当前位置:网站首页>Talking about label smoothing technology
Talking about label smoothing technology
2022-07-05 09:06:00 【aelum】
Author's brief introduction : Non Coban transcoding , We are constantly enriching our technology stack
️ Blog home page :https://raelum.blog.csdn.net
Main areas :NLP、RS、GNN
If this article helps you , Can pay attention to ️ + give the thumbs-up + Collection + Leaving a message. , This will be the biggest motivation for my creation

Catalog
One 、 from One-Hot To Label Smoothing
Consider the cross entropy loss of a single sample
H ( p , q ) = − ∑ i = 1 C p i log q i H(p,q)=-\sum_{i=1}^C p_i\log q_i H(p,q)=−i=1∑Cpilogqi
among C C C Represents the number of categories , p i p_i pi It's a real distribution ( namely target), q i q_i qi Is the predicted distribution ( That is, the output of neural network prediction).
If the real distribution adopts the traditional One-Hot vector , Then its component is not 0 0 0 namely 1 1 1. We might as well set a second k k k A place is 1 1 1, The rest are 0 0 0, At this point, the cross entropy loss becomes
H ( p , q ) = − log q k H(p,q)=-\log q_k H(p,q)=−logqk
It is not difficult to find some problems from the above expression :
- The relationship between real tags and other tags is ignored , Some useful knowledge cannot be learned ;
- One-Hot Tends to make the model overconfident (Overconfidence), It is easy to cause over fitting , This leads to the degradation of generalization performance ;
- Mislabeled samples ( namely
targeterror ) It is easier to affect the training of the model ; - One-Hot Yes “ ready to accept either course ” The sample characterization of is poor .
The way to alleviate these problems is to adopt Label Smoothing Technology , It is also a regularization technique , As follows :
p i : = { 1 − ϵ , i = k ϵ / ( C − 1 ) , i ≠ k p_i:= \begin{cases} 1-\epsilon,& i=k \\ \epsilon/(C-1),&i\neq k\\ \end{cases} pi:={ 1−ϵ,ϵ/(C−1),i=ki=k
among ϵ \epsilon ϵ Is a small positive number .
for example , Set original target by [ 0 , 0 , 1 , 0 , 0 , 0 ] [0,0,1,0,0,0] [0,0,1,0,0,0], take ϵ = 0.1 \epsilon=0.1 ϵ=0.1, Past the Label Smoothing after target Turn into [ 0.02 , 0.02 , 0.9 , 0.02 , 0.02 , 0.02 ] [0.02,0.02,0.9,0.02,0.02,0.02] [0.02,0.02,0.9,0.02,0.02,0.02].
The original One-Hot Vectors are often called Hard Target( or Hard Label), After the label is smoothed, it is usually called Soft Target( or Soft Label)
Two 、Label Smoothing Simple implementation of
import torch
def label_smoothing(label, eps):
label[label == 1] = 1 - eps
label[label == 0] = eps / (len(label) - 1)
return label
a = torch.tensor([0, 0, 1, 0, 0, 0], dtype=torch.float)
print(label_smoothing(a, 0.1))
# tensor([0.0200, 0.0200, 0.9000, 0.0200, 0.0200, 0.0200])
3、 ... and 、Label Smoothing Advantages and disadvantages
advantage :
- To some extent, it can alleviate the model Overconfidence The problem of , In addition, it also has certain anti noise ability ;
- Provides the relationship between categories in training data ( Data to enhance );
- It may enhance the generalization ability of the model to a certain extent .
shortcoming :
- Simply add random noise , It can't reflect the relationship between labels , Therefore, the improvement of the model is limited , There is even a risk of under fitting ;
- In some cases Soft Label It doesn't help us build better Neural Networks ( Not as good as Hard Label).
Four 、 When to use Label Smoothing?
- Huge data sets inevitably have noise ( That is, the marking is wrong ), In order to avoid the noise learned by the model, you can add Label Smoothing;
- For fuzzy case In general, we can introduce Label Smoothing( For example, in the cat and dog classification task , There may be some pictures that look like both dogs and cats );
- Prevention model Overconfidence.
边栏推荐
猜你喜欢
编辑器-vi、vim的使用

Halcon snap, get the area and position of coins
What is a firewall? Explanation of basic knowledge of firewall
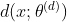
Generate confrontation network

Introduction Guide to stereo vision (2): key matrix (essential matrix, basic matrix, homography matrix)
2020 "Lenovo Cup" National College programming online Invitational Competition and the third Shanghai University of technology programming competition

RT-Thread内核快速入门,内核实现与应用开发学习随笔记
Introduction Guide to stereo vision (1): coordinate system and camera parameters

嗨 FUN 一夏,与 StarRocks 一起玩转 SQL Planner!

牛顿迭代法(解非线性方程)
随机推荐
容易混淆的基本概念 成员变量 局部变量 全局变量
信息與熵,你想知道的都在這裏了
[daiy4] jz32 print binary tree from top to bottom
Golang foundation - the time data inserted by golang into MySQL is inconsistent with the local time
Rebuild my 3D world [open source] [serialization-1]
Applet (use of NPM package)
浅谈Label Smoothing技术
Configuration and startup of kubedm series-02-kubelet
Mengxin summary of LIS (longest ascending subsequence) topics
One dimensional vector transpose point multiplication np dot
Golang foundation -- map, array and slice store different types of data
520 diamond Championship 7-4 7-7 solution
The location search property gets the login user name
Programming implementation of subscriber node of ROS learning 3 subscriber
ROS learning 4 custom message
js异步错误处理
皮尔森相关系数
Introduction Guide to stereo vision (4): DLT direct linear transformation of camera calibration [recommended collection]
C#图像差异对比:图像相减(指针法、高速)
Introduction Guide to stereo vision (5): dual camera calibration [no more collection, I charge ~]