当前位置:网站首页>ucore lab 2
ucore lab 2
2022-07-06 15:27:00 【Hu Da jinshengyu】
LAB 2
Physical memory management
After experiment 1, we made a system that can be started , Experiment 2 mainly involves the physical memory management of the operating system . The operating system in order to use memory , You also need to efficiently manage memory resources . In Experiment 2, you will understand and complete a simple physical memory management system by yourself .
The experiment purpose
- Understand the translation mechanism based on segment page memory address
- Understand the establishment and use of page table
- Understand how to manage physical memory
Experimental content
This experiment consists of three parts . First, learn how to discover the physical memory in the system ; Then learn how to establish a preliminary management of physical memory , That is, understanding continuous physical memory management ; Finally, understand the operation related to page table , That is, how to establish a page table to realize the mapping between virtual memory and physical memory , Have a comprehensive understanding of segment page memory management mechanism . The memory management implemented in this experiment is still very basic , It doesn't involve the optimization of the actual machine , For example cache Optimization, etc . If you have spare time , Try to complete the extension exercise .
practice
In order to achieve lab2 The goal of ,lab2 Provides 3 Basic exercises and 2 Extended exercises , It is required to complete the experiment report .
Requirements for experimental report :
- be based on markdown Format to complete , Text based
- Fill in the report required in each basic exercise
- After finishing the experiment , Please analyze ucore_lab Reference answers provided in , Please explain the difference between your implementation and the reference answer in the experiment report
- List the knowledge points you think are important in this experiment , And corresponding OS Knowledge points in principle , And briefly explain your meaning of the two , Relationship , Understanding of differences and other aspects ( It may also appear that the knowledge points in the experiment have no corresponding principle knowledge points )
- List what you think OS Principle is very important , But there is no corresponding knowledge point in the experiment
practice 0: Fill in the existing experiment
This experiment relies on experiments 1. Please take your experiment 1 Fill in the code in this experiment. There are “LAB1” The corresponding part of the notes . Tips : May adopt diff and patch Tool for semi-automatic merging (merge), Some graphical comparisons can also be used /merge Tools to manually merge , such as meld,eclipse Medium diff/merge Tools ,understand Medium diff/merge Tools etc. .
Explain : Use meld Tools , You can get the following results :
After comparison , We know debug.c,trap.c,init.c The files are different , It can be used directly here meld To replace . One by one, it can be completed . There is no need to modify the rest , It can be used directly .
practice 1: Realization first-fit Continuous physical memory allocation algorithm ( You need to program )
In the realization of first fit The memory allocation algorithm's recycle function , Consider merging between free blocks with consecutive addresses . Tips : When creating a linked list of free page blocks , You need to sort by the starting address of the free page block , Form an orderly linked list . It may change default_pmm.c Medium default_init,default_init_memmap,default_alloc_pages, default_free_pages And so on . Please check carefully and understand default_pmm.c The comments in .
Please briefly describe your design and implementation process in the experimental report . Please answer the following questions :
- Yours first fit Whether there is room for further improvement
Explain : First check according to the prompt default_pmm.c The comments in :
/* In the First Fit algorithm, the allocator keeps a list of free blocks * (known as the free list). Once receiving a allocation request for memory, * it scans along the list for the first block that is large enough to satisfy * the request. If the chosen block is significantly larger than requested, it * is usually splitted, and the remainder will be added into the list as * another free block. * Please refer to Page 196~198, Section 8.2 of Yan Wei Min's Chinese book * "Data Structure -- C programming language". */
// LAB2 EXERCISE 1: YOUR CODE
// you should rewrite functions: `default_init`, `default_init_memmap`,
// `default_alloc_pages`, `default_free_pages`.
/* * Details of FFMA * (1) Preparation: * In order to implement the First-Fit Memory Allocation (FFMA), we should * manage the free memory blocks using a list. The struct `free_area_t` is used * for the management of free memory blocks. * First, you should get familiar with the struct `list` in list.h. Struct * `list` is a simple doubly linked list implementation. You should know how to * USE `list_init`, `list_add`(`list_add_after`), `list_add_before`, `list_del`, * `list_next`, `list_prev`. * There's a tricky method that is to transform a general `list` struct to a * special struct (such as struct `page`), using the following MACROs: `le2page` * (in memlayout.h), (and in future labs: `le2vma` (in vmm.h), `le2proc` (in * proc.h), etc). * (2) `default_init`: * You can reuse the demo `default_init` function to initialize the `free_list` * and set `nr_free` to 0. `free_list` is used to record the free memory blocks. * `nr_free` is the total number of the free memory blocks. * (3) `default_init_memmap`: * CALL GRAPH: `kern_init` --> `pmm_init` --> `page_init` --> `init_memmap` --> * `pmm_manager` --> `init_memmap`. * This function is used to initialize a free block (with parameter `addr_base`, * `page_number`). In order to initialize a free block, firstly, you should * initialize each page (defined in memlayout.h) in this free block. This * procedure includes: * - Setting the bit `PG_property` of `p->flags`, which means this page is * valid. P.S. In function `pmm_init` (in pmm.c), the bit `PG_reserved` of * `p->flags` is already set. * - If this page is free and is not the first page of a free block, * `p->property` should be set to 0. * - If this page is free and is the first page of a free block, `p->property` * should be set to be the total number of pages in the block. * - `p->ref` should be 0, because now `p` is free and has no reference. * After that, We can use `p->page_link` to link this page into `free_list`. * (e.g.: `list_add_before(&free_list, &(p->page_link));` ) * Finally, we should update the sum of the free memory blocks: `nr_free += n`. * (4) `default_alloc_pages`: * Search for the first free block (block size >= n) in the free list and reszie * the block found, returning the address of this block as the address required by * `malloc`. * (4.1) * So you should search the free list like this: * list_entry_t le = &free_list; * while((le=list_next(le)) != &free_list) { * ... * (4.1.1) * In the while loop, get the struct `page` and check if `p->property` * (recording the num of free pages in this block) >= n. * struct Page *p = le2page(le, page_link); * if(p->property >= n){ ... * (4.1.2) * If we find this `p`, it means we've found a free block with its size * >= n, whose first `n` pages can be malloced. Some flag bits of this page * should be set as the following: `PG_reserved = 1`, `PG_property = 0`. * Then, unlink the pages from `free_list`. * (4.1.2.1) * If `p->property > n`, we should re-calculate number of the rest * pages of this free block. (e.g.: `le2page(le,page_link))->property * = p->property - n;`) * (4.1.3) * Re-caluclate `nr_free` (number of the the rest of all free block). * (4.1.4) * return `p`. * (4.2) * If we can not find a free block with its size >=n, then return NULL. * (5) `default_free_pages`: * re-link the pages into the free list, and may merge small free blocks into * the big ones. * (5.1) * According to the base address of the withdrawed blocks, search the free * list for its correct position (with address from low to high), and insert * the pages. (May use `list_next`, `le2page`, `list_add_before`) * (5.2) * Reset the fields of the pages, such as `p->ref` and `p->flags` (PageProperty) * (5.3) * Try to merge blocks at lower or higher addresses. Notice: This should * change some pages' `p->property` correctly. */
According to the notes , We can know First fit Algorithm is a simple idea , Very fast allocation algorithm :
The physical memory page manager searches the free memory area along the bidirectional linked list , Until you find a large enough free area , Because it searches the linked list as little as possible . If the size of the free area is exactly the same as the size of the application allocation , Allocate this free area , Successfully returns ; Otherwise, divide the idle into two parts , Part of the area is equal to the size of the application allocation , Distribute it , The rest of the area forms a new free area . The design idea of releasing memory is very simple , Just put this area back into the bidirectional linked list .
According to the comments, we see the data structure designed for memory allocation in turn :
/* * * struct Page - Page descriptor structures. Each Page describes one * physical page. In kern/mm/pmm.h, you can find lots of useful functions * that convert Page to other data types, such as phyical address. * */
struct Page {
int ref; // page frame's reference counter
uint32_t flags; // array of flags that describe the status of the page frame
unsigned int property; // the num of free block, used in first fit pm manager
list_entry_t page_link; // free list link
};
Next, analyze the specific meaning of each variable in turn :
ref: Notes can be translated as “ Referenced counters ”, This may be more abstract . specifically ref It means , This page is counted by the reference of the page table , That is, the number of virtual pages mapped to this physical page . If this page is referenced by the page table, that is, a page table entry in a page table sets a virtual page to this Page Manage the mapping relationship of physical pages , It will Page Of ref Add one ; conversely , If the page entry is cancelled , That is, the mapping relationship is released , It will Page Of ref Minus one .
flags: The status mark of this physical management page , There are two flag bit states , by 1 When , This page stands for free state , Can be assigned , But you can't release it ; If 0, Then it means that this page has been allocated , Can't be assigned , But it can be released . In short , Is a flag bit that can be assigned .
propert: Record the number of consecutive free pages , What we need to pay attention to here is the... Used in this member variable Page It must be the starting address of a contiguous memory block ( The address on the first page ).
page_link: A bidirectional linked list pointer that facilitates linking multiple free blocks of continuous memory , Continuous memory free blocks utilize the member variables of this page page_link To link other contiguous memory free blocks smaller and larger than its address , When releasing, just put the space back into the two-way linked list through the pointer .
Looking back, you can see the next data structure :
/* free_area_t - maintains a doubly linked list to record free (unused) pages */
typedef struct {
list_entry_t free_list; // the list header
unsigned int nr_free; // # of free pages in this free list
} free_area_t;
The data structure definition here makes me feel like a free list , But it's different . This is because with the allocation of memory , This leads to small continuous free memory, namely external fragments . however , We should use these small continuous free memory , But the cost of each iteration is not worth it . So here we define free_area_t Data structure of .
Let's take a look at the member variables , The first is a list_entry Structure and an unsigned integer variable that records the number of currently free pages nr_free. The linked list pointer points to the free physical page , That is, the head of the linked list .
ad locum , Through the above two data structures , We know that in order to make the memory allocation more reasonable , We designed the data structure of pages and managing idle pages .
