当前位置:网站首页>Topic 1 Single_Cell_analysis(1)
Topic 1 Single_Cell_analysis(1)
2022-06-12 07:38:00 【柚子味的羊】
Topic 1 Single_Cell_analysis(1)
文章目录
Part1 Plan
Part2 原始数据复现——LUAD
Part3 Scissor——Cox regression
scissor的输入是三个数据源:单细胞表达矩阵,批量表达矩阵和interested的表型。每个批量的样本表型注释可以是连续变量、二元组向量或者临床生存数据。
1.prework
- miniconda安装:略,blog上有详细教程
- 在miniconda 安装seurat:seurat-package用于下载LUAD的singcell数据
2.准备单细胞数据
location <- "https://xialab.s3-us-west-2.amazonaws.com/Duanchen/Scissor_data/"
load(url(paste0(location, 'scRNA-seq.RData')))
dim(sc_dataset)

说明共有33694个基因和4102个cell 。对于Scissor中使用的单细胞数据,首选是包含预处理数据和构建网络的Seurat,使用Seurat-package预处理这些数据,构建一个cell-cell之间的similarity网络
注:Seurat_preprocessing()是author自己定义的function,contained in Scissor-package
2.1 Seurat_preprocessing()
(1)realize functions
- 对于每行数据创建一个Seurat 对象(即对于每个基因创建一个Seurat对象)
- 标准化需要处理的数据
- 特征识别
- 确定数据尺度和中新功能
- 对于sc_dataset构造一个SNN(shared nearest neighbor)图
- 通过基于SNN模块化优化的聚类算法识别细胞集群
- 降维选择特征数据(PCA,t-SNE,UMAP)
sc_dataset <- Seurat_preprocessing(sc_dataset, verbose = F)
class(sc_dataset)

sc_dataset

names(sc_dataset)

分簇——umap
DimPlot(sc_dataset, reduction = 'umap', label = T, label.size = 10)
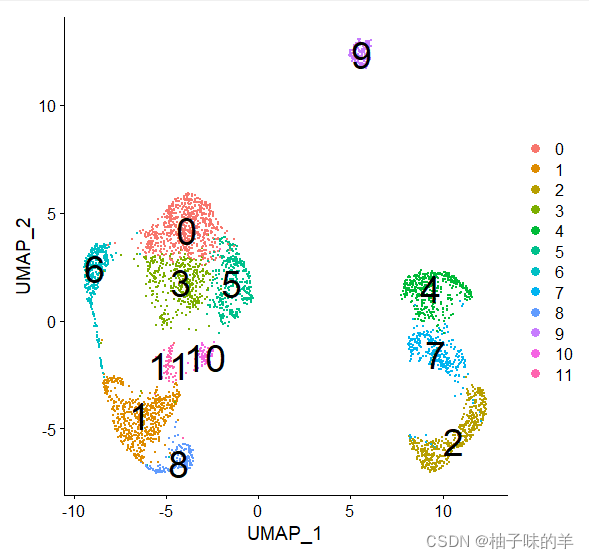
分簇——pca
DimPlot(sc_dataset,reduction='pca',label=T,label.size=10)

分簇——t-sne
DimPlot(sc_dataset,reduction='tsne',label=T,label.size=10)
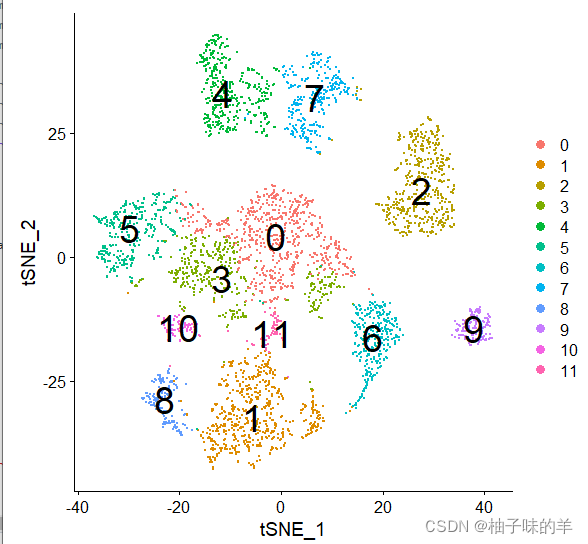
(2) mainly parameters
normalization methods :
- LogNormalize:每个cell的特征数除以该cell的所有特征数,并乘以Scale.Factor——使用log1p转换为自然数
- CLR:应用于居中的log比转换。
- RC:relative count.每个cell的特征数除以该cell的所有特征数,并乘以Scale.Factor
注:scale.factor是cell-level的归一化比例,可以设置
selectin.method:——变量特征选择的方法
- vst:首先根据local的loss进行多项式回归。挑选符合log(方差)和log(平均值)的关系,然后使用观察到的方差和均值标准化特征值。去除最大值后在标准化值后计算特征变量
- mvp:首先函数计算每个特征的平均表达和dispersion,之后依据平均表达将特征划分进num.bin的bins中,并计算每个bin中dispersion的z-score(这样做的目的是识别不同的特征在编译和表达之间的关系强弱)
- dispersion:选择具有高dispersion值得基因
3.准备bulk-cell和表型phenotype数据
load(url(paste0(location, 'TCGA_LUAD_exp1.RData')))
load(url(paste0(location, 'TCGA_LUAD_survival.RData')))

判断bulk-cell中的每个细胞是否都存在于表型数据中的细胞
all(colnames(bulk_dataset) == bulk_survival$TCGA_patient_barcode)

