当前位置:网站首页>MapReduce working mechanism
MapReduce working mechanism
2022-07-06 09:35:00 【Prism 7】
Catalog
1. Map Task Working mechanism
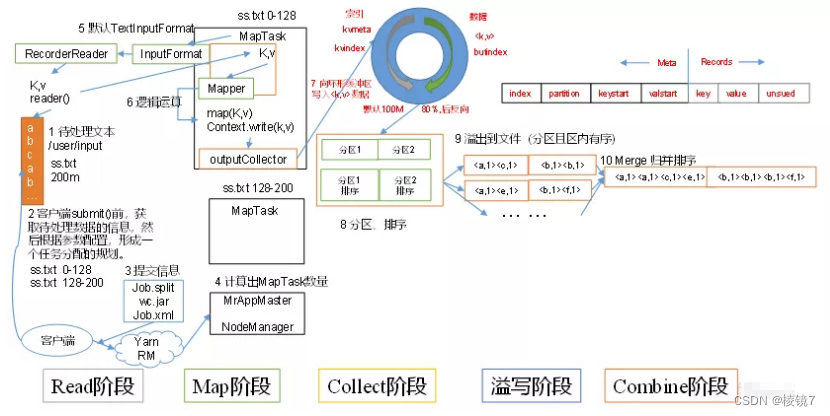
1.1 summary
inputFile adopt split To be cut into several split file , adopt RecordReader Read content by line to map function ( Write your own method of processing logic ), The data is map Hand it over to OutputCollect The collector , For the results key partition , Every map task Each has a memory buffer ( Ring buffer ) Deposit map Output result of , When the buffer reaches the overflow write ratio (0.8) You need to overflow the data in the buffer to the disk in the form of a temporary file ( Before writing data to local disk , First, you need to sort the data locally , And merge the data if necessary 、 Compression and other operations . After sorting , Data is aggregated in partitions , And all data in the same partition are in accordance with key Orderly ), When the whole map task After that, merge the temporary files generated in the disk , Generate the final formal output file , And then wait reduce task Pull away .
1.2 The detailed steps
- Read data components InputFormat ( Default TextInputFormat) Will pass getSplits Methods logical slice planning is carried out on the files in the input directory to get block, How many block Just how many of them start up MapTask.
- Split the input file into block after , from RecordReader object ( The default is LineRecordReader) To read , With \n As a separator , Read a row of data , return <key,value>, Key Represents the offset value of the first character of each line ,Value Represents the content of this line of text
- Read block return <key,value>, Enter the user's own inheritance Mapper Class , Of board
Row user rewritten map function ,RecordReader Read a line, call here once - Mapper At the end of the logic , take Mapper Every result of is passed by context.write Conduct
collect data collection . stay collect in , It will be partitioned first , By default
HashPartitioner. - Next , Will write data to memory , This area of memory is called a ring buffer ( Default 100M), The function of the buffer is Batch collection Mapper result , Reduce disk IO Influence . our Key/Value Yes and Partition Results are written to the buffer . Of course , Before writing ,Key And Value Values are serialized into byte arrays
- When the data in the ring buffer reaches the overflow ratio column ( Default 0.8), That is to say 80M when , Overflow thread starts , You need to 80MB In space Key Sort (Sort). The order is MapReduce The default behavior of the model , The sort here is also the sort of serialized bytes .
- Merge overflow files , Each overflow generates a temporary file on the disk ( Before writing, judge whether there is Combiner), If Mapper The output is really big , There have been many such overflows , There will be multiple temporary files on the disk . When the whole data processing is finished, the temporary files on the disk are processed Merge Merge , Because only one final file is written to disk , And an index file is provided for this file , To record every reduce The offset of the corresponding data
Combiner: Mapreduce Medium Combiner Just to avoid map The tasks and reduce Data transfer between tasks ⽽ Set up ,Hadoop allow ⽤ For map task The output of specifies ⼀ Merge functions . That is, in order to reduce the transmission to Reduce The amount of data in . It is mainly to cut Mapper The output from ⽽ Reduce ⽹ Network bandwidth and Reducer Load on .