In the header file of the file that needs to write code, we find :
extern const struct pmm_manager default_pmm_manager;
As the name suggests, this defines the data structure for managing the free space actually allocated , Let's take a look pmm_manager The specific definition of :
// pmm_manager is a physical memory management class. A special pmm manager - XXX_pmm_manager
// only needs to implement the methods in pmm_manager class, then XXX_pmm_manager can be used
// by ucore to manage the total physical memory space.
struct pmm_manager {
const char *name; // XXX_pmm_manager's name
void (*init)(void); // initialize internal description&management data structure
// (free block list, number of free block) of XXX_pmm_manager
void (*init_memmap)(struct Page *base, size_t n); // setup description&management data structcure according to
// the initial free physical memory space
struct Page *(*alloc_pages)(size_t n); // allocate >=n pages, depend on the allocation algorithm
void (*free_pages)(struct Page *base, size_t n); // free >=n pages with "base" addr of Page descriptor structures(memlayout.h)
size_t (*nr_free_pages)(void); // return the number of free pages
void (*check)(void); // check the correctness of XXX_pmm_manager
};
Next, the notes of each part in the structure are explained :
const char *name: The name of a physical memory manager ( You can customize the new memory manager according to the specific implementation of the algorithm )
*void (*init)(void): Physical memory manager initialization , Including generating internal descriptions and data structures ( Total number of free block lists and free pages )
void (*init_memmap)(struct Page *base, size_t n): Initialize free pages , Map pages to physical memory according to the initial free physical memory area
struct Page *(*alloc_pages)(size_t n): Apply for the allocation of a specified number of physical pages
void (*free_pages)(struct Page *base, size_t n): Apply to release several specified physical pages
size_t (*nr_free_pages)(void): Query the current total number of free pages
void (*check)(void): Check the correctness of the physical memory manager
Next is the macro definition that will be used in the data structure defined above :
/* Flags describing the status of a page frame */
#define PG_reserved 0 // if this bit=1: the Page is reserved for kernel, cannot be used in alloc/free_pages; otherwise, this bit=0
#define PG_property 1 // if this bit=1: the Page is the head page of a free memory block(contains some continuous_addrress pages), and can be used in alloc_pages; if this bit=0: if the Page is the the head page of a free memory block, then this Page and the memory block is alloced. Or this Page isn't the head page.
#define SetPageReserved(page) set_bit(PG_reserved, &((page)->flags))
#define ClearPageReserved(page) clear_bit(PG_reserved, &((page)->flags))
#define PageReserved(page) test_bit(PG_reserved, &((page)->flags))
#define SetPageProperty(page) set_bit(PG_property, &((page)->flags))
#define ClearPageProperty(page) clear_bit(PG_property, &((page)->flags))
#define PageProperty(page) test_bit(PG_property, &((page)->flags))
meanwhile , We found that the operations in the data structure we defined are bound with names , Here we guess that the name of the data structure we define is default_pmm_manager, Next, find the corresponding definition :
const struct pmm_manager default_pmm_manager = {
.name = "default_pmm_manager",
.init = default_init,
.init_memmap = default_init_memmap,
.alloc_pages = default_alloc_pages,
.free_pages = default_free_pages,
.nr_free_pages = default_nr_free_pages,
.check = default_check,
};
I found that the corresponding function and name are bound together .
At the same time, in the above definition, we found that the type defined in the free block list is not the usual data type , So here we guess that it is still a data structure , Next, find the definition of this type of data structure :
struct list_entry {
struct list_entry *prev, *next;
};
/*list_entry_t It is a set composed of two pointers of double linked list nodes , This free block list is actually a collection of pointers on the first page of each block ( from prev and next constitute ) The pointer to ( Or the address of the pointer set ) Connected to a */
typedef struct list_entry list_entry_t;
Know the data structure we defined , Next, we should realize First fit The correlation function of the algorithm :default_init,default_init_memmap,default_alloc_pages, default_free_pages.
defalut_init:
The implementation is as follows :
free_area_t free_area;
#define free_list (free_area.free_list)
#define nr_free (free_area.nr_free)
static void
default_init(void) {
list_init(&free_list);
nr_free = 0;
}
This part is an initialization part , Is to initialize the bidirectional linked list , At the same time, the total number of free pages nr_free Initialize to 0.
default_init_memmap:
Before we write this function , We should understand how this function is used and what its function is :
First of all, its calling process is :kern_init --> pmm_init–>page_init–>init_memmap.
Next, we can track in turn to know under what conditions the code is executed :
- This function is to enter ucore After the operating system , The first function to execute , Initialize the kernel . In which the , Called the function of initializing physical memory pmm_init.
- This function is mainly used to initialize the entire physical memory , Page initialization is only part of it , The calling position is forward , The part after the function can be ignored , Go straight into page_init function .
- page_init The function mainly completes the initialization process of a whole physical address , Including setting the marker bit , Detect physical memory layout and other operations .
- however , The most critical part , It is also the page initialization related to the experiment , To init_memmap Function processing .
//init_memmap - call pmm->init_memmap to build Page struct for free memory
static void
init_memmap(struct Page *base, size_t n) {
pmm_manager->init_memmap(base, n);
}
Come here , Naturally, we should observe these two input parameters , We can roughly know that these two parameters are for initialization :
The first parameter is of type Page *:
static inline struct Page *
pa2page(uintptr_t pa) {
if (PPN(pa) >= npage) {
panic("pa2page called with invalid pa");
}
return &pages[PPN(pa)];
}
The function here is to return the incoming parameters pa The first physical page at the beginning , That's the base address base.
The second parameter n:
This parameter represents the number of physical pages .
Sum up , This function initializes a whole free physical memory block , Put the corresponding Page Structure initialization , The parameters are base address and number of pages ( Because adjacent numbered pages correspond to Page Structures are adjacent in memory , Therefore, the first free physical page can be corresponding to Page Structure address as base address , Base address + Access all idle physical pages by offset Page structure , According to the instructions , This free block list is just a collection of pointers on the first page of each block ( from prev and next constitute ) The pointer to ( Or the address of the pointer set ) Connected to a , And distinguish different continuous memory physical blocks by base address ).
Code implementation :
static void
default_init_memmap(struct Page *base, size_t n) {
assert(n > 0); // Judge n Is it greater than 0
struct Page *p = base;
for (; p != base + n; p ++) {
// initialization n Block physical pages
assert(PageReserved(p)); // Check whether this page is reserved
p->flags = p->property= 0; // The flag is clear 0
SetPageProperty(p); // Set the flag bit to 1
set_page_ref(p, 0); // Clear the number of virtual pages referencing this page
// Join the free list
list_add_before(&free_list, &(p->page_link));
}
nr_free += n; // Calculate the total number of free pages
base->property = n; // modify base The continuous empty page value of is n
}
Here we will first talk about how each step of the code is executed according to the comments :
First , Here, a page structure is used to store the passed down base page , Then use the loop to judge the following n Are the pages reserved ( Before , To prevent the pilot page from being allocated or destroyed , Reserved pages have been set ), If this page is not a reserved page , Then it can be initialized , This call SetPageProperty Set flag bit , Indicates that the current page is empty . At the same time, the number of consecutive empty pages is set to 0, namely p->property. Finally, set the number of virtual pages mapped to this physical page to 0, call set_page_ref Function to empty the reference . Last , Insert it into the bidirectional list , among free_list refer to free_area_t Medium list structure , And the number of consecutive free pages of the base address plus n, The number of free pages is also increased n.
Sum up , The specific process is : Traverse all free physical pages in the block Page structure , Will all flags Set as 0 It is valid to mark the physical page frame , take property Set members to zero , Use SetPageProperty Macro setting PG_Property Flag bit to mark that each page is valid ( To be specific , If the bit of a page is 1, Then the corresponding page should be the first page of a free block ; if 0, Then the corresponding page is either the first page of an allocated block , Or it's not the first page in the block ; Another flag bit PG_Reserved stay pmm_init Function has been set , This is used to confirm that the corresponding page is not OS Reserved pages occupied by the kernel , Therefore, it can be used for the distribution and recycling of user programs ), Clear the reference count of each physical page ref; Finally, put the home page Page Structural property Set as the total number of pages in the block , Total global pages nr_free Add the total number of pages in the block , And use page_link This double linked list node pointer set connects the block home page to the free block linked list .
default_alloc_pages
The implementation of the code is as follows :
static struct Page *
default_alloc_pages(size_t n) {
assert(n > 0); // Judge n Is it greater than 0
if (n > nr_free) {
// The number of pages to be allocated is greater than the total number of free pages , Go straight back to
return NULL;
}
list_entry_t *le, *len; // The head and length of the free linked list
le = &free_list; // The head of the free linked list
while((le=list_next(le)) != &free_list) {
// Traverse the entire free linked list
struct Page *p = le2page(le, page_link); // Convert to page structure
if(p->property >= n){
// Find the right free page
int i;
for(i=0;i<n;i++){
len = list_next(le);
struct Page *pp = le2page(le, page_link); // Convert page structure
SetPageReserved(pp); // Set the flag bit of each page
ClearPageProperty(pp);
list_del(le); // Change this page from free_list Middle clearance
le = len;
}
if(p->property>n){
// If the page block size is larger than the required size , Split page blocks
(le2page(le,page_link))->property = p->property-n;
}
ClearPageProperty(p);
SetPageReserved(p);
nr_free -= n; // Subtract the allocated page block size
return p;
}
}
return NULL;
}
This function allocates the continuous free physical memory space of the specified number of pages , Return the first page of the allocated space Page Pointer to structure .
