当前位置:网站首页>抽丝剥茧C语言(高阶)数据的储存+练习
抽丝剥茧C语言(高阶)数据的储存+练习
2022-07-07 03:31:00 【ℳℓ白ℳℓ夜ℳℓ】
深度剖析数据在内存中的存储
导语
数据类型的变量是如何储存到内存中的?正反补码又是什么?
本章会详细讲解数据的储存。
本章用32位平台
1. 数据类型介绍
前面我们已经学习了基本的内置类型:
char //字符数据类型
short //短整型
int //整形
long //长整型
long long //更长的整形
float //单精度浮点数
double //双精度浮点数
//C语言有没有字符串类型?
以及他们所占存储空间的大小。
类型的意义:
- 使用这个类型开辟内存空间的大小(大小决定了使用范围)。
- 如何看待内存空间的视角。
1.1 类型的基本归类
整形家族:
char //因为char类型储存的是ASCII码值,所以也属于整形家族
unsigned char
signed char
short
unsigned short [int]
signed short [int]
int
unsigned int
signed int
long
unsigned long [int]
signed long [int]
浮点数家族:
float
double
构造类型:
数组类型
结构体类型 struct
枚举类型 enum
联合类型 union
指针类型:
int*pi;
char* pc;
float* pf;
void* pv;
空类型:
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型.
2. 整形在内存中的存储
我们之前讲过一个变量的创建是要在内存中开辟空间的。空间的大小是根据不同的类型而决定的。
数据在所开辟内存中到底是如何存储的?
比如:
int a = 20;
int b = -10;
我们知道为 a 分配四个字节的空间。
那如何存储?
下来了解下面的概念:
2.1 原码、反码、补码
计算机中的整数有三种2进制表示方法,即原码、反码和补码。
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位。
正数的原、反、补码都相同。
负整数的三种表示方法各不相同。
原码
直接将数值按照正负数的形式翻译成二进制就可以得到原码。
反码
将原码的符号位不变,其他位依次按位取反就可以得到反码。
补码//内存中储存的值
反码+1就得到补码。
对于整形来说:数据存放内存中其实存放的是补码。
为什么呢?
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;
