当前位置:网站首页>The charm of SQL optimization! From 30248s to 0.001s
The charm of SQL optimization! From 30248s to 0.001s
2022-07-07 07:54:00 【Hollis Chuang】
Source of the article :cnblogs.com/tangyanbo/p/4462734.html
author : The wind blows through the traceless blog
scene
The database used is mysql5.6, Here is a brief introduction to the scene .
The curriculum
create table Course(
c_id int PRIMARY KEY,
name varchar(10)
)data 100 strip .
Student list
create table Student(
id int PRIMARY KEY,
name varchar(10)
)data 70000 strip .
Student transcript
CREATE table SC(
sc_id int PRIMARY KEY,
s_id int,
c_id int,
score int
)data 70w strip .
Purpose of inquiry :
Search for Chinese test 100 Divided candidates .
Query statement :
select s.* from Student s
where s.s_id in (
select s_id
from SC sc
where sc.c_id = 0 and sc.score = 100 )execution time :30248.271s
dizzy , Why is it so slow , Let's check the query plan first :
EXPLAIN
select s.* from Student s
where s.s_id in (
select s_id
from SC sc
where sc.c_id = 0 and sc.score = 100 )
Found no index used ,type Is full of ALL, So the first thing to think about is to build an index , The fields that are indexed are, of course where Fields for conditions .
First give sc Tabular c_id and score Build an index .
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);Execute the above query statement again , Time is : 1.054s
fast 3w Many times , Greatly shorten the query time , It seems that index can greatly improve query efficiency , It is necessary to build an index , I often forget to build .
Index , When the amount of data is small, I don't feel at all , The optimization feels great .
however 1s It's still too long , Can it be optimized , Take a close look at the execution plan :

Check out the optimized sql:
SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
WHERE
< in_optimizer > (
`YSB`.`s`.`s_id` ,< EXISTS > (
SELECT
1
FROM
`YSB`.`SC` `sc`
WHERE
(
(`YSB`.`sc`.`c_id` = 0)
AND (`YSB`.`sc`.`score` = 100)
AND (
< CACHE > (`YSB`.`s`.`s_id`) = `YSB`.`sc`.`s_id`
)
)
)
)Add : Here are netizens asking how to view the optimized sentence .
The method is as follows :
Execute... In the command window
Yes type=all
As I thought before , The sql The order of execution should be to execute the subquery first .
select s_id
from SC sc
where sc.c_id = 0 and sc.score = 100Time consuming :0.001s
The results are as follows :
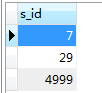
And then execute
select s.*
from Student s
where s.s_id in(7,29,5000)Time consuming :0.001s
That's pretty fast ,Mysql Actually, it's not to execute the inner query first , It's going to be sql Optimization becomes exists Clause , And there comes EPENDENT SUBQUERY,
mysql First, execute the outer query , Execute the inner query again , So it's going to cycle 70007*8 Time .
So use connection query instead ?
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100 In order to re analyze the connection query , Delete index temporarily first sc_c_id_index,sc_score_index .
The execution time is :0.057s
Efficiency has improved , Look at the implementation plan :

There's a situation of connected watches here , I wonder if it's for sc Tabular s_id Build an index
CREATE index sc_s_id_index on SC(s_id);
show index from SC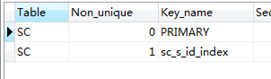
Executing connection query
Time : 1.076s, It's even longer , What's the cause of the ? View execution plan :

The optimized query statement is :
SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
JOIN `YSB`.`SC` `sc`
WHERE
(
(
`YSB`.`sc`.`s_id` = `YSB`.`s`.`s_id`
)
AND (`YSB`.`sc`.`score` = 100)
AND (`YSB`.`sc`.`c_id` = 0)
)It seems to be the connection query done first , Further where filter .
Go back to the execution plan :
This is the first thing to do where filter , And make a watch , The execution plan is not fixed , So let's look at the standard sql Execution order :

Normally it's first join Proceed again where Filter , But our situation here , If first join, There will be a 70w Data sent join Exercise , So first execute where .
Filtration is a wise solution , Now in order to exclude mysql Query optimization , I wrote an optimized sql .
SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_idI.e. execute first sc Filtration of the watch , Then connect the meter , The execution time is :0.054s .
And not built before s_id Index time is almost .
View execution plan :

Extract first sc Connect the watch again , So it's much more efficient , The problem now is to extract sc And then there's the scan table , Now it's clear that there's a need for indexes .
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);Execute query again :
SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_idThe execution time is :0.001s, This time is quite reliable , fast 50 times .
Implementation plan :

We'll see , Extract first sc, Connect the watch again , They all use indexes .
Then let's do it again sql.
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100execution time 0.001s
Implementation plan :

