当前位置:网站首页>對比學習之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
對比學習之 Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
2022-07-07 11:15:00 【InfoQ】

- 諸神黃昏時代的對比學習
- “軍備競賽”時期的對比學習好。
- 將整個imagenet做成字典,從中抽取一個mini batch作為正樣本。再從中隨機抽取4096條作為負樣本。
- 從數據集中抽取一個mini batch對其增廣,使用一個孿生網絡,將原圖放進一個網絡,將增强之後的圖放進另一個網絡,二者同時進行訓練,對二者使用一個NCE loss或者infoNCE loss。一張圖片和它的增廣作為正樣本,剩餘的圖片及其增廣作為負樣本。
- 從數據集中抽取一個mini batch對其進行兩次增廣,使用一個孿生網絡,將一組圖片增强放進一個網絡,將另一組圖片增强放進另一個網絡,二者同時進行訓練,對二者使用一個NCE loss或者infoNCE loss。
- 它可能會重複的抽取到同一數據。雖然你數據集有很多圖片,但是你從中抽可能會抽到相同的圖片。極端的情况下,如果你抽到一組圖片作為正樣本,然後你又抽到同樣重複的一組圖片作為負樣本。那這樣就會對訓練造成影響。
- 也可能不具有整個數據集的代錶性。比如這個數據其實有很多很多種動物,但是你抽到的都是狗,這樣數據就是沒有代錶性的。
- 當然這樣的選取的越全面效果越好,但是如果你選取的過多的負樣本又會造成計算資源的浪費。
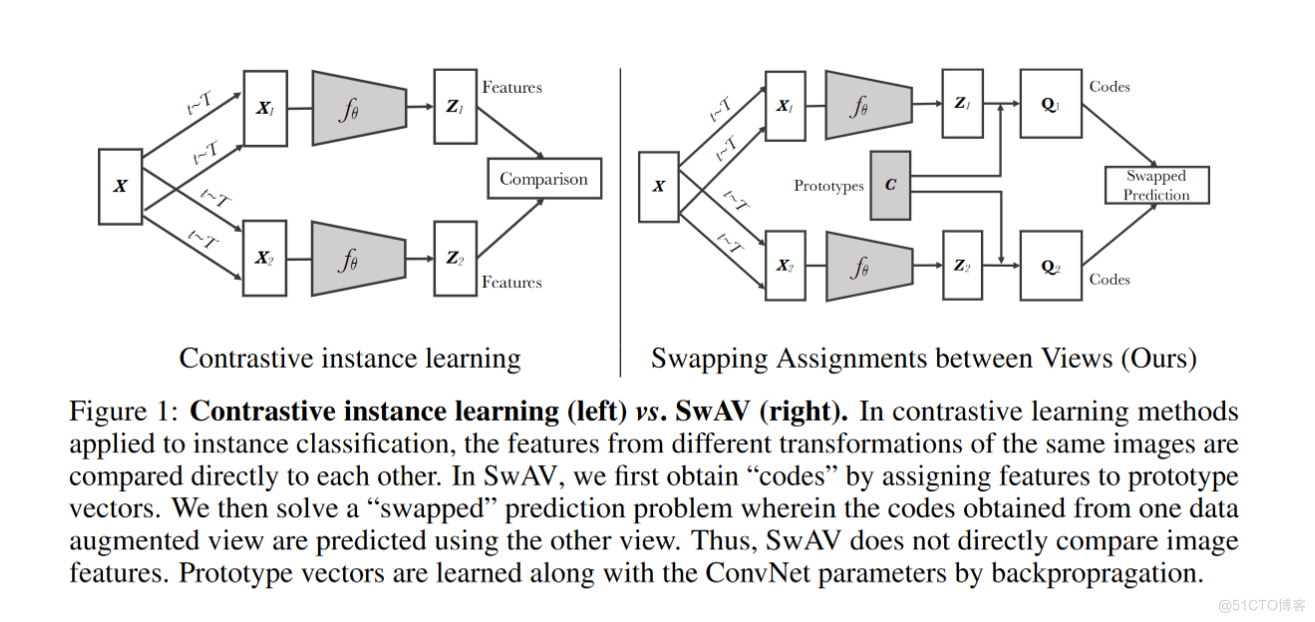
- 先說重複問題:因為你使用的是聚類中心進行比較。雖然是不同的聚類中心,那麼他肯定不可能出現重複的情况。
- 再說一下沒有代錶性的問題:聚類就是將眾多的圖片聚成不同的類別。與每一個類別的中心進行對比,是絕對具有代錶性的。
- 再說一下過去有過多負樣本造成資源浪費的問題。如果要跟很多的負樣本去做類比,可能就需要成千上萬的負樣本,而且即使如此也只是一個近似,而如果只是跟聚類中心做對比,則可以用幾百或者最多3,000個聚類中心,就足以錶示了。大大减少了計算資源消耗。
边栏推荐
猜你喜欢

普通测试年薪15w,测试开发年薪30w+,二者差距在哪?
