当前位置:网站首页>[NTIRE 2022]Residual Local Feature Network for Efficient Super-Resolution
[NTIRE 2022]Residual Local Feature Network for Efficient Super-Resolution
2022-07-05 09:32:00 【hbw136】
Residual Local Feature Network for Efficient Super-Resolution
(用于高效超分辨率的残差特征局部网络)
NTIRE 2022
*图像修复领域最具影响力的国际顶级赛事——New Trends in Image Restoration and Enhancement(NTIRE)
作者:Fangyuan Kong* Mingxi Li∗ Songwei Liu∗ Ding Liu Jingwen He Yang Bai Fangmin Chen Lean Fu
单位:ByteDance Inc
代码: https://github.com/fyan111/RLFN
论文地址:https://arxiv.org/pdf/2205.07514
一、问题动机
基于深度学习的方法在单幅图像超分辨率(SISR)中取得了很好的表现。然而,高效超分辨率的最新进展侧重于减少参数和 FLOP 的数量,它们通过复杂的层连接策略提高特征利用率来聚合更强大的特征。这些结构受限于当今的移动端硬件架构,这使得它们难以部署到资源受限的设备上。
二、主要思路和亮点
作者重新审视了当前最先进的高效 SR 模型 RFDN ,并尝试在重建图像质量和推理时间之间实现更好的权衡。首先,作者重新考虑了 RFDN 提出的残差特征蒸馏块的几个组件的效率。作者观察到,尽管特征蒸馏显着减少了参数数量并有助于整体性能,但它对硬件不够友好,并限制了 RFDN 的推理速度。为了提高其效率,作者提出了一种新颖的残差局部特征网络(RLFN),可以减少网络碎片并保持模型容量。为了进一步提高其性能,作者建议使用对比损失。作者注意到,其特征提取器的中间特征的选择对性能有很大的影响。作者对中间特征的性质进行了综合研究,并得出结论,浅层特征保留了更准确的细节和纹理,这对于面向 PSNR 的模型至关重要。基于此,作者构建了一个改进的特征提取器,可以有效地提取边缘和细节。为了加速模型收敛并提高最终的 SR 恢复精度,作者提出了一种新颖的多阶段热启动训练策略。具体来说,在每个阶段,SR 模型都可以享受到所有先前阶段的模型的预训练权重的好处。结合改进的对比损失和提出的热启动训练策略,RLFN 实现了最先进的性能并保持良好的推理速度。此外,作者还凭此获得了 NTIRE 2022 高效超分辨率挑战赛的运行时间赛道第一名。
作者的贡献可以总结如下:
- 作者重新思考了RFDN的效率,并研究了它的速度瓶颈。作者提出了一种新的残差局部特征网络,它成功地提高了模型的紧凑性,并在不牺牲SR恢复精度的情况下加速了推理。
- 作者分析了由对比损失的特征提取器提取的中间特征。作者观察到,浅层特征对面向神经模型至关重要,这启发作者提出一种新的特征提取器来提取更多的边缘和纹理信息。
- 作者提出了一种多阶段的暖启动训练策略。它可以利用前阶段训练的权重来提高SR性能。
三、细节
1、模型结构
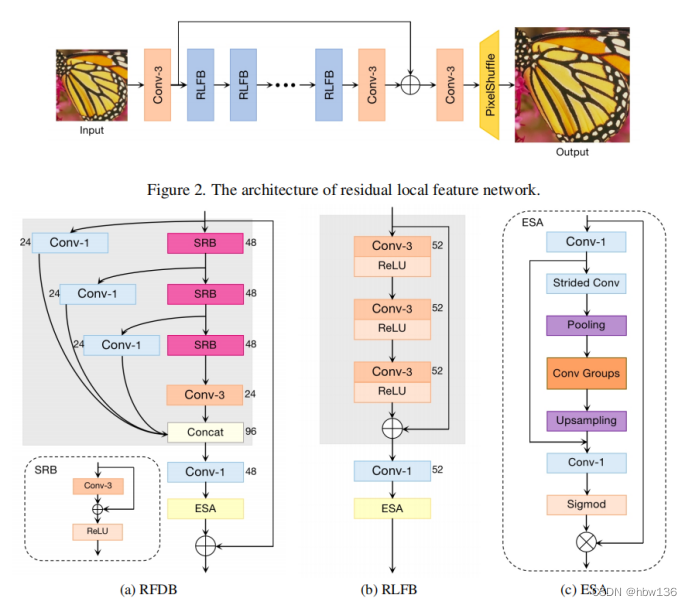
作者提出的残差局部特征网络(RLFN)的整体网络架构如上图所示。作者的RLFN主要由三个部分组成:第一个特征提取卷积、多个堆叠的剩余局部特征块(RLFBs)和重构模块。作者将ILR和ISR表示为RLFN的输入和输出。在第一阶段,作者使用一个单一3×3卷积层来提取粗特征:
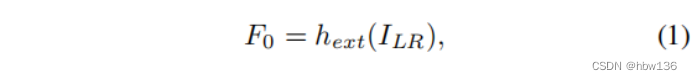
其中,hext(·)为特征提取的卷积运算,f0为提取的特征映射。然后,作者以级联的方式使用多个rlfb进行深度特征提取。这个过程可以用:
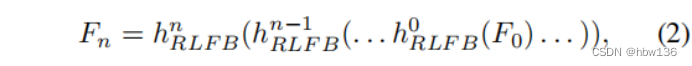
其中,hnRLFB(·)表示第n个RLFB函数,Fn为第n个输出特征映射。
此外,作者使用一个3×3卷积层来平滑逐渐细化的深度特征图。接下来,应用重构模块生成最终的输出ISR。