Here is mysql Optimized the query statement , First executed. where Filter , Then perform the connection operation , And they all use indexes .
2015-04-30 Daily supplement : Recently, I re imported some production data , Test found , Optimized a few days ago sql The execution efficiency has become low again .
Adjust the content to SC The table's data grows to 300W, Student scores are more discrete .
Look back at :
show index from SC

perform sql
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=81 and sc.score=84execution time :0.061s, This time is a little slow . Implementation plan :

It's used here intersect Union operation , That is to say, the results of two indexes retrieval at the same time are combined , Look at the fields score and c_id The differentiation of .
From a single field , The degree of differentiation is not very big , from SC Table to retrieve ,c_id=81 The result of the search is 70001,score=84 The result is 39425.
and c_id=81 and score=84 The result is 897, That is to say, the discrimination degree of these two fields is relatively high , Therefore, the efficiency of establishing joint index query .
Will be higher , From another point of view , The data in this table is 300w, There will be more , In terms of index storage , It's not a small number , As the amount of data increases .
increase , Indexes can't all be loaded into memory , Instead, read from the disk , The more indexes there are , The more expensive it is to read the disk , Therefore, according to the specific .
It is necessary to establish a multi column joint index for business situations , So let's try .
alter table SC drop index sc_c_id_index;
alter table SC drop index sc_score_index;
create index sc_c_id_score_index on SC(c_id,score);Execute the above query statement , The time consumed is :0.007s, This speed is still acceptable .
Implementation plan :

The optimization of this statement is now over .
summary
mysql Nested sub query efficiency is really low
It can be optimized to join queries
When connecting tables , You can use first where Conditions filter the table , Then make a watch connection
( although mysql Will optimize the join table statement )Build the right index , Set up multi column joint index if necessary
Learn to analyze sql Implementation plan ,mysql Would be right sql To optimize , So it's important to analyze the execution plan
Index optimization
The optimization of subquery is mentioned above , And how to index , And when multiple fields are indexed , The fields are individually indexed .
Later, we found that it is more efficient to establish a federated index , Especially in the large amount of data , When the differentiation of single column is not high .
Single index
The query statement is as follows :
select * from user_test_copy where sex = 2 and type = 2 and age = 10Indexes :
CREATE index user_test_index_sex on user_test_copy(sex);
CREATE index user_test_index_type on user_test_copy(type);
CREATE index user_test_index_age on user_test_copy(age);Respectively for sex,type,age The fields are indexed , The amount of data is 300w, Query time :0.415s Implementation plan :

Find out type=index_merge
This is a mysql Optimization of multiple single column indexes , Use... For the result set intersect Union operation
Multi column index
We can be here 3 Multiple column indexes on Columns , Will table copy One for testing
create index user_test_index_sex_type_age on user_test(sex,type,age);Query statement :
select * from user_test where sex = 2 and type = 2 and age = 10execution time :0.032s, fast 10 Many times , And the more distinguishable the multi column index is , The more speed you increase
Implementation plan :

Left most prefix
Multi column indexes also have the leftmost prefix feature :
Execute a statement :
select * from user_test where sex = 2
select * from user_test where sex = 2 and type = 2
select * from user_test where sex = 2 and age = 10Index will be used , The first field of the index sex To appear in where In the condition
Index overlay
That is, all the columns of the query are indexed , In this way, you don't need to go to disk to get the data of other columns when you get the result set , Return index data directly
Such as :
select sex,type,age from user_test where sex = 2 and type = 2 and age = 10execution time :0.003s
It's much faster than taking all the fields
Sort
select * from user_test where sex = 2 and type = 2 ORDER BY user_nameTime :0.139s
Building an index on the sorting field will improve the efficiency of sorting
create index user_name_index on user_test(user_name)Finally, attach some sql Tuning summary , There will be time for further study
Try to define the column type as a numeric type , And the length should be as short as possible , Such as primary key and foreign key , Type fields and so on
Create a single column index
Set up multi column joint index as needed
When a single column is filtered, there is a lot of data , So the efficiency of index will be lower , That is, the distinction between columns is low ,
So if you index multiple columns , So many columns are more distinguishable , There will be a significant increase in efficiency .Build coverage index according to business scenario
Query only the fields required by the business , If these fields are overwritten by the index , Will greatly improve the query efficiencyMultiple table join fields need to be indexed This can greatly improve the efficiency of table connection
where You need to index the condition fields
The sort field needs to be indexed
The group field needs to be indexed
Where Conditionally, don't use operands , To avoid index failure
End
Previous recommendation

HTTP 3.0 Give up completely TCP,TCP What did you do wrong ?

