当前位置:网站首页>How many convolution methods does deep learning have? (including drawings)
How many convolution methods does deep learning have? (including drawings)
2022-07-03 18:21:00 【ZRX_ GIS】
1 The focus of
How to improve the existing network architecture through the selection of convolution mode
About convolution
2 Why do traditional networks use small convolution instead of large convolution ?(VGG Net)
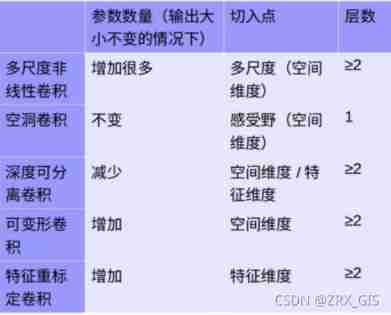
| kernel_size | Adv | exp | dis_Adv |
|---|---|---|---|
| large_kernel_size | The range of perception is large | AlexNet、LeNet And other networks use a relatively large convolution kernel , Such as 5×5,11×11 | There are many parameters ; Large amount of computation |
| small_kernel_size | Less parameters ; A small amount of calculation ; Three nonlinear activation layers are integrated instead of a single nonlinear activation layer , Increase the discrimination ability of the model | VGG after | Insufficient sensory domain ; Deep stack convolution is prone to uncontrollable factors |

3 Can a fixed size convolution kernel see a larger area ?( Cavity convolution )
The standard 3×3 The convolution kernel can only see the corresponding region 3×3 Size , But in order for the convolution kernel to see a larger range ,dilated conv Make it possible .pooling The information loss caused by down sampling operation is irreversible , This is not conducive to pixel level tasks , Replace with void convolution pooling The role of ( Multiply the receptive field ) It is more suitable for semantic segmentation .
4 Must the convolution kernel be a square ?( Asymmetric convolution )
Standard 3×3 The convolution is split into a 1×3 Convolution sum 3×1 Convolution , Without changing the size of receptive field, the amount of calculation can be reduced .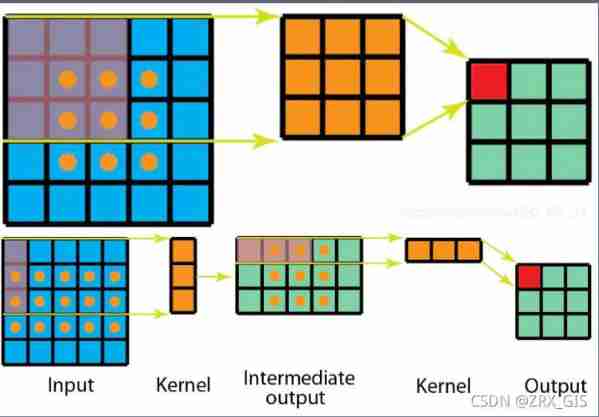
5 Can convolution only be done in the same set ?( Group convolution & Depth separates the convolution )
Group convolution Is to group the input characteristic graph , Convolution was performed for each group . Assume that the size of the input feature map is CHW(12×5×5), The number of output characteristic graphs is N(6) individual , If the setting is to be divided into G(3) individual groups, Then the number of input characteristic diagrams of each group is C / G ( 4 ), The number of output characteristic diagrams of each group is N/G(2), The size of each convolution kernel is (C/G)KK(4×5×5), The total number of convolution kernels is still N(6) individual , The number of convolution kernels in each group is N/G(2), Each convolution kernel only convolutes with the input characteristic graphs of the same group , The total parameter of convolution kernel is N*(C/G)KK, so , The number of total parameters was reduced to the original 1/G.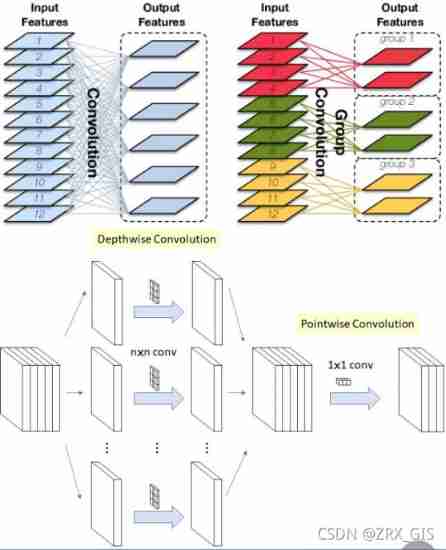
6 Can packet convolution randomly group channels ?(ShffleNet)
To achieve... Between features Mutual communication , In addition to using dense point wise convolution, You can also use channel shuffle. Yes group convolution Then the characteristic diagram is analyzed “ restructuring ”, This ensures that the following convolution inputs come from different groups , Therefore, information can flow between different groups . chart c This process is further demonstrated , amount to “ Disturb evenly ”.
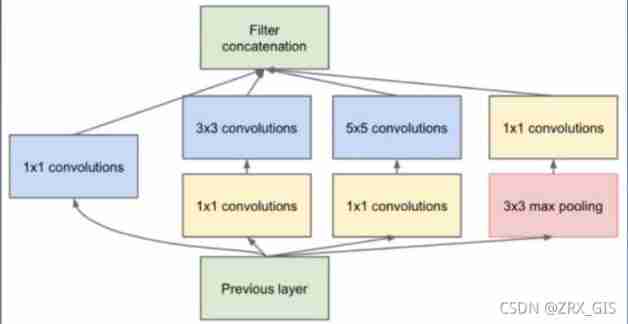
7 Can only one size convolution kernel be used for each layer of convolution ?(Inception)
Traditional cascading networks , It's basically a stack of convolutions , Each layer has only one size convolution kernel , for example V G G A large number of 3×3 Convolution layer . in fact , Same floor feature map Multiple convolution kernels of different sizes can be used separately , In order to obtain features of different scales , Combine these features together , The obtained features are often better than those using a single convolution kernel . In order to reduce the parameters as much as possible , Usually use first 1 * 1 The convolution of maps the characteristic graph to Hidden space , Then do convolution in hidden space .
8 Are the features between channels equal ?(SENet)
Whether in the Inception、DenseNet perhaps ShuffleNet Inside , The features we generate for all channels are directly combined regardless of weight , So why think that the characteristics of all channels have equal effects on the model ? There are often thousands of convolution kernels in a convolution layer , Each convolution kernel corresponds to a feature , So how to distinguish so many features ? This method is to automatically obtain the importance of each feature channel through learning , Then, according to the calculated importance, enhance the useful features and suppress the features that are not useful for the current task .
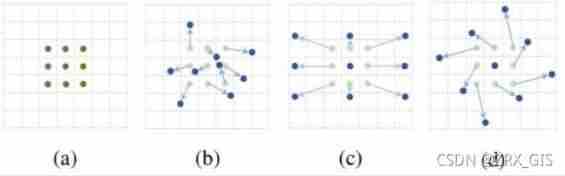
9 Is the convolution kernel necessarily rectangular ?( Deformable convolution )
Regular shaped convolution kernel ( For example, the general square 3*3 Convolution ) Feature extraction may be limited , If the convolution kernel is given the property of deformation , Let the network according to label The error passed back automatically adjusts the shape of the convolution kernel , Adapt to the region of interest that the network focuses on , You can extract better features . for example , The network will be based on the original location (a), Learn one offset Offset , A new convolution kernel is obtained (b)(c)(d), Then some special cases will become special cases of this more generalized model , For example, figure (c) Represents the recognition of objects from different scales , chart (d) Represents the recognition of rotating objects
10 Network rewriting ideas
(1)kernel:
First , The large convolution kernel is replaced by several small convolution kernels
secondly , Single size convolution kernel is replaced by Multi Size convolution kernel
also , The deformable convolution is used to replace the fixed shape convolution kernel
or , Add... To the network 1X1 Convolution
(2)channels:
First , Depth separable convolution is introduced
secondly , Introduce packet convolution
also , introduce channel shuffle
or ,feature map weighting
(3)connection
First , introduce skip
secondly , introduce dense, Make each layer blend with the other layers (DenseNet)
11 summary
边栏推荐
- Research Report on investment trends and development planning of China's thermal insulation material industry, 2022-2028
- 基于人脸识别的课堂考勤系统 tkinter+openpyxl+face_recognition
- Bidding procurement scheme management of Oracle project management system
- How to deploy applications on kubernetes cluster
- Postfix 技巧和故障排除命令
- Change the single node of Postgres database into master-slave
- 2022-2028 global petroleum pipe joint industry research and trend analysis report
- Gear2021 monthly update - December
- 2022-2028 global marking ink industry research and trend analysis report
- PHP MySQL Update
猜你喜欢

