当前位置:网站首页>LeetCode_7_5
LeetCode_7_5
2022-07-07 17:36:00 【Yuucho】
1. 两数之和
[两数之和](1. 两数之和 - 力扣(LeetCode))
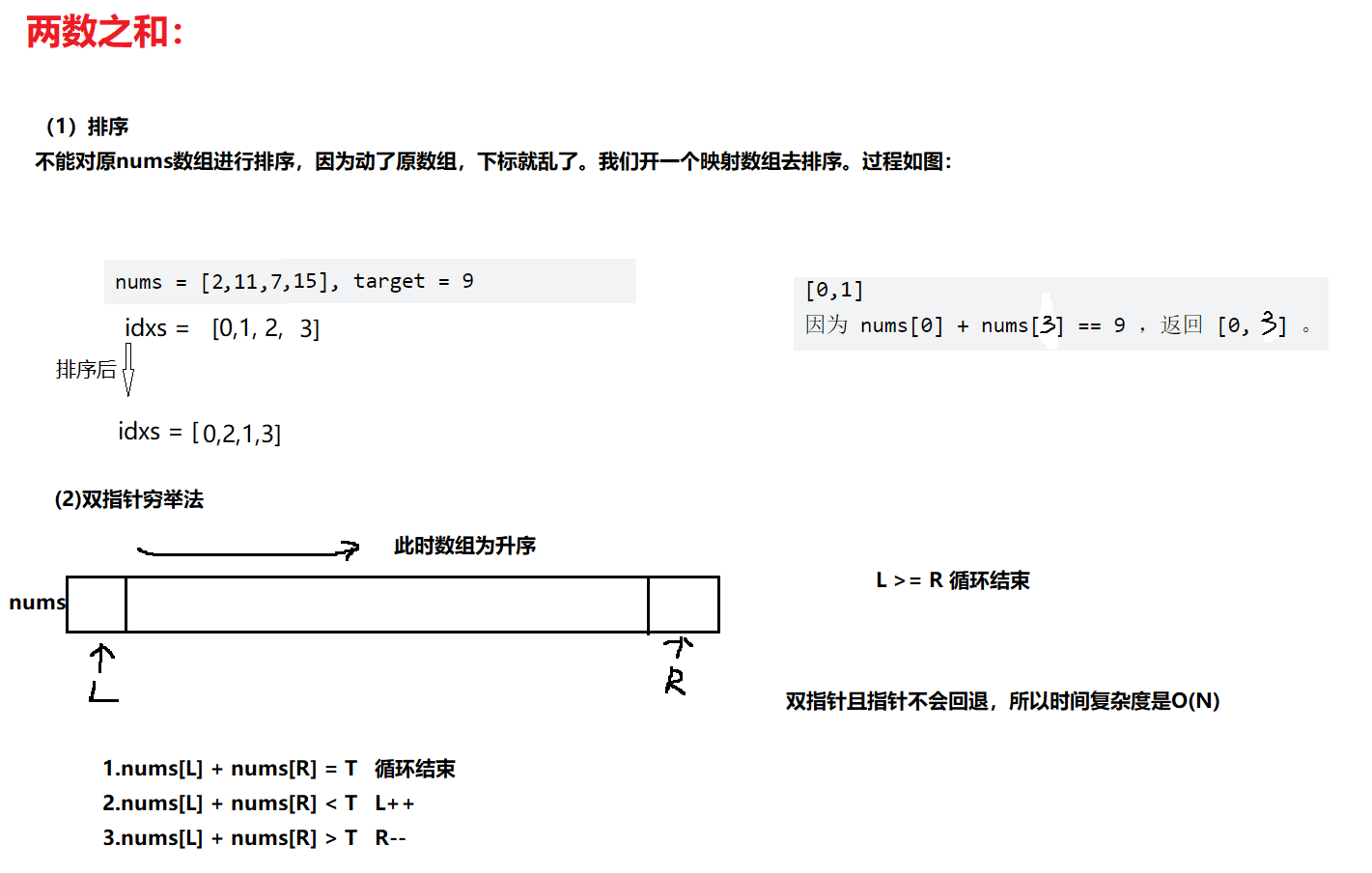
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
int n = nums.size();
//开一个映射数组
vector<int> idxs;
for(int i = 0; i < n; ++i) idxs.push_back(i);
//不能直接排序a,对a数组的下标映射数组排序
sort(idxs.begin(), idxs.end(), [nums, idxs](int i, int j){
return nums[idxs[i]] < nums[idxs[j]];
});
int l = 0, r = n - 1;
vector<int> ret;
while(l < r){
int sum = nums[idxs[l]] + nums[idxs[r]];
if(sum == target){
ret.push_back(idxs[l]);
ret.push_back(idxs[r]);
break;
}else if(sum < target){
l++;
}else{
r--;
}
}
return ret;
}
};
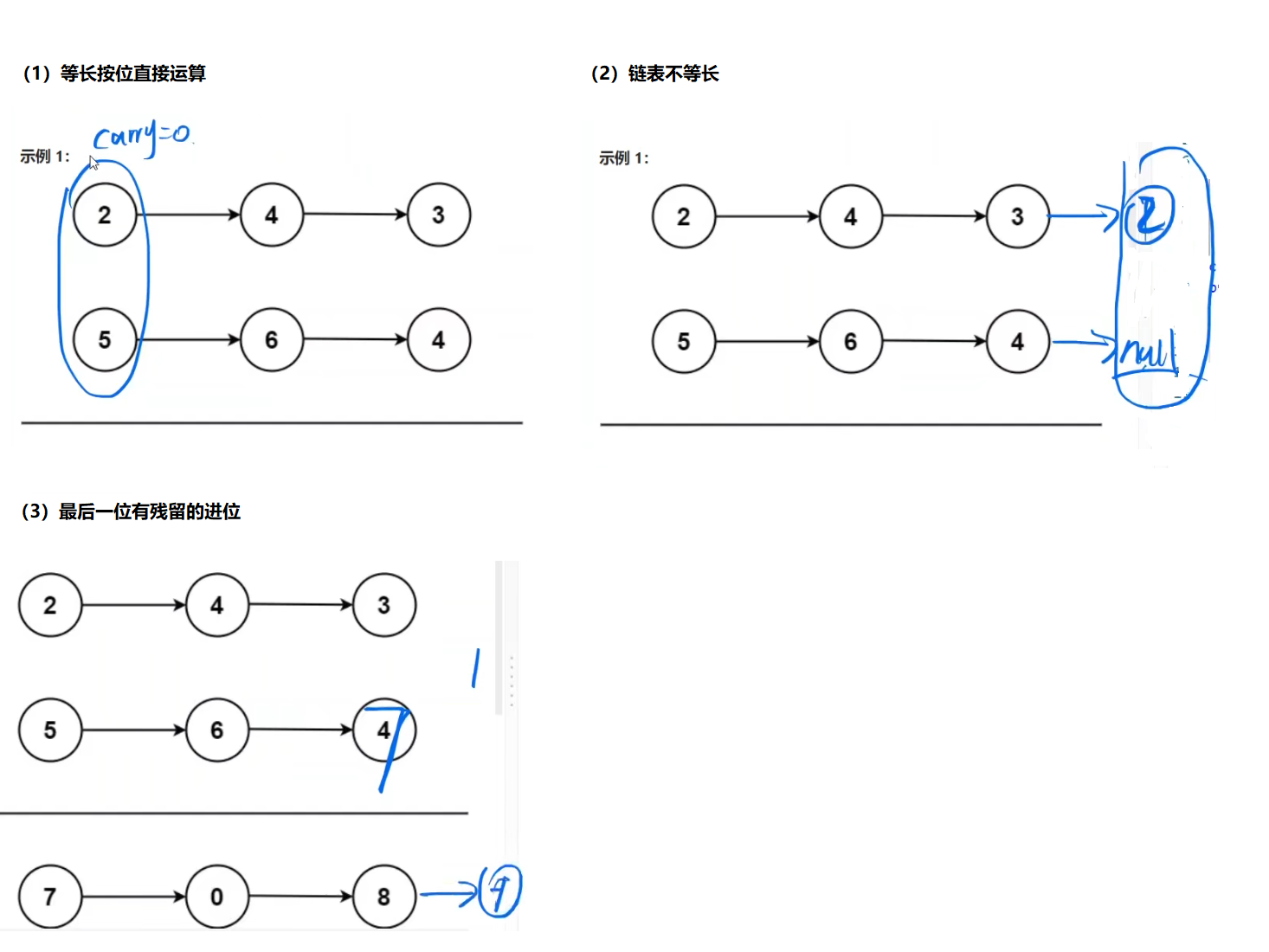
2. 两数相加
[两数相加](2. 两数相加 - 力扣(LeetCode))
高精度加法,和我们做过的字符串相加有点像。
(1)我们按位去加就可以了,考虑进位,每一位运算后还要重置进位。
(2)链表不等长
(2)如果两个链表等长且最后一位需要进位还要在末尾加上1。