同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
我们举个例子:
int a=1;
int c=a-1;
上面说了,CPU只能处理加法,也就是说c=a+(-1),我们来用二进制的角度来看。
a的原码是
00000000000000000000000000000001 //正数的原反补相同
-1的原码是
10000000000000000000000000000001 //原码
11111111111111111111111111111110 //反码
11111111111111111111111111111111 //补码
如果按照CPU的方法,a的原码和-1的原码相加发现:
10000000000000000000000000000010
但如果有了补码,结果如下:

我们看看在内存中的存储: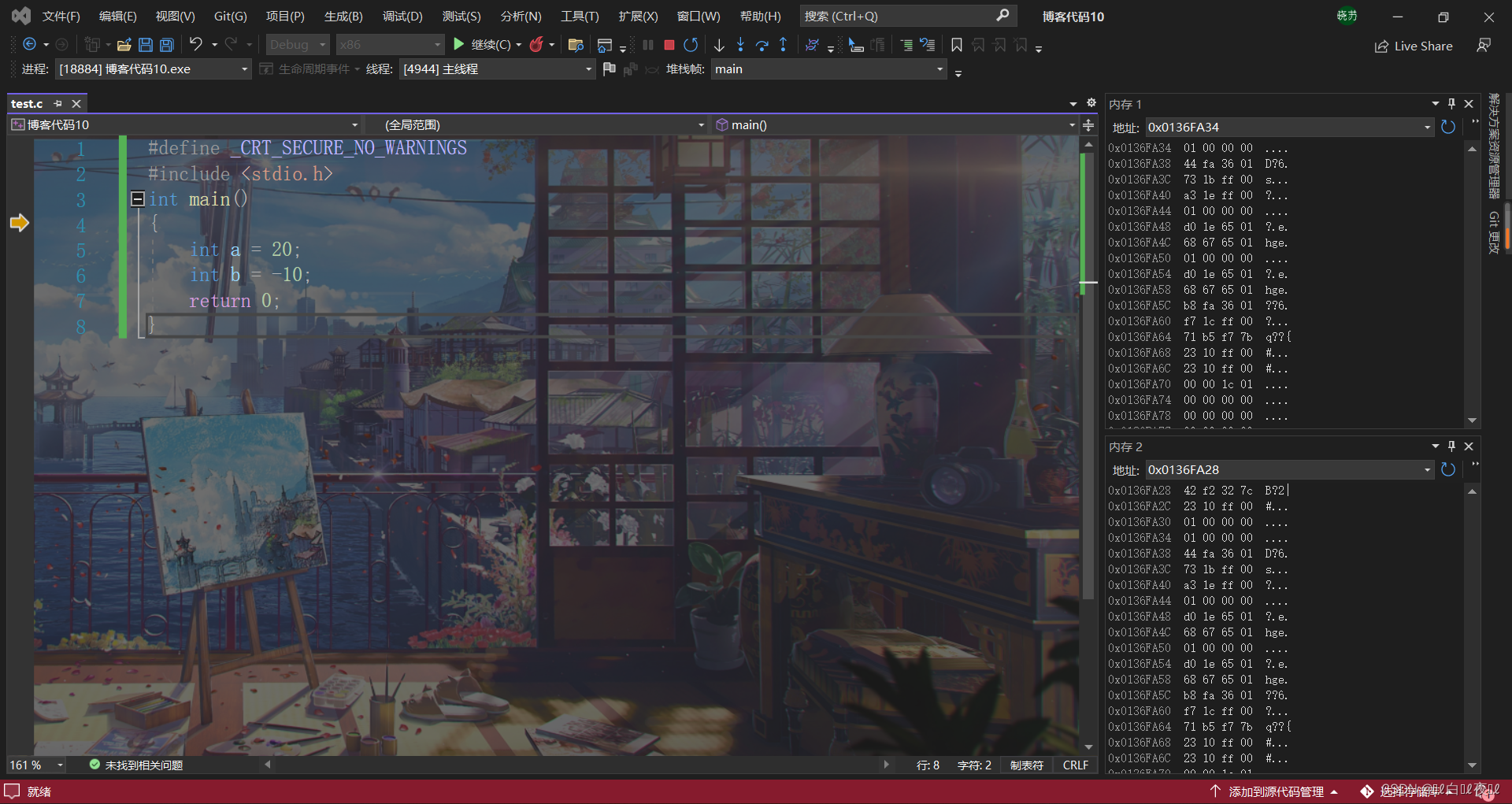
我们可以看到对于a和b分别存储的是补码。但是我们发现顺序有点不对劲。
这是又为什么?
2.2 大小端介绍
什么是大端小端:
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中。
内存中储存的值是用十六进制来表示,至于为什么不用二进制表示,因为二进制太长了,而且不好看,但是内存中实际储存的还是二进制。
我们用0x11223344来举例:
11是数据的高位,44是数据的低位
为什么有大端和小端:
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为高字节, 0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
百度2015年系统工程师笔试题:
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。
首先考虑这个代码应该实现的逻辑:
我们可以创建一个变量为1,然后取地址,强制类型转换为char类型,因为取地址取的是第一个字节的地址,所以我们打印出来第一个字节里面的里面的值看是1还是0。
参考代码:
#include <stdio.h>
int check_sys()
{
int i = 1;
return (*(char*)&i);
}
int main()
{
int ret = check_sys();
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
代码的运行结果是:
我电脑的硬件是小端储存方式。
练习
下面的这些代码,如果不经过简单的思考,输出的内容会让你诧异。
下面程序输出什么?