First, explain the code process of this function : First , Determine whether the total number of free pages is enough to allocate the required memory , If it is enough, continue to execute downward , Otherwise return to NULL The pointer . After this check , Traverse the entire free linked list . If you find the right free page , namely p->property >= n( Start with this page , The number of consecutive free pages is greater than n), It can be considered distributable , Reset the flag bit . The specific operation is to call ClearPageProperty(pp), Mark the allocated memory pages as not free . Then from the free linked list , namely free_area_t in , Delete this item . If the size of the current free page is larger than the required size . Then split the page block . The specific operation is , Just assigned n A page , If the allocation is complete , And continuous space , Then on the next page of the last allocated page ( Not allocated ), Update its continuous free page value . If it's just right , No operation . Finally, calculate the number of remaining free pages and return the allocated page block address .
technological process : Search the free block linked list in sequence from the starting position , Find the first page that is not less than the requested page n The block ( Just check each Page Of property member , At its value >=n Stop on the first page of ), If the number of pages in this block is exactly equal to the number of pages requested , Can be allocated directly ; If the number of pages is more than the number of pages applied , Divide the block into two halves , Allocate the lower half of the starting address , Take the higher half of the starting address as the new block in the linked list , After allocation, recalculate the number of free pages in the block and the number of global free pages ; If you traverse the entire free linked list, you still can't find a large enough block , Then return to NULL Distribution failure .
default_free_pages
The implementation of the code is as follows :
static void
default_free_pages(struct Page *base, size_t n) {
assert(n > 0);
assert(PageReserved(base)); // Check whether the page block to be released has been allocated
list_entry_t *le = &free_list;
struct Page * p;
while((le=list_next(le)) != &free_list) {
// Find the right place
p = le2page(le, page_link); // Get the... Corresponding to the linked list Page
if(p>base){
break;
}
}
for(p=base;p<base+n;p++){
list_add_before(le, &(p->page_link)); // Insert the linked list corresponding to each free block into the free linked list
}
base->flags = 0; // Modify flag bit
set_page_ref(base, 0);
ClearPageProperty(base);
SetPageProperty(base);
base->property = n; // Set the continuous size to n
// If it's high , Then merge to the high address
p = le2page(le,page_link) ;
if( base+n == p ){
base->property += p->property;
p->property = 0;
}
// If it is low and in range , Then merge to the low address
le = list_prev(&(base->page_link));
p = le2page(le, page_link);
if(le!=&free_list && p==base-1){
// Meet the conditions , If not allocated, merge
while(le!=&free_list){
if(p->property){
// continuity
p->property += base->property;
base->property = 0;
break;
}
le = list_prev(le);
p = le2page(le,page_link);
}
}
nr_free += n;
return ;
}
Release several occupied consecutive physical pages starting from a specified physical page , Put these pages back into the empty block linked list , Reset the flag information , Finally, perform some defragmentation block merging operations .
First, according to the block base address provided by the parameter , Traverse the linked list to find the position to be inserted , Insert these pages . Then count the references ref、flags Mark position bit , Last call merge_blocks Function iteratively performs block merging , To get as large a contiguous memory block as possible . The rule is to start with the newly inserted block , First, traverse the linked list in positive order , Constantly merge the free blocks adjacent to the larger end of the base address in the linked list and the physical address of the new inserted block into the new inserted block ( It also corresponds to the block with a larger physical base address being left in the linked list when allocating memory blocks ); Then traverse the linked list in reverse order , Constantly merge the free blocks adjacent to the base address in the linked list and the smaller end of the physical address of the new inserted block into the new inserted block .
practice 2: Find the page table item corresponding to the virtual address ( You need to program )
By setting the page table and the corresponding page table item , The corresponding relationship between virtual memory address and physical memory address can be established . Among them get_pte Function is an important step in setting page table items . This function finds the kernel virtual address of the secondary page table entry corresponding to a virtual address , If this secondary page entry does not exist , Then a secondary page table containing this item is allocated . This exercise needs to be completed get_pte function in kern/mm/pmm.c, Realize its function . Please check carefully and understand get_pte Comments in functions .get_pte The function call diagram is as follows :
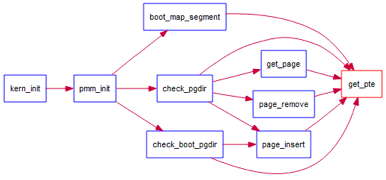 chart 1 get_pte Function call graph
chart 1 get_pte Function call graph
Please briefly describe your design and implementation process in the experimental report . Please answer the following questions :
- Please describe the page directory entry (Page Directory Entry) And page table entries (Page Table Entry) The meaning of each component of the and its impact on ucore The potential use of .
- If ucore Accessing memory during execution , Page access exception occurred , What does the hardware do ?
Make sure in advance :PDT( Page table of contents ),PDE( Page catalog entry ),PTT( A page table ),PTE( Page table item ) The relationship between : Page table saves page table entries , Page table entries are mapped to physical memory addresses ; The page directory table saves page directory entries , Page directory entries are mapped to page tables .
Explain : According to the prompt , Let's first look at get_pte Comments in functions :
//get_pte - get pte and return the kernel virtual address of this pte for la
// - if the PT contians this pte didn't exist, alloc a page for PT
// parameter:
// pgdir: the kernel virtual base address of PDT
// la: the linear address need to map
// create: a logical value to decide if alloc a page for PT
// return vaule: the kernel virtual address of this pte
pte_t *
get_pte(pde_t *pgdir, uintptr_t la, bool create) {
/* LAB2 EXERCISE 2: YOUR CODE * * If you need to visit a physical address, please use KADDR() * please read pmm.h for useful macros * * Maybe you want help comment, BELOW comments can help you finish the code * * Some Useful MACROs and DEFINEs, you can use them in below implementation. * MACROs or Functions: * PDX(la) = the index of page directory entry of VIRTUAL ADDRESS la. * KADDR(pa) : takes a physical address and returns the corresponding kernel virtual address. * set_page_ref(page,1) : means the page be referenced by one time * page2pa(page): get the physical address of memory which this (struct Page *) page manages * struct Page * alloc_page() : allocation a page * memset(void *s, char c, size_t n) : sets the first n bytes of the memory area pointed by s * to the specified value c. * DEFINEs: * PTE_P 0x001 // page table/directory entry flags bit : Present * PTE_W 0x002 // page table/directory entry flags bit : Writeable * PTE_U 0x004 // page table/directory entry flags bit : User can access */
#if 0
pde_t *pdep = NULL; // (1) find page directory entry
if (0) {
// (2) check if entry is not present
// (3) check if creating is needed, then alloc page for page table
// CAUTION: this page is used for page table, not for common data page
// (4) set page reference
uintptr_t pa = 0; // (5) get linear address of page
// (6) clear page content using memset
// (7) set page directory entry's permission
}
return NULL; // (8) return page table entry
#endif
}
The above comments explain some function definitions and macro definitions that may be encountered when writing functions next :
PDX(la): Return the virtual address la Page directory index of
KADDR(pa): Return the physical address pa Related kernel virtual address
set_page_ref(page,1): Set this page to be referenced once
page2pa(page): obtain page The physical address of the page managed
struct Page * alloc_page() : Assign a page
memset(void * s, char c, size_t n) : Set up s Point to the front of the address n Bytes are bytes ‘c’
PTE_P 0x001 Indicates that the physical memory page exists
PTE_W 0x002 Indicates that the contents of the physical memory page are writable
PTE_U 0x004 Indicates that the physical memory page content of the corresponding address can be read
According to the description of the subject , We can know that we need to understand the basic concept of segmental management :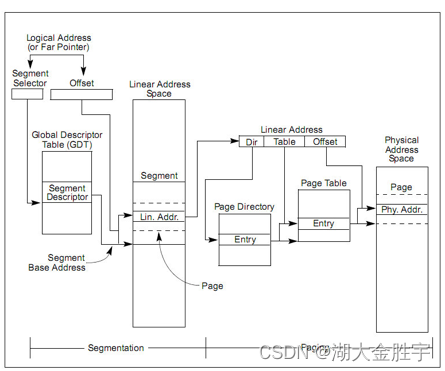
As shown in the figure, in the protection mode ,x86 The architecture divides memory addresses into three types : Logical address ( Also known as virtual address )、 Linear address and physical address . The logical address is the address used in the program instruction , The physical address is the address where the memory is actually accessed . Logical address can get linear address through the address mapping of segment management , Linear address gets the physical address through the address mapping of page management .
But in this experiment, the logical address is directly mapped into a linear address without conversion , So we can make no distinction between these two addresses in the following discussion ( current OS Implementation is also indiscriminate ).
As shown in the figure , Page management divides linear addresses into three parts ( In the picture Linear Address Of Directory part 、 Table Part and Offset part ).ucore The page management of is realized through a two-level page table . The starting physical address of the first level page table is stored in cr3 In the register , This address must be a page aligned address , That's low 12 Bit must be 0. at present ,ucore use boot_cr3(mm/pmm.c) Record this value .
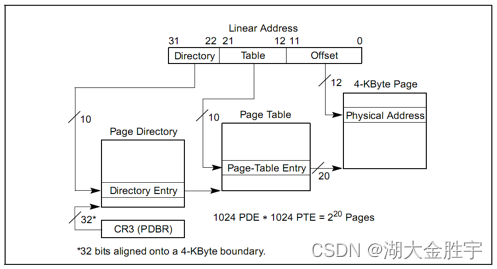
From the figure, we can see that the first level page table is stored in high 10 In a , The secondary page table is stored in the middle 10 In a , final 12 Bit represents offset , It can be proved that , Page size is 4KB(2 Of 12 Power ,4096).
There are three types involved pte_t、pde_t and uintptr_t. By viewing the definition :
typedef unsigned int uint32_t;
typedef uint32_t uintptr_t;
typedef uintptr_t pte_t;
typedef uintptr_t pde_t;
It can be seen that they are all unsigned int type . among ,pde_t Its full name is page directory entry, That is, the entries of the first level page table , front 10 position ;
pte_t Its full name is page table entry, Represents the table entry of the secondary page table , in 10 position .
As can be seen from the above figure, for 32 Bit linear address , We can split it into three parts , Here we look at mmu.h To see the definition of these parts :
// A linear address 'la' has a three-part structure as follows:
//
// +--------10------+-------10-------+---------12----------+
// | Page Directory | Page Table | Offset within Page |
// | Index | Index | |
// +----------------+----------------+---------------------+
// \--- PDX(la) --/ \--- PTX(la) --/ \---- PGOFF(la) ----/
// \----------- PPN(la) -----------/
//
// The PDX, PTX, PGOFF, and PPN macros decompose linear addresses as shown.