2. Reduce Task Working mechanism
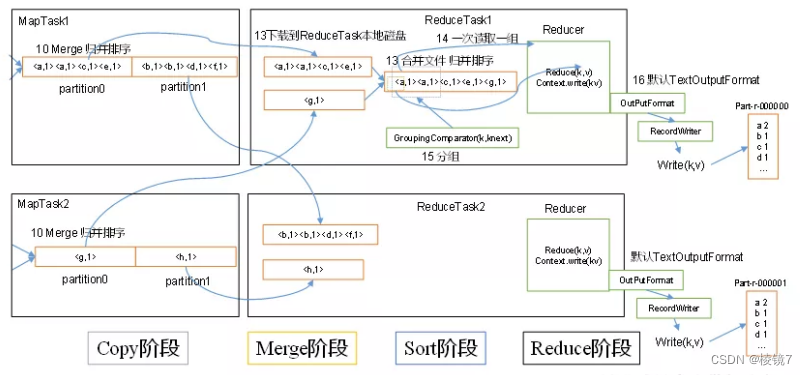
2.1 The detailed steps
(1)Copy Stage :ReduceTask From each MapTask Copy a piece of data remotely , And for a piece of data , If its size exceeds a certain threshold , Write it to disk , Otherwise, put it directly in memory .
(2)Merge Stage : While copying data remotely ,ReduceTask Started two background threads to merge files on memory and disk , To prevent excessive memory usage or excessive files on disk .
(3)Sort Stage : according to MapReduce semantics , Users write reduce() Function input data by key A set of data for aggregation . In order to key Same data coming together ,Hadoop A sort based strategy . Because of the various MapTask It has realized the partial sorting of its own processing results , therefore ,ReduceTask Only need to merge and sort all data once .
(4)Reduce Stage :reduce() Function to write the calculation result to HDFS On .
3. Shuffle Working mechanism
shuffle The stage is divided into four steps : In turn : Partition , Sort , Statute , grouping , The first three steps are map Stages to complete , The last step is reduce Stages to complete .
shuffle yes Mapreduce At the heart of , It's distributed in Mapreduce Of map Phase and reduce Stage . Generally speaking, we should start from Map The output starts to Reduce The process before taking data as input is called shuffle
3.1 Shuffle Stage data compression mechanism
stay shuffle Stage , You can see the data through a large number of copies , from map Phase output data , All have to be copied over the network , Send to reduce Stage , In the process , It involves a large number of networks IO, If the data can be compressed , Then the amount of data sent will be much less .
hadoop The compression algorithm supported in it :
gzip、bzip2、LZO、LZ4、Snappy, These compression algorithms combine the rate of compression and decompression , Google's Snappy It's the best , We usually choose Snappy Compress .
4. Writing MR when , Under what circumstances can the protocol be used
Statute (combiner) It is a partial summary that cannot affect the running results of the task , Applicable to summation class , Not suitable for averaging .combiner and reducer The difference is the location of the operation ,combiner It's in every maptask The node is running , Reducer Receive global ownership Mapper Output result of