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
//开一个头结点存每一位的计算结果
ListNode* H = new ListNode();
//ptr遍历,H->next返回
ListNode* ptr = H;
int carry = 0;
while(l1 || l2 || carry){
int val = 0;
if(l1) val += l1->val, l1 = l1->next;
if(l2) val += l2->val, l2 = l2->next;
val += carry;
ListNode* node = new ListNode(val % 10);
ptr->next = node;
ptr = node;
//重置carry
carry = val / 10;
}
return H->next;
}
};
3.无重复字符的最长子串
假设我们随机截取原串的一部分,然后这一部分恰好是没有重复字符的子串,我们就可以尝试向两边扩展。只有没有遇到与这一部分相同的字符就可以一路扩展下去。
同样的,我们也可以固定一头,用另一头去扩展。
因为题目给的字符串只由英文字母、数字、符合和空格组成,是一个比较有限的字符串,所以我们可以开一个哈希表,去统计当前区间每一个字符出现的次数。
当每一个字符只出现一次,我们就可以扩展。当有一个字符出现两次,我们没必要删除扩展端的字符,而是让固定端越过这个字符前一次出现的位置。就形成了一段合法的新区间。
滑动窗口,两个指针扫到头之后,这个问题就解决了,所以时间复杂度是O(n)。
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int n = s.length();
int ret = 0;
//固定左区间
