当前位置:网站首页>Hiengine: comparable to the local cloud native memory database engine
Hiengine: comparable to the local cloud native memory database engine
2022-07-05 12:58:00 【Huawei cloud developer Alliance】
Abstract :HiEngine HUAWEI GaussDB (for MySQL) Integrate , Bring the advantages of an in memory database engine to the cloud , And coexist with disk based engine .HiEngine Performance is higher than traditional storage centric solutions 7.5 times .
This article is shared from Huawei cloud community 《SIGMOD’22 HiEngine Interpretation of the thesis 》, author : Cloud database innovation Lab .
Reading guide
Huawei cloud database innovation Lab In the first paper 《HiEngine: How to Architect a Cloud-Native Memory-Optimized Database Engine》 Huawei self-developed 、 Memory centric cloud native memory database engine HiEngine.SIGMOD, namely Special Interest Group on Management Of Data International Conference on Data Management , The conference was organized by the American Computer Association (ACM) Data Management Professional Committee (SIGMOD The organization's 、 The top international academic conference in the field of database .HiEngine It is cloud database innovation LAB One of the key technological achievements in the field of cloud native memory database .
Abstract
High performance memory database engine has become an essential basic component in many systems and Applications , However, most existing systems are designed based on local memory storage , It can't give full play to the advantages of cloud computing environment . Most of the existing cloud native database systems follow the design centered on external storage .HiEngine Key features include :1) In addition to the separation of storage and accounting , On the computing side, the reliable memory service of cloud infrastructure is used to achieve fast persistence and reliability ;2) Achieve the same performance as the main memory database engine ;3) And backward compatibility with existing cloud native database systems .
HiEngine HUAWEI GaussDB (for MySQL) Integrate , Bring the advantages of an in memory database engine to the cloud , And coexist with disk based engine .HiEngine Performance is higher than traditional storage centric solutions 7.5 times .
Research background
1. Memory-centric Computing architecture
Memory centric computing has become a research hotspot in academia and industry . Persistent memory provides DRAM Level performance and Flash Flash level capacity , The research and application of pool memory based on persistent memory has gradually become a new direction of exploration . Academic research prototype system has HydraDB、RAM Cloud、NAM-DB、Hotpot、DDC And Infiniswap, Industrial systems such as FaRM、SAP HANA、SRSS SCM、WSCs、 And DAOS etc. .
meanwhile , Customers of in memory databases migrate applications to the cloud , Providers provide cloud native memory optimized OLTP Solutions have become a trend .
2. OLTP Database Ecology

Most of the existing cloud local database systems are disk resident databases , Follow a storage centric design , Such as Aurora、PolarDB、GaussDB(for be used for MySQL) etc. . They have the following characteristics : Page block based IO、, Page oriented layout and buffer pool . Besides
Specially , They have buffer pools that the in memory database does not have , This directly affects how to build an engine in the cloud platform and make full use of the hardware performance of memory devices . At present , Most in memory databases are designed based on local deployment solutions , You can't work directly in the cloud . Although some memory databases are separated from computing ( Such as NAM-DB) It can provide cloud native features , But their access latency across the network is expensive .

3. Huawei cloud infrastructure
Huawei cloud storage infrastructure services have the following characteristics :

- Hardware trends and challenges :1) Introduce persistent memory into the memory computing separation architecture , In particular, configuring persistent memory on the computing side can provide high-speed transaction log caching and other functions , But this is different from that of the computing node Stateless Characteristics contradict .2) be based on ARM The multi-core processor has better cost performance and ideal energy consumption , But it also brings Cross-NUMA Multi core expansion challenge .
- SRSS: As a new generation of distributed storage service of Huawei cloud , It USES RDMA Based on modern SSD/NVM On top of hardware , Adopt log structured additional storage .
- SRSS The necessary persistent memory primitives are provided in the cloud .SRSS Support memory semantics and persistent storage on the computing side , customized mmapMMAP Kernel driver API Support consistent reading of data from local or remote persistent storage ,SRSS Provided by memory mapping in addition to opening 、/ close 、/ Additional 、/ Read and other interfaces , It also provides memory semantic operations . Data is stored in three copies on the computing side and the storage side , Adopt a storage network with low latency . This allows the computing node to persist locally on the computing side and remotely on the storage side , Similarly, there is no round-trip network overhead on the critical path between storage tiers .
HiEngine framework
This paper presents a cloud native memory optimized memory database engine HiEngine To address these challenges .HiEngine Architectural features include :
1) Introduce persistent state into the computing layer , To support fast persistence and low latency transactions .
2) Logs are data .
3) At the computing level SRSS Use persistent memory ( Such as Intel Optane Memory ) Store replica logs synchronously in three compute nodes , At the same time, asynchronously persist to remote storage .
4)HiEngine The system has three-layer physical structure and three-layer logical structure , The logical log layer and the computing layer are located in the same physical location .