// To construct a linear address la from PDX(la), PTX(la), and PGOFF(la),
// use PGADDR(PDX(la), PTX(la), PGOFF(la)).
// page directory index
#define PDX(la) ((((uintptr_t)(la)) >> PDXSHIFT) & 0x3FF)
// page table index
#define PTX(la) ((((uintptr_t)(la)) >> PTXSHIFT) & 0x3FF)
// page number field of address
#define PPN(la) (((uintptr_t)(la)) >> PTXSHIFT)
// offset in page
#define PGOFF(la) (((uintptr_t)(la)) & 0xFFF)
// construct linear address from indexes and offset
#define PGADDR(d, t, o) ((uintptr_t)((d) << PDXSHIFT | (t) << PTXSHIFT | (o)))
// address in page table or page directory entry
#define PTE_ADDR(pte) ((uintptr_t)(pte) & ~0xFFF)
#define PDE_ADDR(pde) PTE_ADDR(pde)
la It's a linear address ,32 position , You need to extract the contents of this field , To get the contents of the page table .
among ,PDXSHIFT The value of is 22, Move right 22 position , And again 10 individual 1 And , You can get it directory;PTXSHIFT The value of is 11, Move right 10 position , And again 11 individual 1 And , Due to address alignment ,0x3FF Of 11 It was all before 0, In this way, we can extract table part . At the same time, there is also the definition of offset , Also know how to construct a linear address .
Sum up , Page table saves page table entries , Page table entries are mapped to physical memory addresses ; The page directory table saves page directory entries , Page directory entries are mapped to page tables .
Next , Let's start answering questions :
First of all PDE and PTE The meaning and use of each part of :
PDE and PTE All are 4B An element of size , Its high 20bit Used to save the index , low 12bit Used to save attributes , But because of different uses , There are small differences inside , As shown in the figure :
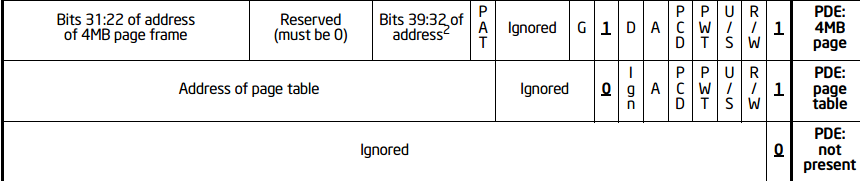
| bit | PDE | PTE |
|---|---|---|
| 0 | Present position ,0 non-existent ,1 There are subordinate page tables | Same as |
| 1 | Read/Write position ,0 read-only ,1 Can write | Same as |
| 2 | User/Supervisor position ,0 Then the table on the next page / Physical page users cannot access ,1 You can visit | Same as |
| 3 | Page level Write Through,1 Then the page level writeback mechanism is enabled ,0 Don't open | Same as |
| 4 | Page level Cache Disable, 1 Disable page level caching ,0 No prohibition | Same as |
| 5 | Accessed position ,1 The representative has been visited in the process of address translation ,0 No, | Same as |
| 6 | Ignore | Dirty bits , Judge whether there is writing |
| 7 | PS, If and only if PS=1 And CR4.PSE=1, Page size is 4M, Otherwise 4K | If the support PAT Pagination , Indirectly determine the memory type of the page accessed , Otherwise 0 |
| 8 | Ignore | Global position . When CR4.PGE Position as 1 when , This bit is 1 Then the global translation |
| 9 | Ignore | Ignore |
| 10 | Ignore | Ignore |
| 11 | Ignore | Ignore |
When page access exception occurs , Work performed by hardware :
First of all, you need to put the wrong linear address la Save in CR2 In the register
- Here is the control register CR0-4 The role of
- CR0 Of 0 Is it PE position , If 1 Then start the protection mode , The rest also have their own role
- CR1 Is undefined control register , Keep it for later use
- CR2 Is a page fault linear address register , Save the full page of the last page failure 32 Bit linear address
- CR3 Is the page directory base register , preservation PDT The physical address of
- CR4 stay Pentium Only in series processors , It handles transactions such as when to enable virtual 8086 Patterns, etc
After that, you need to push into the stack at the time of interruption EFLAGS,CS,EIP,ERROR CODE, If this page access exception happens in user mode , You also need to press in SS,ESP And switch to kernel mode
According to the IDT The corresponding table query also accesses abnormal ISR, Jump over and leave the rest to the software .
Code implementation :
pte_t *
get_pte(pde_t *pgdir, uintptr_t la, bool create) {
pde_t *pdep = &pgdir[PDX(la)]; // Try to get the page table
if (!(*pdep & PTE_P)) {
// If it doesn't work
struct Page *page;
// If there is no need to allocate or the allocation fails
if (!create || (page = alloc_page()) == NULL) {
return NULL;
}
set_page_ref(page, 1); // Number of citations plus one
uintptr_t pa = page2pa(page); // Get the physical address of the page
memset(KADDR(pa), 0, PGSIZE); // Physical address to virtual address , And initialization
*pdep = pa | PTE_U | PTE_W | PTE_P; // Set control bit
}
return &((pte_t *)KADDR(PDE_ADDR(*pdep)))[PTX(la)];
//KADDR(PDE_ADDR(*pdep)): This part gets the physical address of the associated page table from the page directory entry address , And then turn it into a virtual address
//PTX(la): Return the virtual address la Page entry index of
// Finally, the virtual address is returned la The corresponding page entry address
}
First try to use PDX function , Get the location of the first level page table , If successful , You can return something directly .
If it doesn't work , Then it needs to be based on create Flag bit to determine whether to create this secondary page table ( Be careful , In the first level page table , All stored are the starting address of the secondary page table ). If create by 0, Then don't create , Otherwise create .
Since you need to look up this page table , Then the number of references to the page table should be increased by one .
after , Need to use memset The virtual address of the new page table , All set to 0, Because the virtual addresses represented by this page are not mapped .
The next step is to set the control bit . Here should be set at the same time PTE_U、PTE_W and PTE_P, The software representing the user status can read the physical memory page content of the corresponding address 、 The contents of the physical memory page can be written 、 Physical memory page exists .

Only when the entries of the primary and secondary page tables are set with user write permission , Users can read and write the corresponding physical address . So we can write permissions to users in the first level page table , Then restrict the user's permissions as needed on the secondary page table , Protect physical pages . Because a physical page may be mapped to different virtual addresses ( For example, there are different processes sharing in a piece ), When the page needs to be unmapped on an address , The operating system cannot recycle this page directly , But to see if it is mapped to another virtual address . This is to manage the physical page by searching Page Member variables of the data structure ref( The number of mapping relationships between virtual pages and physical pages ) To achieve , If ref by 0 了 , It means that there is no mapping relationship between virtual pages and physical pages , You can recycle this physical page , So this physical page is free Of course. , Can be reassigned .page_insert Function maps the physical page to the page table . For reference. page_insert Function to understand ucore How does the kernel maintain this variable . When you no longer need to access this virtual address , This physical page can be recycled and used in other places in the future . Unmapping is done by page_remove To do it , This is actually page_insert The inverse operation .
ad locum , We see that KADDR function , Let's take a look at the specific statement :
/* * * KADDR - takes a physical address and returns the corresponding kernel virtual * address. It panics if you pass an invalid physical address. * */
#define KADDR(pa) ({
\ uintptr_t __m_pa = (pa); \ size_t __m_ppn = PPN(__m_pa); \ if (__m_ppn >= npage) {
\ panic("KADDR called with invalid pa %08lx", __m_pa); \ } \ (void *) (__m_pa + KERNBASE); \ })
Last use KADDR Return the linear address corresponding to the secondary page table , Because the physical address is not required here , Instead, you need to find the corresponding secondary page table entry , Before querying the secondary page table , All belong to the category of virtual addresses .
practice 3: Release the page where a virtual address is located and unmap the corresponding secondary page table entry ( You need to program )
When a physical memory page containing a virtual address is released , You need to make the management data structure corresponding to this physical memory page Page Do relevant cleaning treatment , Make this physical memory page free ; In addition, it is also necessary to clear the secondary page table entries that represent the corresponding relationship between the virtual address and the physical address . Please check carefully and understand page_remove_pte Comments in functions . So , It needs to be completed in kern/mm/pmm.c Medium page_remove_pte function .page_remove_pte The function call diagram is as follows :
chart 2 page_remove_pte Function call graph
Please briefly describe your design and implementation process in the experimental report . Please answer the following questions :
- data structure Page Global variable of ( It's actually an array ) Whether each item of the page table corresponds to the page directory item and page table item in the page table ? If there is , What is the corresponding relationship ?
- If you want the virtual address to be equal to the physical address , How to modify lab2, Finish this ? Encourage programming to accomplish this problem
Explain : First, we see the comments that need to design the code :
//page_remove_pte - free an Page sturct which is related linear address la
// - and clean(invalidate) pte which is related linear address la
//note: PT is changed, so the TLB need to be invalidate
static inline void
page_remove_pte(pde_t *pgdir, uintptr_t la, pte_t *ptep) {
/* LAB2 EXERCISE 3: YOUR CODE * * Please check if ptep is valid, and tlb must be manually updated if mapping is updated * * Maybe you want help comment, BELOW comments can help you finish the code * * Some Useful MACROs and DEFINEs, you can use them in below implementation. * MACROs or Functions: * struct Page *page pte2page(*ptep): get the according page from the value of a ptep * free_page : free a page * page_ref_dec(page) : decrease page->ref. NOTICE: ff page->ref == 0 , then this page should be free. * tlb_invalidate(pde_t *pgdir, uintptr_t la) : Invalidate a TLB entry, but only if the page tables being * edited are the ones currently in use by the processor. * DEFINEs: * PTE_P 0x001 // page table/directory entry flags bit : Present */
#if 0
if (0) {
//(1) check if this page table entry is present
struct Page *page = NULL; //(2) find corresponding page to pte
//(3) decrease page reference
//(4) and free this page when page reference reachs 0
//(5) clear second page table entry
//(6) flush tlb
}
#endif
}
The above comments mentioned some macro definitions , At the same time, it also explains the idea of solving problems .
