当前位置:网站首页>百度智能小程序巡檢調度方案演進之路
百度智能小程序巡檢調度方案演進之路
2022-07-05 09:36:00 【百度Geek說】

導讀:百度智能小程序依托以百度APP為代錶的全域流量,精准連接用戶。如今,百度智能小程序線上體量近百萬,包含的內容資源量更有上百億之多;海量的頁面下,如何更高效、快速的發現有問題的頁面,從而保障線上內容安全與用戶體驗,將是一個不小的挑戰。本文內容會圍繞小程序線上內容的安全巡查機制,並重點介紹小程序的巡檢調度方案的演進過程。
全文6178字,預計閱讀時間16分鐘。
一、業務簡介
1.1 巡檢業務介紹
百度智能小程序依托百度的生態和場景,通過百度APP“搜索+推薦”的方式為開發者獲取流量提供了便捷的通道,極大的降低了開發者獲客成本。隨著小程序開發者入駐量增長,線上小程序的內容質量參差不齊,低質的內容(色情、低俗等)如果在線上展現,會極大地影響用戶體驗;且部分嚴重違規內容(政治敏感、賭博等)甚至會造成嚴重法務風險,同時威脅到小程序的生態安全。因此,針對線上小程序,需要建設質量評估能力、巡檢及線上幹預機制,通過對小程序內容實現7*24小時的線上巡查,對於不符合標准的小程序,及時進行限時整改或强制下線等處理,從而最終保障小程序線上生態質量和用戶體驗。
1.2 巡檢調度策略的目標和核心限制因素
目前百度智能小程序天級去重後的頁面訪問量達數億,小程序線上的全部頁面資源量更是高達上百億。理想情况下,為了全面把控風險,應該對所有頁面實現“應檢盡檢”,快速高准地召回線上風險。
但實際執行中,需要考慮到以下因素或限制:
不同小程序(或主體)下的內容安全指數不同。如,政務等特殊類目小程序發布本身需要經過較嚴格的審查,出現違規的可能性不大;相反,其他某些特殊類目下的小程序存在違規的風險指數就比較高。而當某些主體下的部分小程序曆史上違規次數比較多,該主體下的其他小程序發生違規作弊的可能性就也比較大,等等,導致對不同小程序(或主體)下的頁面需要區別對待;
小程序被抓取的配額限制。每次針對小程序頁面的抓取,最終都等同於對該頁面的訪問,會轉換為小程序服務端的壓力,不能因為巡檢本身影響到開發者服務的穩定性。在小程序開發平臺中,開發者可以錶達自身小程序允許被抓取的配額;針對沒有顯示錶達配額的小程序,我們也會根據小程序的流量(PV、UV等)設置合理的抓取閾值;