![[untitled]](/img/f0/a34c116a793e844da46c7cd407224b.jpg)
[untitled]
Input type= "password" how to solve the problem of password automatically brought in
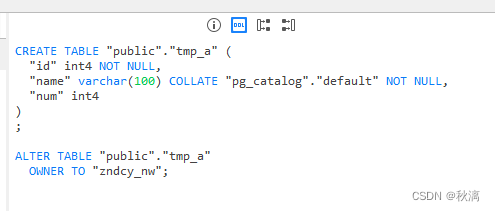
PostgreSQL中的表复制
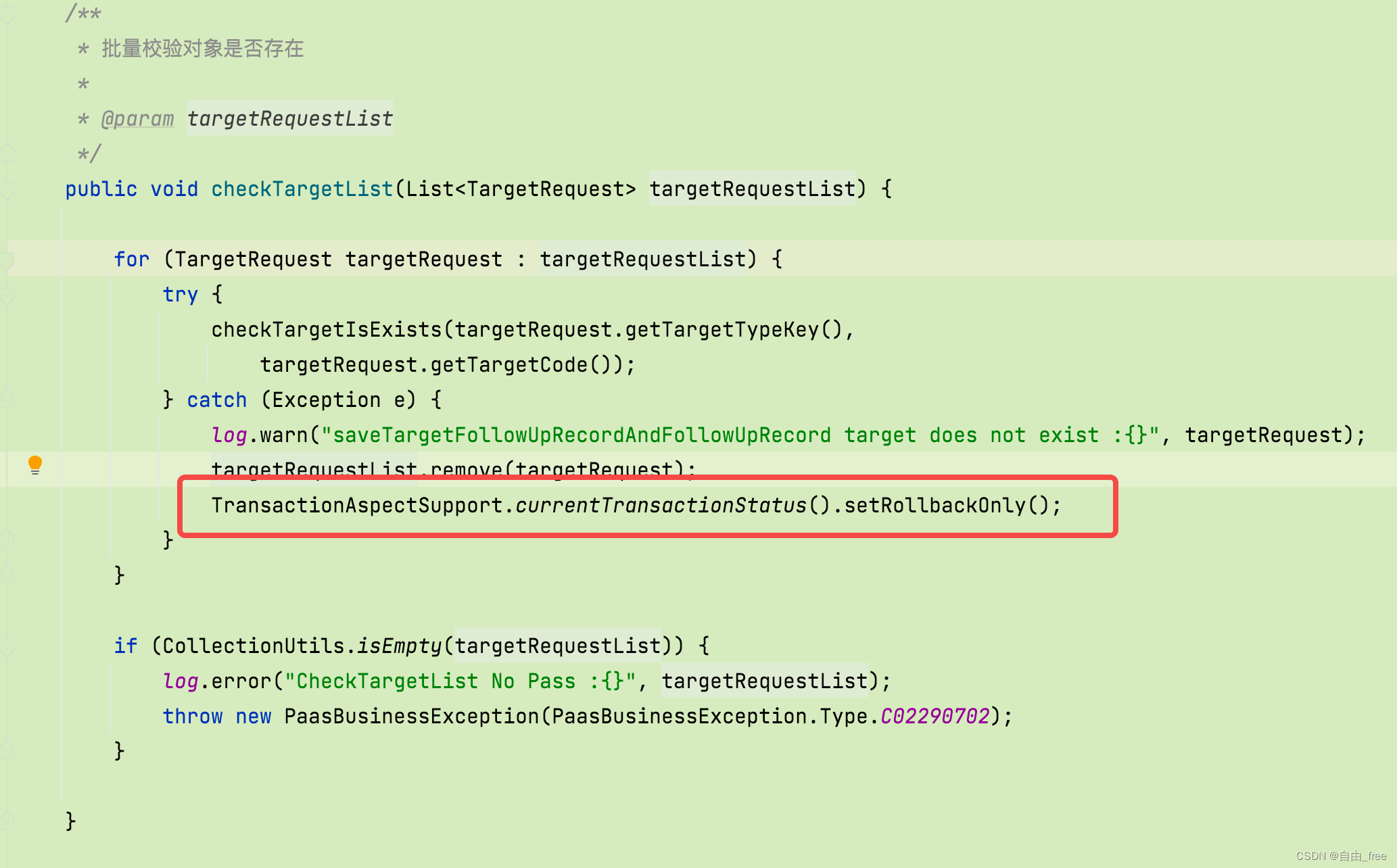
Transaction rolled back because it has been marked as rollback-only解决
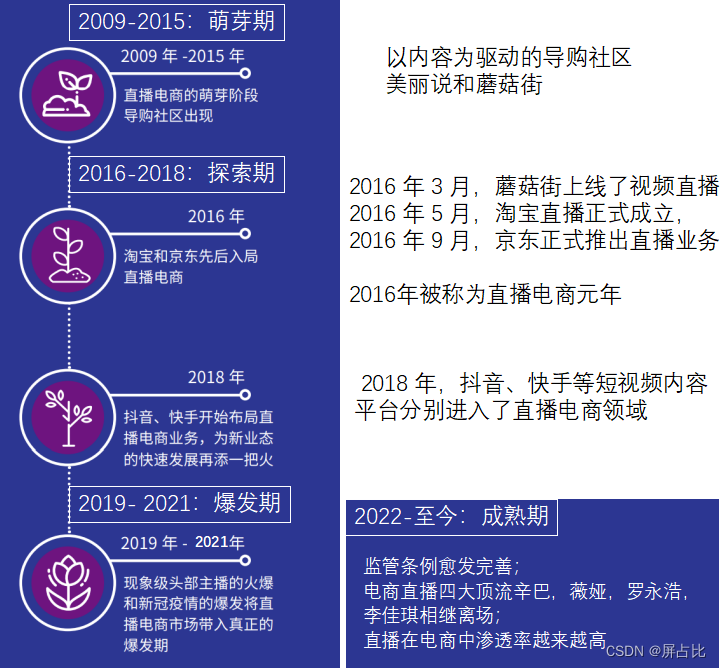
从色情直播到直播电商
![[OneNote] can't connect to the network and can't sync the problem](/img/28/9a02b1da0f43889989a9539c9fb6b6.png)
