当前位置:网站首页>Paper notes: graph neural network gat
Paper notes: graph neural network gat
2022-07-06 02:14:00 【Min fan】
Abstract : Share your understanding of the paper . See the original Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, Yoshua Bengio, Graph attention networks, ICLR 2018, 1–12. Can be in ArXiv: 1710.10903v3 download . It's completely difficult to estimate the influence !
1. Contribution of thesis
- Overcome the shortcomings of the existing methods of graph convolution .
- No time-consuming matrix operation ( Such as inverse ).
- There is no need to predict the structure of the graph .
- Applicable to inductive and deductive problems .
2. Basic ideas
Use neighbor information , Map the original attributes of the nodes in the graph to a new space , To support later learning tasks .
This idea may be common to different graph Neural Networks .
3. programme
| Symbol | meaning | remarks |
|---|---|---|
| N N N | Number of nodes | |
| F F F | Original feature number | |
| F ′ F' F′ | Original feature number | In the example 4 |
| h \mathbf{h} h | Node feature set | { h → 1 , … , h → N } \{\overrightarrow{h}_1,\dots, \overrightarrow{h}_N \} { h1,…,hN} |
| h → i \overrightarrow{h}_i hi | The first i i i Characteristics of nodes | Belong to space R F \mathbb{R}^F RF |
| h ′ \mathbf{h}' h′ | Node new feature set | { h → 1 ′ , … , h → N ′ } \{\overrightarrow{h}'_1,\dots, \overrightarrow{h}'_N \} { h1′,…,hN′} |
| h → i ′ \overrightarrow{h}'_i hi′ | The first i i i New features of nodes | Belong to space R F ′ \mathbb{R}^{F'} RF′ |
| W \mathbf{W} W | Characteristic mapping matrix | Belong to R F × F ′ \mathbb{R}^{F \times F'} RF×F′, All nodes share |
| N i \mathcal{N}_i Ni | node i i i The neighborhood set of | Include i i i own , In the example, the cardinality is 6 |
| a → \overrightarrow{\mathbf{a}} a | Feature weight vector | Belong to R 2 F ′ \mathbb{R}^{2F'} R2F′, All nodes share , Corresponding to single-layer network |
| α i j \alpha_{ij} αij | node j j j Yes i i i Influence | The sum of the influences of all neighbor nodes is 1 |
| α → i j \overrightarrow{\alpha}_{ij} αij | node j j j Yes i i i Influence vector of | The length is K K K, Corresponding to the bull |
Map node features to the new space , Using the attention mechanism a a a Calculate the relationship between nodes
e i j = a ( W h → i , W h → j ) (1) e_{ij} = a(\mathbf{W}\overrightarrow{h}_i, \mathbf{W}\overrightarrow{h}_j) \tag{1} eij=a(Whi,Whj)(1)
Here only if j j j yes i i i When you are a neighbor on the network , Only calculated e i j e_{ij} eij.
Carry it on softmax, Make nodes i i i The corresponding weight sum is 1.
α i j = s o f t m a x j ( e i j ) = exp ( e i j ) ∑ k ∈ N i exp ( e i k ) (2) \alpha_{ij} = \mathrm{softmax}_j(e_{ij}) = \frac{\exp(e_{ij})}{\sum_{k \in \mathcal{N}_i} \exp(e_{ik})}\tag{2} αij=softmaxj(eij)=∑k∈Niexp(eik)exp(eij)(2)
because a a a The length will be 2 F ′ 2F' 2F′ The column vector of is converted to a scalar , It can be written as a line vector of the same length a → T \overrightarrow{\mathbf{a}}^{\mathrm{T}} aT. Plus an activation function , It can be realized with a single-layer neural network .