資源限制。對頁面的內容安全評估,首先依賴對頁面進行spider抓取、渲染、解析其中包含的文本和圖片內容、針對文本和圖片的安全檢測;而抓取、渲染、檢測等過程均需要耗費大量的機器資源;
其他相關因素和限制還包括:頁面流量對應的風險指數(流量高的頁面和只有一次點擊的頁面發生風險時對應的影響面不同)、不同流量入口的區分等。
因此,我們需要綜合考慮以上各項,設計巡檢調度策略,並根據對線上准召case的評估,不斷地優化調整策略,優化資源利用率,以更高效、更准確地發現線上潜在的風險問題,降低風險在線上的暴露時長,最終保證智能小程序的生態健康。
二、巡檢調度方案的演進過程
2.1 V1.0版巡檢調度方案
2.1.1 頂層架構
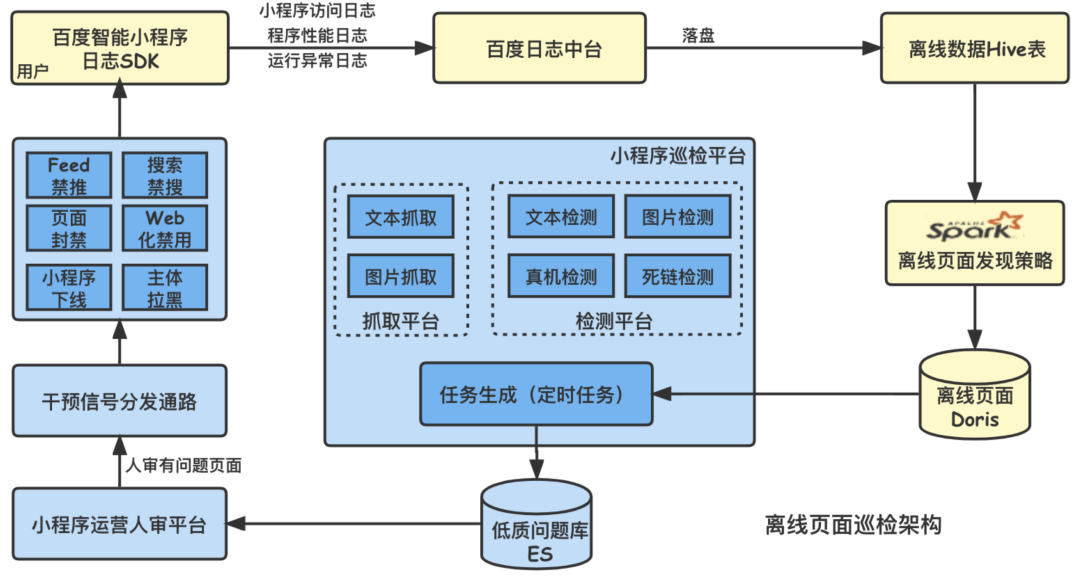
巡檢V1.0的頂層設計如下圖所示,其中包含的關鍵組件(或流程)如下:
數據源:線上用戶在使用百度智能小程序的過程中,端sdk會不斷采集相關的埋點日志(包括小程序訪問日志、性能日志、异常日志等),隨後上報到百度日志中臺,並落盤存儲。這些日志數據將是巡檢頁面發現策略很重要的數據源。(備注:基於百度安全准則,我們不會采集或通過登錄態等獲取或存儲密保的手機號等用戶隱私信息)
頁面發現策略:小程序每天有點擊(或訪問)的去重頁面量高達數億之多,受限於抓取、渲染、檢測等各環節的資源限制,如何從這些頁面中高效挖掘出潜在的風險頁面,是巡檢策略的目標。
巡檢平臺:平臺本身包含巡檢任務生成、頁面送抓取、各種能力檢測(對應風控類/體驗類、紅線類/非紅線類等各類低質問題)等多個子服務模塊,模塊間多經過Kafka進行异步交互。
低質審核及信號下發:由於部分機審能力側重高召回,運營同學會對機審召回的風險內容進行人工審核,經過人工確認的低質信號會被下發應用至下遊。
線上低質幹預(打壓):針對各類低質風險問題,結合小程序流量特點、問題的風險等級等,我們有一套完善的、精細化的線上幹預流程,會對小程序實施從單頁面屏蔽、流量關閉到小程序下線、甚至主體拉黑等不同程度的處罰措施。
2.1.2 巡檢調度策略實現
V1.0版的巡檢策略集中采用離線方式調度,結合小程序流量分布、行業類目特點、線上發布周期、違規曆史等特征,我們從線上抽象出多種不同的策略,分別做從小時級到周級等不同周期的調度。
為平衡業務訴求和資源需要,巡檢調度方案還考慮了如下因素:
同策略內及不同策略間的頁面URL精確去重
不同渠道來源的相同頁面識別及去重