[OneNote] can't connect to the network and can't sync the problem
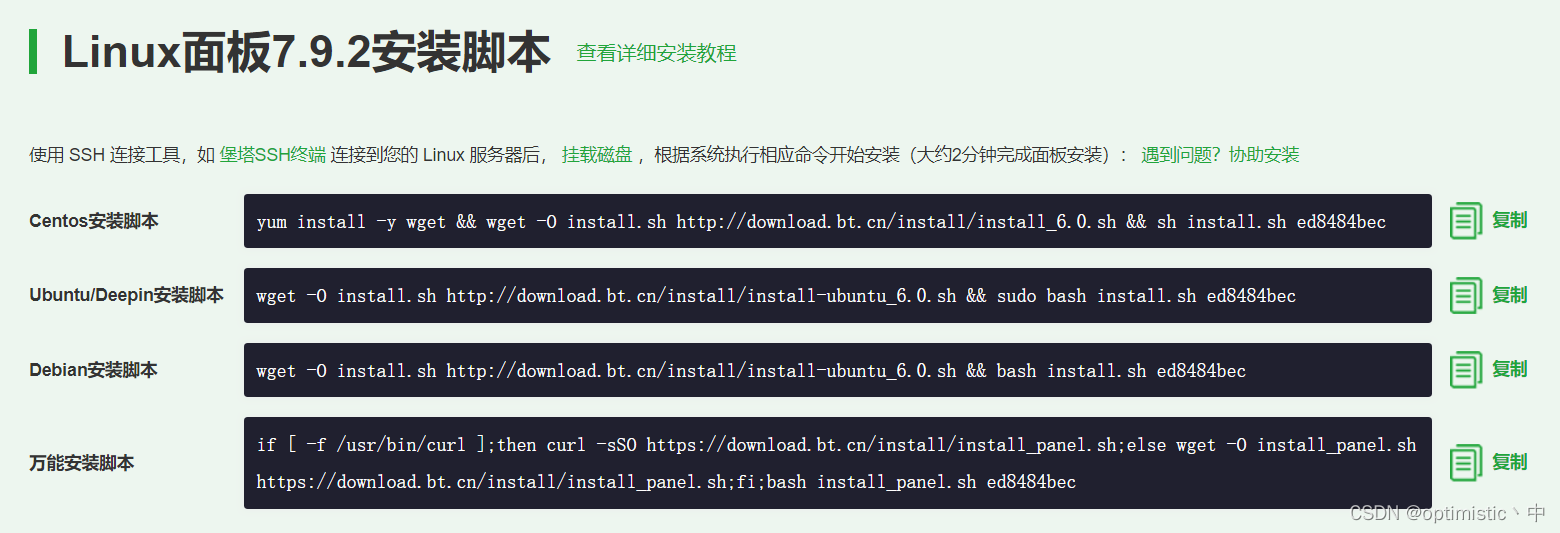
关于在云服务器上(这里用腾讯云)安装mysql8.0并使本地可以远程连接的方法
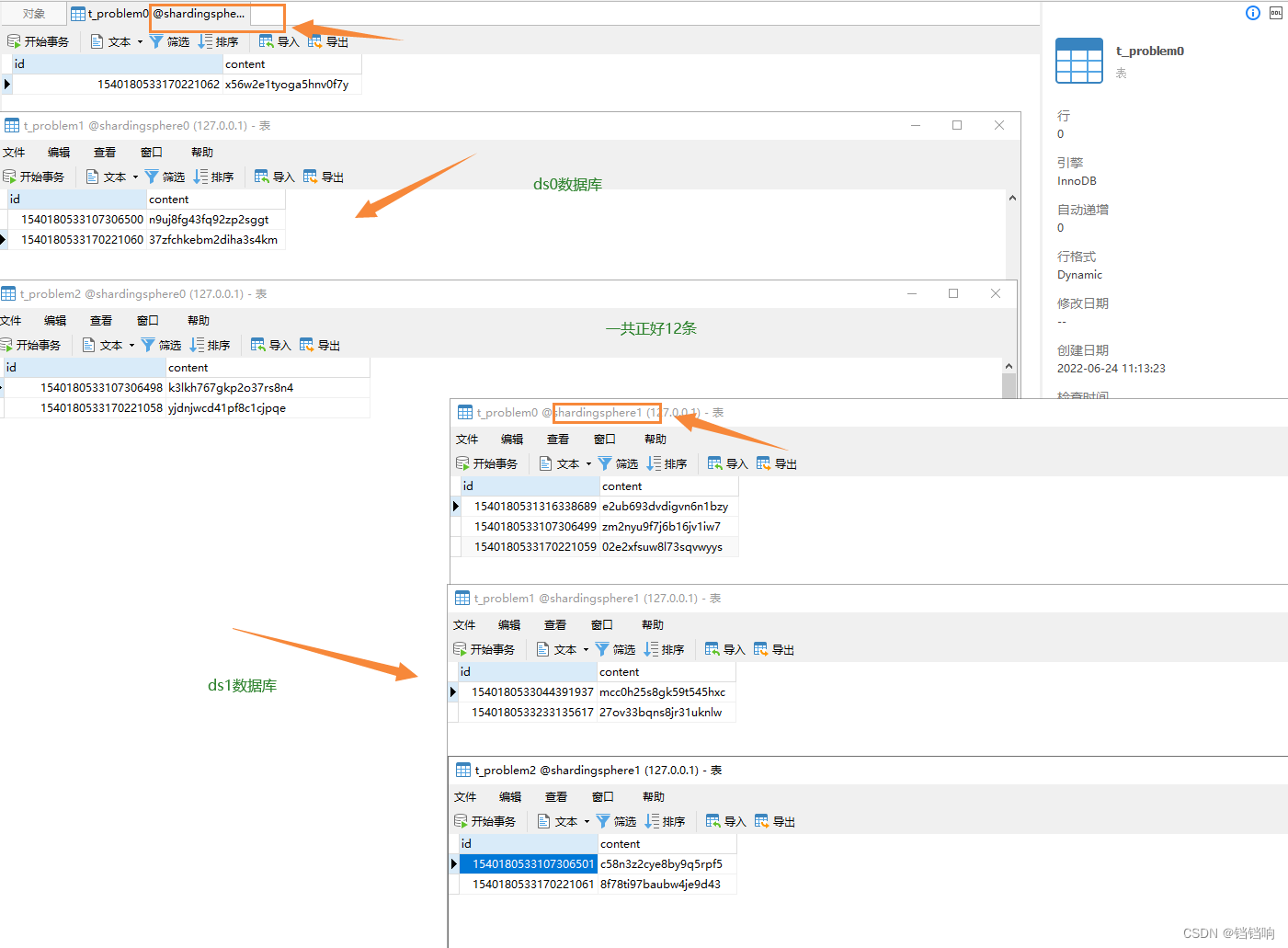
Shardingsphere sub database and table examples (logical table, real table, binding table, broadcast table, single table)
如何在博客中添加Aplayer音乐播放器
随机推荐
uniapp 在onLaunch中跳转页面后,点击事件失效解决方法
Using ENSP to do MPLS pseudo wire test
[pyqt] the cellwidget in tablewidget uses signal and slot mechanism
Process control (creation, termination, waiting, program replacement)
毕业季|与青春作伴,一起向未来!
2021-05-21
A simple example of delegate usage
使用引用
Force buckle 1002 Find common characters
Kitex retry mechanism
技术分享 | 抓包分析 TCP 协议
TDengine 社区问题双周精选 | 第二期
[untitled]
Avoid mutating a prop directly since the value will be overwritten whenever the parent component
uniCloud
Shardingsphere sub database and table examples (logical table, real table, binding table, broadcast table, single table)
The use of list and Its Simulation Implementation
The sixth training assignment
verilog设计抢答器【附源码】
书签整理-程序员常用网站导航