int l = 0;
//开一个哈希表
unordered_map<char, int> count;
for(int r = 0; r < n; ++r){
count[s[r]]++;
//如果一个字符出现那么左区间越过这个字符即l++
//同时这个字符的出现次数--
while(count[s[r]] >= 2){
count[s[l++]]--;
}
ret = max(ret,r-l+1);
}
return ret;
}
};
4. 寻找两个正序数组的中位数
4. 寻找两个正序数组的中位数 - 力扣(LeetCode)
emmm,这道题要求时间复杂度应为O(log (m+n)),是比较有难度的。
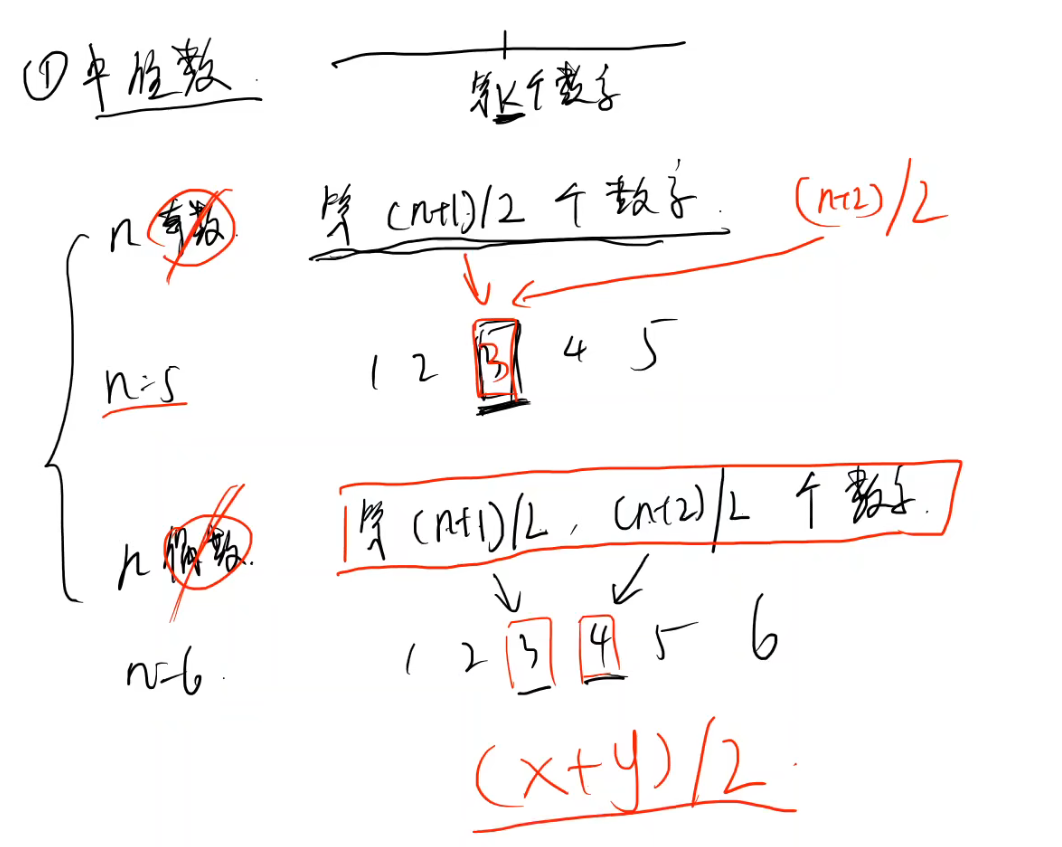
(1)首先,我们要仅仅抓住中位数这一点。我们先来计算一下这个中位数到底是什么,这个中位数其实是两个数组合并后的中间的某个数字,我们假设为第k个。
此时k又要根据数组大小n的奇偶数来讨论,这两种情况又可以用一种简单数学技巧并成一条公式。
因为奇数时(n+1)/2、(n+2)/2指向同一个位置。
(2)对k进行二分
我们分别取两个数组的前h(k的一半)个,装到一个大小为k的容器里。此时这两个取出来的数组的长度之和一定小于等于k,如果数组是奇数就少一个,如果数组是偶数就等于k。
如果a[h-1]<=b[h-1],那么红色小段绝对不可能是第k个元素(两个数组是有序的)。
此时我们就可以淘汰红色区间的前半段,下一轮我们就该在黄色区间中找第k-h个数。
如果b[h-1]<=a[h-1],我们就淘汰蓝色小段。
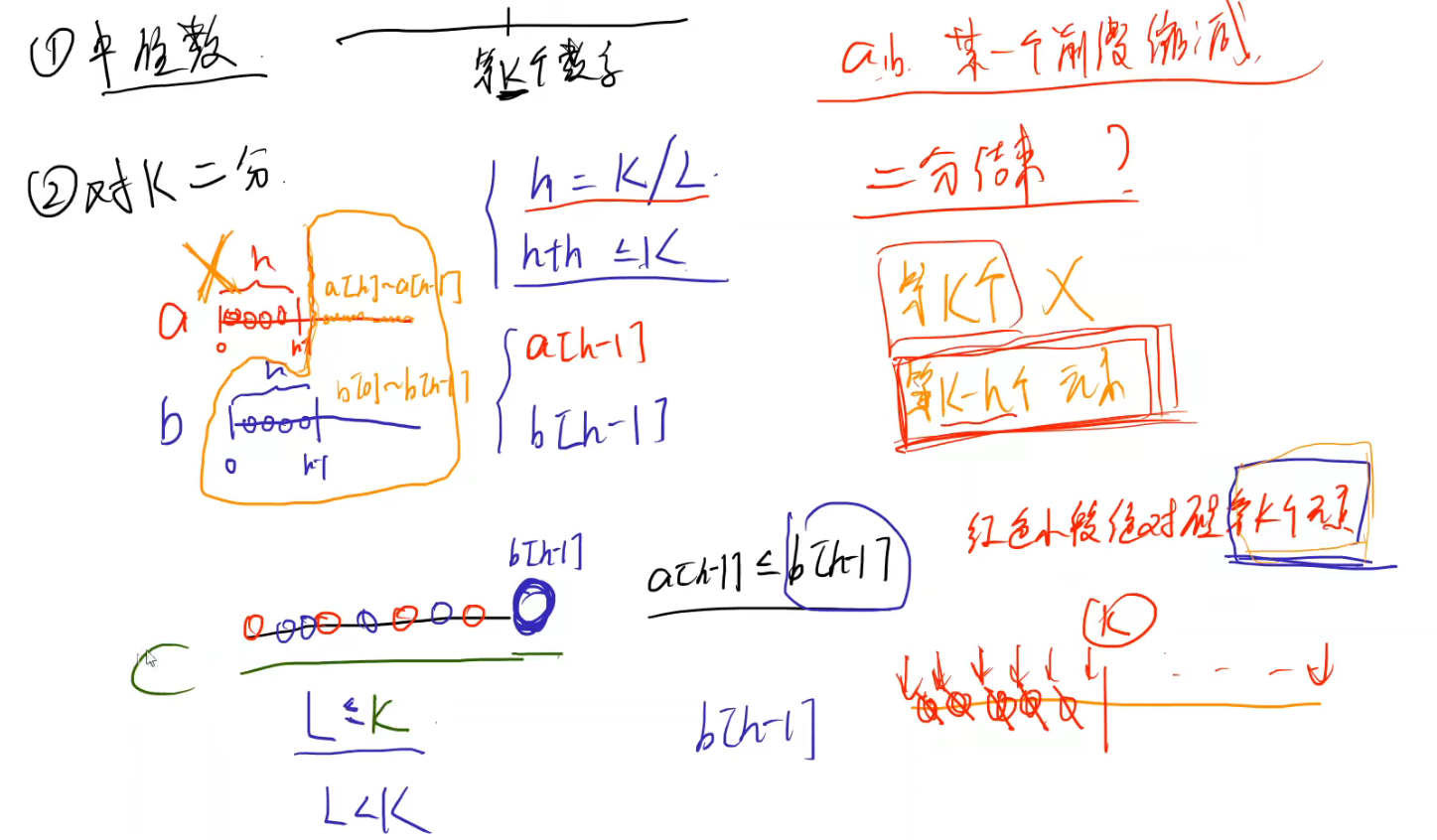
(3)结束条件
- 因为我们每一次二分k的时候,都把a、b两个数组的某一个前缀给缩减了。所以这两个数组的长度是没法保证的,因为有可能在某一次二分中,有一个数组被全部缩减完了。此时我们直接读取剩余数组的k-1个元素就可以了。