小程序的頁面由不同渠道分發,如Feed、搜索、動態轉發等,不同分發渠道下的相同頁面URL上會有一定區別,而頁面內容本身是一樣的,我們因此建設了專門的策略來識別不同流量渠道下的相同頁面。以上頁面去重,目的均是提高資源的有效利用率。
2.1.3 業務挑戰
然而,隨著入駐百度智能小程序的開發者量和小程序量的迅速增長,小程序的頁面量更是從數十億激增到上百億;同時對於服務類業務的引入,對風險控制時效性的要求從天級提昇到小時級。當前的架構已不再能滿足業務增長對於線上風控的業務要求。
2.2 V2.0版巡檢調度方案
2.2.1 設計目標(優化方向)
V1.0架構檢測數據以離線數據為主,具有T+1的時間延遲,前一天暴露的風控問題在第二天才能發現,為了更快地發現暴露在線上的風控問題,减少線上問題的暴露時間,V2.0架構設計的最終目標為線上風險頁面暴露即發現。為了實現這一目標,送檢頁面以實時流數據為主,離線數據作為補充;另外,小程序頁面檢測需要抓取頁面內容,會對小程序服務端造成壓力,因此還要保證單一小程序頁面送檢的均勻性與單日限額的限制。具體的設計准則如下:
原則:實時優先、離線補充
紅線:不超過小程序抓取額度限定、抓取均勻,不能集中抓取同一小程序
產品需求:保證頁面檢測的高覆蓋率
限制:頁面抓取資源限制
2.2.2 頂層架構
演進後的V2.0巡檢策略頂層架構設計如下:
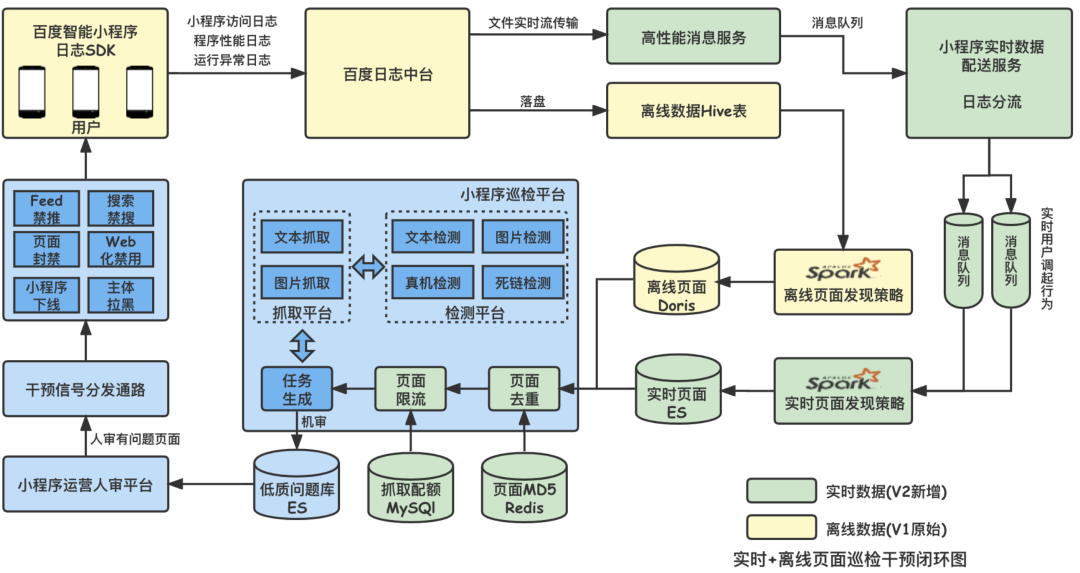
相較V1.0,V2.0引入了實時數據流,並對小程序的抓取配額做出了5分鐘一個窗口級別的更細粒度的控制。
2.2.3 V2.0巡檢調度策略拆解實現
實時巡檢整體實現方式如下圖所示,可以拆分為三個部分:實時頁面發現策略、離線頁面發現策略與頁面調度策略。實時頁面發現策略是相較於巡檢V1.0架構的新策略,直接接收實時流日志數據,根據一定策略篩選出用戶點擊的頁面,能够實現分鐘級的風控問題發現;離線頁面發現策略與巡檢V1.0架構類似,采用T-1的日志數據,作為實時數據的兜底,沒有全部采用實時數據是由於小程序的使用qps有波峰與波穀,在小程序使用波穀,頁面發現量會减少,導致頁面抓取與檢測能力沒有充分利用,此時需要離線數據做為補充;頁面調度策略將實時與離線策略聚合,實現了離線數據補充實時數據,頁面實時去重的功能,將頁面送抓取並送機審檢測。
2.2.3.1 離線頁面發現策略
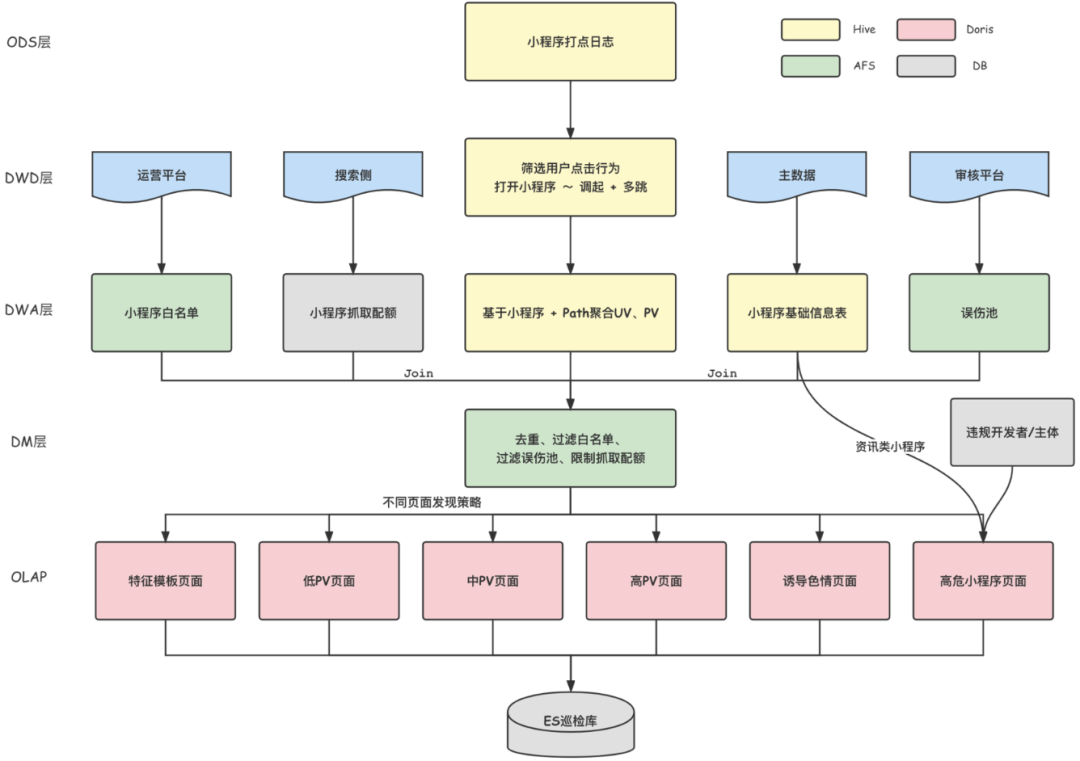