The real king of caching ,Google Guava Just a brother
There is Tao without skill , It can be done with skill ; No way with skill , Stop at surgery
Welcome to pay attention Java Road official account

Good article , I was watching ️
边栏推荐
- Pytest + allure + Jenkins Environment - - achèvement du remplissage de la fosse
- Redis technology leak detection and filling (II) - expired deletion strategy
- 2022 simulated examination question bank and online simulated examination of tea master (primary) examination questions
- C语言二叉树与建堆
- IPv4 exercises
- vus. Precautions for SSR requesting data in asyndata function
- pytest+allure+jenkins安装问题:pytest: error: unrecognized arguments: --alluredir
- json 数据展平pd.json_normalize
- Resource create package method
- [P2P] local packet capturing
猜你喜欢
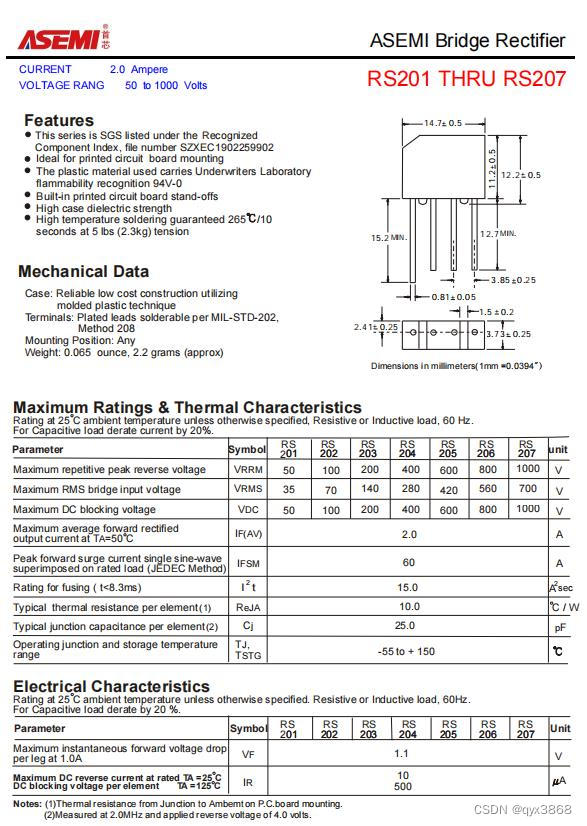
Asemi rectifier bridge rs210 parameters, rs210 specifications, rs210 package
![[Stanford Jiwang cs144 project] lab3: tcpsender](/img/82/5f99296764937e7d119b8ab22828fd.png)
[Stanford Jiwang cs144 project] lab3: tcpsender
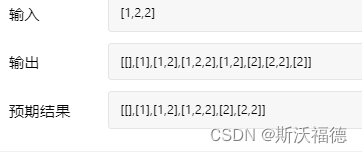
Leetcode 90: subset II
Resource create package method
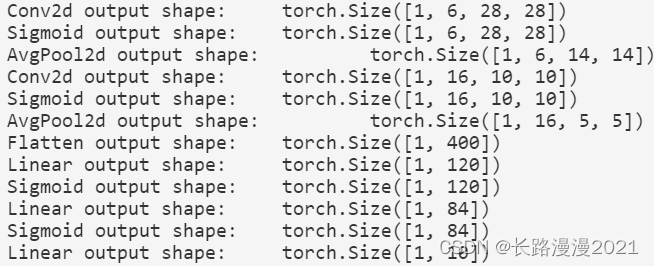
《动手学深度学习》(四) -- 卷积神经网络 CNN
【斯坦福计网CS144项目】Lab4: TCPConnection
![[SUCTF 2019]Game](/img/9c/362117a4bf3a1435ececa288112dfc.png)
[SUCTF 2019]Game

Detailed explanation of Kalman filter for motion state estimation

You Li takes you to talk about C language 6 (common keywords)

2022焊工(初级)判断题及在线模拟考试
随机推荐
Cnopendata American Golden Globe Award winning data
2022焊工(初级)判断题及在线模拟考试
微博发布案例
Button wizard script learning - about tmall grabbing red envelopes
Codeforces Global Round 19
Tianqing sends instructions to bypass the secondary verification
自定义类加载器加载网络Class
@component(““)
After the interview, the interviewer roast in the circle of friends
Most elements
CTF daily question day43 rsa5
C语言通信行程卡后台系统
解决:Could NOT find KF5 (missing: CoreAddons DBusAddons DocTools XmlGui)
leanote私有云笔记搭建
[UVM foundation] what is transaction
为什么要了解现货黄金走势?
微信小程序基本组件使用介绍
Operation suggestions for today's spot Silver
【VHDL 并行语句执行】
JS get all date or time stamps between two time stamps