其中,frec(·)表示由一个3×3卷积层和一个亚像素操作(非参数)组成的重构模块。此外,fsmooth表示3×3卷积运算。
对比于原始的RFDN(baseline)相比作者主要将蒸馏分支删去换为残差连接,并经过冗余分析将每个group里的conv数量删减为一个,保证了在移动设备上的运行效率。
2、重新审视对比损失
对比学习在自我监督学习中表现出令人印象深刻的表现。 背后的基本思想是在潜在空间中将正数推向锚点,并将负数推离锚点。 最近的工作提出了一种新颖的对比损失,并通过提高重建图像的质量来证明其有效性。 对比损失定义为:
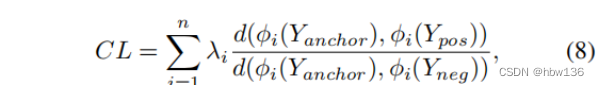
其中,φj表示第j层的中间特征。d(x,y)是x和y之间的l1距离,λj是每一层的平衡权重。AECR-Net和CSD从预训练后的VGG-19的第1、第3、第5、第9和第13层中提取特征。然而,作者通过实验发现,当使用对比损失时,PSNR值降低了。
接下来,作者试图调查它的原因来解释这种差异。在等式中定义的对比损失(8)主要依赖于两幅图像Y1和Y2之间的特征图的差异。因此,作者试图可视化由预先训练的模型φ提取的特征图的差异图:
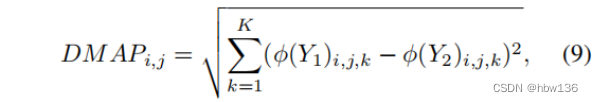
式中,i、j为y1、y2的空间坐标,k为y1、y2的通道指数。作者使用DIV2K数据集中的100个验证性的高分辨率图像作为Y1,相应的图像将模糊核退化为Y2。下图给出了可视化的示例。一个令人惊讶的观察是,从更深的层次提取的特征差异图更语义,但缺乏准确的细节。例如,边缘和纹理大部分在第一层保留,而第13层的特征只保留了整体的空间结构,而细节通常缺失。综上所述,深层特征可以提高真实感知质量的性能,因为它提供了更多的语义指导。来自浅层的特征保留了更准确的细节和纹理,这对于面向PSNR的模型是至关重要的。建议作者利用浅层特征来改进训练模型的PSNR。

