当前位置:网站首页>Train your dataset with yolov4
Train your dataset with yolov4
2022-07-05 07:47:00 【Fall in love with wx】
Environmental Science :ubuntu16.04 cuda8.0 cudnn6.0.1 GT1070
1,GitHub:https://github.com/AlexeyAB/darknet download
2, compile ;
① modify makefile file
GPU=1
CUDNN=1
CUDNN_HALF=0# Here, if the computing power of the graphics card is less than 7.0, No need to change to 1
OPENCV=1
AVX=0
OPENMP=1
LIBSO=1
’‘’
DEBUG=1
‘’‘
NVCC=/usr/local/cuda-8.0/bin/nvcc# Change to your own path
②make
remarks : Common mistakes can be found online , It's just a version problem
3, Download pre training model :GitHub There is
4, A simple test :
./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jpg
The test results :
Done! Loaded 162 layers from weights-file
data/dog.jpg: Predicted in 67.411000 milli-seconds.
bicycle: 92%
dog: 98%
truck: 92%
pottedplant: 33%

5, Train your data set :
① Collecting data sets , This is collected according to their own project requirements , There are the vast majority of data sets needed on the Internet , Download classification .
② For data set preprocessing : You can change the names of many pictures to VOC The format of the dataset , namely 000**.jpg. Modify the code as follows :
import os
path=input(' Please enter the file path ( Add at the end /):')
# Get all the files in this directory , Put it in the list
f=os.listdir(path)
n=0
for i in f:
# Set old file name ( Is the path + file name )
oldname=path+f[n]
# Set a new file name
newname=path+'000'+str(n+1)+'.jpg'
# use os Module rename Method to rename the file
os.rename(oldname,newname)
print(oldname,'======>',newname)
n+=1
③ Mark data sets : I use labelImg Tools for marking , Enclosed GitHub link :https://github.com/tzutalin/labelImg Very simple installation and operation .
④ Expand the data set : Generally used to flip 、 shear 、 rotate , According to the needs of their own projects, expand to the required number of data sets .( More code , Inconvenient to paste , You can have a private chat with the friends you need )
⑤ Change the dataset to VOC Dataset format :
One 、 Dataset folder format
VOC The format of dataset folder is generally :
---VOC***( Can be the date of the day in person VOC531)
----Annotations( It's all marked inside .xml file )
----ImageSets
----Main
----JPEGImages( Inside are all pictures )
Two 、 Split data sets
It is generally divided into training sets 、 Verification set 、 Test set , The division proportion can be adjusted by yourself ( I use 9-1) The code is as follows
import os
import random
xmlfilepath=r'/home/nph/darknet-master/VOC531/Annotations' #change xml path
saveBasePath=r"/home/nph/darknet-master/" #change base path
trainval_percent=0.9 #adjust trainval percentage
train_percent=0.9 #adjust train percentage
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'VOC531/ImageSets/Main/trainval.txt'), 'w') #change your path
ftest = open(os.path.join(saveBasePath,'VOC531/ImageSets/Main/test.txt'), 'w') #
ftrain = open(os.path.join(saveBasePath,'VOC531/ImageSets/Main/train.txt'), 'w') #
fval = open(os.path.join(saveBasePath,'VOC531/ImageSets/Main/val.txt'), 'w') #
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
The path that needs to be changed has been marked , After running in Main Four will be generated under the file txt file : Respectively trainval.txt、train.txt、test.txt and val.txt. Inside is the name of the corresponding category picture , That is, the previous named number 000***( There is no suffix ) Pictured :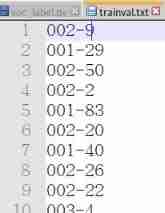
This is the label of the picture .
3、 ... and 、 Extract label and coordinate information .
This step is to combine the label information with xml Extract the coordinate information marked in the file , The code is as follows :
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('531', 'train'), ('531', 'val'), ('531', 'test')] # Change it to your own VOC*** Digital information after
classes = ["supervisor_white", "technicist_blue", "worker_yellow", "manager_red" ] # Classify your data set in quotation marks
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOC%s/labels/'%(year)):
os.makedirs('VOC%s/labels/'%(year))
image_ids = open('VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
Everything that needs to be modified has been marked , After running, it will be in VOC*** A... Is generated under the file labels file , Inside is txt file , It stores the information of each picture marking box , Pictured :
stay VOC*** Folder directory will generate three txt file , It is generally named :***(VOC Back number )_train(test/val).txt, Inside is the path of photos , Pictured :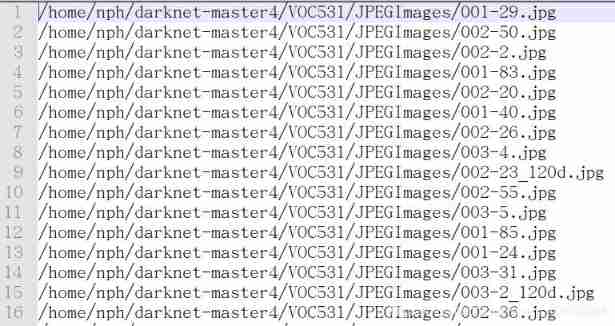
These three txt Files can be put into VOC In the file , It is convenient to fill in the address during the later training .
thus ,VOC The format of data set has been completely changed , Next is the change YOLOv4 Network files for training .
⑥ Modify the network file :
Major changes cfg names data file
take darknet-master/cfg/yolov4-custom.cfg、darknet-master/cfg/coco.data and darknet-master/data/coco.names Copy the file to your own VOC*** Under the document
One 、cfg file
modify cfg file ( I changed it to 531.cfg)
[net]
# Testing # The training process will test Three lines of comment
#batch=1
#subdivisions=1
# Training
batch=32 # Modify according to your own graphics card memory , It's usually 16,32,64
subdivisions=8 # Rewrite according to the uplink , It's usually 4,8,16
width=416 # The size can be modified by yourself , It's usually 16 Multiple
height=416
'''
learning_rate=0.001
burn_in=1000
max_batches = 12000 # It's usually classess*2000, Training category *2000
policy=steps
steps=9600,10800 #max_batches Of 0.8 and 0.9 times
scales=.1,.1
[convolutional]
size=1
stride=1
pad=1
filters=24 #(classes+5))3
activation=linear
[yolo]
mask = 6,7,8
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=3 # Number of training categories
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
scale_x_y = 1.05
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
max_delta=5
#3 individual yolo Layers need to be changed , All in cfg The lowest level of the file
Two 、 modify data file
open 531.data file , Revised as follows :
classes= 3
train = /home/u/qingxin/potgraduate/Fire/darknet-master/Fire/Multi/VOC531/531_train.txt # Here is the image path file of the training generated above , Change to your own path
valid = /home/u/qingxin/potgraduate/Fire/darknet-master/Fire/Multi/VOC531/531_val.txt # Verify the image path file , Change to your own path
names = /home/u/qingxin/potgraduate/Fire/darknet-master/Fire/Multi/VOC531/3fire.names #names File path
backup = /home/u/qingxin/potgraduate/Fire/darknet-master/Fire/Multi/VOC531/backup # Training model storage address during training , You can modify it yourself
3、 ... and 、 modify names file
open 531.names file , Revised as follows :
supervisor_white
technicist_blue
worker_yellow
manager_red
That is, the name of your dataset classification
thus , The network file has been modified , You can train .
⑦ Training
stay darknet-master Enter instructions under the path
./darknet detector train VOC531/531.data VOC531/531.cfg yolov4.conv.137 -gpus 1,2 -dont_show
They are training instructions -data file -cfg file - Pre training model - Appoint GPU
You can add logs
./darknet detector train VOC531/531.data VOC531/531.cfg yolov4.conv.137 -gpus 1,2 -dont_show 2>&1 | tee VOC531/531.log
Start training ~
Test to be updated ~
边栏推荐
- Practical application cases of digital Twins - fans
- mysql 盲注常见函数
- [professional literacy] core conferences and periodicals in the field of integrated circuits
- Global and Chinese markets for medical oxygen machines 2022-2028: Research Report on technology, participants, trends, market size and share
- Extended application of single chip microcomputer-06 independent key
- 1089 insert or merge, including test point 5
- Could NOT find XXX (missing: XXX_LIBRARY XXX_DIR)
- Software designer: 03 database system
- Detour of Tkinter picture scaling
- RTOS in the development of STM32 single chip microcomputer
猜你喜欢

