当前位置:网站首页>《动手学深度学习》(四) -- 卷积神经网络 CNN
《动手学深度学习》(四) -- 卷积神经网络 CNN
2022-07-07 04:04:00 【长路漫漫2021】
上一小节学习了卷积神经网络的卷积层和池化层的实现,趁热打铁继续学习现代卷积神经网络的搭建,欢迎小伙伴们一起学习和交流~
为了能够应⽤softmax回归和多层感知机,我们⾸先将每个⼤小为 28 × 28 28 \times 28 28×28的图像展平为⼀个784维的固定⻓度的⼀维向量,然后⽤全连接层对其进⾏处理。而现在, 我们已经掌握了卷积层的处理⽅法,可以在图像中保留空间结构。同时,⽤卷积层代替全连接层的另⼀个好处是:模型更简洁、所需的参数更少。
网上有很多对这些网络的详细介绍和优缺点分析,这里只是介绍各种卷积网络的组成和实现。这些模型包括:
- LeNet。最早发布的卷积神经⽹络之⼀;
- AlexNet。第⼀个在⼤规模视觉竞赛中击败传统计算机视觉模型的⼤型神经⽹络;
- 使⽤重复块的⽹络(VGG)。利⽤许多重复的神经⽹络块;
- ⽹络中的⽹络(NiN)。重复使⽤由卷积层和 1 × 1 1\times 1 1×1卷积层(⽤来代替全连接层)来构建深层⽹络;
- 含并⾏连结的⽹络(GoogLeNet)。使⽤并⾏连结的⽹络,通过不同窗口⼤小的卷积层和最⼤汇聚层来并⾏抽取信息;
- 残差⽹络(ResNet)。通过残差块构建跨层的数据通道,是计算机视觉中最流⾏的体系架构;
- 稠密连接⽹络(DenseNet)。计算成本很⾼,但给我们带来了更好的效果。
1 LeNet
1.1 模型搭建
LeNet(LeNet-5)由两个部分组成:(1)卷积编码器:由两个卷积层组成;(2)全连接层密集块:由三个全连接层组成。架构如下图所示:
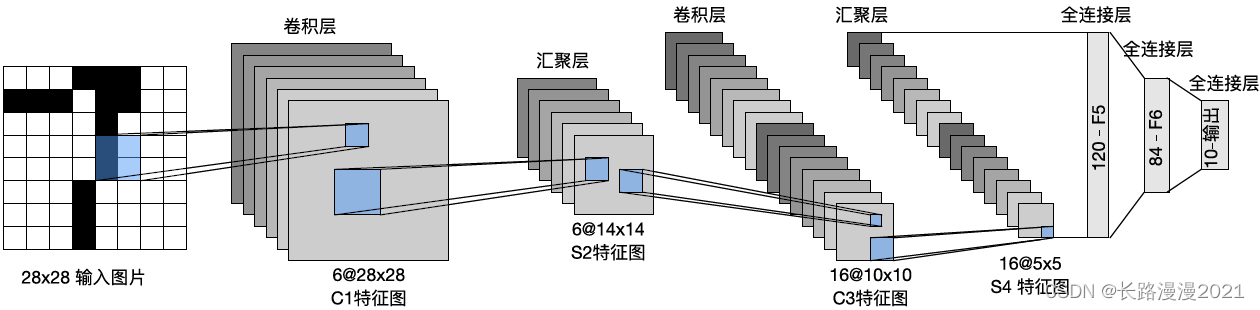
每个卷积块中的基本单元是⼀个卷积层、⼀个sigmoid激活函数和平均汇聚层。请注意,虽然ReLU和最⼤汇聚层更有效,但它们在20世纪90年代还没有出现。每个卷积层使⽤ 5 × 5 5\times 5 5×5卷积核和⼀个sigmoid激活函数。这些层将输⼊映射到多个⼆维特征输出,通常同时增加通道的数量。第⼀卷积层有6个输出通道,而第⼆个卷积层有16个输出通道。每个 2 × 2 2\times 2 2×2 池化操作(步骤2)通过空间下采样将维数减少4倍。卷积的输出形状由批量⼤小、通道数、⾼度、宽度决定。
为了将卷积块的输出传递给稠密块,我们必须在小批量中展平每个样本。换⾔之,将这个四维输⼊转换成全连接层所期望的⼆维输⼊。这⾥的⼆维表⽰的第⼀个维度索引小批量中的样本,第⼆个维度给出每个样本的平⾯向量表⽰。LeNet的稠密块有三个全连接层,分别有120、84和10个输出。因为我们仍在执⾏分类,所以输出层的10维对应于最后输出结果的数量。LeNet的实现只需要实例化一个Sequential块并将需要的层连接在一起。
import torch
from torch import nn
from d2l import torch as d2l
from torchvision import transforms
from torch.utils.data import DataLoader
from mnist_dataset import FashionMnistDataset # 自定义的数据集导入
# 模型搭建
LeNet = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
这里对原始模型做了⼀点小改动,去掉了最后⼀层的⾼斯激活。除此之外,这个⽹络与最初的LeNet-5⼀致。
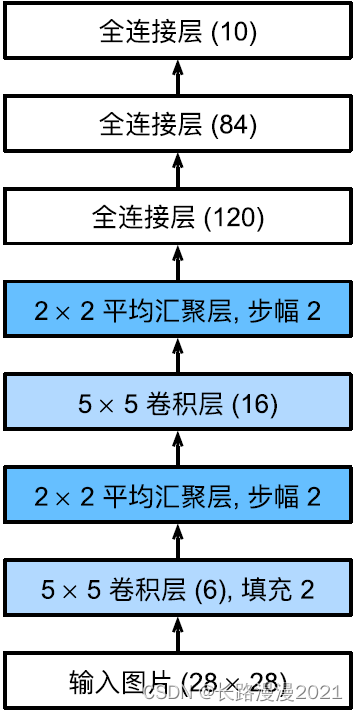
下⾯,我们将⼀个⼤小为 28 × 28 28\times 28 28×28的单通道(⿊⽩)图像通过LeNet。通过在每⼀层打印输出的形状,我们可以检查模型,以确保其操作与我们期望的⼀致。
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in LeNet:
X = layer(X)
print(layer.__class__.__name__, 'output shape: \t', X.shape)
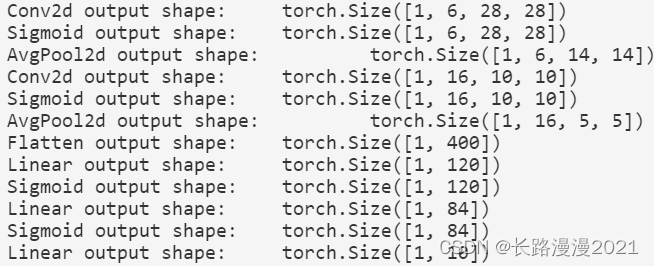
温馨提示,在整个卷积块中,与上⼀层相⽐,每⼀层特征的⾼度和宽度都减小了。第⼀个卷积层使⽤2个像素的填充,来补偿 5 × 5 5 \times 5 5×5卷积核导致的特征减少。相反,第⼆个卷积层没有填充,因此⾼度和宽度都减少了4个像素。随着层叠的上升,通道的数量从输⼊时的1个,增加到第⼀个卷积层之后的6个,再到第⼆个卷积层之后的16个。同时,每个汇聚层的⾼度和宽度都减半。最后,每个全连接层减少维数,最终输出⼀个维数与结果分类数相匹配的输出。
1.2 模型训练
下面让我们看看LeNet在Fashion-MNIST数据集上的表现。
这里由于国内网络的原因,下载数据集特别慢,所以使用下载好的本地数据集,在线下载数据集,可以使用d2l包里的load_data_fashion_mnist,如下:
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
自定义的数据导入如下:
# -*- coding: utf-8 -*-
""" Function Name:mnist_dataset.py Version:0.1 Description:实现mnsit和Fashion-mnist两个数据集的导入 Author:CarpeDiem """
import gzip
import os
import numpy as np
from torch.utils.data import Dataset
class FashionMnistDataset(Dataset):
"""读取数据、初始化数据"""
def __init__(self, folder, data_name, label_name, transform=None):
(train_set, train_labels) = load_data(folder, data_name, label_name)
self.train_set = train_set
self.train_labels = train_labels
self.transform = transform
def __getitem__(self, index):
img, target = self.train_set[index], int(self.train_labels[index])
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self):
return len(self.train_set)
def load_data(data_folder, data_name, label_name):
with gzip.open(os.path.join(data_folder, label_name), 'rb') as labpath:
y_train = np.frombuffer(labpath.read(), np.uint8, offset=8)
with gzip.open(os.path.join(data_folder, data_name), 'rb') as imgpath:
x_train = np.frombuffer(imgpath.read(), np.uint8,
offset=16).reshape(len(y_train), 28, 28)
return (x_train, y_train)
# 数据集导入
batch_size = 256
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = FashionMnistDataset('../dataset/fashion-mnist', 'train-images-idx3-ubyte.gz', 'train-labels-idx1-ubyte.gz', transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = FashionMnistDataset('../dataset/fashion-mnist', 't10k-images-idx3-ubyte.gz', 't10k-labels-idx1-ubyte.gz', transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
虽然卷积神经⽹络的参数较少,但与深度的多层感知机相⽐,它们的计算成本仍然很⾼,因为每个参数都参与更多的乘法。这里使⽤GPU加快训练。这里重写evaluate_accuracy函数。
def evaluate_accuracy_gpu(net, data_loader, device=None):
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_loader:
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
在进⾏正向和反向传播之前,我们需要将每⼀小批量数据移动到我们指定的设备(例如GPU)上。与全连接层⼀样,使⽤交叉熵损失函数和小批量随机梯度下降,训练模型如下所示。
def train_ch6(net, train_loader, test_loader, num_epoches, lr, device):
"""用GPU训练模型"""
def init_weights(m):
if isinstance(m, nn.Linear) or isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
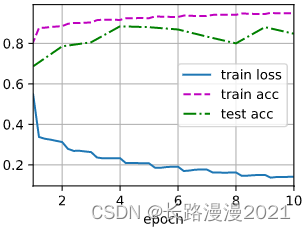
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epoches], legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_loader)
for epoch in range(num_epoches):
# 训练损失之和,训练准确率之和,范例数
metric = d2l.Accumulator(3)
net.train()
for iteration, (X, y) in enumerate(train_loader):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
loss = criterion(y_hat, y)
loss.backward()
optimizer.step()
with torch.no_grad():
metric.add(loss * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_loss = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (iteration + 1) % (num_batches // 5) == 0 or iteration == num_batches - 1: # 每num_batches//5次计算一次损失和训练准确率
animator.add(epoch + (iteration + 1) / num_batches, (train_loss, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_loader) # 训练一轮后计算预测的准确率
animator.add(epoch+1, (None, None, test_acc))
print(f'loss {
train_loss:.3f}, train acc {
train_acc:.3f}, test acc {
test_acc:.3f}')
print(f'{
metric[2] * num_epoches / timer.sum():.1f} examples/sec, on {
str(device)}')
接下来,训练和评估LeNet-5模型。
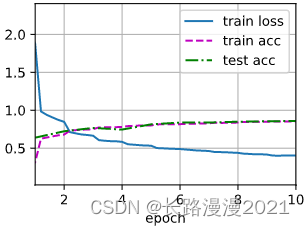
lr, num_epochs = 0.9, 10
train_ch6(LeNet, train_loader, test_loader,num_epochs, lr, d2l.try_gpu())
# loss 0.465, train acc 0.826, test acc 0.824
# 84969.9 examples/sec, on cuda:0

