当前位置:网站首页>SQL优化的魅力!从 30248s 到 0.001s
SQL优化的魅力!从 30248s 到 0.001s
2022-07-07 04:20:00 【Hollis Chuang】
文章来源:cnblogs.com/tangyanbo/p/4462734.html
作者: 风过无痕的博客
场景
用的数据库是mysql5.6,下面简单的介绍下场景。
课程表
create table Course(
c_id int PRIMARY KEY,
name varchar(10)
)数据100条。
学生表
create table Student(
id int PRIMARY KEY,
name varchar(10)
)数据70000条。
学生成绩表
CREATE table SC(
sc_id int PRIMARY KEY,
s_id int,
c_id int,
score int
)数据70w条。
查询目的:
查找语文考100分的考生。
查询语句:
select s.* from Student s
where s.s_id in (
select s_id
from SC sc
where sc.c_id = 0 and sc.score = 100 )执行时间:30248.271s
晕,为什么这么慢,先来查看下查询计划:
EXPLAIN
select s.* from Student s
where s.s_id in (
select s_id
from SC sc
where sc.c_id = 0 and sc.score = 100 )
发现没有用到索引,type全是ALL,那么首先想到的就是建立一个索引,建立索引的字段当然是在where条件的字段。
先给sc表的c_id和score建个索引。
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);再次执行上述查询语句,时间为: 1.054s
快了3w多倍,大大缩短了查询时间,看来索引能极大程度的提高查询效率,建索引很有必要,很多时候都忘记建。
索引了,数据量小的的时候压根没感觉,这优化的感觉挺爽。
但是1s的时间还是太长了,还能进行优化吗,仔细看执行计划:

查看优化后的sql:
SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
WHERE
< in_optimizer > (
`YSB`.`s`.`s_id` ,< EXISTS > (
SELECT
1
FROM
`YSB`.`SC` `sc`
WHERE
(
(`YSB`.`sc`.`c_id` = 0)
AND (`YSB`.`sc`.`score` = 100)
AND (
< CACHE > (`YSB`.`s`.`s_id`) = `YSB`.`sc`.`s_id`
)
)
)
)补充:这里有网友问怎么查看优化后的语句。
方法如下:
在命令窗口执行
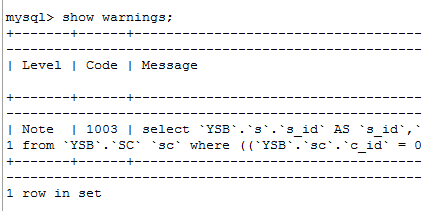
有type=all
按照我之前的想法,该sql的执行的顺序应该是先执行子查询。
select s_id
from SC sc
where sc.c_id = 0 and sc.score = 100耗时:0.001s
得到如下结果:
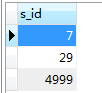
然后再执行
select s.*
from Student s
where s.s_id in(7,29,5000)耗时:0.001s
这样就是相当快了啊,Mysql竟然不是先执行里层的查询,而是将sql优化成了exists子句,并出现了EPENDENT SUBQUERY,
mysql是先执行外层查询,再执行里层的查询,这样就要循环70007*8次。
那么改用连接查询呢?
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100这里为了重新分析连接查询的情况,先暂时删除索引sc_c_id_index,sc_score_index 。
执行时间是:0.057s
效率有所提高,看看执行计划:

这里有连表的情况出现,我猜想是不是要给sc表的s_id建立个索引
CREATE index sc_s_id_index on SC(s_id);
show index from SC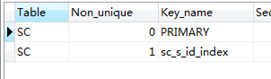
在执行连接查询
时间: 1.076s, 竟然时间还变长了,什么原因?查看执行计划:

优化后的查询语句为:
SELECT
`YSB`.`s`.`s_id` AS `s_id`,
`YSB`.`s`.`name` AS `name`
FROM
`YSB`.`Student` `s`
JOIN `YSB`.`SC` `sc`
WHERE
(
(
`YSB`.`sc`.`s_id` = `YSB`.`s`.`s_id`
)
AND (`YSB`.`sc`.`score` = 100)
AND (`YSB`.`sc`.`c_id` = 0)
)貌似是先做的连接查询,再进行的where条件过滤。
回到前面的执行计划:
这里是先做的where条件过滤,再做连表,执行计划还不是固定的,那么我们先看下标准的sql执行顺序:

正常情况下是先join再进行where过滤,但是我们这里的情况,如果先join,将会有70w条数据发送join做操,因此先执行where 。
过滤是明智方案,现在为了排除mysql的查询优化,我自己写一条优化后的sql 。
SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id即先执行sc表的过滤,再进行表连接,执行时间为:0.054s 。
和之前没有建s_id索引的时间差不多。
查看执行计划:

先提取sc再连表,这样效率就高多了,现在的问题是提取sc的时候出现了扫描表,那么现在可以明确需要建立相关索引。
CREATE index sc_c_id_index on SC(c_id);
CREATE index sc_score_index on SC(score);再执行查询:
SELECT
s.*
FROM
(
SELECT
*
FROM
SC sc
WHERE
sc.c_id = 0
AND sc.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id执行时间为:0.001s,这个时间相当靠谱,快了50倍。
执行计划:

我们会看到,先提取sc,再连表,都用到了索引。
那么再来执行下sql。
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=0 and sc.score=100执行时间0.001s
执行计划:

这里是mysql进行了查询语句优化,先执行了where过滤,再执行连接操作,且都用到了索引。
2015-04-30日补充:最近又重新导入一些生产数据,经测试发现,前几天优化完的sql执行效率又变低了。
调整内容为SC表的数据增长到300W,学生分数更为离散。
先回顾下:
show index from SC

执行sql
SELECT s.* from
Student s
INNER JOIN SC sc
on sc.s_id = s.s_id
where sc.c_id=81 and sc.score=84执行时间:0.061s,这个时间稍微慢了点。执行计划:

这里用到了intersect并集操作,即两个索引同时检索的结果再求并集,再看字段score和c_id的区分度。
单从一个字段看,区分度都不是很大,从SC表检索,c_id=81检索的结果是70001,score=84的结果是39425。
而c_id=81 and score=84 的结果是897,即这两个字段联合起来的区分度是比较高的,因此建立联合索引查询效率。
将会更高,从另外一个角度看,该表的数据是300w,以后会更多,就索引存储而言,都是不小的数目,随着数据量的。
增加,索引就不能全部加载到内存,而是要从磁盘去读取,这样索引的个数越多,读磁盘的开销就越大,因此根据具体。
业务情况建立多列的联合索引是必要的,那么我们来试试吧。
alter table SC drop index sc_c_id_index;
alter table SC drop index sc_score_index;
create index sc_c_id_score_index on SC(c_id,score);执行上述查询语句,消耗时间为:0.007s,这个速度还是可以接收的。
执行计划:

该语句的优化暂时告一段落。
总结
mysql嵌套子查询效率确实比较低
可以将其优化成连接查询
连接表时,可以先用where条件对表进行过滤,然后做表连接
(虽然mysql会对连表语句做优化)建立合适的索引,必要时建立多列联合索引
学会分析sql执行计划,mysql会对sql进行优化,所以分析执行计划很重要
索引优化
上面讲到子查询的优化,以及如何建立索引,而且在多个字段索引时,分别对字段建立了单个索引。
后面发现其实建立联合索引效率会更高,尤其是在数据量较大,单个列区分度不高的情况下。
单列索引
查询语句如下:
select * from user_test_copy where sex = 2 and type = 2 and age = 10索引:
CREATE index user_test_index_sex on user_test_copy(sex);
CREATE index user_test_index_type on user_test_copy(type);
CREATE index user_test_index_age on user_test_copy(age);分别对sex,type,age字段做了索引,数据量为300w,查询时间:0.415s执行计划:

