当前位置:网站首页>[cloud native] how to give full play to memory advantage of memory database
[cloud native] how to give full play to memory advantage of memory database
2022-07-07 07:25:00 【Shizhenzhen's grocery store】
author : Shi Zhenzhen , CSDN Blog star Top5、Kafka Contributor 、nacos Contributor、 Hua Wei Yun MVP , Tencent cloud TVP, sound of dripping water Kafka technician 、LogiKM PMC( Change of name KnowStream).
List of articles
Compared with ordinary database based on disk storage , The data access speed of in memory database can be several orders of magnitude higher , It can greatly improve the computing performance , More suitable for high concurrency 、 Low latency business scenarios .
however , At present, most memory databases still use SQL Model , and SQL Lack of some necessary data types and operations , Unable to make full use of the characteristics of memory to realize some high-performance algorithms . Just simply move the external data and operations into the memory , Of course, it can also obtain much better performance than external memory , But it hasn't made full use of memory features , You can't get the ultimate performance .
Let's take a look at , What algorithms and storage mechanisms are suitable for memory characteristics , It can further improve the calculation speed of in memory database .
Pointer multiplexing
We know , Memory can be accessed by address ( The pointer ) To visit . but SQL There are no data objects represented by memory pointers , When returning the result set , Usually copy the data , Form a new data table . This not only consumes more CPU Time ( For copying data ) And it will take up more expensive memory space ( Used to store replicated data ), Reduce memory usage .
except SQL Out of memory database ,Spark Medium RDD It's also a problem , And the situation is more serious . In order to maintain RDD Of immutable characteristic ,Spark After each calculation step, a new RDD, Cause memory and CPU A lot of waste . therefore , Even if it consumes huge resources ,Spark High performance is still not possible . by comparison ,SQL Memory databases are usually optimized , stay SQL The calculation in the statement will try to use the memory address , It's usually better than Spark Better performance .
however , Limited by theory , Realization SQL The logic of , The returned result set must be copied . If a multi-step process operation is involved , The result set of the previous step should be repeated ( A temporary table ) Further calculation based on ,SQL The disadvantage will be obvious .
in fact , If you don't change the data structure , We can directly use the address of the original data to form the result set , There is no need to copy the data itself , Just save one more address ( The pointer ), At the same time reduce CPU And memory consumption .
SPL Expanded SQL Data type of , Support this Pointer multiplexing Mechanism . such as , According to the order date (odate) After range filtering , Calculate the order amount separately (amount1) Greater than 1000 And freight charges (amount2) Greater than 1000 The order of , Then calculate the intersection of the two 、 Union and subtraction , Finally, the difference set is set according to the customer number (cid) Sort .SPL The code is roughly like this :
| A | B | |
|---|---|---|
| 1 | =orders.select(odate>=date(2000,1,1) && odate<=date(2022,1,1)) | |
| 2 | =A1.select(amount1>1000) | =A1.select(amount2>1000) |
| 3 | =A2^B2 | =A2&B2 |
| 4 | =A2\B2 | =B2\A2 |
| 5 | =A4.sort(cid) | =B4.sort(cid) |
| There are several steps in the above code , Some intermediate results have also been used many times , But because all the pointers used are the records of the order table , So the increase in memory usage is very small , It also avoids the time-consuming of record replication . |
Foreign key preassociation
Foreign key association refers to using a table ( Fact table ) Non primary key field of , To associate another table ( Dimension table ) Primary key of . For example, the customer number and product number in the order table are associated with the customer table respectively 、 The primary key of the product table . In real computing, this association may be as many as seven or eight or even more than a dozen tables , There may also be multiple layers of correlation .SQL Database usually uses HASH JOIN Algorithm to do memory connection , Need to calculate and compare HASH value , The process also takes up memory to store intermediate results , The performance of the correlation table will decline sharply .
Actually , We can also use the memory pointer reference mechanism to make association in advance . In the system initialization phase , Convert the associated field value in the fact table into the pointer of the corresponding dimension table record . Because the associated field of the dimension table is the primary key , So the associated record is unique , Converting foreign key values to record pointers does not cause errors . In subsequent calculations , When you need to reference dimension table fields , You can refer to... Directly with a pointer , There is no need to calculate and compare HASH value , There is no need to store intermediate results , So as to obtain better performance .SQL There is no record pointer for this data type , It is impossible to realize pre Association .