2 AlexNet
2012年,AlexNet横空出世。它⾸次证明了学习到的特征可以超越⼿⼯设计的特征。它⼀举打破了计算机视觉研究的现状。AlexNet使⽤了8层卷积神经⽹络,并以很⼤的优势赢得了2012年ImageNet图像识别挑战赛。
AlexNet和LeNet的架构⾮常相似,如下图所⽰。注意,这⾥提供了⼀个稍微精简版本的AlexNet,去除了当年需要两个小型GPU同时运算的设计特点。
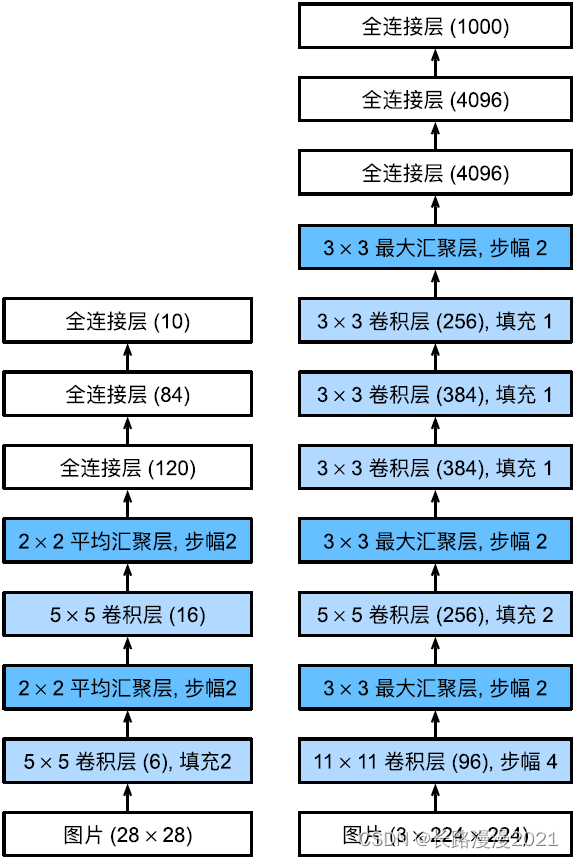
AlexNet和LeNet的设计理念⾮常相似,但也存在显著差异。⾸先,AlexNet⽐相对较小的LeNet5要深得多。AlexNet由⼋层组成:五个卷积层、两个全连接隐藏层和⼀个全连接输出层。其次,AlexNet使⽤ReLU而不是sigmoid作为其激活函数。下⾯,让我们深⼊研究AlexNet的细节。
2.1 模型设计
在AlexNet的第⼀层,卷积窗口的形状是 11 × 11 11\times 11 11×11。由于ImageNet中⼤多数图像的宽和⾼⽐MNIST图像的多10倍以上,因此,需要⼀个更⼤的卷积窗口来捕获⽬标。第⼆层中的卷积窗口形状被缩减为 5 × 5 5\times 5 5×5,然后是 3 × 3 3\times 3 3×3。此外,在第⼀层、第⼆层和第五层卷积层之后,加⼊窗口形状为 3 × 3 3\times 3 3×3、步幅为2的最⼤汇聚层。而且,AlexNet的卷积通道数⽬是LeNet的10倍。
在最后⼀个卷积层后有两个全连接层,分别有4096个输出。这两个巨⼤的全连接层拥有将近1GB的模型参数。由于早期GPU显存有限,原版的AlexNet采⽤了双数据流设计,使得每个GPU只负责存储和计算模型的⼀半参数。幸运的是,现在GPU显存相对充裕,所以我们现在很少需要跨GPU分解模型(因此,我们的AlexNet模型在这⽅⾯与原始论⽂稍有不同)。
AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。⼀⽅⾯,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。另⼀⽅⾯,当使⽤不同的参数初始化⽅法时,ReLU激活函数使训练模型更加容易。当sigmoid激活函数的输出⾮常接近于0或1时,这些区域的梯度⼏乎为0,因此反向传播⽆法继续更新⼀些模型参数。相反,ReLU激活函数在正区间的梯度总是1。因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到⼏乎为0的梯度,从而使模型⽆法得到有效的训练。
AlexNet通过dropout控制全连接层的模型复杂度,而LeNet只使⽤了权重衰减。
Alexnet = nn.Sequential(
# 这⾥使⽤⼀个11*11的更⼤窗⼝来捕捉对象。
# 步幅为4,以减少输出的⾼度和宽度。
# 输出通道的数⽬远⼤于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减⼩卷积窗⼝,使⽤填充为2来使得输⼊与输出的⾼和宽⼀致,且增⼤输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使⽤三个连续的卷积层和较⼩的卷积窗⼝。
# 除了最后的卷积层,输出通道的数量进⼀步增加。
# 在前两个卷积层之后,汇聚层不⽤于减少输⼊的⾼度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这⾥,全连接层的输出数量是LeNet中的好⼏倍。使⽤dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这⾥使⽤Fashion-MNIST,所以⽤类别数为10,⽽⾮论⽂中的1000
nn.Linear(4096, 10))
构造⼀个⾼度和宽度都为224的单通道数据,来观察每⼀层输出的形状。
X = torch.randn(1, 1, 224, 224)
for layer in Alexnet:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)