发现 type=index_merge
这是mysql对多个单列索引的优化,对结果集采用intersect并集操作
多列索引
我们可以在这3个列上建立多列索引,将表copy一份以便做测试
create index user_test_index_sex_type_age on user_test(sex,type,age);查询语句:
select * from user_test where sex = 2 and type = 2 and age = 10执行时间:0.032s,快了10多倍,且多列索引的区分度越高,提高的速度也越多
执行计划:

最左前缀
多列索引还有最左前缀的特性:
执行一下语句:
select * from user_test where sex = 2
select * from user_test where sex = 2 and type = 2
select * from user_test where sex = 2 and age = 10都会使用到索引,即索引的第一个字段sex要出现在where条件中
索引覆盖
就是查询的列都建立了索引,这样在获取结果集的时候不用再去磁盘获取其它列的数据,直接返回索引数据即可
如:
select sex,type,age from user_test where sex = 2 and type = 2 and age = 10执行时间:0.003s
要比取所有字段快的多
排序
select * from user_test where sex = 2 and type = 2 ORDER BY user_name时间:0.139s
在排序字段上建立索引会提高排序的效率
create index user_name_index on user_test(user_name)最后附上一些sql调优的总结,以后有时间再深入研究
列类型尽量定义成数值类型,且长度尽可能短,如主键和外键,类型字段等等
建立单列索引
根据需要建立多列联合索引
当单个列过滤之后还有很多数据,那么索引的效率将会比较低,即列的区分度较低,
那么如果在多个列上建立索引,那么多个列的区分度就大多了,将会有显著的效率提高。根据业务场景建立覆盖索引
只查询业务需要的字段,如果这些字段被索引覆盖,将极大的提高查询效率多表连接的字段上需要建立索引 这样可以极大的提高表连接的效率
where条件字段上需要建立索引
排序字段上需要建立索引
分组字段上需要建立索引
Where条件上不要使用运算函数,以免索引失效
完
往期推荐


面试官灵魂拷问:为什么代码规范要求 SQL 语句不要过多的 join?
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号

好文章,我在看️
边栏推荐
- Detailed explanation of neo4j installation process
- 【obs】win-capture需要winrt
- 【Unity】物体做圆周运动的几个思路
- [experience sharing] how to expand the cloud service icon for Visio
- Mysql高低版本切换需要修改的配置5-8(此处以aicode为例)
- Six methods of flattening arrays with JS
- Bi she - college student part-time platform system based on SSM
- pytorch 参数初始化
- [performance pressure test] how to do a good job of performance pressure test?
- 二、并发、测试笔记 青训营笔记
猜你喜欢
图解GPT3的工作原理

Initial experience of teambiion network disk (Alibaba cloud network disk)

Mutual conversion between InputStream, int, shot, long and byte arrays

Calculus key and difficult points record part integral + trigonometric function integral
About some details of final, I have something to say - learn about final CSDN creation clock out from the memory model
Summary of customer value model (RFM) technology for data analysis
![[UTCTF2020]file header](/img/e3/818e2d531a06ab90de189055f634ad.png)
[UTCTF2020]file header
毕设-基于SSM大学生兼职平台系统
After 95, Alibaba P7 published the payroll: it's really fragrant to make up this
Interviewer: what development models do you know?
随机推荐
Simple example of ros2 planning system plansys2
BGP experiment (1)
【webrtc】m98 screen和window采集
JS plot flot application - simple curve
Write CPU yourself -- Chapter 9 -- learning notes
buuctf misc USB
【Liunx】进程控制和父子进程
Outsourcing for three years, abandoned
电商常规问题part1
[webrtc] M98 screen and window acquisition
The configuration that needs to be modified when switching between high and low versions of MySQL 5-8 (take aicode as an example here)
Mysql高低版本切换需要修改的配置5-8(此处以aicode为例)
即刻报名|飞桨黑客马拉松第三期等你挑战
二、并发、测试笔记 青训营笔记
【性能压测】如何做好性能压测?
外包干了四年,废了...
【obs】win-capture需要winrt
vus. Precautions for SSR requesting data in asyndata function
1、 Go knowledge check and remedy + practical course notes youth training camp notes
pytest+allure+jenkins安装问题:pytest: error: unrecognized arguments: --alluredir