離線頁面發現策略,是利用前一日的用戶瀏覽小程序頁面的日志,統計出各頁面的PV,並經過誤傷池過濾、抓取配額限制等策略,將待巡檢的頁面與頁面的PV存入Doris中,供巡檢調度使用。
數據流轉如下圖所示,數據依次經過ODS層(Hive錶存儲小程序原始日志)、DWD層(Hive錶存儲用戶調起日志)、DWA層(Hive錶存儲各頁面PV)、DM層(Doris錶存儲待檢測頁面信息),數倉各層間的計算通過Spark實現。
2.2.3.2 實時頁面發現策略
實時頁面發現策略的數據源為小程序實時配送服務,小程序實時配送服務是小程序實時數倉的基礎,數據使用方在實時數據配送服務的管理端新增日志分流規則,就可以將符合條件的數據分流的指定的消息隊列(百度BigPipe)中,利用Spark、Flink或程序接收消息進行計算即可。實時數據服務整體架構如下圖所示,目前已實現秒極延遲。
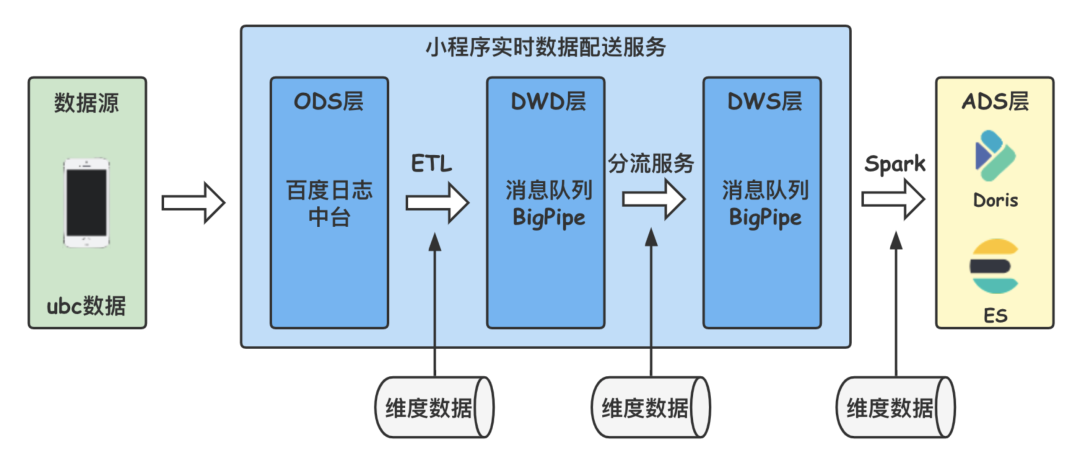
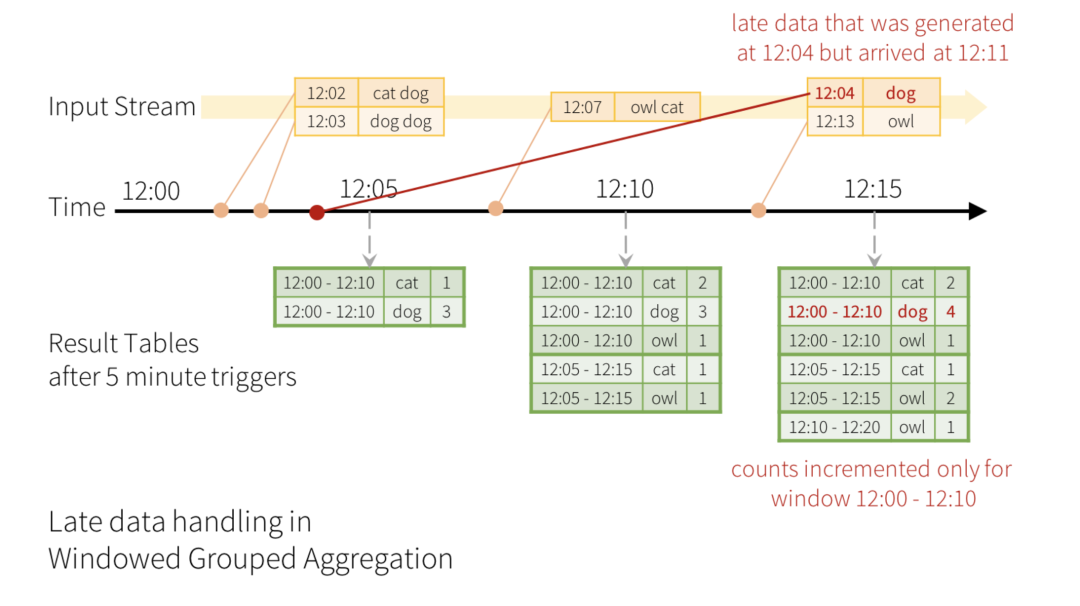
在小程序實時數據配送服務中配置篩選用戶調起小程序的日志分流規則,利用Structured Streaming接收對應的消息隊列Topic,首先提取日志中的關鍵信息,包括:小程序ID、頁面url、事件時間等。小程序每日有點擊的頁面達數億,檢測全部覆蓋所有頁面不現實,因此篩選出PV較高的頁面優先檢測,實時數據PV的計算需要一個時間區間,與Structured Streaming micro-batch對應,取時間區間為5min,Structured Streaming 的 windowSize 設置為5分鐘,滑動步長也設置為5分鐘,窗口之間不重疊,計算5分鐘內,每個頁面的PV。對於延遲過久的數據,需要通過watermark(水印)將其拋弃,取水印時間為15分鐘,即15分鐘前的數據將被過濾。數據輸出采用Append模式,每個窗口只輸出一次,輸出最終結果,避免單窗口內頁面重複送檢。具體窗口與水印的概念如下圖所示(本圖引用自Spark Structured Streaming官網,https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html)。