2.2 读取数据集
尽管本⽂中AlexNet是在ImageNet上进⾏训练的,但我们在这⾥使⽤的是Fashion-MNIST数据集。因为即使在现代GPU上,训练ImageNet模型,同时使其收敛可能需要数小时或数天的时间。将AlexNet直接应⽤于Fashion-MNIST的⼀个问题是,Fashion-MNIST图像的分辨率( 28 × 28 28\times28 28×28像素)低于ImageNet图像。为了解决这个问题,我们将它们增加到 224 × 224 224\times224 224×224(通常来讲这不是⼀个明智的做法,但我们在这⾥这样做是为了有效使⽤AlexNet架构)。
# 数据集导入
batch_size = 256
resize = 224
transform = transforms.Compose([transforms.ToTensor(), transforms.Resize(resize)])
train_dataset = FashionMnistDataset('../dataset/fashion-mnist', 'train-images-idx3-ubyte.gz', 'train-labels-idx1-ubyte.gz', transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = FashionMnistDataset('../dataset/fashion-mnist', 't10k-images-idx3-ubyte.gz', 't10k-labels-idx1-ubyte.gz', transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
2.3 训练AlexNet
与上一节中的LeNet相⽐,这⾥的主要变化是使⽤更小的学习速率训练,这是因为⽹络更深更⼴、图像分辨率更⾼,训练卷积神经⽹络就更昂贵。
lr, num_epochs = 0.01, 10
d2l.train_ch6(Alexnet, train_loader, test_loader, num_epochs, lr, d2l.try_gpu())
# loss 0.402, train acc 0.853, test acc 0.859
# 3433.1 examples/sec on cuda:0
3 VGG
3.1 VGG块
经典卷积神经⽹络的基本组成部分是下⾯的这个序列:1. 带填充以保持分辨率的卷积层;1. ⾮线性激活函数,如ReLU;1. 汇聚层,如最⼤汇聚层。
而⼀个VGG块与之类似,由⼀系列卷积层组成,后⾯再加上⽤于空间下采样的最⼤汇聚层。在最初的VGG论⽂Simonyan & Zisserman, 2014中,作者使⽤了带有 3 × 3 3 \times 3 3×3卷积核、填充为1(保持⾼度和宽度)的卷积层,和带有 2 × 2 2 \times 2 2×2汇聚窗口、步幅为2(每个块后的分辨率减半)的最⼤汇聚层。在下⾯的代码中,定义了⼀个名为vgg_block的函数来实现⼀个VGG块。该函数有三个参数,分别对应于卷积层的数量num_convs、输⼊通道的数量in_channels 和输出通道的数量out_channels。
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
3.2 VGG网络
与AlexNet、LeNet⼀样,VGG⽹络可以分为两部分:第⼀部分主要由卷积层和汇聚层组成,第⼆部分由全连接层组成。网络结构如下图所示。
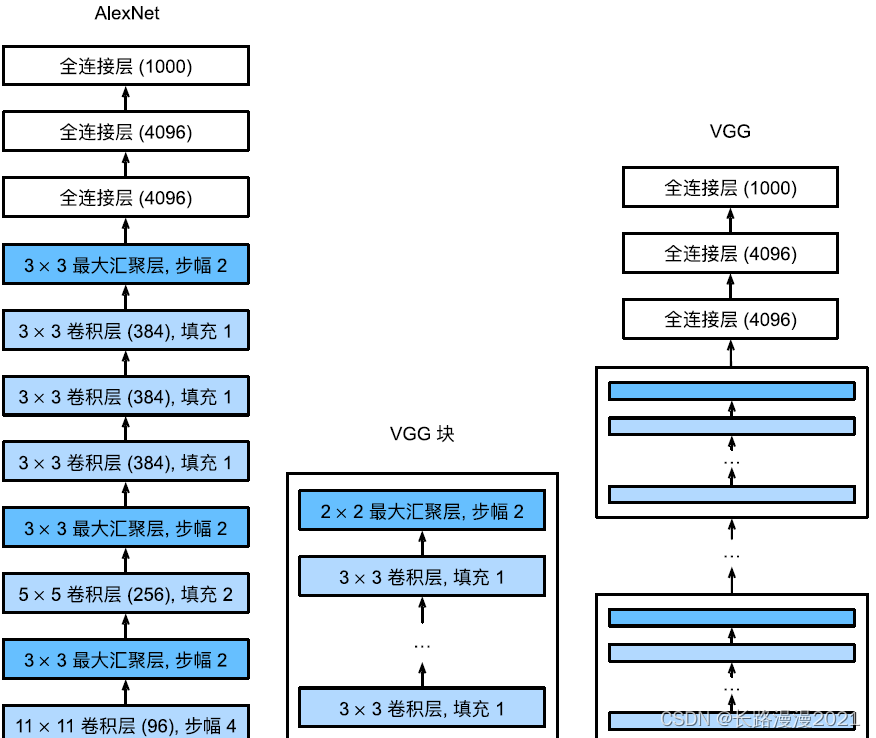
VGG神经⽹络连续连接上图的⼏个VGG块(在vgg_block函数中定义)。其中有超参数变量conv_arch。该变量指定了每个VGG块⾥卷积层个数和输出通道数。全连接模块则与AlexNet中的相同。
原始VGG⽹络有5个卷积块,其中前两个块各有⼀个卷积层,后三个块各包含两个卷积层。第⼀个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该⽹络使⽤8个卷积层和3个全连接层,因此它通常被称为VGG-11。下⾯的代码实现了VGG-11。可以通过在conv_arch上执⾏for循环来简单实现。
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
net = vgg(conv_arch)
接下来,构建⼀个⾼度和宽度为224的单通道数据样本,以观察每个层输出的形状。
X = torch.rand(size=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__, 'output shape:\t', X.shape)
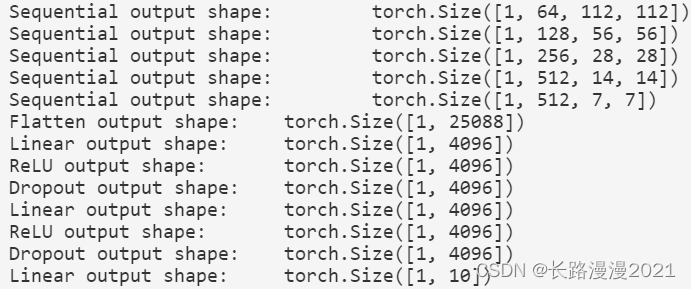
可以发现,在每个块的⾼度和宽度减半,最终⾼度和宽度都为7。最后再展平表⽰,送⼊全连接层处理。
3.3 训练模型
由于VGG-11⽐AlexNet计算量更⼤,因此我们构建了⼀个通道数较少的⽹络,⾜够⽤于训练Fashion-MNIST数据集。
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
模型训练过程与上一节的AlexNet类似。
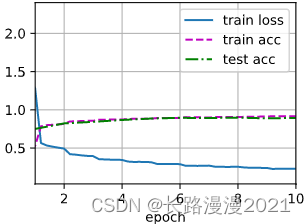
lr, num_epochs = 0.05, 10
d2l.train_ch6(net, train_loader, test_loader, num_epochs, lr, d2l.try_gpu())
# loss 0.228, train acc 0.917, test acc 0.894
# 1851.7 examples/sec on cuda:0
4 NiN
LeNet、AlexNet和VGG都有⼀个共同的设计模式:通过⼀系列的卷积层与汇聚层来提取空间结构特征;然后通过全连接层对特征的表征进⾏处理。AlexNet和VGG对LeNet的改进主要在于如何扩⼤和加深这两个模块。或者,可以想象在这个过程的早期使⽤全连接层。然而,如果使⽤了全连接层,可能会完全放弃表征的空间结构。⽹络中的⽹络(NiN)提供了⼀个⾮常简单的解决⽅案:在每个像素的通道上分别使⽤多层感知机。
4.1 NiN块
NiN的想法是在每个像素位置(针对每个⾼度和宽度)应⽤⼀个全连接层。如果我们将权重连接到每个空间位置,我们可以将其视为 1 × 1 1 \times 1 1×1卷积层,或作为在每个像素位置上独⽴作⽤的全连接层。从另⼀个⻆度看,即将空间维度中的每个像素视为单个样本,将通道维度视为不同特征(feature)。
下图说明了VGG和NiN及它们的块之间主要架构差异。NiN块以⼀个普通卷积层开始,后⾯是两个 1 × 1 1 \times 1 1×1的卷积层。这两个 1 × 1 1 \times 1 1×1卷积层充当带有ReLU激活函数的逐像素全连接层。第⼀层的卷积窗口形状通常由⽤⼾设置。随后的卷积窗口形状固定为 1 × 1 1 \times 1 1×1。
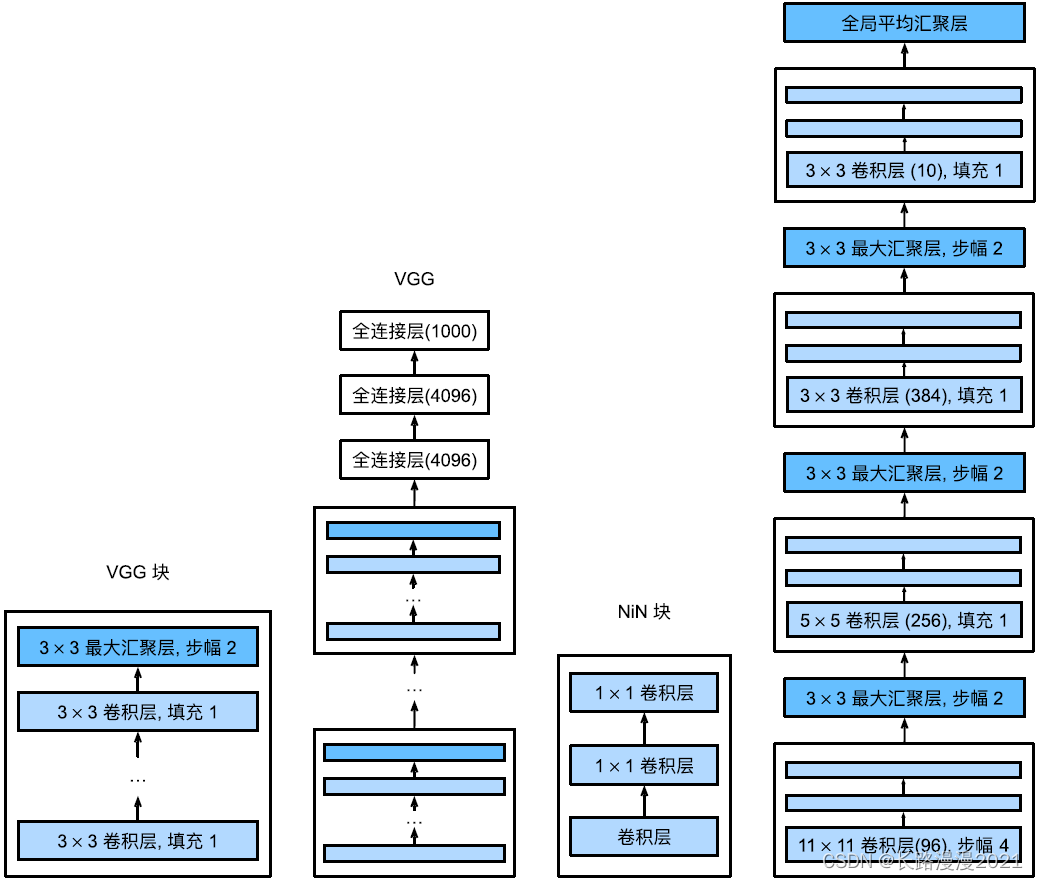
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
4.2 NiN模型
NiN使⽤窗口形状为 11 × 11 11\times11 11×11、 5 × 5 5\times5 5×5和 3 × 3 3\times3 3×3的卷积层,输出通道数量与AlexNet中的相同。每个NiN块后有⼀个最⼤汇聚层,汇聚窗口形状为 3 × 3 3 \times 3 3×3,步幅为2。
NiN和AlexNet之间的⼀个显著区别是NiN完全取消了全连接层。相反,NiN使⽤⼀个NiN块,其输出通道数等于标签类别的数量。最后放⼀个全局平均汇聚层(global average pooling layer),⽣成⼀个多元逻辑向量(logits)。NiN设计的⼀个优点是,它显著减少了模型所需参数的数量。然而,在实践中,这种设计有时会增加训练模型的时间。
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成⼆维的输出,其形状为(批量⼤⼩,10)
nn.Flatten())
创建⼀个数据样本来查看每个块的输出形状。
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)