//代码1
#include <stdio.h>
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d,b=%d,c=%d", a, b, c);
return 0;
}
代码的运行结果如下: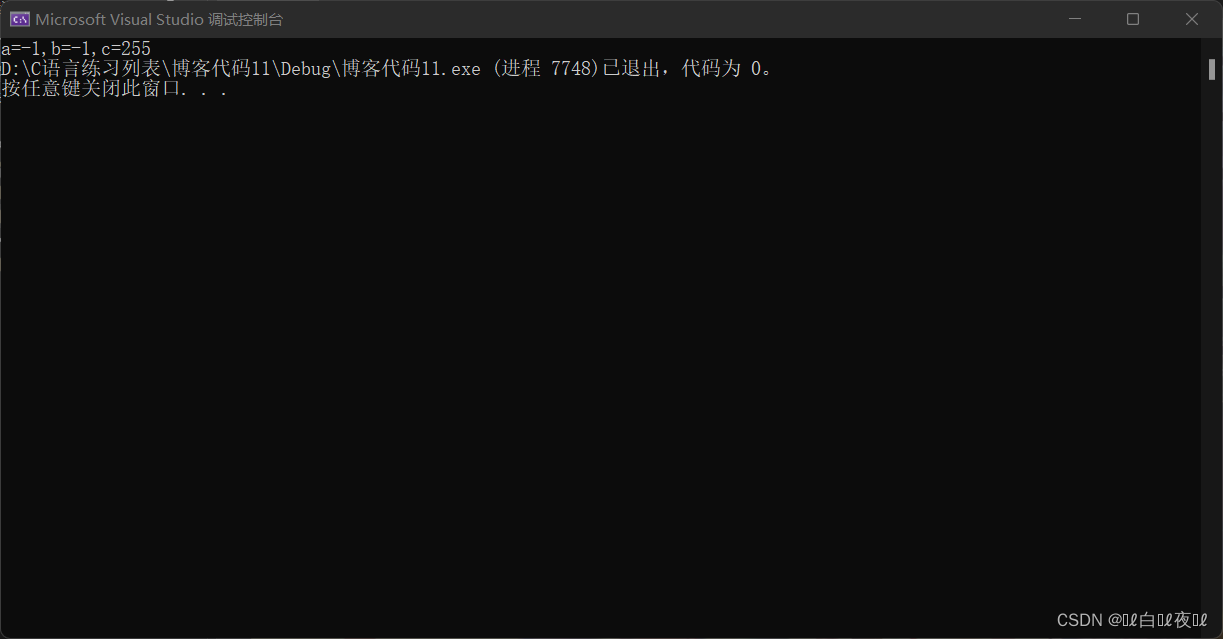
-1的补码是
11111111111111111111111111111111
储存进入a中,因为是char类型,所以这里会截断,也就是说取二进制的后八位。
储存进入b中,因为是signed char(有符号的char类型),和上面的char类型一样。
储存进入c中,因为是unsigned char(无符号的char类型),也就是说没有符号位。
我们打印的时候使用%d,需要整形提升,a和b是有符号类型,所以整型提升是左边补1,最后和-1的补码是一样的。
然而c是无符号类型,左边补0,补全之后的补码是这样的:
00000000000000000000000011111111
所以打印出来的才是255。
//代码2
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n", a);
return 0;
}
代码的运行结果如下: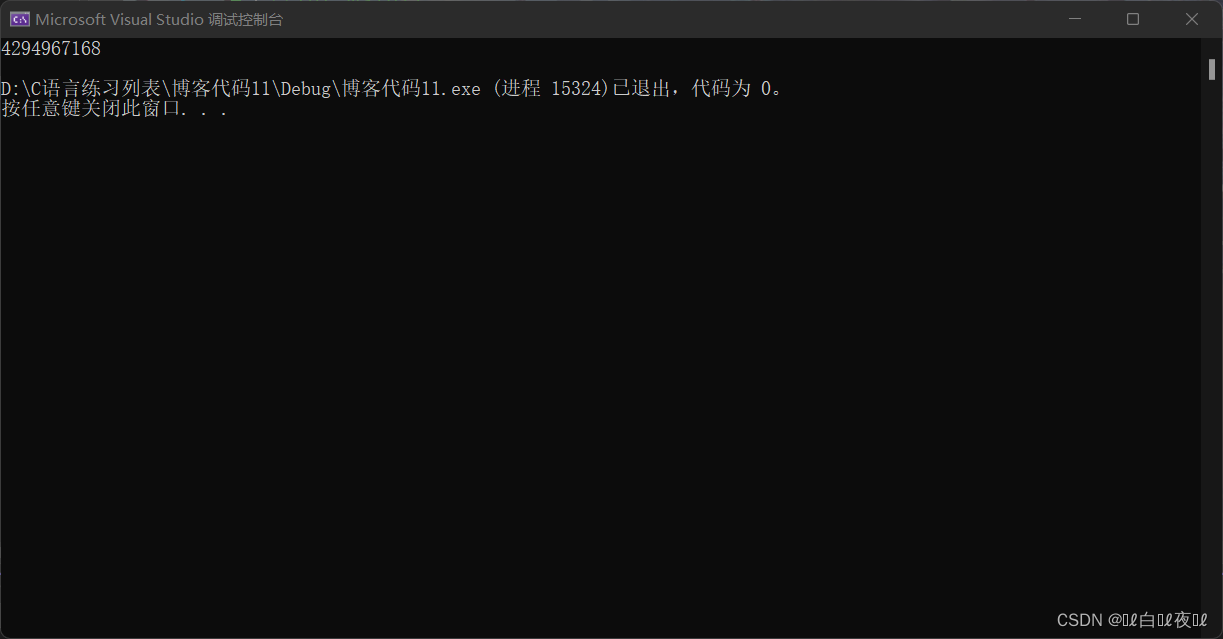
-128的补码是:
11111111111111111111111110000000
储存进入char类型的a中要截断,10000000,这是有符号位,我们打印的是无符号整形,所以要整型提升,变成这个样子。
11111111111111111111111110000000
因为是无符号整型,补码等于原码,结果就是上面很大的那个数了。
//代码3
#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n", a);
return 0;
}
这段代码结果和上面一样,只不过128的补码是
00000000000000000000000010000000。