由於頁面內容抓取QPS有限,無法將全部頁面抓取送檢,對於窗口內PV較大的頁面全部送抓取,對於低PV頁面,由於頁面數過多,采用抽檢的方式,Structured Streaming不支持Limit語句,為了實現數據抽樣,給PV = 1的頁面一個0-9999的隨機數rand,篩選出rand < 100的頁面,即低PV頁面抽樣1%,最終將高PV頁面與抽樣後的低PV頁面union後輸出,保證送檢qps小於頁面抓取qps限制。
篩選出的頁面還需要經過一系列產品策略的限制:
部分小程序為免審小程序,將這些小程序的頁面過濾出去;
誤傷池是機審被召回,但人審複核無問題的頁面,過濾誤傷池可以大幅提昇檢測准確性;
大量的頁面抓取會對小程序造成服務端壓力,每個小程序有抓取配額限制。
頁面過濾時采用left join操作,將實時流與離線維度錶關聯,離線維度數據也在不斷地更新,需要保證維度數據的名稱不變,數據內容不斷更新,保證實時流在每一個窗口都可以拿到最新的維度數據。
最終產出的數據輸出到Elasticsearch中,若全部數據都寫在同一個索引下面,增删改都在這同一個索引下,索引下的數據量與日俱增,查詢與插入效率降低,並且删除曆史數據不方便,delete_by_query本身性能差,且非物理删除,不能起到釋放空間和提高性能的目的。這裏采用索引別名與按時間索引切分的方式,好處是删除曆史數據可以按曆史索引删除,方便操作,可以有效釋放空間,提高性能。ES索引切分需要依次創建索引別名,創建索引模板,創建包含日期的索引,制定並配置rollover規則,創建切分索引與删除舊索引的定時任務。
PUT /%3Conline-realtime-risk-page-index-%7Bnow%2FH%7BYYYY.MM.dd%7C%2B08%3A00%7D%7D-1%3E/{ "aliases": { "online-realtime-risk-page-index": { "is_write_index" : true } }}POST /online-realtime-risk-page-index/_rollover{ "conditions": { "max_age": "1d", //按天切分索引 "max_docs": 10000000, "max_size": "2gb" }}
2.2.3.3 頁面調度策略
經過前面兩部分介紹的離線和實時頁面發現策略,分別得到了待檢的離線頁面數據集和實時頁面數據集。下面將基於這兩個待檢集合來詳細介紹最終的頁面調度策略。
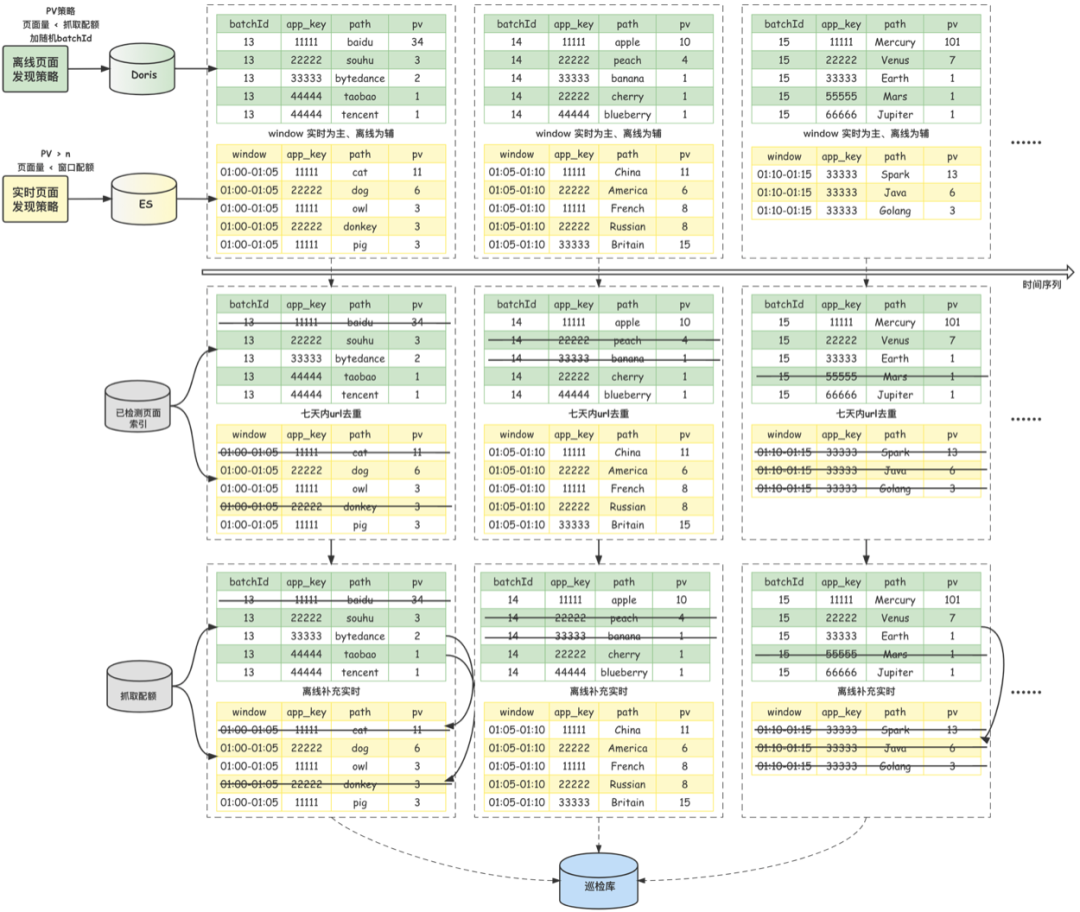
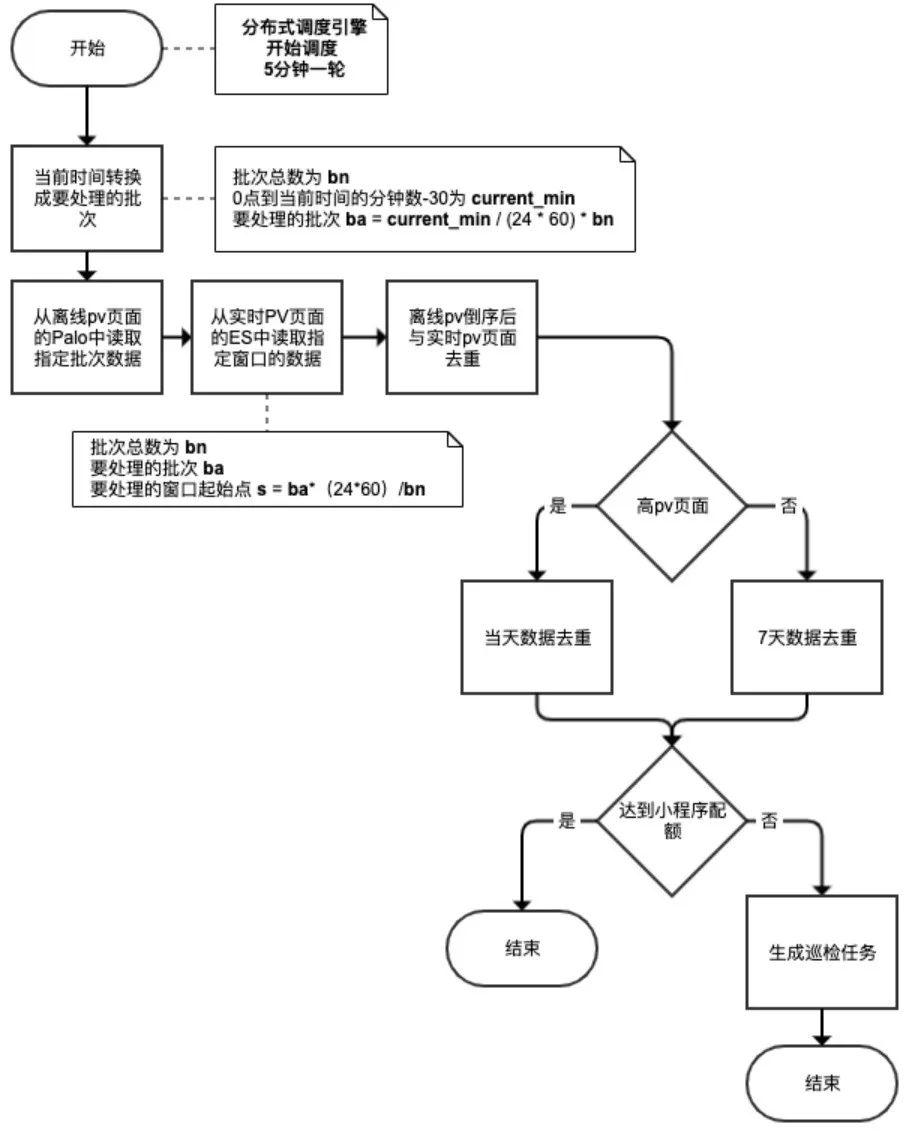