为了进一步改进对比损失,作者重新讨论了特征提取器的架构。原始的对比损失试图在ReLU激活函数后最小化两个激活特征之间的距离。然而,ReLU函数是无界的,激活的特征映射是稀疏的,导致信息丢失,提供较弱的监督。因此,作者将特征提取器的ReLU激活函数替换为Tanh函数。
此外,由于VGG-19是用ReLU激活函数进行训练的,所以如果不经过任何训练就将ReLU激活替换为Tanh函数,那么性能就不能保证。最近的一些研究表明,一个具有良好结构的随机初始化的网络足以捕获感知细节。受这些工作的启发,作者构建了一个随机初始化的两层特征提取器,它具有Convk3s1-Tanh-Convk3s1的体系结构。预先训练好的VGG-19和作者提出的特征提取器的差异图如下图所示。作者可以观察到,与预先训练过的VGG-19的差异图相比,作者提出的特征提取器的差异图具有更强的响应能力,可以捕获更多的细节和纹理。这也提供了证据,表明一个随机初始化的特征提取器已经可以捕获一些结构信息,而预训练是不必要的。

3、暖启动策略(warm start)
对于像SR任务中的3或4这样的大规模因素,之前的一些工作使用2x模型作为一个预先训练的网络,而不是从头开始训练它们。2x模型提供了良好的初始化权值,加速了收敛速度,提高了最终的性能。但是,由于预训练模型和目标模型的scale不同,一次针对特定scale的训练无法适应多种尺度。
为了解决这一问题,作者提出了一种新的多阶段暖启动训练策略,它可以通过经验来提高SISR模型性能。在第一阶段,作者从零开始训练RLFN。然后在下一阶段,作者不是从头开始训练,而不是加载前一阶段的RLFN的权重,这被称为暖启动策略。训练设置,如批量大小和学习率,在第一阶段遵循完全相同的训练方案。在接下来的本文中,作者使用RFLN_ws_i来表示使用暖启动i次(在i+1阶段之后)的训练模型。例如,RFLN_ws_1表示一个双阶段的训练过程。在第一阶段,作者从零开始训练RLFN。然后在第二阶段,RLFN加载预先训练好的权值,并按照与第一阶段相同的训练方案进行训练。
四、实验
1、设置
数据集和指标作者使用 DIV2K 数据集中的 800 张训练图像进行训练。作者在四个基准数据集上测试了作者模型的性能:Set5、Set14、BSD100 [35] 和 Urban100。作者在 YCbCr 空间的 Y 通道上评估 PSNR 和 SSIM。训练细节作者的模型是在 RGB 通道上训练的,作者通过随机翻转和 90 度旋转来增加训练数据。 LR 图像是通过在 MATLAB 中使用双三次插值对 HR 图像进行下采样而生成的。作者从ground truth中随机裁剪大小为 256×256 的 HR 补丁,小批量大小设置为 64。训练过程分为三个阶段。在第一阶段,作者从头开始训练模型。然后作者两次采用热启动策略。在每个阶段,作者通过设置 β1 = 0.9、β2 = 0.999 和 = 10−8 来采用 Adam 优化器,并在 RFDN 的训练过程之后最小化 L1 损失。初始学习率为 5e-4,每 2 × 105 次迭代减半。此外,作者还在第三阶段使用了广泛使用的对比损失。作者实现了两个模型,RLFN-S 和 RLFN。 RLFB 的数量在两个模型中都设置为 6。作者将 RLFN 的通道数设置为 52。为了获得更好的运行时间,RLFN-S 的通道数较小,为 48。
2、实验结果

3、消融实验
为了评估作者的模型架构优化的有效性,作者设计了RFDB的两个变体。如图7所示,作者删除RFDB中的特征蒸馏层得到RFDBR48,然后RFDBR52将通道数量增加到52,ESA的中间通道增加到16,以降低性能下降,RLFB删除基于RFDBR52的SRB内部的密集添加操作。RFDB、RFDBR48、RFDBR52和RLFB作为SR网络的主体部分堆叠,如下表所示,RLFB与RFDB保持了相同的恢复性能水平,但具有明显的速度优势。