1. Log centric Log-centric MVCC Storage engine Overview

HiEngine Around “ Logs are databases ” The idea of , And some key technologies are used, such as lock free index 、MVCC Transaction model 、tuple-level Tuple level memory layout . It USES SRSS Realize data persistence and rapid recovery .HiEngine adopt rRowmap Data access ,rowmap It is HiEngine The core data structure of , Support MVCC、 Efficient checkpointing and parallel recovery .
2. Tuple-level Memory layout
HiEngine Use MVCC Transaction model , This fully excavates SRSS Performance and functional features . At the memory layout level , It uses lock-free Of ARTree Indexes 、 Use Row Map To map rowid That's ok ID To the specific data version version data .

Tuple-level Memory layout features include :
1) A version contains many key fields , Such as [tmin, tmax, nextver, loffset…] Field ;
2)Index The leaf node of is a rowid That's ok ID;
3) The key of the secondary index is defined by the user and the current row IDrowid form ;
4) The version chain is based on Epoch Space management mechanism and based on Session Controlled Non-blocking Garbage collection strategy of .
3. Transaction model
at present HiEngine Provide snapshot isolation level . When the transaction begins , It is assigned a read CSN And a globally unique TID, And submit tminTMIN and TMAXtmax In the field TID Replace with CSN.HiEngine Two timestamp authorization methods are proposed . The timestamp allocation delay of the logical clock is 40 Microsecond , The delay of the global clock without atomic clock is 20 Microsecond .

In distributed database ,Global Clock It is the best choice for high-performance timestamp timing and high-performance expansion .
4. PIA/RowMap
HiEngine Organize data records in the form of logs , No, “ page ” The concept of .PIA Record the version line ID Map to record address .

PIA There are the following benefits :
- The row update operation will not change the internal structure of the index
- Secondary index “ key ”=“ User defined key + RID”
- Checkpoints become lightweight , Because you only need persistence PIA Not real data
- Recovery will only rebuild PIA, Instead of reading tuple versions
5. Highly reliable and scalable Redo-Only Logging
HiEngine in ,WAL There are two purposes : Persistence assurance and 、 Data copy implementation .WAL It is synchronously persisted to the near end of the computing side SRSS SCM pool pool in , Then it is distributed asynchronously to the storage side SRSS PLOG.
SRSS adopt PLOG Provides an additional abstraction and segment structure .HiEngine Use distributed logging on the computing side , Once the transaction log record is persisted to the persistent memory of the computing side , The transaction will be committed . Logs are batched and asynchronously refreshed to the storage tier .

PLOGPLog In physical structure , Organize by segment , Then map to Plog. Each thread maintains an open PLOGPLog, Segments are dynamically allocated and released on demand . Each segment consists of PLOG Plog ID and PLOGPlog To identify .
HiEngine Distributed logging, It uses ::
- Add write and based on mmapMMAP The reading of
- The updated version contains the complete content of a record
- Use SRSS The additional interface of writes the log record to the segment / PLOGPlog
- After the three copies of data are successfully persisted to the persistent memory on the computing side, the transaction is committed
6. Dataless Checkpointing and parallel recovery
To accelerate recovery ,HiEngine Run checkpoints in the background . Checkpoints become very lightweight , Just persist PIA.
Recovery is divided into loading stage and replay stage : 1) once PIA Setup completed , The recovery is complete ;2) Subsequent visits will be made through mmapMMAP Bring the data version into main memory . We also designed a parallel recovery algorithm :
1). Multiple replay threads scan logs in turn ( One per thread )
2). If the logging operation is an insert or update operation , Then the corresponding PIA The entry is updated to the offset in the log
3). Only when PIA When an entry points to an old record version , The replay thread will overwrite with the new record address PIA entry
meanwhile ,HiEngine Perform log merging regularly to do log garbage collection . Merge thread gets the current minimum read LSN Snapshot , The snapshot is stored locally as truncLSN, For partial consolidation . Complete consolidation requires deleting all versions and records of the table , In order to gather data into new storage space for repair loffset. Asynchronously after completing log merging ,HiEngine Will repair asynchronously PIA Medium loffset.

7. Index persistence and checkpoints
stay HiEngine in , Changes to the index tree are not immediately persistent . The checkpoint of an index tree is similar to a log structure merge tree . However, there is read amplification . Fortunately , Read amplification exists .

