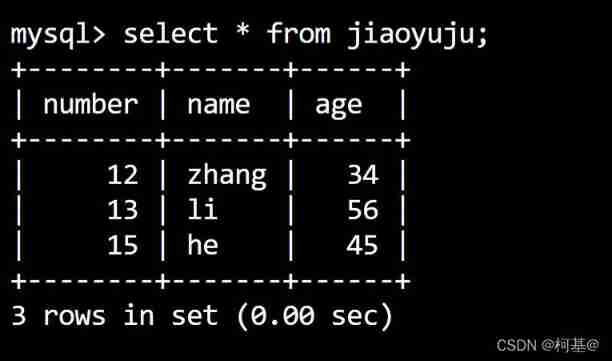
23. Update data
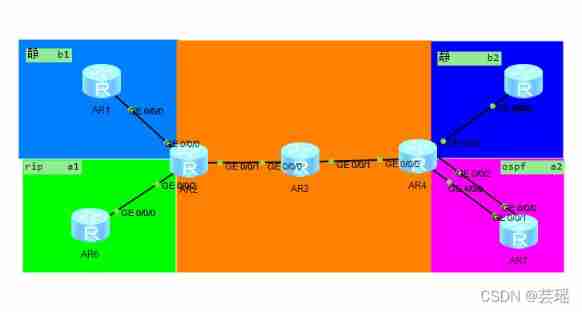
hcip--mpls

MEX有关的学习
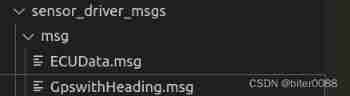
ROS learning (IX): referencing custom message types in header files
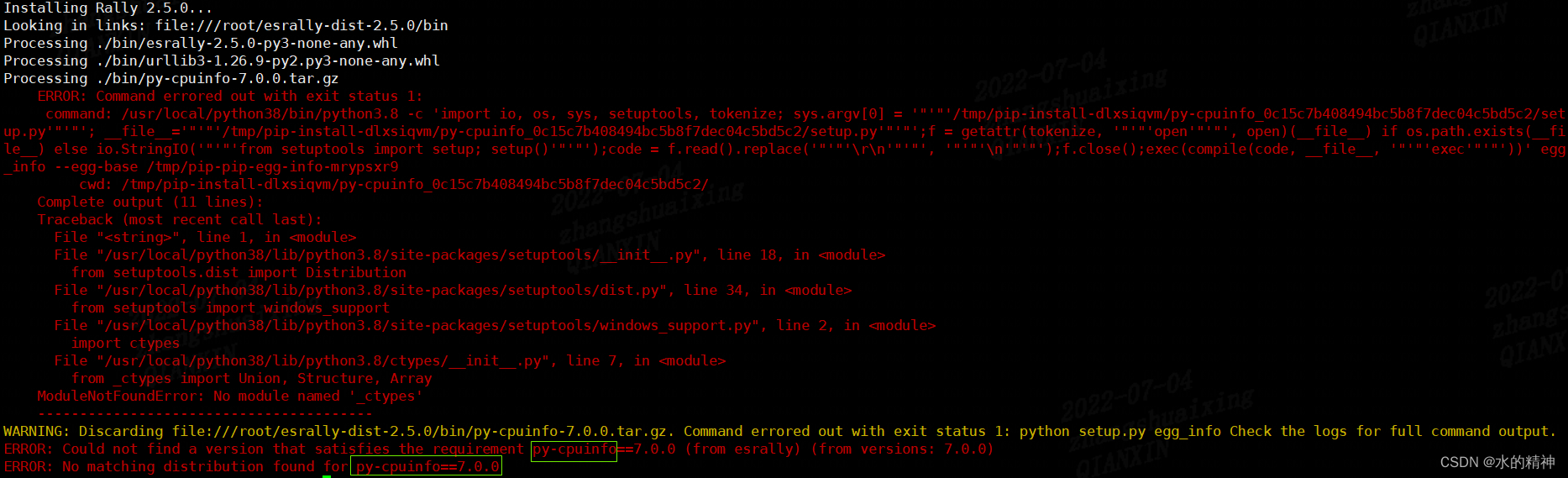
Esrally domestic installation and use pit avoidance Guide - the latest in the whole network
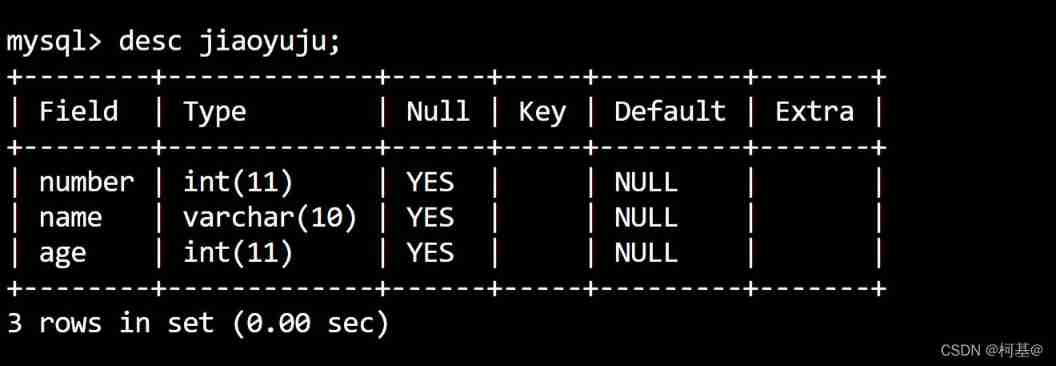
22. Empty the table
Secure captcha (unsafe verification code) of DVWA range
【T31ZL智能视频应用处理器资料】
Sanzi chess (C language)
随机推荐
Iterator Foundation
Asia Pacific Financial Media | designer universe | Guangdong responds to the opinions of the national development and Reform Commission. Primary school students incarnate as small community designers
"Friendship and righteousness" of the center for national economy and information technology: China's friendship wine - the "unparalleled loyalty and righteousness" of the solidarity group released th
opencv学习笔记九--背景建模+光流估计
Webrtc series-h.264 estimated bit rate calculation
HTTP cache, forced cache, negotiated cache
Hill sort c language
数据治理:主数据的3特征、4超越和3二八原则
Mex related learning
Secure captcha (unsafe verification code) of DVWA range
【T31ZL智能视频应用处理器资料】
Transformer principle and code elaboration
Solution: système de surveillance vidéo intelligent de patrouille sur le chantier
opencv学习笔记八--答题卡识别
xpath中的position()函数使用
1204 character deletion operation (2)
Solution: intelligent site intelligent inspection scheme video monitoring system
Data governance: 3 characteristics, 4 transcendence and 3 28 principles of master data
Description of octomap averagenodecolor function
[Yugong series] creation of 009 unity object of U3D full stack class in February 2022