The number of occurrences of numbers in the offer 56 array (XOR)

A complete set of indicators for the 10000 class clean room of electronic semiconductors
Close of office 365 reading
Set theory of Discrete Mathematics (I)

Altium Designer 19.1.18 - 清除测量距离产生的信息
SQL JOINS

Oracle triggers and packages
High end electronic chips help upgrade traditional oil particle monitoring
II Simple NSIS installation package
What is Bezier curve? How to draw third-order Bezier curve with canvas?
随机推荐
Day06 class variables instance variables local variables constant variables naming conventions
Win10 shortcut key
Linked list (establishment, deletion, insertion and printing of one-way linked list)
Global and Chinese markets of large aperture scintillators 2022-2028: Research Report on technology, participants, trends, market size and share
Scm-05 basis of independent keyboard
Apple animation optimization
. Net service governance flow limiting middleware -fireflysoft RateLimit
assert_ Usage of param function
Day08 ternary operator extension operator character connector symbol priority
What is Bezier curve? How to draw third-order Bezier curve with canvas?
MySQL blind note common functions
Leetcode solution - number of islands
Day09 how to create packages import package naming conventions Alibaba Development Manual
Acwing - the collection of pet elves - (multidimensional 01 Backpack + positive and reverse order + two forms of DP for the answer)
Day01 markdown log entry tips
RF ride side door processing of prompt box
Close of office 365 reading
万字详解八大排序 必读(代码+动图演示)
Function of static
Distinction between heap and stack