1、數據劃分,周期調度
對於離線數據集,使用【批次】來劃分多批數據集;對於實時數據集,使用【窗口】來劃分多批數據集。使用【定時任務】來周期性處理這些被劃分的數據集。將一天劃分為 bn 個批次,假設【定時任務】當前運行的時間所在當天的分鐘數為 currentMinutes,那麼,現在要處理的【離線數據】的【批次】 batch = currentMinutes * bn / (24 * 60)。對應地,現在要處理的【實時數據】的【窗口起點】 windowStart = batch * (24 * 60) / bn。考慮到實時數據處理的水印設置和定時任務的調度周期,currentMinutes並不是嚴格取當前的時間,而是由當前時間-30分鐘後得到。
2、實時優先,離線補充
再次圍繞系統資源的限制、對單個小程序抓取造成的壓力、離線和實時頁面集合間的補充等設計原則,在頁面調度單個周期內,如果沒有達到限額,會全部調度實時頁面進行檢測;如若實時頁面此時仍未能達到限額,那麼會使用離線頁面進行補充,以保證系統時刻滿負荷運行,充分均勻有效利用到資源。同時,這種調度方式也能保證實時和離線策略互備,當單個策略出現問題的時候,系統仍然可以通過另一個策略發現頁面並送檢,不至於空轉。此外,離線數據集中頁面會根據PV進行到倒排,使得點擊較多的離線頁面被檢測更優先檢。
3、頁面去重
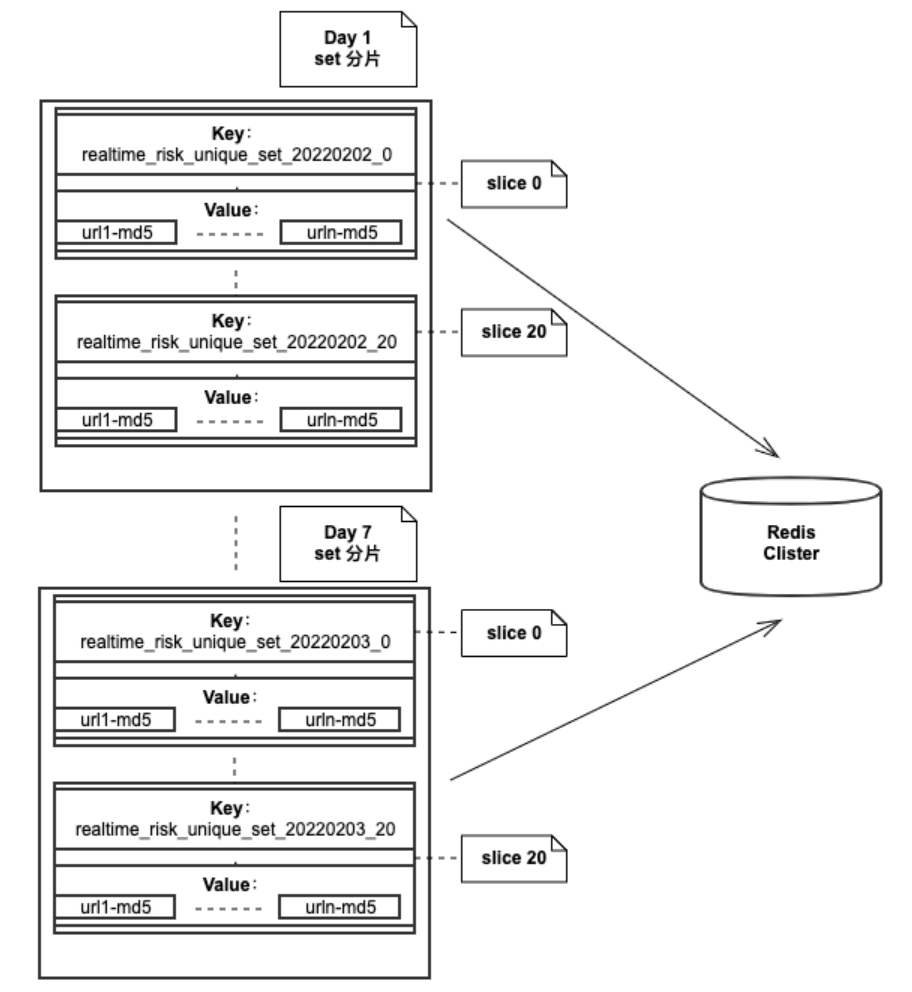
基於線上頁面的PV分布規律,為盡可能提高巡檢的PV覆蓋率,頁面調度策略中還增加了高 pv 頁面當天去重與中低PV頁面指定周期內去重的邏輯。存儲數據庫選型Redis,數據結構及頁面url對應的分片計算設計如下:
數據結構
集合,集合中存儲已經檢測頁面的URL轉換為16比特md5,單個集合存儲一天的數據量太大,因此將一天的數據分成多個分片,每一個分片是一個集合。如果將一天分比特100個分片,那麼一天就有100個集合。
url對應的分片計算
1、小程序url中字母轉int後相加得到數字x
2、x mod 分片數量得到 key
數據結構示意圖:
2.2.4 收益回顧
智能小程序巡檢平臺在不斷演進、優化的過程中,平臺能力得到極大的提昇:
每日巡檢的頁面數量已支持數千萬量,頁面覆蓋率得到極大提昇;
加入了基於實時數據的實時巡檢通路,將問題頁面的線上暴露時長大幅减小,問題發現達分鐘級,整理幹預鏈路由天級降低至小時級;
