当前位置:网站首页>5.过拟合,dropout,正则化
5.过拟合,dropout,正则化
2022-07-07 23:11:00 【booze-J】
过拟合
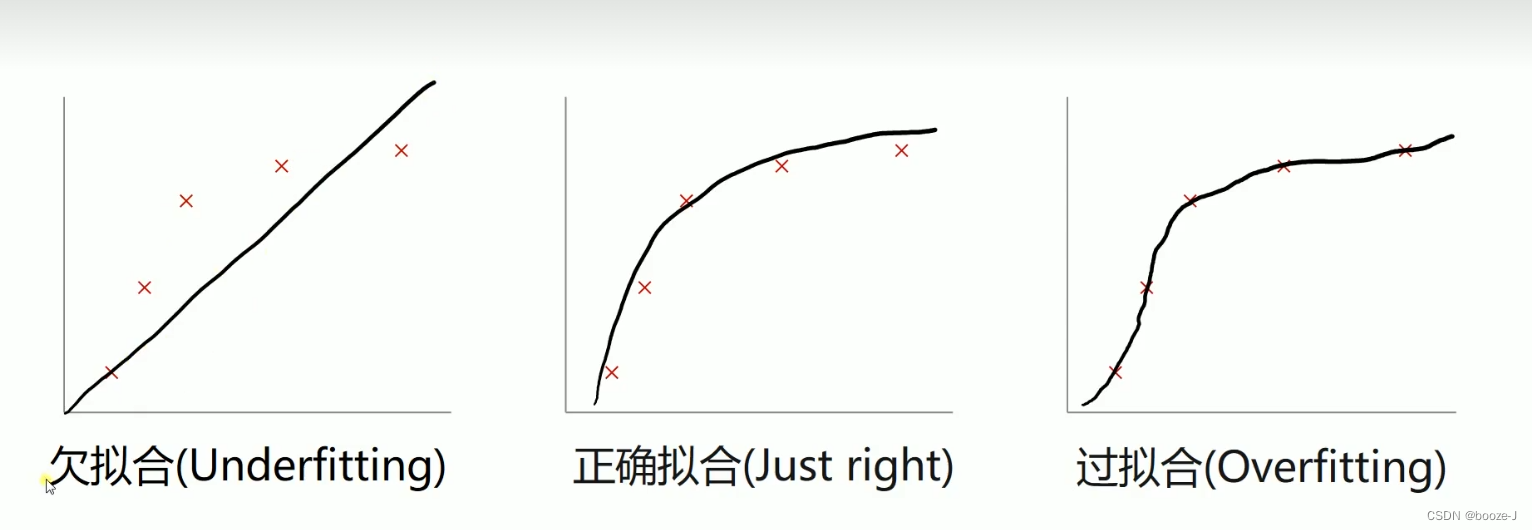
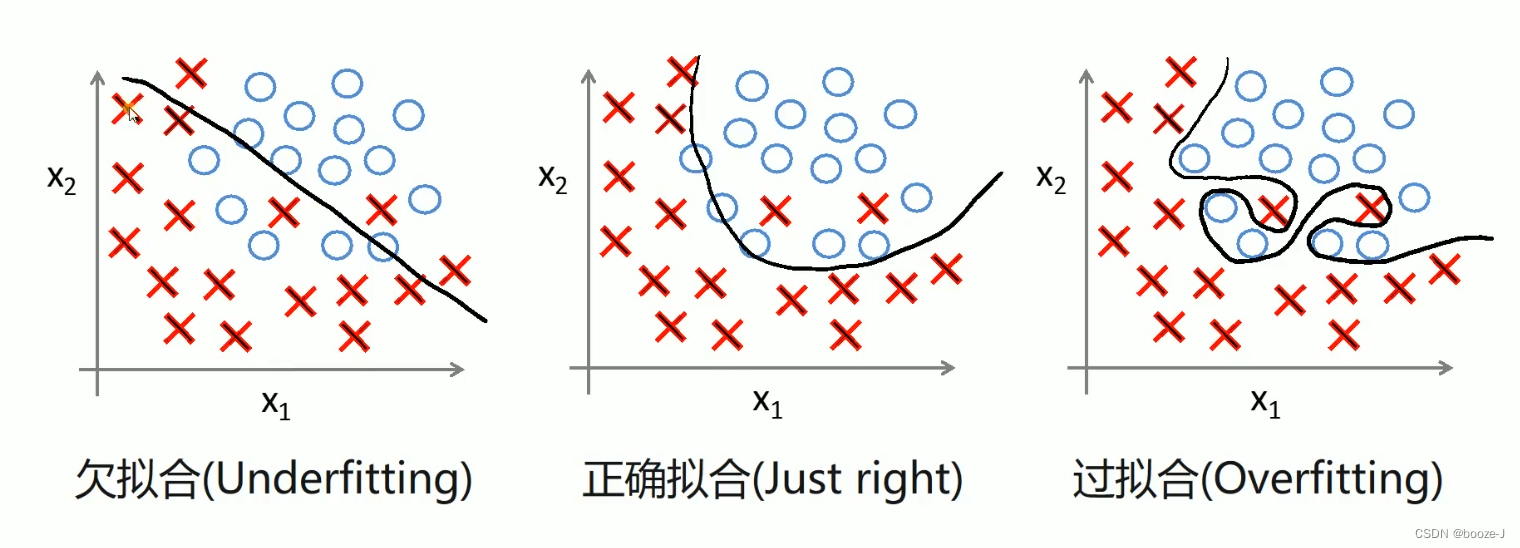
过拟合导致测试误差变大: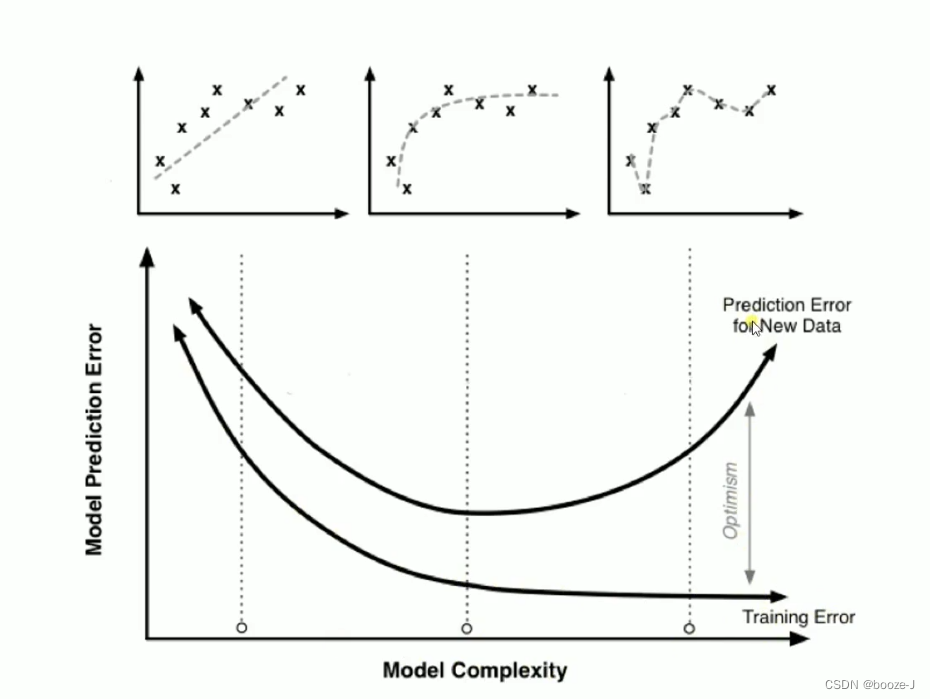
可以看到图中随着模型结构的越来越复杂,训练集的误差越来越小,测试集的误差先变小后变大,过拟合导致测试误差变大。
比较好的情况是训练误差和测试误差这两条线比较接近。
防止过拟合
1.增大数据集
数据挖掘领域流行着这样一句话,“有时候拥有更多的数据胜过一个好的模型”。一般来说更多的数据参与训练,训练得到的模型就越好。如果数据太少,而我们构建的神经网络又太复杂的话就比较容易产生过拟合的现象。
2.Early stopping
在训练模型的时候,我们往往会设置一个比较大的选代次数。Early stopping便是一种提前结束训练的策略用来防止过拟合。
一般的做法是记录到目前为止最好的validation accuracy,当连续10个Epoch没有达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping)。
3.Dropout
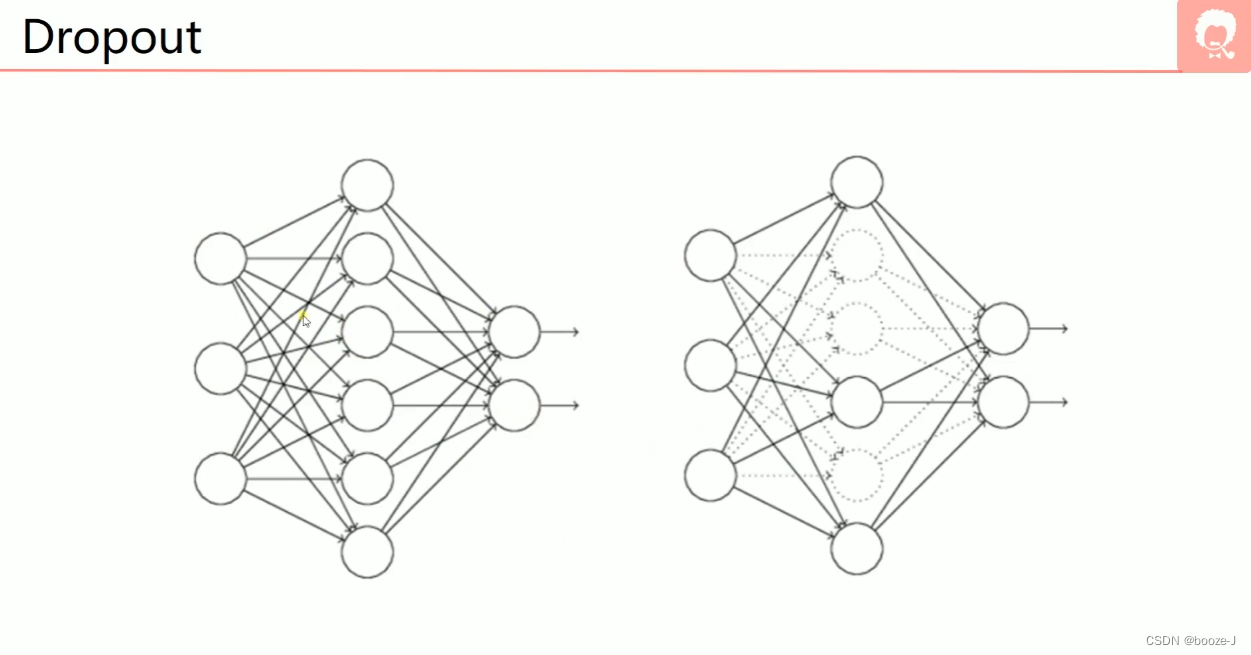
每次训练的时候,都会随机的去关闭一些神经元,关闭的意思并不是去掉,而是这些画虚线的神经元不参与训练。注意一般训练完,测试模型的时候,是使用所有神经元,不会进行dropout。
4.正则化
C0代表原始的代价函数,n代表样本的个数, λ \lambda λ就是正则项系数,权衡正则项与C0项的比重。