4.3 训练模型
和以前⼀样,使⽤Fashion-MNIST来训练模型。训练NiN与训练AlexNet、VGG时相似。
lr, num_epochs = 0.1, 10
d2l.train_ch6(net, train_loader, test_loader, num_epochs, lr, d2l.try_gpu())
# loss 0.448, train acc 0.833, test acc 0.827
# 2613.3 examples/sec on cuda:0
5 GoogLeNet
在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)。这很可能得名于电影《盗梦空间》(Inception),因为电影中的⼀句话“我们需要走得更深”(“We need to go deeper”)。
5.1 Inception块
如下图所示,Inception块由四条并⾏路径组成。前三条路径使⽤窗口⼤小为 1 × 1 1\times1 1×1、 3 × 3 3\times3 3×3和 5 × 5 5\times5 5×5的卷积层,从不同空间⼤小中提取信息。中间的两条路径在输⼊上执⾏ 1 × 1 1 \times 1 1×1卷积,以减少通道数,从而降低模型的复杂性。第四条路径使⽤ 3 × 3 3 \times 3 3×3最⼤汇聚层,然后使⽤ 1 × 1 1 \times 1 1×1卷积层来改变通道数。这四条路径都使⽤合适的填充来使输⼊与输出的⾼和宽⼀致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道数。
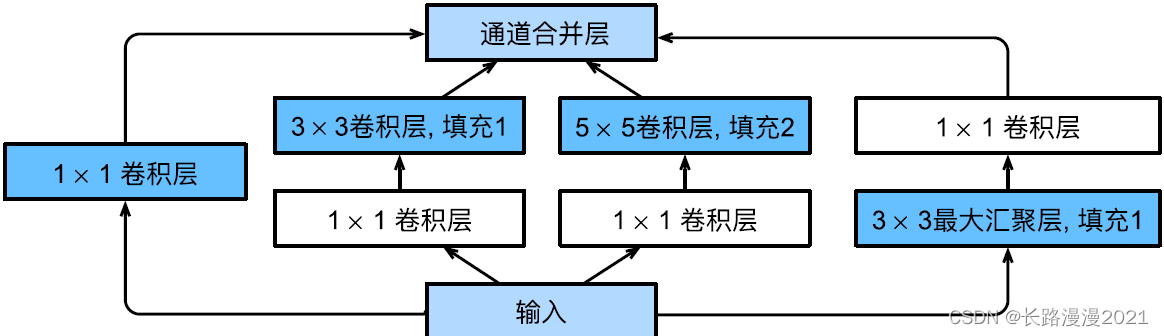
from torch.nn import functional as F
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1×1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最⼤汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
那么为什么GoogLeNet这个⽹络如此有效呢?⾸先我们考虑⼀下滤波器(filter)的组合,它们可以⽤各种滤波器尺⼨探索图像,这意味着不同⼤小的滤波器可以有效地识别不同范围的图像细节。同时,我们可以为不同的滤波器分配不同数量的参数。
5.2 GoogLeNet模型
GoogLeNet⼀共使⽤9个Inception块和全局平均汇聚层的堆叠来⽣成其估计值。Inception块之间的最⼤汇聚层可降低维度。第⼀个模块类似于AlexNet和LeNet,Inception块的组合从VGG继承,全局平均汇聚层避免了在最后使⽤全连接层。网络结构如下图所示。

