当前位置:网站首页>【load dataset】
【load dataset】
2022-07-05 11:48:00 【Network starry sky (LUOC)】
List of articles

1.generate data txt file
# coding:utf-8
import os
''' Generate corresponding txt file '''
train_txt_path = os.path.join("../..", "..", "Data", "train.txt")
train_dir = os.path.join("../..", "..", "Data", "train")
valid_txt_path = os.path.join("../..", "..", "Data", "valid.txt")
valid_dir = os.path.join("../..", "..", "Data", "valid")
def gen_txt(txt_path, img_dir):
f = open(txt_path, 'w')
for root, s_dirs, _ in os.walk(img_dir, topdown=True): # obtain train Name of each folder under the file
for sub_dir in s_dirs:
i_dir = os.path.join(root, sub_dir) # Get all kinds of folders Absolute path
img_list = os.listdir(i_dir) # Get all items under the category folder png Path to picture
for i in range(len(img_list)):
if not img_list[i].endswith('png'): # If it is not png file , skip
continue
label = img_list[i].split('_')[0]
img_path = os.path.join(i_dir, img_list[i])
line = img_path + ' ' + label + '\n'
f.write(line)
f.close()
if __name__ == '__main__':
gen_txt(train_txt_path, train_dir)
gen_txt(valid_txt_path, valid_dir)
2.MyDataset class
# coding: utf-8
from PIL import Image
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, txt_path, transform=None, target_transform=None):
fh = open(txt_path, 'r')
imgs = []
for line in fh:
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1])))
self.imgs = imgs # The main thing is to generate this list, then DataLoader Middle feeding index, adopt getitem Read image data
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index]
img = Image.open(fn).convert('RGB') # Pixel values 0~255, stay transfrom.totensor Will divide by 255, Change the pixel value to 0~1
if self.transform is not None:
img = self.transform(img) # Do it here transform, To tensor wait
return img, label
def __len__(self):
return len(self.imgs)
3.instance MyDataset
train_data = MyDataset(txt_path=train_txt_path, transform=trainTransform)
valid_data = MyDataset(txt_path=valid_txt_path, transform=validTransform)
4.compute mean
# coding: utf-8
import numpy as np
import cv2
import random
import os
""" Random selection CNum A picture , Calculate the mean value by channel mean And standard deviation std First, change the pixels from 0~255 Normalize to 0-1 Calculate again """
train_txt_path = os.path.join("../..", "..", "Data/train.txt")
CNum = 2000 # How many pictures are selected for calculation
img_h, img_w = 32, 32
imgs = np.zeros([img_w, img_h, 3, 1])
means, stdevs = [], []
with open(train_txt_path, 'r') as f:
lines = f.readlines()
random.shuffle(lines) # shuffle , Randomly selected pictures
for i in range(CNum):
img_path = lines[i].rstrip().split()[0]
img = cv2.imread(img_path)
img = cv2.resize(img, (img_h, img_w))
img = img[:, :, :, np.newaxis]
imgs = np.concatenate((imgs, img), axis=3)
print(i)
imgs = imgs.astype(np.float32)/255.
for i in range(3):
pixels = imgs[:,:,i,:].ravel() # Pull into a line
means.append(np.mean(pixels))
stdevs.append(np.std(pixels))
means.reverse() # BGR --> RGB
stdevs.reverse()
print("normMean = {}".format(means))
print("normStd = {}".format(stdevs))
print('transforms.Normalize(normMean = {}, normStd = {})'.format(means, stdevs))
5.DataLoder
# pytorch dateset
#import torchvision
#train_data = torchvision.datasets.CIFAR10(root = './data/', train = True, transform = trainTransform, download = True)
#valid_data = torchvision.datasets.CIFAR10(root = './data/', train = False, transform = trainTransform, download = True)
# structure DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=train_bs, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=valid_bs)
6.net loss optimizer scheduler
#import torchvision.models as models
#net = models.vgg() # Create a network
# ------------------------------------ step 3/5 : Define the loss function and optimizer ------------------------------------
#criterion = nn.CrossEntropyLoss() # Choose the loss function
#optimizer = optim.SGD(net.parameters(), lr=lr_init, momentum=0.9, dampening=0.1) # Choose the optimizer
#scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # Set learning rate reduction strategy
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc2_1 = nn.Linear(84, 40)
self.fc3 = nn.Linear(40, 10)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc2_2(x))
x = self.fc3(x)
return x
# Define weight initialization
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
torch.nn.init.normal_(m.weight.data, 0, 0.01)
m.bias.data.zero_()
net = Net() # Create a network
# ================================ #
# finetune Weight initialization
# ================================ #
# load params
pretrained_dict = torch.load('net_params.pkl')
# Get the of the current network dict
net_state_dict = net.state_dict()
# Eliminate the mismatched weight parameters
pretrained_dict_1 = {
k: v for k, v in pretrained_dict.items() if k in net_state_dict}
# Update the new model parameter Dictionary
net_state_dict.update(pretrained_dict_1)
# The dictionary that will contain the pre training model parameters " discharge " To new model
net.load_state_dict(net_state_dict)
# ------------------------------------ step 3/5 : Define the loss function and optimizer ------------------------------------
# ================================= #
# Set the learning rate as needed
# ================================= #
# take fc3 Layer parameters are removed from the original network parameters
ignored_params = list(map(id, net.fc3.parameters()))
base_params = filter(lambda p: id(p) not in ignored_params, net.parameters())
# by fc3 The learning rate required for layer setup
optimizer = optim.SGD([
{
'params': base_params},
{
'params': net.fc3.parameters(), 'lr': lr_init*10}], lr_init, momentum=0.9, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss() # Choose the loss function
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.1) # Set learning rate reduction strategy
7. train
Insert a code chip here
边栏推荐
猜你喜欢