The index has the following features including :1)1 Main in memory R/W Trees + Persistent storage R/O The forest ;2) be based on AR-Tree Of lock-free Tree index ;3) adopt mmapMMAP Read the index of persistent storage ;4) The trees in the forest can be of different kinds ( It means you can have different kinds of trees ( For example B+ -tTree);5) Index merging : Merge multiple trees into one .
Deployment way

HiEngine Two deployment modes are proposed :
1. Vertical integration :HiEngine And GaussDB Existing InnoDB Engine coexistence ( in the light of MySQL), stay CREATE TABLE Use in statement WITH ENGINE=HiEngine Parameters , Inquire about ( Compiled or interpreted ) Will be routed to the corresponding storage engine for execution .
2. Horizontal integration . Put it in front of the database table as a transparent ACID cache , Part or all of it as the front of the table ACID cache .
This article focuses on the deployment of vertical integration ,HiEngine HUAWEI GaussDB(for MySQL) Integrated into a single engine . This paper mainly studies the vertical integration mode .HiEngine And GaussDB Existing InnoDB Engine coexistence ( in the light of MySQL). Users only need to be in CREATE TABLE The statement declares that the engine type query will be routed to the corresponding storage engine .
System evaluation
This article focuses on the deployment of vertical integration ,HiEngine HUAWEI GaussDB(for MySQL) Integrated into a single engine .
The two engines share the same SQL layer , Besides HiEngine Using code generation technology . We use Sysbench And standards TPC-C Benchmark to compare HiEngine And three other industrial systems . All evaluations were conducted in two environments , Single server and cloud SRSS.

HiEngine The performance on both platforms is significantly better than DBMS-M. HiEngine Single server performance is up to 6500 ten thousand tpmC.


The end-to-end performance under Compilation execution is > 50%. We evaluate the target by setting the memory allocation policy and workload partition armARM The optimization of the . In all cases ,HiEngine The performance of the storage engine is better than DBMS-M Higher than 60%. Through to ARM On the platform TPC-C Model analysis , Span Socket Every increase in remote access 10%, Performance degradation 5%. The optimized RTO Performance improved 10 times .

summary
This paper proposes HiEngine, This is a cloud native memory optimized memory database engine . It uses modern cloud infrastructure and fast persistent memory on the computing side , And bring the advantages of the main memory database engine to the cloud , And coexist with disk based engine . Besides , Its performance is comparable to that of the local memory database engine .
1. Modern cloud infrastructure has been developing rapidly , Especially in the development of modern hardware technology . The new hardware includes multi-core processors, especially based on ARM The platform of 、 Large main memory and persistence SCM、 And RDMA Network, etc .
2. Most of the existing cloud native database engines are storage centric , This makes the potential of new hardware largely untapped in cloud native memory databases , At the same time, the cloud brings some unique challenges to the in memory database engine .
3. HiEngine Propose a cloud native memory optimized database engine , Its features include :1) The high-performance memory database that separates storage and computing is presented to users on the cloud ;2) Adopt Huawei's highly reliable shared cloud storage service , Support log centric storage and computing side high-performance persistent memory ;3) Optimization is based on ARM The multi-core processor of ;4) Maintain backward compatibility between memory centric and storage centric engines 、 Can be deployed as a single engine or in front of another engine ACID cache ;5) Compared with the previous system , Provide up to 7 The performance of The Times .
4. HiEngine Bridging the gap between academic prototype system and cloud production system .
5. HiEngine It is the key engine of Huawei cloud's next generation cloud native distributed memory database .
Click to follow , The first time to learn about Huawei's new cloud technology ~
边栏推荐
- Install rhel8.2 virtual machine
- A deep long article on the simplification and acceleration of join operation
- Transactions from December 29, 2021 to January 4, 2022
- Docker configures redis and redis clusters
- VoneDAO破解组织发展效能难题
- ##无监控,不运维,以下是监控里常用的脚本监控
- Transactions from December 27 to 28, 2021
- About LDA model
- Insmod prompt invalid module format
- Halcon 模板匹配实战代码(一)
猜你喜欢
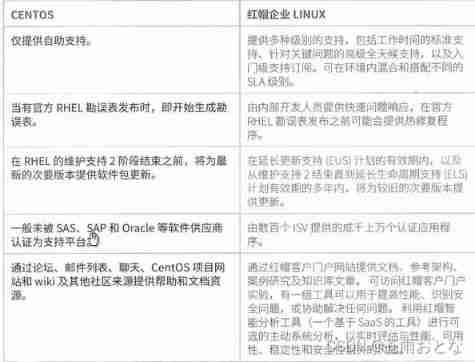
RHCSA1
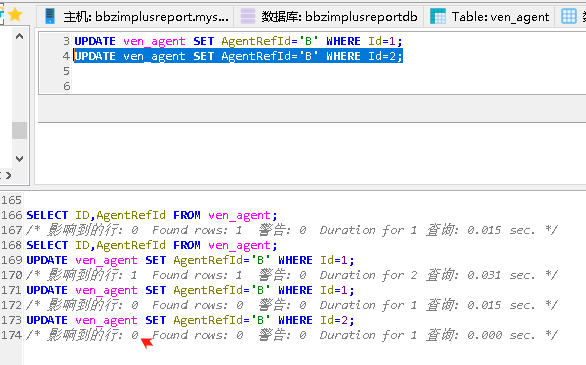
MySQL 巨坑:update 更新慎用影响行数做判断!!!