逐⼀实现GoogLeNet的每个模块。第⼀个模块使⽤64个通道、 7 × 7 7 \times 7 7×7卷积层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第⼆个模块使⽤两个卷积层:第⼀个卷积层是64个通道、 1 × 1 1 \times 1 1×1卷积层;第⼆个卷积层使⽤将通道数量增加三倍的 3 × 3 3 \times 3 3×3卷积层。这对应于Inception块中的第⼆条路径。
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第三个模块串联两个完整的Inception块。第⼀个Inception块的输出通道数为64 + 128 + 32 + 32 = 256,四个路径之间的输出通道数量⽐为64 : 128 : 32 : 32 = 2 : 4 : 1 : 1。第⼆个和第三个路径⾸先将输⼊通道的数量分别减少到96/192 = 1/2和16/192 = 1/12,然后连接第⼆个卷积层。第⼆个Inception块的输出通道数增加到128 + 192 + 96 + 64 = 480,四个路径之间的输出通道数量⽐为128 : 192 : 96 : 64 = 4 : 6 : 3 : 2。第⼆条和第三条路径⾸先将输⼊通道的数量分别减少到128/256 = 1/2和32/256 = 1/8。
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第四模块更加复杂,它串联了5个Inception块,其输出通道数分别是192+208+48+64 = 512、160+224+64 + 64 = 512、128 + 256 + 64 + 64 = 512、112 + 288 + 64 + 64 = 528和256 + 320 + 128 + 128 = 832。这些路径的通道数分配和第三模块中的类似,⾸先是含3×3卷积层的第⼆条路径输出最多通道,其次是仅含1×1卷积层的第⼀条路径,之后是含5×5卷积层的第三条路径和含3×3最⼤汇聚层的第四条路径。其中第⼆、第三条路径都会先按⽐例减小通道数。这些⽐例在各个Inception块中都略有不同。
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
第五模块包含输出通道数为256 + 320 + 128 + 128 = 832和384 + 384 + 128 + 128 = 1024的两个Inception块。其中每条路径通道数的分配思路和第三、第四模块中的⼀致,只是在具体数值上有所不同。需要注意的是,第五模块的后⾯紧跟输出层,该模块同NiN⼀样使⽤全局平均汇聚层,将每个通道的⾼和宽变成1。最后我们将输出变成⼆维数组,再接上⼀个输出个数为标签类别数的全连接层。
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
GoogLeNet模型的计算复杂,而且不如VGG那样便于修改通道数。为了使Fashion-MNIST上的训练短小精悍,我们将输⼊的⾼和宽从224降到96,这简化了计算。下⾯演⽰各个模块输出的形状变化。
X = torch.rand(size=(1, 1, 96, 96))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)

