当前位置:网站首页>Five papers recommended for the new development of convolutional neural network in deep learning
Five papers recommended for the new development of convolutional neural network in deep learning
2022-07-04 23:50:00 【deephub】
1、Deformable CNN and Imbalance-Aware Feature Learning for Singing Technique Classification
Yuya Yamamoto, Juhan Nam, Hiroko Terasawa
https://arxiv.org/pdf/2206.12230
Singing technology is the use of timbre 、 The pitch and other components of the sound fluctuate in time to perform an expressive vocal performance . Their classification is a challenging task , This is mainly due to two factors :1) There are many kinds of fluctuations in singing skills , Affected by many factors ;2) Existing datasets are unbalanced . To solve these problems , This paper develops a new audio feature learning method based on deformation convolution , The class weighted loss function is used to decouple the feature extractor and the classifier . Experimental results show that :1) Deformable convolution improves the classification effect , Especially when applied to the last two layers of convolution ;2) Retrain the classifier , And through the smooth inverse frequency weighted cross entropy loss function , Improved classification performance .
2、CNN-based fully automatic wrist cartilage volume quantification in MR Image
Nikita Vladimirov, Ekaterina Brui, Anatoliy Levchuk, Vladimir Fokin, Aleksandr Efimtcev, David Bendahan
https://arxiv.org/pdf/2206.11127
The detection of cartilage loss is very important for the diagnosis of osteoarthritis and rheumatoid arthritis . So far, there have been a large number of papers on the automatic segmentation tool for cartilage evaluation of joint magnetic resonance images . Compared with knee or hip , The structure of carpal cartilage is more complex , Automatic tools developed for large joints cannot be used for the segmentation of wrist cartilage . However, the automatic wrist cartilage segmentation method has high clinical value , So the paper through optimization U-Net Depth of architecture and increased attention layer (U-Net_AL), Assessed U-Net The performance of four excellent variants of the architecture . and · Compare the corresponding results with the previous design based on patch Convolution neural network of (CNN) Compare the results of . The evaluation of segmentation quality is based on the use of several morphologies (2D DSC、3D DSC、 precision ) And the comparative analysis of volume index and manual segmentation . These four networks are better than those based on patch Of CNN.U-Net_AL Calculated three-dimensional DSC The median (0.817) Significantly larger than the corresponding three-dimensional calculation of other networks DSC value . Besides U-Net_AL CNN Provides minimum average volume error (17%) And the highest relative to the real value Pearson The correlation coefficient (0.765). Use U-Net_AL The reproducibility of calculation is greater than that of manual segmentation . With an additional attention layer U-net Convolutional neural network provides the best performance of wrist cartilage segmentation . For use under clinical conditions , The trained network can fine tune the data set representing a specific group of patients .
3、EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications
Muhammad Maaz, Abdelrahman Shaker, Hisham Cholakkal, Salman Khan, Syed Waqas Zamir, Rao Muhammad Anwer, Fahad Shahbaz Khan
https://arxiv.org/pdf/2206.10589
In order to pursue the continuous improvement of accuracy , It is usually necessary to develop large and complex neural networks . This model requires high computational resources , Therefore, it cannot be deployed on edge devices . Therefore, building a resource efficient general network has received great attention in many application fields . The work of this paper effectively combines CNN and Transformer The advantages of the model , And propose a new efficient hybrid architecture EdgeNeXt. Especially in EdgeNeXt in , Introduced segmentation depth transpose attention (SDTA) Encoder , The encoder divides the input into multiple channel groups , We use deep convolution and cross channel self attention to implicitly increase the receiving field and encode multi-scale features . By sorting in 、 A large number of experiments on detection and segmentation tasks , The advantages of the proposed method are proved : Relatively low calculation requirements and superior to the most advanced methods . With 2.2% The absolute gain sum of 28% Of FLOP The reduced absolute gain exceeds MobileViT.EdgeNeXt The model has 5.6M Parameters , stay ImageNet-1K It has been realized. 79.4% top-1 precision .
4、Scaling up Kernels in 3D CNNs
Yukang Chen, Jianhui Liu, Xiaojuan Qi, Xiangyu Zhang, Jian Sun, Jiaya Jia
https://arxiv.org/abs/2206.10555
2D CNN and ViT The latest developments in the field show that , A large kernel is essential for sufficient receptive fields and high performance . Inspired by these papers , Change the paper to study 3D The feasibility and challenges of large kernel design . Prove that 3D CNN There are more difficulties in performance and efficiency in the application of large convolution cores . stay 2D CNN Existing technologies that work well in 3D It is invalid in the network , Including popular depth-wise convolutions. In order to overcome these problems , This paper proposes the space group convolution and its large kernel module (SW-LK block ). Avoid the traditional 3D Optimization and efficiency of large kernel . The big core proposed in this paper 3D CNN The Internet , namely LargeKernel3D, For all kinds of 3D Mission ( Including semantic segmentation and object detection ) Significant improvements have been made . It's in ScanNetv2 Semantic segmentation realizes 73.9% Of mIoU, stay NDS nuScenes Based on the object detection benchmark 72.8%, stay nuScenes LIDAR Number one on the charts . Through simple multimodal fusion ,NDS Further upgrade to 74.2%.LargeKernel3D Got its CNN and Transformer An equivalent or better result . And it is proved for the first time that a large kernel is suitable for 3D Network is feasible and essential .
5、MEStereo-Du2CNN: A Novel Dual Channel CNN for Learning Robust Depth Estimates from Multi-exposure Stereo Images for HDR 3D Applications
Rohit Choudhary, Mansi Sharma, Uma T V, Rithvik Anil
https://arxiv.org/pdf/2206.10375
In display technology HDR Capture 、 Processing and displaying solutions is critical . Developing cost-effective 3D HDR In video content , Depth estimation of multi exposure stereo image sequences is an essential task . This paper proposes and develops a new depth architecture for stereo depth estimation of multiple exposures . The proposed architecture has two new components .1、 The stereo matching technology used in traditional stereo depth estimation is improved , Deployed a three-dimensional transfer learning method , This method avoids the requirement of cost volume construction , The adoption is based on ResNet Double encoders and single decoders with different weights CNN Feature fusion , And use the effentnet To learn parallax .2、 Using robust parallax feature fusion method , The parallax maps of stereo images under different exposure levels are combined . The parallax images obtained by different exposures are combined and the weight images are used to calculate different qualities . The final predicted disparity map has stronger robustness , And retain the best feature of depth discontinuity . Proposed by the paper CNN Architecture in challenging scene streams and different exposures Middlebury On the stereo data set , It surpasses the most advanced monocular and stereo depth estimation methods in both quantitative and qualitative aspects . The architecture also performs very well in complex natural scenes , It proves that it can be applied to all kinds of 3D HDR Applications are useful .
https://avoid.overfit.cn/post/518cdba7f3174604bb8236cee180e353
author :monodeep
边栏推荐
- 企业里Win10 开启BitLocker锁定磁盘,如何备份系统,当系统出现问题又如何恢复,快速恢复又兼顾系统安全(远程设备篇)
- Illustrated network: what is gateway load balancing protocol GLBP?
- How to effectively monitor the DC column head cabinet
- [JS] - [sort related] - Notes
- Hong Kong Jewelry tycoon, 2.2 billion "bargain hunting" Giordano
- Every time I look at the interface documents of my colleagues, I get confused and have a lot of problems...
- Etcd database source code analysis - brief process of processing entry records
- QT addition calculator (simple case)
- Fast parsing intranet penetration helps enterprises quickly achieve collaborative office
- 【js】-【动态规划】-笔记
猜你喜欢