- 如果两个数组都没有被缩减完,k被缩减为1。那么就是两个数组的最小值中较小的那一个。
class Solution {
public:
//从a[sta,n-1]以及b[stb,m-1]里面查找第kth个元素
int findKth(const vector<int>& a, int sta, const vector<int>& b, int stb, int kth) {
//a缩减完
if (sta >= a.size()) return b[stb + kth - 1];
//b缩减完
if (stb >= b.size()) return a[sta + kth - 1];
//k缩减为1
if (kth == 1) return min(a[sta], b[stb]);
//开始二分
int half = kth / 2;
int vala = sta + half > a.size() ? a.back() : a[sta + half - 1];
int counta = sta + half > a.size() ? a.size() - sta : half;
int valb = stb + half > b.size() ? b.back() : b[stb + half - 1];
int countb = stb + half > b.size() ? b.size() - stb : half;
if (vala <= valb)
return findKth(a, sta + counta, b, stb, kth - counta);
return findKth(a, sta, b, stb + countb, kth - countb);
}
double findMedianSortedArrays(vector<int>& a, vector<int>& b) {
int n = a.size();
int m = b.size();
int idx0 = (n + m + 1) / 2;
int idx1 = (n + m + 2) / 2;
int val0 = findKth(a, 0, b, 0, idx0);
int val1 = findKth(a, 0, b, 0, idx1);
return 1. * (val0 + val1) / 2;
}
};
int idx1 = (n + m + 2) / 2;
int val0 = findKth(a, 0, b, 0, idx0);
int val1 = findKth(a, 0, b, 0, idx1);
return 1. * (val0 + val1) / 2;
}
};
边栏推荐
- The research group of the Hunan Organizing Committee of the 24th China Association for science and technology visited Kirin Xin'an
- 小试牛刀之NunJucks模板引擎
- Kirin Xin'an won the bid for the new generation dispatching project of State Grid!
- 杰理之关于 TWS 配对方式配置【篇】
- Le PGR est - il utile au travail? Comment choisir une plate - forme fiable pour économiser le cœur et la main - d'œuvre lors de la préparation de l'examen!!!
