当前位置:网站首页>[semantic segmentation] - multi-scale attention
[semantic segmentation] - multi-scale attention
2022-07-07 07:22:00 【Programmer base camp】
Reprinted from :https://mp.weixin.qq.com/s/r_U3XWeLjlMzyaNGLW7aXw
author :Andrew Tao and Karan Sapra
compile :ronghuaiyang
There is an important technology , Usually used for automatic driving 、 Medical imaging , Even zoom the virtual background :“ Semantic segmentation . This marks the pixels in the image as belonging to N One of the classes (N Is any number of classes ) The process of , These classes can be like cars 、 road 、 Things like people or trees . In terms of medical images , Categories correspond to different organs or anatomical structures .
NVIDIA Research Semantic segmentation is being studied , Because it is a widely applicable technology . We also believe that , Improved semantic segmentation techniques may also help improve many other intensive prediction tasks , Such as optical flow prediction ( Predict the motion of objects ), Image super-resolution , wait .
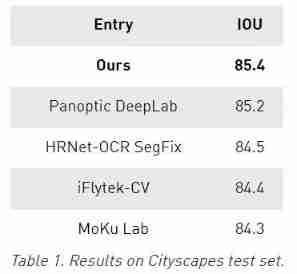
We develop a new method of semantic segmentation , On two common benchmarks :Cityscapes and Mapillary Vistas Up to SOTA Result ..IOU It's Cross and compare , It is a measure of the prediction accuracy of semantic segmentation .
stay Cityscapes in , This method achieves 85.4 IOU, Considering the closeness between these scores , This is a considerable improvement over other methods .
Predicted results 
Research process
In order to develop this new method , We considered which specific areas of the image need to be improved . chart 2 It shows the two biggest failure modes of the current semantic segmentation model : Detail error and class confusion .

chart 2, An example is given to illustrate the common error patterns of semantic segmentation due to scale . In the first line , Shrinking 0.5x In the image of , The thin mailboxes are divided inconsistently , But it is expanding 2.0x In the image of , Better prediction . In the second line , The bigger road / The isolation zone area is at a low resolution (0.5x) The lower segmentation effect is better
In this case , There are two problems : Details are confused with classes .
- The details of the mailbox in the first picture are 2 The best resolution is obtained in the prediction of multiple scales , But in 0.5 The resolution at multiple scales is very poor .
- Compared with median segmentation , stay 0.5x The rough prediction of roads under the scale is better than that under 2x Better under the scale , stay 2x There is class confusion under the scale .
Our solution can perform much better on these two problems , Class confusion rarely occurs , The prediction of details is also more smooth and consistent .
After identifying these error patterns , The team experimented with many different strategies , Including different network backbones ( for example ,WiderResnet-38、EfficientNet-B4、xcepase -71), And different partition decoders ( for example ,DeeperLab). We decided to adopt HRNet As the backbone of the network ,RMI As the main loss function .
HRNet It has been proved to be very suitable for computer vision tasks , Because it keeps the network better than before WiderResnet38 high 2 Multiple resolution representation .RMI Losses provide a way to obtain structural losses without resorting to things like conditional random fields .HRNet and RMI Loss can help solve the confusion of details and classes .
To further address the main error patterns , We have innovated two methods : Multiscale attention and automatic tagging .
Multiscale attention
In the computer vision model , Usually, the method of multi-scale reasoning is used to obtain the best result . Multiscale images run in the network , And combine the results using average pooling .
Use average pooling as a combination strategy , Regard all dimensions as equally important . However , Fine details are usually best predicted at higher scales , Large objects are better predicted at lower scales , On a lower scale , The receptive field of the network can better understand the scene . This is the same as the previous article ,
Learning how to combine multi-scale prediction at the pixel level can help solve this problem . There has been research on this strategy before ,Chen Etc. Attention to Scale It's the closest . In this method , Learn all scales of attention at the same time . We call it explicit method , As shown in the figure below .
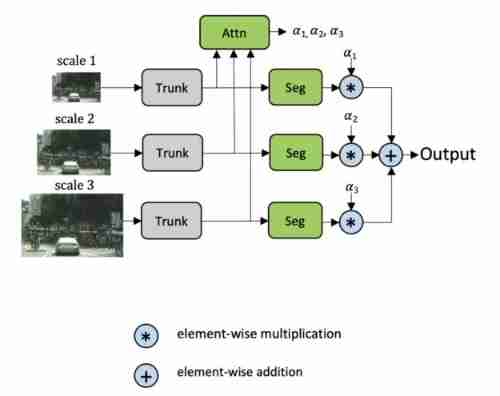
chart 3,Chen Their explicit method is to learn a set of fixed scale intensive attention mask, Combine them to form the final semantic prediction .
suffer Chen Method inspiration , We propose a multi-scale attention model , The model also learned to predict a dense mask, So as to combine MULTI-SCALE PREDICTION . But in this method , We learned a relative attention mask, It is used to pay attention between one scale and the next higher scale , Pictured 4 Shown . We call it hierarchical method .