α i j = exp ( L e a k y R e L u ( a → T [ W h → i ∥ W h → j ] ) ) ∑ k ∈ N i exp ( L e a k y R e L u ( a → T [ W h → i ∥ W h → k ] ) ) (2) \alpha_{ij} = \frac{\exp(\mathrm{LeakyReLu}(\overrightarrow{\mathbf{a}}^{\mathrm{T}}[\mathbf{W}\overrightarrow{h}_i \| \mathbf{W}\overrightarrow{h}_j]))}{\sum_{k \in \mathcal{N}_i} \exp(\mathrm{LeakyReLu}(\overrightarrow{\mathbf{a}}^{\mathrm{T}}[\mathbf{W}\overrightarrow{h}_i \| \mathbf{W}\overrightarrow{h}_k]))}\tag{2} αij=∑k∈Niexp(LeakyReLu(aT[Whi∥Whk]))exp(LeakyReLu(aT[Whi∥Whj]))(2)
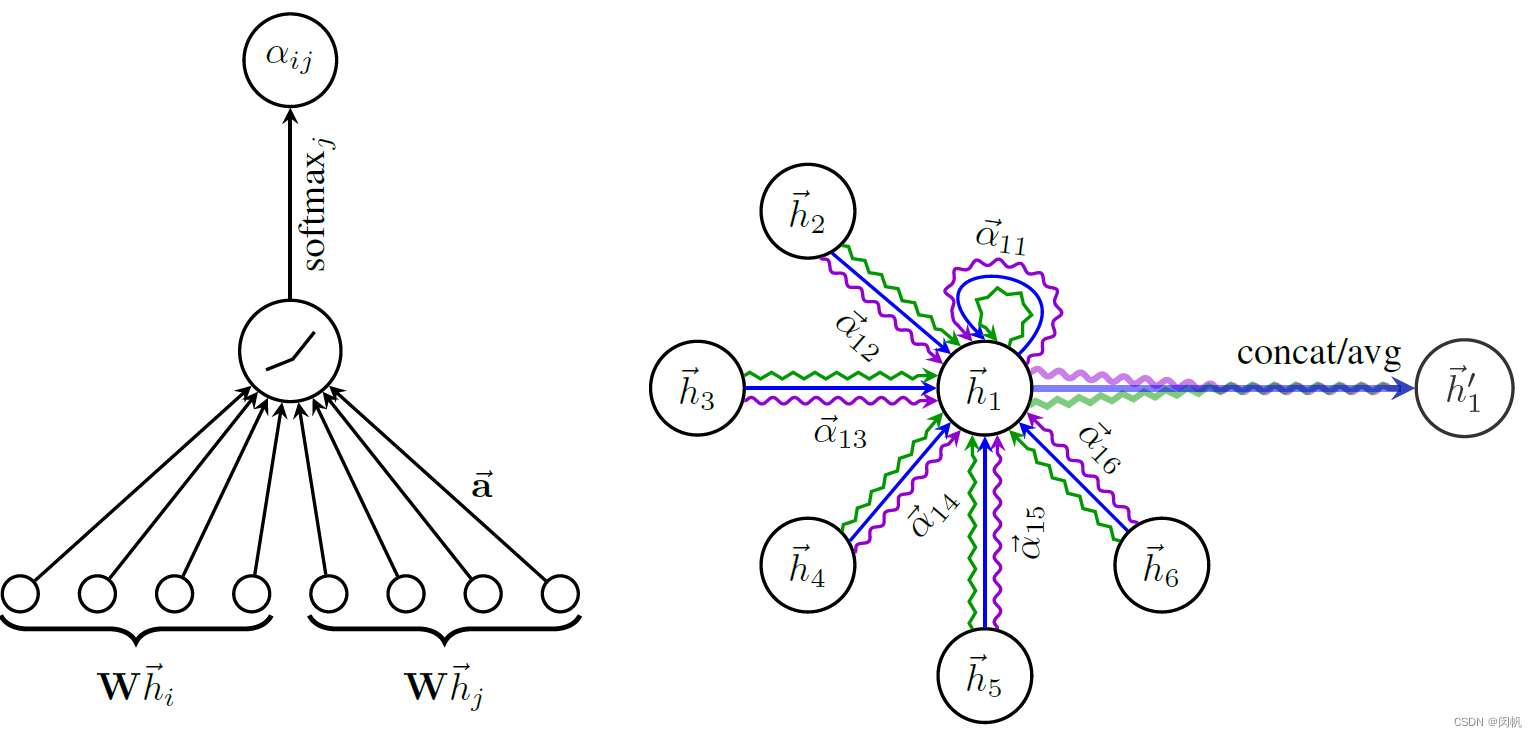
chart 1. GAT Core program . Left : F ′ = 4 F' = 4 F′=4 When , from W \mathbf{W} W The new space mapped to is 4 dimension . Corresponding 2 F ′ = 8 2F' = 8 2F′=8 dimension . vector a → \overrightarrow{\mathbf{a}} a Shared by all nodes . Right : K = 3 K = 3 K=3 Head .
3.1 Scheme 1 : Single head
h → i ′ = σ ( ∑ j ∈ i α i j W h → j ) (4) \overrightarrow{h}'_i = \sigma\left(\sum_{j \in \mathcal{i}} \alpha_{ij} \mathbf{W} \overrightarrow{h}_j\right)\tag{4} hi′=σ(j∈i∑αijWhj)(4)
All neighbor nodes are mapped to the new space first ( Such as 4 dimension ), Then the weighted sum is calculated according to its influence , And use sigmoid Isononlinear activation function , What you finally get is 4 Dimension vector .
3.2 Option two : Multi head connection
h → i ′ = ∥ k = 1 K σ ( ∑ j ∈ N i α i j k W k h → j ) (5) \overrightarrow{h}'_i = \|_{k = 1}^K \sigma\left(\sum_{j \in \mathcal{N}_i} \alpha^k_{ij} \mathbf{W}^k \overrightarrow{h}_j\right)\tag{5} hi′=∥k=1Kσ⎝⎛j∈Ni∑αijkWkhj⎠⎞(5)
K K K Get the corresponding new vectors respectively , chart 1 The right shows 3 Head , So the last vector is 3 × 4 = 12 3 \times 4 = 12 3×4=12 dimension .