離線數據補充實時數據的調度策略,充分地利用了頁面抓取與頁面檢測資源,利用更少的資源,檢測更多的頁面;
最終建立起小程序質量保障體系,幫助更好地發現並處理線上問題,控制線上風險,降低線上低質占比,保障小程序的生態健康。
===
三、思考與展望
本文我們圍繞巡檢的業務目標和背景,重點介紹了小程序巡檢調度策略的演化曆程,足以見對線上質量的巡檢工作是需要不斷建設和磨練的。隨著業務的不斷發展,線上資源會更豐富,內容更加多樣性,頁面資源量還會保持持續增長,我們勢必會面對更大的挑戰。如何從海量頁面資源中高效、准確地召回線上風險問題,始終是巡檢調度策略的思考目標。我們會不斷地進行探索、優化,堅定不移地為不斷增長的智能小程序業務保駕護航。
推薦閱讀:
百度官方技術號「百度Geek說」上線啦!
技術幹貨 · 行業資訊 · 線上沙龍 · 行業大會
招聘信息 · 內推信息 · 技術書籍 · 百度周邊
歡迎各比特同學關注百度Geek說!
边栏推荐
- Explain NN in pytorch in simple terms CrossEntropyLoss
- Node collaboration and publishing
- Applet global style configuration window
- OpenGL - Lighting
- Unity skframework framework (24), avatar controller third person control
- TDengine ×英特尔边缘洞见软件包 加速传统行业的数字化转型
- [listening for an attribute in the array]
- Principle and performance analysis of lepton lossless compression
- Unity SKFramework框架(二十三)、MiniMap 小地图工具
- 一文详解图对比学习(GNN+CL)的一般流程和最新研究趋势
猜你喜欢
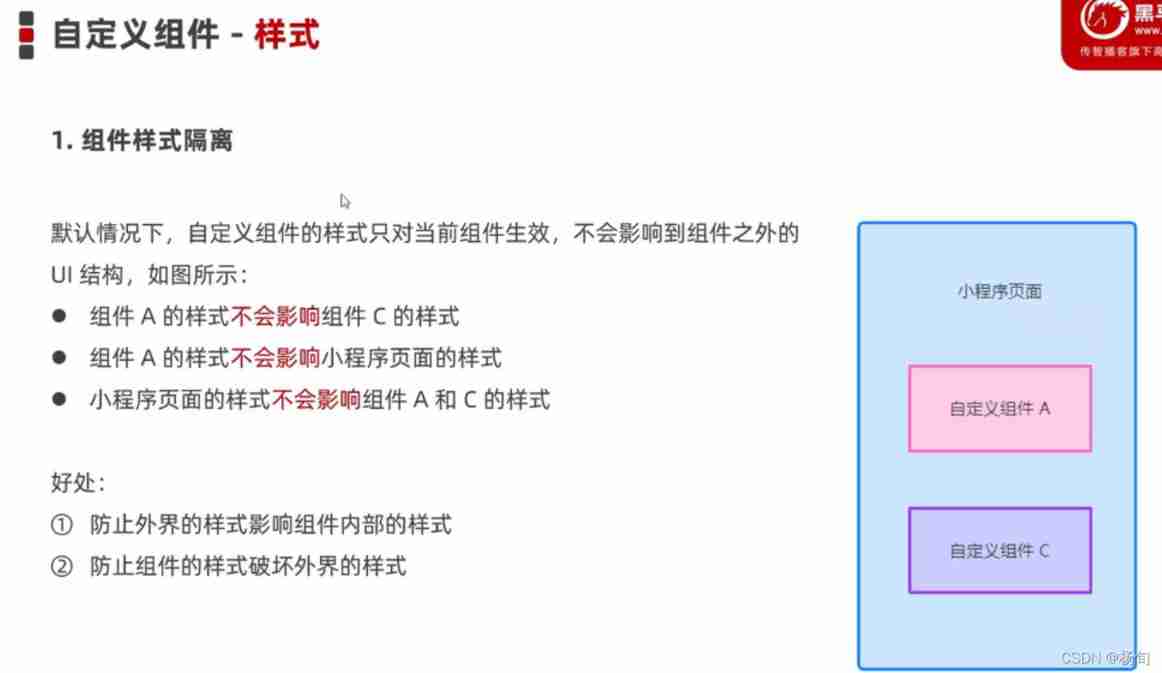
Applet customization component

LeetCode 556. 下一个更大元素 III
Node の MongoDB Driver

Hi Fun Summer, play SQL planner with starrocks!