SPL It supports and realizes this kind of Pre Association Mechanism . for example , Complete the order form and customer form 、 The pre associated code of the product table is roughly like this :
| A | |
|---|---|
| 1 | =file(“customer.btx”)[email protected]()[email protected](cid) |
| 2 | =file(“product.btx”)[email protected]()[email protected](pid) |
| 3 | =file(“orders.btx”)[email protected]().switch(cid,A1;pid,A2) |
| 4 | >env(orders,A3) |
A1、A2 Load customer table and product table .
A3: Load order form , Put the customer number cid、 Product number pid Convert to the pointer of the corresponding dimension table record .
A4: Store the pre associated order table into the global variable , For subsequent calculations .
When the system is running , Filter orders by product supplier , The codes grouped and summarized by the customer's city are roughly as follows :
| A | |
|---|---|
| 1 | =orders.select(pid.supplier==“raqsoft.com”).groups(cid.city;sum(pid.price*quantity)) |
In the order form pid Pointer that has been converted to product table record , So you can use it directly “.” The operator references the product table record . Not only is writing easier , And the computing performance is much faster .
Just two 、 When three tables are associated , Pre Association and HASH JOIN The difference is not very obvious . This is because relevance is not the ultimate goal , There will be many other operations , The operation time of association itself is relatively small . But if the correlation is complex , There are many tables involved , And when there are multiple layers ( For example, order related products , Product related suppliers , Supplier's associated city , City related countries and so on ), The performance advantage of pre correlation will be more obvious .
Serial number location
Compared with external storage , Another important feature of memory is that it supports high-speed random access , You can quickly press the specified sequence number from the memory table ( That's location ) Take out the data . When doing search calculation , If the searched value is exactly the sequence number of the target value in the memory table , Or it is easy to calculate the sequence number of the target value through the searched value , We can use the serial number to get the target record directly . This method can directly get the search results without any comparison , Performance is not only much better than traversal lookup , Better than the search algorithm using index .
however ,SQL Based on unordered sets , Members cannot be retrieved by serial number , You can only use the serial number to find . If there is no index, you can only traverse and find , Will be very slow . Calculate even if there is an index HASH Value or use dichotomy to find , It's not as fast as direct positioning . and , Indexing also takes up expensive memory . If there is no serial number in the data table, you have to sort first and then hard create a serial number , The performance will be worse .
SPL Based on ordered sets , Provide Serial number location function . For example, the order number in the order table is from 1 The natural number of the beginning . Looking for the order number i when , Directly get the... In the order table i Just a record . Another example is the data sheet T from 2000 Year to 2022 Store one piece of data every day for a year , Now you need to query the records of the specified date . Although the date is not the sequence number of the target value , But we can first calculate the number of days from the specified date to the start date . This is the sequence number of the target value , Then use the serial number to get T Just record the table . Counter table T Locate and find with serial number 2022 year 4 month 20 Diary code , Roughly as follows :
| A | |
|---|---|
| 1 | =date(2022,12,31)-date(1999,12,31) |
| 2 | [email protected](to(A1),dt-date(1999,12,31)) |
| 3 | =env(T,A5) |
| 4 | =T(date(2021,4,20)-date(1999,12,31)) |
A1: To calculate the 2000 Year to 2022 The total number of days in a year is 8401 God .
A2: With the original T The table records the number of days from the start date , And again to(A1) This set of natural numbers [1,2,3,…,8401] alignment , The vacancy date will be in null A filling .align Of @b Option means that the dichotomy will be used to find the position when aligning , This will also make the alignment a little faster .
A3: The calculated result , Put it in the global variable T in .
A4: To find out 2021 year 4 month 20 Diaries , Find the distance between this date and the start date 7781 God , Take it out directly T No 7781 Just a record .
A1 To A3 It's alignment calculation , Date used to process the vacancy , It can be put in the system initialization stage . When looking up calculations , use A4 The search result can be obtained by the serial number positioning code in , The actual search date can be passed in as a parameter .