Next, we will explain the specific meaning of these macro definitions and functions :
#define PTE_P 0x001 // Present
A page table / Directory entry target niche : Existential bit .
tlb_invalidate(pde_t *pgdir, uintptr_t la):
// invalidate a TLB entry, but only if the page tables being
// edited are the ones currently in use by the processor.
void
tlb_invalidate(pde_t *pgdir, uintptr_t la) {
if (rcr3() == PADDR(pgdir)) {
invlpg((void *)la);
}
}
When the modified page tables are those used by the process , Make it invalid .
page_ref_dec(page):
static inline int
page_ref_dec(struct Page *page) {
page->ref -= 1; // Subtract one from the number of citations
return page->ref;
}
Reduce the number of references to this page , Return the number of references left . Obviously , This function tests the number of times this page is referenced , If only one level up ( Second level page table ) Quoted once , Then minus one is 0, Pages and the corresponding secondary page table can be released directly ( Set the secondary page table 0 Is unmapping ).
If more page tables apply it , Then you can't release this page , But cancel the mapping of the corresponding secondary page table entries , That is, the entry of mapping ( Incoming secondary page table ) Release for 0.
pte2page:
static inline struct Page *
pte2page(pte_t pte) {
// from ptep Value to get the corresponding page
if (!(pte & PTE_P)) {
panic("pte2page called with invalid pte");
}
return pa2page(PTE_ADDR(pte));
}
Code implementation :
static inline void
page_remove_pte(pde_t *pgdir, uintptr_t la, pte_t *ptep) {
if (*ptep & PTE_P) {
// Page table entry exists
struct Page *page = pte2page(*ptep); // Find the page entry
if (page_ref_dec(page) == 0) {
// Only referenced by the current process
free_page(page); // Release page
}
*ptep = 0; // The directory entry of this page is cleared
tlb_invalidate(pgdir, la);
// The modified page tables are those used by the process , Make it invalid
}
}
You can see that it is easy to write code according to comments .
data structure Page Global variable of ( It's actually an array ) Whether each item of the page table corresponds to the page directory item and page table item in the page table ? If there is , What is the corresponding relationship ?
All physical pages have a description of it Page structure , All page tables are through alloc_page() The distribution of , Each page entry is stored in a Page In the physical page of the structure description ; If PTE Point to a physical page , There is also a Page Structure describes the physical page . So there are two corresponding relationships :
(1) Can pass PTE Calculate the address of the page table where it is located Page structure :
Align the virtual address down to the page size , Convert to physical address ( reduce KERNBASE), Then move it to the right PGSHIFT(12) Bit get in pages Index in array PPN,&pages[PPN] That's what we're looking for Page Structure address .
(2) Can pass PTE Calculate the corresponding physical address of the physical page Page structure :
PTE Bitwise AND 0xFFF Get the physical address of the page it points to , Move right again PGSHIFT(12) Bit get in pages Index in array PPN,&pages[PPN] Just PTE The address pointed to corresponds to Page structure .
If you want the virtual address to be equal to the physical address , How to modify lab2, Finish this ? Encourage programming to accomplish this problem
ucore There are two steps to set up the mapping from virtual address to physical address :
- lab 2 in ucore Entrance point
kern_entry()( It's defined in kern/init/entry.s) in , Set up a temporary page table , Virtual address KERNBASE ~ KERNBASE + 4M Map to a physical address 0 ~ 4M , And will eip Modify to the corresponding virtual address .ucore All codes and all data structures of this experimental operation (PageArray ) All within this virtual address range . - After ensuring that the program can run normally , call boot_map_segment(boot_pgdir, KERNBASE, KMEMSIZE, 0, PTE_W); Virtual address KERNBASE ~ KERNBASE + KMEMSIZE.
Because when compiling Links ld Script kern/tools/kernel.ld Set the link address ( Virtual address ), The base address of the code segment is 0xC0100000( Corresponding physical address 0x00100000), The address must be changed to 0x00100000 To ensure that the kernel loads correctly .
/* Load the kernel at this address: "." means the current address */
/* . = 0xC0100000; */
. = 0x00100000;
.text : {
*(.text .stub .text.* .gnu.linkonce.t.*)
}
In the 1 In step ,ucore Set the virtual address 0 ~ 4M To the physical address 0 ~ 4M To ensure that after opening the page table kern_entry Be able to perform normally , Will be eip Change to the corresponding virtual address ( Add KERNBASE) Then the temporary mapping is cancelled . Because we want to make the physical address equal to the virtual address , So leave this mapping unchanged ( Comment out the code that clears the mapping ).
next:
# unmap va 0 ~ 4M, it's temporary mapping
#xorl %eax, %eax
#movl %eax, __boot_pgdir
ucore A lot of code is used KERNBASE+ Physical address equals the mapping of virtual address , To minimize the number of modified code , Still use macros KERNBASE and VPT(lab2 I didn't use , for fear of bug Still modify it ), But subtract them 0x38000000.
// #define KERNBASE 0xC0000000
#define KERNBASE 0x00000000
// #define VPT 0xFAC00000
#define VPT 0xC2C00000
Revised KERNBASE after , The relationship between virtual address and physical address becomes :
physical address + 0 == virtual address
stay boot_map_segment() in , Clear away first boot_pgdir[1] Of present position , And do something else . This is a get_pte A physical page will be allocated as boot_pgdir[1] Page table pointed to .
static void
boot_map_segment(pde_t *pgdir, uintptr_t la, size_t size, uintptr_t pa, uint32_t perm)
{
boot_pgdir[1] &= ~PTE_P;
...
}
The mapping from virtual address to physical address has changed , It's impossible to pass check_pgdir() and check_boot_pgdir() Test of , So comment out these two lines of calls .
The final result is as follows :
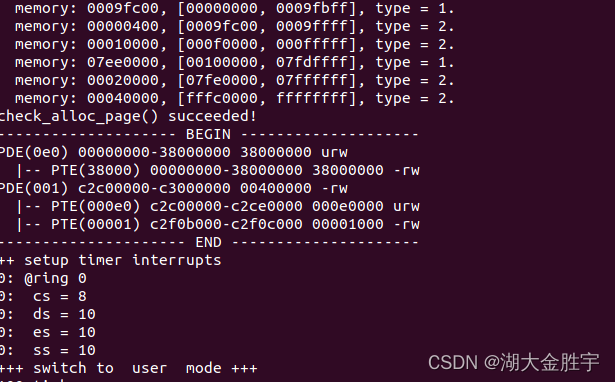
Summary :
After three exercises , Input make qemu You can get the following results :
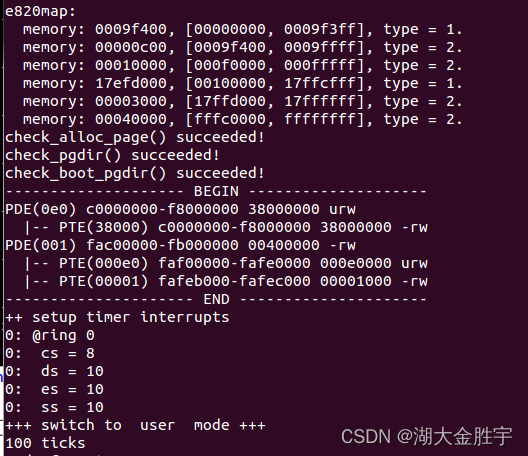
meanwhile , How to know that the output result is correct ? Input make grade, You can know it is correct by seeing the following results :
thus , Experiment 2 has been preliminarily completed .
Extended exercises Challenge:buddy system( Buddy system ) Allocation algorithm ( You need to program )
Buddy System The algorithm divides the available storage space into storage blocks (Block) To manage , The size of each storage block must be 2 Of n The next power (Pow(2, n)), namely 1, 2, 4, 8, 16, 32, 64, 128…
- Reference resources A minimalist implementation of partner allocator , stay ucore To realize buddy system Allocation algorithm , Sufficient test cases are required to illustrate the correctness of the implementation , Design documentation is required .
Explain : First , We need to understand buddy system( Buddy system ) The definition of :
Allocate memory :
1. Looking for the right size memory block ( Greater than or equal to the required size and closest to 2 The power of , Such as the need to 27, Actual distribution 32)
1.1 If you find it , Assigned to the application .
1.2 If not , Separate out the appropriate memory block .
1.2.1 Separate the free memory blocks larger than the required size in half
1.2.2 If it gets to the minimum , Allocate this size .
1.2.3 Back to the steps 1( Looking for blocks of the right size )
1.2.4 Repeat this step until a suitable block
Free memory :
1. Release the memory block
1.1 Look for adjacent blocks , See if it's released .
1.2 If adjacent blocks are also released , Merge these two blocks , Repeat the above steps until you encounter an adjacent block that is not released , Or reach the maximum limit ( That is, all memory is released ).
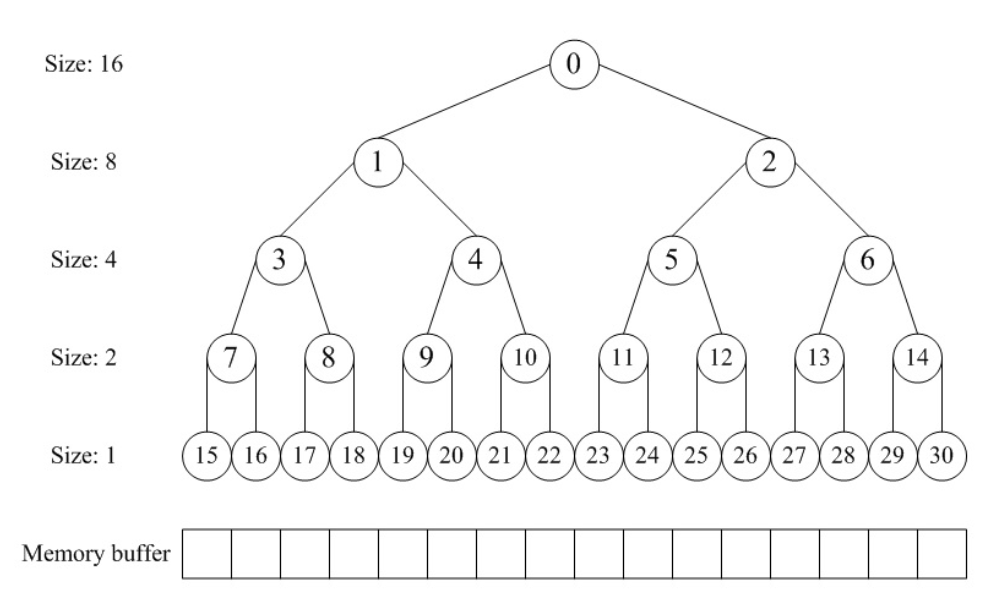
Under this definition , We use the array allocator to simulate the construction of such a complete binary tree structure, rather than really using pointers to build the tree structure —— The up or down pointer index in the tree structure is realized by the subscript offset in the array allocator . In this “ Perfect binary tree ” In structure , The node of the binary tree is used to mark the usage status of the corresponding memory block , High level nodes correspond to large blocks , Low level nodes correspond to small blocks , In the allocation and release, we separate and merge blocks through the tag attributes of these nodes .