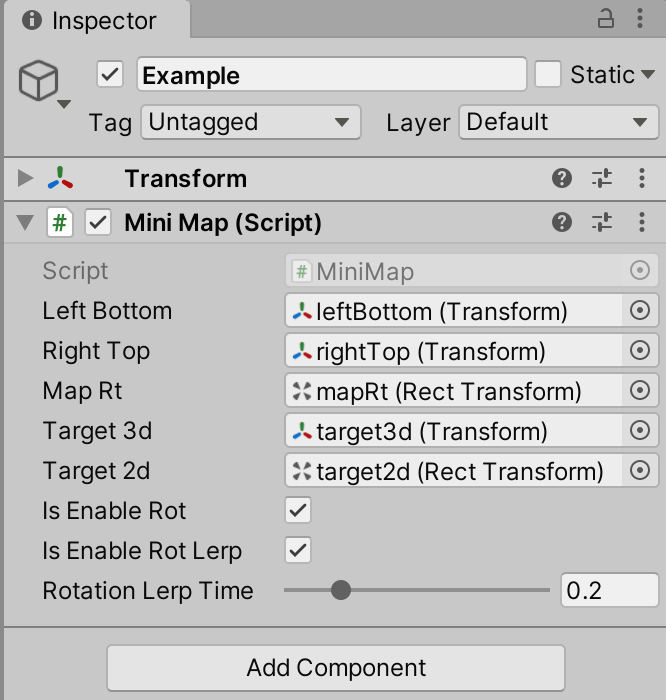
Unity skframework framework (XXIII), minimap small map tool

An article takes you into the world of cookies, sessions, and tokens

How do enterprises choose the appropriate three-level distribution system?
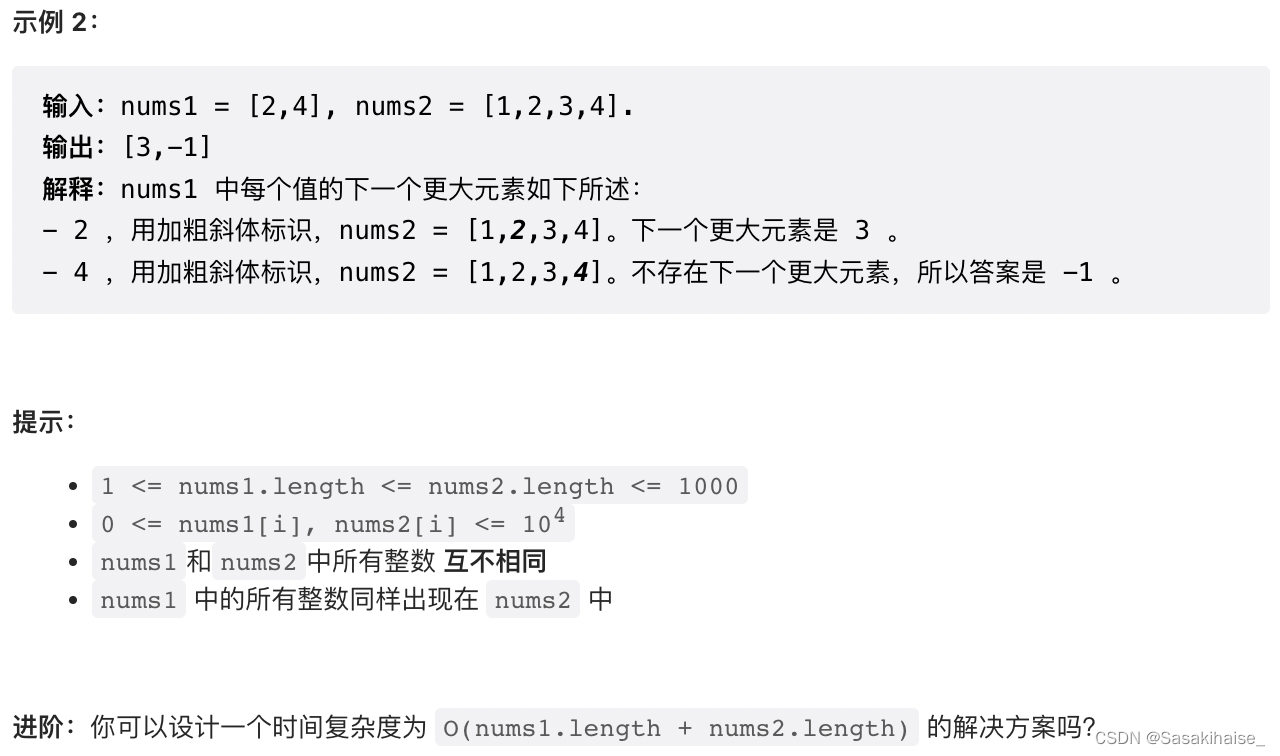
LeetCode 496. Next larger element I

7 月 2 日邀你来TD Hero 线上发布会
C语言-从键盘输入数组二维数组a,将a中3×5矩阵中第3列的元素左移到第0列,第3列以后的每列元素行依次左移,原来左边的各列依次绕到右边
随机推荐
Hosting environment API
一文详解图对比学习(GNN+CL)的一般流程和最新研究趋势
Figure neural network + comparative learning, where to go next?
揭秘百度智能测试在测试自动执行领域实践
Svg optimization by svgo
C form click event did not respond
LeetCode 31. 下一个排列
LeetCode 496. Next larger element I
基于模板配置的数据可视化平台
阿里十年测试带你走进APP测试的世界
OpenGL - Model Loading
Newton iterative method (solving nonlinear equations)
c语言指针深入理解
【两个对象合并成一个对象】
Community group buying has triggered heated discussion. How does this model work?
LeetCode 556. 下一个更大元素 III
Kotlin introductory notes (III) kotlin program logic control (if, when)
【组队 PK 赛】本周任务已开启 | 答题挑战,夯实商品详情知识
百度评论中台的设计与探索
小程序启动性能优化实践