Cluster dimension table
When the amount of data is too large , When the stand-alone memory is exceeded , You need to use the cluster to load this data . Many in memory databases also support distributed computing , Usually, the data is divided into multiple segments , Load them into the memory of different extensions of the cluster .
JOIN Is a troublesome task of Distributed Computing , It will involve data transmission between multiple extensions . When it's serious , The delay caused by the transmission will offset the benefits of the cluster sharing the amount of computation , There will be a phenomenon that the cluster becomes larger, but the performance cannot be improved .
SQL Distributed database system , It is usually a single machine HASH JOIN Method is extended to the cluster . Each extension is based on HASH Value to distribute local data to other extensions , Ensure that the associated data is on the same extension . Then make a stand-alone connection on each extension . however ,HASH Method in bad luck , It may cause serious imbalance in data distribution , External memory is needed to cache the distributed data , Otherwise, the system may crash due to memory overflow . however , The main feature of memory database is to load data into memory for calculation , The appearance of external memory cache will seriously slow down the computing performance .
actually , The fact table associated with foreign keys is very different from the dimension table . Fact tables are generally large , It can only be loaded in segments with the memory of each extension . The fact table is also suitable for segmentation , The data of each segment is independent of each other , There is no need for mutual access between extensions . The dimension table records will be accessed randomly , Any segment of the fact table may be associated with all dimension table records . We can use the difference between fact table and dimension table , Speed up the foreign key Association of clusters .
If the dimension table is small , Copy the full data of the dimension table to the memory of all extensions . such , The fact table segment and full dimension table in each extension can continue to complete the pre Association , The network transmission in the association process is completely avoided .
If the dimension table is also large , Stand alone memory can't fit , It can only be loaded in segments in the memory of each extension . At this time , No extension has a full range of dimension tables , Foreign key Association calculation cannot avoid network transmission . However, the transmission content is not very large , Only the foreign keys of the fact table and the fields of the associated records of the dimension table are involved , Other fields of the fact table do not need to be transferred , The calculation can be done directly , Cache data will not be generated in the process .
SPL Distinguish dimension table and fact table in principle , For the two cases of small dimension table and large dimension table , Respectively provided Dimension table replication The mechanism and Segmented dimension table Mechanism , The above algorithm is realized , It can significantly improve the computing performance of foreign key Association in cluster .
Spare wheel fault-tolerant
Fault tolerance must be considered in cluster system , The fault tolerance of in memory data is different from that of external memory . External storage generally uses the method of copy , That is, there are multiple copies of the same data , After one extension fails, data can still be found in other extensions . The storage utilization of this mechanism is very low , Only 1/k(k Is the number of copies ).
however , For data in memory , But you can't use this replica fault-tolerant method . This is because hard drives are cheap enough to expand almost indefinitely , But memory is much more expensive and there is an upper limit to expansion . Only 1/k Memory utilization is intolerable .
Memory fault tolerance requires special means different from external memory .SPL Provides Spare wheel fault-tolerant Mechanism , Divide the data into n After the segment is loaded into n In the memory of an extension . Then prepare k An idle extension is used as a standby . When a running extension fails , Then start a standby machine immediately , Temporarily load the data of the failed extension , And other extensions to form a cluster with complete data and continue to provide services . The failed extension can be restored to use after troubleshooting , It can be used as a standby machine again . The whole process is very similar to the mode of changing the spare tire of a car .
The memory utilization of the spare wheel fault-tolerant mechanism can be as high as n/(n+k), Much higher than replica fault tolerance 1/k. The amount of data that can be loaded into memory is usually not very large , There is not much time for temporary loading after the extension fails , Cluster services can be restored quickly .
Review and summarize
Memory database computing system , You must make full use of the characteristics of memory to achieve maximum performance . From the point of view of data calculation , The main advantages of memory are : Support pointer reference 、 Support high-speed random access 、 Strong concurrent reading ability . The disadvantage of memory is : The high cost of 、 There is an upper limit for capacity expansion .
and SQL The computing system lacks some necessary data types and operations , such as : Missing record pointer type , Ordered operations are not supported ,JOIN The definition is too general , Indistinguishes JOIN Type, etc , In principle, we can't make full use of the above characteristics of memory to realize some high-speed algorithms . be based on SQL Memory database of , Usually just simply copy the external memory data structure and operation , There will be problems . such as : Recording replication consumes too much CPU And memory ; Find and JOIN Performance is not at its best . Another example is the cluster : Memory utilization is too low ; A large number of network transmission leads to an increase in the number of extensions, but the performance decreases ; Multimachine JOIN External memory cache, etc .