In the allocation phase , First of all, search for the block with appropriate size —— The memory size represented by this block is just greater than or equal to the nearest required memory 2 The next power ; By traversing the depth of the tree , Find the most suitable one from the left and right subtrees , Allocate memory .
In the release phase , We will restore the previously allocated memory occupancy , And check whether it can merge with another node under the same parent node , Then recursively merge , Until you can't merge .
Lead to
The size of each storage block in the partner system must be 2 Of n The next power , So one of them must be You can convert the incoming number to the nearest 2 Of n The next power Function of , The relevant code is as follows :
// Pass in a number , Returns the nearest 2 The index of ( Including the number is 2 In this case )
size_t getLessNearOfPower2(size_t x)
{
size_t _i;
for(_i = 0; _i < sizeof(size_t) * 8 - 1; _i++)
if((1 << (_i+1)) > x)
break;
return (size_t)(1 << _i);
}
initialization
At the beginning , The program will transfer a large physical memory space into init_memmap function , However, the size of the physical memory space is not necessarily 2 Of n The next power , So we need to segment it . Set the memory layout after segmentation as follows :
/* buddy system Memory layout in A large physical space Low address High address +-+--+----+--------+-------------------+ | | | | | | +-+--+----+--------+-------------------+ Low address memory blocks are smaller The memory block with high address is larger */
meanwhile , In double linked list free_area.free_list in , Make the memory block with small space in the front of the bidirectional linked list , Memory blocks with large space are at the back of the bidirectional linked list ; Low address in front , High address after . Therefore, the following is the final linked list layout :
/* free_area.free_list Memory block order in : 1. After a large piece of continuous physical memory is cut ,free_area.free_list Memory block order in addr: 0x34 0x38 0x40 +----+ +--------+ +---------------+ <-> | 0x4| <-> | 0x8 | <-> | 0x10 | <-> +----+ +--------+ +---------------+ 2. A few blocks of physical memory ( These pieces may not be continuous ) After being cut ,free_area.free_list Memory block order in addr: 0x34 0x104 0x38 0x108 0x40 0x110 +----+ +----+ +--------+ +--------+ +---------------+ +---------------+ <-> | 0x4| <-> | 0x4| <-> | 0x8 | <-> | 0x8 | <-> | 0x10 | <-> | 0x10 | <-> +----+ +----+ +--------+ +--------+ +---------------+ +---------------+ */
According to the memory planning above , You can get buddy_init_memmap Code for
static void
buddy_init_memmap(struct Page *base, size_t n) {
assert(n > 0);
// Set the current page backward curr_n A page
struct Page *p = base;
for (; p != base + n; p ++) {
assert(PageReserved(p));
p->flags = p->property = 0;
set_page_ref(p, 0);
}
// Set the total free memory pages
nr_free += n;
// Set up base Points to unprocessed memory end Address
base += n;
while(n != 0)
{
size_t curr_n = getLessNearOfPower2(n);
// Move a piece forward
base -= curr_n;
// Set up free pages The number of
base->property = curr_n;
// Set the current page as available
SetPageProperty(base);
// Insert free blocks according to the size of the block , Sort from small to large
// @note You must use search to insert blocks instead of directly list_add_after(&free_list), Because there are large memory blocks that are not adjacent
list_entry_t* le;
for(le = list_next(&free_list); le != &free_list; le = list_next(le))
{
struct Page *p = le2page(le, page_link);
// The sorting method has priority over the size of internal storage blocks , Address comes next .
if((p->property > base->property)
|| (p->property == base->property && p > base))
break;
}
list_add_before(le, &(base->page_link));
n -= curr_n;
}
}
Space allocation
When allocating space , Traversal double linked list , Find a memory block of appropriate size .
- If there is no memory block of appropriate size in the linked list , be Cut in half The first memory block encountered in the traversal process is larger than the required space .
- If the size of the two memory blocks after cutting is still too large , Continue cutting First block Memory block .
- Loop the operation , Until a memory block of appropriate size is cut .
Final buddy_alloc_pages The code is as follows :
static struct Page *
buddy_alloc_pages(size_t n) {
assert(n > 0);
// Take up 2 Power square , If the current number is 2 The power of is constant
size_t lessOfPower2 = getLessNearOfPower2(n);
if (lessOfPower2 < n)
n = 2 * lessOfPower2;
// If the number of free pages to be allocated is less than the amount of memory required
if (n > nr_free) {
return NULL;
}
// Find consecutive pages that meet the requirements
struct Page *page = NULL;
list_entry_t *le = &free_list;
while ((le = list_next(le)) != &free_list) {
struct Page *p = le2page(le, page_link);
if (p->property >= n) {
page = p;
break;
}
}
// If you need to cut memory blocks , Be sure to allocate the front piece after cutting
if (page != NULL) {
// If the memory block is too large , Then continue cutting memory
while(page->property > n)
{
page->property /= 2;
// The right half of the cut memory block is not used for memory allocation
struct Page *p = page + page->property;
p->property = page->property;
SetPageProperty(p);
list_add_after(&(page->page_link), &(p->page_link));
}
nr_free -= n;
ClearPageProperty(page);
assert(page->property == n);
list_del(&(page->page_link));
}
return page;
}
Memory free
When freeing memory
First, set the memory block as Memory block size and memory block address from small to large Insert into the bidirectional linked list in the order of ( Please see the above linked list layout for details ).
Try merging forward , One time is enough . If the forward merge succeeds , Then you must not merge forward again .
Then loop back and merge , Until it cannot be merged .
It should be noted that , When looking for whether two memory blocks can be merged , If the current memory block has been merged , Then its size will change to the original 2 times , At this time, you need to traverse the original size ( Memory block size before merging ) Larger memory blocks .
Determine whether the location of the current memory block is normal , If it's not normal , You need to disconnect the linked list and re insert it into a new location .
If the current memory block is not merged, it must be normal , If merged Not necessarily abnormal .
The final code is as follows :
static void
buddy_free_pages(struct Page *base, size_t n) {
assert(n > 0);
// Take up 2 Power square , If the current number is 2 The power of is constant
size_t lessOfPower2 = getLessNearOfPower2(n);
if (lessOfPower2 < n)
n = 2 * lessOfPower2;
struct Page *p = base;
for (; p != base + n; p ++) {
assert(!PageReserved(p) && !PageProperty(p));
p->flags = 0;
set_page_ref(p, 0);
}
base->property = n;
SetPageProperty(base);
nr_free += n;
list_entry_t *le;
// Insert it into the linked list first
for(le = list_next(&free_list); le != &free_list; le = list_next(le))
{
p = le2page(le, page_link);
if ((base->property <= p->property)
|| (p->property == base->property && p > base))) {
break;
}
}
list_add_before(le, &(base->page_link));
// Merge left first
if(base->property == p->property && p + p->property == base) {
p->property += base->property;
ClearPageProperty(base);
list_del(&(base->page_link));
base = p;
le = &(base->page_link);
}
// Then loop back and merge
// At this time le Point to the next block of the inserted block
while (le != &free_list) {
p = le2page(le, page_link);
// If you can merge ( equal + The address is adjacent to ), Then merge
// If two blocks are the same size , Then they are not necessarily adjacent to memory .
// in other words , On a chain , There may be multiple blocks of equal size that cannot be merged
if (base->property == p->property && base + base->property == p)
{
// Merge right
base->property += p->property;
ClearPageProperty(p);
list_del(&(p->page_link));
le = &(base->page_link);
}
// If the memory blocks traversed must not be merged , The exit
else if(base->property < p->property)
{
// If you can't merge , It needs to be modified base Position in the linked list , Make the same size together
list_entry_t* targetLe = list_next(&base->page_link);
p = le2page(targetLe, page_link);
while(p->property < base->property)
|| (p->property == base->property && p > base))
targetLe = list_next(targetLe);
// If the current memory block location is incorrect , Then reset the position
if(targetLe != list_next(&base->page_link))
{
list_del(&(base->page_link));
list_add_before(targetLe, &(base->page_link));
}
// Finally exit
break;
}
le = list_next(le);
}
}
summary
buddySystem stay The allocated memory size is 2 Of n The next power In this environment , Excellent effect .
because buddySystem Characteristics of , It is better to use binary tree instead of ordinary bidirectional linked list to manage memory blocks , In this way, a series of bug.
Even ordinary two-way linked list can be well implemented buddySystem, But there is still a troublesome problem :
When a physical block is released , Insert it into the bidirectional linked list , If this physical block can be merged with the previous physical block , It can also be merged with the next physical block , Which physical block should be merged at this time ?
result
[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-zXL7EX3y-1654085660290)(C:\Users\zhaolv\AppData\Roaming\Typora\typora-user-images\image-20220430005630823.png)]
ad locum , The output is correct , But I found that I can't put my algorithm in ucore To implement inside . So the imitation of the previous exercise here will buddy system The algorithm is inserted into ucore in , Only in the end can we succeed .
Extended exercises Challenge: Memory units of any size slub Allocation algorithm ( You need to program )
slub Algorithm , Realize efficient memory unit allocation of two-tier architecture , The first layer is memory allocation based on page size , The second layer is to realize memory allocation based on arbitrary size on the basis of the first layer . Can simplify the implementation of , Can reflect its main idea .
