当前位置:网站首页>2.非线性回归
2.非线性回归
2022-07-07 23:11:00 【booze-J】
代码运行平台为jupyter-notebook,文章中的代码块,也是按照jupyter-notebook中的划分顺序进行书写的,运行文章代码,直接分单元粘入到jupyter-notebook即可。
1.导入第三方库
import keras
import numpy as np
import matplotlib.pyplot as plt
# Sequential 按顺序构成的模型
from keras.models import Sequential
# Dense 全连接层
from keras.layers import Dense,Activation
from tensorflow.keras.optimizers import SGD
2.随机生成数据集
# 使用numpy生成200个随机点
# 在-0.5~0.5生成200个点
x_data = np.linspace(-0.5,0.5,200)
noise = np.random.normal(0,0.02,x_data.shape)
# y = x^2 + noise
y_data = np.square(x_data) + noise
# 显示随机点
plt.scatter(x_data,y_data)
plt.show()
运行结果: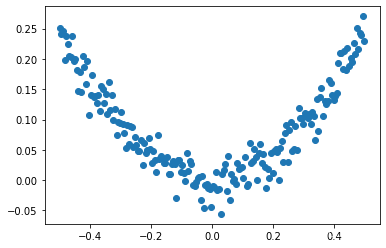
3.非线性回归
# 构建一个顺序模型
model = Sequential()
# 按shift+tab可以显示参数
# 1-10-1 输入一个神经层,10个隐藏层,输出一个神经层
model.add(Dense(units=10,input_dim=1))
# 添加激活函数 激活函数默认情况下是线性的,但是我们是非线性回归,所以要对激活函数进行修改
# 添加激活函数 方式一:直接添加activation参数
# model.add(Dense(units=10,input_dim=1,activation="relu"))
# 添加激活函数 方式二:直接添加Activation激活层
model.add(Activation("tanh"))
model.add(Dense(units=1,input_dim=10))
# model.add(Dense(units=1,input_dim=10,activation="relu"))
model.add(Activation("tanh"))
# 定义优化算法 提高学习率可以降低迭代次数
sgd = SGD(lr=0.3)
# sgd:Stochastic gradient descent , 随机梯度下降法 默认的sgd学习率表较小 所以需要的迭代次数就比较多 消耗的时间也就更多
# mse:Mean Squared Error , 均方误差
model.compile(optimizer=sgd,loss='mse')
# 训练3001个批次
for step in range(3001):
# 每次训练一个批次
cost = model.train_on_batch(x_data,y_data)
# 每500个batch打印一次cost
if step%500==0:
print("cost:",cost)
# 打印权值和批次值
W,b = model.layers[0].get_weights()
print("W:",W)
print("b:",b)
# x_data输入网络中得到预测值
y_pred = model.predict(x_data)
# 显示随机点
plt.scatter(x_data,y_data)
# 显示预测结果
plt.plot(x_data,y_pred,"r-",lw=3)
plt.show()
运行结果: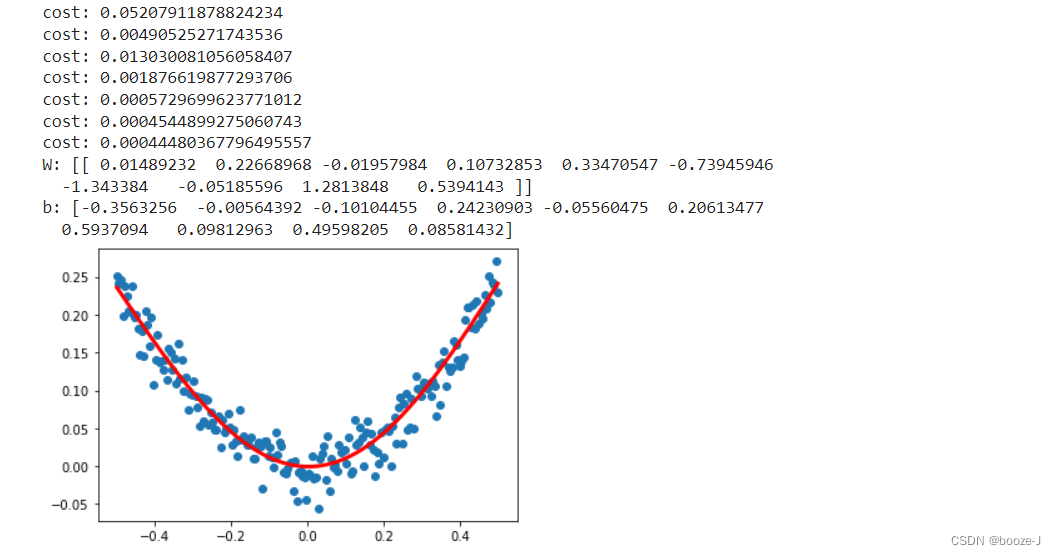
注意
- 1.进行非线性回归的要注意修改激活函数,因为激活函数默认情况下是线性的。
- 2.默认的sgd学习率表较小 所以需要的迭代次数就比较多 消耗的时间也就更多,所以可以自定义sgd学习率进行学习。
- 3.整体上代码和线性回归的代码非常类似,只是修改了一下数据集,网络模型,激活函数,以及优化器。
边栏推荐
- Analysis of 8 classic C language pointer written test questions
- 接口测试进阶接口脚本使用—apipost(预/后执行脚本)
- 华泰证券官方网站开户安全吗?