Open source data computing engine SPL Extended data type and operation definition , Can make full use of the characteristics of memory , So as to realize a variety of high-performance algorithms , Maximize performance . among , Pointer multiplexing Using memory specific pointer reference mechanism , Save memory space , And faster . Pre Association Also use the pointer reference mechanism , Complete the time-consuming foreign key Association in the initialization phase , The results with good correlation are directly used in subsequent calculations , The calculation speed is significantly improved . Serial number location Use order , Give full play to the advantages of high-speed random access to memory , Without any calculation and comparison , Read the serial number directly , Better performance than HASH Index and other search algorithms . Cluster dimension table Effectively avoid or reduce network transmission 、 Avoid external memory cache , Spare wheel fault-tolerant On the premise of ensuring high availability , Effectively improve the memory utilization of the cluster .
besides ,SPL It also provides Row key 、 Serial number index 、 Data type compression And other ways . The programmer can according to the specific scenario , Adopt these methods pertinently , You can make full use of the advantages of memory , So as to effectively improve the performance of memory data calculation .
SPL Information
边栏推荐
- [explanation of JDBC and internal classes]
- Lm11 reconstruction of K-line and construction of timing trading strategy
- 抽丝剥茧C语言(高阶)数据的储存+练习
- SQLMAP使用教程(四)实战技巧三之绕过防火墙
- 子组件传递给父组件
- 修改Jupyter Notebook文件路径
- 面试官:你都了解哪些开发模型?
- Explain Bleu in machine translation task in detail
- Detailed explanation of neo4j installation process
- Implementing data dictionary with JSP custom tag
猜你喜欢
計算機服務中缺失MySQL服務
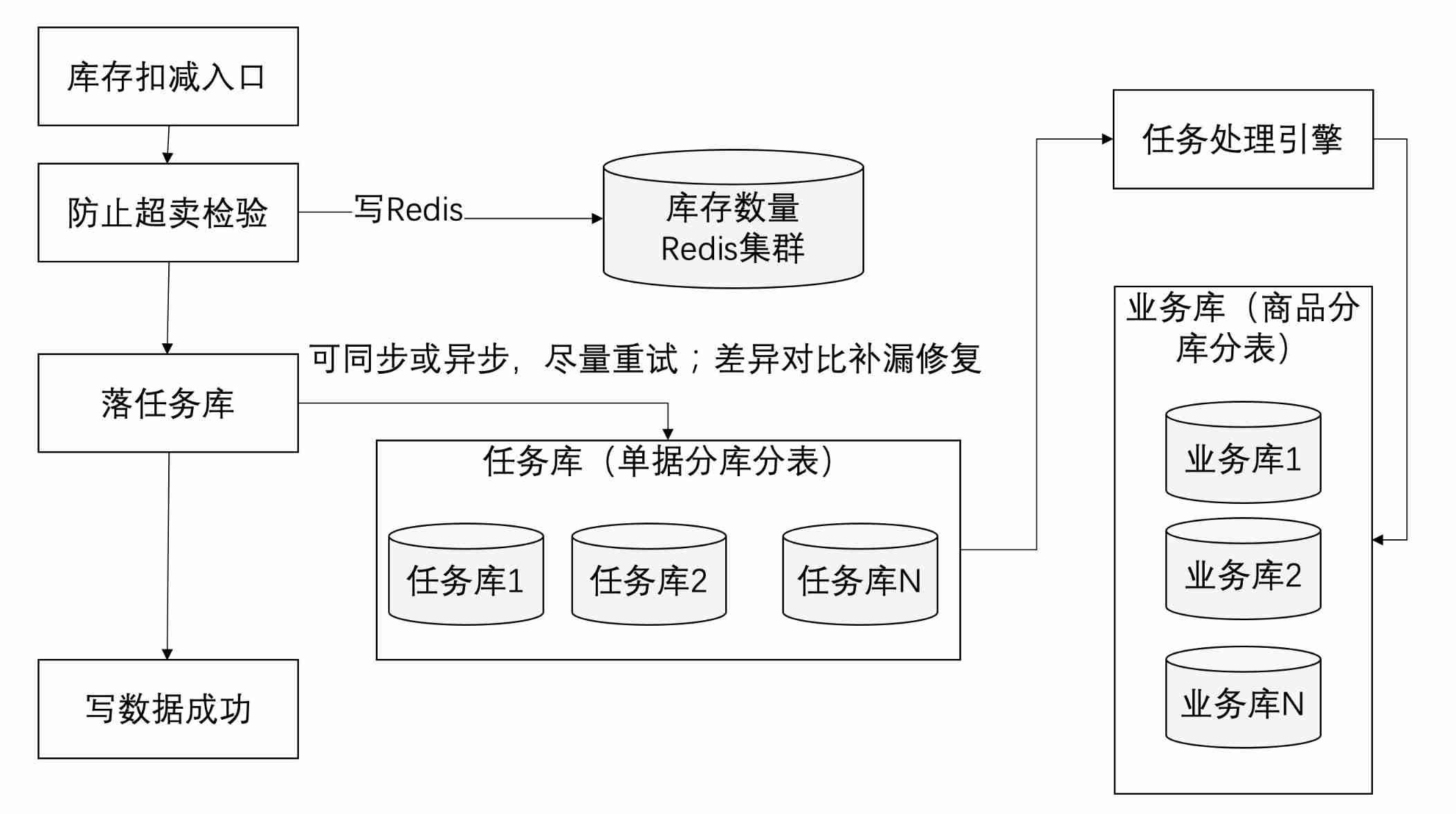
How to reduce inventory with high concurrency on the Internet
Flexible layout (I)

外包幹了三年,廢了...
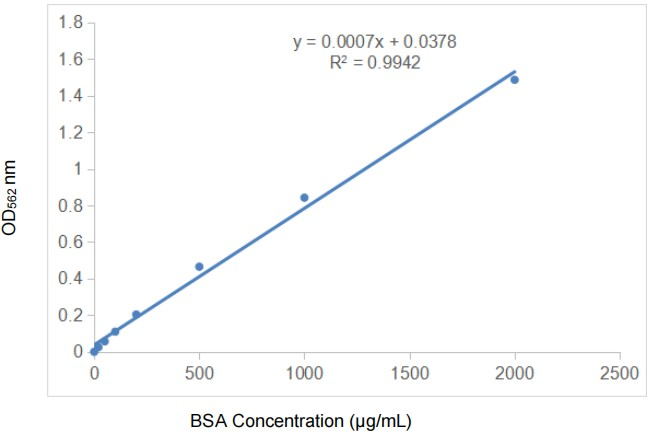
Fast quantitative, abbkine protein quantitative kit BCA method is coming!
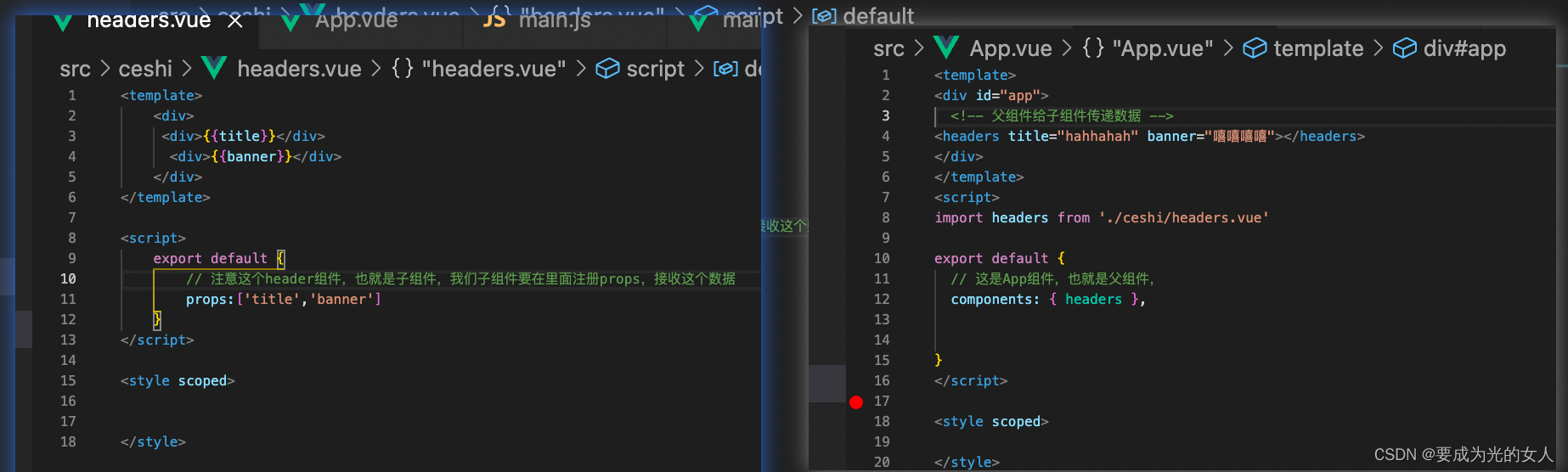
Pass parent component to child component: props
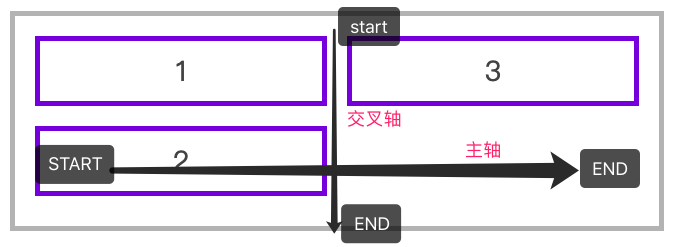
Flexible layout (II)