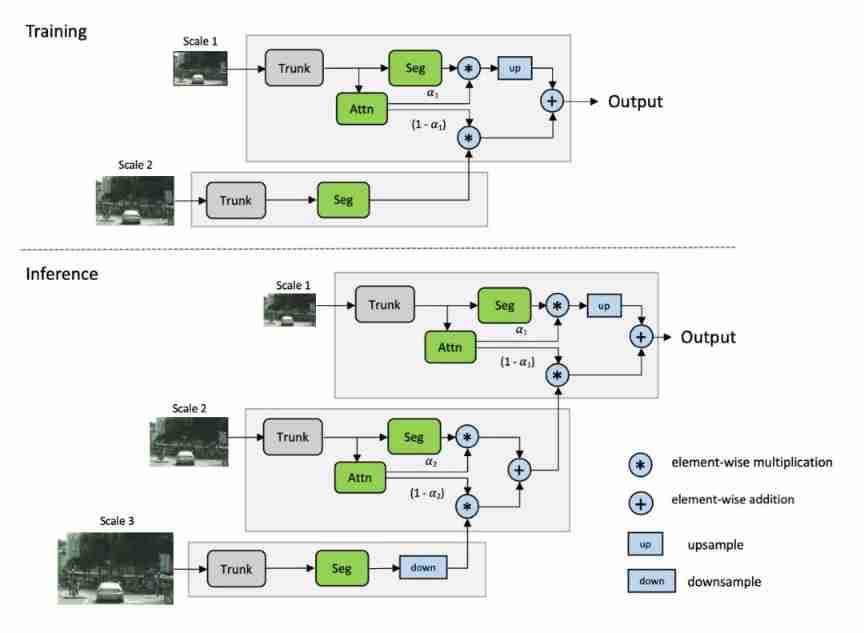
chart 4, Our hierarchical multiscale attention method . Upper figure : In the process of training , Our model learned to predict the attention between two adjacent scale pairs . The figure below : Reasoning is in a chain / Complete in a hierarchical way , In order to combine multiple prediction scales . Low scale attention determines the contribution of the next higher scale .
The main benefits of this method are as follows :
- Theoretical training cost ratio Chen The method reduces about 4x.
- Training is only carried out on a paired scale , Reasoning is flexible , It can be carried out on any number of scales .
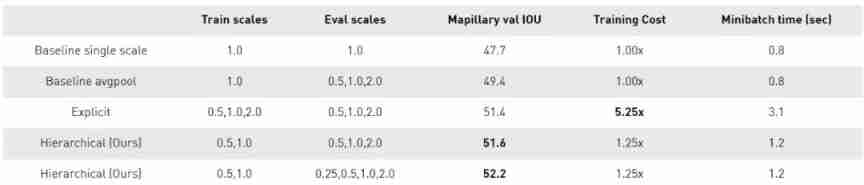
surface 3, Hierarchical multi-scale attention method and Mapillary Comparison of other methods on the validation set . The network structure is DeepLab V3+ and ResNet-50 The trunk . Evaluation scale : Scale for multi-scale evaluation .FLOPS: The relative of network for training flops. This method obtains the best verification set score , But compared with the explicit method , The amount of calculation is only medium .
chart 5 Some examples of our method are shown , And learned attention mask. For the details of the mailbox in the left picture , We pay little attention to 0.5x The forecast , But yes. 2.0x The prediction of scale is very concerned . contrary , For the very large road in the image on the right / Isolation zone area , Attention mechanisms learn to make the best use of lower scales (0.5x), And less use of the wrong 2.0x forecast .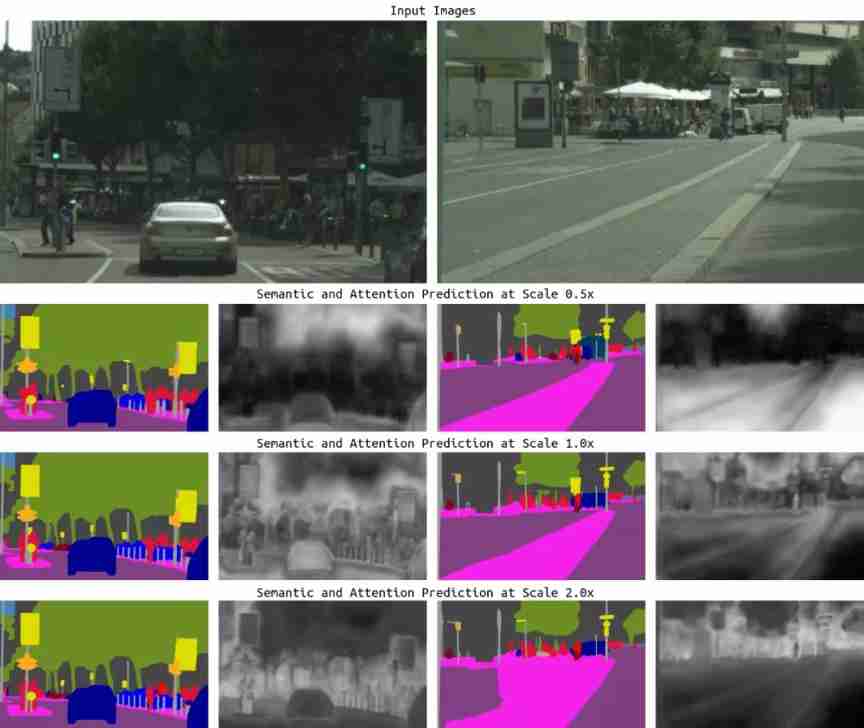
chart 5, Semantic and attention prediction of two different scenarios . The scene on the left illustrates a fine detail , The scene on the right illustrates a large area segmentation problem . White indicates a higher value ( near 1.0). The sum of attention values of a given pixel on all scales is 1.0. Left : The small mailbox beside the road is 2 Get the best resolution at a scale of times , Attention has successfully focused on this scale and not on other scales , This can be done from 2 It is proved in the white of the mailbox in the double attention image . Right picture : Big road / The isolation zone area is 0.5x The prediction effect under the scale is the best , And the attention of this area has indeed successfully focused on 0.5x On the scale .