//代码4
#include <stdio.h>
int main()
{
int i = -20;
unsigned int j = 10;
printf("%d\n", i + j);
//按照补码的形式进行运算,最后格式化成为有符号整数
return 0;
}
代码运行结果: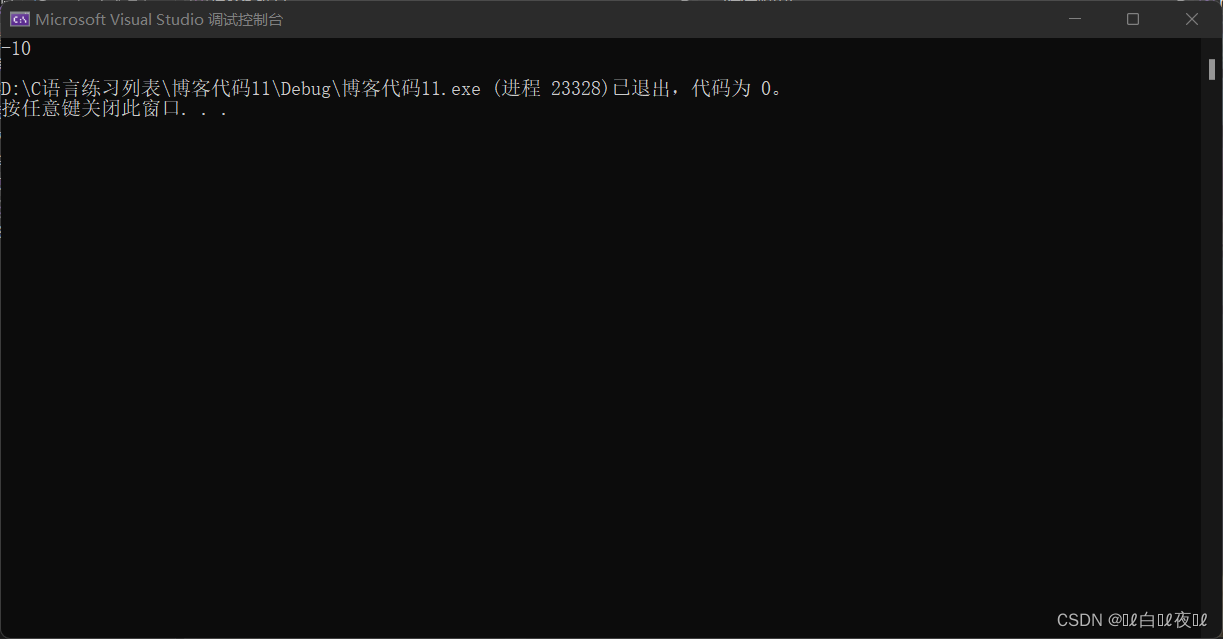
变量 i 的补码是:
11111111111111111111111111101100
变量 j 的补码是:
00000000000000000000000000001010
i+j的补码是:
i+j的补码变成原码是
10000000000000000000000000001010
最后以%d方式打印。
//代码5
#include <stdio.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
}
return 0;
}
这段代码打印出来的结果是死循环。
因为 i 是unsigned int类型,无论怎么样都是正数,所以会死循环。
//代码6
#include <stdio.h>
#include <string.h>
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
这段代码的输出结果是: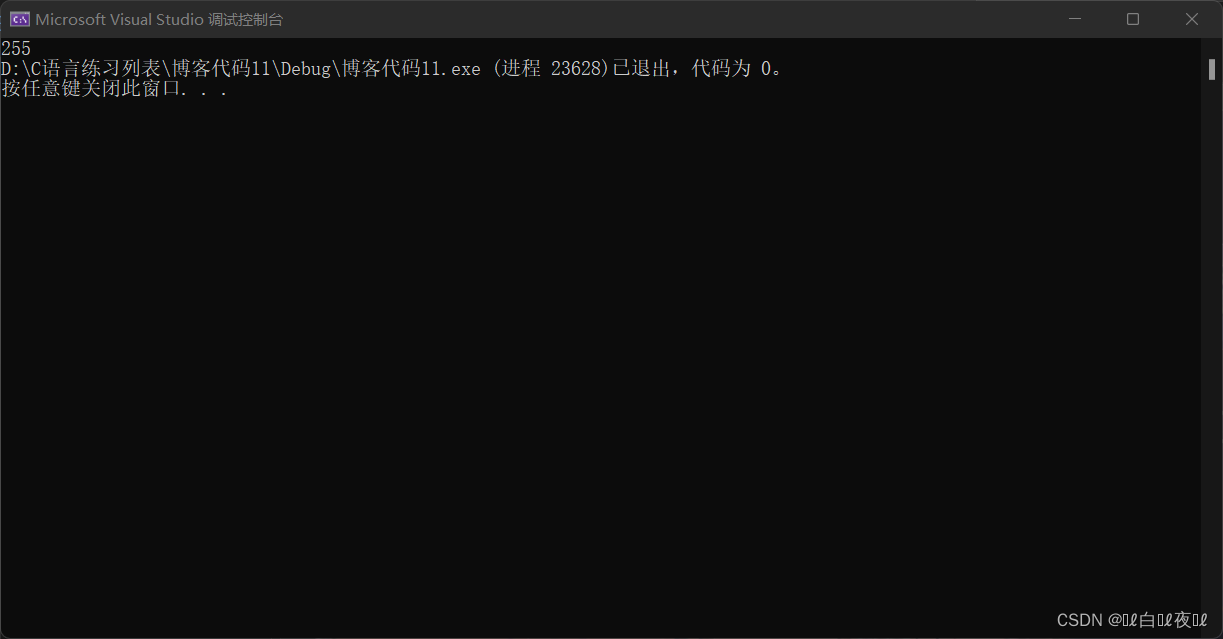
我们第一次进入循环的时候,char a[1000]这个数组里面的第一个元素是:
-1,然后是-2…
以二进制的角度来看:
-1的补码 11111111111111111111111111111111
-2的补码 11111111111111111111111111111110
…
我们只能储存进后八位的数据,这里要注意,strlen是遇到\0然后停止,不计算\0的位置,‘\0’等于char里面储存的0。
也就是说二进制到这里才会停止:
11111111111111111111111100000000