The vscode code is automatically modified to a compliance code when it is formatted and saved
![[combinatorics] generating function (summation property)](/img/74/e6ef8ee69ed07d62df9f213c015f2c.jpg)
[combinatorics] generating function (summation property)
English语法_名词 - 分类

Research Report on investment trends and development planning of China's thermal insulation material industry, 2022-2028

Sensor 调试流程

G1 garbage collector of garbage collector
How do microservices aggregate API documents? This wave of operation is too good

Have you learned the correct expression posture of programmers on Valentine's day?

Win32: dump file analysis of heap corruption
Module 9 operation
随机推荐
PHP MySQL preprocessing statement
The second largest gay dating website in the world was exposed, and the status of programmers in 2022
A. Odd Selection【BruteForce】
2022-2028 global marking ink industry research and trend analysis report
How to expand the capacity of golang slice slice
[LINUX]CentOS 7 安装MYSQL时报错“No package mysql-server available“No package zabbix-server-mysql availabl
The number of incremental paths in the grid graph [dfs reverse path + memory dfs]
English grammar_ Noun classification
Win32: analyse du fichier dump pour la défaillance du tas
Administrative division code acquisition
Mature port AI ceaspectus leads the world in the application of AI in terminals, CIMC Feitong advanced products go global, smart terminals, intelligent ports, intelligent terminals
Redis core technology and practice - learning notes (VI) how to achieve data consistency between master and slave Libraries
As soon as we enter "remote", we will never regret, and several people will be happy and several people will be sad| Community essay solicitation
[combinatorics] generating function (summation property)
[linux]centos 7 reports an error when installing MySQL "no package MySQL server available" no package ZABBIX server MySQL available
Supervisor monitors gearman tasks
Keepalived 设置不抢占资源
[combinatorics] generating function (example of generating function | calculating generating function with given general term formula | calculating general term formula with given generating function)
[combinatorics] exponential generating function (concept of exponential generating function | permutation number exponential generating function = combinatorial number ordinary generating function | e
Kotlin的协程:上下文