5.3 训练模型
和以前⼀样,我们使⽤Fashion-MNIST数据集来训练我们的模型。在训练之前,我们将图⽚转换为 96 × 96 96 \times 96 96×96分辨率。
# 数据集导入,并更改尺寸
batch_size = 128
resize = 96
transform = transforms.Compose([transforms.ToTensor(), transforms.Resize(resize)])
train_dataset = FashionMnistDataset('../dataset/fashion-mnist', 'train-images-idx3-ubyte.gz', 'train-labels-idx1-ubyte.gz', transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = FashionMnistDataset('../dataset/fashion-mnist', 't10k-images-idx3-ubyte.gz', 't10k-labels-idx1-ubyte.gz', transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
lr, num_epochs = 0.1, 10
d2l.train_ch6(net, train_loader, test_loader, num_epochs, lr, d2l.try_gpu())
# loss 0.274, train acc 0.896, test acc 0.893
# 720.0 examples/sec on cuda:0
6 批量规范化
训练深层神经⽹络是⼗分困难的,特别是在较短的时间内使他们收敛更加棘⼿。在本节中,将介绍批量规范化(batch normalization),这是⼀种流⾏且有效的技术,可持续加速深层⽹络的收敛速度。
批量规范化应⽤于单个可选层(也可以应⽤到所有层),其原理如下:在每次训练迭代中,⾸先规范化输⼊,即通过减去其均值并除以其标准差,其中两者均基于当前小批量处理。接下来,应⽤⽐例系数和⽐例偏移。正是由于这个基于批量统计的标准化,才有了批量规范化的名称。
请注意,如果我们尝试使⽤⼤小为1的小批量应⽤批量规范化,我们将⽆法学到任何东西。这是因为在减去均值之后,每个隐藏单元将为0。所以,只有使⽤⾜够⼤的小批量,批量规范化这种⽅法才是有效且稳定的。请注意,在应⽤批量规范化时,批量⼤小的选择可能⽐没有批量规范化时更重要。
从形式上来说,⽤ x ∈ B \pmb{x} \in \mathcal{B} xxx∈B表⽰⼀个来⾃小批量 B \mathcal{B} B的输⼊,批量规范化BN根据以下表达式转换 x \pmb{x} xxx:
BN ( x ) = γ ⊙ x − μ ^ B σ ^ B + β \operatorname{BN}(\mathbf{x})=\gamma \odot \frac{\mathbf{x}-\hat{\boldsymbol{\mu}}_{\mathcal{B}}}{\hat{\sigma}_{\mathcal{B}}}+\beta BN(x)=γ⊙σ^Bx−μ^B+β
式中, μ ^ B \hat{\boldsymbol{\mu}}_{\mathcal{B}} μ^B是样本均值, σ ^ B \hat{\sigma}_{\mathcal{B}} σ^B是小批量 B \mathcal{B} B的样本标准差。应⽤标准化后,⽣成的小批量的平均值为0和单位⽅差为1。由于单位⽅差(与其他⼀些魔法数)是⼀个任意的选择,因此我们通常包含拉伸参数(scale) γ \gamma γ和偏移参数(shift) β \beta β,它们的形状与 x \pmb{x} xxx相同。请注意, γ \gamma γ和 β \beta β是需要与其他模型参数⼀起学习的参数。由于在训练过程中,中间层的变化幅度不能过于剧烈,而批量规范化将每⼀层主动居中,并将它们重新调整为给定的平均值和⼤小(通过 μ ^ B \hat{\boldsymbol{\mu}}_{\mathcal{B}} μ^B和 σ ^ B \hat{\sigma}_{\mathcal{B}} σ^B)。
下面计算 μ ^ B \hat{\boldsymbol{\mu}}_{\mathcal{B}} μ^B和 σ ^ B \hat{\sigma}_{\mathcal{B}} σ^B,如下所示:
μ ^ B = 1 ∣ B ∣ ∑ x ∈ B x σ ^ B 2 = 1 ∣ B ∣ ∑ x ∈ B ( x − μ ^ B ) 2 + ϵ \hat{\boldsymbol{\mu}}_{\mathcal{B}}=\frac{1}{|\mathcal{B}|}\sum_{\pmb{x} \in \mathcal{B}}\pmb{x}\\ \hat{\sigma}_{\mathcal{B}}^2=\frac{1}{|\mathcal{B}|}\sum_{\pmb{x} \in \mathcal{B}}(\pmb{x}-\hat{\boldsymbol{\mu}}_{\mathcal{B}})^2+\epsilon μ^B=∣B∣1xxx∈B∑xxxσ^B2=∣B∣1xxx∈B∑(xxx−μ^B)2+ϵ
请注意,我们在⽅差估计值中添加⼀个小常量 ϵ > 0 \epsilon>0 ϵ>0,以确保我们永远不会尝试除以零,即使在经验⽅差估计值可能消失的情况下也是如此。
6.1 批量规范化层
1. 全连接层
通常,我们将批量规范化层置于全连接层中的仿射变换和激活函数之间。设全连接层的输⼊为 u \pmb{u} uuu,权重参数和偏置参数分别为 W \pmb{W} WWW和 b \pmb{b} bbb,激活函数为 ϕ \phi ϕ,批量规范化的运算符为BN。那么,使⽤批量规范化的全连接层的输出的计算详情如下:
h = ϕ ( BN ( W x + b ) ) \mathbf{h}=\phi(\operatorname{BN}(\mathbf{W} \mathbf{x}+\mathbf{b})) h=ϕ(BN(Wx+b))
2. 卷积层
对于卷积层,我们可以在卷积层之后和⾮线性激活函数之前应⽤批量规范化。当卷积有多个输出通道时,我们需要对这些通道的“每个”输出执⾏批量规范化,每个通道都有⾃⼰的拉伸(scale)和偏移(shift)参数,这两个参数都是标量。假设我们的微批次包含m个⽰例,并且对于每个通道,卷积的输出具有⾼度p和宽度q。那么对于卷积层,我们在每个输出通道的 m × p × q m \times p \times q m×p×q个元素上同时执⾏每个批量规范化。因此,在计算平均值和⽅差时,我们会收集所有空间位置的值,然后在给定通道内应⽤相同的均值和⽅差,以便在每个空间位置对值进⾏规范化。
3. 预测过程中的批量规范化
批量规范化在训练模式和预测模式下的⾏为通常不同。⾸先,将训练好的模型⽤于预测时,不再需要样本均值中的噪声以及在微批次上估计每个小批次产⽣的样本⽅差了。其次,例如,我们可能需要使⽤我们的模型对逐个样本进⾏预测。⼀种常⽤的⽅法是通过移动平均估算整个训练数据集的样本均值和⽅差,并在预测时使⽤它们得到确定的输出。
6.2 从零实现
从头开始实现⼀个具有张量的批量规范化层。
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使⽤传⼊的移动平均所得的均值和⽅差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使⽤⼆维卷积层的情况,计算通道维上(axis=1)的均值和⽅差。
# 这⾥我们需要保持X的形状以便后⾯可以做⼴播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# 训练模式下,⽤当前的均值和⽅差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data
现在可以创建⼀个正确的BatchNorm图层。这个层将保持适当的参数:拉伸gamma和偏移beta,这两个参数将在训练过程中更新。此外,我们的图层将保存均值和⽅差的移动平均值,以便在模型预测期间随后使⽤。
class BatchNorm(nn.Module):
# num_features:完全连接层的输出数量或卷积层的输出通道数。
# num_dims:2表⽰完全连接层,4表⽰卷积层
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# ⾮模型参数的变量初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var
# 复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = batch_norm(X, self.gamma, self.beta, self.moving_mean, self.moving_var, eps=1e-5, momentum=0.9)
return Y
6.3 使⽤批量规范化层的LeNet
下⾯我们将BatchNorm应⽤于LeNet模型。
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),
nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),
nn.Linear(84, 10))
和以前⼀样,我们将在Fashion-MNIST数据集上训练⽹络。这个代码与我们第⼀次训练LeNet(第一节)时⼏乎完全相同,主要区别在于学习率⼤得多。
lr, num_epochs = 1.0, 10
d2l.train_ch6(net, train_loader, test_loader, num_epochs, lr, d2l.try_gpu())
# loss 0.260, train acc 0.905, test acc 0.874
# 29144.9 examples/sec on cuda:0
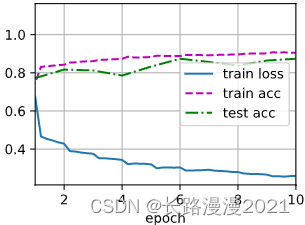
下面来看看从第⼀个批量规范化层中学到的拉伸参数gamma和偏移参数beta。
net[1].gamma.reshape((-1,)), net[1].beta.reshape((-1,))