所以输出结果是255。
这里我们还发现一件事,有符号char类型的范围是0~127和-1~-128
无符号的char类型范围是是0~255。
//代码7
#include <stdio.h>
unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}
这个代码的运行结果也是死循环。
因为 i 是unsigned char类型,无论 i 怎么加,都是正数,所以死循环。
3. 浮点型在内存中的存储
常见的浮点数:
3.14159
1E10
浮点数家族包括: float、double、long double 类型。
浮点数表示的范围:float.h中定义
3.1 一个例子
浮点数存储的例子:
#include <stdio.h>
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
return 0;
}
我们的输出结果是: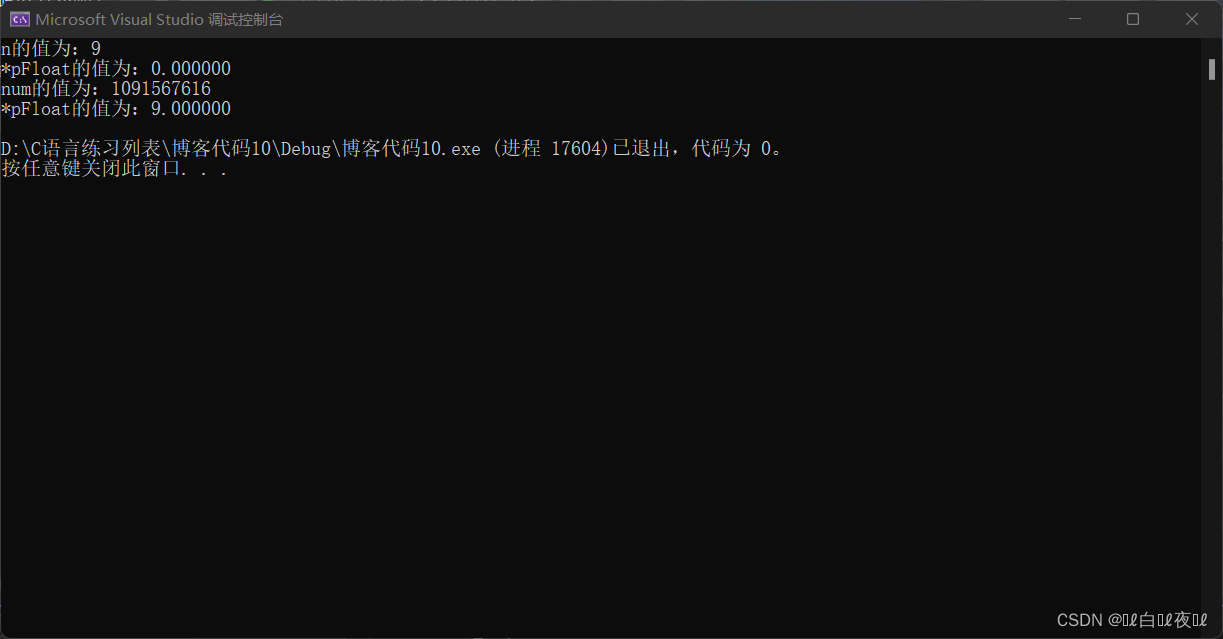
实际的结果是不是很不符合我们的预期结果?
这又是为什么呢?我们往下看:
3.2 浮点数存储规则
num 和 *pFloat 在内存中明明是同一个数,为什么浮点数和整数的解读结果会差别这么大?
要理解这个结果,一定要搞懂浮点数在计算机内部的表示方法。
详细解读:
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
(-1)^S * M * 2^E
(-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
M表示有效数字,大于等于1,小于2。
2^E表示指数位。
举例来说:
十进制的5.0,写成二进制是 101.0 ,相当于 1.01×2^2 。
那么,按照上面V的格式,可以得出S=0,M=1.01,E=2。
十进制的-5.0,写成二进制是 -101.0 ,相当于 -1.01×2^2 。那么,S=1,M=1.01,E=2。