Abnova immunohistochemical service solution
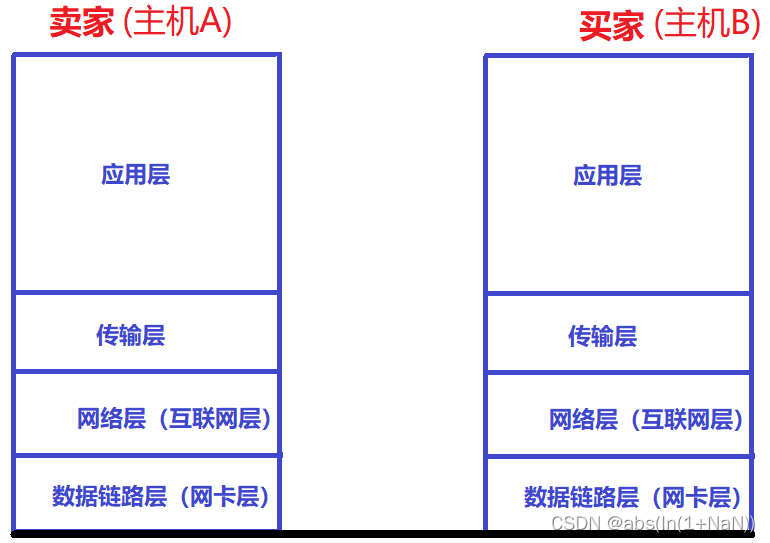
Basic process of network transmission using tcp/ip four layer model
Abnova membrane protein lipoprotein technology and category display
随机推荐
【云原生】内存数据库如何发挥内存优势
Common function detect_ image/predict
Talk about seven ways to realize asynchronous programming
聊聊异步编程的 7 种实现方式
URP - shaders and materials - light shader lit
1、 Go knowledge check and remedy + practical course notes youth training camp notes
组件的嵌套和拆分
Introduction to abnova's in vitro mRNA transcription workflow and capping method
Implementation of AVL tree
Summary of customer value model (RFM) technology for data analysis
RuntimeError: CUDA error: CUBLAS_ STATUS_ ALLOC_ Failed when calling `cublascreate (handle) `problem solving
抽絲剝繭C語言(高階)指針的進階
At the age of 20, I got the ByteDance offer on four sides, and I still can't believe it
FullGC问题分析及解决办法总结
95后CV工程师晒出工资单,狠补了这个,真香...
Unity C function notes
FPGA course: application scenario of jesd204b (dry goods sharing)
外包干了三年,废了...
Bindingexception exception (error reporting) processing
异步组件和Suspense(真实开发中)