Tips and tricks of image segmentation summarized from 39 Kabul competitions
I met Tencent in the morning and took out 38K, which showed me the basic smallpox
开发者,云原生数据库是未来吗?
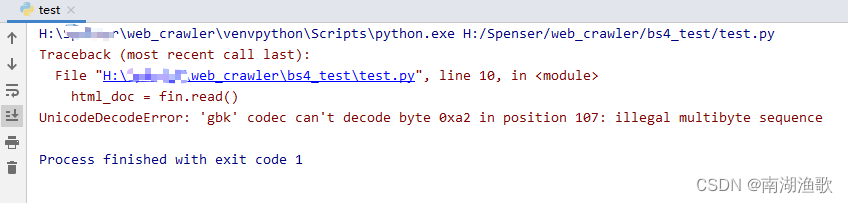
解决 UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xa2 in position 107
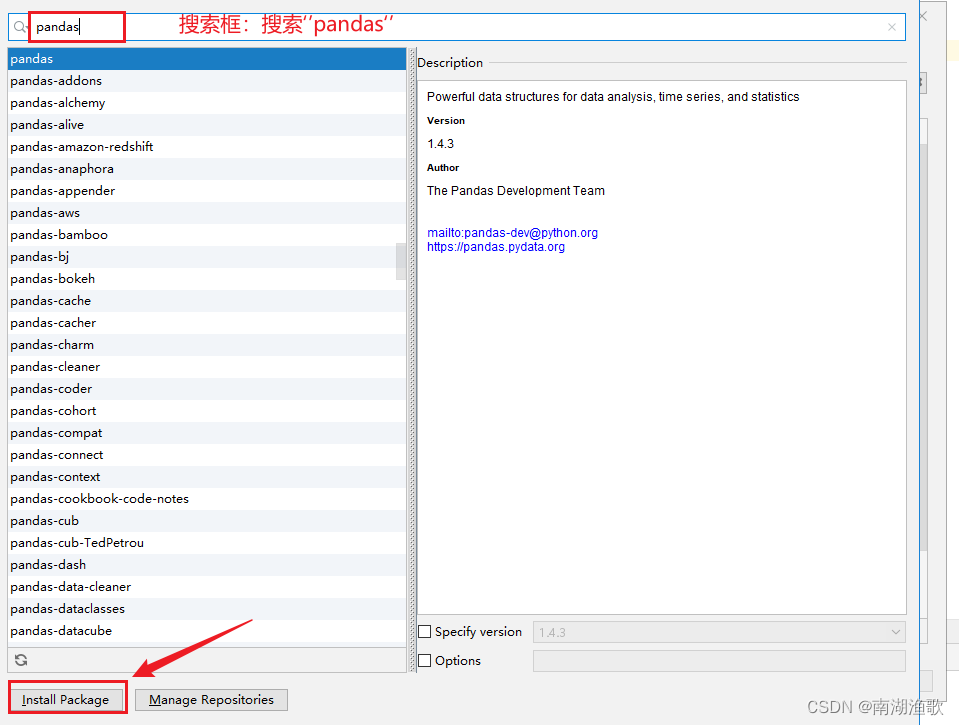
PyCharm安装第三方库图解
Simply take stock reading notes (2/8)
Overflow toolbar control in SAP ui5 view
946. 验证栈序列
随机推荐
RHCSA3
Halcon 模板匹配实战代码(一)
Taobao short video, why the worse the effect
滴滴开源DELTA:AI开发者可轻松训练自然语言模型
Taobao order interface | order flag remarks, may be the most stable and easy-to-use interface
Introduction aux contrôles de la page dynamique SAP ui5
Transactions from January 6 to October 2022
Kotlin process control and circulation
从39个kaggle竞赛中总结出来的图像分割的Tips和Tricks
RHCSA5
JXL notes
Docker configures redis and redis clusters
A possible investment strategy and a possible fuzzy fast stock valuation method
Simply take stock reading notes (4/8)
2021-12-21 transaction record
Shi Zhenzhen's 2021 summary and 2022 outlook | colorful eggs at the end of the article
How to connect the API interface of Taobao open platform (super detailed)
【云原生】Nacos-TaskManager 任务管理的使用
Taobao product details API | get baby SKU, main map, evaluation and other API interfaces
【云原生】Nacos中的事件发布与订阅--观察者模式