4.执行scissor选择重要的带有信号的细胞
infos1 <- Scissor(bulk_dataset, sc_dataset, phenotype, alpha = 0.05,
family = "cox", Save_file = 'Scissor_LUAD_survival.RData')

scissor首先输出五个single-cell和bulk-sample之间相关性的summary。这些值都是正值,并且这些值都不接近于0。
注:在使用过程中,如果使用数据的中间相关值小于0.01,将会给出warning,因为这会导致细胞和表型之间的关联度不可靠
4.1 查看scissor后的数据

4.2 使用Scissorh后筛选出的positive和negative基因分别存在Scissor_pos和Scissor_neg中
将positive和negative分别连同整个sc_dataset绘制在一张map上
Scissor_select <- rep(0, ncol(sc_dataset))
names(Scissor_select) <- colnames(sc_dataset)
Scissor_select[infos1$Scissor_pos] <- 1
Scissor_select[infos1$Scissor_neg] <- 2
sc_dataset <- AddMetaData(sc_dataset, metadata = Scissor_select, col.name = "scissor")
DimPlot(sc_dataset, reduction = 'umap', group.by = 'scissor', cols = c('grey','indianred1','royalblue'), pt.size = 1.2, order = c(2,1))

其中:1 代表positive,2代表negative
4.3 model建立所需要的parameter

5. 调整模型参数
在上述过程中得到了新的参数,因此将参数设置为alpha=0.05——参数alpha平衡了L1范数和基于网络的惩罚影响。较大的alpha倾向于强调L1范数以鼓励稀疏性,使得在Scissor选择的cell数少于使用较小alpha的结果。在实际的应用中,Scissor可以自动将回归输入保存到RData中,方便用户调整不同的alpha。可以设置Load_file='Scissor_LUAD_survival.RData’,并使用默认的alpha=NULL运行Scissor:(这时会根据cutoff的不同将回归得到的值不断返回model,重新构建新的model,直到所选择的cell占比达到一定值的时候停止)
infos2 <- Scissor(bulk_dataset, sc_dataset, phenotype, alpha = NULL, cutoff = 0.03, family = "cox", Load_file = 'Scissor_LUAD_survival.RData')

附 存储下载数据并转化
将数据存在本地,下次直接使用。存的时候直接用write.table(file,"D:/Topic/data/sicssor_data/"),看了一下每个三个矩阵的class
sc_dataset:原来的应该也是matrix吧,我已经转成Seurat了,下次再看吧
bulk_dataset:matrix
bulk_survival:data.frame
都存为table了,下次直接转:
- 将table转为matrix:bulk_dataset<-as.matrix(bulk_dataset)
- 将table转为data.frame:bulk_survival<-as.data.frame.array(bulk_survival)
边栏推荐
- VS 2019 MFC 通过ACE引擎连接并访问Access数据库类库封装
- 初步认知Next.js中ISR/RSC/Edge Runtime/Streaming等新概念
- @DateTimeFormat @JsonFormat 的区别
- Scoring prediction problem
- Chapter 8 - firewall, Chapter 9 - Intrusion Detection
- 2022 G3 boiler water treatment recurrent training question bank and answers
- R语言使用neuralnet包构建神经网络回归模型(前馈神经网络回归模型),计算模型在测试集上的MSE值(均方误差)
- [tutorial] deployment process of yolov5 based on tensorflow Lite
- Xshell installation
- Logistic regression
猜你喜欢
Complete set of typescript Basics

modelarts二

Gd32f4 (5): gd32f450 clock is configured as 200m process analysis
LED lighting experiment with simulation software proteus

2022年G3锅炉水处理复训题库及答案

Right click the general solution of file rotation jam, refresh, white screen, flash back and desktop crash

Voice assistant - overall architecture and design

2022R2移动式压力容器充装试题模拟考试平台操作

謀新局、促發展,桂林綠色數字經濟的頭雁效應
Summary of machine learning + pattern recognition learning (II) -- perceptron and neural network
随机推荐
R语言使用caTools包的sample.split函数将机器学习数据集划分为训练集和测试集
Federated reconnaissance: efficient, distributed, class incremental learning paper reading + code analysis
Summary of software testing tools in 2021 - unit testing tools
Use of gt911 capacitive touch screen
Question bank and answers of special operation certificate examination for safety management personnel of hazardous chemical business units in 2022
R语言使用neuralnet包构建神经网络回归模型(前馈神经网络回归模型),计算模型在测试集上的MSE值(均方误差)
R语言使用RStudio将可视化结果保存为pdf文件(export--Save as PDF)
Fcpx plug-in: simple line outgoing text title introduction animation call outs with photo placeholders for fcpx
AcWing——4268. 性感素
Voice assistant - Qu - single entity recall
AI狂想|来这场大会,一起盘盘 AI 的新工具!
There is no solid line connection between many devices in Proteus circuit simulation design diagram. How are they realized?
Velocity autocorrelation function lammps v.s MATALB
R语言glm函数构建泊松回归模型(possion)、epiDisplay包的poisgof函数对拟合的泊松回归模型进行拟合优度检验、即模型拟合的效果、验证模型是否有过度离散overdispersion
谋新局、促发展,桂林绿色数字经济的头雁效应
Continuous local training for better initialization of Federated models
Personalized federated learning using hypernetworks paper reading notes + code interpretation
Understanding management - four dimensions of executive power
Right click the general solution of file rotation jam, refresh, white screen, flash back and desktop crash
R语言caTools包进行数据划分、scale函数进行数据缩放、class包的knn函数构建K近邻分类器、比较不同K值超参数下模型准确率(accuracy)