- 【GO记录】从零开始GO语言——用GO语言做一个示波器(一)GO语言基础
- How to insert highlighted code blocks in WPS and word
- Qt不同类之间建立信号槽,并传递参数
- FOFA-攻防挑战记录
- [go record] start go language from scratch -- make an oscilloscope with go language (I) go language foundation
- 12.RNN应用于手写数字识别
- Basic types of 100 questions for basic grammar of Niuke
猜你喜欢
新库上线 | CnOpenData中华老字号企业名录
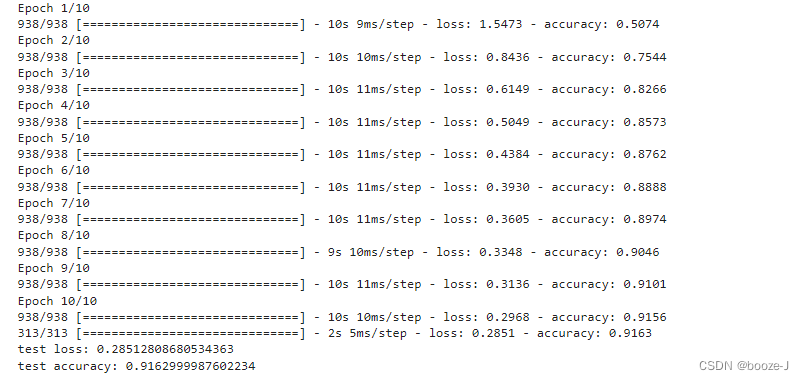
12. RNN is applied to handwritten digit recognition
国外众测之密码找回漏洞
Qt不同类之间建立信号槽,并传递参数
What does interface testing test?
Application practice | the efficiency of the data warehouse system has been comprehensively improved! Data warehouse construction based on Apache Doris in Tongcheng digital Department
Deep dive kotlin synergy (XXII): flow treatment
基于人脸识别实现课堂抬头率检测

《因果性Causality》教程,哥本哈根大学Jonas Peters讲授
【obs】官方是配置USE_GPU_PRIORITY 效果为TRUE的
随机推荐
[Yugong series] go teaching course 006 in July 2022 - automatic derivation of types and input and output
Reentrantlock fair lock source code Chapter 0
Codeforces Round #804 (Div. 2)(A~D)
13.模型的保存和載入
Interface test advanced interface script use - apipost (pre / post execution script)
Application practice | the efficiency of the data warehouse system has been comprehensively improved! Data warehouse construction based on Apache Doris in Tongcheng digital Department
German prime minister says Ukraine will not receive "NATO style" security guarantee
[necessary for R & D personnel] how to make your own dataset and display it.
基于卷积神经网络的恶意软件检测方法
What is load balancing? How does DNS achieve load balancing?
A brief history of information by James Gleick
新库上线 | 中国记者信息数据
Introduction to paddle - using lenet to realize image classification method II in MNIST
【obs】官方是配置USE_GPU_PRIORITY 效果为TRUE的
letcode43:字符串相乘
赞!idea 如何单窗口打开多个项目?
第一讲:链表中环的入口结点
Is it safe to open an account on the official website of Huatai Securities?
C # generics and performance comparison
RPA cloud computer, let RPA out of the box with unlimited computing power?