IEEE 754规定:
对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。
对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。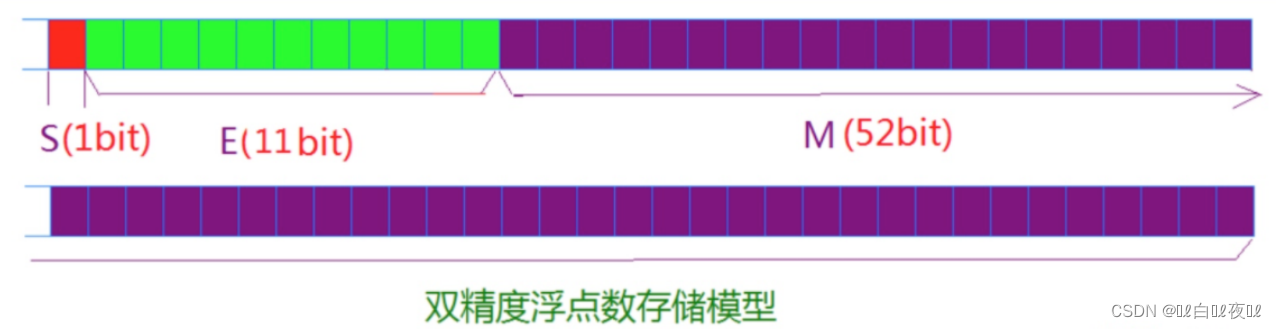
IEEE 754对有效数字M和指数E,还有一些特别规定。
前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。
至于指数E,情况就比较复杂。
首先,E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0 ~ 255;如果E为11位,它的取值范围为0 ~ 2047。但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
然后,指数E从内存中取出还可以再分成三种情况:
E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第一位的1。
比如:
0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为1.0*2^(-1),其阶码为-1+127=126,表示为
01111110,而尾数1.0去掉整数部分为0,补齐0到23位00000000000000000000000,则其二进制表示形式为:
0 01111110 00000000000000000000000
E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于0的很小的数字。
E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s);
这就是浮点型的数据储存方式。
解释前面的题目:
下面,让我们回到一开始的问题:为什么 0x00000009 还原成浮点数,就成了 0.000000 ?