- Reference resources linux Of slub Allocation algorithm /, stay ucore To realize slub Allocation algorithm . Sufficient test cases are required to illustrate the correctness of the implementation , Design documentation is required .
Challenges Is optional , It's good to be one . complete Challenge Students can submit separately Challenge. Students who finish well can get extra points for their final exam results .
Explain : First , We need to read the blog we need :
Kernel object buffer management
Linux The kernel is running , It is often necessary to use some kernel data structures ( object ). for example , When a thread of a process first opens a file , The kernel needs to allocate a file called file Data structure of ; When the file is finally closed , The kernel must release the associated file data structure . These small pieces of storage space are not only used inside a kernel function , Otherwise, you can use the kernel stack space of the current thread . meanwhile , These small pieces of storage space are dynamic , It cannot be used like physical memory page management page The structure is like that , There are as many memories as there are page structure , Form a static length queue . And because the kernel cannot predict the buffer requirements of various kernel objects in operation , Therefore, it is not suitable to create a “ Buffer pool ”, Because in that case, it is likely that some buffer pools have been exhausted and there are a large number of free buffers in some buffer pools . therefore , The kernel can only take a more holistic approach .
We can see that , The management of kernel objects is similar to the heap management in user processes , The core issues are : How to efficiently manage memory space , It makes it possible to allocate and recycle objects quickly and reduce memory fragmentation . But the kernel cannot simply adopt the heap based memory allocation algorithm of user processes , This is because the kernel's use of its objects has the following particularity :
- The kernel uses a wide variety of objects , A unified and efficient management method should be adopted .
- Kernel for some objects ( Such as task_struct) The use of is very frequent , Therefore, search based allocation algorithms commonly used in user process heap management, such as First-Fit( The first memory block found in the heap that meets the request ) and Best-Fit( Use the most appropriate memory block in the heap to meet the request ) Not directly applicable , Instead, some kind of buffer mechanism should be used .
- A considerable number of members of kernel objects need some special initialization ( For example, queue head ) Instead of simply completing 0. If the released objects can be fully reused, there is no need to initialize the next allocation , Then it can improve the running efficiency of the kernel .
- The allocator's organization and management of the kernel object buffer must fully consider the impact on the hardware cache .
- With the popularity of multiprocessor systems with shared memory , Multiprocessors often allocate certain types of objects at the same time , Therefore, the allocator should try to avoid the overhead of synchronization between processors , Some kind of Lock-Free The algorithm of .
How to effectively manage buffer space , It has been a hot research topic for a long time .90 In the early s , stay Solaris 2.4 Operating system , It uses a method called “slab”( The original meaning is a large piece of concrete ) Buffer allocation and management method , To a certain extent, it meets the special needs of the kernel .
SLAB Distributor introduction
SLAB The allocator creates a separate buffer for each kernel object used . Each buffer consists of multiple slab form , Every slab It is a group of contiguous physical memory page frames , Divided into a fixed number of objects . Depending on the size of the object , By default, one slab At most it can be 1024 Physical memory page frames .
The kernel using kmem_cache Data structure management buffer . because kmem_cache Itself is also a kernel object , So we need a special buffer . Of all buffers kmem_cache The control structure is organized in cache_chain A two-way circular queue for the queue header , meanwhile cache_cache Global variables point to kmem_cache Object buffer kmem_cache object . Every slab You need a type of struct slab The descriptor data structure of manages its state , At the same time, we need a kmem_bufctl_t( Is defined as an unsigned integer ) Structure array to manage idle objects . If the object does not exceed 1/8 Size of physical memory page frames , So these slab The management structure is stored directly in slab Internal , Located in assigned to slab The starting position of the first physical memory page frame ; Otherwise , Store in slab external , Located by kmalloc Allocated generic object buffer .
slab The objects in are 2 States : Allocated or idle . In order to manage effectively slab, According to the number of allocated objects ,slab There can be 3 States , Dynamically in the queue corresponding to the buffer :
Full queue , At this point the slab There are no free objects in .
Partial queue , At this point the slab There are already assigned objects in , There are also idle objects .
Empty queue , At this point the slab All are idle objects .
stay SLUB In distributor , One slab It is a group of contiguous physical memory page frames , Divided into a fixed number of objects .slab There is no extra queue of idle objects ( This is related to SLAB Different ), Instead, it reuses the space of the free object itself .slab There is no additional description structure , because SLUB The allocator represents the physical page box page Add freelist,inuse and slab Of union Field , Respectively represent the pointer of the first free object , Number of allocated objects and buffers kmem_cache Pointer to structure , therefore slab Of the first physical page box page Structure can describe yourself .
Each processor has a local activity slab, from kmem_cache_cpu Structure description .
Space allocation
slab_alloc function :
static __always_inline void *slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node, void *addr)
{
void **object;
struct kmem_cache_cpu *c;
unsigned long flags;
local_irq_save(flags);
c = get_cpu_slab(s, smp_processor_id()); // (a)
if (unlikely(!c->freelist || !node_match(c, node)))
object = __slab_alloc(s, gfpflags, node, addr, c); // (b)
else {
object = c->freelist; // (c)
c->freelist = object[c->offset];
stat(c, ALLOC_FASTPATH);
}
local_irq_restore(flags);
if (unlikely((gfpflags & __GFP_ZERO) && object))
memset(object, 0, c->objsize);
return object; // (d)
}
- Get the kmem_cache_cpu data structure .
- Suppose the current activity slab There are no free objects , Or the node of this processor is inconsistent with the specified node , Call __slab_alloc function .
- Get the pointer of the first free object , Then update the pointer to point to the next free object .
- Return the object address .
__slab_alloc function :
static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node, void *addr, struct kmem_cache_cpu *c)
{
void **object;
struct page *new;
gfpflags &= ~__GFP_ZERO;
if (!c->page) // (a)
goto new_slab;
slab_lock(c->page);
if (unlikely(!node_match(c, node))) // (b)
goto another_slab;
stat(c, ALLOC_REFILL);
load_freelist:
object = c->page->freelist;
if (unlikely(!object)) // (c)
goto another_slab;
if (unlikely(SlabDebug(c->page)))
goto debug;
c->freelist = object[c->offset]; // (d)
c->page->inuse = s->objects;
c->page->freelist = NULL;
c->node = page_to_nid(c->page);
unlock_out:
slab_unlock(c->page);
stat(c, ALLOC_SLOWPATH);
return object;
another_slab:
deactivate_slab(s, c); // (e)
new_slab:
new = get_partial(s, gfpflags, node); // (f)
if (new) {
c->page = new;
stat(c, ALLOC_FROM_PARTIAL);
goto load_freelist;
}
if (gfpflags & __GFP_WAIT) // (g)
local_irq_enable();
new = new_slab(s, gfpflags, node); // (h)
if (gfpflags & __GFP_WAIT)
local_irq_disable();
if (new) {
c = get_cpu_slab(s, smp_processor_id());
stat(c, ALLOC_SLAB);
if (c->page)
flush_slab(s, c);
slab_lock(new);
SetSlabFrozen(new);
c->page = new;
goto load_freelist;
}
if (!(gfpflags & __GFP_NORETRY) && (s->flags & __PAGE_ALLOC_FALLBACK)) {
if (gfpflags & __GFP_WAIT)
local_irq_enable();
object = kmalloc_large(s->objsize, gfpflags); // (i)
if (gfpflags & __GFP_WAIT)
local_irq_disable();
return object;
}
return NULL;
debug:
if (!alloc_debug_processing(s, c->page, object, addr))
goto another_slab;
c->page->inuse++;
c->page->freelist = object[c->offset];
c->node = -1;
goto unlock_out;
}
- If there is no local activity slab, go to (f) Step get slab .
- If the node of this processor is inconsistent with the specified node , go to (e) step .
- Check processor activity slab There are no free objects , go to (e) step .
- Activity at this time slab There are still free objects , take slab The idle object queue pointer of is copied to kmem_cache_cpu Structural freelist Field , hold slab The idle object queue pointer of is set to null , From now on, only from kmem_cache_cpu Structural freelist Field to get idle object queue information .
- Cancel the current activity slab, Add it to the location NUMA Node Partial In line .
- Priority is assigned to NUMA Get a Partial slab.
- Join in gfpflags The sign is set with __GFP_WAIT, Open interrupt , Therefore, subsequent creation slab Operation can sleep .
- Create a slab, And initialize all objects .
- If there is not enough memory , could not be built slab, call kmalloc_large( Actually call the physical page box allocator ) Assigned to .
Memory free
slab_free function :
static __always_inline void slab_free(struct kmem_cache *s, struct page *page, void *x, void *addr)
{
void **object = (void *)x;
struct kmem_cache_cpu *c;
unsigned long flags;
local_irq_save(flags);
c = get_cpu_slab(s, smp_processor_id());
debug_check_no_locks_freed(object, c->objsize);
if (likely(page == c->page && c->node >= 0)) {
// (a)
object[c->offset] = c->freelist;
c->freelist = object;
stat(c, FREE_FASTPATH);
} else
__slab_free(s, page, x, addr, c->offset); // (b)
local_irq_restore(flags);
}
- If the object belongs to the currently active processor slab, Or where the processor is NUMA Node number is not -1( Values used for debugging ), Put the object back in the idle object queue .
- Otherwise, call __slab_free function .