L1正则化:
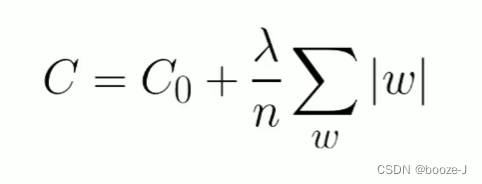
L1正则化可以达到模型参数稀疏化的效果。
L2正则化: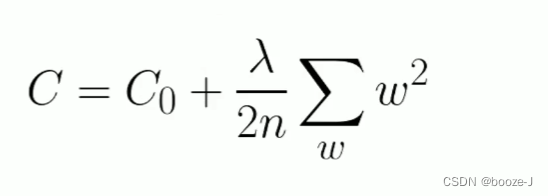
L2正则化可以使得模型的权值衰减,使模型参数值都接近于0。
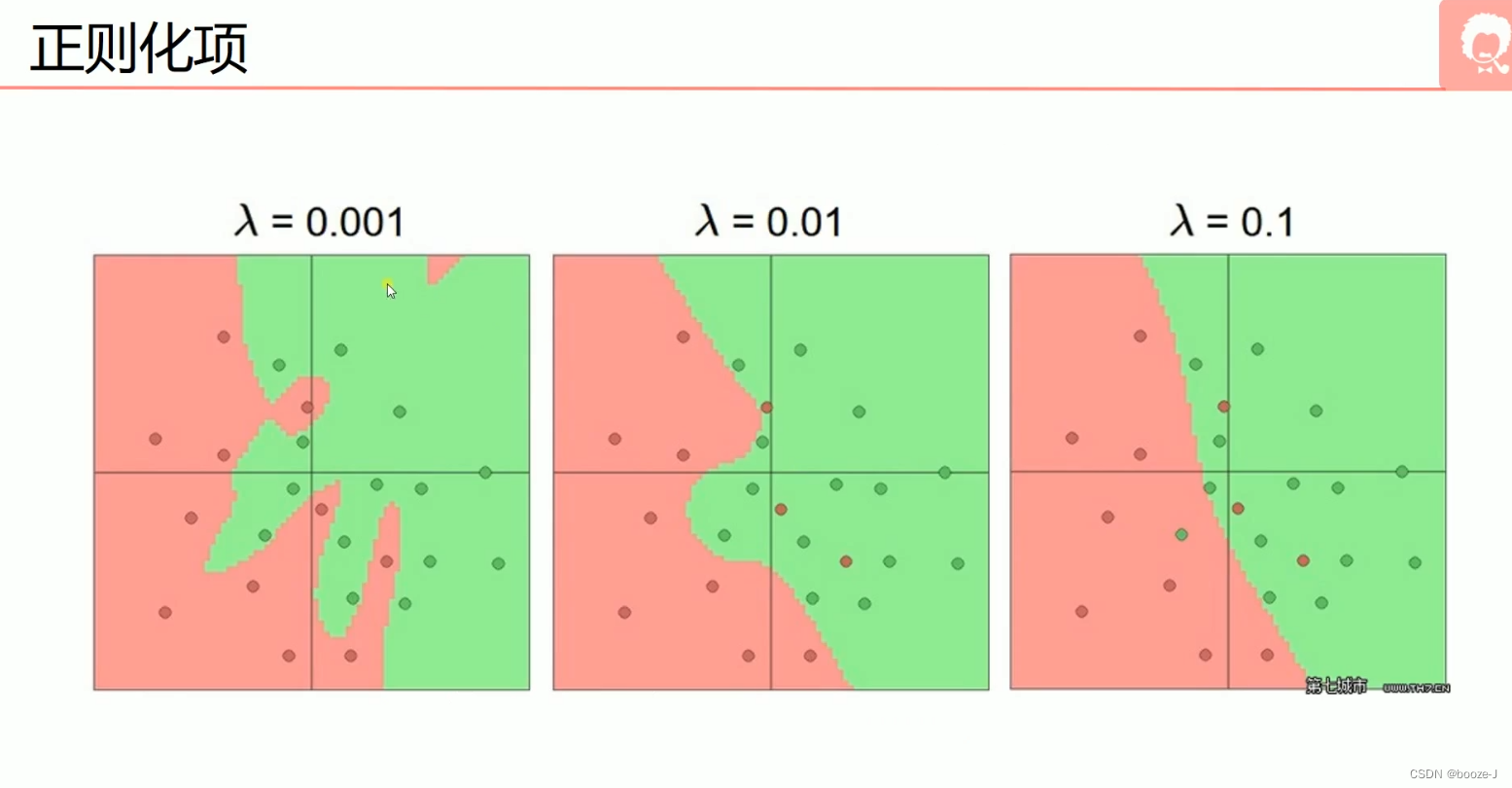
当 λ \lambda λ=0.001时,出现了过拟合现象,当 λ \lambda λ=0.01时,有较轻微的过拟合,当 λ \lambda λ=0.1的时候没有出现过拟合现象。
边栏推荐
- Leetcode brush questions
- 新库上线 | CnOpenData中国星级酒店数据
- Reptile practice (VIII): reptile expression pack
- 【GO记录】从零开始GO语言——用GO语言做一个示波器(一)GO语言基础
- 从服务器到云托管,到底经历了什么?
- Semantic segmentation model base segmentation_ models_ Detailed introduction to pytorch
- Su embedded training - Day3
- C# 泛型及性能比较
- 玩轉Sonar
- From starfish OS' continued deflationary consumption of SFO, the value of SFO in the long run
猜你喜欢
Password recovery vulnerability of foreign public testing

他们齐聚 2022 ECUG Con,只为「中国技术力量」
基于微信小程序开发的我最在行的小游戏