边栏推荐
- Redis geospatial
- Redis之Bitmap
- Global and Chinese market of AVR series microcontrollers 2022-2028: Research Report on technology, participants, trends, market size and share
- MapReduce工作机制
- Redis之连接redis服务命令
- Kratos战神微服务框架(三)
- 【深度學習】語義分割-源代碼匯總
- 五月刷题03——排序
- Sentinel mode of redis
- MapReduce instance (IX): reduce end join
猜你喜欢

Mapreduce实例(九):Reduce端join
Redis分布式锁实现Redisson 15问
Advanced Computer Network Review(4)——Congestion Control of MPTCP
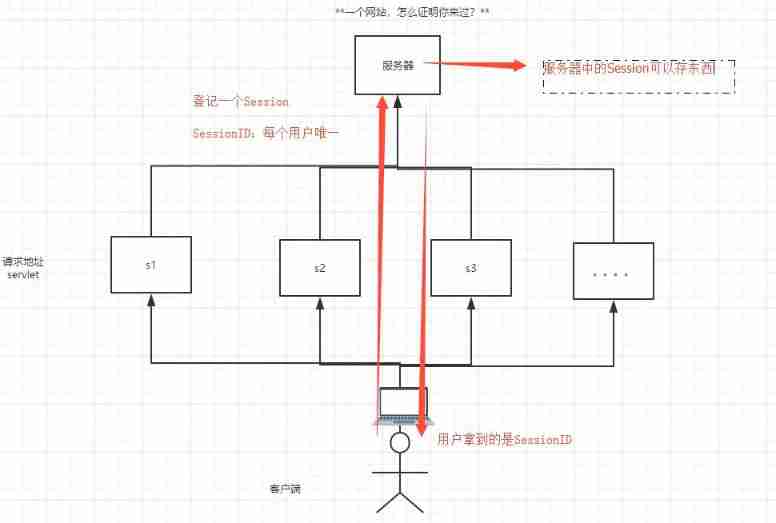
Detailed explanation of cookies and sessions
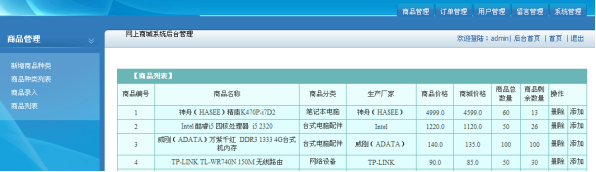
Design and implementation of online shopping system based on Web (attached: source code paper SQL file)

五月集训总结——来自阿光
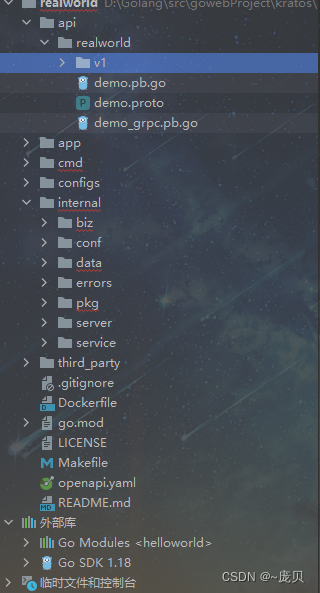
Kratos战神微服务框架(二)
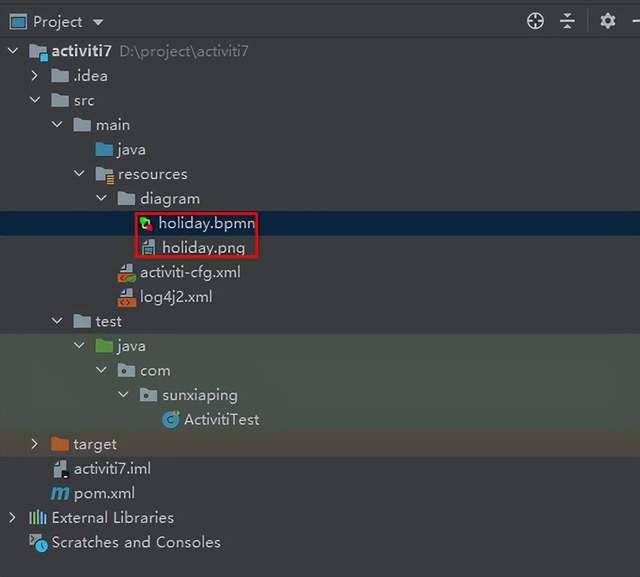
Activiti7工作流的使用
Design and implementation of online snack sales system based on b/s (attached: source code paper SQL file)
Persistence practice of redis (Linux version)
随机推荐
Global and Chinese market of capacitive displacement sensors 2022-2028: Research Report on technology, participants, trends, market size and share
Servlet learning diary 8 - servlet life cycle and thread safety
Sentinel mode of redis
CSP salary calculation
Publish and subscribe to redis
Design and implementation of film and television creation forum based on b/s (attached: source code paper SQL file project deployment tutorial)
The five basic data structures of redis are in-depth and application scenarios
Vs All comments and uncomments
Redis connection redis service command
Global and Chinese markets for modular storage area network (SAN) solutions 2022-2028: Research Report on technology, participants, trends, market size and share
Redis之核心配置
五月刷题26——并查集
五月刷题01——数组
Segmentation sémantique de l'apprentissage profond - résumé du code source
Sqlmap installation tutorial and problem explanation under Windows Environment -- "sqlmap installation | CSDN creation punch in"
One article read, DDD landing database design practice
Kratos ares microservice framework (II)
Redis分布式锁实现Redisson 15问
Redis cluster
Mapreduce实例(九):Reduce端join