- State mode - Unity (finite state machine)
- 杰理之快速配对,不支持取消配对【篇】
- LeetCode 648(C#)
- Key points of anti reptile: identifying reptiles
- PV static creation and dynamic creation
猜你喜欢

Netease Yunxin participated in the preparation of the standard "real time audio and video service (RTC) basic capability requirements and evaluation methods" issued by the Chinese Academy of Communica
Numpy——axis

论文解读(ValidUtil)《Rethinking the Setting of Semi-supervised Learning on Graphs》
![[Verilog advanced challenge of Niuke network question brushing series] ~ multi bit MUX synchronizer](/img/7d/ed9a5c536b4cc1913fb69640afb98d.png)
[Verilog advanced challenge of Niuke network question brushing series] ~ multi bit MUX synchronizer

# 欢迎使用Markdown编辑器

索引总结(突击版本)
Navicat连接2002 - Can‘t connect to local MySQL server through socket ‘/var/lib/mysql/mysql.sock‘解决
Research and practice of super-resolution technology in the field of real-time audio and video
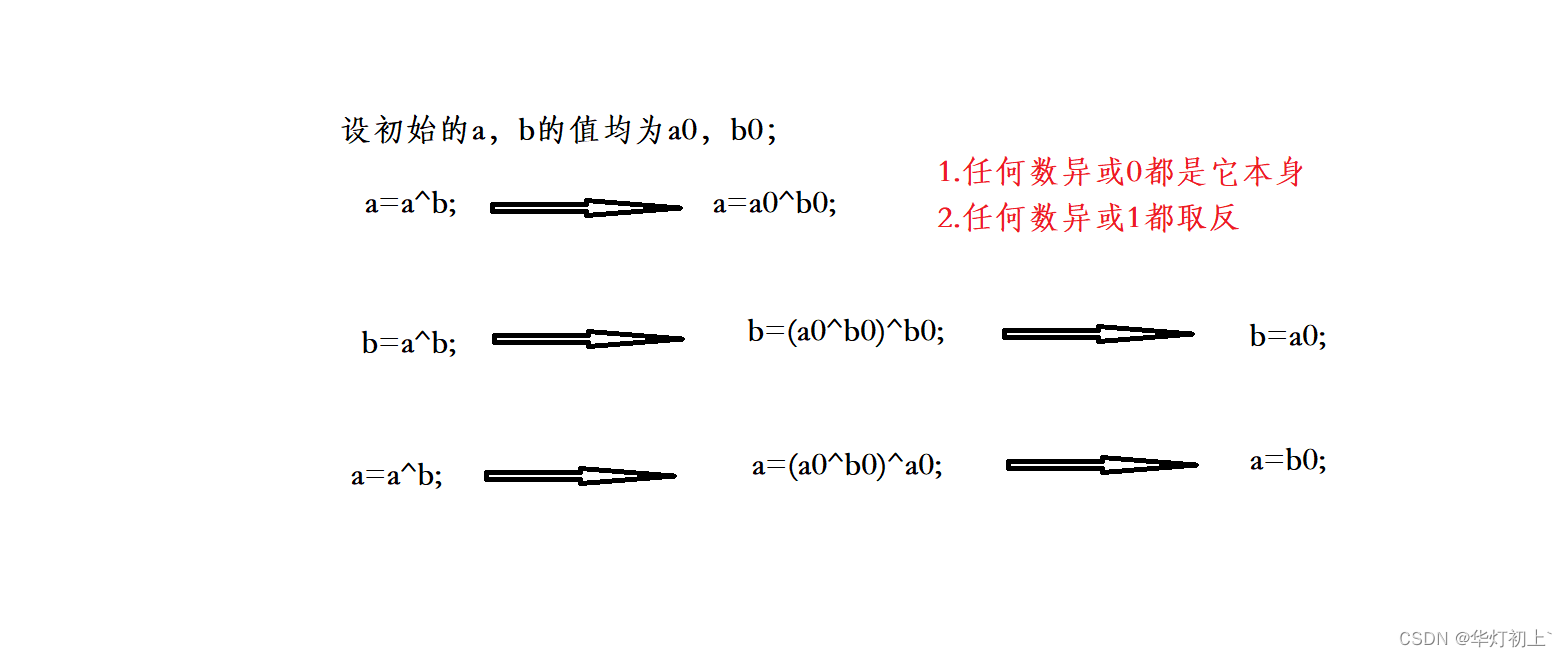
位运算介绍

杰理之手动配对方式【篇】
随机推荐
2022.07.04
2022.07.02
关于ssh登录时卡顿30s左右的问题调试处理
IP 工具类
华南X99平台打鸡血教程
CMD command enters MySQL times service name or command error (fool teaching)
Le PGR est - il utile au travail? Comment choisir une plate - forme fiable pour économiser le cœur et la main - d'œuvre lors de la préparation de l'examen!!!
Key points of anti reptile: identifying reptiles
The strength index of specialized and new software development enterprises was released, and Kirin Xin'an was honored on the list
How to buy bank financial products? Do you need a bank card?
Jerry's headphones with the same channel are not allowed to pair [article]
ASP.NET体育馆综合会员管理系统源码,免费分享
指定opencv非标准安装的版本
2022年投资哪个理财产品收益高?
浏览积分设置的目的
Solve the error reporting problem of rosdep
LeetCode 515(C#)
网信办公布《数据出境安全评估办法》,9 月 1 日起施行
让这个 CRMEB 单商户微信商城系统火起来,太好用了!
LC: string conversion integer (ATOI) + appearance sequence + longest common prefix