首先,将 0x00000009 拆分,得到第一位符号位s=0,后面8位的指数E=00000000 ,最后23位的有效数字M=000 0000 0000 0000 0000 1001。
9 -> 0000 0000 0000 0000 0000 0000 0000 1001
由于指数E全为0,所以符合上一节的第二种情况。因此,浮点数V就写成:
V=(-1)^0 × 0.00000000000000000001001×2^(-126)=1.001×2^(-146)
显然,V是一个很小的接近于0的正数,所以用十进制小数表示就是0.000000。(%f只打印小数点后面6位的数)
再看例题的第二部分。
请问浮点数9.0,如何用二进制表示?还原成十进制又是多少?
首先,浮点数9.0等于二进制的1001.0,即1.001×2^3。
9.0 -> 1001.0 ->(-1)^01.0012^3 -> s=0, M=1.001,E=3+127=130
那么,第一位的符号位s=0,有效数字M等于001后面再加20个0,凑满23位,指数E等于3+127=130, 即10000010。
所以,写成二进制形式,应该是s+E+M,即
0 10000010 001 0000 0000 0000 0000 0000
这个32位的二进制数,还原成十进制,正是 1091567616 。
结束语
请家人们点个赞,大佬们指点不足。
边栏推荐
- 云备份项目
- Get the city according to IP
- Basic introduction of JWT
- Databinding exception of kotlin
- MySQL user permissions
- How to share the same storage among multiple kubernetes clusters
- PostgreSQL source code (59) analysis of transaction ID allocation and overflow judgment methods
- AVL树的实现
- Master-slave replication principle of MySQL
- Flexible layout (II)
猜你喜欢

Composition API premise
Nesting and splitting of components

大咖云集|NextArch基金会云开发Meetup来啦
Freeswitch dials extension number source code tracking
![How to model and simulate the target robot [mathematical / control significance]](/img/bd/79f6338751b6773859435c54430ec3.png)
How to model and simulate the target robot [mathematical / control significance]
Pass child component to parent component

How can brand e-commerce grow against the trend? See the future here!

. Net 5 fluentftp connection FTP failure problem: this operation is only allowed using a successfully authenticated context
$refs: get the element object or sub component instance in the component:

$parent(获取父组件) 和 $root(获取根组件)
随机推荐
Detailed explanation of transform origin attribute
Explain Bleu in machine translation task in detail
How can flinksql calculate the difference between a field before and after update when docking with CDC?
Academic report series (VI) - autonomous driving on the journey to full autonomy
Learning records on July 4, 2022
linux系统rpm方式安装的mysql启动失败
Circulating tumor cells - here comes abnova's solution
组件的通信
Pass child component to parent component
Asynchronous components and suspend (in real development)
抽丝剥茧C语言(高阶)指针的进阶
The currently released SKU (sales specification) information contains words that are suspected to have nothing to do with baby
Basic process of network transmission using tcp/ip four layer model
Config distributed configuration center
Composition API premise
多线程与高并发(9)——AQS其他同步组件(Semaphore、ReentrantReadWriteLock、Exchanger)
Abnova immunohistochemical service solution
JS decorator @decorator learning notes
选择商品属性弹框从底部弹出动画效果
Use of completable future