3.3 Option three : Long average
h → i ′ = σ ( 1 K ∑ k = 1 K ∑ j ∈ N i α i j k W k h → j ) (5) \overrightarrow{h}'_i = \sigma \left(\frac{1}{K} \sum_{k = 1}^K \sum_{j \in \mathcal{N}_i} \alpha^k_{ij} \mathbf{W}^k \overrightarrow{h}_j\right)\tag{5} hi′=σ⎝⎛K1k=1∑Kj∈Ni∑αijkWkhj⎠⎞(5)
Just average , The last vector is 4 4 4 dimension .
4. doubt
problem : there W \mathbf{W} W And a → \overrightarrow{\mathbf{a}} a How to learn ?
guess : From related work , That is, the necessary knowledge is obtained in the graph neural network . This paper just wants to describe different core technologies .
If the output of this network is used as the input of other networks ( The final output is class labels, etc ), It is possible to learn accordingly .
Tang Wentao's explanation : In essence, it is equivalent to matrix multiplication ( Linear regression ), You can see from the code of the paper : In the training phase , The whole training set is entered ( Characteristic matrix and adjacency matrix of samples ), adopt W \mathbf{W} W and a → \overrightarrow{\mathbf{a}} a Get the prediction label of the training set ( First, get the self attention weight of each sample for all samples , Then according to the adjacency matrix mask, Then normalize the weight as a layer of self attention ), Then proceed loss Calculation and dissemination of .problem : Why use when calculating influence LeakyReLU, When calculating the final eigenvector sigmoid?
Force to explain : The former is only different from the latter ( It's not necessary ), The latter is to change linearity ( It is necessary to ).
Tang Wentao's explanation : Calculate influence using LeakyReLU: Pay more attention to the neighbor nodes that are more positively related to the target node .
The final eigenvector uses sigmoid It should be to prevent the value from being too large , Affect the next level of learning , Because the self attention mechanism is relatively unstable ( From my previous experiments ), High requirements for the range and density of values ( Small scope :0-1 And so on , More dense ).
Besides , stay GAT The source code given in the paper can be seen , The author uses only two layers of self attention network for all data sets , also dropout All set to 0.5-0.8, It can be seen that it is easier to over fit .
5. Summary
- utilize W \mathbf{W} W Linear mapping to new space .
- utilize a → \overrightarrow{\mathbf{a}} a Calculate the influence of each neighbor α i j \alpha_{ij} αij. a → \overrightarrow{\mathbf{a}} a Only for the corresponding attribute , Not affected by neighbor number . α i j \alpha_{ij} αij The calculation of involves LeakyReLU Use of activation functions .
- Use bulls to increase stability .
- Calculating mean 、 Using nonlinear function activation will not change the dimension of the vector .
边栏推荐
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
- Redis daemon cannot stop the solution
- leetcode3、实现 strStr()
- 一题多解,ASP.NET Core应用启动初始化的N种方案[上篇]
- NLP fourth paradigm: overview of prompt [pre train, prompt, predict] [Liu Pengfei]
- Use Scrollview and tabhost to realize vertical scrollbars and tabs
- Sword finger offer 38 Arrangement of strings
- Apicloud openframe realizes the transfer and return of parameters to the previous page - basic improvement
- VIM usage guide
- NiO related knowledge (II)
猜你喜欢
![[ssrf-01] principle and utilization examples of server-side Request Forgery vulnerability](/img/43/a8f302eb69beff4037aadda808f886.png)
[ssrf-01] principle and utilization examples of server-side Request Forgery vulnerability
It's wrong to install PHP zbarcode extension. I don't know if any God can help me solve it. 7.3 for PHP environment

NumPy 数组索引 切片
同一个 SqlSession 中执行两条一模一样的SQL语句查询得到的 total 数量不一样
Computer graduation design PHP enterprise staff training management system

Selenium waiting mode
在线怎么生成富文本
Redis如何实现多可用区?
Online reservation system of sports venues based on PHP

02. Go language development environment configuration
随机推荐
Computer graduation design PHP college student human resources job recruitment network
02. Go language development environment configuration
Gbase 8C database upgrade error
1. Introduction to basic functions of power query
Redis守护进程无法停止解决方案
通过PHP 获取身份证相关信息 获取生肖,获取星座,获取年龄,获取性别
正则表达式:示例(1)
插卡4G工业路由器充电桩智能柜专网视频监控4G转以太网转WiFi有线网速测试 软硬件定制
Flutter Doctor:Xcode 安装不完整
SPI communication protocol
Global and Chinese markets of general purpose centrifuges 2022-2028: Research Report on technology, participants, trends, market size and share
[solution] every time idea starts, it will build project
Leetcode3, implémenter strstr ()
Text editing VIM operation, file upload
leetcode-两数之和
I like Takeshi Kitano's words very much: although it's hard, I will still choose that kind of hot life
Jisuanke - t2063_ Missile interception
[Clickhouse] Clickhouse based massive data interactive OLAP analysis scenario practice
Unity learning notes -- 2D one-way platform production method
Virtual machine network, networking settings, interconnection with host computer, network configuration