Why does infographic help your SEO
业务场景功能的继续修改
QT personal learning summary
微服务(Microservice)那点事儿
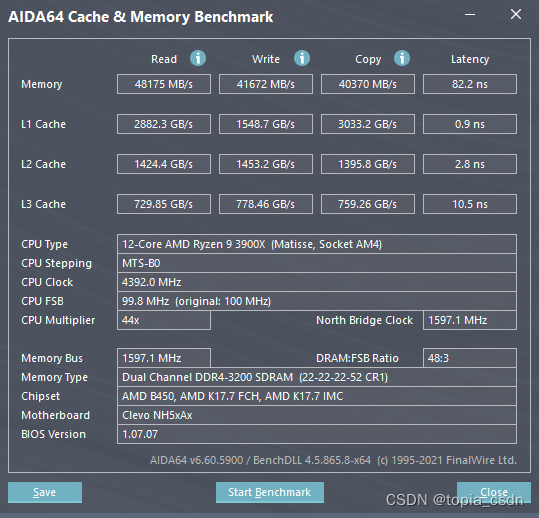
Blue sky nh55 series notebook memory reading and writing speed is extremely slow, solution process record

How to effectively monitor the DC column head cabinet
Application of multi loop instrument in base station "switching to direct"
![[path planning] RRT adds dynamic model for trajectory planning](/img/98/dd9b106fd9dc64e676d9c943c03ab3.jpg)
[path planning] RRT adds dynamic model for trajectory planning

基于三维gis平台的消防系统运用
【js】-【排序-相关】-笔记
随机推荐
[crawler] XPath for data extraction
快解析——好用的内网安全软件
如何避免电弧产生?—— AAFD故障电弧探测器为您解决
MIT-6.824-lab4B-2022(万字思路讲解-代码构建)
[ODX studio edit PDX] -0.3- how to delete / modify inherited elements in variant variants
ECCV 2022 | Tencent Youtu proposed disco: the effect of saving small models in self supervised learning
Servlet+jdbc+mysql simple web exercise
MP advanced operation: time operation, SQL, querywapper, lambdaquerywapper (condition constructor) quick filter enumeration class
Build your own minecraft server with fast parsing
Ffmpeg quick clip
The initial arrangement of particles in SPH (solved by two pictures)
JS convert pseudo array to array
[IELTS reading] Wang Xiwei reading P4 (matching1)
Meet ThreadPoolExecutor
List related knowledge points to be sorted out
Application of machine learning in housing price prediction
Excel shortcut keys - always add
Jar batch management gadget
业务场景功能的继续修改
How to use fast parsing to make IOT cloud platform