为了研究对比损失的有效性,作者去掉了第二个热启动阶段的对比损失,只使用L1损失。如下表所示,在四个基准数据集上,对比损失持续地提高了PSNR和SSIM的性能。

热启动策略的有效性为了证明作者提出的热启动策略的有效性,作者比较了 RLFN-S ws 1 作为基线和不同学习率策略的两种变体,RLFN-S e2000 和 RLFNS clr。 在此比较中不使用对比损失,而其他训练设置保持不变。 他们将总时期设置为 2000 以与 RLFN-S ws 1 进行比较。RLFNS e2000 每 4 × 105 次迭代将学习率减半。 RLFN-S clr 应用循环学习率策略,与 RLFN-S ws 1 相同。但是,它加载优化器的状态,而 RLFN-S ws 1 应用默认初始化。 如下表所示,与作者提出的热启动策略相比,RLFN-S e2000 和 RLFN-S clr 降低了 PSNR 和 SSIM。 说明热启动策略有助于在优化过程中跳出局部最小值,提高整体性能。

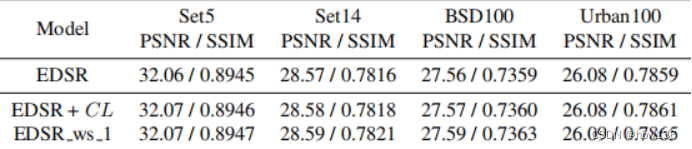
作者也研究了作者提出的对比损失和热启动策略的推广。作者分别对EDSR采用对比损失和热启动策略。定量比较如下表所示,这表明作者提出的方法是通用的,可以应用于其他现有的SISR模型。
五、总结
在本文中,作者提出了一个有效的SISR的剩余局部特征网络。通过减少层数和简化层之间的连接,作者的网络更轻、更快。然后,作者重新审视对比损失的使用,改变特征提取器的结构,并重新选择对比损失所使用的中间特征。作者还提出了一种热启动策略,这有利于轻量级SR模型的训练。大量的实验表明,作者的总体方案,包括模型结构和训练方法,达到了质量和推理速度的平衡。
六、启发
1、通读作者的论文后,我们知道了浅层特征对面向神经模型至关重要,作者也提出一种新的特征提取器来提取更多的边缘和纹理信息,可以用它来提升模型的指标性能(?)以及视觉效果
2、作者提出的多阶段的暖启动训练策略。它可以利用前阶段训练的权重来提高SR性能。
边栏推荐
- Kotlin introductory notes (VI) interface and function visibility modifiers
- Lepton 无损压缩原理及性能分析
- Why does everyone want to do e-commerce? How much do you know about the advantages of online shopping malls?
- Tdengine already supports the industrial Intel edge insight package
- LeetCode 503. 下一个更大元素 II
- STM32 simple multi-level menu (array table lookup method)
- The writing speed is increased by dozens of times, and the application of tdengine in tostar intelligent factory solution
- 【组队 PK 赛】本周任务已开启 | 答题挑战,夯实商品详情知识
- How to implement complex SQL such as distributed database sub query and join?
- LeetCode 556. 下一个更大元素 III
猜你喜欢

Three-level distribution is becoming more and more popular. How should businesses choose the appropriate three-level distribution system?

Android privacy sandbox developer preview 3: privacy, security and personalized experience
OpenGL - Lighting
Using request headers to develop multi terminal applications
图神经网络+对比学习,下一步去哪?

LeetCode 556. 下一个更大元素 III
TDengine ×英特尔边缘洞见软件包 加速传统行业的数字化转型
使用el-upload封装得组件怎么清空已上传附件

mysql安装配置以及创建数据库和表
Unity skframework framework (XXIII), minimap small map tool
随机推荐
基于宽表的数据建模应用
Lepton 无损压缩原理及性能分析
OpenGL - Coordinate Systems
SQL learning alter add new field
Analysis of eventbus source code
[object array A and object array B take out different elements of ID and assign them to the new array]
LeetCode 556. 下一个更大元素 III
LeetCode 31. 下一个排列
百度智能小程序巡检调度方案演进之路
MySQL does not take effect in sorting string types
一次 Keepalived 高可用的事故,让我重学了一遍它
SQL learning - case when then else
SMT32H7系列DMA和DMAMUX的一点理解
E-commerce apps are becoming more and more popular. What are the advantages of being an app?
Tdengine can read and write through dataX, a data synchronization tool
[listening for an attribute in the array]
Vs code problem: the length of long lines can be configured through "editor.maxtokenizationlinelength"
Kotlin introductory notes (V) classes and objects, inheritance, constructors
OpenGL - Lighting
测试老鸟浅谈unittest和pytest的区别