6.4 简明实现
可以直接使⽤深度学习框架中定义的BatchNorm。
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16*4*4, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),
nn.Linear(84, 10))
lr, num_epochs = 1.0, 10
d2l.train_ch6(net, train_loader, test_loader, num_epochs, lr, d2l.try_gpu())
# loss 0.267, train acc 0.901, test acc 0.883
# 53287.4 examples/sec on cuda:0
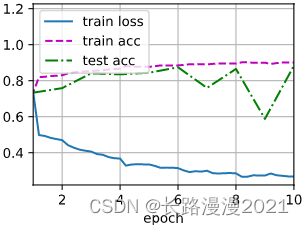
这里我们使⽤相同超参数来训练模型。请注意,通常⾼级API变体运⾏速度快得多,因为它的代码已编译为C++或CUDA,而我们的⾃定义代码由Python实现。
7 ResNet
7.1 残差块
聚焦于神经⽹络局部:如下图所⽰,假设我们的原始输⼊为 x \pmb{x} xxx,而希望学出的理想映射为 f ( x ) f(\pmb{x}) f(xxx)。下图左图虚线框中的部分需要直接拟合出该映射 f ( x ) f(\pmb{x}) f(xxx),而右图虚线框中的部分则需要拟合出残差映射 f ( x ) − x f(\pmb{x})-\pmb{x} f(xxx)−xxx。残差映射在现实中往往更容易优化。实际中,当理想映射 f ( x ) f(\pmb{x}) f(xxx)极接近于恒等映射时,残差映射也易于捕捉恒等映射的细微波动。下图右图是ResNet的基础架构‒残差块(residual block)。在残差块中,输⼊可通过跨层数据线路更快地向前传播。

ResNet沿⽤了VGG完整的 3 × 3 3 \times 3 3×3卷积层设计。残差块⾥⾸先有2个有相同输出通道数的 3 × 3 3 \times 3 3×3卷积层。每个卷积层后接⼀个批量规范化层和ReLU激活函数。然后我们通过跨层数据通路,跳过这2个卷积运算,将输⼊直接加在最后的ReLU激活函数前。这样的设计要求2个卷积层的输出与输⼊形状⼀样,从而使它们可以相加。如果想改变通道数,就需要引⼊⼀个额外的 1 × 1 1\times1 1×1卷积层来将输⼊变换成需要的形状后再做相加运算。残差块的实现如下:
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
此代码⽣成两种类型的⽹络:⼀种是在use_1x1conv=False、应⽤ReLU⾮线性函数之前,将输⼊添加到输出。另⼀种是在use_1x1conv=True时,添加通过 1 × 1 1 \times 1 1×1卷积调整通道和分辨率。

下⾯来查看输⼊和输出形状⼀致的情况。
blk = Residual(3, 3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape # torch.Size([4, 3, 6, 6])
也可以在增加输出通道数的同时,减半输出的⾼和宽。
blk = Residual(3, 6, use_1x1conv=True, strides=2)
blk(X).shape # torch.Size([4, 6, 3, 3])
7.2 ResNet模型
ResNet的前两层跟之前介绍的GoogLeNet中的⼀样:在输出通道数为64、步幅为2的 7 × 7 7 \times 7 7×7卷积层后,接步幅为2的 3 × 3 3 \times 3 3×3的最⼤汇聚层。不同之处在于ResNet每个卷积层后增加了批量规范化层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
GoogLeNet在后⾯接了4个由Inception块组成的模块。ResNet则使⽤4个由残差块组成的模块,每个模块使⽤若⼲个同样输出通道数的残差块。第⼀个模块的通道数同输⼊通道数⼀致。由于之前已经使⽤了步幅为2的最⼤汇聚层,所以⽆须减小⾼和宽。之后的每个模块在第⼀个残差块⾥将上⼀个模块的通道数翻倍,并将⾼和宽减半。下⾯来实现这个模块。注意,这里对第⼀个模块做了特别处理。
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
接着在ResNet加⼊所有残差块,这⾥每个模块使⽤2个残差块。
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
最后,与GoogLeNet⼀样,在ResNet中加⼊全局平均汇聚层,以及全连接层输出。
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
每个模块有4个卷积层(不包括恒等映射的 1 × 1 1 \times 1 1×1卷积层)。加上第⼀个 7 × 7 7 \times 7 7×7卷积层和最后⼀个全连接层,共有18层。因此,这种模型通常被称为ResNet-18。通过配置不同的通道数和模块⾥的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。虽然ResNet的主体架构跟GoogLeNet类似,但ResNet架构更简单,修改也更⽅便。这些因素都导致了ResNet迅速被⼴泛使⽤。下图描述了完整的ResNet-18。
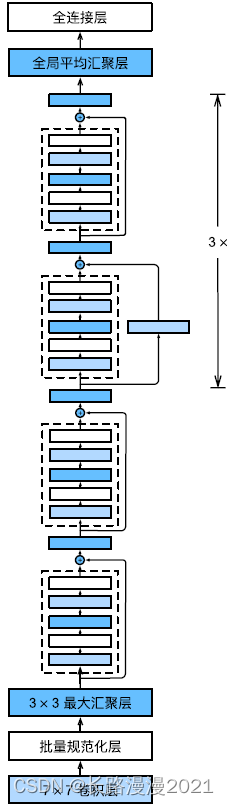
X = torch.rand(1, 1, 224, 224)
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)

7.3 训练模型
在Fashion-MNIST数据集上训练ResNet。
lr, num_epochs = 0.05, 10
d2l.train_ch6(net, train_loader, test_loader, num_epochs, lr, d2l.try_gpu())
# loss 0.020, train acc 0.995, test acc 0.909
# 847.8 examples/sec on cuda:0

8 DenseNet
8.1 从ResNet到DenseNet
回想⼀下任意函数的泰勒展开式(Taylor expansion),它把这个函数分解成越来越⾼阶的项。在x接近0时,
f ( x ) = f ( 0 ) + f ′ ( 0 ) x + f ′ ′ ( 0 ) 2 ! x 2 + f ′ ′ ′ ( 0 ) 3 ! x 3 + … f(x)=f(0)+f^{\prime}(0) x+\frac{f^{\prime \prime}(0)}{2 !} x^{2}+\frac{f^{\prime \prime \prime}(0)}{3 !} x^{3}+\ldots f(x)=f(0)+f′(0)x+2!f′′(0)x2+3!f′′′(0)x3+…
同样,ResNet将函数展开为
f ( x ) = x + g ( x ) f(\pmb{x}) = \pmb{x} + g(\pmb{x}) f(xxx)=xxx+g(xxx)
也就是说,ResNet将f分解为两部分:⼀个简单的线性项和⼀个复杂的⾮线性项。那么再向前拓展⼀步,如果我们想将f拓展成超过两部分的信息呢?⼀种⽅案便是DenseNet。
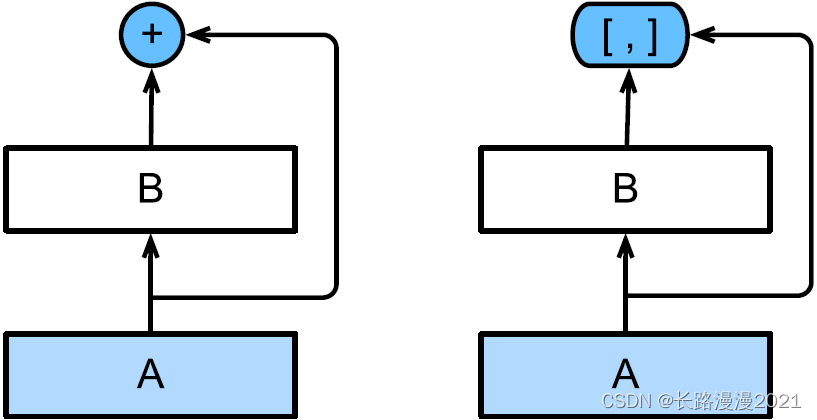
如上图所示,ResNet和DenseNet的关键区别在于,DenseNet输出是连接(⽤图中的[; ]表⽰)而不是如ResNet的简单相加。因此,在应⽤越来越复杂的函数序列后,我们执⾏从x到其展开式的映射:
x → [ x , f 1 ( x ) , f 2 ( [ x , f 1 ( x ) ] ) , f 3 ( [ x , f 1 ( x ) , f 2 ( [ x , f 1 ( x ) ] ) ] ) , … ] \mathbf{x} \rightarrow\left[\mathbf{x}, f_{1}(\mathbf{x}), f_{2}\left(\left[\mathbf{x}, f_{1}(\mathbf{x})\right]\right), f_{3}\left(\left[\mathbf{x}, f_{1}(\mathbf{x}), f_{2}\left(\left[\mathbf{x}, f_{1}(\mathbf{x})\right]\right)\right]\right), \ldots\right] x→[x,f1(x),f2([x,f1(x)]),f3([x,f1(x),f2([x,f1(x)])]),…]
最后,将这些展开式结合到多层感知机中,再次减少特征的数量。实现起来⾮常简单:我们不需要添加术语,而是将它们连接起来。DenseNet这个名字由变量之间的“稠密连接”而得来,最后⼀层与之前的所有层紧密相连。稠密连接如下图所⽰。