Interface test advanced interface script use - apipost (pre / post execution script)
1293_ Implementation analysis of xtask resumeall() interface in FreeRTOS
How to learn a new technology (programming language)
New library launched | cnopendata China Time-honored enterprise directory
5g NR system messages
ThinkPHP kernel work order system source code commercial open source version multi user + multi customer service + SMS + email notification

华为交换机S5735S-L24T4S-QA2无法telnet远程访问
随机推荐
Deep dive kotlin synergy (XXII): flow treatment
RPA cloud computer, let RPA out of the box with unlimited computing power?
[Yugong series] go teaching course 006 in July 2022 - automatic derivation of types and input and output
Summary of weidongshan phase II course content
Reentrantlock fair lock source code Chapter 0
基于卷积神经网络的恶意软件检测方法
C language 001: download, install, create the first C project and execute the first C language program of CodeBlocks
【obs】Impossible to find entrance point CreateDirect3D11DeviceFromDXGIDevice
CVE-2022-28346:Django SQL注入漏洞
华为交换机S5735S-L24T4S-QA2无法telnet远程访问
Service Mesh的基本模式
New library online | information data of Chinese journalists
SDNU_ ACM_ ICPC_ 2022_ Summer_ Practice(1~2)
Codeforces Round #804 (Div. 2)(A~D)
Analysis of 8 classic C language pointer written test questions
Cancel the down arrow of the default style of select and set the default word of select
第一讲:链表中环的入口结点
ThinkPHP kernel work order system source code commercial open source version multi user + multi customer service + SMS + email notification
接口测试进阶接口脚本使用—apipost(预/后执行脚本)
ReentrantLock 公平锁源码 第0篇