Automatic marking
A common method to improve the results of semantic segmentation of urban landscape is to use a large number of coarse labeled data . This data is about the baseline fine annotation data 7 times . In the past Cityscapes Upper SOTA Method will use bold labels , Or use rough labeled data to pre train the network , Or mix it with fine-grained data .
However , Rough labeling is a challenge , Because they are noisy and inaccurate .ground truth The thick label is shown in the figure 6 As shown in the for “ Original thick label ”.

chart 6, Examples of automatic generation of coarse image labels . Automatically generated thick labels ( Right ) Provides more than the original ground truth Thick label ( in ) Finer label details . This finer label improves the distribution of labels , Because now small and large objects have representation , Not only on major big items .
Inspired by recent work , We will use automatic annotation as a method , To produce richer labels , To fill in ground truth The label of the thick label is blank . The automatic labels we generated show better details than the baseline thick labels , Pictured 6 Shown . We think , By filling the data distribution gap of long tailed classes , This helps to generalize .
Use the naive method of automatic marking , For example, use multi class probability from teacher network to guide students , It will cost a lot of disk space . by 20,000 Zhang straddle 19 Category 、 The resolution is 1920×1080 It takes about 2tb Storage space . The biggest impact of such a big price will be to reduce the training performance .
We use the hard threshold method instead of the soft threshold method to reduce the space occupied by the generated tag from 2TB Greatly reduced to 600mb. In this method , Teachers predict probability > 0.5 It works , A prediction with a lower probability is considered “ Ignore ” class . surface 4 It shows the benefits of adding coarse data to fine data and using the fused data set to train new students .
surface 4, The baseline method shown here uses HRNet-OCR As the backbone and our multi-scale attention method . We compared the two models : use ground truth Fine label + ground truth Rough label training to ground truth Fine label + auto- Thick label ( Our approach ). The method of using automatic coarsening labels improves the baseline 0.9 Of IOU.
chart 7, Examples of automatic generation of coarse image labels
边栏推荐
- Four goals for the construction of intelligent safety risk management and control platform for hazardous chemical enterprises in Chemical Industry Park
- 2018 Jiangsu Vocational College skills competition vocational group "information security management and evaluation" competition assignment
- Implementation of AVL tree
- Tujia, muniao, meituan... Home stay summer war will start
- 詳解機器翻譯任務中的BLEU
- 【mysqld】Can't create/write to file
- Modify the jupyter notebook file path
- 外包干了四年,废了...
- "Xiaodeng in operation and maintenance" meets the compliance requirements of gdpr
- Several important steps to light up the display
猜你喜欢
抽絲剝繭C語言(高階)指針的進階

$parent(获取父组件) 和 $root(获取根组件)
Sqlmap tutorial (IV) practical skills three: bypass the firewall
LC interview question 02.07 Linked list intersection & lc142 Circular linked list II
面试官:你都了解哪些开发模型?
freeswitch拨打分机号源代码跟踪
IP address
组件的嵌套和拆分
Release notes of JMeter version 5.5
Advanced practice of C language (high level) pointer
随机推荐
Example of Pushlet using handle of Pushlet
How can brand e-commerce grow against the trend? See the future here!
freeswitch拨打分机号源代码跟踪
Stack Title: nesting depth of valid parentheses
我理想的软件测试人员发展状态
IP address
Abnova circulating tumor DNA whole blood isolation, genomic DNA extraction and analysis
Use of completable future
Blue Bridge Cup Netizen age (violence)
Lvs+kept (DR mode) learning notes
Software acceptance test
Fast quantitative, abbkine protein quantitative kit BCA method is coming!
Communication between non parent and child components
About binary cannot express decimals accurately
Pass child component to parent component
Hidden Markov model (HMM) learning notes
Exception of DB2 getting table information: caused by: com ibm. db2.jcc. am. SqlException: [jcc][t4][1065][12306][4.25.13]
A slow SQL drags the whole system down
After the promotion, sales volume and flow are both. Is it really easy to relax?
Test of transform parameters of impdp