稠密⽹络主要由2部分构成:稠密块(dense block)和过渡层(transition layer)。前者定义如何连接输⼊和输出,而后者则控制通道数量,使其不会太复杂。
8.2 稠密块体
DenseNet使⽤了ResNet改良版的“批量规范化、激活和卷积”架构。
def conv_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1))
⼀个稠密块由多个卷积块组成,每个卷积块使⽤相同数量的输出通道。然而,在前向传播中,我们将每个卷积块的输⼊和输出在通道维上连结。
class DenseBlock(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
super(DenseBlock, self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block(num_channels * i + input_channels, num_channels))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
# 连接通道维度上每个块的输⼊和输出
X = torch.cat((X, Y), dim = 1)
return X
在下⾯的例⼦中,我们定义⼀个有2个输出通道数为10的DenseBlock。使⽤通道数为3的输⼊时,我们会得到通道数为 3 + 2 × 10 = 23 3 + 2 \times 10 = 23 3+2×10=23的输出。卷积块的通道数控制了输出通道数相对于输⼊通道数的增⻓,因此也被称为增⻓率(growth rate)。
blk = DenseBlock(2, 3, 10)
X = torch.randn(4, 3, 8, 8)
Y = blk(X)
Y.shape
8.3 过渡层
由于每个稠密块都会带来通道数的增加,使⽤过多则会过于复杂化模型。而过渡层可以⽤来控制模型复杂度。它通过 1 × 1 1 \times 1 1×1卷积层来减小通道数,并使⽤步幅为2的平均汇聚层减半⾼和宽,从而进⼀步降低模型复杂度。
def transition_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2))
对上⼀个例⼦中稠密块的输出使⽤通道数为10的过渡层。此时输出的通道数减为10,⾼和宽均减半。
blk = transition_block(23, 10)
blk(Y).shape
8.4 DenseNet模型
我们来构造DenseNet模型。DenseNet⾸先使⽤同ResNet⼀样的单卷积层和最⼤汇聚层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
接下来,类似于ResNet使⽤的4个残差块,DenseNet使⽤的是4个稠密块。与ResNet类似,我们可以设置每个稠密块使⽤多少个卷积层。这⾥我们设成4,从而与上一节的ResNet-18保持⼀致。稠密块⾥的卷积层通道数(即增⻓率)设为32,所以每个稠密块将增加128个通道。
在每个模块之间,ResNet通过步幅为2的残差块减小⾼和宽,DenseNet则使⽤过渡层来减半⾼和宽,并减半通道数。
num_channels, growth_rate = 64, 32
num_convs_in_dense_blocks = [4, 4, 4, 4]
blks = []
for i, num_convs in enumerate(num_convs_in_dense_blocks):
blks.append(DenseBlock(num_convs, num_channels, growth_rate))
# 上⼀个稠密块的输出通道数
num_channels += num_convs * growth_rate
# 在稠密块之间添加⼀个转换层,使通道数量减半
if i != len(num_convs_in_dense_blocks) - 1:
blks.append(transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
与ResNet类似,最后接上全局汇聚层和全连接层来输出结果。
net = nn.Sequential(
b1, *blks,
nn.BatchNorm2d(num_channels), nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(num_channels, 10))
8.5 训练模型
由于这⾥使⽤了⽐较深的⽹络,本节⾥我们将输⼊⾼和宽从224降到96来简化计算。
# 数据集导入
batch_size = 256
resize = 96
transform = transforms.Compose([transforms.ToTensor(), transforms.Resize(resize)])
train_dataset = FashionMnistDataset('../dataset/fashion-mnist', 'train-images-idx3-ubyte.gz', 'train-labels-idx1-ubyte.gz', transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = FashionMnistDataset('../dataset/fashion-mnist', 't10k-images-idx3-ubyte.gz', 't10k-labels-idx1-ubyte.gz', transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
lr, num_epochs = 0.1, 10
d2l.train_ch6(net, train_loader, test_loader, num_epochs, lr, d2l.try_gpu())
# loss 0.141, train acc 0.949, test acc 0.848
# 4122.0 examples/sec on cuda:0
完美撒花~虽然只是把教材上的代码重新敲了一遍,但加深了很多技术细节的理解,进一寸有一寸的欢喜,大家一起加油哈!
边栏推荐
- 二、并发、测试笔记 青训营笔记
- Talk about seven ways to realize asynchronous programming
- Simple example of ros2 planning system plansys2
- 抽丝剥茧C语言(高阶)指针的进阶
- [cloud native] how to give full play to memory advantage of memory database
- Tumor immunotherapy research prosci Lag3 antibody solution
- 抽丝剥茧C语言(高阶)指针进阶练习
- 外包干了四年,废了...
- Outsourcing for three years, abandoned
- 计算机服务中缺失MySQL服务
猜你喜欢
Robot technology innovation and practice old version outline

【Liunx】进程控制和父子进程
【leetcode】1020. Number of enclaves
ROS2规划系统plansys2简单的例子

1142_ SiCp learning notes_ Functions and processes created by functions_ Linear recursion and iteration

一、Go知识查缺补漏+实战课程笔记 | 青训营笔记

三、高质量编程与性能调优实战 青训营笔记
抽絲剝繭C語言(高階)指針的進階
Make a bat file for cleaning system garbage
关于二进制无法精确表示小数
随机推荐
About binary cannot express decimals accurately
JS small exercise ---- time sharing reminder and greeting, form password display hidden effect, text box focus event, closing advertisement
Flexible layout (II)
考研失败,卷不进大厂,感觉没戏了
Causes and solutions of oom (memory overflow)
Fast quantitative, abbkine protein quantitative kit BCA method is coming!
How to reduce inventory with high concurrency on the Internet
【leetcode】1020. Number of enclaves
[ANSYS] learning experience of APDL finite element analysis
Leetcode-543. Diameter of Binary Tree
解决could not find or load the Qt platform plugin “xcb“in ““.
resource 创建包方式
Lm11 reconstruction of K-line and construction of timing trading strategy
按键精灵脚本学习-关于天猫抢红包
Wechat applet full stack development practice Chapter 3 Introduction and use of APIs commonly used in wechat applet development -- 3.10 tabbar component (I) how to open and use the default tabbar comp
Software acceptance test
Music | cat and mouse -- classic not only plot
我理想的软件测试人员发展状态
After 95, Alibaba P7 published the payroll: it's really fragrant to make up this
修改Jupyter Notebook文件路径