__slab_free function :
static void __slab_free(struct kmem_cache *s, struct page *page,
void *x, void *addr, unsigned int offset)
{
void *prior;
void **object = (void *)x;
struct kmem_cache_cpu *c;
c = get_cpu_slab(s, raw_smp_processor_id());
stat(c, FREE_SLOWPATH);
slab_lock(page);
if (unlikely(SlabDebug(page)))
goto debug;
checks_ok:
prior = object = page->freelist; // (a)
page->freelist = object;
page->inuse--;
if (unlikely(SlabFrozen(page))) {
stat(c, FREE_FROZEN);
goto out_unlock;
}
if (unlikely(!page->inuse)) // (b)
goto slab_empty;
if (unlikely(!prior)) {
// (c)
add_partial(get_node(s, page_to_nid(page)), page, 1);
stat(c, FREE_ADD_PARTIAL);
}
out_unlock:
slab_unlock(page);
return;
slab_empty:
if (prior) {
// (d)
remove_partial(s, page);
stat(c, FREE_REMOVE_PARTIAL);
}
slab_unlock(page);
stat(c, FREE_SLAB);
discard_slab(s, page);
return;
debug:
if (!free_debug_processing(s, page, x, addr))
goto out_unlock;
goto checks_ok;
}
- Executing this function indicates that the object belongs to slab Not an activity slab. Save pointer to idle object queue , Put the object back in this queue , Finally, reduce the number of allocated objects by one .
- If the number of allocated objects is 0, explain slab be in Empty state , go to (d) step .
- If the pointer of the original idle object queue is null , explain slab The original state is Full, Then the current state should be Partial, Will be slab Added to the node Partial In line .
- If slab The state changes to Empty, And previously located on the node Partial In line , Then it will be removed and the occupied memory space will be released .
summary
Come here ,Challenge2 It's done . meanwhile , Here I want to be in ucore To realize , Just like Challenge1 Same change code in , You can output the corresponding results .
Refer to the answer analysis
practice 1
- Because the code implementation itself is relatively simple , The purpose of this experiment is default_init, default_memmap The implementation of is basically consistent with the idea of the reference answer , Therefore, I will not repeat ;
- About default_alloca_pages Implementation of function , The differences between this experiment and the experiment with reference answers are as follows :
- In the implementation of traversing the free block linked list , The implementation in this experiment first finds the qualified block , Then exit the traversal process , Process idle blocks , The reference answer is processed directly in the traversal process , Then exit the function directly ;
- The answer is being realized , The linked list of free blocks stores the corresponding... Of all free physical pages Page, And the realization of this experiment , Only the first physical page corresponding to all consecutive free blocks is left in the free block list Page, My implementation reduces the length of the linked list , It is conducive to improving time efficiency ;
- Let's talk about default_free_pages Function implementation differences :
- Again , Due to the difference of the contents stored in the free block linked list mentioned above , My implementation only needs to remove the first page of a physical free block from the linked list , The implementation of reference answer needs to delete all pages of the whole free block from the linked list ;
- It is convenient to merge free blocks , The implementation in this experiment extracts the merge operation to form a separate function , Make the code thinking clearer ;
practice 2
- Because of practice 2 The code idea in is relatively simple , The difference between the implementation in this experiment and the reference answer is only reflected in some specific code descriptions , For example, when getting an item in the page directory table , Refer to the answer using
pgdir[PDX(la)]To get , And the implementation in this experiment usespgdir + PDX(la)To get ; There is no specific distinction between the two descriptions ;
practice 3
- Because of practice 3 The code implementation of is relatively simple , The implementation in this experiment is basically no different from the reference answer , So I won't repeat it ;
The knowledge points involved in the experiment are listed
The knowledge points involved in this experiment are listed as follows :
- 80386 CPU Segment page memory management mechanism , And how to enter the page mechanism ;
- Methods of detecting physical memory ;
- Specific continuous physical memory allocation algorithm , Include first-fit,best-fit Wait for a series of strategies ;
- ucore Implementation method of linked list in ;
- stay C Language using object-oriented thinking to achieve physical memory manager ;
- Link address 、 Virtual address 、 Linear address 、 Physical address and ELF The meaning of each segment in the binary executable ;
Corresponding to OS The knowledge points in are as follows :
- Memory page management mechanism ;
- Continuous physical memory management ;
The corresponding relationship between the two is :
- The former provides the latter with the underlying support to specifically complete the memory management function corresponding to the operating system on a platform ;
- At the same time, some other knowledge points designed in the experiment , For example, object-oriented thinking 、 The use of linked lists , It facilitates the implementation and coding of specific operating systems ;
List the knowledge points not involved in the experiment
The knowledge points not involved in the experiment include :
- Virtual memory management , Including swapping out temporarily unused physical pages to external memory when physical memory is insufficient , So as to realize the virtual memory space larger than the physical memory space ;
- PageFault To deal with ;
- OS Process in 、 Thread creation 、 management 、 Scheduling process , And the synchronization and mutual exclusion between processes ;
- OS File system used to access external storage in ;
- OS Yes IO Equipment management ;
lab The original state is Full, Then the current state should be Partial, Will be slab Added to the node Partial In line .
- If slab The state changes to Empty, And previously located on the node Partial In line , Then it will be removed and the occupied memory space will be released .
边栏推荐
- ucorelab3
- JS --- detailed explanation of JS facing objects (VI)
- Preface to the foundations of Hilbert geometry
- Daily code 300 lines learning notes day 9
- UCORE LaB6 scheduler experiment report
- Leetcode simple question: check whether the numbers in the sentence are increasing
- The minimum sum of the last four digits of the split digit of leetcode simple problem
- MySQL数据库(一)
- Jupyter installation and use tutorial
- Mysql的事务
猜你喜欢
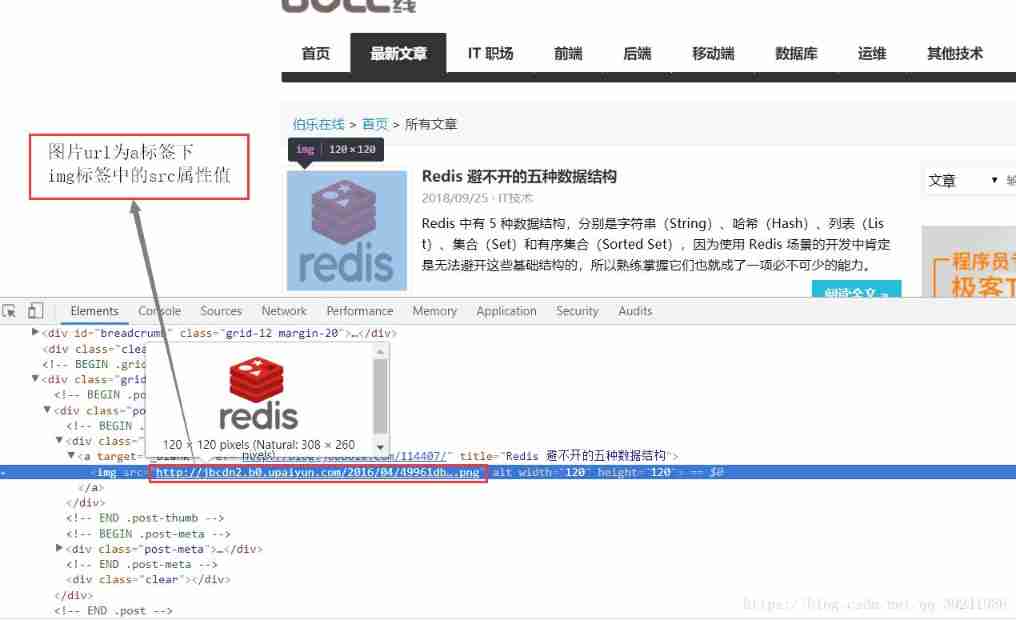
Crawler series (9): item+pipeline data storage

软件测试有哪些常用的SQL语句?

The minimum sum of the last four digits of the split digit of leetcode simple problem
学习记录:TIM—基本定时器
JS --- all knowledge of JS objects and built-in objects (III)

C4D quick start tutorial - creating models
Lab 8 file system
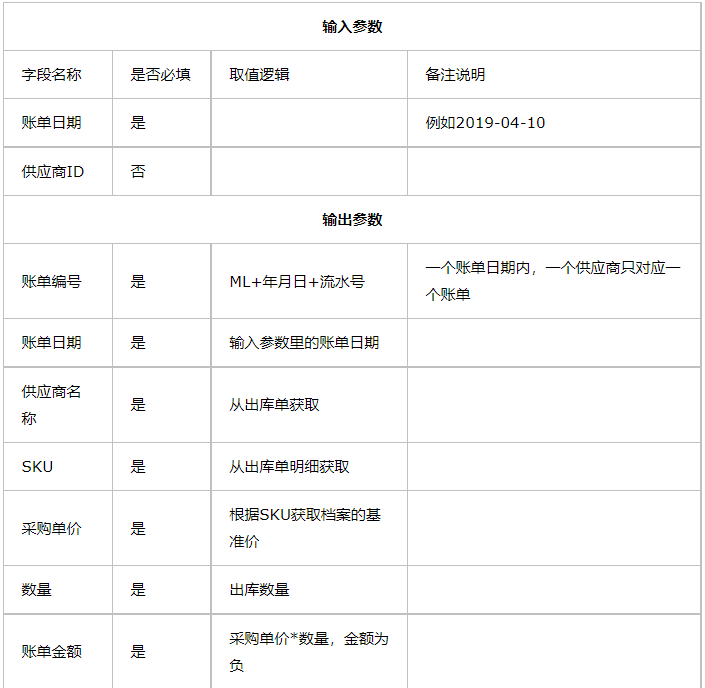
The most detailed postman interface test tutorial in the whole network. An article meets your needs

Dlib detects blink times based on video stream
What is "test paper test" in software testing requirements analysis

随机推荐
ucore lab 6
ucore lab5用户进程管理 实验报告
Dlib detects blink times based on video stream
The minimum sum of the last four digits of the split digit of leetcode simple problem
Brief description of compiler optimization level
Capitalize the title of leetcode simple question
Leetcode simple question: check whether the numbers in the sentence are increasing
51 lines of code, self-made TX to MySQL software!
Pedestrian re identification (Reid) - Overview
[C language] twenty two steps to understand the function stack frame (pressing the stack, passing parameters, returning, bouncing the stack)
LeetCode#237. Delete nodes in the linked list
Mysql database (II) DML data operation statements and basic DQL statements
Currently, mysql5.6 is used. Which version would you like to upgrade to?
Sleep quality today 81 points
Brief introduction to libevent
Mysql database (IV) transactions and functions
Preface to the foundations of Hilbert geometry
The minimum number of operations to convert strings in leetcode simple problem
Investment should be calm
csapp shell lab