How can China Africa diamond accessory stones be inlaid to be safe and beautiful?
1个插件搞定网页中的广告

全网最全的新型数据库、多维表格平台盘点 Notion、FlowUs、Airtable、SeaTable、维格表 Vika、飞书多维表格、黑帕云、织信 Informat、语雀

13. (map data) conversion between Baidu coordinate (bd09), national survey of China coordinate (Mars coordinate, gcj02), and WGS84 coordinate system

【pytorch 修改预训练模型:实测加载预训练模型与模型随机初始化差别不大】
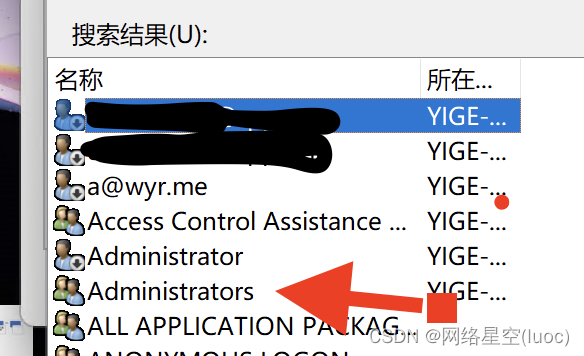
【Win11 多用户同时登录远程桌面配置方法】
Use and install RkNN toolkit Lite2 on itop-3568 development board NPU
The most comprehensive new database in the whole network, multidimensional table platform inventory note, flowus, airtable, seatable, Vig table Vika, flying Book Multidimensional table, heipayun, Zhix
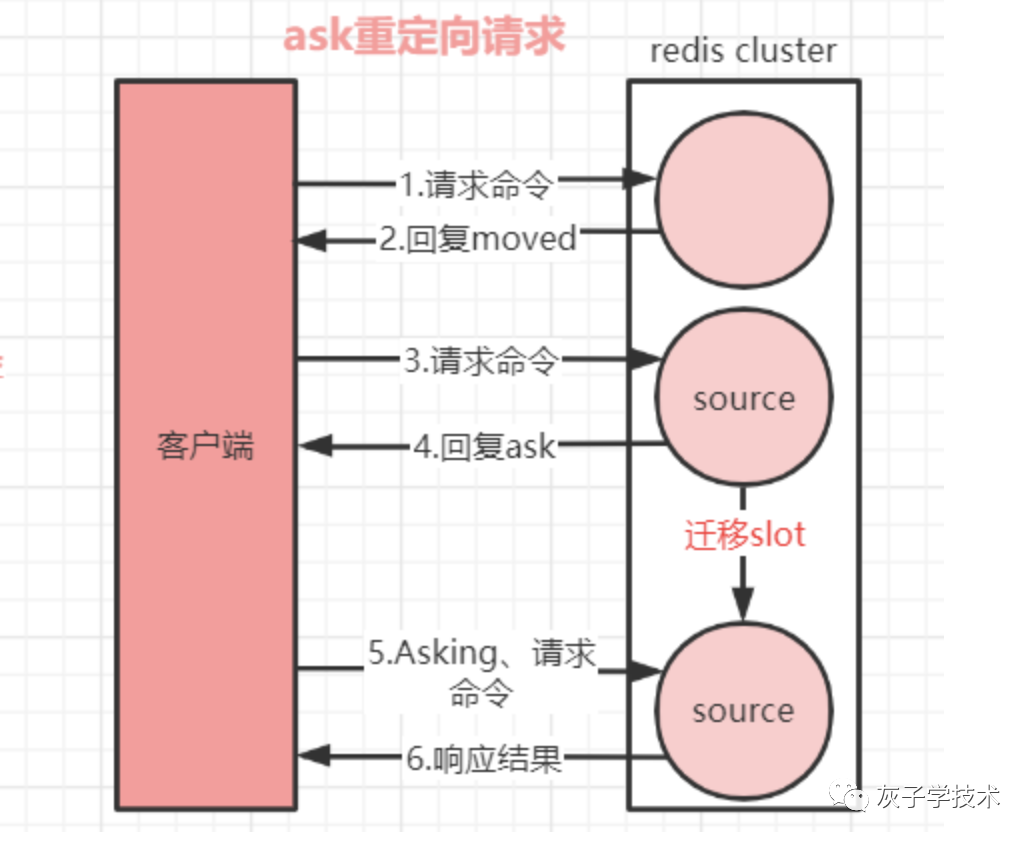
Redis集群的重定向
多表操作-子查询
随机推荐
[yolov3 loss function]
idea设置打开文件窗口个数
【load dataset】
Error assembling WAR: webxml attribute is required (or pre-existing WEB-INF/web.xml if executing in
c#操作xml文件
[singleshotmultiboxdetector (SSD, single step multi frame target detection)]
《增长黑客》阅读笔记
Prevent browser backward operation
What does cross-border e-commerce mean? What do you mainly do? What are the business models?
The ninth Operation Committee meeting of dragon lizard community was successfully held
【使用TensorRT通过ONNX部署Pytorch项目】
查看rancher中debug端口信息,并做IDEA Remote Jvm Debug
跨平台(32bit和64bit)的 printf 格式符 %lld 输出64位的解决方式
多表操作-自关联查询
调查显示传统数据安全工具在60%情况下无法抵御勒索软件攻击
[yolov5.yaml parsing]
Network five whip
【 YOLOv3中Loss部分计算】
Liunx prohibit Ping explain the different usage of traceroute
Shell script file traversal STR to array string splicing